 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-end Remote Sensing Change Detection of Unregistered Bi-temporal Images for Natural Disasters
Jul 27, 2023
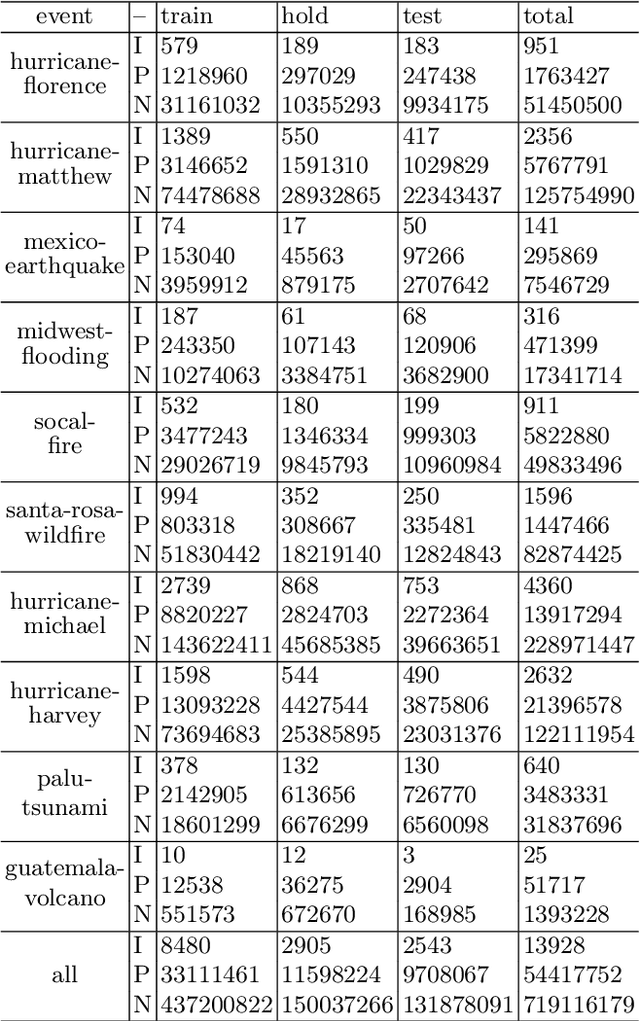
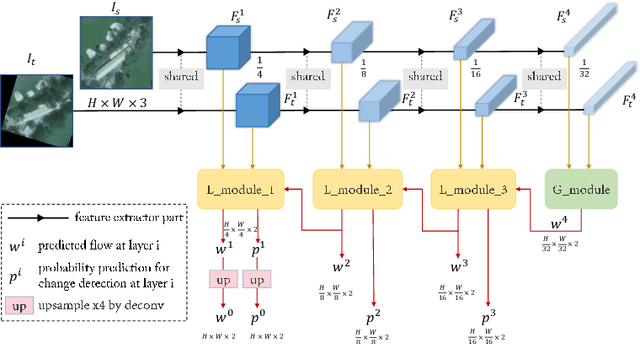
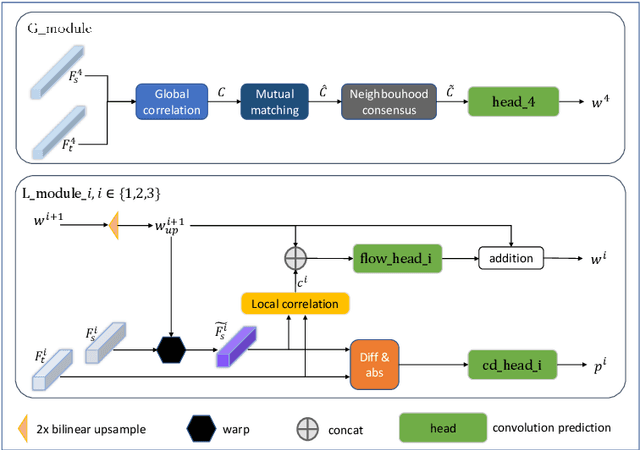

Change detection based on remote sensing images has been a prominent area of interest in the field of remote sensing. Deep networks have demonstrated significant success in detecting changes in bi-temporal remote sensing images and have found applications in various fields. Given the degradation of natural environments and the frequent occurrence of natural disasters, accurately and swiftly identifying damaged buildings in disaster-stricken areas through remote sensing images holds immense significance. This paper aims to investigate change detection specifically for natural disasters. Considering that existing public datasets used in change detection research are registered, which does not align with the practical scenario where bi-temporal images are not matched, this paper introduces an unregistered end-to-end change detection synthetic dataset called xBD-E2ECD. Furthermore, we propose an end-to-end change detection network named E2ECDNet, which takes an unregistered bi-temporal image pair as input and simultaneously generates the flow field prediction result and the change detection prediction result. It is worth noting that our E2ECDNet also supports change detection for registered image pairs, as registration can be seen as a special case of non-registration. Additionally, this paper redefines the criteria for correctly predicting a positive case and introduces neighborhood-based change detection evaluation metrics. The experimental results have demonstrated significant improvements.
