 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High Dynamic Range Imaging via Visual Attention Modules
Jul 27, 2023
Thanks to High Dynamic Range (HDR) imaging methods, the scope of photography has seen profound changes recently. To be more specific, such methods try to reconstruct the lost luminosity of the real world caused by the limitation of regular cameras from the Low Dynamic Range (LDR) images. Additionally, although the State-Of-The-Art methods in this topic perform well, they mainly concentrate on combining different exposures and have less attention to extracting the informative parts of the images. Thus, this paper aims to introduce a new model capable of incorporating information from the most visible areas of each image extracted by a visual attention module (VAM), which is a result of a segmentation strategy. In particular, the model, based on a deep learning architecture, utilizes the extracted areas to produce the final HDR image. The results demonstrate that our method outperformed most of the State-Of-The-Art algorithms.
Language-based Action Concept Spaces Improve Video Self-Supervised Learning
Jul 20, 2023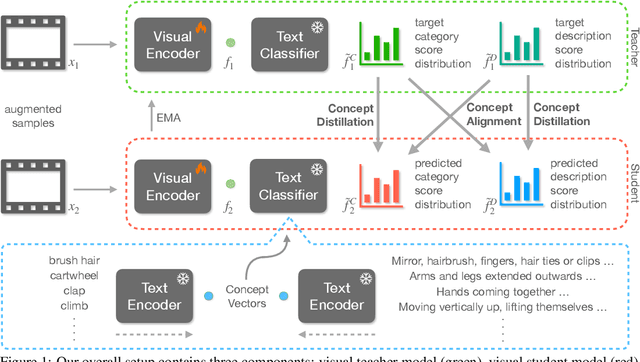
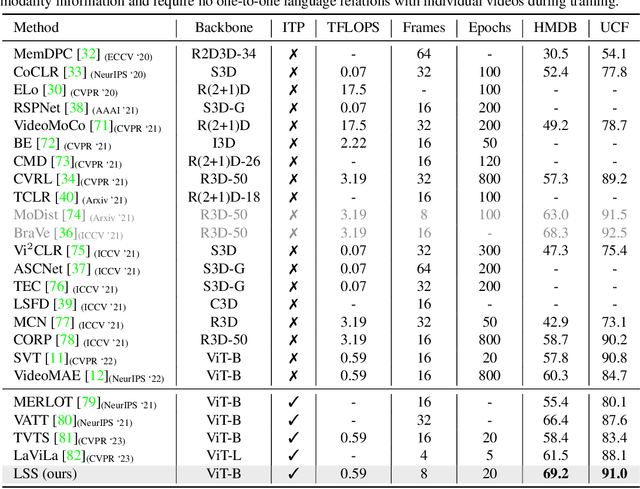
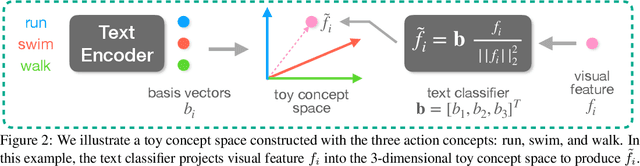
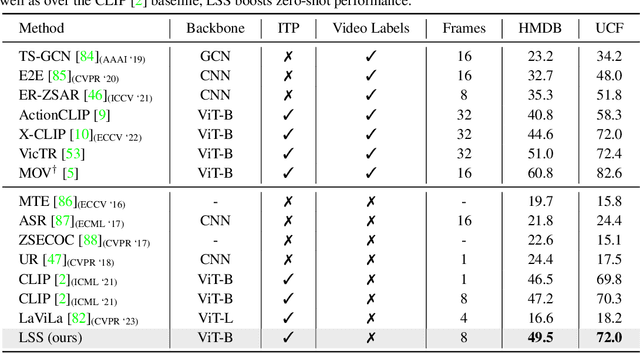
Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
Generalized Expectation Maximization Framework for Blind Image Super Resolution
May 23, 2023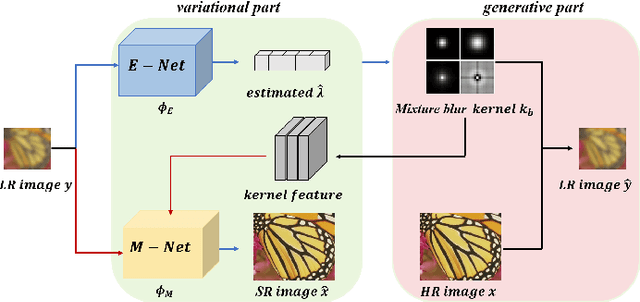
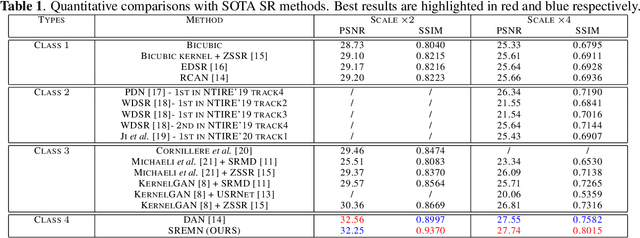

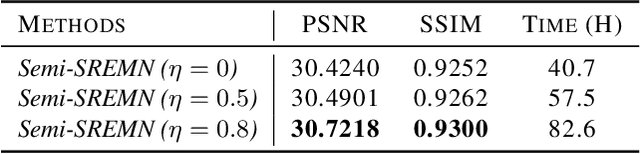
Learning-based methods for blind single image super resolution (SISR) conduct the restoration by a learned mapping between high-resolution (HR) images and their low-resolution (LR) counterparts degraded with arbitrary blur kernels. However, these methods mostly require an independent step to estimate the blur kernel, leading to error accumulation between steps. We propose an end-to-end learning