 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tiny LVLM-eHub: Early Multimodal Experiments with Bard
Aug 07, 2023

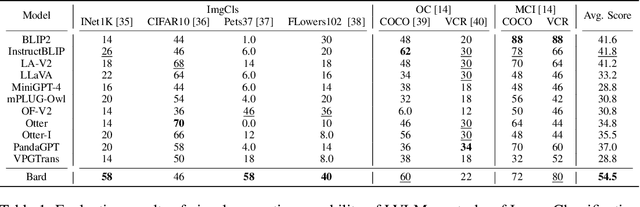
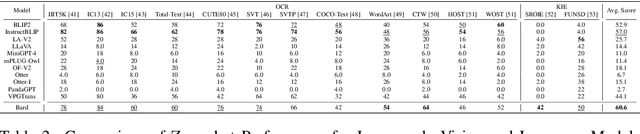
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated significant progress in tackling complex multimodal tasks. Among these cutting-edge developments, Google's Bard stands out for its remarkable multimodal capabilities, promoting comprehensive comprehension and reasoning across various domains. This work presents an early and holistic evaluation of LVLMs' multimodal abilities, with a particular focus on Bard, by proposing a lightweight variant of LVLM-eHub, named Tiny LVLM-eHub. In comparison to the vanilla version, Tiny LVLM-eHub possesses several appealing properties. Firstly, it provides a systematic assessment of six categories of multimodal capabilities, including visual perception, visual knowledge acquisition, visual reasoning, visual commonsense, object hallucination, and embodied intelligence, through quantitative evaluation of $42$ standard text-related visual benchmarks. Secondly, it conducts an in-depth analysis of LVLMs' predictions using the ChatGPT Ensemble Evaluation (CEE), which leads to a robust and accurate evaluation and exhibits improved alignment with human evaluation compared to the word matching approach. Thirdly, it comprises a mere $2.1$K image-text pairs, facilitating ease of use for practitioners to evaluate their own offline LVLMs. Through extensive experimental analysis, this study demonstrates that Bard outperforms previous LVLMs in most multimodal capabilities except object hallucination, to which Bard is still susceptible. Tiny LVLM-eHub serves as a baseline evaluation for various LVLMs and encourages innovative strategies aimed at advancing multimodal techniques. Our project is publicly available at \url{https://github.com/OpenGVLab/Multi-Modality-Arena}.