Image Completion via Dual-path Cooperative Filtering
Apr 30, 2023

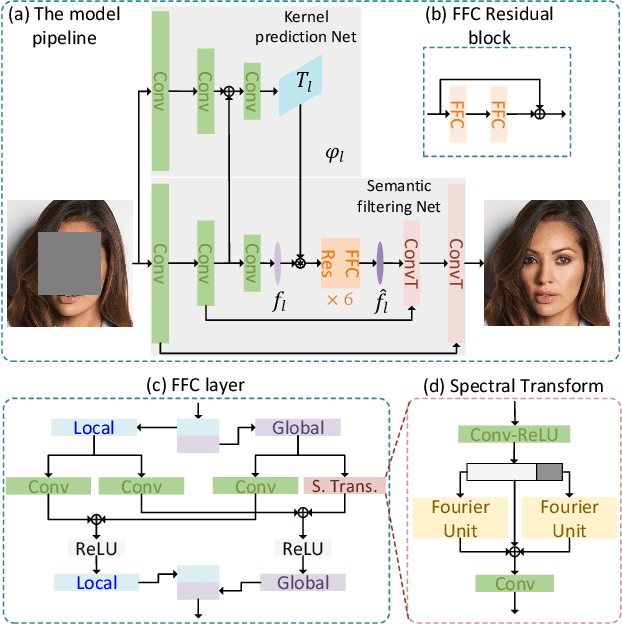
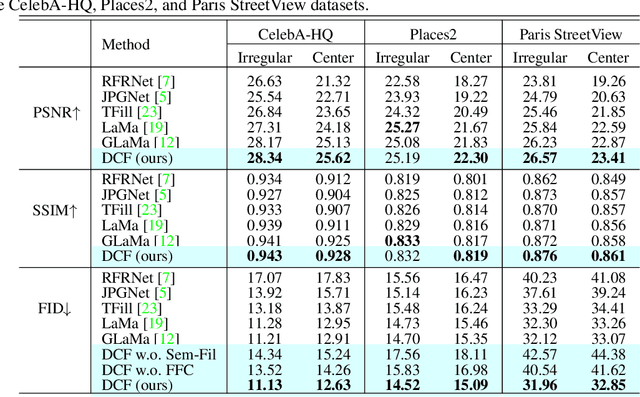
Given the recent advances with image-generating algorithms, deep image completion methods have made significant progress. However, state-of-art methods typically provide poor cross-scene generalization, and generated masked areas often contain blurry artifacts. Predictive filtering is a method for restoring images, which predicts the most effective kernels based on the input scene. Motivated by this approach, we address image completion as a filtering problem. Deep feature-level semantic filtering is introduced to fill in missing information, while preserving local structure and generating visually realistic content. In particular, a Dual-path Cooperative Filtering (DCF) model is proposed, where one path predicts dynamic kernels, and the other path extracts multi-level features by using Fast Fourier Convolution to yield semantically coherent reconstructions. Experiments on three challenging image completion datasets show that our proposed DCF outperforms state-of-art methods.