framework for the blind SISR problem, which enables image restoration within a unified Bayesian framework with either full- or semi-supervision. The proposed method, namely SREMN, integrates learning techniques into the generalized expectation-maximization (GEM) algorithm and infers HR images from the maximum likelihood estimation (MLE). Extensive experiments show the superiority of the proposed method with comparison to existing work and novelty in semi-supervised learning.
Unlocking the Diagnostic Potential of ECG through Knowledge Transfer from Cardiac MRI
Aug 09, 2023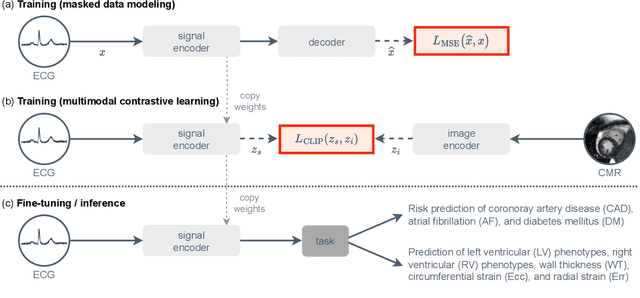
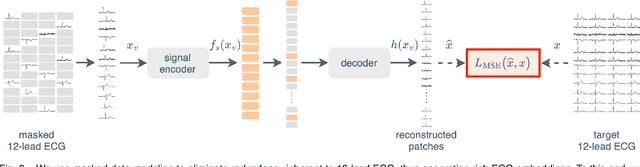
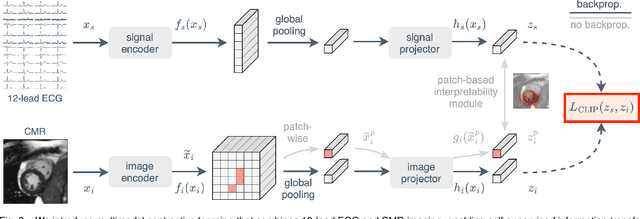
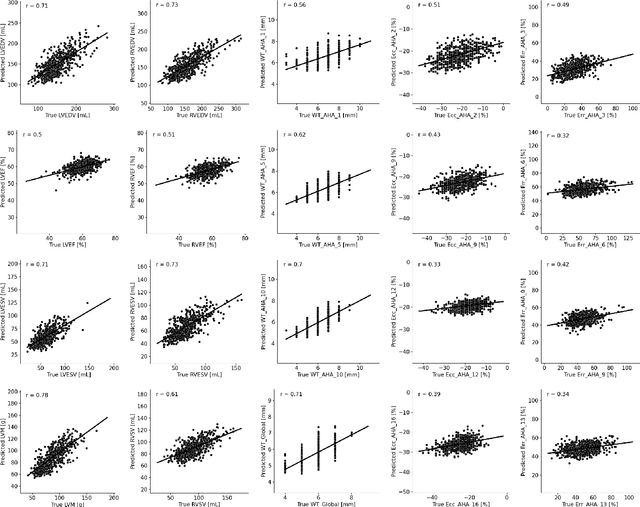
The electrocardiogram (ECG) is a widely available diagnostic tool that allows for a cost-effective and fast assessment of the cardiovascular health. However, more detailed examination with expensive cardiac magnetic resonance (CMR) imaging is often preferred for the diagnosis of cardiovascular diseases. While providing detailed visualization of the cardiac anatomy, CMR imaging is not widely available due to long scan times and high costs. To address this issue, we propose the first self-supervised contrastive approach that transfers domain-specific information from CMR images to ECG embeddings. Our approach combines multimodal contrastive learning with masked data modeling to enable holistic cardiac screening solely from ECG data. In extensive experiments using data from 40,044 UK Biobank subjects, we demonstrate the utility and generalizability of our method. We predict the subject-specific risk of various cardiovascular diseases and determine distinct cardiac phenotypes solely from ECG data. In a qualitative analysis, we demonstrate that our learned ECG embeddings incorporate information from CMR image regions of interest. We make our entire pipeline publicly available, including the source code and pre-trained model weights.
