 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Spatiotemporal Fusion of Satellite Images: A Constrained Convex Optimization Approach
Aug 01, 2023
This paper proposes a novel spatiotemporal (ST) fusion framework for satellite images, named Robust Optimization-based Spatiotemporal Fusion (ROSTF). ST fusion is a promising approach to resolve a trade-off between the temporal and spatial resolution of satellite images. Although many ST fusion methods have been proposed, most of them are not designed to explicitly account for noise in observed images, despite the inevitable influence of noise caused by the measurement equipment and environment. Our ROSTF addresses this challenge by treating the noise removal of the observed images and the estimation of the target high-resolution image as a single optimization problem. Specifically, first, we define observation models for satellite images possibly contaminated with random noise, outliers, and/or missing values, and then introduce certain assumptions that would naturally hold between the observed images and the target high-resolution image. Then, based on these models and assumptions, we formulate the fusion problem as a constrained optimization problem and develop an efficient algorithm based on a preconditioned primal-dual splitting method for solving the problem. The performance of ROSTF was verified using simulated and real data. The results show that ROSTF performs comparably to several state-of-the-art ST fusion methods in noiseless cases and outperforms them in noisy cases.
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023
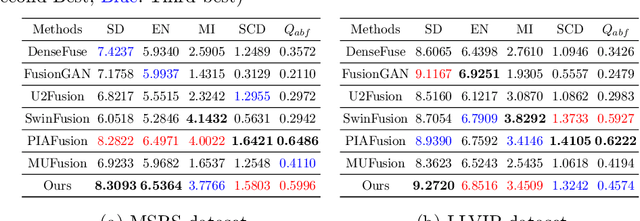
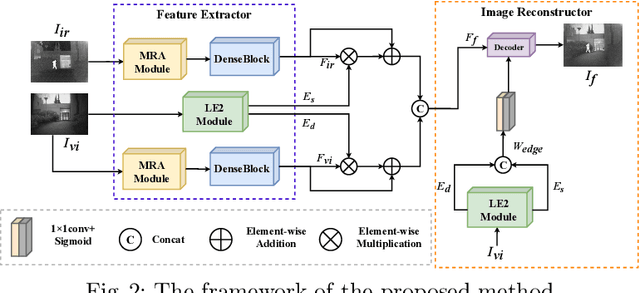
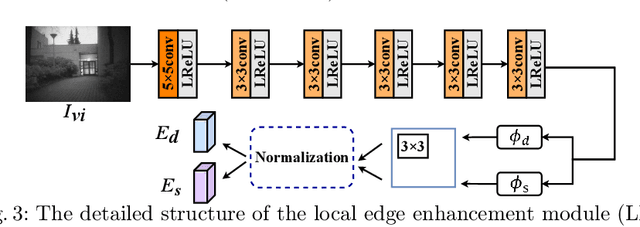
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.
