 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Focus Image Fusion Based on Spatial Frequency(SF) and Consistency Verification(CV) in DCT Domain
May 18, 2023
Multi-focus is a technique of focusing on different aspects of a particular object or scene. Wireless Visual Sensor Networks (WVSN) use multi-focus image fusion, which combines two or more images to create a more accurate output image that describes the scene better than any individual input image. WVSN has various applications, including video surveillance, monitoring, and tracking. Therefore, a high-level analysis of these networks can benefit Biometrics. This paper introduces an algorithm that utilizes discrete cosine transform (DCT) standards to fuse multi-focus images in WVSNs. The spatial frequency (SF) of the corresponding blocks from the source images determines the fusion criterion. The blocks with higher spatial frequencies make up the DCT presentation of the fused image, and the Consistency Verification (CV) procedure is used to enhance the output image quality. The proposed fusion method was tested on multiple pairs of multi-focus images coded on JPEG standard to evaluate the fusion performance, and the results indicate that it improves the visual quality of the output image and outperforms other DCT-based techniques.
Learning Full-Head 3D GANs from a Single-View Portrait Dataset
Jul 27, 2023



33D-aware face generators are commonly trained on 2D real-life face image datasets. Nevertheless, existing facial recognition methods often struggle to extract face data captured from various camera angles. Furthermore, in-the-wild images with diverse body poses introduce a high-dimensional challenge for 3D-aware generators, making it difficult to utilize data that contains complete neck and shoulder regions. Consequently, these face image datasets often contain only near-frontal face data, which poses challenges for 3D-aware face generators to construct \textit{full-head} 3D portraits. To this end, we first create the dataset {$\it{360}^{\circ}$}-\textit{Portrait}-\textit{HQ} (\textit{$\it{360}^{\circ}$PHQ}), which consists of high-quality single-view real portraits annotated with a variety of camera parameters {(the yaw angles span the entire $360^{\circ}$ range)} and body poses. We then propose \textit{3DPortraitGAN}, the first 3D-aware full-head portrait generator that learns a canonical 3D avatar distribution from the body-pose-various \textit{$\it{360}^{\circ}$PHQ} dataset with body pose self-learning. Our model can generate view-consistent portrait