Which Tokens to Use? Investigating Token Reduction in Vision Transformers
Aug 09, 2023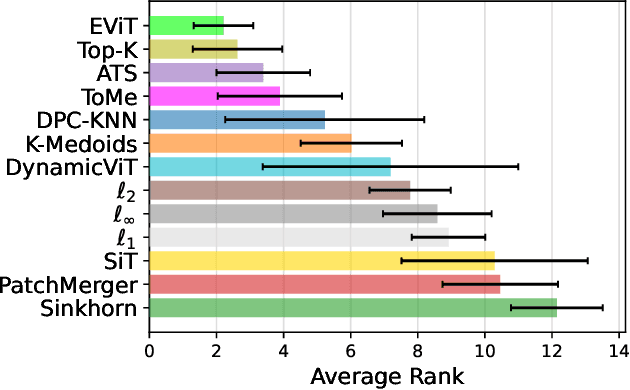
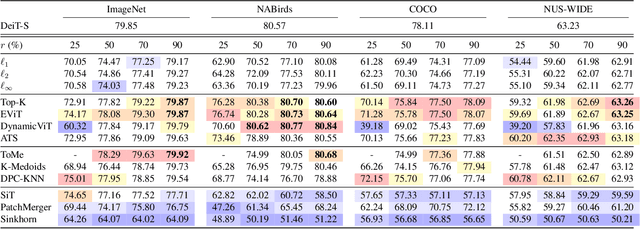


Since the introduction of the Vision Transformer (ViT), researchers have sought to make ViTs more efficient by removing redundant information in the processed tokens. While different methods have been explored to achieve this goal, we still lack understanding of the resulting reduction patterns and how those patterns differ across token reduction methods and datasets. To close this gap, we set out to understand the reduction patterns of 10 different token reduction methods using four image classification datasets. By systematically comparing these methods on the different classification tasks, we find that the Top-K pruning method is a surprisingly strong baseline. Through in-depth analysis of the different methods, we determine that: the reduction patterns are generally not consistent when varying the capacity of the backbone model, the reduction patterns of pruning-based methods significantly differ from fixed radial patterns, and the reduction patterns of pruning-based methods are correlated across classification datasets. Finally we report that the similarity of reduction patterns is a moderate-to-strong proxy for model performance. Project page at https://vap.aau.dk/tokens.
Seeing in Flowing: Adapting CLIP for Action Recognition with Motion Prompts Learning
Aug 09, 2023The Contrastive Language-Image Pre-training (CLIP) has recently shown remarkable generalization on "zero-shot" training and has applied to many downstream tasks. We explore the adaptation of CLIP to achieve a more efficient and generalized action recognition method. We propose that the key lies in explicitly modeling the motion cues flowing in video frames. To that end, we design a two-stream motion modeling block to capture motion and spatial information at the same time. And then, the obtained motion cues are utilized to drive a dynamic prompts learner to generate motion-aware prompts, which contain much semantic information concerning human actions. In addition, we propose a multimodal communication block to achieve a collaborative learning and further improve the performance. We conduct extensive experiments on HMDB-51, UCF-101, and Kinetics-400 datasets. Our method outperforms most existing state-of-the-art methods by a significant margin on "few-shot" and "zero-shot" training. We also achieve competitive performance on "closed-set" training with extremely few trainable parameters and additional computational costs.
