 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UWAT-GAN: Fundus Fluorescein Angiography Synthesis via Ultra-wide-angle Transformation Multi-scale GAN
Jul 21, 2023
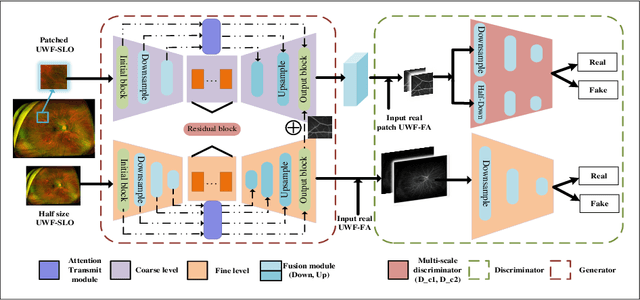
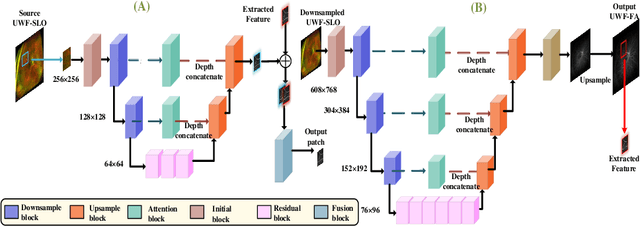
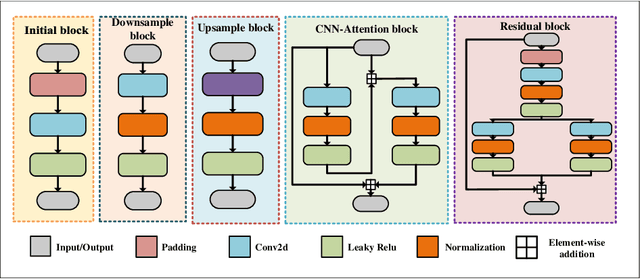
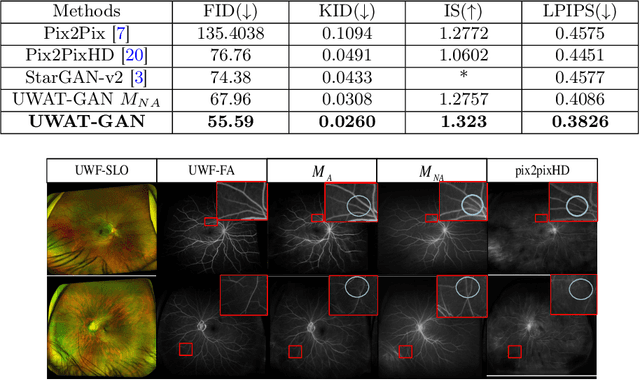
Fundus photography is an essential examination for clinical and differential diagnosis of fundus diseases. Recently, Ultra-Wide-angle Fundus (UWF) techniques, UWF Fluorescein Angiography (UWF-FA) and UWF Scanning Laser Ophthalmoscopy (UWF-SLO) have been gradually put into use. However, Fluorescein Angiography (FA) and UWF-FA require injecting sodium fluorescein which may have detrimental influences. To avoid negative impacts, cross-modality medical image generation algorithms have been proposed. Nevertheless, current methods in fundus imaging could not produce high-resolution images and are unable to capture tiny vascular lesion areas. This paper proposes a novel conditional generative adversarial network (UWAT-GAN) to synthesize UWF-FA from UWF-SLO. Using multi-scale generators and a fusion module patch to better extract global and local information, our model can generate high-resolution images. Moreover, an attention transmit module is proposed to help the decoder learn effectively. Besides, a supervised approach is used to train the network using multiple new weighted losses on different scales of data. Experiments on an in-house UWF image dataset demonstrate the superiority of the UWAT-GAN over the state-of-the-art methods. The source code is available at: https://github.com/Tinysqua/UWAT-GAN.