FB-BEV: BEV Representation from Forward-Backward View Transformations
Aug 04, 2023
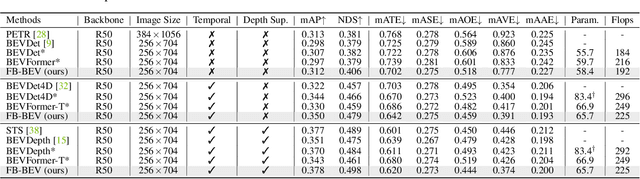
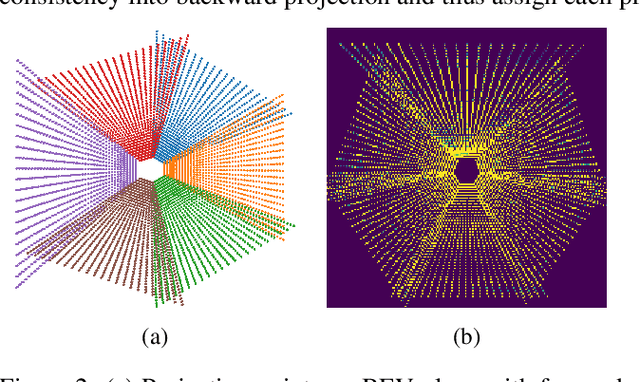
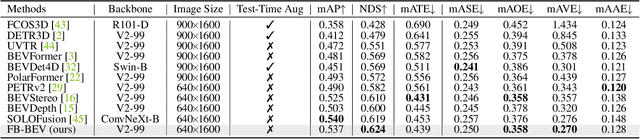
View Transformation Module (VTM), where transformations happen between multi-view image features and Bird-Eye-View (BEV) representation, is a crucial step in camera-based BEV perception systems. Currently, the two most prominent VTM paradigms are forward projection and backward projection. Forward projection, represented by Lift-Splat-Shoot, leads to sparsely projected BEV features without post-processing. Backward projection, with BEVFormer being an example, tends to generate false-positive BEV features from incorrect projections due to the lack of utilization on depth. To address the above limitations, we propose a novel forward-backward view transformation module. Our approach compensates for the deficiencies in both existing methods, allowing them to enhance each other to obtain higher quality BEV representations mutually. We instantiate the proposed module with FB-BEV, which achieves a new state-of-the-art result of 62.4\% NDS on the nuScenes test set. The code will be released at \url{https://github.com/NVlabs/FB-BEV}.
Multimodal Pretrained Models for Sequential Decision-Making: Synthesis, Verification, Grounding, and Perception
Aug 10, 2023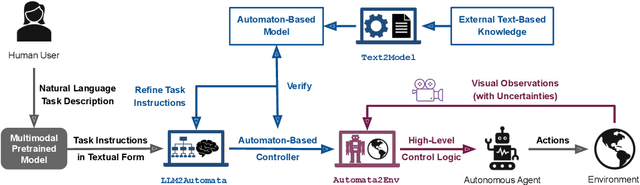
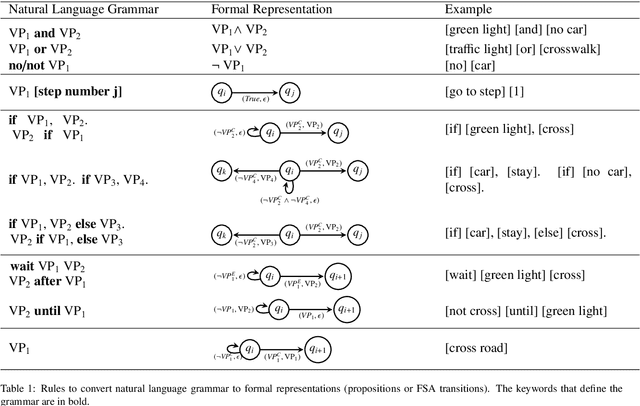
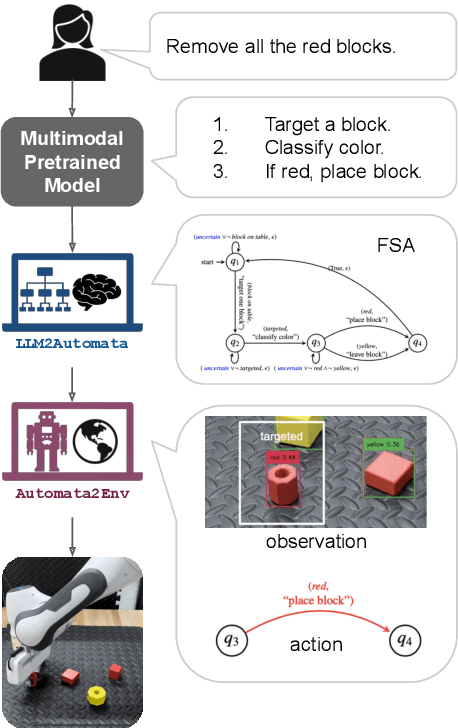
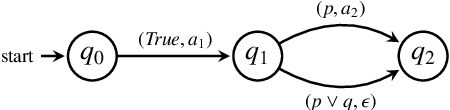
Recently developed pretrained models can encode rich world knowledge expressed in multiple modalities, such as text and images. However, the outputs of these models cannot be integrated into algorithms to solve sequential decision-making tasks. We develop an algorithm that utilizes the knowledge from pretrained models to construct and verify controllers for sequential decision-making tasks, and to ground these controllers to task environments through visual observations. In particular, the algorithm queries a pretrained model with a user-provided, text-based task description and uses the model's output to construct an automaton-based controller that encodes the model's task-relevant knowledge. It then verifies whether the knowledge encoded in the controller is consistent with other independently available knowledge, which may include abstract information on the environment or user-provided specifications. If this verification step discovers any inconsistency, the algorithm automatically refines the controller to resolve the inconsistency. Next, the