 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based Visual Counterfactual Explanations -- Towards Systematic Quantitative Evaluation
Aug 11, 2023


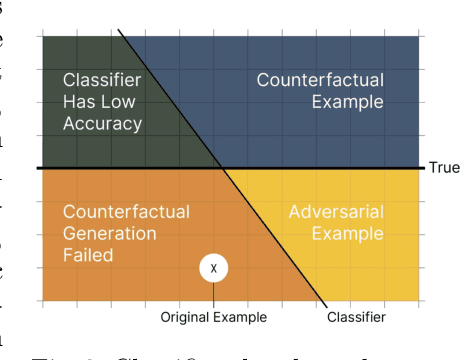
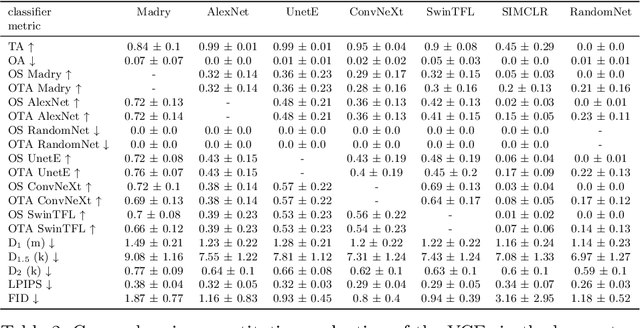
Latest methods for visual counterfactual explanations (VCE) harness the power of deep generative models to synthesize new examples of high-dimensional images of impressive quality. However, it is currently difficult to compare the performance of these VCE methods as the evaluation procedures largely vary and often boil down to visual inspection of individual examples and small scale user studies. In this work, we propose a framework for systematic, quantitative evaluation of the VCE methods and a minimal set of metrics to be used. We use this framework to explore the effects of certain crucial design choices in the latest diffusion-based generative models for VCEs of natural image classification (ImageNet). We conduct a battery of ablation-like experiments, generating thousands of VCEs for a suite of classifiers of various complexity, accuracy and robustness. Our findings suggest multiple directions for future advancements and improvements of VCE methods. By sharing our methodology and our approach to tackle the computational challenges of such a study on a limited hardware setup (including the complete code base), we offer a valuable guidance for researchers in the field fostering consistency and transparency in the assessment of counterfactual explanations.
Denoising Diffusion Models for Plug-and-Play Image Restoration
May 15, 2023
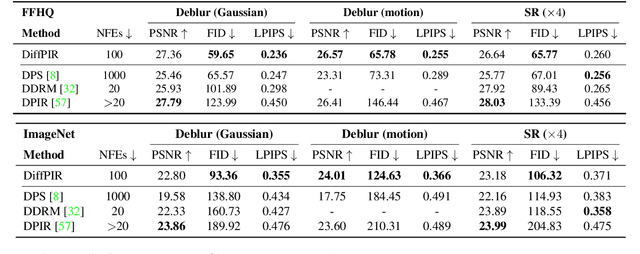


Plug-and-play Image Restoration (IR) has been widely recognized as a flexible and interpretable method for solving various inverse problems by utilizing any off-the-shelf denoiser as the implicit image prior. However, most existing methods focus on discriminative Gaussian denoisers. Although diffusion models have shown impressive performance for high-quality image synthesis, their potential to serve as a generative denoiser prior to the plug-and-play IR methods remains to be further explored. While several other attempts have been made to adopt