 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Mixed Transformer for Single Image Super-Resolution
May 22, 2023
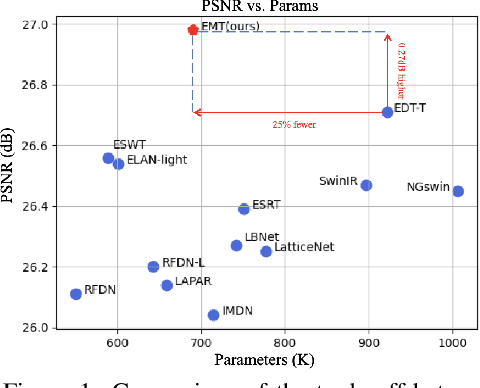
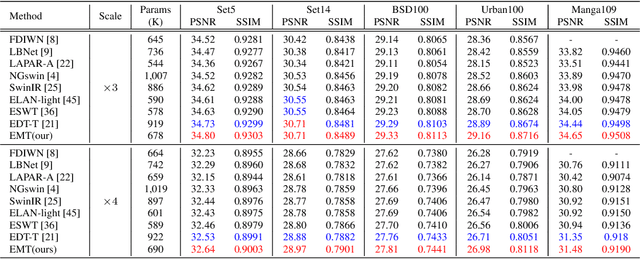
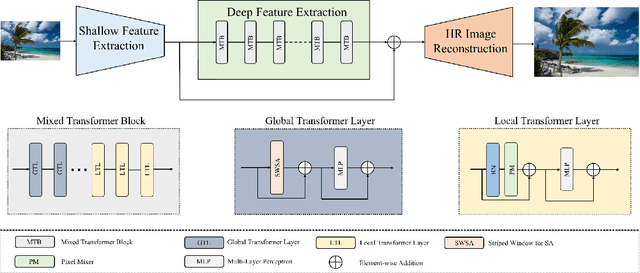
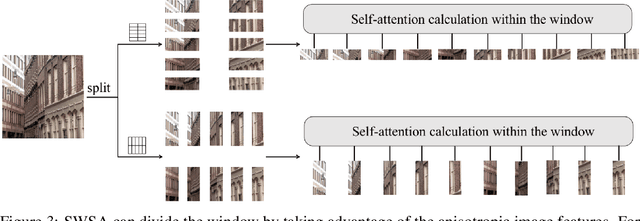
Recently, Transformer-based methods have achieved impressive results in single image super-resolution (SISR). However, the lack of locality mechanism and high complexity limit their application in the field of super-resolution (SR). To solve these problems, we propose a new method, Efficient Mixed Transformer (EMT) in this study. Specifically, we propose the Mixed Transformer Block (MTB), consisting of multiple consecutive transformer layers, in some of which the Pixel Mixer (PM) is used to replace the Self-Attention (SA). PM can enhance the local knowledge aggregation with pixel shifting operations. At the same time, no additional complexity is introduced as PM has no parameters and floating-point operations. Moreover, we employ striped window for SA (SWSA) to gain an efficient global dependency modelling by utilizing image anisotropy. Experimental results show that EMT outperforms the existing methods on benchmark dataset and achieved state-of-the-art performance. The Code is available at https://github. com/Fried-Rice-Lab/EMT.git.
Pelta: Shielding Transformers to Mitigate Evasion Attacks in Federated Learning
Aug 08, 2023The main premise of federated learning is that machine learning model updates are computed locally, in particular to preserve user data privacy, as those never leave the perimeter of their device. This mechanism supposes the general model, once aggregated, to be broadcast to collaborating and non malicious nodes. However, without proper defenses, compromised clients can easily probe the model inside their local memory in search of adversarial examples. For instance, considering image-based applications, adversarial examples consist of imperceptibly perturbed images (to the human eye) misclassified by the local model, which can be later presented to a victim node's counterpart model to replicate the attack. To mitigate such malicious probing, we introduce Pelta, a novel shielding mechanism leveraging trusted hardware. By harnessing the capabilities of Trusted Execution Environments (TEEs), Pelta masks part of the back-propagation chain rule, otherwise typically exploited by attackers for the design of malicious samples. We evaluate Pelta on a state of the art ensemble model and demonstrate its effectiveness against the Self Attention Gradient adversarial Attack.