algorithm leverages the vision and language capabilities of pretrained models to ground the controller to the task environment. It collects image-based observations from the task environment and uses the pretrained model to link these observations to the text-based control logic encoded in the controller (e.g., actions and conditions that trigger the actions). We propose a mechanism to ensure the controller satisfies the user-provided specification even when perceptual uncertainties are present. We demonstrate the algorithm's ability to construct, verify, and ground automaton-based controllers through a suite of real-world tasks, including daily life and robot manipulation tasks.
Geometric Learning-Based Transformer Network for Estimation of Segmentation Errors
Aug 10, 2023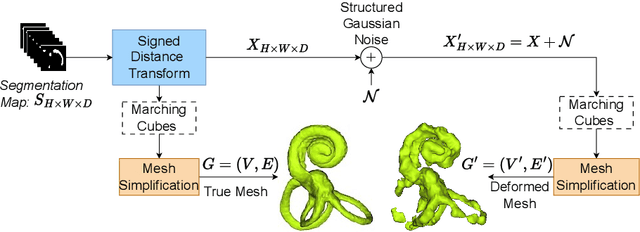

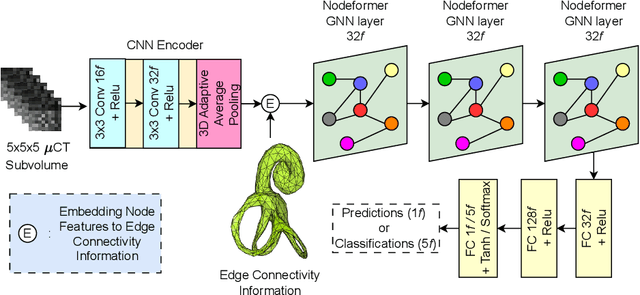
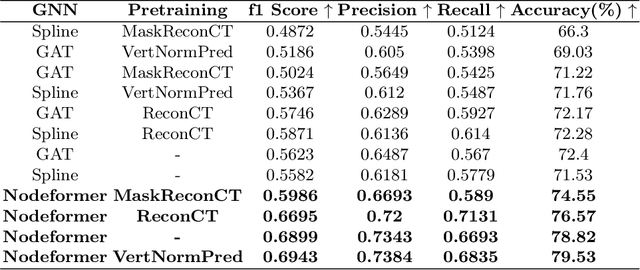
Many segmentation networks have been proposed for 3D volumetric segmentation of tumors and organs at risk. Hospitals and clinical institutions seek to accelerate and minimize the efforts of specialists in image segmentation. Still, in case of errors generated by these networks, clinicians would have to manually edit the generated segmentation maps. Given a 3D volume and its putative segmentation map, we propose an approach to identify and measure erroneous regions in the segmentation map. Our method can estimate error at any point or node in a 3D mesh generated from a possibly erroneous volumetric segmentation map, serving as a Quality Assurance tool. We propose a graph neural network-based transformer based on the Nodeformer architecture to measure and classify the segmentation errors at any point. We have evaluated our network on a high-resolution micro-CT dataset of the human inner-ear bony labyrinth structure by simulating erroneous 3D segmentation maps. Our network incorporates a convolutional encoder to compute node-centric features from the input micro-CT data, the Nodeformer to learn the latent graph embeddings, and a Multi-Layer Perceptron (MLP) to compute and classify the node-wise errors. Our network achieves a mean absolute error of ~0.042 over other Graph Neural Networks (GNN) and an accuracy of 79.53% over other GNNs in estimating and classifying the node-wise errors, respectively. We also put forth vertex-normal prediction as a custom pretext task for pre-training the CNN encoder to improve the network's overall performance. Qualitative analysis shows the efficiency of our network in correctly classifying errors and reducing misclassifications.