Lightweight Structure-aware Transformer Network for VHR Remote Sensing Image Change Detection
Jun 03, 2023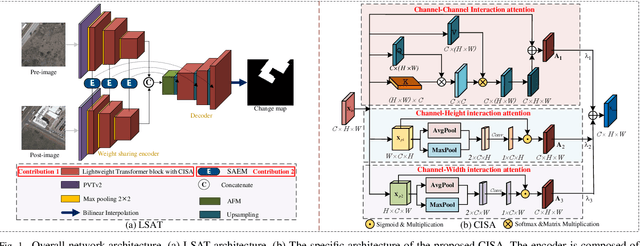
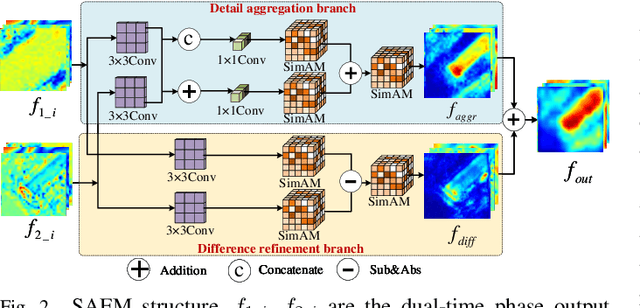
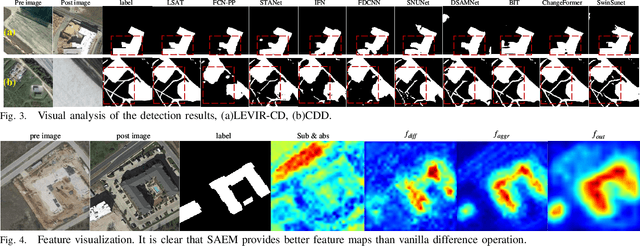
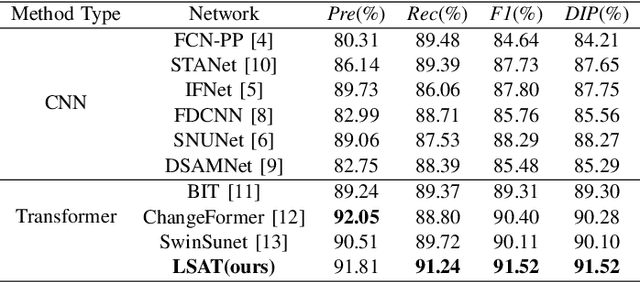
Popular Transformer networks have been successfully applied to remote sensing (RS) image change detection (CD) identifications and achieve better results than most convolutional neural networks (CNNs), but they still suffer from two main problems. First, the computational complexity of the Transformer grows quadratically with the increase of image spatial resolution, which is unfavorable to very high-resolution (VHR) RS images. Second, these popular Transformer networks tend to ignore the importance of fine-grained features, which results in poor edge integrity and internal tightness for largely changed objects and leads to the loss of small changed objects. To address the above issues, this Letter proposes a Lightweight Structure-aware Transformer (LSAT) network for RS image CD. The proposed LSAT has two advantages. First, a Cross-dimension Interactive Self-attention (CISA) module with linear complexity is designed to replace the vanilla self-attention in visual Transformer, which effectively reduces the computational complexity while improving the feature representation ability of the proposed LSAT. Second, a Structure-aware Enhancement Module (SAEM) is designed to enhance difference features and edge detail information, which can achieve double enhancement by difference refinement and detail aggregation so as to obtain fine-grained features of bi-temporal RS images. Experimental results show that the proposed LSAT achieves significant improvement in detection accuracy and offers a better tradeoff between accuracy and computational costs than most state-of-the-art CD methods for VHR RS images.
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
May 25, 2023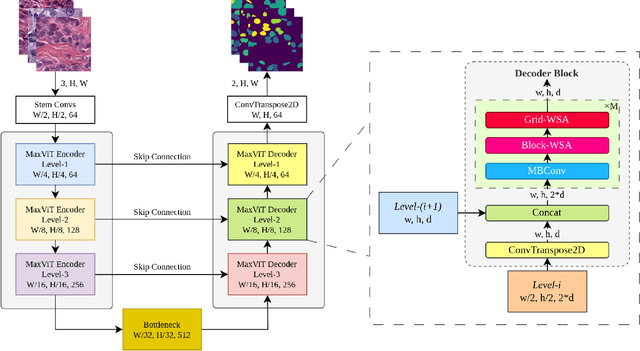
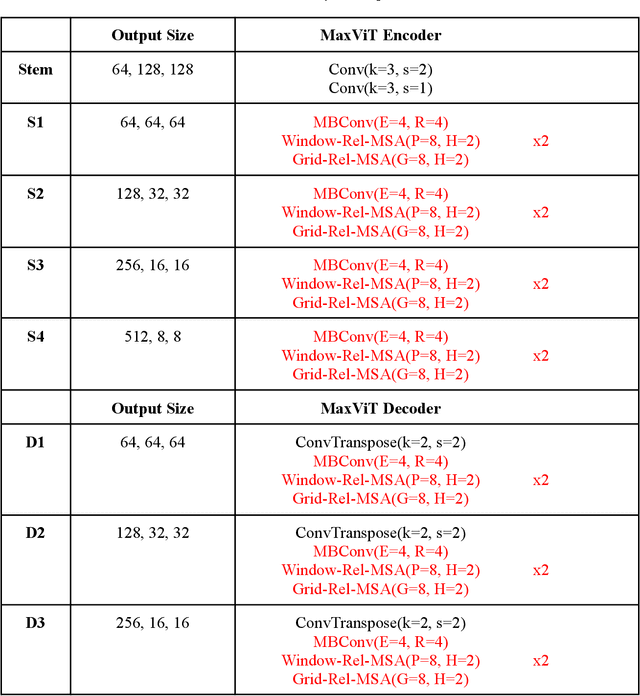
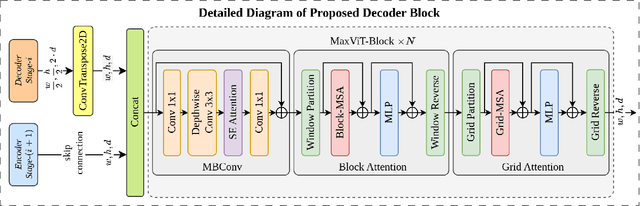
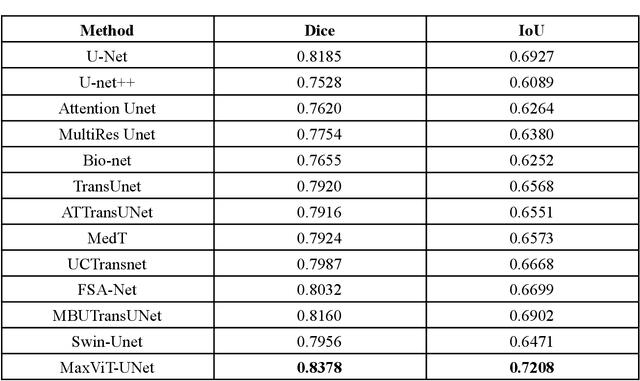