Remote Sensing Image Change Detection Towards Continuous Bitemporal Resolution Differences
May 24, 2023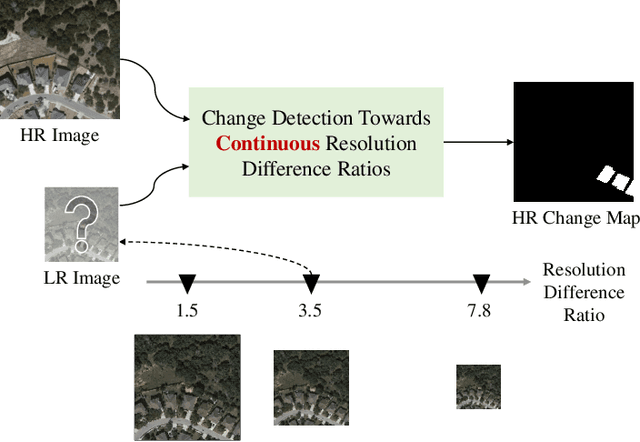

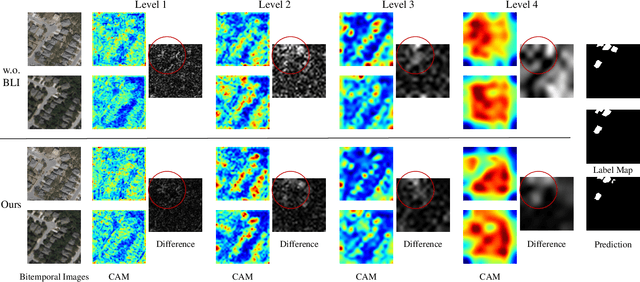
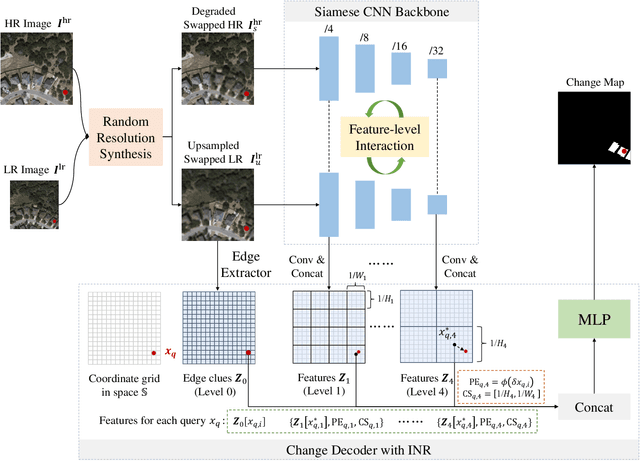
Most contemporary supervised Remote Sensing (RS) image Change Detection (CD) approaches are customized for equal-resolution bitemporal images. Real-world applications raise the need for cross-resolution change detection, aka, CD based on bitemporal images with different spatial resolutions. Current cross-resolution methods that are trained with samples of a fixed resolution difference (resolution ratio between the high-resolution (HR) image and the low-resolution (LR) one) may fit a certain ratio but lack adaptation to other resolution differences. Toward continuous cross-resolution CD, we propose scale-invariant learning to enforce the model consistently predicting HR results given synthesized samples of varying bitemporal resolution differences. Concretely, we synthesize blurred versions of the HR image by random downsampled reconstructions to reduce the gap between HR and LR images. We introduce coordinate-based representations to decode per-pixel predictions by feeding the coordinate query and corresponding multi-level embedding features into an MLP that implicitly learns the shape of land cover changes, therefore benefiting recognizing blurred objects in the LR image. Moreover, considering that spatial resolution mainly affects the local textures, we apply local-window self-attention to align bitemporal features during the early stages of the encoder. Extensive experiments on two synthesized and one real-world different-resolution CD datasets verify the effectiveness of the proposed method. Our method significantly outperforms several vanilla CD methods and two cross-resolution CD methods on the three datasets both in in-distribution and out-of-distribution settings. The empirical results suggest that our method could yield relatively consistent HR change predictions regardless of varying resolution difference ratios. Our code will be public.