diffusion models for image restoration, they either fail to achieve satisfactory results or typically require an unacceptable number of Neural Function Evaluations (NFEs) during inference. This paper proposes DiffPIR, which integrates the traditional plug-and-play method into the diffusion sampling framework. Compared to plug-and-play IR methods that rely on discriminative Gaussian denoisers, DiffPIR is expected to inherit the generative ability of diffusion models. Experimental results on three representative IR tasks, including super-resolution, image deblurring, and inpainting, demonstrate that DiffPIR achieves state-of-the-art performance on both the FFHQ and ImageNet datasets in terms of reconstruction faithfulness and perceptual quality with no more than 100 NFEs. The source code is available at {\url{https://github.com/yuanzhi-zhu/DiffPIR}}
Image storage on synthetic DNA using compressive autoencoders and DNA-adapted entropy coders
Jun 22, 2023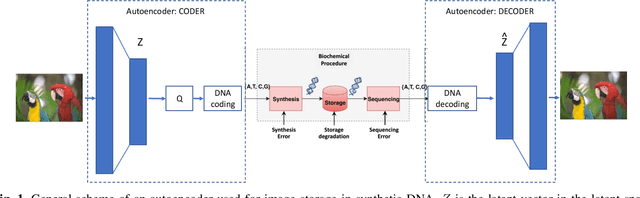
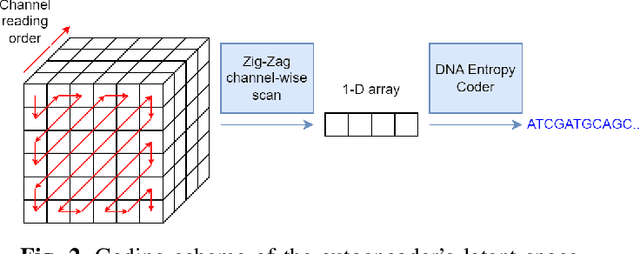
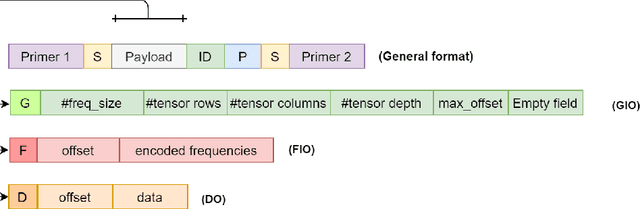
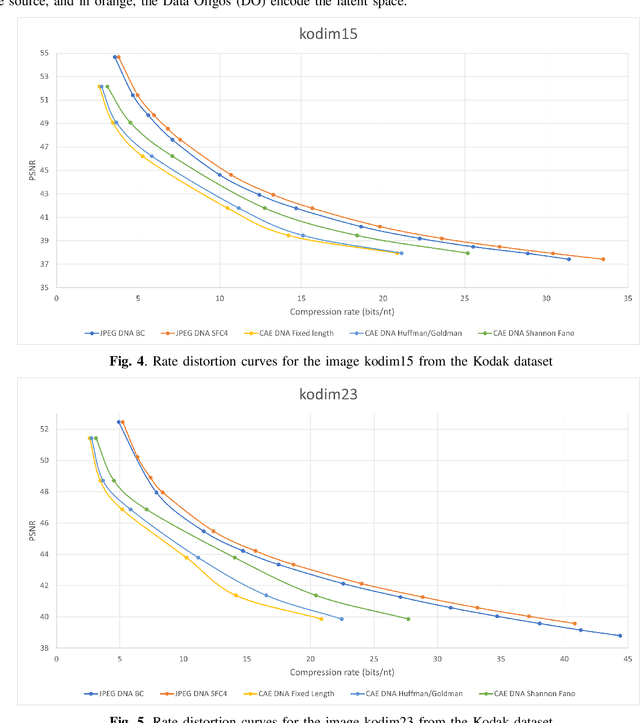
Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (rarely accessed data), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are now considered as serious candidates for this new kind of storage. This paper presents some results on lossy image compression methods based on convolutional autoencoders adapted to DNA data storage, with synthetic DNA-adapted entropic and fixed-length codes. The model architectures presented here have been designed to efficiently compress images, encode them into a quaternary code, and finally store them into synthetic DNA molecules. This work also aims at making the compression models better fit the problematics that we encounter when storing data into DNA, namely the fact that the DNA writing, storing and reading methods are error prone processes. The main take aways of this kind of compressive autoencoder are our latent space quantization and the different DNA adapted entropy coders used to encode the quantized latent space, which are an improvement over the fixed length DNA adapted coders that were previously used.
