 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ADASSM: Adversarial Data Augmentation in Statistical Shape Models From Images
Jul 10, 2023
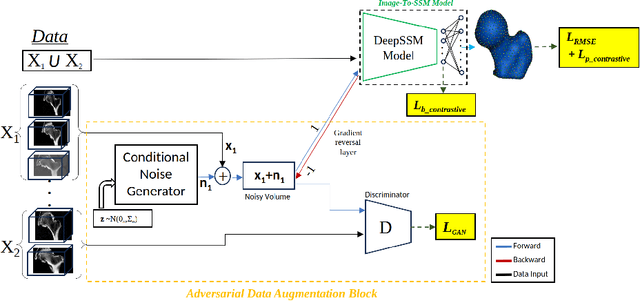
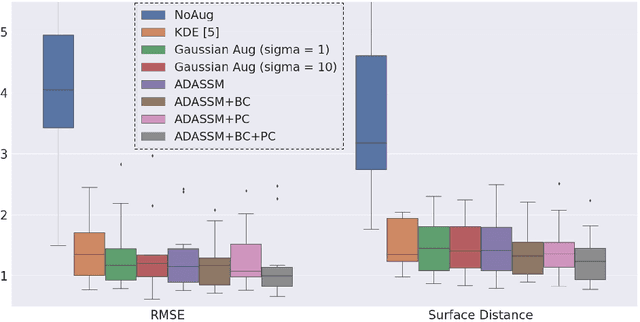
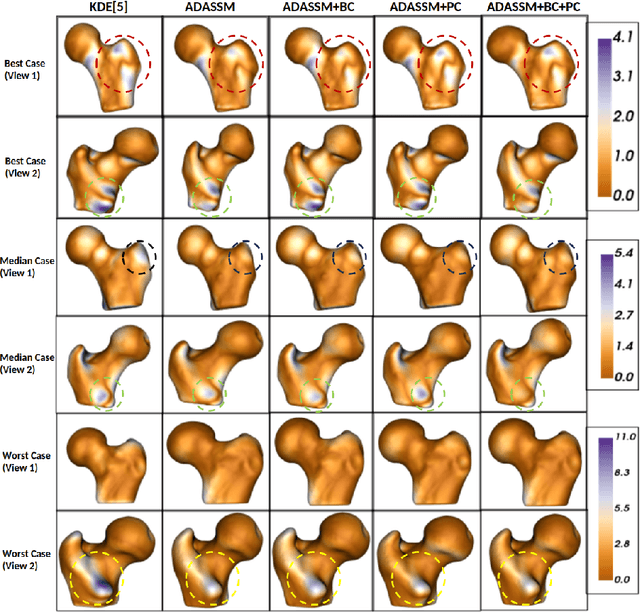
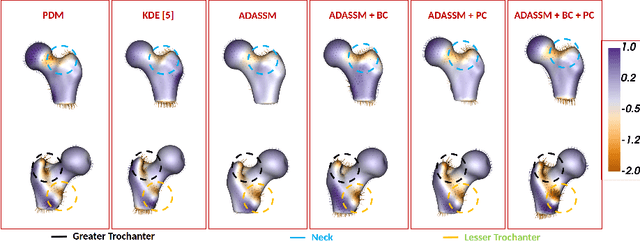
Statistical shape models (SSM) have been well-established as an excellent tool for identifying variations in the morphology of anatomy across the underlying population. Shape models use consistent shape representation across all the samples in a given cohort, which helps to compare shapes and identify the variations that can detect pathologies and help in formulating treatment plans. In medical imaging, computing these shape representations from CT/MRI scans requires time-intensive preprocessing operations, including but not limited to anatomy segmentation annotations, registration, and texture denoising. Deep learning models have demonstrated exceptional capabilities in learning shape representations directly from volumetric images, giving rise to highly effective and efficient Image-to-SSM. Nevertheless, these models are data-hungry and due to the limited availability of medical data, deep learning models tend to overfit. Offline data augmentation techniques, that use kernel density estimation based (KDE) methods for generating shape-augmented samples, have successfully aided Image-to-SSM networks in achieving comparable accuracy to traditional SSM methods. However, these augmentation methods focus on shape augmentation, whereas deep learning models exhibit image-based texture bias results in sub-optimal models. This paper introduces a novel strategy for on-the-fly data augmentation for the Image-to-SSM framework by leveraging data-dependent noise generation or texture augmentation. The proposed framework is trained as an adversary to the Image-to-SSM network, augmenting diverse and challenging noisy samples. Our approach achieves improved accuracy by encouraging the model to focus on the underlying geometry rather than relying solely on pixel values.