Networks are Slacking Off: Understanding Generalization Problem in Image Deraining
May 24, 2023


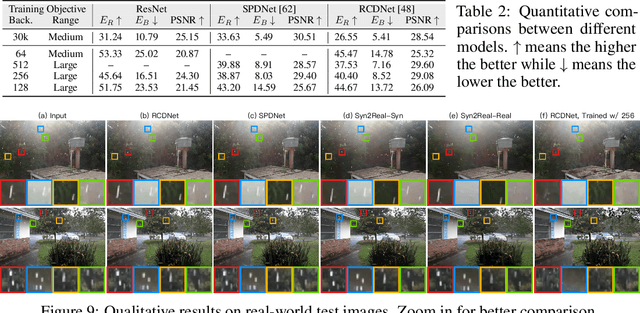
Deep deraining networks, while successful in laboratory benchmarks, consistently encounter substantial generalization issues when deployed in real-world applications. A prevailing perspective in deep learning encourages the use of highly complex training data, with the expectation that a richer image content knowledge will facilitate overcoming the generalization problem. However, through comprehensive and systematic experimentation, we discovered that this strategy does not enhance the generalization capability of these networks. On the contrary, it exacerbates the tendency of networks to overfit to specific degradations. Our experiments reveal that better generalization in a deraining network can be achieved by simplifying the complexity of the training data. This is due to the networks are slacking off during training, that is, learning the least complex elements in the image content and degradation to minimize training loss. When the complexity of the background image is less than that of the rain streaks, the network will prioritize the reconstruction of the background, thereby avoiding overfitting to the rain patterns and resulting in improved generalization performance. Our research not only offers a valuable perspective and methodology for better understanding the generalization problem in low-level vision tasks, but also displays promising practical potential.
An Explainable Model-Agnostic Algorithm for CNN-based Biometrics Verification
Jul 25, 2023
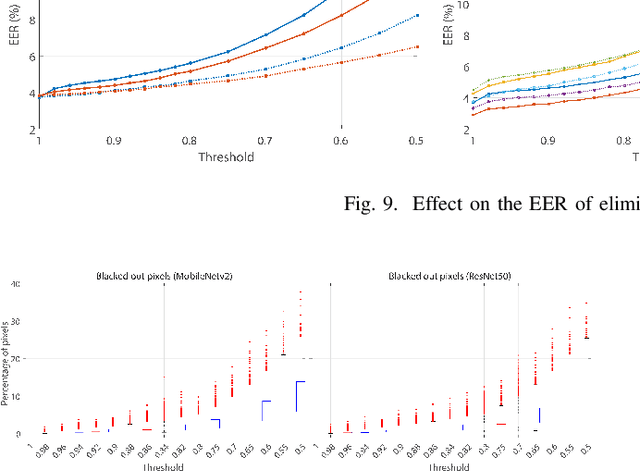

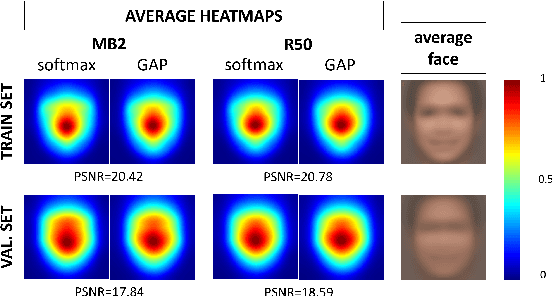
This paper describes an adaptation of the Local Interpretable Model-Agnostic Explanations (LIME) AI method to operate under a biometric verification setting. LIME was initially proposed for networks with the same output classes used for training, and it employs the softmax probability to determine which regions of the image contribute the most to classification. However, in a verification setting, the classes to be recognized have not been seen during training. In addition, instead of using the softmax output, face descriptors are usually obtained from a layer before the classification layer. The model is adapted to achieve explainability via cosine similarity between feature vectors of perturbated versions of the input image. The method is showcased for face biometrics with two CNN models based on MobileNetv2 and ResNet50.