A Lightweight and Accurate Face Detection Algorithm Based on Retinaface
Aug 08, 2023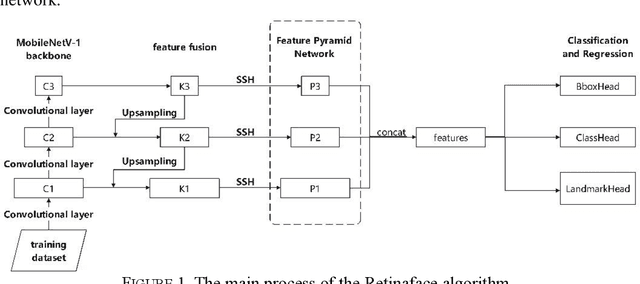
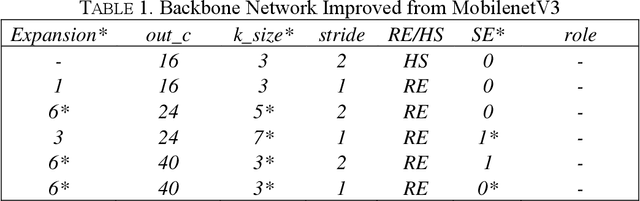
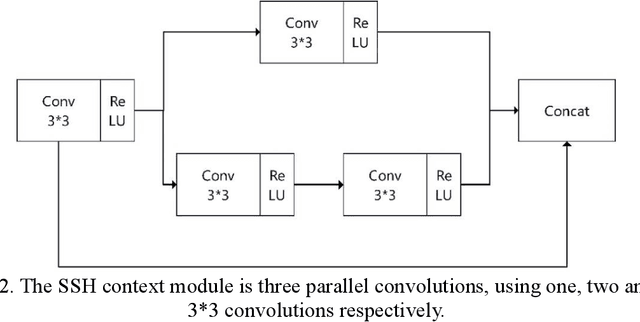
In this paper, we propose a lightweight and accurate face detection algorithm LAFD (Light and accurate face detection) based on Retinaface. Backbone network in the algorithm is a modified MobileNetV3 network which adjusts the size of the convolution kernel, the channel expansion multiplier of the inverted residuals block and the use of the SE attention mechanism. Deformable convolution network(DCN) is introduced in the context module and the algorithm uses focal loss function instead of cross-entropy loss function as the classification loss function of the model. The test results on the WIDERFACE dataset indicate that the average accuracy of LAFD is 94.1%, 92.2% and 82.1% for the "easy", "medium" and "hard" validation subsets respectively with an improvement of 3.4%, 4.0% and 8.3% compared to Retinaface and 3.1%, 4.1% and 4.1% higher than the well-performing lightweight model, LFFD. If the input image is pre-processed and scaled to 1560px in length or 1200px in width, the model achieves an average accuracy of 86.2% on the 'hard' validation subset. The model is lightweight, with a size of only 10.2MB.
Towards Automatic Scoring of Spinal X-ray for Ankylosing Spondylitis
Aug 08, 2023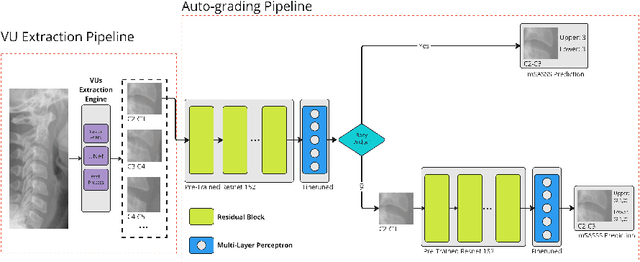
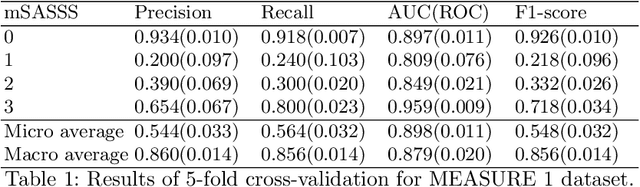
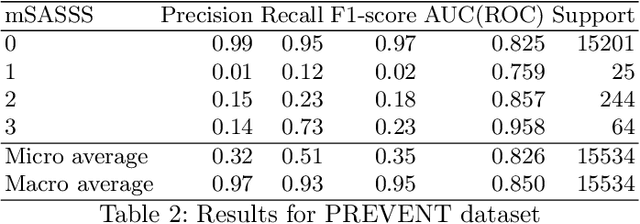
Manually grading structural changes with the modified Stoke Ankylosing Spondylitis Spinal Score (mSASSS) on spinal X-ray imaging is costly and time-consuming due to bone shape complexity and image quality variations. In this study, we address this challenge by prototyping a 2-step auto-grading pipeline, called VertXGradeNet, to automatically predict mSASSS scores for the cervical and lumbar vertebral units (VUs) in X-ray