Prototype Learning for Out-of-Distribution Polyp Segmentation
Aug 07, 2023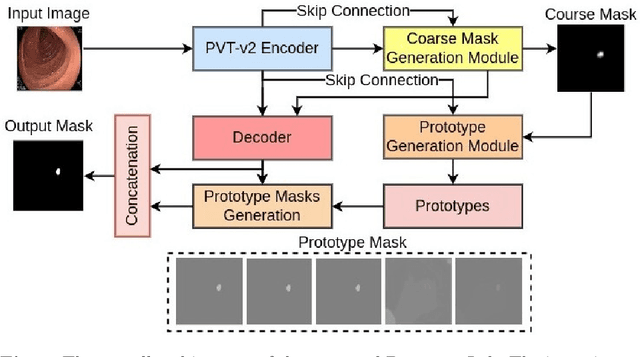
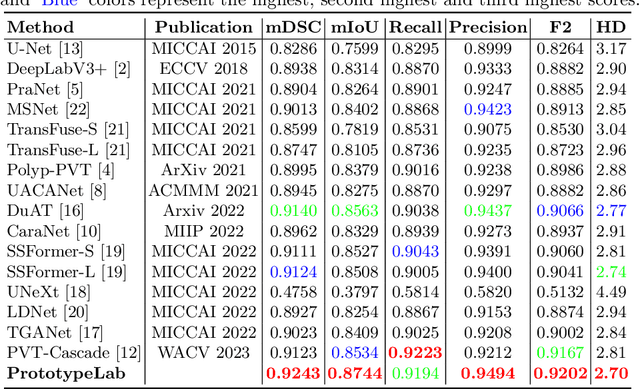
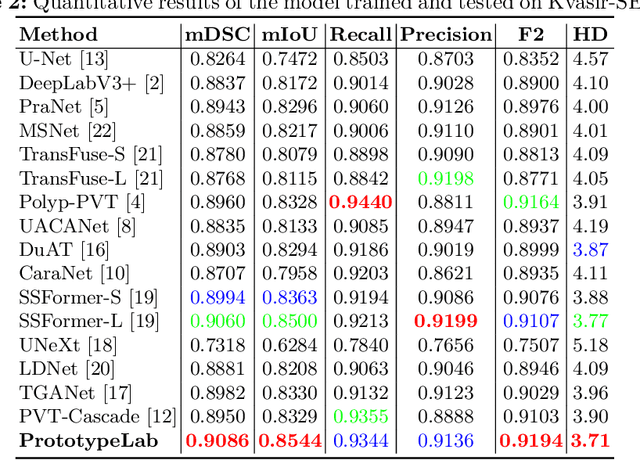
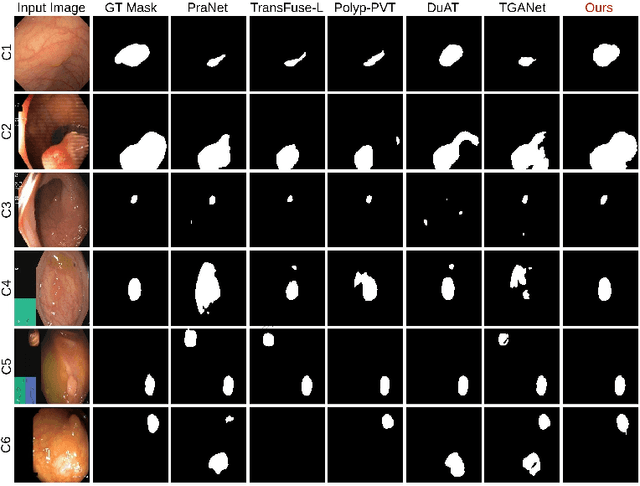
Existing polyp segmentation models from colonoscopy images often fail to provide reliable segmentation results on datasets from different centers, limiting their applicability. Our objective in this study is to create a robust and well-generalized segmentation model named PrototypeLab that can assist in polyp segmentation. To achieve this, we incorporate various lighting modes such as White light imaging (WLI), Blue light imaging (BLI), Linked color imaging (LCI), and Flexible spectral imaging color enhancement (FICE) into our new segmentation model, that learns to create prototypes for each class of object present in the images. These prototypes represent the characteristic features of the objects, such as their shape, texture, color. Our model is designed to perform effectively on out-of-distribution (OOD) datasets from multiple centers. We first generate a coarse mask that is used to learn prototypes for the main object class, which are then employed to generate the final segmentation mask. By using prototypes to represent the main class, our approach handles the variability present in the medical images and generalize well to new data since prototype capture the underlying distribution of the data. PrototypeLab offers a promising solution with a dice coefficient of $\geq$ 90\% and mIoU $\geq$ 85\% with a near real-time processing speed for polyp segmentation. It achieved superior performance on OOD datasets compared to 16 state-of-the-art image segmentation architectures, potentially improving clinical outcomes. Codes are available at https://github.com/xxxxx/PrototypeLab.
