 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Point Anywhere: Directed Object Estimation from Omnidirectional Images
Aug 02, 2023
One of the intuitive instruction methods in robot navigation is a pointing gesture. In this study, we propose a method using an omnidirectional camera to eliminate the user/object position constraint and the left/right constraint of the pointing arm. Although the accuracy of skeleton and object detection is low due to the high distortion of equirectangular images, the proposed method enables highly accurate estimation by repeatedly extracting regions of interest from the equirectangular image and projecting them onto perspective images. Furthermore, we found that training the likelihood of the target object in machine learning further improves the estimation accuracy.
Compositional Feature Augmentation for Unbiased Scene Graph Generation
Aug 13, 2023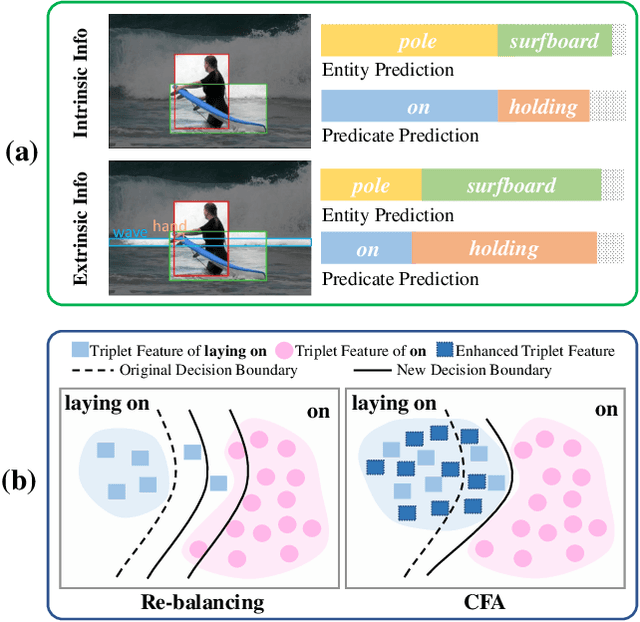
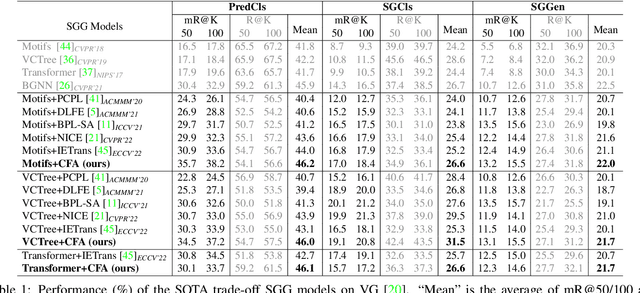
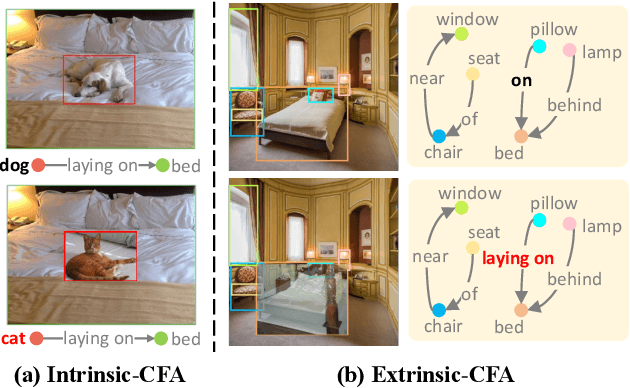
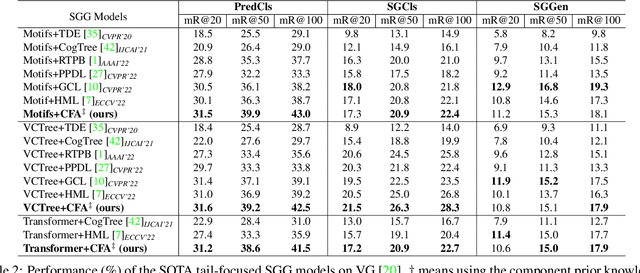
Scene Graph Generation (SGG) aims to detect all the visual relation triplets <sub, pred, obj> in a given image. With the emergence of various advanced techniques for better utilizing both the intrinsic and extrinsic information in each relation triplet, SGG has achieved great progress over the recent years. However, due to the ubiquitous long-tailed predicate distributions, today's SGG models are still easily biased to the head predicates. Currently, the most prevalent debiasing solutions for SGG are re-balancing methods, e.g., changing the distributions of original training samples. In this paper, we argue that all existing re-balancing strategies fail to increase the diversity of the relation triplet features of each predicate, which is critical for robust SGG. To this end, we propose a novel Compositional Feature Augmentation (CFA) strategy, which is the first unbiased SGG work to mitigate the bias issue from the perspective of increasing the diversity of triplet features. Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively. Then, we design two different feature augmentation modules to enrich the feature diversity of original relation triplets by replacing or mixing up either their intrinsic or extrinsic features from other samples. Due to its model-agnostic nature, CFA can be seamlessly incorporated into various SGG frameworks. Extensive ablations have shown that CFA achieves a new state-of-the-art performance on the trade-off between different metrics.