Character Time-series Matching For Robust License Plate Recognition
Jul 21, 2023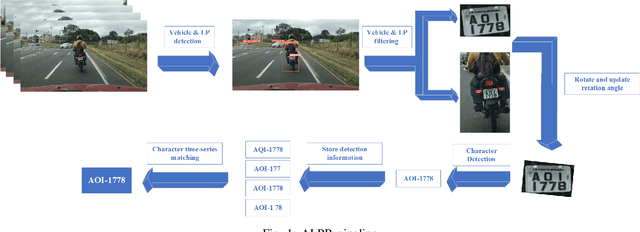
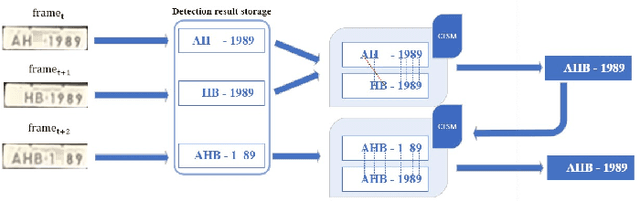
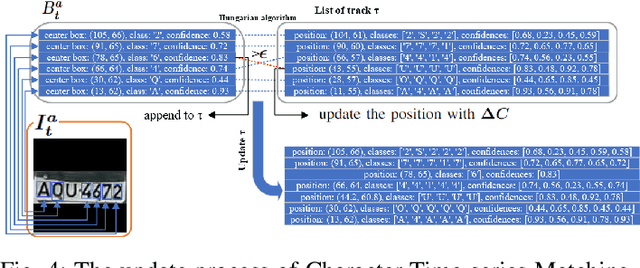

Automatic License Plate Recognition (ALPR) is becoming a popular study area and is applied in many fields such as transportation or smart city. However, there are still several limitations when applying many current methods to practical problems due to the variation in real-world situations such as light changes, unclear License Plate (LP) characters, and image quality. Almost recent ALPR algorithms process on a single frame, which reduces accuracy in case of worse image quality. This paper presents methods to improve license plate recognition accuracy by tracking the license plate in multiple frames. First, the Adaptive License Plate Rotation algorithm is applied to correctly align the detected license plate. Second, we propose a method called Character Time-series Matching to recognize license plate characters from many consequence frames. The proposed method archives high performance in the UFPR-ALPR dataset which is \boldmath$96.7\%$ accuracy in real-time on RTX A5000 GPU card. We also deploy the algorithm for the Vietnamese ALPR system. The accuracy for license plate detection and character recognition are 0.881 and 0.979 $mAP^{test}$@.5 respectively. The source code is available at https://github.com/chequanghuy/Character-Time-series-Matching.git
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
Jul 21, 2023
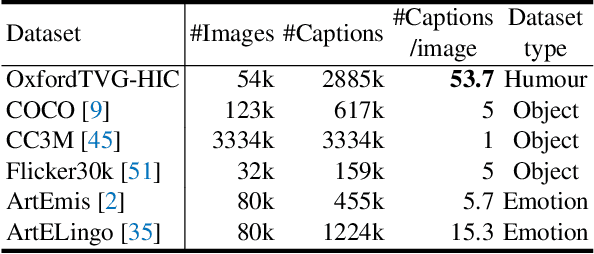
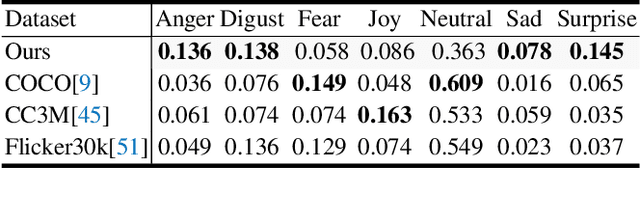
This paper presents OxfordTVG-HIC (Humorous Image Captions), a large-scale dataset for humour generation and understanding. Humour is an abstract, subjective, and context-dependent cognitive construct involving several cognitive factors, making it a challenging task to generate and interpret. Hence, humour generation and understanding can serve as a new task for evaluating the ability of deep-learning methods to process abstract and subjective information. Due to the scarcity of data, humour-related generation tasks such as captioning remain under-explored. To address this gap, OxfordTVG-HIC offers approximately 2.9M image-text pairs with humour scores to train a generalizable humour captioning model. Contrary to existing captioning datasets, OxfordTVG-HIC features a wide range of emotional and semantic diversity resulting in out-of-context examples that are particularly conducive to generating humour. Moreover, OxfordTVG-HIC is curated devoid of offensive content. We also show how OxfordTVG-HIC can be leveraged for evaluating the humour of a generated text. Through explainability analysis of the trained models, we identify the visual and linguistic cues influential for evoking humour prediction (and generation). We observe qualitatively that these cues are aligned with the benign violation theory of humour in cognitive psychology.