On the Challenges and Perspectives of Foundation Models for Medical Image Analysis
Jun 09, 2023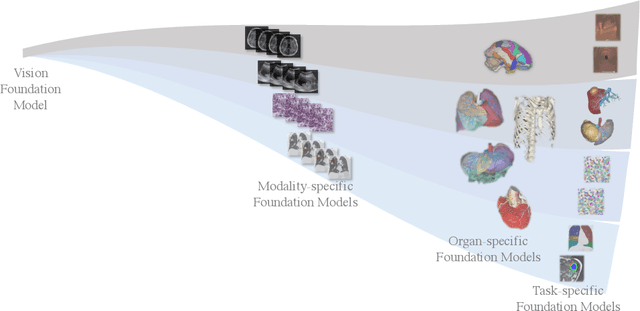
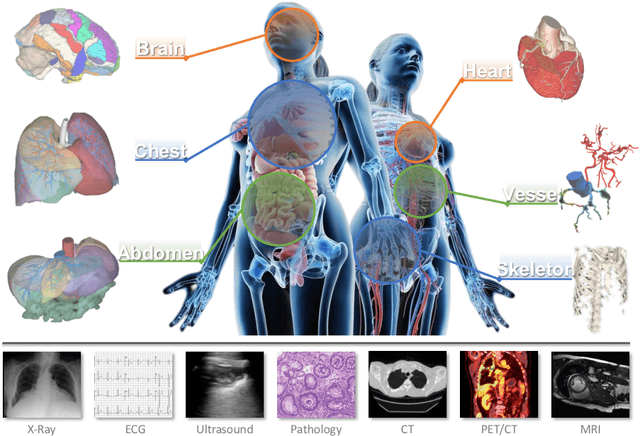

This article discusses the opportunities, applications and future directions of large-scale pre-trained models, i.e., foundation models, for analyzing medical images. Medical foundation models have immense potential in solving a wide range of downstream tasks, as they can help to accelerate the development of accurate and robust models, reduce the large amounts of required labeled data, preserve the privacy and confidentiality of patient data. Specifically, we illustrate the "spectrum" of medical foundation models, ranging from general vision models, modality-specific models, to organ/task-specific models, highlighting their challenges, opportunities and applications. We also discuss how foundation models can be leveraged in downstream medical tasks to enhance the accuracy and efficiency of medical image analysis, leading to more precise diagnosis and treatment decisions.