* arXiv admin note: substantial text overlap with arXiv:2203.09981
Planting a SEED of Vision in Large Language Model
Jul 16, 2023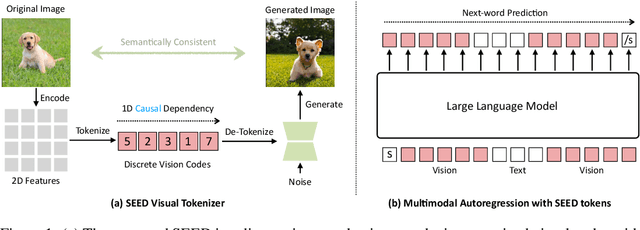


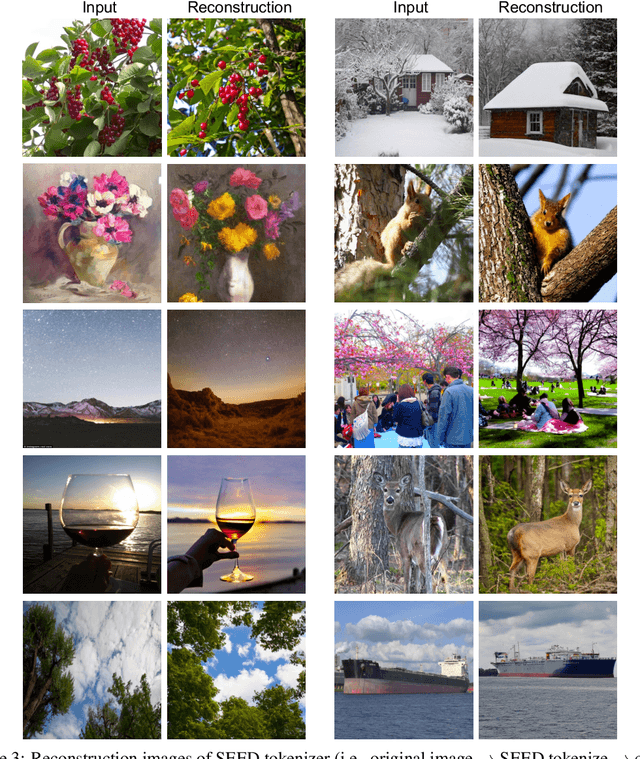
We present SEED, an elaborate image tokenizer that empowers Large Language Models (LLMs) with the emergent ability to SEE and Draw at the same time. Research on image tokenizers has previously reached an impasse, as frameworks employing quantized visual tokens have lost prominence due to subpar performance and convergence in multimodal comprehension (compared to BLIP-2, etc.) or generation (compared to Stable Diffusion, etc.). Despite the limitations, we remain confident in its natural capacity to unify visual and textual representations, facilitating scalable multimodal training with LLM's original recipe. In this study, we identify two crucial principles for the architecture and training of SEED that effectively ease subsequent alignment with LLMs. (1) Image tokens should be independent of 2D physical patch positions and instead be produced with a 1D causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should capture high-level semantics consistent with the degree of semantic abstraction in words, and be optimized for both discriminativeness and reconstruction during the tokenizer training phase. As a result, the off-the-shelf LLM is able to perform both image-to-text and text-to-image generation by incorporating our SEED through efficient LoRA tuning. Comprehensive multimodal pretraining and instruction tuning, which may yield improved results, are reserved for future investigation. This version of SEED was trained in 5.7 days using only 64 V100 GPUs and 5M publicly available image-text pairs. Our preliminary study emphasizes the great potential of discrete visual tokens in versatile multimodal LLMs and the importance of proper image tokenizers in broader research.