Convolutional neural networks have made significant strides in medical image analysis in recent years. However, the local nature of the convolution operator inhibits the CNNs from capturing global and long-range interactions. Recently, Transformers have gained popularity in the computer vision community and also medical image segmentation. But scalability issues of self-attention mechanism and lack of the CNN like inductive bias have limited their adoption. In this work, we present MaxViT-UNet, an Encoder-Decoder based hybrid vision transformer for medical image segmentation. The proposed hybrid decoder, also based on MaxViT-block, is designed to harness the power of convolution and self-attention mechanism at each decoding stage with minimal computational burden. The multi-axis self-attention in each decoder stage helps in differentiating between the object and background regions much more efficiently. The hybrid decoder block initially fuses the lower level features upsampled via transpose convolution, with skip-connection features coming from hybrid encoder, then fused features are refined using multi-axis attention mechanism. The proposed decoder block is repeated multiple times to accurately segment the nuclei regions. Experimental results on MoNuSeg dataset proves the effectiveness of the proposed technique. Our MaxViT-UNet outperformed the previous CNN only (UNet) and Transformer only (Swin-UNet) techniques by a large margin of 2.36% and 5.31% on Dice metric respectively.
Multi-scale Multi-site Renal Microvascular Structures Segmentation for Whole Slide Imaging in Renal Pathology
Aug 10, 2023Segmentation of microvascular structures, such as arterioles, venules, and capillaries, from human kidney whole slide images (WSI) has become a focal point in renal pathology. Current manual segmentation techniques are time-consuming and not feasible for large-scale digital pathology images. While deep learning-based methods offer a solution for automatic segmentation, most suffer from a limitation: they are designed for and restricted to training on single-site, single-scale data. In this paper, we present Omni-Seg, a novel single dynamic network method that capitalizes on multi-site, multi-scale training data. Unique to our approach, we utilize partially labeled images, where only one tissue type is labeled per training image, to segment microvascular structures. We train a singular deep network using images from two datasets, HuBMAP and NEPTUNE, across different magnifications (40x, 20x, 10x, and 5x). Experimental results indicate that Omni-Seg outperforms in terms of both the Dice Similarity Coefficient (DSC) and Intersection over Union (IoU). Our proposed method provides renal pathologists with a powerful computational tool for the quantitative analysis of renal microvascular structures.