Ariadne's Thread:Using Text Prompts to Improve Segmentation of Infected Areas from Chest X-ray images
Jul 08, 2023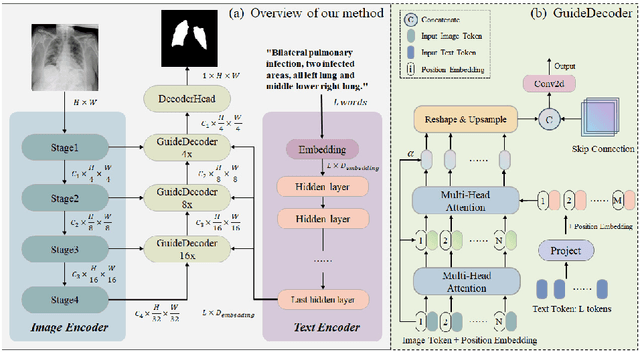
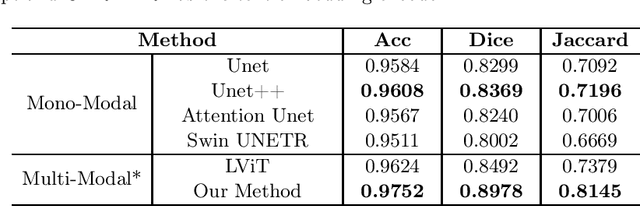

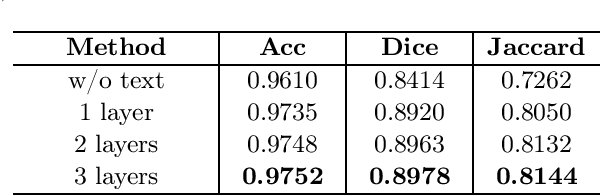
Segmentation of the infected areas of the lung is essential for quantifying the severity of lung disease like pulmonary infections. Existing medical image segmentation methods are almost uni-modal methods based on image. However, these image-only methods tend to produce inaccurate results unless trained with large amounts of annotated data. To overcome this challenge, we propose a language-driven segmentation method that uses text prompt to improve to the segmentation result. Experiments on the QaTa-COV19 dataset indicate that our method improves the Dice score by 6.09% at least compared to the uni-modal methods. Besides, our extended study reveals the flexibility of multi-modal methods in terms of the information granularity of text and demonstrates that multi-modal methods have a significant advantage over image-only methods in terms of the size of training data required.
Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
Jul 08, 2023We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by the unimodal prototypical networks for few-shot learning, we introduce PROTO-CLIP that utilizes image prototypes and text prototypes for few-shot learning. Specifically, PROTO-CLIP adapts the image encoder and text encoder in CLIP in a joint fashion using few-shot examples. The two encoders are used to compute prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of corresponding classes. Such a proposed alignment is beneficial for few-shot classification due to the contributions from both types of prototypes. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning as well as in the real world for robot perception.
