 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unimodal Intermediate Training for Multimodal Meme Sentiment Classification
Aug 01, 2023
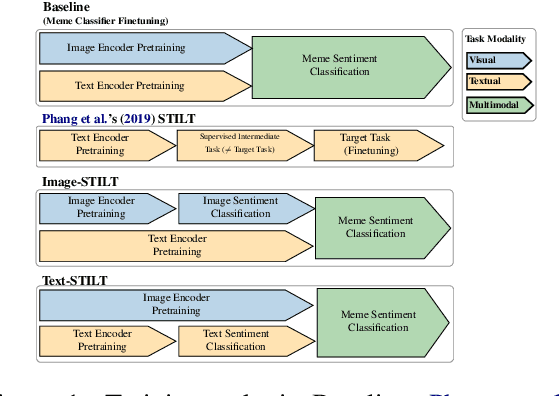

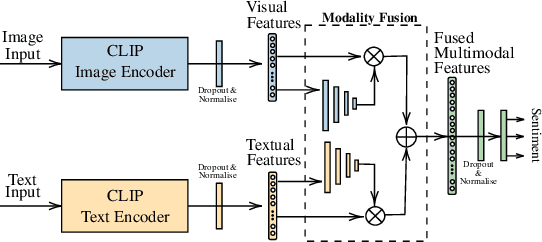
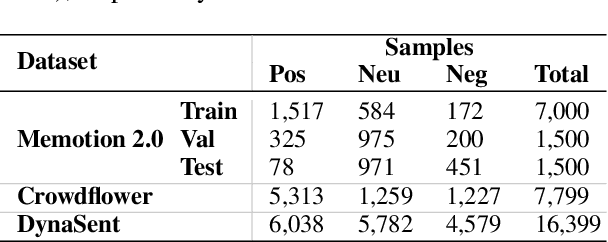
Internet Memes remain a challenging form of user-generated content for automated sentiment classification. The availability of labelled memes is a barrier to developing sentiment classifiers of multimodal memes. To address the shortage of labelled memes, we propose to supplement the training of a multimodal meme classifier with unimodal (image-only and text-only) data. In this work, we present a novel variant of supervised intermediate training that uses relatively abundant sentiment-labelled unimodal data. Our results show a statistically significant performance improvement from the incorporation of unimodal text data. Furthermore, we show that the training set of labelled memes can be reduced by 40% without reducing the performance of the downstream model.
Scene Separation & Data Selection: Temporal Segmentation Algorithm for Real-Time Video Stream Analysis
Aug 01, 2023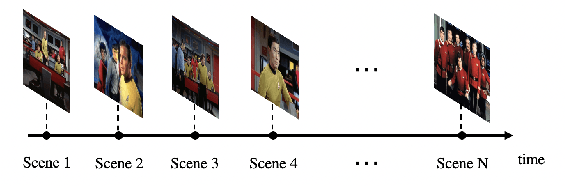
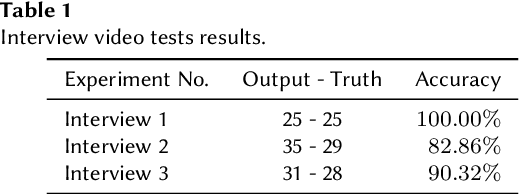
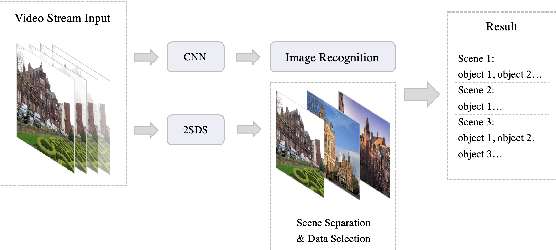
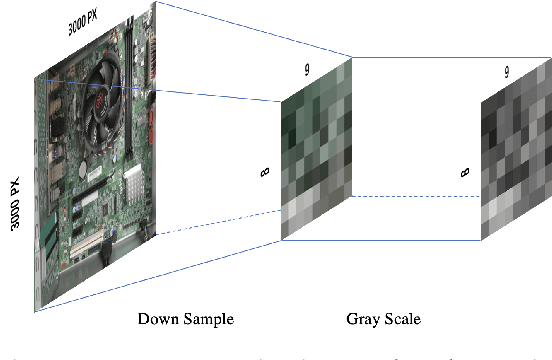
We present 2SDS (Scene Separation and Data Selection algorithm), a temporal segmentation algorithm used in real-time video stream interpretation. It complements CNN-based models to make use of temporal information in videos. 2SDS can detect the change between scenes in a video stream by com-paring the image difference between two frames. It separates a video into segments (scenes), and by combining itself with a CNN model, 2SDS can select the optimal result for each scene. In this paper, we will be discussing some basic methods and concepts behind 2SDS, as well as presenting some preliminary experiment results regarding 2SDS. During these experiments, 2SDS has achieved an overall accuracy of over 90%.