images from all camera angles (${360}^{\circ}$) with a full-head 3D representation. We incorporate a mesh-guided deformation field into volumetric rendering to produce deformed results to generate portrait images that conform to the body pose distribution of the dataset using our canonical generator. We integrate two pose predictors into our framework to predict more accurate body poses to address the issue of inaccurately estimated body poses in our dataset. Our experiments show that the proposed framework can generate view-consistent, realistic portrait images with complete geometry from all camera angles and accurately predict portrait body pose.
UMat: Uncertainty-Aware Single Image High Resolution Material Capture
May 25, 2023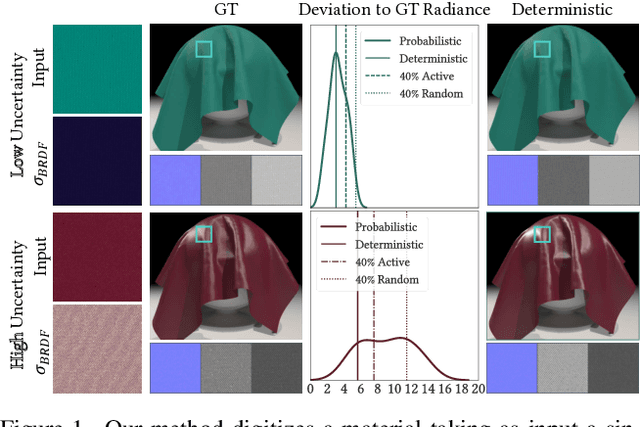
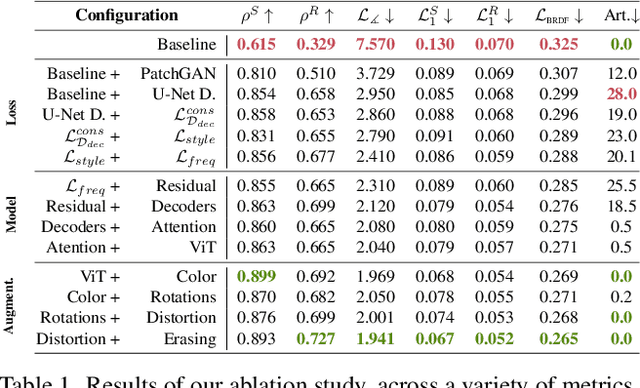

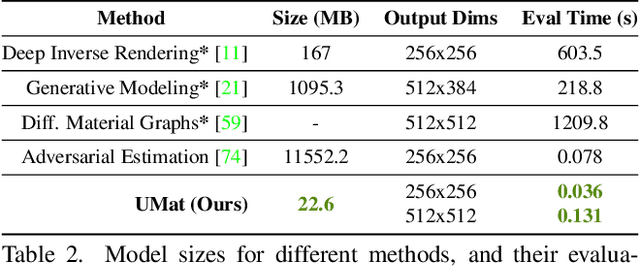
We propose a learning-based method to recover normals, specularity, and roughness from a single diffuse image of a material, using microgeometry appearance as our primary cue. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. Previous methods that work on single images tend to produce over-smooth outputs with artifacts, operate at limited resolution, or train one model per class with little room for generalization. In contrast, in this work, we propose a novel capture approach that leverages a generative network with attention and a U-Net discriminator, which shows outstanding performance integrating global information at reduced computational complexity. We showcase the performance of our method with a real dataset of digitized textile materials and show that a commodity flatbed scanner can produce the type of diffuse illumination required as input to our method. Additionally, because the problem might be illposed -more than a single diffuse image might be needed to disambiguate the specular reflection- or because the training dataset is not representative enough of the real distribution, we propose a novel framework to quantify the model's confidence about its prediction at test time. Our method is the first one to deal with the problem of modeling uncertainty in material digitization, increasing the trustworthiness of the process and enabling more intelligent strategies for dataset creation, as we demonstrate with an active learning experiment.
Scene Text Recognition with Image-Text Matching-guided Dictionary
May 08, 2023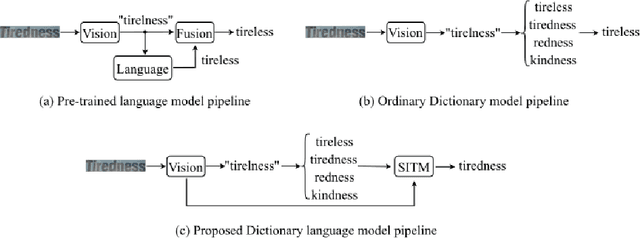
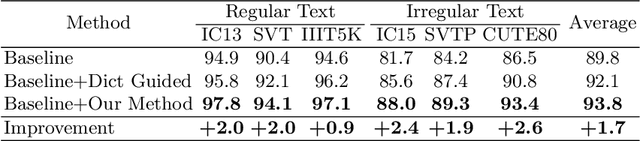
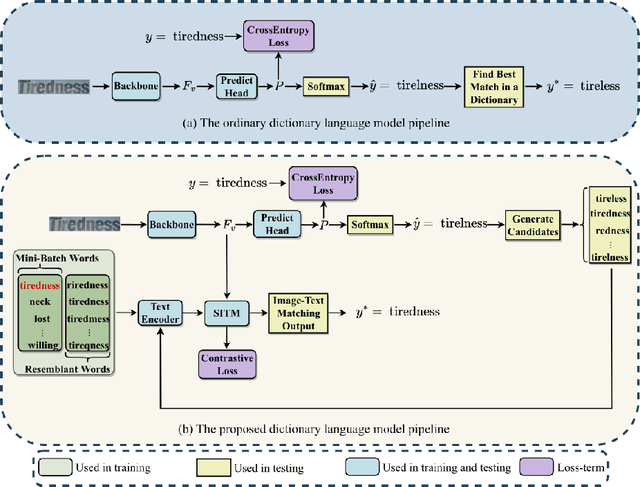
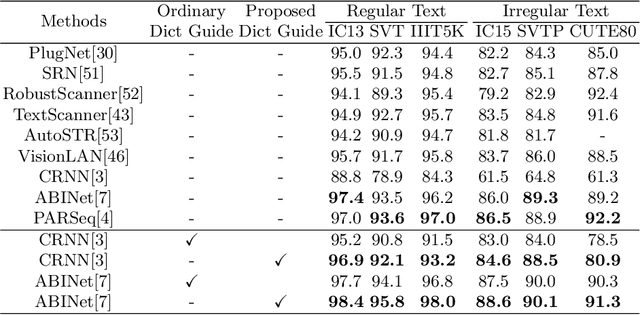