Point2Mask: Point-supervised Panoptic Segmentation via Optimal Transport
Aug 03, 2023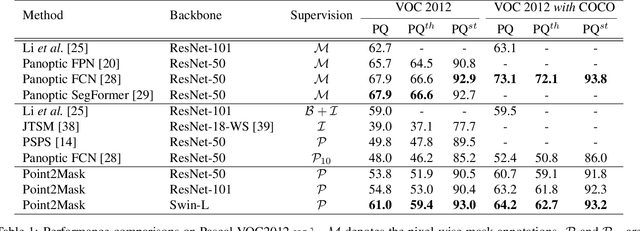
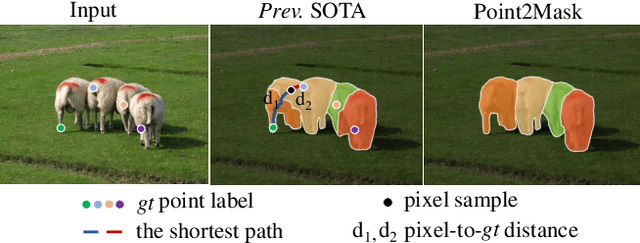
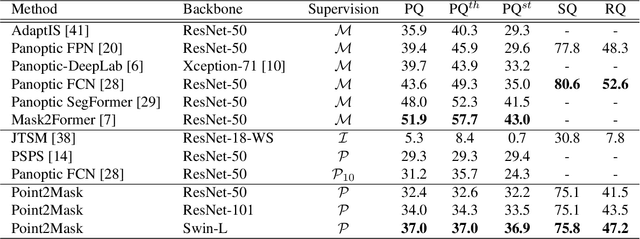
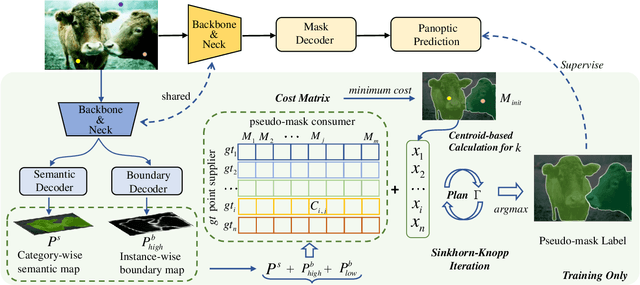
Weakly-supervised image segmentation has recently attracted increasing research attentions, aiming to avoid the expensive pixel-wise labeling. In this paper, we present an effective method, namely Point2Mask, to achieve high-quality panoptic prediction using only a single random point annotation per target for training. Specifically, we formulate the panoptic pseudo-mask generation as an Optimal Transport (OT) problem, where each ground-truth (gt) point label and pixel sample are defined as the label supplier and consumer, respectively. The transportation cost is calculated by the introduced task-oriented maps, which focus on the category-wise and instance-wise differences among the various thing and stuff targets. Furthermore, a centroid-based scheme is proposed to set the accurate unit number for each gt point supplier. Hence, the pseudo-mask generation is converted into finding the optimal transport plan at a globally minimal transportation cost, which can be solved via the Sinkhorn-Knopp Iteration. Experimental results on Pascal VOC and COCO demonstrate the promising performance of our proposed Point2Mask approach to point-supervised panoptic segmentation. Source code is available at: https://github.com/LiWentomng/Point2Mask.
Uni-ControlNet: All-in-One Control to Text-to-Image Diffusion Models
May 25, 2023

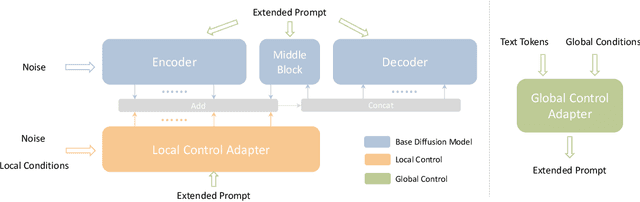
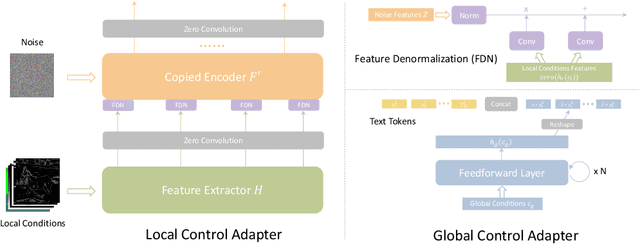
Text-to-Image diffusion models have made tremendous progress over the past two years, enabling the generation of highly realistic images based on open-domain text descriptions. However, despite their success, text descriptions often struggle to adequately convey detailed controls, even when composed of long and complex texts. Moreover, recent studies have also shown that these models face challenges in understanding such complex texts and generating the corresponding images. Therefore, there is a growing need to enable more control modes beyond text description. In this paper, we introduce Uni-ControlNet, a novel approach that allows for the simultaneous utilization of different local controls (e.g., edge maps, depth map, segmentation masks) and global controls (e.g., CLIP image embeddings) in a flexible and composable manner within one model. Unlike existing methods, Uni-ControlNet only requires the fine-tuning of two additional adapters upon frozen pre-trained text-to-image diffusion models, eliminating the huge cost of training from scratch. Moreover, thanks to some dedicated adapter designs, Uni-ControlNet only necessitates a constant number (i.e., 2) of adapters, regardless of the number of local or global controls used. This not only reduces the fine-tuning costs and model size, making it more suitable for real-world deployment, but also facilitate composability of different conditions. Through both quantitative and qualitative comparisons, Uni-ControlNet demonstrates its superiority over existing methods in terms of controllability, generation quality and composability. Code is available at \url{https://github.com/ShihaoZhaoZSH/Uni-ControlNet}.