What do neural networks learn in image classification? A frequency shortcut perspective
Jul 19, 2023
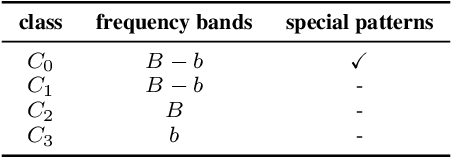
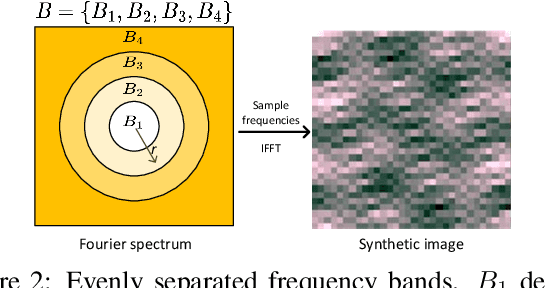
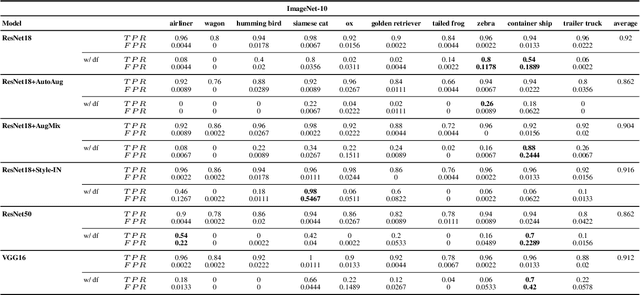
Frequency analysis is useful for understanding the mechanisms of representation learning in neural networks (NNs). Most research in this area focuses on the learning dynamics of NNs for regression tasks, while little for classification. This study empirically investigates the latter and expands the understanding of frequency shortcuts. First, we perform experiments on synthetic datasets, designed to have a bias in different frequency bands. Our results demonstrate that NNs tend to find simple solutions for classification, and what they learn first during training depends on the most distinctive frequency characteristics, which can be either low- or high-frequencies. Second, we confirm this phenomenon on natural images. We propose a metric to measure class-wise frequency characteristics and a method to identify frequency shortcuts. The results show that frequency shortcuts can be texture-based or shape-based, depending on what best simplifies the objective. Third, we validate the transferability of frequency shortcuts on out-of-distribution (OOD) test sets. Our results suggest that frequency shortcuts can be transferred across datasets and cannot be fully avoided by larger model capacity and data augmentation. We recommend that future research should focus on effective training schemes mitigating frequency shortcut learning.
The Brain Tumor Segmentation (BraTS) Challenge 2023: Brain MR Image Synthesis for Tumor Segmentation (BraSyn)
May 20, 2023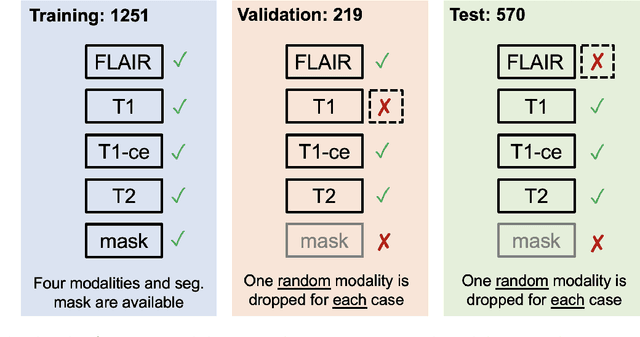
Automated brain tumor segmentation methods are well established, reaching performance levels with clear clinical utility. Most algorithms require four input magnetic resonance imaging (MRI) modalities, typically T1-weighted images with and without contrast enhancement, T2-weighted images, and FLAIR images. However, some of these sequences are often missing in clinical practice, e.g., because of time constraints and/or image artifacts (such as patient motion). Therefore, substituting missing modalities to recover segmentation performance in these scenarios is highly desirable and necessary for the more widespread adoption of such algorithms in clinical routine. In this work, we report the set-up of the Brain MR Image Synthesis Benchmark (BraSyn), organized in conjunction with the Medical Image Computing and Computer-Assisted Intervention (MICCAI) 2023. The objective of the challenge is to benchmark image synthesis methods that realistically synthesize missing MRI modalities given multiple available images to facilitate automated brain tumor segmentation pipelines. The image dataset is multi-modal and diverse, created in collaboration with various hospitals and research institutions.