Pre-Pruning and Gradient-Dropping Improve Differentially Private Image Classification
Jun 19, 2023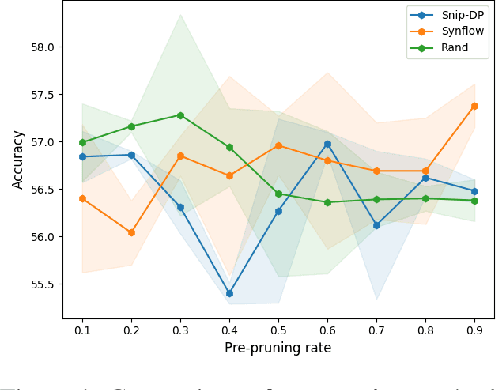
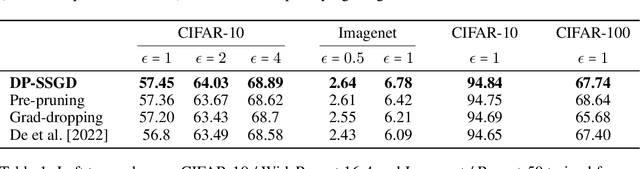
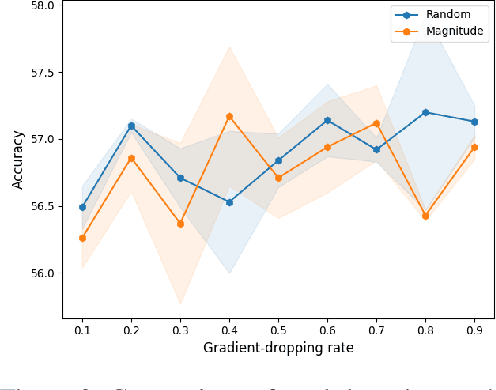
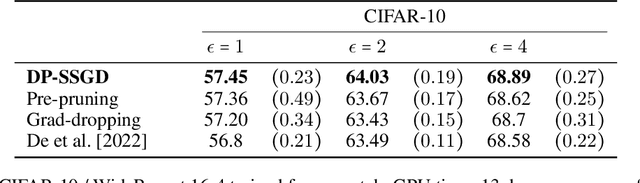
Scalability is a significant challenge when it comes to applying differential privacy to training deep neural networks. The commonly used DP-SGD algorithm struggles to maintain a high level of privacy protection while achieving high accuracy on even moderately sized models. To tackle this challenge, we take advantage of the fact that neural networks are overparameterized, which allows us to improve neural network training with differential privacy. Specifically, we introduce a new training paradigm that uses \textit{pre-pruning} and \textit{gradient-dropping} to reduce the parameter space and improve scalability. The process starts with pre-pruning the parameters of the original network to obtain a smaller model that is then trained with DP-SGD. During training, less important gradients are dropped, and only selected gradients are updated. Our training paradigm introduces a tension between the rates of pre-pruning and gradient-dropping, privacy loss, and classification accuracy. Too much pre-pruning and gradient-dropping reduces the model's capacity and worsens accuracy, while training a smaller model requires less privacy budget for achieving good accuracy. We evaluate the interplay between these factors and demonstrate the effectiveness of our training paradigm for both training from scratch and fine-tuning pre-trained networks on several benchmark image classification datasets. The tools can also be readily incorporated into existing training paradigms.