Bidirectional Copy-Paste for Semi-Supervised Medical Image Segmentation
May 01, 2023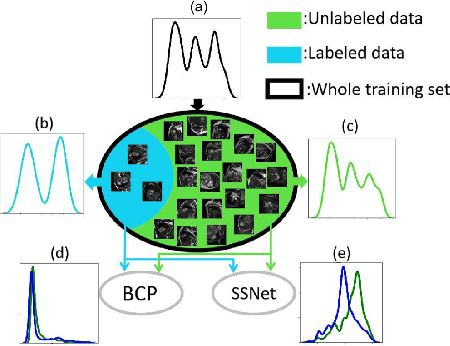
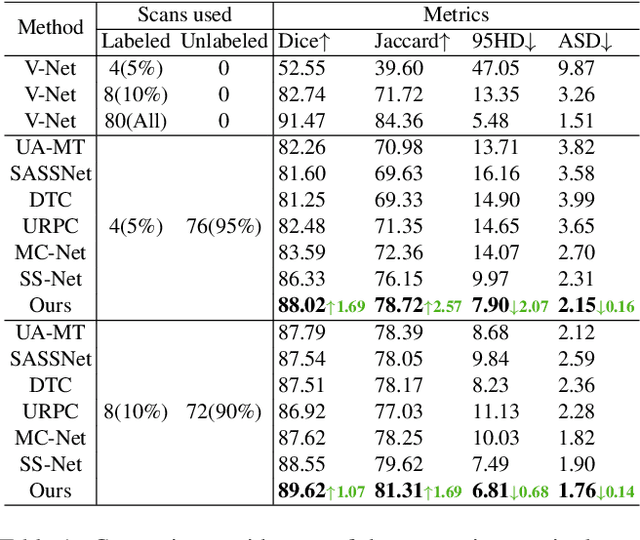
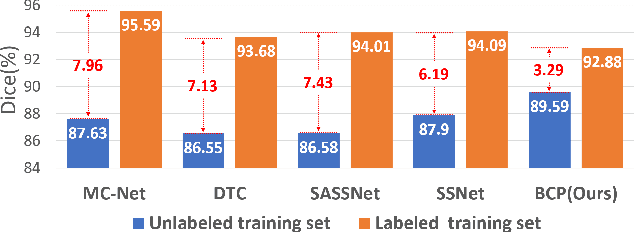
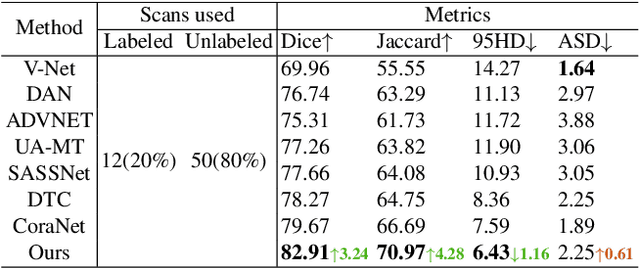
In semi-supervised medical image segmentation, there exist empirical mismatch problems between labeled and unlabeled data distribution. The knowledge learned from the labeled data may be largely discarded if treating labeled and unlabeled data separately or in an inconsistent manner. We propose a straightforward method for alleviating the problem - copy-pasting labeled and unlabeled data bidirectionally, in a simple Mean Teacher architecture. The method encourages unlabeled data to learn comprehensive common semantics from the labeled data in both inward and outward directions. More importantly, the consistent learning procedure for labeled and unlabeled data can largely reduce the empirical distribution gap. In detail, we copy-paste a random crop from a labeled image (foreground) onto an unlabeled image (background) and an unlabeled image (foreground) onto a labeled image (background), respectively. The two mixed images are fed into a Student network and supervised by the mixed supervisory signals of pseudo-labels and ground-truth. We reveal that the simple mechanism of copy-pasting bidirectionally between labeled and unlabeled data is good enough and the experiments show solid gains (e.g., over 21% Dice improvement on ACDC dataset with 5% labeled data) compared with other state-of-the-arts on various semi-supervised medical image segmentation datasets. Code is available at https://github.com/DeepMed-Lab-ECNU/BCP}.