* 5 pages, 4 figures, at IJCAI-ECAI 2022 workshop, First International Workshop on Spatio-Temporal Reasoning and Learning, July 24, 2022, Vienna, Austria
DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models
May 24, 2023

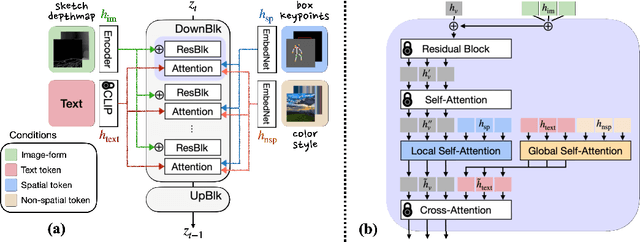
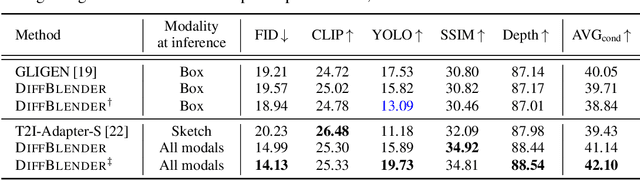
The recent progress in diffusion-based text-to-image generation models has significantly expanded generative capabilities via conditioning the text descriptions. However, since relying solely on text prompts is still restrictive for fine-grained customization, we aim to extend the boundaries of conditional generation to incorporate diverse types of modalities, e.g., sketch, box, and style embedding, simultaneously. We thus design a multimodal text-to-image diffusion model, coined as DiffBlender, that achieves the aforementioned goal in a single model by training only a few small hypernetworks. DiffBlender facilitates a convenient scaling of input modalities, without altering the parameters of an existing large-scale generative model to retain its well-established knowledge. Furthermore, our study sets new standards for multimodal generation by conducting quantitative and qualitative comparisons with existing approaches. By diversifying the channels of conditioning modalities, DiffBlender faithfully reflects the provided information or, in its absence, creates imaginative generation.
Principal Uncertainty Quantification with Spatial Correlation for Image Restoration Problems
May 17, 2023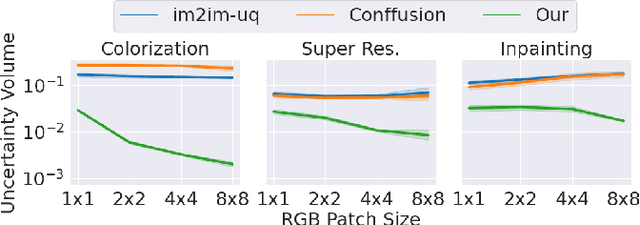


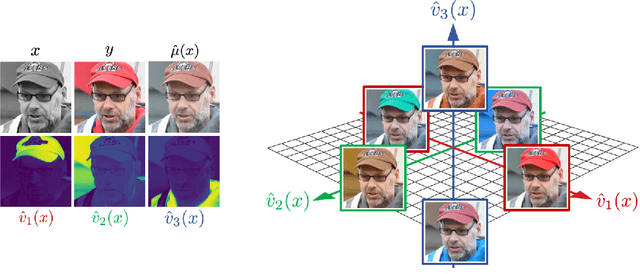
Uncertainty quantification for inverse problems in imaging has drawn much attention lately. Existing approaches towards this task define uncertainty regions based on probable values per pixel, while ignoring spatial correlations within the image, resulting in an exaggerated volume of uncertainty. In this paper, we propose PUQ (Principal Uncertainty Quantification) -- a novel definition and corresponding analysis of uncertainty regions that takes into account spatial relationships within the image, thus providing reduced volume regions. Using recent advancements in stochastic generative models, we derive uncertainty intervals around principal components of the empirical posterior distribution, forming an ambiguity region that guarantees the inclusion of true unseen values with a user confidence probability. To improve computational efficiency and interpretability, we also guarantee the recovery of true unseen values using only a few principal directions, resulting in ultimately more informative uncertainty regions. Our approach is verified through experiments on image colorization, super-resolution, and inpainting; its effectiveness is shown through comparison to baseline methods, demonstrating significantly tighter uncertainty regions.