spinal imaging. The VertXGradeNet utilizes VUs generated by our previously developed VU extraction pipeline (VertXNet) as input and predicts mSASSS based on those VUs. VertXGradeNet was evaluated on an in-house dataset of lateral cervical and lumbar X-ray images for axial spondylarthritis patients. Our results show that VertXGradeNet can predict the mSASSS score for each VU when the data is limited in quantity and imbalanced. Overall, it can achieve a balanced accuracy of 0.56 and 0.51 for 4 different mSASSS scores (i.e., a score of 0, 1, 2, 3) on two test datasets. The accuracy of the presented method shows the potential to streamline the spinal radiograph readings and therefore reduce the cost of future clinical trials.
Image Quality Is Not All You Want: Task-Driven Lens Design for Image Classification
May 26, 2023
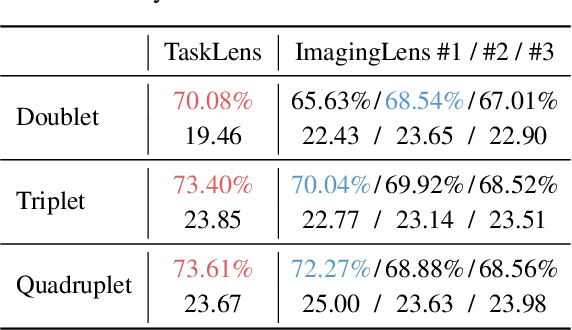
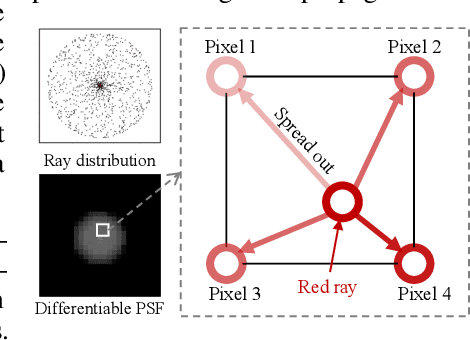
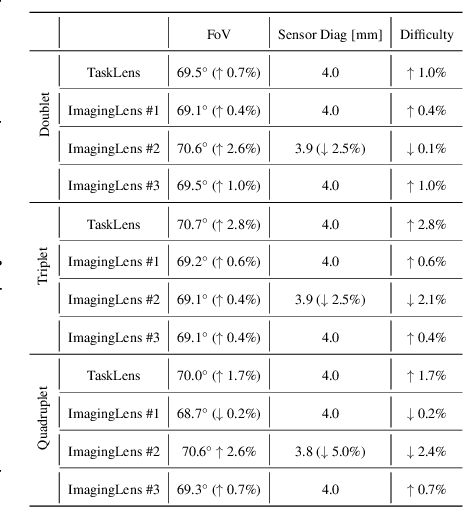
In computer vision, it has long been taken for granted that high-quality images obtained through well-designed camera lenses would lead to superior results. However, we find that this common perception is not a "one-size-fits-all" solution for diverse computer vision tasks. We demonstrate that task-driven and deep-learned simple optics can actually deliver better visual task performance. The Task-Driven lens design approach, which relies solely on a well-trained network model for supervision, is proven to be capable of designing lenses from scratch. Experimental results demonstrate the designed image classification lens (``TaskLens'') exhibits higher accuracy compared to conventional imaging-driven lenses, even with fewer lens elements. Furthermore, we show that our TaskLens is compatible with various network models while maintaining enhanced classification accuracy. We propose that TaskLens holds significant potential, particularly when physical dimensions and cost are severely constrained.