Scene Text Recognition with Image-Text Matching-guided Dictionary
May 08, 2023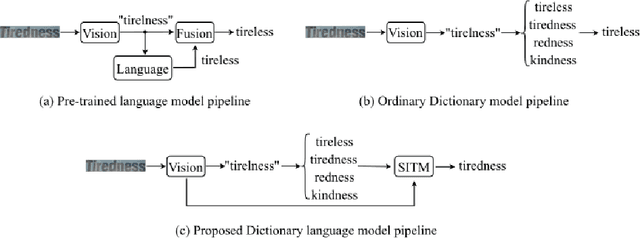
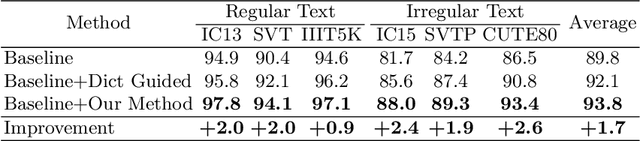
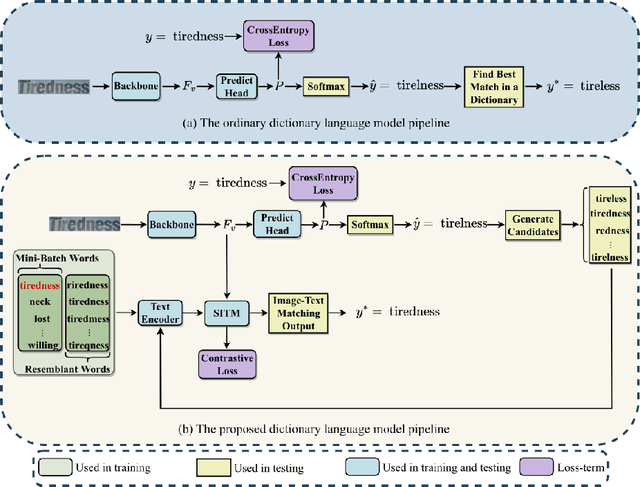
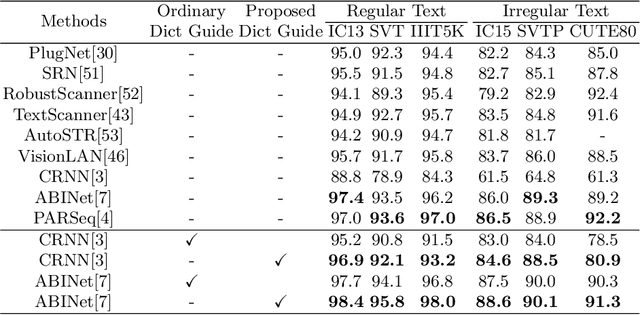
Employing a dictionary can efficiently rectify the deviation between the visual prediction and the ground truth in scene text recognition methods. However, the independence of the dictionary on the visual features may lead to incorrect rectification of accurate visual predictions. In this paper, we propose a new dictionary language model leveraging the Scene Image-Text Matching(SITM) network, which avoids the drawbacks of the explicit dictionary language model: 1) the independence of the visual features; 2) noisy choice in candidates etc. The SITM network accomplishes this by using Image-Text Contrastive (ITC) Learning to match an image with its corresponding text among candidates in the inference stage. ITC is widely used in vision-language learning to pull the positive image-text pair closer in feature space. Inspired by ITC, the SITM network combines the visual features and the text features of all candidates to identify the candidate with the minimum distance in the feature space. Our lexicon method achieves better results(93.8\% accuracy) than the ordinary method results(92.1\% accuracy) on six mainstream benchmarks. Additionally, we integrate our method with ABINet and establish new state-of-the-art results on several benchmarks.