Domain Adaptation based Enhanced Detection for Autonomous Driving in Foggy and Rainy Weather
Jul 20, 2023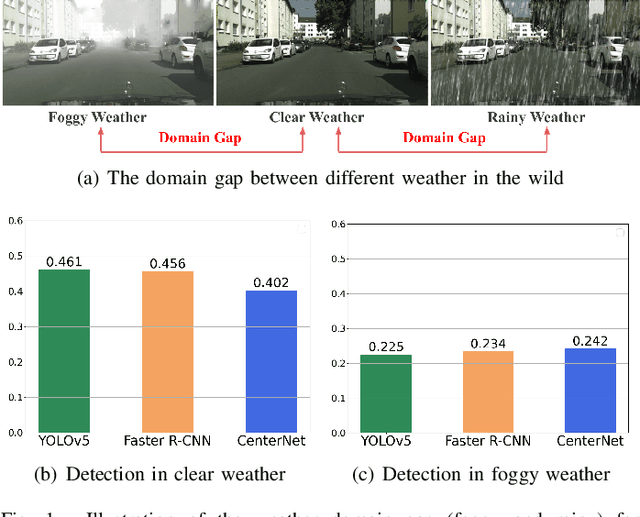
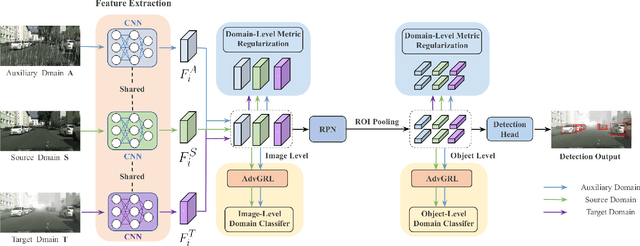

Typically, object detection methods for autonomous driving that rely on supervised learning make the assumption of a consistent feature distribution between the training and testing data, however such assumption may fail in different weather conditions. Due to the domain gap, a detection model trained under clear weather may not perform well in foggy and rainy conditions. Overcoming detection bottlenecks in foggy and rainy weather is a real challenge for autonomous vehicles deployed in the wild. To bridge the domain gap and improve the performance of object detectionin foggy and rainy weather, this paper presents a novel framework for domain-adaptive object detection. The adaptations at both the image-level and object-level are intended to minimize the differences in image style and object appearance between domains. Furthermore, in order to improve the model's performance on challenging examples, we introduce a novel adversarial gradient reversal layer that conducts adversarial mining on difficult instances in addition to domain adaptation. Additionally, we suggest generating an auxiliary domain through data augmentation to enforce a new domain-level metric regularization. Experimental findings on public V2V benchmark exhibit a substantial enhancement in object detection specifically for foggy and rainy driving scenarios.
Joint Perceptual Learning for Enhancement and Object Detection in Underwater Scenarios
Jul 07, 2023
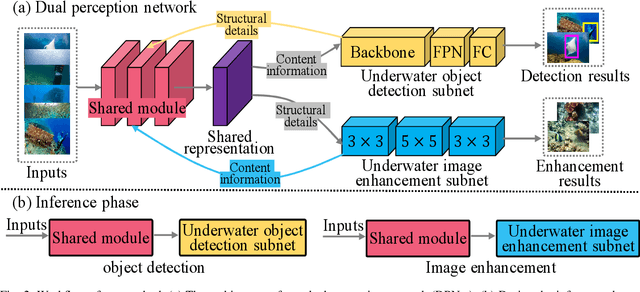
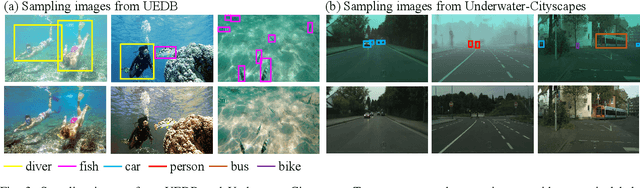

Underwater degraded images greatly challenge existing algorithms to detect objects of interest. Recently, researchers attempt to adopt attention mechanisms or composite connections for improving the feature representation of detectors. However, this solution does \textit{not} eliminate the impact of degradation on image content such as color and texture, achieving minimal improvements. Another feasible solution for underwater object detection is to develop sophisticated deep architectures in order to enhance image quality or features. Nevertheless, the visually appealing output of these enhancement modules do \textit{not} necessarily generate high accuracy for deep detectors. More recently, some multi-task learning methods jointly learn underwater detection and image enhancement, accessing promising improvements. Typically, these methods invoke huge architecture and expensive computations, rendering inefficient inference. Definitely, underwater object detection and image enhancement are two interrelated tasks. Leveraging information coming from the two tasks can benefit each task. Based on these factual opinions, we propose a bilevel optimization formulation for jointly learning underwater object detection and image enhancement, and then unroll to a dual perception network (DPNet) for the two tasks. DPNet with one shared module and two task subnets learns from the two different tasks, seeking a shared representation. The shared representation provides more structural details for image enhancement and rich content information for object detection. Finally, we derive a cooperative training strategy to optimize parameters for DPNet. Extensive experiments on real-world and synthetic underwater datasets demonstrate that our method outputs visually favoring images and higher detection accuracy.