Custom-Edit: Text-Guided Image Editing with Customized Diffusion Models
May 25, 2023
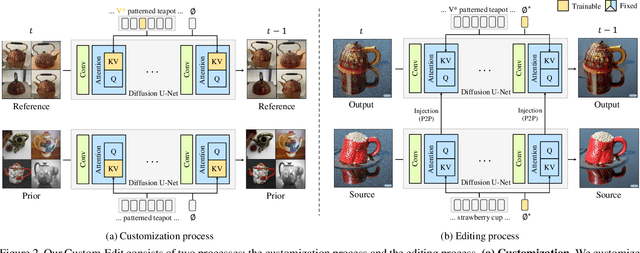

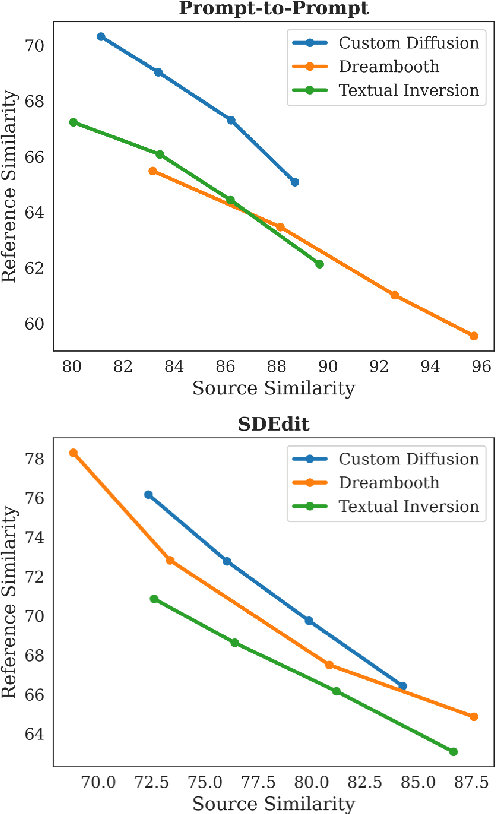
Text-to-image diffusion models can generate diverse, high-fidelity images based on user-provided text prompts. Recent research has extended these models to support text-guided image editing. While text guidance is an intuitive editing interface for users, it often fails to ensure the precise concept conveyed by users. To address this issue, we propose Custom-Edit, in which we (i) customize a diffusion model with a few reference images and then (ii) perform text-guided editing. Our key discovery is that customizing only language-relevant parameters with augmented prompts improves reference similarity significantly while maintaining source similarity. Moreover, we provide our recipe for each customization and editing process. We compare popular customization methods and validate our findings on two editing methods using various datasets.