Improving Viewpoint Robustness for Visual Recognition via Adversarial Training
Jul 21, 2023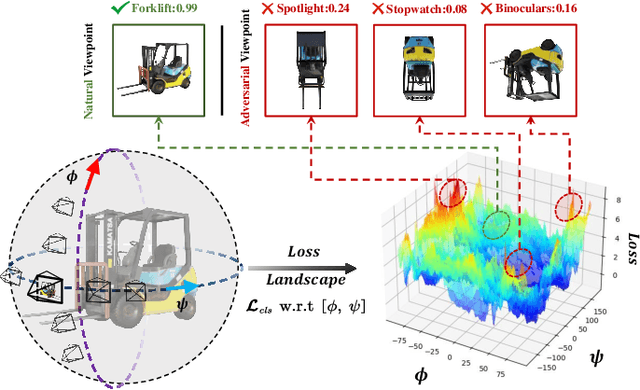
Viewpoint invariance remains challenging for visual recognition in the 3D world, as altering the viewing directions can significantly impact predictions for the same object. While substantial efforts have been dedicated to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. Motivated by the success of adversarial training in enhancing model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve the viewpoint robustness of image classifiers. Regarding viewpoint transformation as an attack, we formulate VIAT as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on the proposed attack method GMVFool. The outer minimization obtains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case viewpoint distributions that can share the same one for different objects within the same category. Based on GMVFool, we contribute a large-scale dataset called ImageNet-V+ to benchmark viewpoint robustness. Experimental results show that VIAT significantly improves the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool. Furthermore, we propose ViewRS, a certified viewpoint robustness method that provides a certified radius and accuracy to demonstrate the effectiveness of VIAT from the theoretical perspective.
SegNetr: Rethinking the local-global interactions and skip connections in U-shaped networks
Jul 21, 2023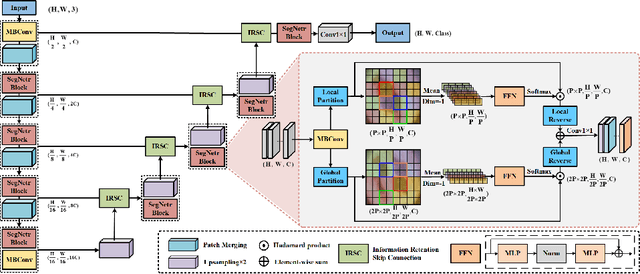
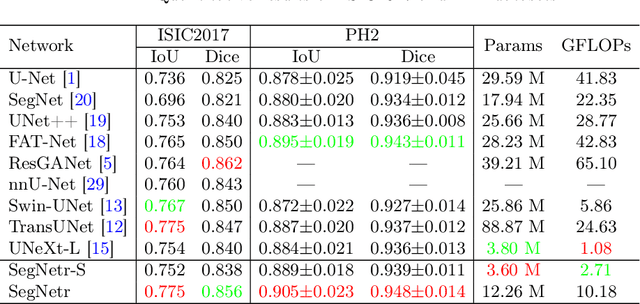
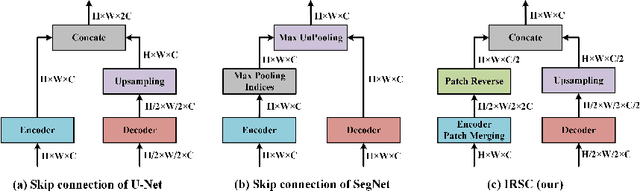
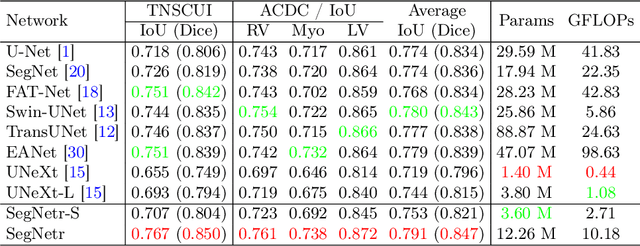
Recently, U-shaped networks have dominated the field of medical image segmentation due to their simple and easily tuned structure. However, existing U-shaped segmentation networks: 1) mostly focus on designing complex self-attention modules to compensate for the lack of long-term dependence based on convolution operation, which increases the overall number of parameters and computational complexity of the network; 2) simply fuse