Discrimination of Radiologists Utilizing Eye-Tracking Technology and Machine Learning: A Case Study
Aug 04, 2023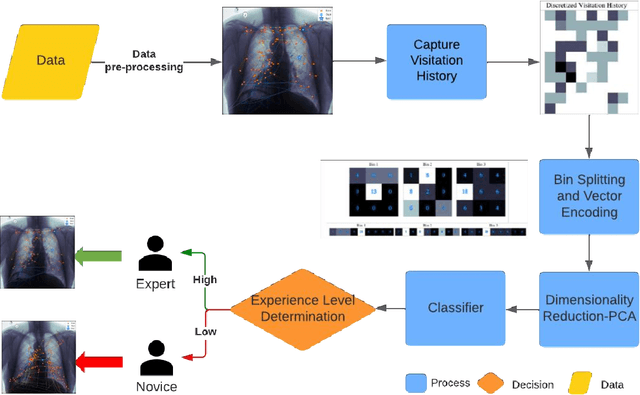
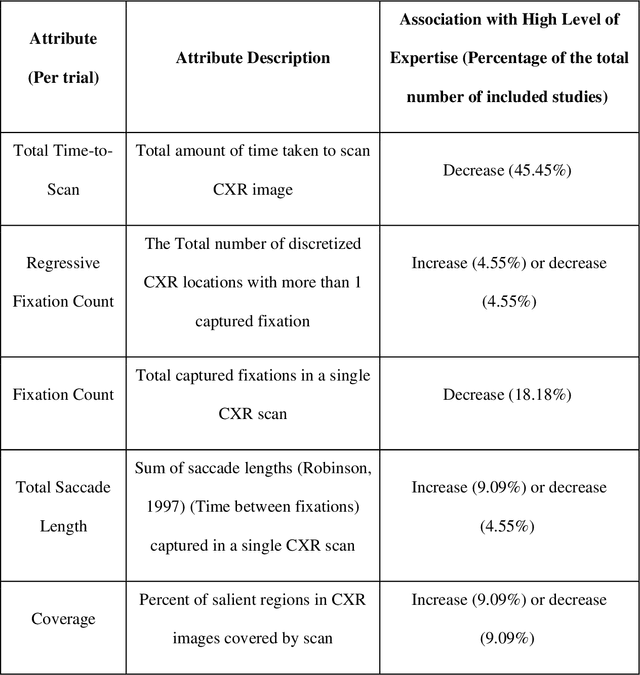
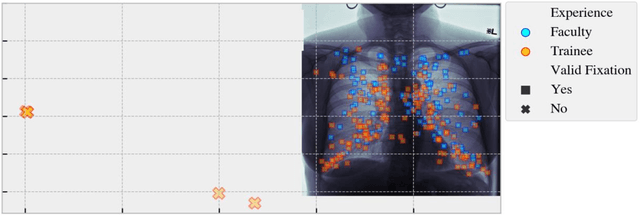
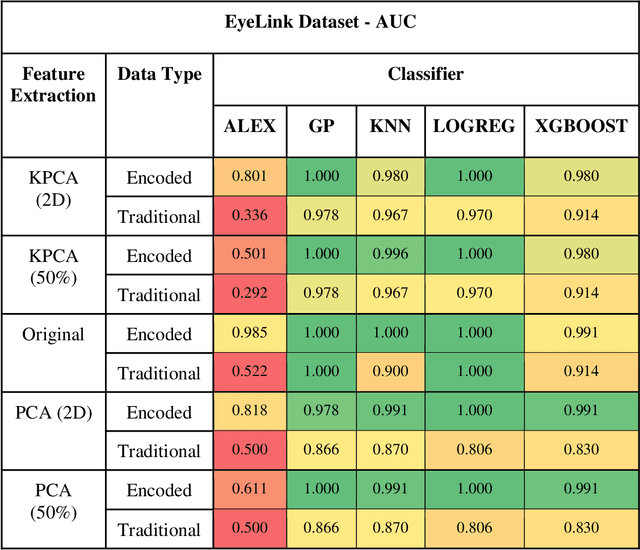
Perception-related errors comprise most diagnostic mistakes in radiology. To mitigate this problem, radiologists employ personalized and high-dimensional visual search strategies, otherwise known as search patterns. Qualitative descriptions of these search patterns, which involve the physician verbalizing or annotating the order he/she analyzes the image, can be unreliable due to discrepancies in what is reported versus the actual visual patterns. This discrepancy can interfere with quality improvement interventions and negatively impact patient care. This study presents a novel discretized feature encoding based on spatiotemporal binning of fixation data for efficient geometric alignment and temporal ordering of eye movement when reading chest X-rays. The encoded features of the eye-fixation data are employed by machine learning classifiers to discriminate between faculty and trainee radiologists. We include a clinical trial case study utilizing the Area Under the Curve (AUC), Accuracy, F1, Sensitivity, and Specificity metrics for class separability to evaluate the discriminability between the two subjects in regard to their level of experience. We then compare the classification performance to state-of-the-art methodologies. A repeatability experiment using a separate dataset, experimental protocol, and eye tracker was also performed using eight subjects to evaluate the robustness of the proposed approach. The numerical results from both experiments demonstrate that classifiers employing the proposed feature encoding methods outperform the current state-of-the-art in differentiating between radiologists in terms of experience level. This signifies the potential impact of the proposed method for identifying radiologists' level of expertise and those who would benefit from additional training.