Not So Robust After All: Evaluating the Robustness of Deep Neural Networks to Unseen Adversarial Attacks
Aug 12, 2023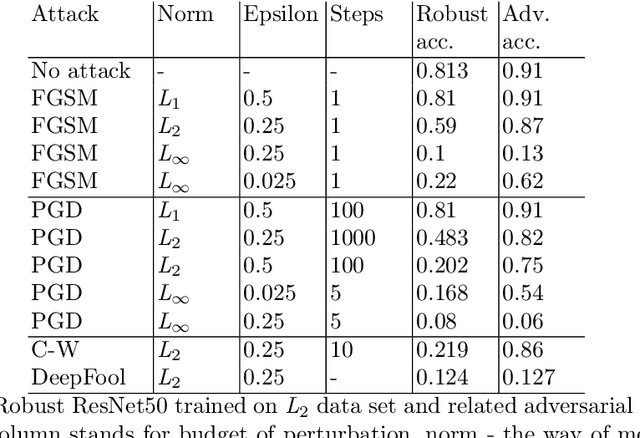
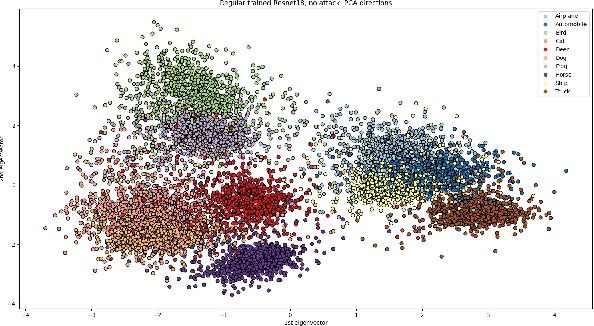
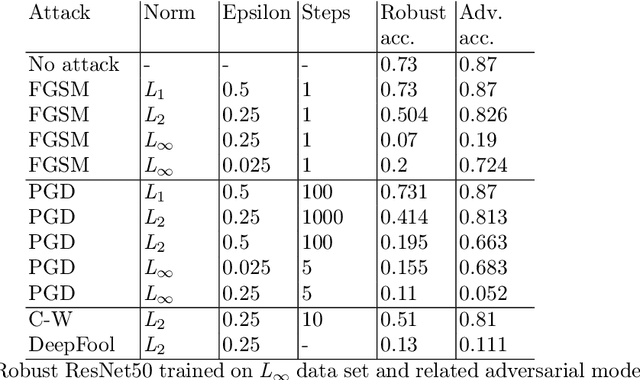
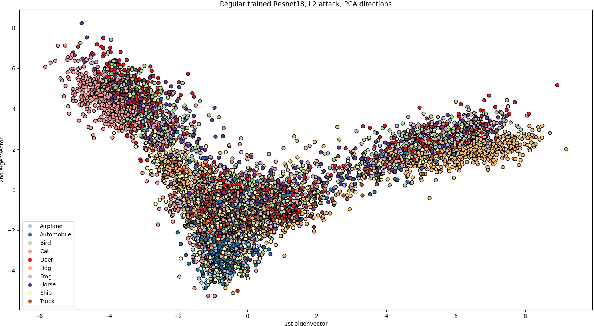
Deep neural networks (DNNs) have gained prominence in various applications, such as classification, recognition, and prediction, prompting increased scrutiny of their properties. A fundamental attribute of traditional DNNs is their vulnerability to modifications in input data, which has resulted in the investigation of adversarial attacks. These attacks manipulate the data in order to mislead a DNN. This study aims to challenge the efficacy and generalization of contemporary defense mechanisms against adversarial attacks. Specifically, we explore the hypothesis proposed by Ilyas et. al, which posits that DNN image features can be either robust or non-robust, with adversarial attacks targeting the latter. This hypothesis suggests that training a DNN on a dataset consisting solely of robust features should produce a model resistant to adversarial attacks. However, our experiments demonstrate that this is not universally true. To gain further insights into our findings, we analyze the impact of adversarial attack norms on DNN representations, focusing on samples subjected to $L_2$ and $L_{\infty}$ norm attacks. Further, we employ canonical correlation analysis, visualize the representations, and calculate the mean distance between these representations and various DNN decision boundaries. Our results reveal a significant difference between $L_2$ and $L_{\infty}$ norms, which could provide insights into the potential dangers posed by $L_{\infty}$ norm attacks, previously underestimated by the research community.