Human Action Recognition in Still Images Using ConViT
Jul 18, 2023


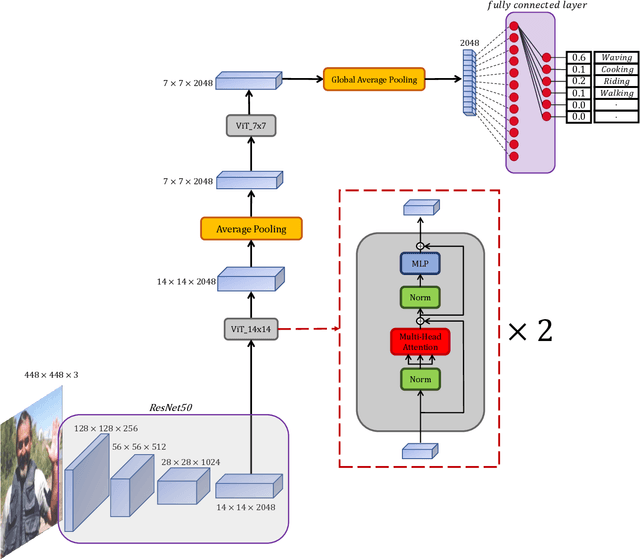
Understanding the relationship between different parts of the image plays a crucial role in many visual recognition tasks. Despite the fact that Convolutional Neural Networks (CNNs) have demonstrated impressive results in detecting single objects, they lack the capability to extract the relationship between various regions of an image, which is a crucial factor in human action recognition. To address this problem, this paper proposes a new module that functions like a convolutional layer using Vision Transformer (ViT). The proposed action recognition model comprises two components: the first part is a deep convolutional network that extracts high-level spatial features from the image, and the second component of the model utilizes a Vision Transformer that extracts the relationship between various regions of the image using the feature map generated by the CNN output. The proposed model has been evaluated on the Stanford40 and PASCAL VOC 2012 action datasets and has achieved 95.5% mAP and 91.5% mAP results, respectively, which are promising compared to other state-of-the-art methods.
Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression
May 12, 2023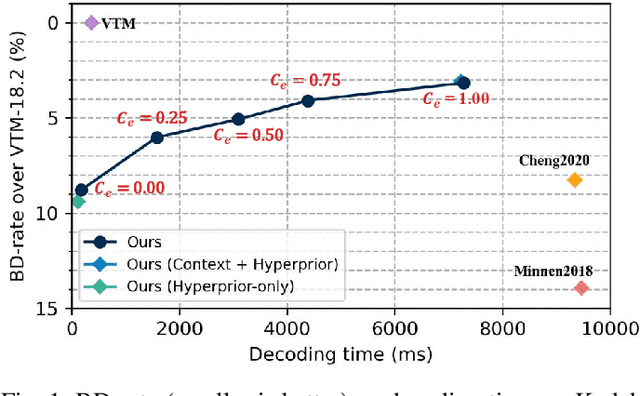
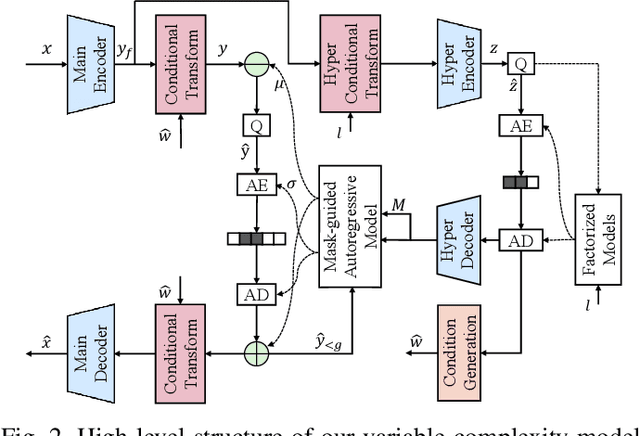
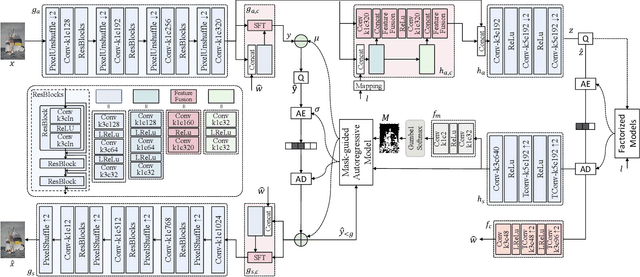
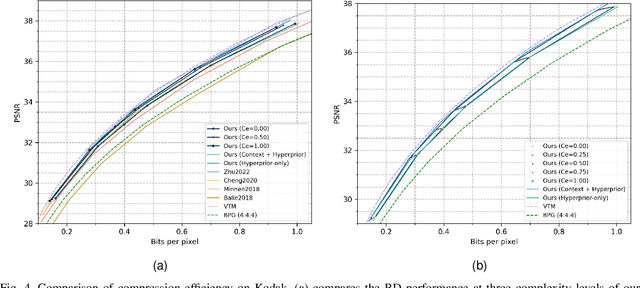
Despite a short history, neural image codecs have been shown to surpass classical image codecs in terms of rate-distortion performance. However, most of them suffer from significantly longer decoding times, which hinders the practical applications of neural image codecs. This issue is especially pronounced when employing an effective yet time-consuming autoregressive context model since it would increase entropy decoding time by orders of magnitude. In this paper, unlike most previous works that pursue optimal RD performance while temporally overlooking the coding complexity, we make a systematical investigation on the rate-distortion-complexity (RDC) optimization in neural image compression. By quantifying the decoding complexity as a factor in the optimization goal, we are now able to precisely control the RDC trade-off and then demonstrate how the rate-distortion performance of neural image codecs could adapt to various complexity demands. Going beyond the investigation of RDC optimization, a variable-complexity neural codec is designed to leverage the spatial dependencies adaptively according to industrial demands, which supports fine-grained complexity adjustment by balancing the RDC tradeoff. By implementing this scheme in a powerful base model, we demonstrate the feasibility and flexibility of RDC optimization for neural image codecs.