Employing a dictionary can efficiently rectify the deviation between the visual prediction and the ground truth in scene text recognition methods. However, the independence of the dictionary on the visual features may lead to incorrect rectification of accurate visual predictions. In this paper, we propose a new dictionary language model leveraging the Scene Image-Text Matching(SITM) network, which avoids the drawbacks of the explicit dictionary language model: 1) the independence of the visual features; 2) noisy choice in candidates etc. The SITM network accomplishes this by using Image-Text Contrastive (ITC) Learning to match an image with its corresponding text among candidates in the inference stage. ITC is widely used in vision-language learning to pull the positive image-text pair closer in feature space. Inspired by ITC, the SITM network combines the visual features and the text features of all candidates to identify the candidate with the minimum distance in the feature space. Our lexicon method achieves better results(93.8\% accuracy) than the ordinary method results(92.1\% accuracy) on six mainstream benchmarks. Additionally, we integrate our method with ABINet and establish new state-of-the-art results on several benchmarks.
Quantized Feature Distillation for Network Quantization
Jul 20, 2023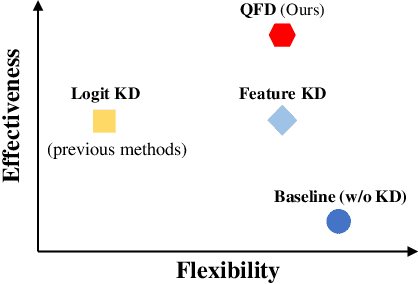
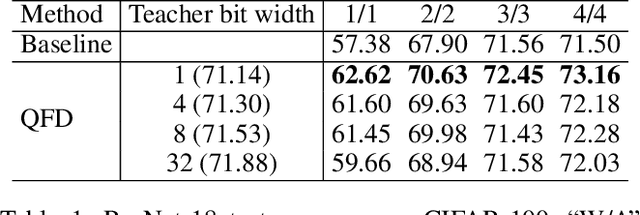
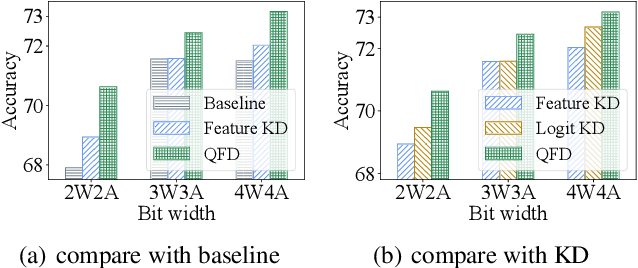
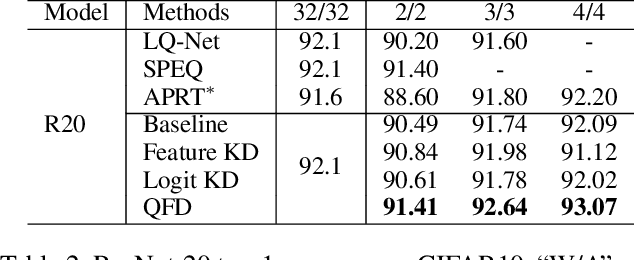
Neural network quantization aims to accelerate and trim full-precision neural network models by using low bit approximations. Methods adopting the quantization aware training (QAT) paradigm have recently seen a rapid growth, but are often conceptually complicated. This paper proposes a novel and highly effective QAT method, quantized feature distillation (QFD). QFD first trains a quantized (or binarized) representation as the teacher, then quantize the network using knowledge distillation (KD). Quantitative results show that QFD is more flexible and effective (i.e., quantization friendly) than previous quantization methods. QFD surpasses existing methods by a noticeable margin on not only image classification but also object detection, albeit being much simpler. Furthermore, QFD quantizes ViT and Swin-Transformer on MS-COCO detection and segmentation, which verifies its potential in real world deployment. To the best of our knowledge, this is the first time that vision transformers have been quantized in object detection and image segmentation tasks.