Semantically Structured Image Compression via Irregular Group-Based Decoupling
May 04, 2023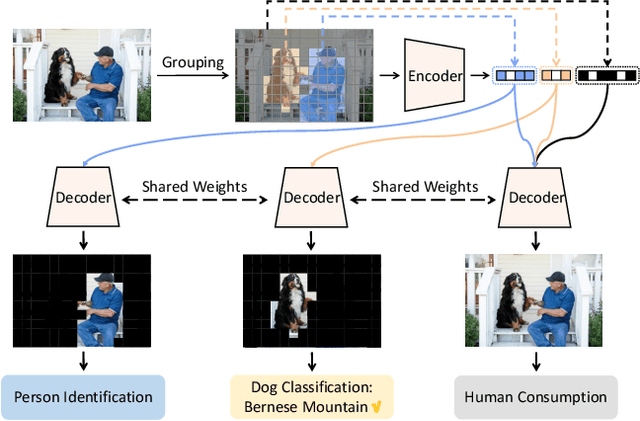
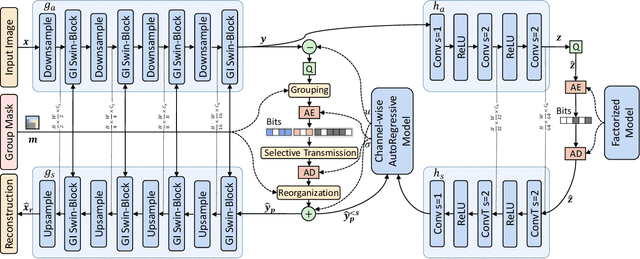
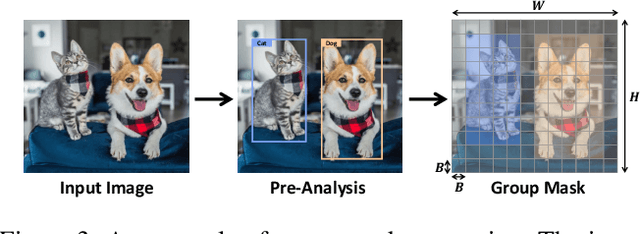
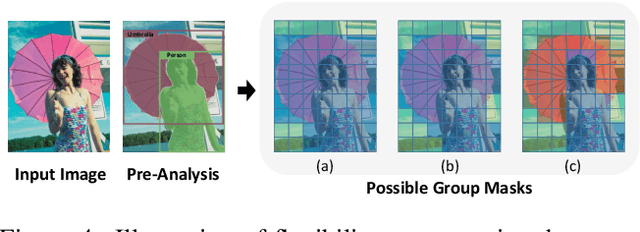
Image compression techniques typically focus on compressing rectangular images for human consumption, however, resulting in transmitting redundant content for downstream applications. To overcome this limitation, some previous works propose to semantically structure the bitstream, which can meet specific application requirements by selective transmission and reconstruction. Nevertheless, they divide the input image into multiple rectangular regions according to semantics and ignore avoiding information interaction among them, causing waste of bitrate and distorted reconstruction of region boundaries. In this paper, we propose to decouple an image into multiple groups with irregular shapes based on a customized group mask and compress them independently. Our group mask describes the image at a finer granularity, enabling significant bitrate saving by reducing the transmission of redundant content. Moreover, to ensure the fidelity of selective reconstruction, this paper proposes the concept of group-independent transform that maintain the independence among distinct groups. And we instantiate it by the proposed Group-Independent Swin-Block (GI Swin-Block). Experimental results demonstrate that our framework structures the bitstream with negligible cost, and exhibits superior performance on both visual quality and intelligent task supporting.