Improving Mass Detection in Mammography Images: A Study of Weakly Supervised Learning and Class Activation Map Methods
Aug 07, 2023In recent years, weakly supervised models have aided in mass detection using mammography images, decreasing the need for pixel-level annotations. However, most existing models in the literature rely on Class Activation Maps (CAM) as the activation method, overlooking the potential benefits of exploring other activation techniques. This work presents a study that explores and compares different activation maps in conjunction with state-of-the-art methods for weakly supervised training in mammography images. Specifically, we investigate CAM, GradCAM, GradCAM++, XGradCAM, and LayerCAM methods within the framework of the GMIC model for mass detection in mammography images. The evaluation is conducted on the VinDr-Mammo dataset, utilizing the metrics Accuracy, True Positive Rate (TPR), False Negative Rate (FNR), and False Positive Per Image (FPPI). Results show that using different strategies of activation maps during training and test stages leads to an improvement of the model. With this strategy, we improve the results of the GMIC method, decreasing the FPPI value and increasing TPR.
Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023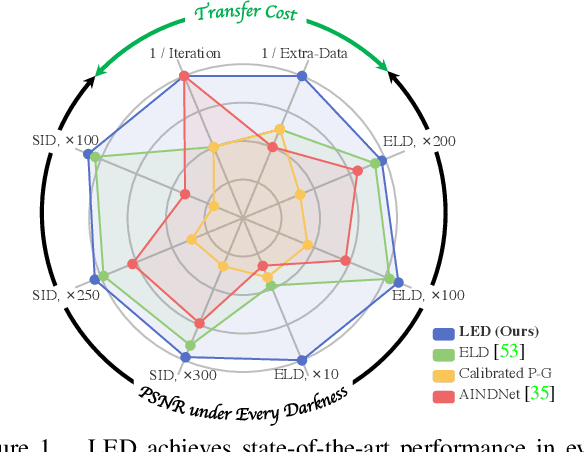
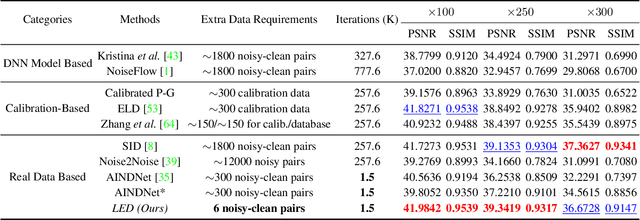
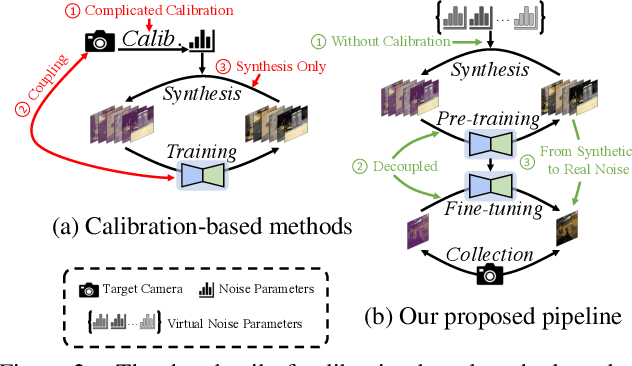
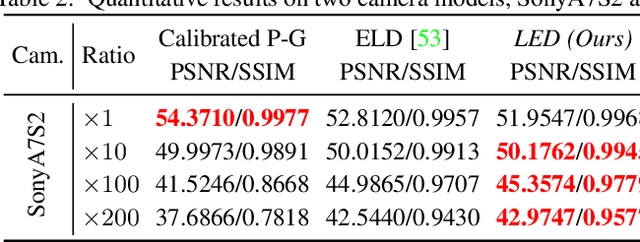
Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
Image Reconstruction using Superpixel Clustering and Tensor Completion
May 16, 2023


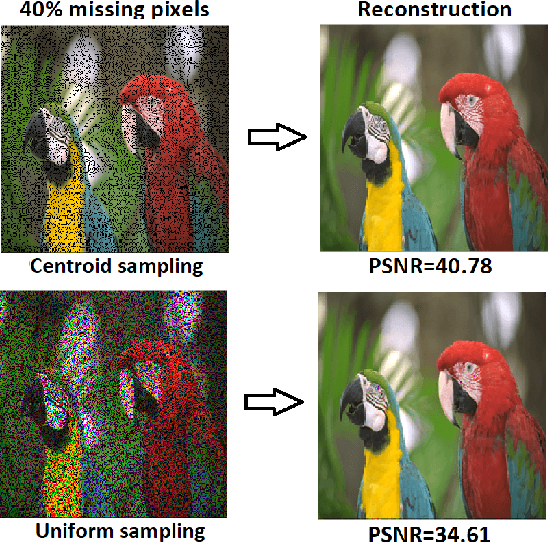