An Examination of the Robustness of Reference-Free Image Captioning Evaluation Metrics
May 24, 2023
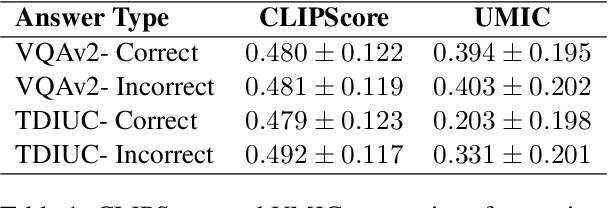
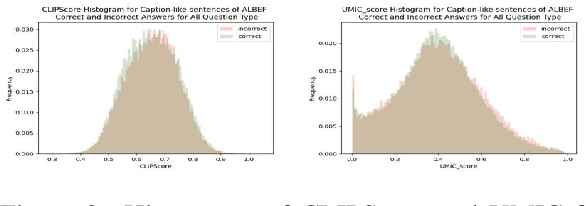

Recently, reference-free metrics such as CLIPScore (Hessel et al., 2021) and UMIC (Lee et al., 2021) have been proposed for automatic evaluation of image captions, demonstrating a high correlation with human judgment. In this work, our focus lies in evaluating the robustness of these metrics in scenarios that require distinguishing between two captions with high lexical overlap but very different meanings. Our findings reveal that despite their high correlation with human judgment, both CLIPScore and UMIC struggle to identify fine-grained errors in captions. However, when comparing different types of fine-grained errors, both metrics exhibit limited sensitivity to implausibility of captions and strong sensitivity to lack of sufficient visual grounding. Probing further into the visual grounding aspect, we found that both CLIPScore and UMIC are impacted by the size of image-relevant objects mentioned in the caption, and that CLIPScore is also sensitive to the number of mentions of image-relevant objects in the caption. In terms of linguistic aspects of a caption, we found that both metrics lack the ability to comprehend negation, UMIC is sensitive to caption lengths, and CLIPScore is insensitive to the structure of the sentence. We hope our findings will serve as a valuable guide towards improving reference-free evaluation in image captioning.
Do Diffusion Models Suffer Error Propagation? Theoretical Analysis and Consistency Regularization
Aug 09, 2023While diffusion models have achieved promising performances in data synthesis, they might suffer error propagation because of their cascade structure, where the distributional mismatch spreads and magnifies through the chain of denoising modules. However, a strict analysis is expected since many sequential models such as Conditional Random Field (CRF) are free from error propagation. In this paper, we empirically and theoretically verify that diffusion models are indeed affected by error propagation and we then propose a regularization to address this problem. Our theoretical analysis reveals that the question can be reduced to whether every denoising module of the diffusion model is fault-tolerant. We derive insightful transition equations, indicating that the module can't recover from input errors and even propagates additional errors to the next module. Our analysis directly leads to a consistency regularization scheme for diffusion models, which explicitly reduces the distribution gap between forward and backward processes. We further introduce a bootstrapping algorithm to reduce the computation cost of the regularizer. Our experimental results on multiple image datasets show that our regularization effectively handles error propagation and significantly improves the performance of vanilla diffusion models.