Local-Global Information Interaction Debiasing for Dynamic Scene Graph Generation
Aug 10, 2023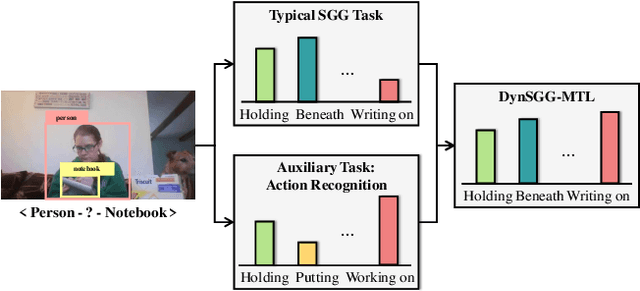
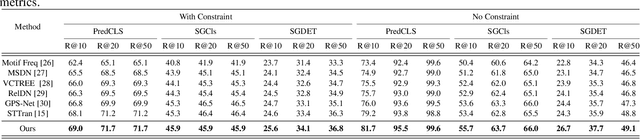
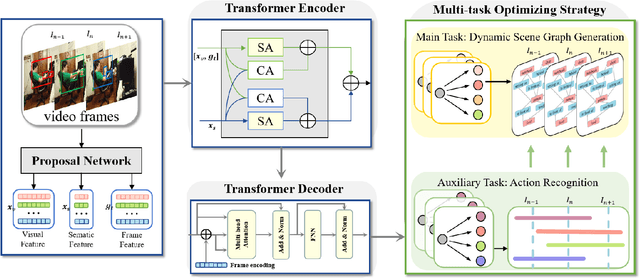
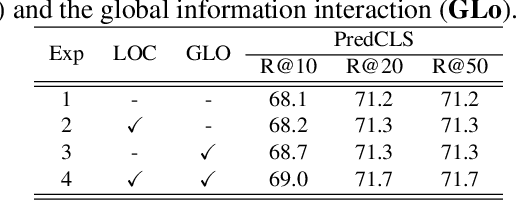
The task of dynamic scene graph generation (DynSGG) aims to generate scene graphs for given videos, which involves modeling the spatial-temporal information in the video. However, due to the long-tailed distribution of samples in the dataset, previous DynSGG models fail to predict the tail predicates. We argue that this phenomenon is due to previous methods that only pay attention to the local spatial-temporal information and neglect the consistency of multiple frames. To solve this problem, we propose a novel DynSGG model based on multi-task learning, DynSGG-MTL, which introduces the local interaction information and global human-action interaction information. The interaction between objects and frame features makes the model more fully understand the visual context of the single image. Long-temporal human actions supervise the model to generate multiple scene graphs that conform to the global constraints and avoid the model being unable to learn the tail predicates. Extensive experiments on Action Genome dataset demonstrate the efficacy of our proposed framework, which not only improves the dynamic scene graph generation but also alleviates the long-tail problem.