the features of encoder and decoder, ignoring the connection between their spatial locations. In this paper, we rethink the above problem and build a lightweight medical image segmentation network, called SegNetr. Specifically, we introduce a novel SegNetr block that can perform local-global interactions dynamically at any stage and with only linear complexity. At the same time, we design a general information retention skip connection (IRSC) to preserve the spatial location information of encoder features and achieve accurate fusion with the decoder features. We validate the effectiveness of SegNetr on four mainstream medical image segmentation datasets, with 59\% and 76\% fewer parameters and GFLOPs than vanilla U-Net, while achieving segmentation performance comparable to state-of-the-art methods. Notably, the components proposed in this paper can be applied to other U-shaped networks to improve their segmentation performance.
Feature Learning in Image Hierarchies using Functional Maximal Correlation
May 31, 2023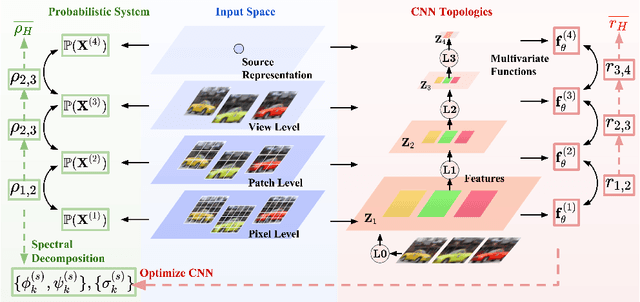
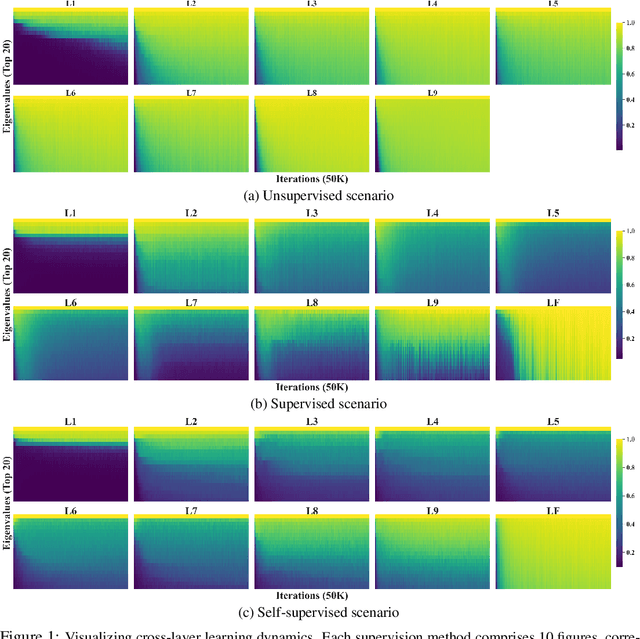
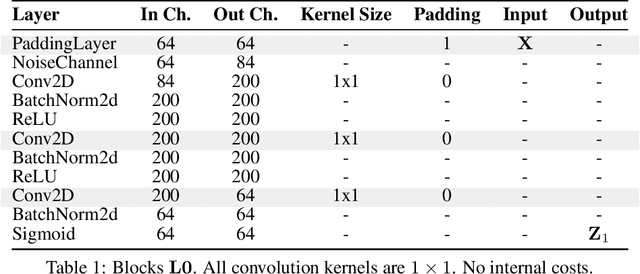
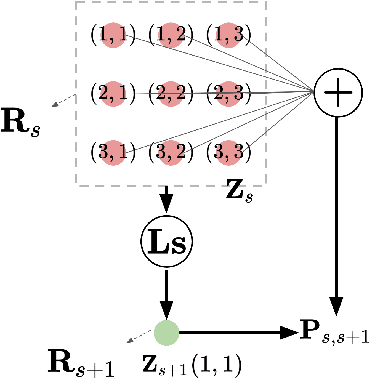
This paper proposes the Hierarchical Functional Maximal Correlation Algorithm (HFMCA), a hierarchical methodology that characterizes dependencies across two hierarchical levels in multiview systems. By framing view similarities as dependencies and ensuring contrastivity by imposing orthonormality, HFMCA achieves faster convergence and increased stability in self-supervised learning. HFMCA defines and measures dependencies within image hierarchies, from pixels and patches to full images. We find that the network topology for approximating orthonormal basis functions aligns with a vanilla CNN, enabling the decomposition of density ratios between neighboring layers of feature maps. This approach provides powerful interpretability, revealing the resemblance between supervision and self-supervision through the lens of internal representations.