Multi-Focus Image Fusion Based on Spatial Frequency(SF) and Consistency Verification(CV) in DCT Domain
May 18, 2023Multi-focus is a technique of focusing on different aspects of a particular object or scene. Wireless Visual Sensor Networks (WVSN) use multi-focus image fusion, which combines two or more images to create a more accurate output image that describes the scene better than any individual input image. WVSN has various applications, including video surveillance, monitoring, and tracking. Therefore, a high-level analysis of these networks can benefit Biometrics. This paper introduces an algorithm that utilizes discrete cosine transform (DCT) standards to fuse multi-focus images in WVSNs. The spatial frequency (SF) of the corresponding blocks from the source images determines the fusion criterion. The blocks with higher spatial frequencies make up the DCT presentation of the fused image, and the Consistency Verification (CV) procedure is used to enhance the output image quality. The proposed fusion method was tested on multiple pairs of multi-focus images coded on JPEG standard to evaluate the fusion performance, and the results indicate that it improves the visual quality of the output image and outperforms other DCT-based techniques.
Boosting 3-DoF Ground-to-Satellite Camera Localization Accuracy via Geometry-Guided Cross-View Transformer
Jul 19, 2023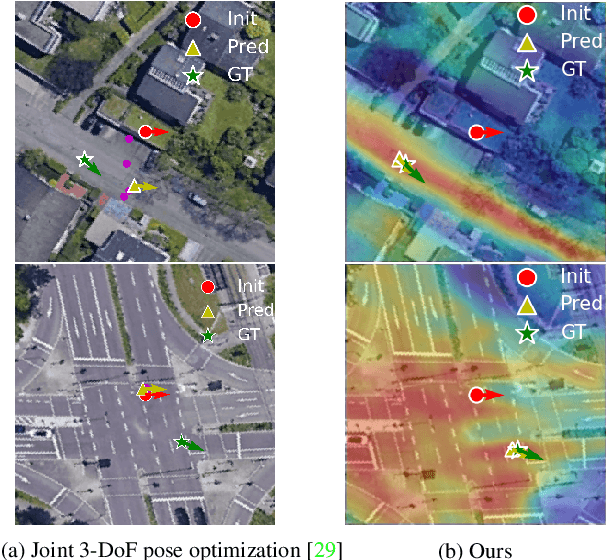
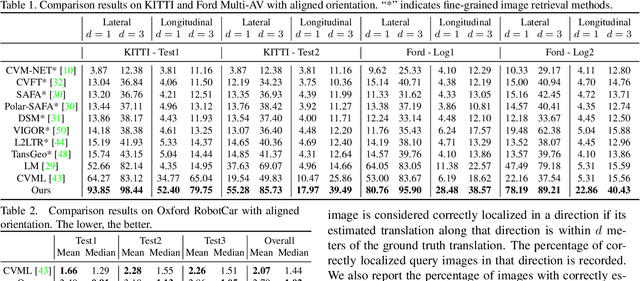
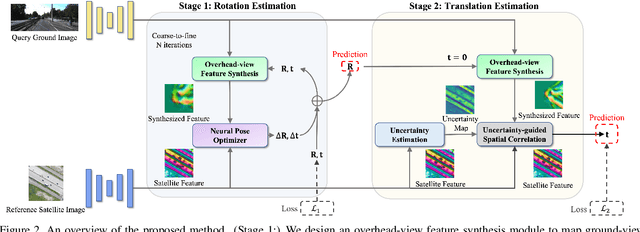
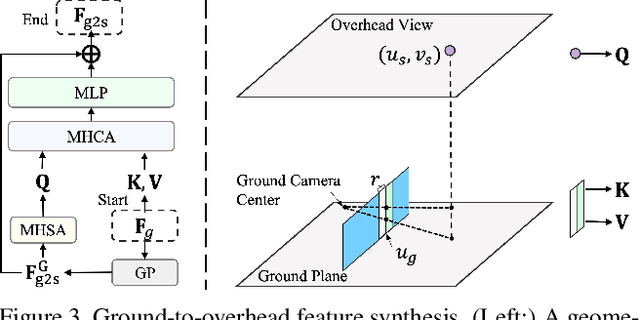
Image retrieval-based cross-view localization methods often lead to very coarse camera pose estimation, due to the limited sampling density of the database satellite images. In this paper, we propose a method to increase the accuracy of a ground camera's location and orientation by estimating the relative rotation and translation between the ground-level image and its matched/retrieved satellite image. Our approach designs a geometry-guided cross-view transformer that combines the benefits of conventional geometry and learnable cross-view transformers to map the ground-view observations to an overhead view. Given the synthesized overhead view and observed satellite feature maps, we construct a neural pose optimizer with strong global information embedding ability to estimate the relative rotation between them. After aligning their rotations, we develop an uncertainty-guided spatial correlation to generate a probability map of the vehicle locations, from which the relative translation can be determined. Experimental results demonstrate that our method significantly outperforms the state-of-the-art. Notably, the likelihood of restricting the vehicle lateral pose to be within 1m of its Ground Truth (GT) value on the cross-view KITTI dataset has been improved from $35.54\%$ to $76.44\%$, and the likelihood of restricting the vehicle orientation to be within $1^{\circ}$ of its GT value has been improved from $19.64\%$ to $99.10\%$.