DELFlow: Dense Efficient Learning of Scene Flow for Large-Scale Point Clouds
Aug 09, 2023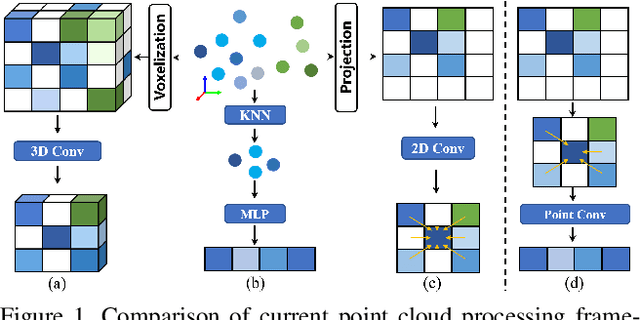
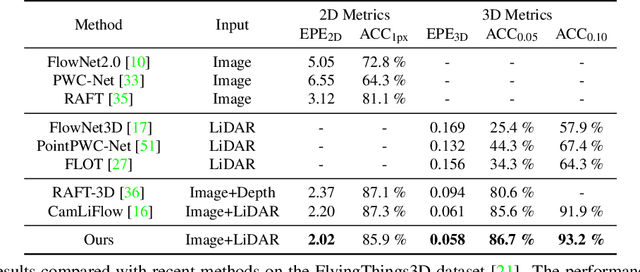
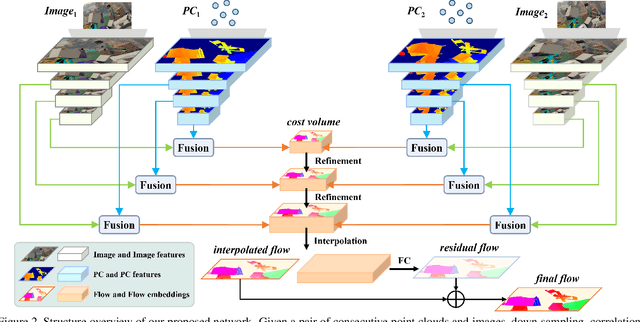
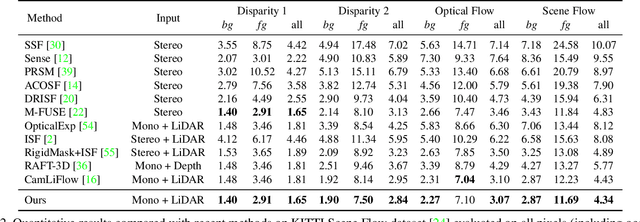
Point clouds are naturally sparse, while image pixels are dense. The inconsistency limits feature fusion from both modalities for point-wise scene flow estimation. Previous methods rarely predict scene flow from the entire point clouds of the scene with one-time inference due to the memory inefficiency and heavy overhead from distance calculation and sorting involved in commonly used farthest point sampling, KNN, and ball query algorithms for local feature aggregation. To mitigate these issues in scene flow learning, we regularize raw points to a dense format by storing 3D coordinates in 2D grids. Unlike the sampling operation commonly used in existing works, the dense 2D representation 1) preserves most points in the given scene, 2) brings in a significant boost of efficiency, and 3) eliminates the density gap between points and pixels, allowing us to perform effective feature fusion. We also present a novel warping projection technique to alleviate the information loss problem resulting from the fact that multiple points could be mapped into one grid during projection when computing cost volume. Sufficient experiments demonstrate the efficiency and effectiveness of our method, outperforming the prior-arts on the FlyingThings3D and KITTI dataset.
SelectNAdapt: Support Set Selection for Few-Shot Domain Adaptation
Aug 09, 2023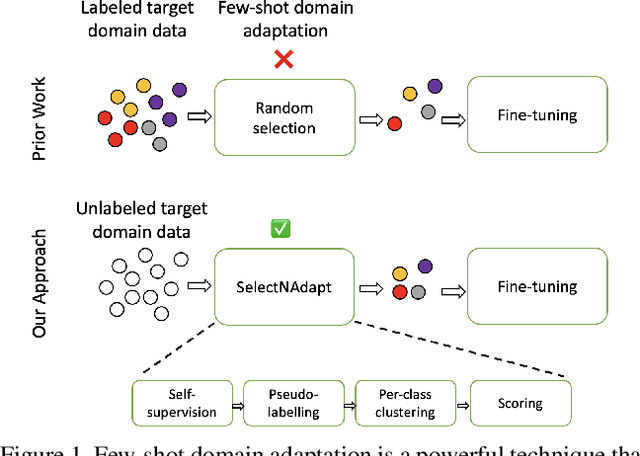

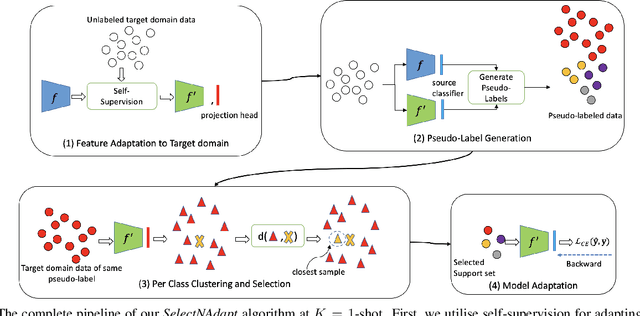
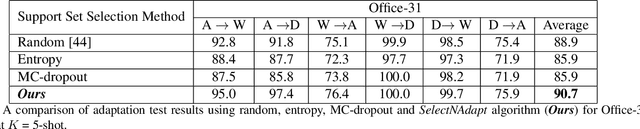
Generalisation of deep neural networks becomes vulnerable when distribution shifts are encountered between train (source) and test (target) domain data. Few-shot domain adaptation mitigates this issue by adapting deep neural networks pre-trained on the source domain to the target domain using a randomly selected and annotated support set from the target domain. This paper argues that randomly selecting the support set can be further improved for effectively adapting the pre-trained source models to the target domain. Alternatively, we propose SelectNAdapt, an algorithm to curate the selection of the target domain samples, which are then annotated and included in the support set. In particular, for the K-shot adaptation problem, we first leverage self-supervision to learn features of the target domain data. Then, we propose a per-class clustering scheme of the learned target domain features and select K representative target samples using a distance-based scoring function. Finally, we bring our selection setup towards a practical ground by relying on pseudo-labels for clustering semantically similar target domain samples. Our experiments show promising results on three few-shot domain adaptation benchmarks for image recognition compared to related approaches and the standard random selection.