T-former: An Efficient Transformer for Image Inpainting
May 12, 2023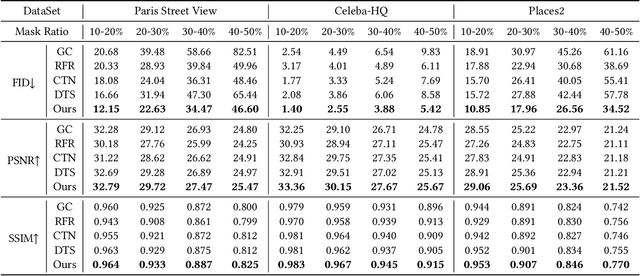
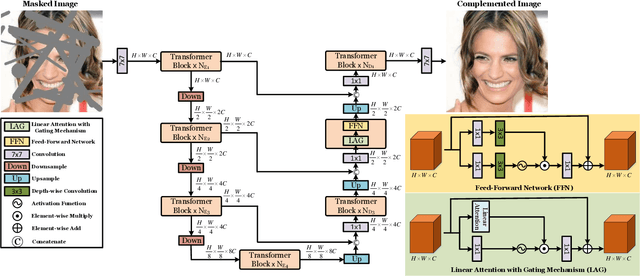


Benefiting from powerful convolutional neural networks (CNNs), learning-based image inpainting methods have made significant breakthroughs over the years. However, some nature of CNNs (e.g. local prior, spatially shared parameters) limit the performance in the face of broken images with diverse and complex forms. Recently, a class of attention-based network architectures, called transformer, has shown significant performance on natural language processing fields and high-level vision tasks. Compared with CNNs, attention operators are better at long-range modeling and have dynamic weights, but their computational complexity is quadratic in spatial resolution, and thus less suitable for applications involving higher resolution images, such as image inpainting. In this paper, we design a novel attention linearly related to the resolution according to Taylor expansion. And based on this attention, a network called $T$-former is designed for image inpainting. Experiments on several benchmark datasets demonstrate that our proposed method achieves state-of-the-art accuracy while maintaining a relatively low number of parameters and computational complexity. The code can be found at \href{https://github.com/dengyecode/T-former_image_inpainting}{github.com/dengyecode/T-former\_image\_inpainting}
Classification of Visualization Types and Perspectives in Patents
Jul 19, 2023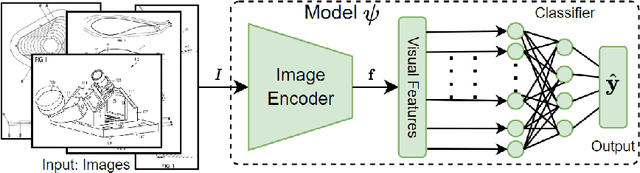
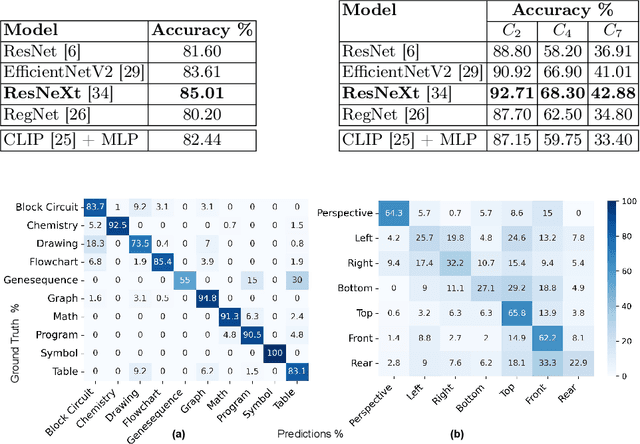

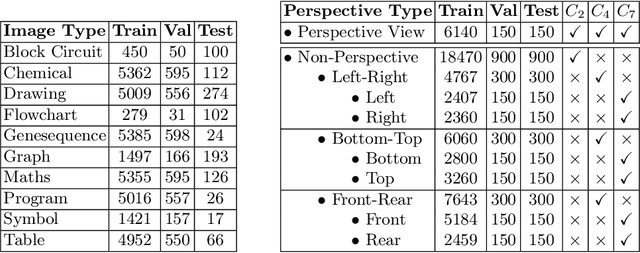
Due to the swift growth of patent applications each year, information and multimedia retrieval approaches that facilitate patent exploration and retrieval are of utmost importance. Different types of visualizations (e.g., graphs, technical drawings) and perspectives (e.g., side view, perspective) are used to visualize details of innovations in patents. The classification of these images enables a more efficient