Late-Constraint Diffusion Guidance for Controllable Image Synthesis
May 19, 2023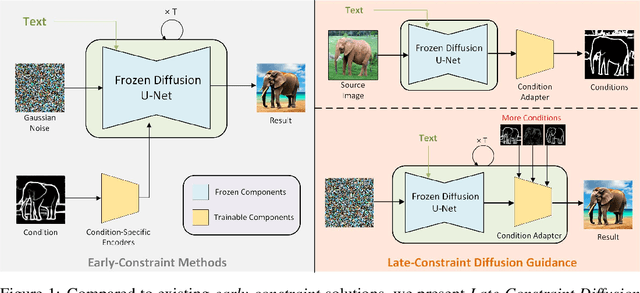
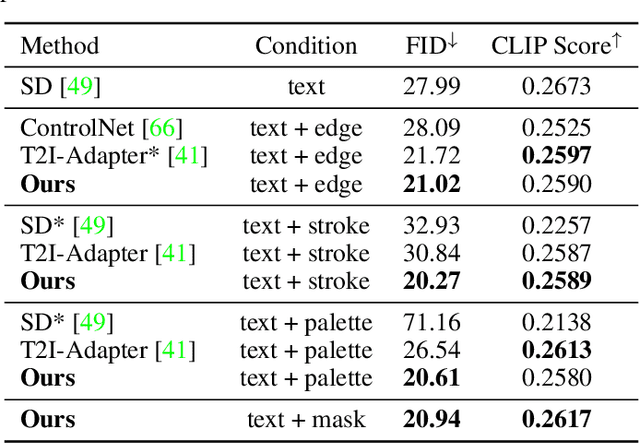
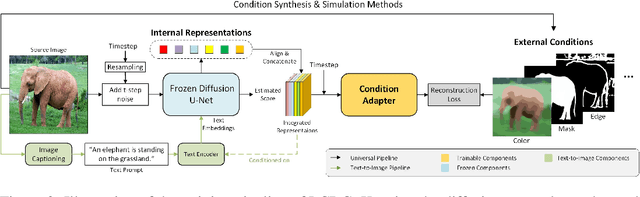
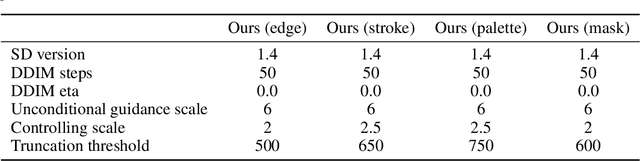
Diffusion models, either with or without text condition, have demonstrated impressive capability in synthesizing photorealistic images given a few or even no words. These models may not fully satisfy user need, as normal users or artists intend to control the synthesized images with specific guidance, like overall layout, color, structure, object shape, and so on. To adapt diffusion models for controllable image synthesis, several methods have been proposed to incorporate the required conditions as regularization upon the intermediate features of the diffusion denoising network. These methods, known as early-constraint ones in this paper, have difficulties in handling multiple conditions with a single solution. They intend to train separate models for each specific condition, which require much training cost and result in non-generalizable solutions. To address these difficulties, we propose a new approach namely late-constraint: we leave the diffusion networks unchanged, but constrain its output to be aligned with the required conditions. Specifically, we train a lightweight condition adapter to establish the correlation between external conditions and internal representations of diffusion models. During the iterative denoising process, the conditional guidance is sent into corresponding condition adapter to manipulate the sampling process with the established correlation. We further equip the introduced late-constraint strategy with a timestep resampling method and an early stopping technique, which boost the quality of synthesized image meanwhile complying with the guidance. Our method outperforms the existing early-constraint methods and generalizes better to unseen condition.