SwinIA: Self-Supervised Blind-Spot Image Denoising with Zero Convolutions
May 09, 2023
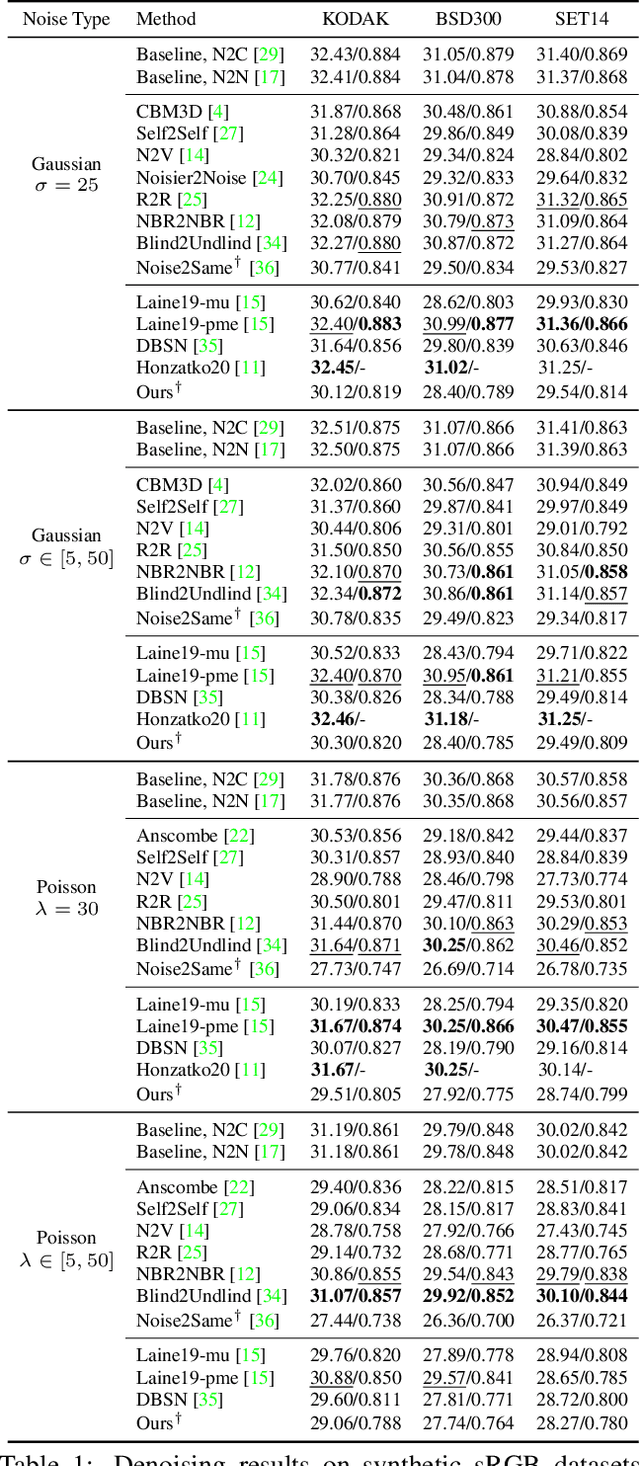
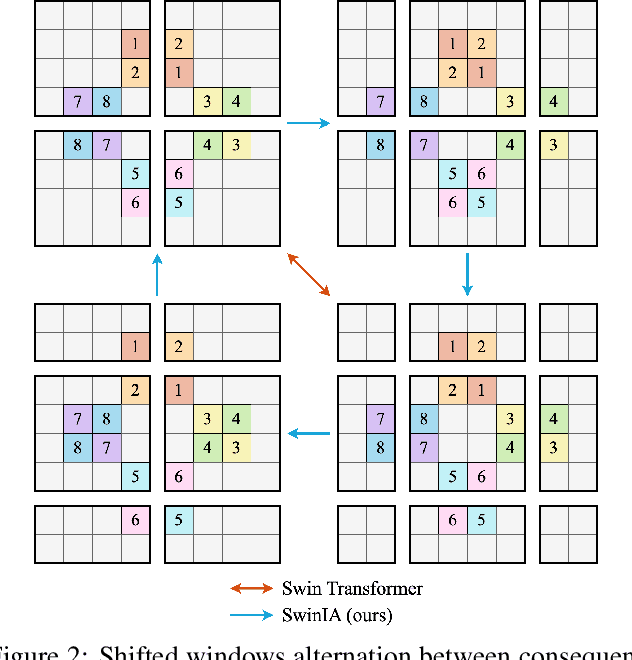
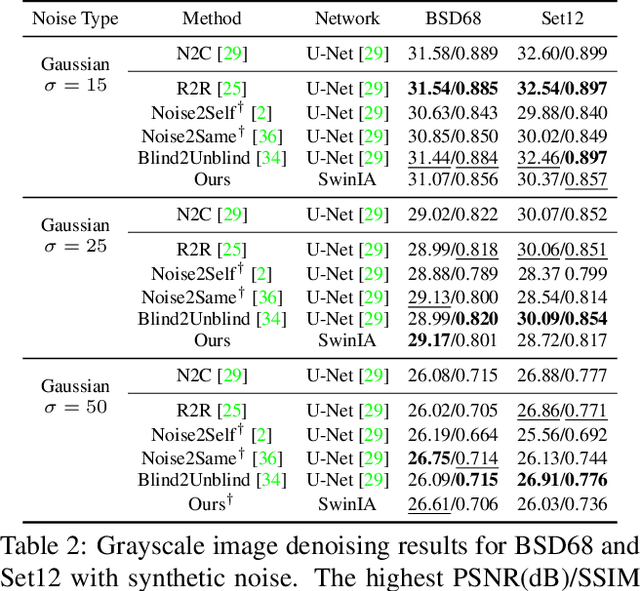
The essence of self-supervised image denoising is to restore the signal from the noisy image alone. State-of-the-art solutions for this task rely on the idea of masking pixels and training a fully-convolutional neural network to impute them. This most often requires multiple forward passes, information about the noise model, and intricate regularization functions. In this paper, we propose a Swin Transformer-based Image Autoencoder (SwinIA), the first convolution-free architecture for self-supervised denoising. It can be trained end-to-end with a simple mean squared error loss without masking and does not require any prior knowledge about clean data or noise distribution. Despite its simplicity, SwinIA establishes state-of-the-art on several common benchmarks.
PLIP: Language-Image Pre-training for Person Representation Learning
May 15, 2023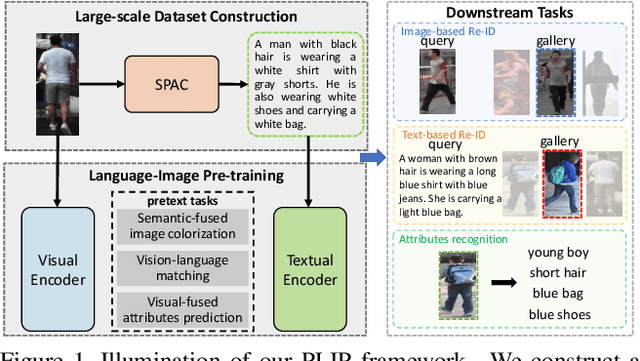
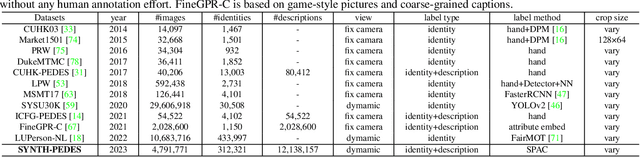
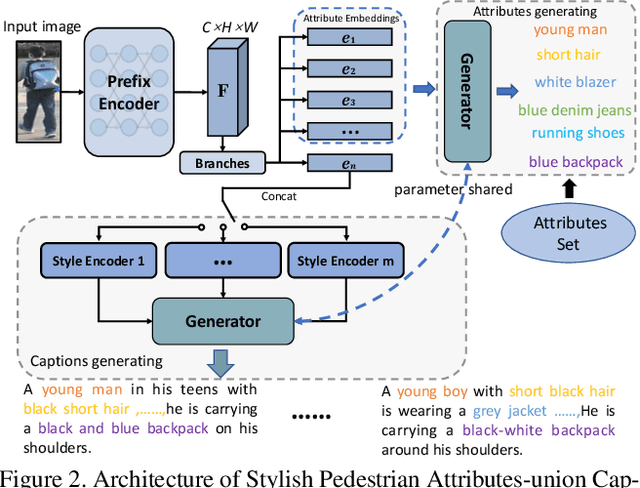
Pre-training has emerged as an effective technique for learning powerful person representations. Most existing methods have shown that pre-training on pure-vision large-scale datasets like ImageNet and LUPerson has achieved remarkable performance. However, solely relying on visual information, the absence of robust explicit indicators poses a challenge