Ill-Posed Image Reconstruction Without an Image Prior
Apr 12, 2023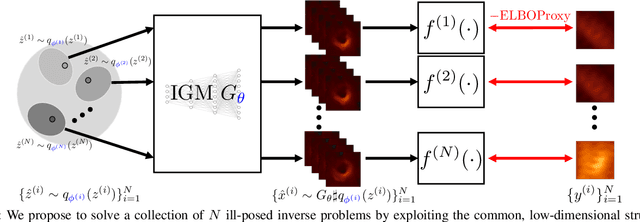
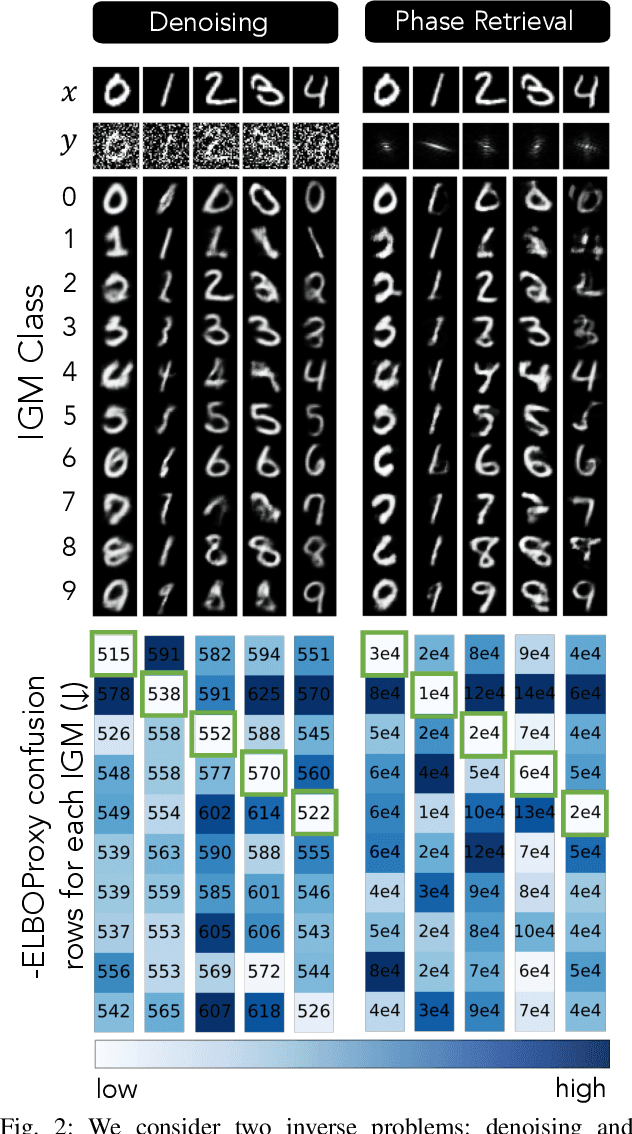
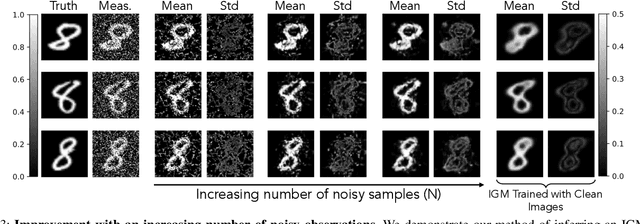

We consider solving ill-posed imaging inverse problems without access to an image prior or ground-truth examples. An overarching challenge in these inverse problems is that an infinite number of images, including many that are implausible, are consistent with the observed measurements. Thus, image priors are required to reduce the space of possible solutions to more desireable reconstructions. However, in many applications it is difficult or potentially impossible to obtain example images to construct an image prior. Hence inaccurate priors are often used, which inevitably result in biased solutions. Rather than solving an inverse problem using priors that encode the spatial structure of any one image, we propose to solve a set of inverse problems jointly by incorporating prior constraints on the collective structure of the underlying images. The key assumption of our work is that the underlying images we aim to reconstruct share common, low-dimensional structure. We show that such a set of inverse problems can be solved simultaneously without the use of a spatial image prior by instead inferring a shared image generator with a low-dimensional latent space. The parameters of the generator and latent embeddings are found by maximizing a proxy for the Evidence Lower Bound (ELBO). Once identified, the generator and latent embeddings can be combined to provide reconstructed images for each inverse problem. The framework we propose can handle general forward model corruptions, and we show that measurements derived from only a small number of ground-truth images ($\leqslant 150$) are sufficient for "prior-free" image reconstruction. We demonstrate our approach on a variety of convex and non-convex inverse problems, ranging from denoising, phase retrieval, and black hole video reconstruction.