Bridging the Gap: Multi-Level Cross-Modality Joint Alignment for Visible-Infrared Person Re-Identification
Jul 17, 2023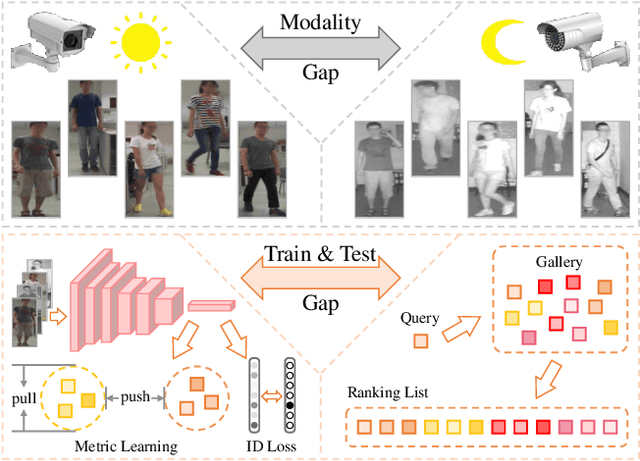
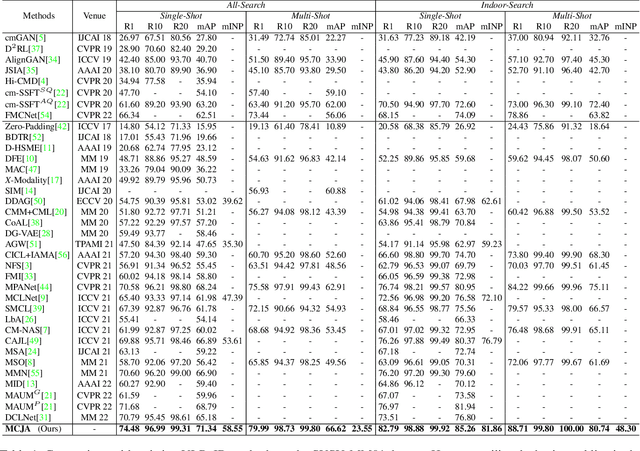
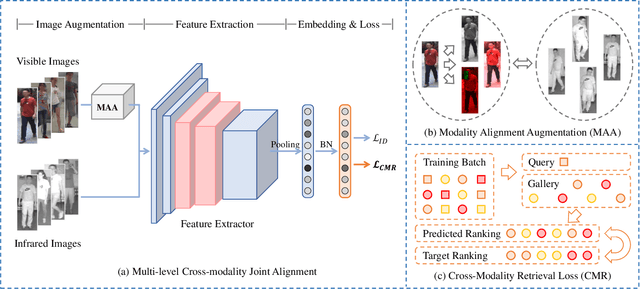
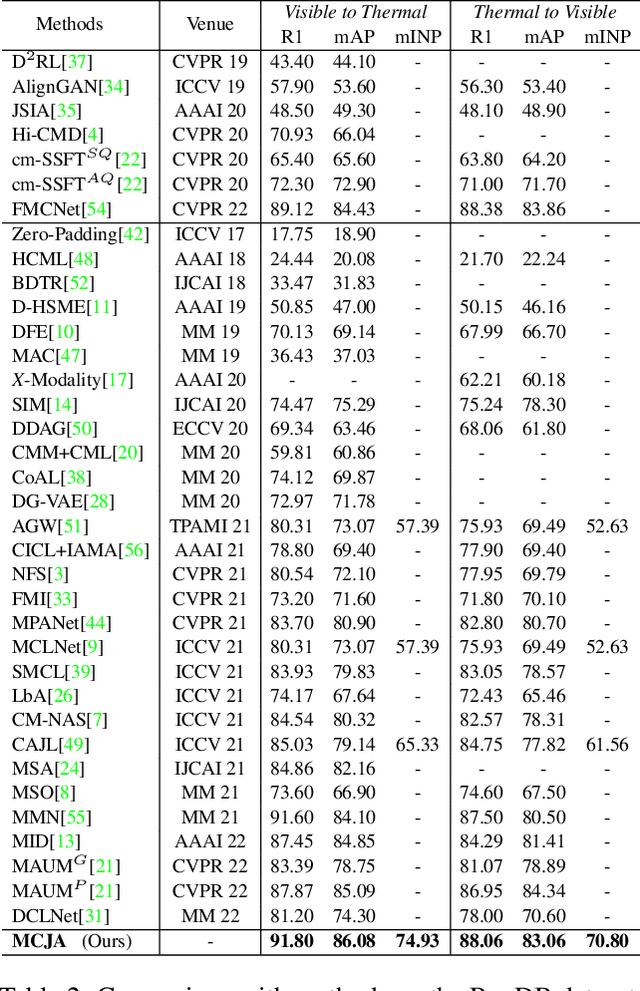
Visible-Infrared person Re-IDentification (VI-ReID) is a challenging cross-modality image retrieval task that aims to match pedestrians' images across visible and infrared cameras. To solve the modality gap, existing mainstream methods adopt a learning paradigm converting the image retrieval task into an image classification task with cross-entropy loss and auxiliary metric learning losses. These losses follow the strategy of adjusting the distribution of extracted embeddings to reduce the intra-class distance and increase the inter-class distance. However, such objectives do not precisely correspond to the final test setting of the retrieval task, resulting in a new gap at the optimization level. By rethinking these keys of VI-ReID, we propose a simple and effective method, the Multi-level Cross-modality Joint Alignment (MCJA), bridging both modality and objective-level gap. For the former, we design the Modality Alignment Augmentation, which consists of three novel strategies, the weighted grayscale, cross-channel cutmix, and spectrum jitter augmentation, effectively reducing modality discrepancy in the image space. For the latter, we introduce a new Cross-Modality Retrieval loss. It is the first work to constrain from the perspective of the ranking list, aligning with the goal of the testing stage. Moreover, based on the global feature only, our method exhibits good performance and can serve as a strong baseline method for the VI-ReID community.