Latent Graph Attention for Enhanced Spatial Context
Jul 12, 2023
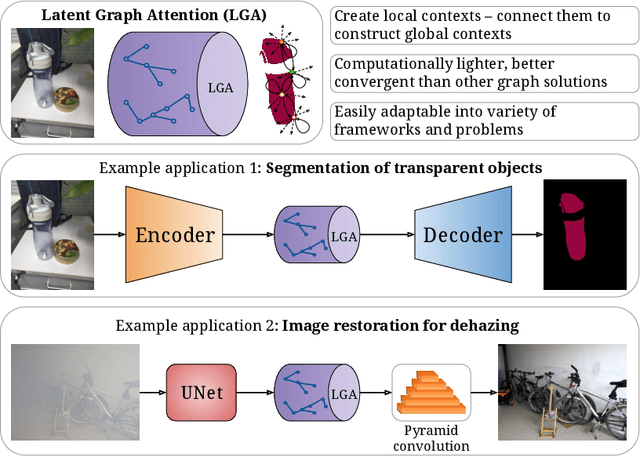
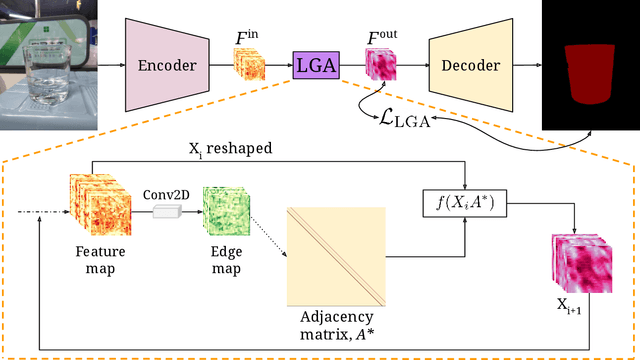
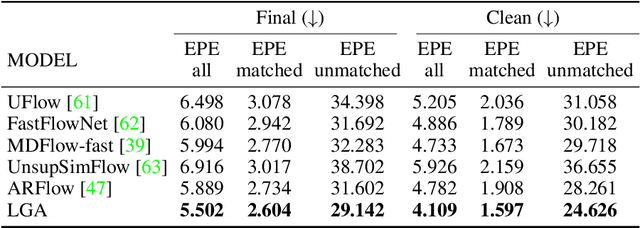
Global contexts in images are quite valuable in image-to-image translation problems. Conventional attention-based and graph-based models capture the global context to a large extent, however, these are computationally expensive. Moreover, the existing approaches are limited to only learning the pairwise semantic relation between any two points on the image. In this paper, we present Latent Graph Attention (LGA) a computationally inexpensive (linear to the number of nodes) and stable, modular framework for incorporating the global context in the existing architectures, especially empowering small-scale architectures to give performance closer to large size architectures, thus making the light-weight architectures more useful for edge devices with lower compute power and lower energy needs. LGA propagates information spatially using a network of locally connected graphs, thereby facilitating to construct a semantically coherent relation between any two spatially distant points that also takes into account the influence of the intermediate pixels. Moreover, the depth of the graph network can be used to adapt the extent of contextual spread to the target dataset, thereby being able to explicitly control the added computational cost. To enhance the learning mechanism of LGA, we also introduce a novel contrastive loss term that helps our LGA module to couple well with the original architecture at the expense of minimal additional computational load. We show that incorporating LGA improves the performance on three challenging applications, namely transparent object segmentation, image restoration for dehazing and optical flow estimation.