Image Captioners Sometimes Tell More Than Images They See
May 04, 2023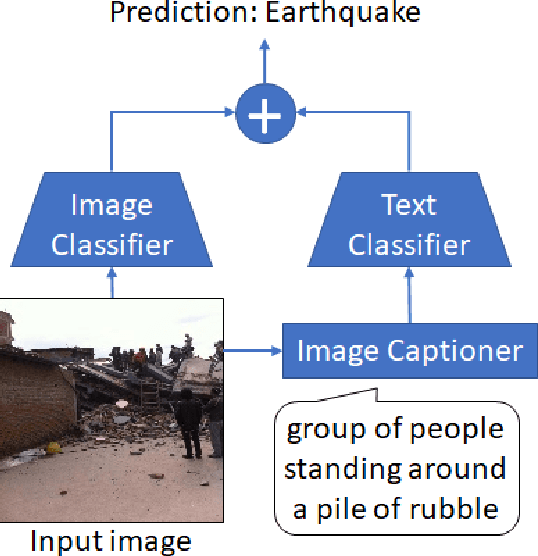
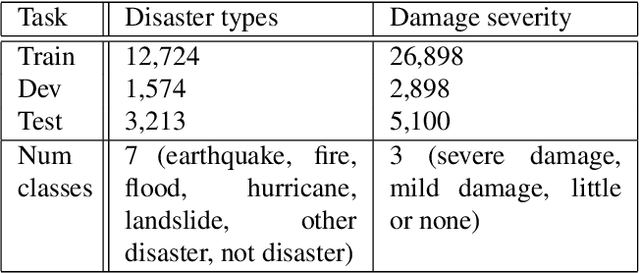

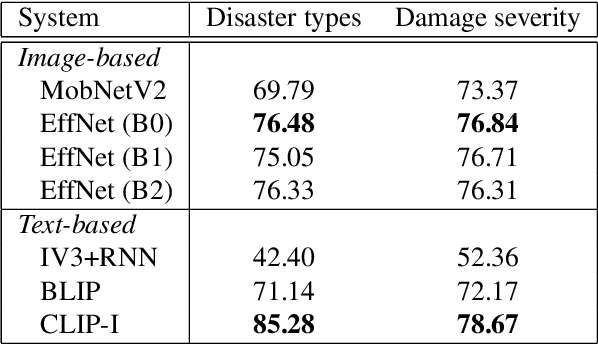
Image captioning, a.k.a. "image-to-text," which generates descriptive text from given images, has been rapidly developing throughout the era of deep learning. To what extent is the information in the original image preserved in the descriptive text generated by an image captioner? To answer that question, we have performed experiments involving the classification of images from descriptive text alone, without referring to the images at all, and compared results with those from standard image-based classifiers. We have evaluate several image captioning models with respect to a disaster image classification task, CrisisNLP, and show that descriptive text classifiers can sometimes achieve higher accuracy than standard image-based classifiers. Further, we show that fusing an image-based classifier with a descriptive text classifier can provide improvement in accuracy.