This paper presents a pixel selection method for compact image representation based on superpixel segmentation and tensor completion. Our method divides the image into several regions that capture important textures or semantics and selects a representative pixel from each region to store. We experiment with different criteria for choosing the representative pixel and find that the centroid pixel performs the best. We also propose two smooth tensor completion algorithms that can effectively reconstruct different types of images from the selected pixels. Our experiments show that our superpixel-based method achieves better results than uniform sampling for various missing ratios.
DermoSegDiff: A Boundary-aware Segmentation Diffusion Model for Skin Lesion Delineation
Aug 05, 2023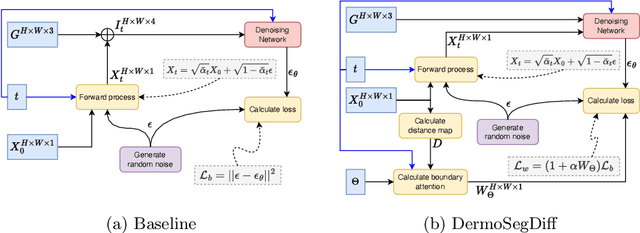
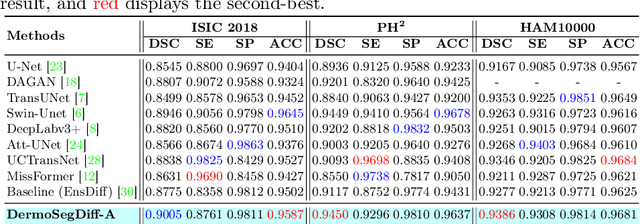
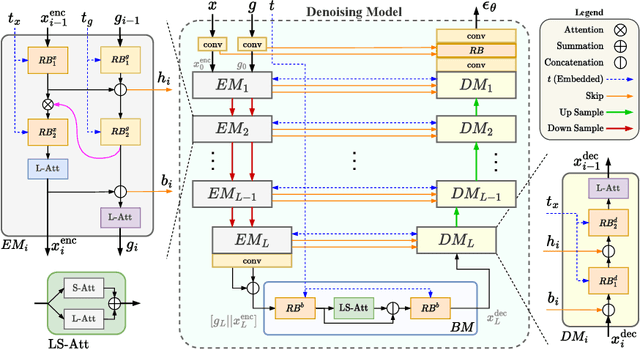
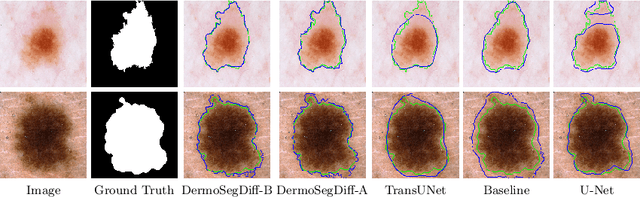
Skin lesion segmentation plays a critical role in the early detection and accurate diagnosis of dermatological conditions. Denoising Diffusion Probabilistic Models (DDPMs) have recently gained attention for their exceptional image-generation capabilities. Building on these advancements, we propose DermoSegDiff, a novel framework for skin lesion segmentation that incorporates boundary information during the learning process. Our approach introduces a novel loss function that prioritizes the boundaries during training, gradually reducing the significance of other regions. We also introduce a novel U-Net-based denoising network that proficiently integrates noise and semantic information inside the