Multimodal Adaptation of CLIP for Few-Shot Action Recognition
Aug 03, 2023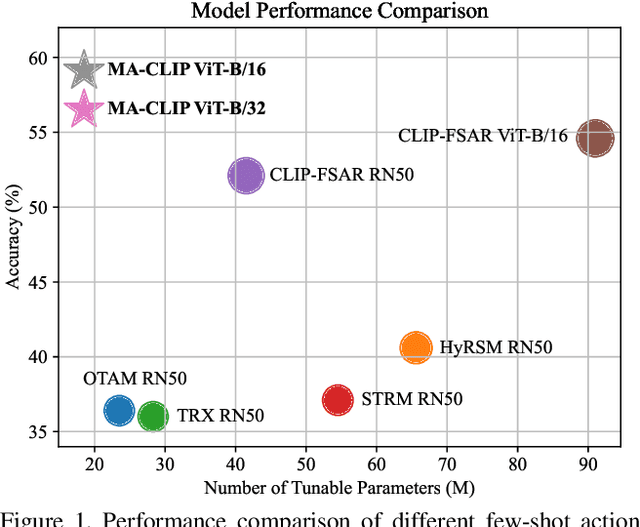
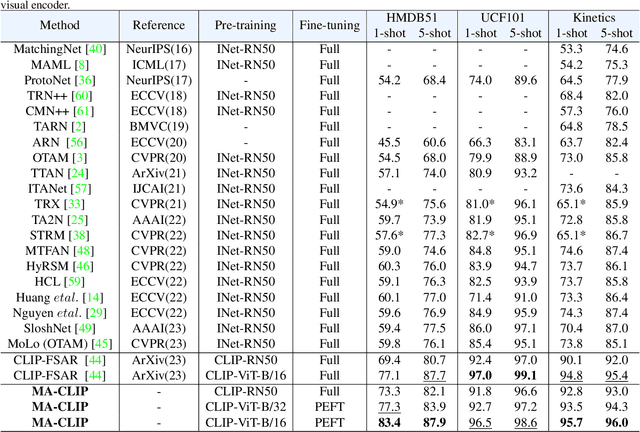
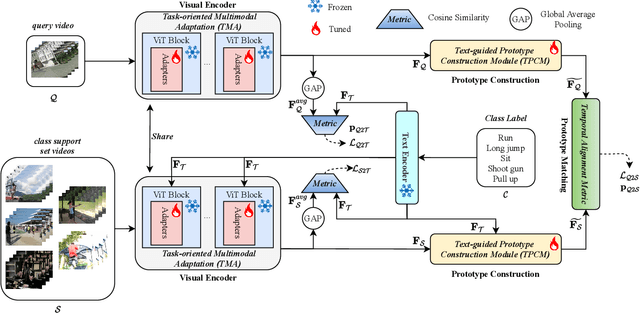
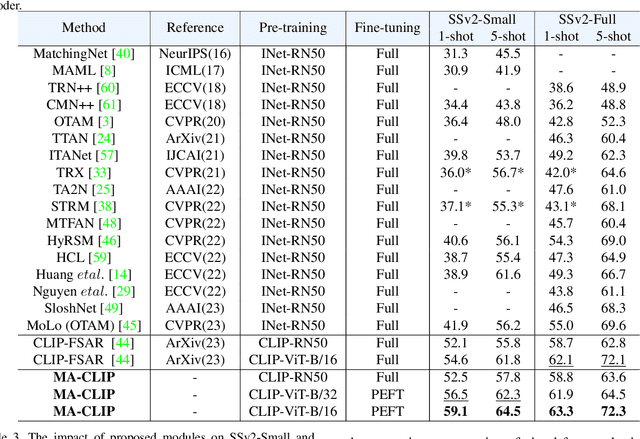
Applying large-scale pre-trained visual models like CLIP to few-shot action recognition tasks can benefit performance and efficiency. Utilizing the "pre-training, fine-tuning" paradigm makes it possible to avoid training a network from scratch, which can be time-consuming and resource-intensive. However, this method has two drawbacks. First, limited labeled samples for few-shot action recognition necessitate minimizing the number of tunable parameters to mitigate over-fitting, also leading to inadequate fine-tuning that increases resource consumption and may disrupt the generalized representation of models. Second, the video's extra-temporal dimension challenges few-shot recognition's effective temporal modeling, while pre-trained visual models are usually image models. This paper proposes a novel method called Multimodal Adaptation of CLIP (MA-CLIP) to address these issues. It adapts CLIP for few-shot action recognition by adding lightweight adapters, which can minimize the number of learnable parameters and enable the model to transfer across different tasks quickly. The adapters we design can combine information from video-text multimodal sources for task-oriented spatiotemporal modeling, which is fast, efficient, and has low training costs. Additionally, based on the attention mechanism, we design a text-guided prototype construction module that can fully utilize video-text information to enhance the representation of video prototypes. Our MA-CLIP is plug-and-play, which can be used in any different few-shot action recognition temporal alignment metric.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Aug 03, 2023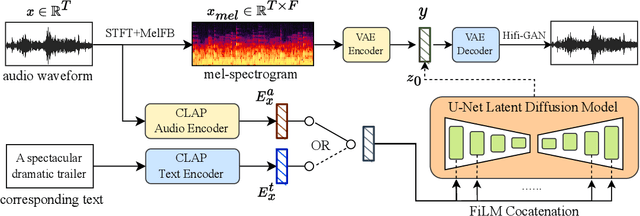