Advancing Volumetric Medical Image Segmentation via Global-Local Masked Autoencoder
Jun 15, 2023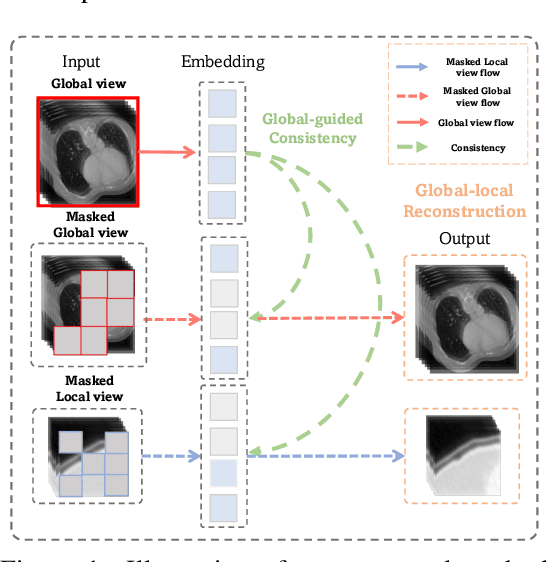
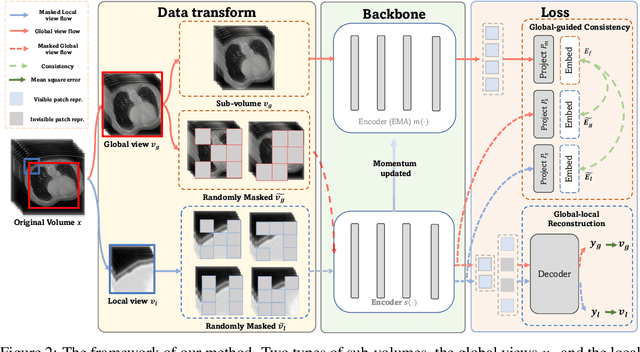
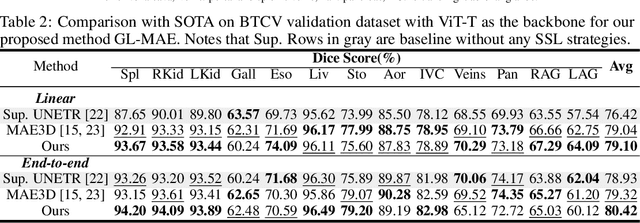
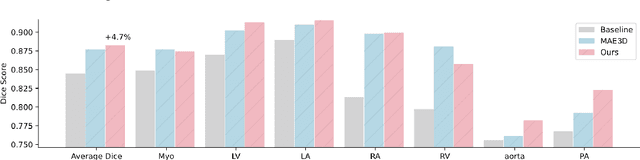
Masked autoencoder (MAE) has emerged as a promising self-supervised pretraining technique to enhance the representation learning of a neural network without human intervention. To adapt MAE onto volumetric medical images, existing methods exhibit two challenges: first, the global information crucial for understanding the clinical context of the holistic data is lacked; second, there was no guarantee of stabilizing the representations learned from the randomly masked inputs. To tackle these limitations, we proposed Global-Local Masked AutoEncoder (GL-MAE), a simple yet effective self-supervised pre-training strategy. GL-MAE reconstructs both the masked global and masked local volumes, which enables learning the essential local details as well as the global context. We further introduced global-to-global consistency and local-to-global correspondence via global-guided consistency learning to enhance and stabilize the representation learning of the masked volumes. Finetuning results on multiple datasets illustrate the superiority of our method over other state-of-the-art self-supervised algorithms, demonstrating its effectiveness on versatile volumetric medical image segmentation tasks, even when annotations are scarce. Codes and models will be released upon acceptance.
Mitigating Inappropriateness in Image Generation: Can there be Value in Reflecting the World's Ugliness?
May 28, 2023
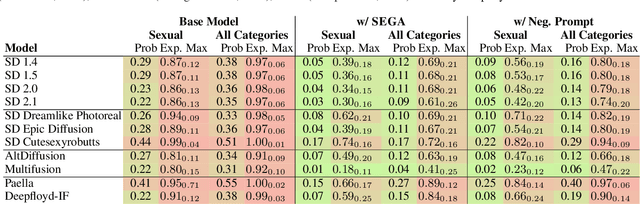

Text-conditioned image generation models have recently achieved astonishing results in image quality and text alignment and are consequently employed in a fast-growing number of applications. Since they are highly data-driven, relying on billion-sized datasets randomly scraped from the web, they also reproduce inappropriate human behavior. Specifically, we demonstrate inappropriate degeneration on a large-scale for various generative text-to-image models, thus motivating the need for monitoring and moderating them at deployment. To this end, we evaluate mitigation strategies at inference to suppress the generation of inappropriate content. Our findings show that we can use models' representations of the world's ugliness to align them with human preferences.