NeRT: Implicit Neural Representations for General Unsupervised Turbulence Mitigation
Aug 01, 2023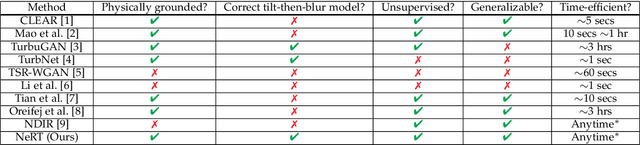
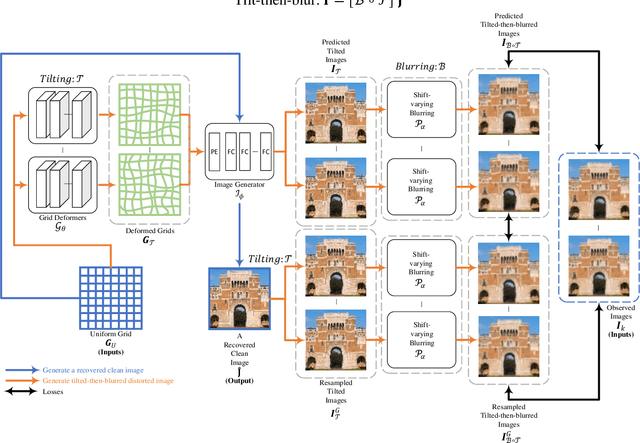

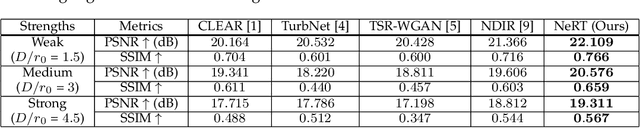
The atmospheric and water turbulence mitigation problems have emerged as challenging inverse problems in computer vision and optics communities over the years. However, current methods either rely heavily on the quality of the training dataset or fail to generalize over various scenarios, such as static scenes, dynamic scenes, and text reconstructions. We propose a general implicit neural representation for unsupervised atmospheric and water turbulence mitigation (NeRT). NeRT leverages the implicit neural representations and the physically correct tilt-then-blur turbulence model to reconstruct the clean, undistorted image, given only dozens of distorted input images. Moreover, we show that NeRT outperforms the state-of-the-art through various qualitative and quantitative evaluations of atmospheric and water turbulence datasets. Furthermore, we demonstrate the ability of NeRT to eliminate uncontrolled turbulence from real-world environments. Lastly, we incorporate NeRT into continuously captured video sequences and demonstrate $48 \times$ speedup.