Towards Viewpoint-Invariant Visual Recognition via Adversarial Training
Jul 16, 2023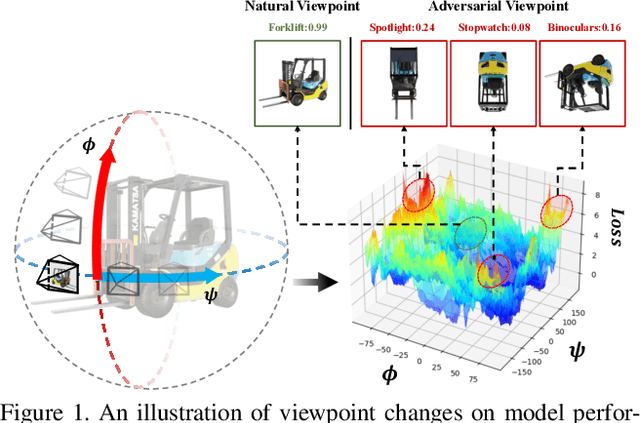
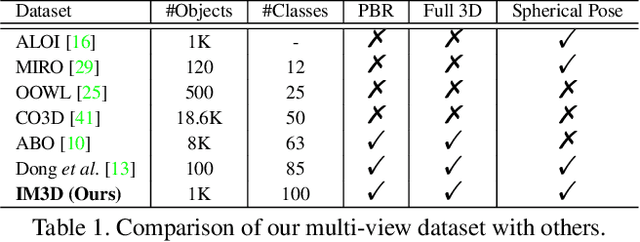
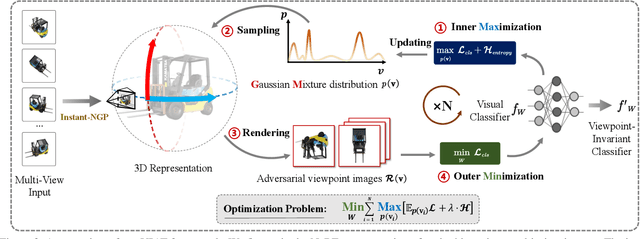
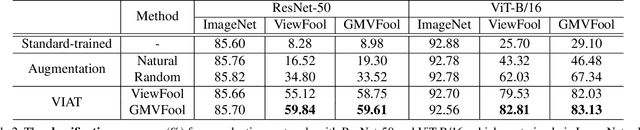
Visual recognition models are not invariant to viewpoint changes in the 3D world, as different viewing directions can dramatically affect the predictions given the same object. Although many efforts have been devoted to making neural networks invariant to 2D image translations and rotations, viewpoint invariance is rarely investigated. As most models process images in the perspective view, it is challenging to impose invariance to 3D viewpoint changes based only on 2D inputs. Motivated by the success of adversarial training in promoting model robustness, we propose Viewpoint-Invariant Adversarial Training (VIAT) to improve viewpoint robustness of common image classifiers. By regarding viewpoint transformation as an attack, VIAT is formulated as a minimax optimization problem, where the inner maximization characterizes diverse adversarial viewpoints by learning a Gaussian mixture distribution based on a new attack GMVFool, while the outer minimization trains a viewpoint-invariant classifier by minimizing the expected loss over the worst-case adversarial viewpoint distributions. To further improve the generalization performance, a distribution sharing strategy is introduced leveraging the transferability of adversarial viewpoints across objects. Experiments validate the effectiveness of VIAT in improving the viewpoint robustness of various image classifiers based on the diversity of adversarial viewpoints generated by GMVFool.