search and allows for further analysis. So far, datasets for image type classification miss some important visualization types for patents. Furthermore, related work does not make use of recent deep learning approaches including transformers. In this paper, we adopt state-of-the-art deep learning methods for the classification of visualization types and perspectives in patent images. We extend the CLEF-IP dataset for image type classification in patents to ten classes and provide manual ground truth annotations. In addition, we derive a set of hierarchical classes from a dataset that provides weakly-labeled data for image perspectives. Experimental results have demonstrated the feasibility of the proposed approaches. Source code, models, and dataset will be made publicly available.
Deep Homography Prediction for Endoscopic Camera Motion Imitation Learning
Jul 24, 2023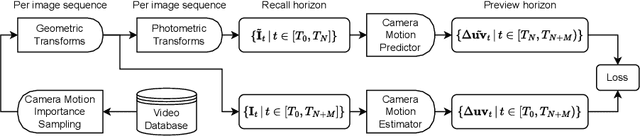

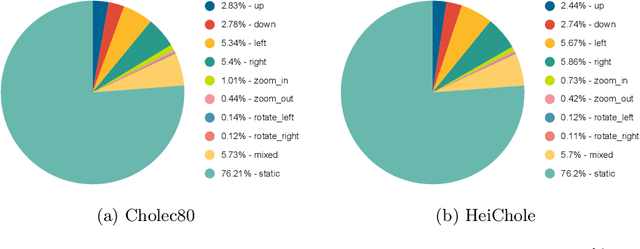
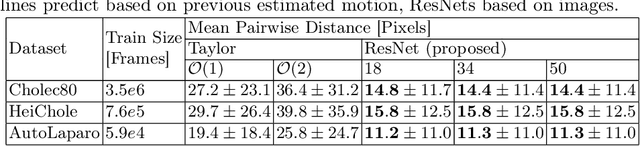
In this work, we investigate laparoscopic camera motion automation through imitation learning from retrospective videos of laparoscopic interventions. A novel method is introduced that learns to augment a surgeon's behavior in image space through object motion invariant image registration via homographies. Contrary to existing approaches, no geometric assumptions are made and no depth information is necessary, enabling immediate translation to a robotic setup. Deviating from the dominant approach in the literature which consist of following a surgical tool, we do not handcraft the objective and no priors are imposed on the surgical scene, allowing the method to discover unbiased policies. In this new research field, significant improvements are demonstrated over two baselines on the Cholec80 and HeiChole datasets, showcasing an improvement of 47% over camera motion continuation. The method is further shown to indeed predict camera motion correctly on the public motion classification labels of the AutoLaparo dataset. All code is made accessible on GitHub.