for these methods to learn discriminative person representations. Drawing inspiration from the intrinsic fine-grained attribute indicators of person descriptions, we explore introducing the language modality into person representation learning. To this end, we propose a novel language-image pre-training framework for person representation learning, termed PLIP. To explicitly build fine-grained cross-modal associations, we specifically design three pretext tasks, \ie semantic-fused image colorization, visual-fused attributes prediction, and vision-language matching. In addition, due to the lack of an appropriate dataset, we present a large-scale person dataset named SYNTH-PEDES, where the Stylish Pedestrian Attributes-union Captioning method is proposed to synthesize diverse textual descriptions. We pre-train PLIP on SYNTH-PEDES and evaluate our model by spanning downstream tasks such as text-based Re-ID, image-based Re-ID, and person attribute recognition. Extensive experiments demonstrate that our model not only significantly improves existing methods on all these tasks, but also shows great ability in the few-shot and domain generalization settings. The code, dataset and weights will be released at~\url{https://github.com/Zplusdragon/PLIP}
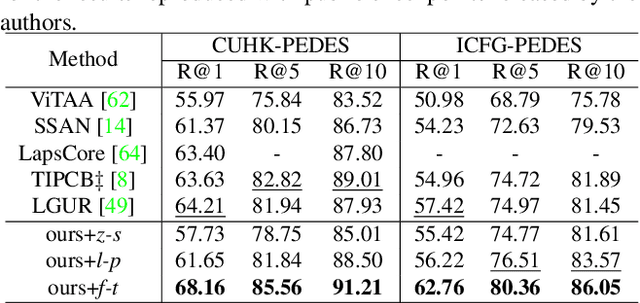
Iterative Robust Visual Grounding with Masked Reference based Centerpoint Supervision
Jul 23, 2023
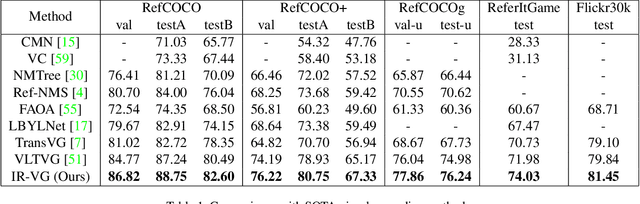
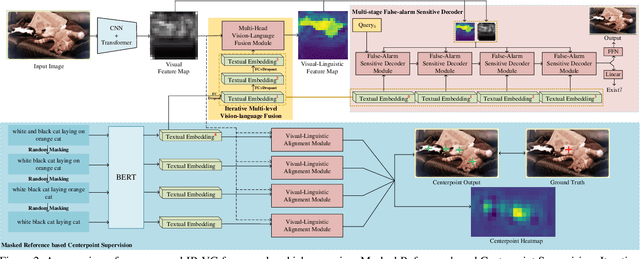
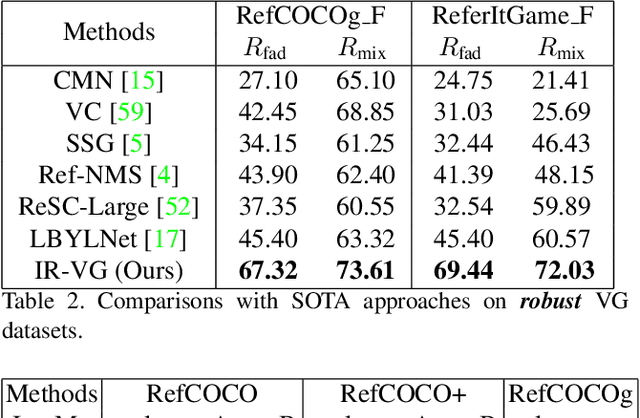
Visual Grounding (VG) aims at localizing target objects from an image based on given expressions and has made significant progress with the development of detection and vision transformer. However, existing VG methods tend to generate false-alarm objects when presented with inaccurate or irrelevant descriptions, which commonly occur in practical applications. Moreover, existing methods fail to capture fine-grained features, accurate localization, and sufficient context comprehension from the whole image and textual descriptions. To address both issues, we propose an Iterative Robust Visual Grounding (IR-VG) framework with Masked Reference based Centerpoint Supervision (MRCS). The framework introduces iterative multi-level vision-language fusion (IMVF) for better alignment. We use MRCS to ahieve more accurate localization with point-wised feature supervision. Then, to improve the robustness of VG, we also present a multi-stage false-alarm sensitive decoder (MFSD) to prevent the generation of false-alarm objects when presented with inaccurate expressions. The proposed framework is evaluated on five regular VG datasets and two newly constructed robust VG datasets. Extensive experiments demonstrate that IR-VG achieves new state-of-the-art (SOTA) results, with improvements of 25\% and 10\% compared to existing SOTA approaches on the two newly proposed robust VG datasets. Moreover, the proposed framework is also verified effective on five regular VG datasets. Codes and models will be publicly at https://github.com/cv516Buaa/IR-VG.