Class Anchor Margin Loss for Content-Based Image Retrieval
Jun 03, 2023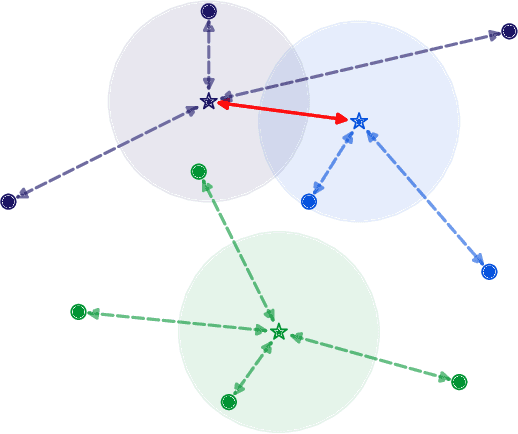
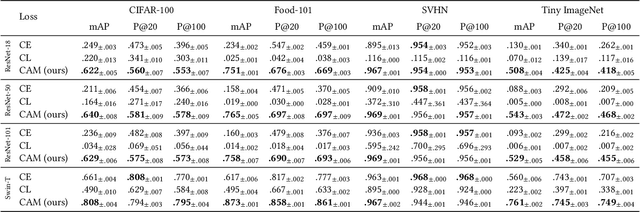
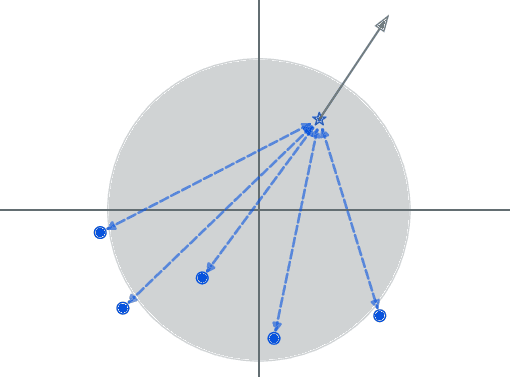
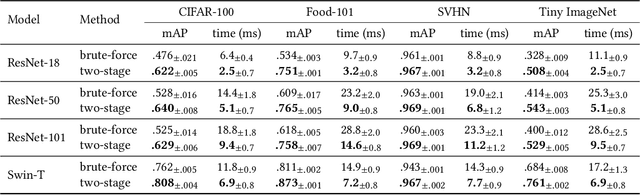
The performance of neural networks in content-based image retrieval (CBIR) is highly influenced by the chosen loss (objective) function. The majority of objective functions for neural models can be divided into metric learning and statistical learning. Metric learning approaches require a pair mining strategy that often lacks efficiency, while statistical learning approaches are not generating highly compact features due to their indirect feature optimization. To this end, we propose a novel repeller-attractor loss that falls in the metric learning paradigm, yet directly optimizes for the L2 metric without the need of generating pairs. Our loss is formed of three components. One leading objective ensures that the learned features are attracted to each designated learnable class anchor. The second loss component regulates the anchors and forces them to be separable by a margin, while the third objective ensures that the anchors do not collapse to zero. Furthermore, we develop a more efficient two-stage retrieval system by harnessing the learned class anchors during the first stage of the retrieval process, eliminating the need of comparing the query with every image in the database. We establish a set of four datasets (CIFAR-100, Food-101, SVHN, and Tiny ImageNet) and evaluate the proposed objective in the context of few-shot and full-set training on the CBIR task, by using both convolutional and transformer architectures. Compared to existing objective functions, our empirical evidence shows that the proposed objective is generating superior and more consistent results.