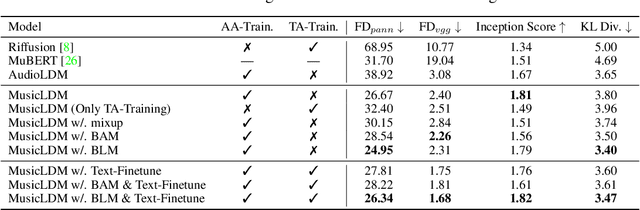
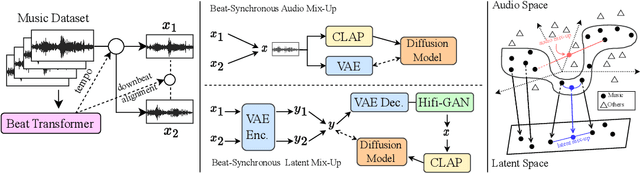
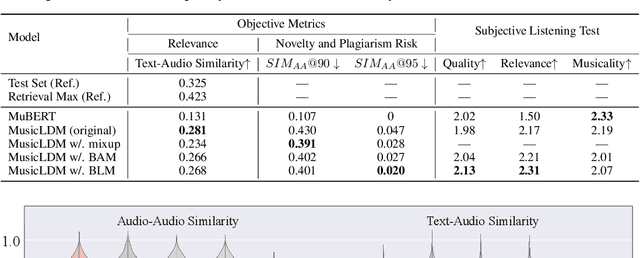
Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.
Enhancing Visibility in Nighttime Haze Images Using Guided APSF and Gradient Adaptive Convolution
Aug 03, 2023
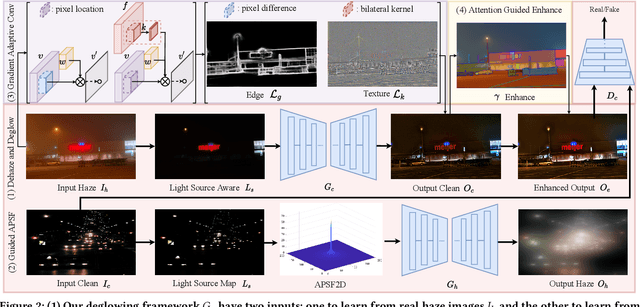

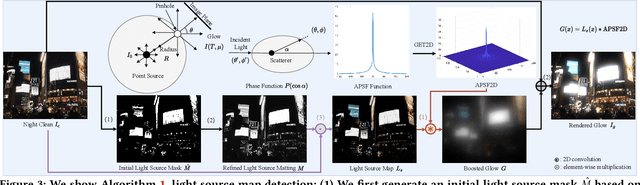
Visibility in hazy nighttime scenes is frequently reduced by multiple factors, including low light, intense glow, light scattering, and the presence of multicolored light sources. Existing nighttime dehazing methods often struggle with handling glow or low-light conditions, resulting in either excessively dark visuals or unsuppressed glow outputs. In this paper, we enhance the visibility from a single nighttime haze image by suppressing glow and enhancing low-light regions. To handle glow effects, our framework learns from the rendered glow pairs. Specifically, a light source aware network is proposed to detect light sources of night images, followed by the APSF (Angular Point Spread Function)-guided glow rendering. Our framework is then trained on the rendered images, resulting in glow suppression. Moreover, we utilize gradient-adaptive convolution, to capture edges and textures in hazy scenes. By leveraging extracted edges and textures, we enhance the contrast of the scene without losing important structural details. To boost low-light intensity, our network learns an attention map, then adjusted by gamma correction. This attention has high values on low-light regions and low values on haze and glow regions. Extensive evaluation on real nighttime haze images, demonstrates the effectiveness of our method. Our experiments demonstrate that our method achieves a PSNR of 30.72dB, outperforming state-of-the-art methods by 14$\%$ on GTA5 nighttime haze dataset. Our data and code is available at: \url{https://github.com/jinyeying/nighttime_dehaze}.