DINO-CXR: A self supervised method based on vision transformer for chest X-ray classification
Aug 01, 2023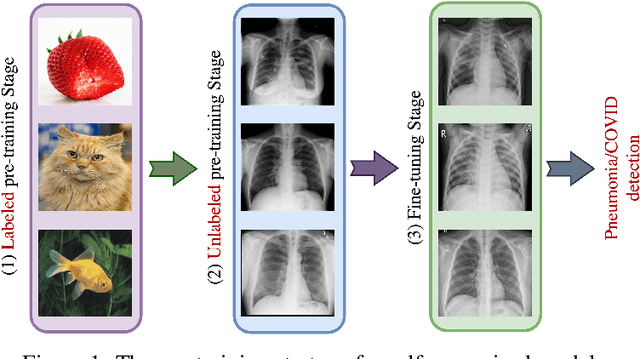
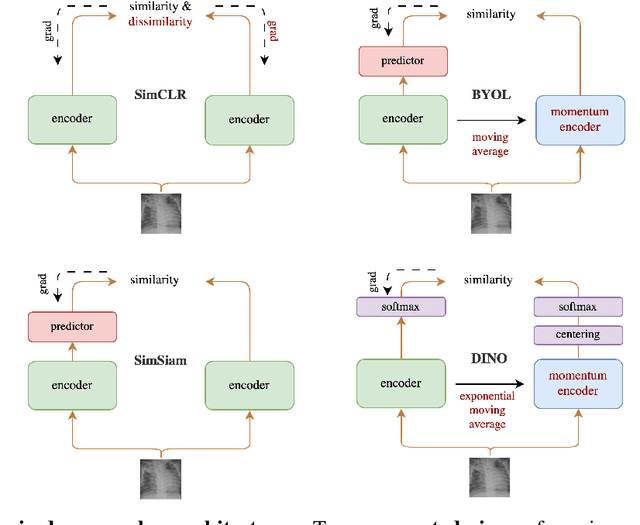
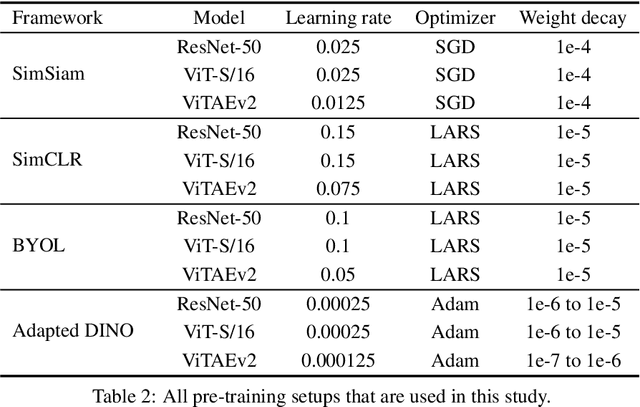
The limited availability of labeled chest X-ray datasets is a significant bottleneck in the development of medical imaging methods. Self-supervised learning (SSL) can mitigate this problem by training models on unlabeled data. Furthermore, self-supervised pretraining has yielded promising results in visual recognition of natural images but has not been given much consideration in medical image analysis. In this work, we propose a self-supervised method, DINO-CXR, which is a novel adaptation of a self-supervised method, DINO, based on a vision transformer for chest X-ray classification. A comparative analysis is performed to show the effectiveness of the proposed method for both pneumonia and COVID-19 detection. Through a quantitative analysis, it is also shown that the proposed method outperforms state-of-the-art methods in terms of accuracy and achieves comparable results in terms of AUC and F-1 score while requiring significantly less labeled data.
Secure Deep-JSCC Against Multiple Eavesdroppers
Aug 05, 2023In this paper, a generalization of deep learning-aided joint source channel coding (Deep-JSCC) approach to secure communications is studied. We propose an end-to-end (E2E) learning-based approach for secure communication against multiple eavesdroppers over complex-valued fading channels. Both scenarios of colluding and non-colluding eavesdroppers are studied. For the colluding strategy, eavesdroppers share their logits to collaboratively infer private attributes based on ensemble learning method, while for the non-colluding setup they act alone. The goal is to prevent eavesdroppers from inferring private (sensitive) information about the transmitted images, while delivering the images to a legitimate receiver with minimum distortion. By generalizing the ideas of privacy funnel and wiretap channel coding, the trade-off between the image recovery at the legitimate node and the information leakage to the eavesdroppers is characterized. To solve this secrecy funnel framework, we implement deep neural networks (DNNs) to realize a data-driven secure communication scheme, without relying on a specific data distribution. Simulations over CIFAR-10 dataset verifies the secrecy-utility trade-off. Adversarial accuracy of eavesdroppers are also studied over Rayleigh fading, Nakagami-m, and AWGN channels to verify the generalization of the proposed scheme. Our experiments show that employing the proposed secure neural encoding can decrease the adversarial accuracy by 28%.