Attentive Continuous Generative Self-training for Unsupervised Domain Adaptive Medical Image Translation
May 23, 2023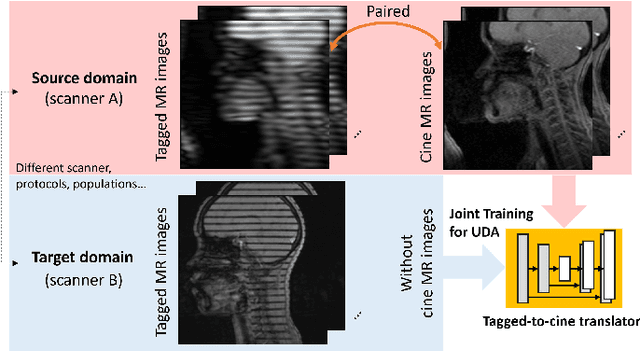

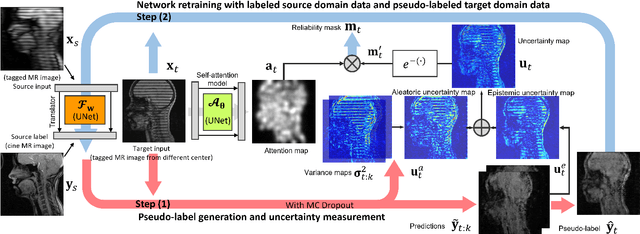
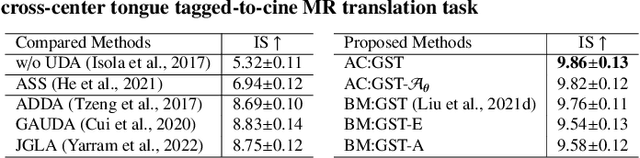
Self-training is an important class of unsupervised domain adaptation (UDA) approaches that are used to mitigate the problem of domain shift, when applying knowledge learned from a labeled source domain to unlabeled and heterogeneous target domains. While self-training-based UDA has shown considerable promise on discriminative tasks, including classification and segmentation, through reliable pseudo-label filtering based on the maximum softmax probability, there is a paucity of prior work on self-training-based UDA for generative tasks, including image modality translation. To fill this gap, in this work, we seek to develop a generative self-training (GST) framework for domain adaptive image translation with continuous value prediction and regression objectives. Specifically, we quantify both aleatoric and epistemic uncertainties within our GST using variational Bayes learning to measure the reliability of synthesized data. We also introduce a self-attention scheme that de-emphasizes the background region to prevent it from dominating the training process. The adaptation is then carried out by an alternating optimization scheme with target domain supervision that focuses attention on the regions with reliable pseudo-labels. We evaluated our framework on two cross-scanner/center, inter-subject translation tasks, including tagged-to-cine magnetic resonance (MR) image translation and T1-weighted MR-to-fractional anisotropy translation. Extensive validations with unpaired target domain data showed that our GST yielded superior synthesis performance in comparison to adversarial training UDA methods.