Flow Matching in Latent Space
Jul 17, 2023
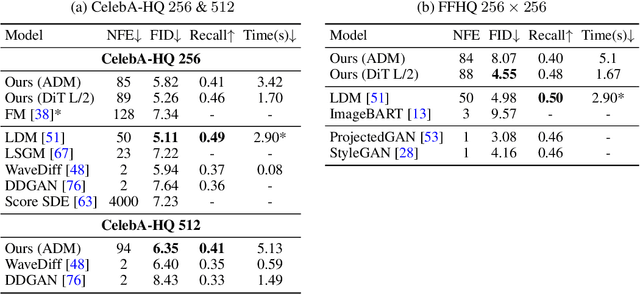

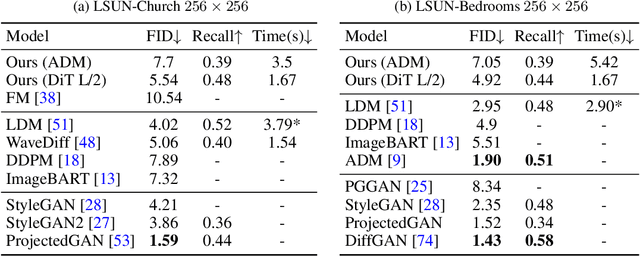
Flow matching is a recent framework to train generative models that exhibits impressive empirical performance while being relatively easier to train compared with diffusion-based models. Despite its advantageous properties, prior methods still face the challenges of expensive computing and a large number of function evaluations of off-the-shelf solvers in the pixel space. Furthermore, although latent-based generative methods have shown great success in recent years, this particular model type remains underexplored in this area. In this work, we propose to apply flow matching in the latent spaces of pretrained autoencoders, which offers improved computational efficiency and scalability for high-resolution image synthesis. This enables flow-matching training on constrained computational resources while maintaining their quality and flexibility. Additionally, our work stands as a pioneering contribution in the integration of various conditions into flow matching for conditional generation tasks, including label-conditioned image generation, image inpainting, and semantic-to-image generation. Through extensive experiments, our approach demonstrates its effectiveness in both quantitative and qualitative results on various datasets, such as CelebA-HQ, FFHQ, LSUN Church & Bedroom, and ImageNet. We also provide a theoretical control of the Wasserstein-2 distance between the reconstructed latent flow distribution and true data distribution, showing it is upper-bounded by the latent flow matching objective. Our code will be available at https://github.com/VinAIResearch/LFM.git.