network. Experimental results on multiple skin segmentation datasets demonstrate the superiority of DermoSegDiff over existing CNN, transformer, and diffusion-based approaches, showcasing its effectiveness and generalization in various scenarios. The implementation is publicly accessible on \href{https://github.com/mindflow-institue/dermosegdiff}{GitHub}
Efficient Mixed Transformer for Single Image Super-Resolution
May 22, 2023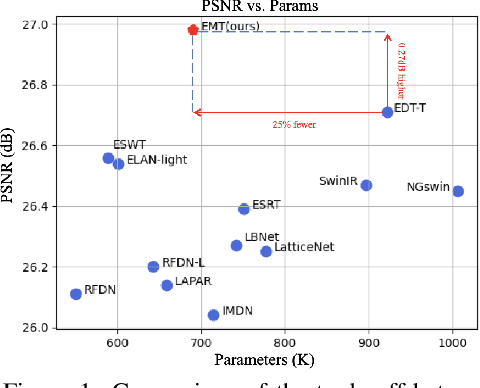
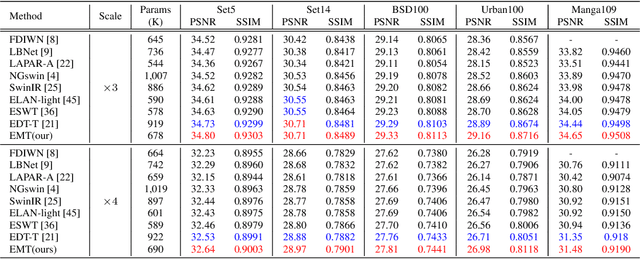
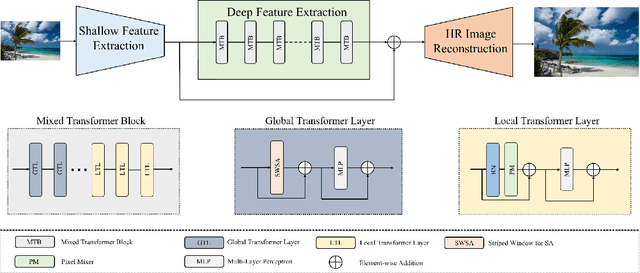
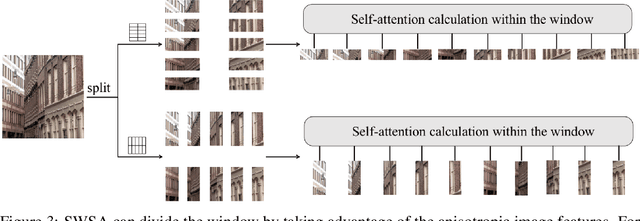
Recently, Transformer-based methods have achieved impressive results in single image super-resolution (SISR). However, the lack of locality mechanism and high complexity limit their application in the field of super-resolution (SR). To solve these problems, we propose a new method, Efficient Mixed Transformer (EMT) in this study. Specifically, we propose the Mixed Transformer Block (MTB), consisting of multiple consecutive transformer layers, in some of which the Pixel Mixer (PM) is used to replace the Self-Attention (SA). PM can enhance the local knowledge aggregation with pixel shifting operations. At the same time, no additional complexity is introduced as PM has no parameters and floating-point operations. Moreover, we employ striped window for SA (SWSA) to gain an efficient global dependency modelling by utilizing image anisotropy. Experimental results show that EMT outperforms the existing methods on benchmark dataset and achieved state-of-the-art performance. The Code is available at https://github. com/Fried-Rice-Lab/EMT.git.