LoLep: Single-View View Synthesis with Locally-Learned Planes and Self-Attention Occlusion Inference
Aug 09, 2023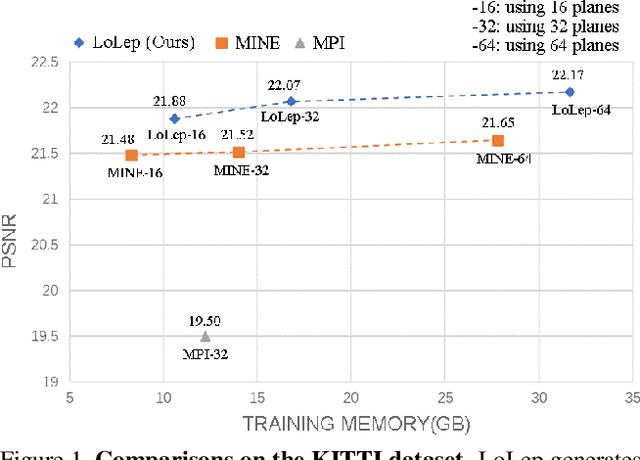

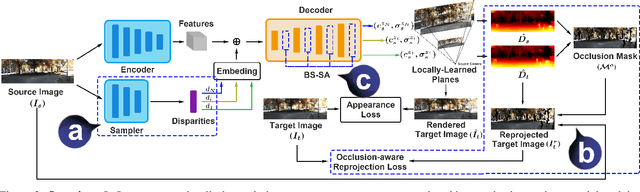
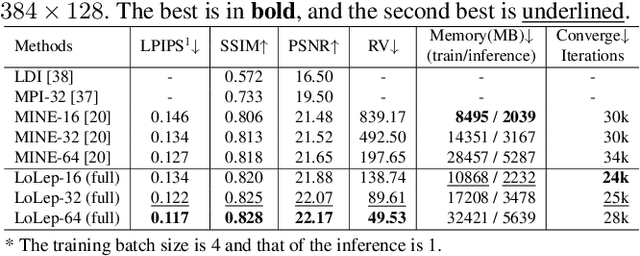
We propose a novel method, LoLep, which regresses Locally-Learned planes from a single RGB image to represent scenes accurately, thus generating better novel views. Without the depth information, regressing appropriate plane locations is a challenging problem. To solve this issue, we pre-partition the disparity space into bins and design a disparity sampler to regress local offsets for multiple planes in each bin. However, only using such a sampler makes the network not convergent; we further propose two optimizing strategies that combine with different disparity distributions of datasets and propose an occlusion-aware reprojection loss as a simple yet effective geometric supervision technique. We also introduce a self-attention mechanism to improve occlusion inference and present a Block-Sampling Self-Attention (BS-SA) module to address the problem of applying self-attention to large feature maps. We demonstrate the effectiveness of our approach and generate state-of-the-art results on different datasets. Compared to MINE, our approach has an LPIPS reduction of 4.8%-9.0% and an RV reduction of 73.9%-83.5%. We also evaluate the performance on real-world images and demonstrate the benefits.