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
May 26, 2023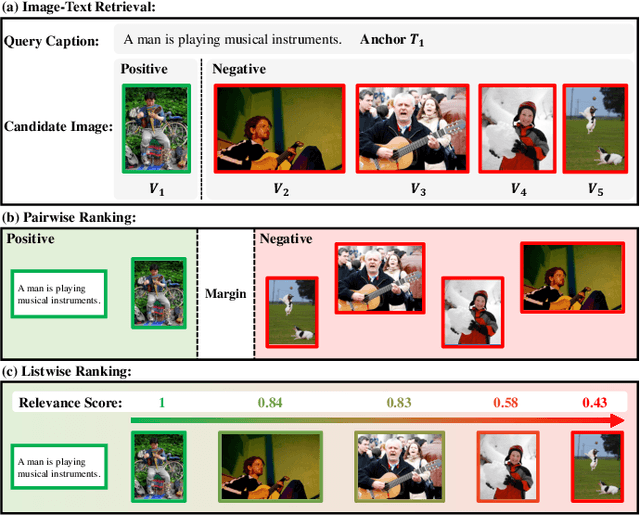

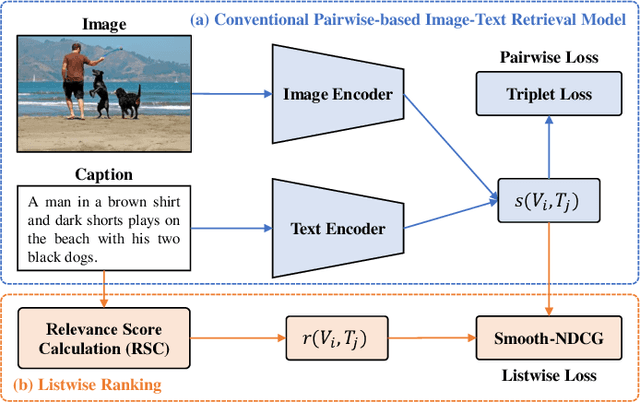
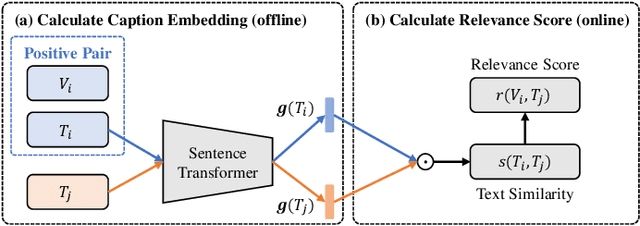
Image-Text Retrieval (ITR) is essentially a ranking problem. Given a query caption, the goal is to rank candidate images by relevance, from large to small. The current ITR datasets are constructed in a pairwise manner. Image-text pairs are annotated as positive or negative. Correspondingly, ITR models mainly use pairwise losses, such as triplet loss, to learn to rank. Pairwise-based ITR increases positive pair similarity while decreasing negative pair similarity indiscriminately. However, the relevance between dissimilar negative pairs is different. Pairwise annotations cannot reflect this difference in relevance. In the current datasets, pairwise annotations miss many correlations. There are many potential positive pairs among the pairs labeled as negative. Pairwise-based ITR can only rank positive samples before negative samples, but cannot rank negative samples by relevance. In this paper, we integrate listwise ranking into conventional pairwise-based ITR. Listwise ranking optimizes the entire ranking list based on relevance scores. Specifically, we first propose a Relevance Score Calculation (RSC) module to calculate the relevance score of the entire ranked list. Then we choose the ranking metric, Normalized Discounted Cumulative Gain (NDCG), as the optimization objective. We transform the non-differentiable NDCG into a differentiable listwise loss, named Smooth-NDCG (S-NDCG). Our listwise ranking approach can be plug-and-play integrated into current pairwise-based ITR models. Experiments on ITR benchmarks show that integrating listwise ranking can improve the performance of current ITR models and provide more user-friendly retrieval results. The code is available at https://github.com/AAA-Zheng/Listwise_ITR.
Contrastive Learning Based Recursive Dynamic Multi-Scale Network for Image Deraining
May 29, 2023



Rain streaks significantly decrease the visibility of captured images and are also a stumbling block that restricts the performance of subsequent computer vision applications. The existing deep learning-based image deraining methods employ manually crafted networks and learn a straightforward projection from rainy images to clear images. In pursuit of better deraining performance, they focus on elaborating a more complicated architecture rather than exploiting the intrinsic properties of the positive and negative information. In this paper, we propose a contrastive learning-based image deraining method that investigates the correlation between rainy and clear images and leverages a contrastive prior to optimize the mutual information of the rainy and restored counterparts. Given the complex and varied real-world rain patterns, we develop a recursive mechanism. It involves multi-scale feature extraction and dynamic cross-level information recruitment modules. The former advances the portrayal of diverse rain patterns more precisely, while the latter can selectively compensate high-level features for shallow-level information. We term the proposed recursive dynamic multi-scale network with a contrastive prior, RDMC. Extensive experiments on synthetic benchmarks and real-world images demonstrate that the proposed RDMC delivers strong performance on the depiction of rain streaks and outperforms the state-of-the-art methods. Moreover, a practical evaluation of object detection and semantic segmentation shows the effectiveness of the proposed method.
Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
May 23, 2023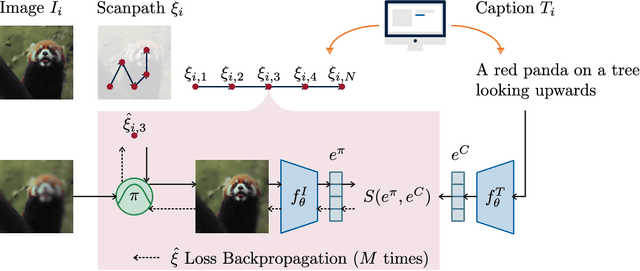
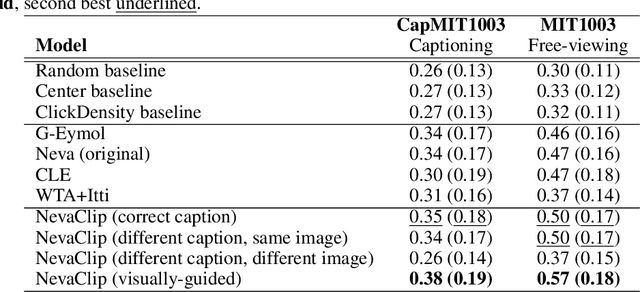

Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.
MOCA: Self-supervised Representation Learning by Predicting Masked Online Codebook Assignments
Jul 18, 2023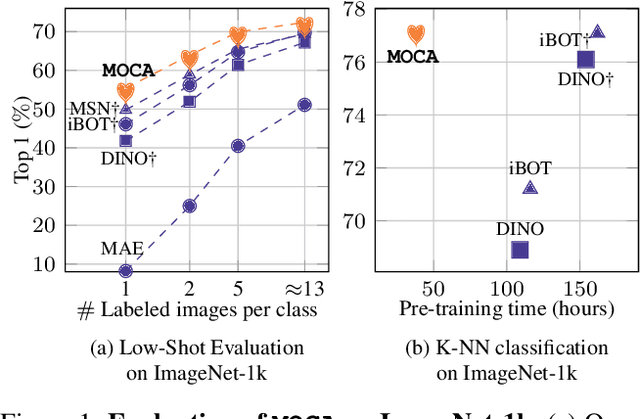

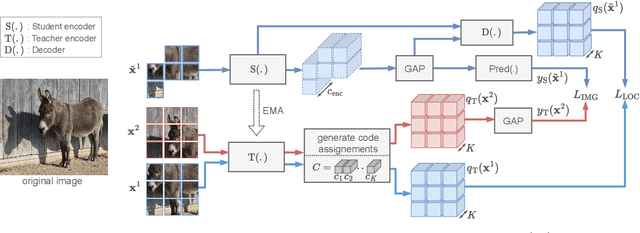
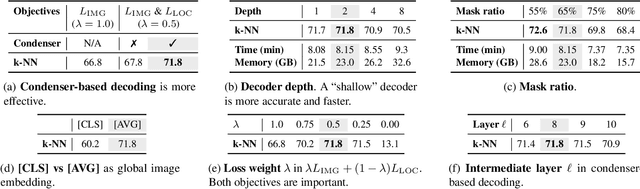
Self-supervised learning can be used for mitigating the greedy needs of Vision Transformer networks for very large fully-annotated datasets. Different classes of self-supervised learning offer representations with either good contextual reasoning properties, e.g., using masked image modeling strategies, or invariance to image perturbations, e.g., with contrastive methods. In this work, we propose a single-stage and standalone method, MOCA, which unifies both desired properties using novel mask-and-predict objectives defined with high-level features (instead of pixel-level details). Moreover, we show how to effectively employ both learning paradigms in a synergistic and computation-efficient way. Doing so, we achieve new state-of-the-art results on low-shot settings and strong experimental results in various evaluation protocols with a training that is at least 3 times faster than prior methods.