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
Jun 05, 2023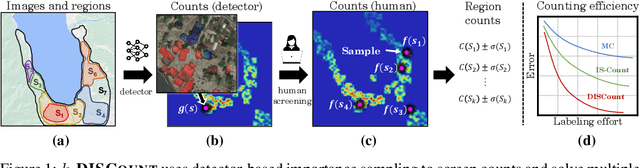
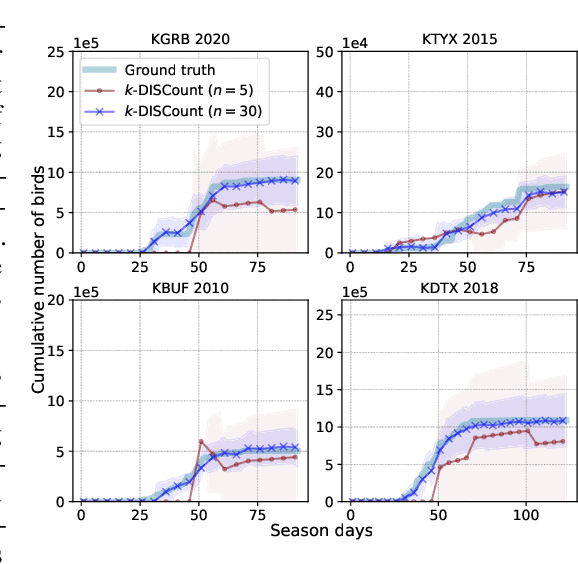
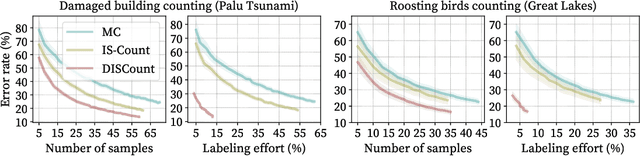
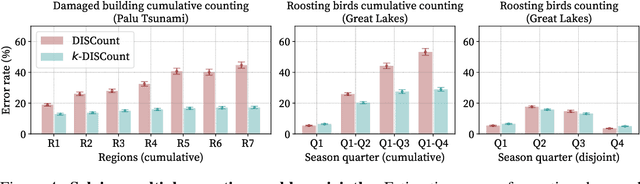
Many modern applications use computer vision to detect and count objects in massive image collections. However, when the detection task is very difficult or in the presence of domain shifts, the counts may be inaccurate even with significant investments in training data and model development. We propose DISCount -- a detector-based importance sampling framework for counting in large image collections that integrates an imperfect detector with human-in-the-loop screening to produce unbiased estimates of counts. We propose techniques for solving counting problems over multiple spatial or temporal regions using a small number of screened samples and estimate confidence intervals. This enables end-users to stop screening when estimates are sufficiently accurate, which is often the goal in a scientific study. On the technical side we develop variance reduction techniques based on control variates and prove the (conditional) unbiasedness of the estimators. DISCount leads to a 9-12x reduction in the labeling costs over naive screening for tasks we consider, such as counting birds in radar imagery or estimating damaged buildings in satellite imagery, and also surpasses alternative covariate-based screening approaches in efficiency.
Denoising Diffusion Models for Plug-and-Play Image Restoration
May 15, 2023
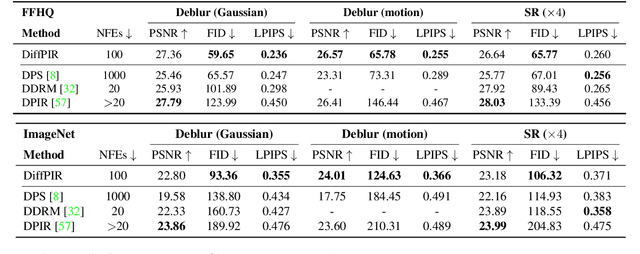


Plug-and-play Image Restoration (IR) has been widely recognized as a flexible and interpretable method for solving various inverse problems by utilizing any off-the-shelf denoiser as the implicit image prior. However, most existing methods focus on discriminative Gaussian denoisers. Although diffusion models have shown impressive performance for high-quality image synthesis, their potential to serve as a generative denoiser prior to the plug-and-play IR methods remains to be further explored. While several other attempts have been made to adopt diffusion models for image restoration, they either fail to achieve satisfactory results or typically require an unacceptable number of Neural Function Evaluations (NFEs) during inference. This paper proposes DiffPIR, which integrates the traditional plug-and-play method into the diffusion sampling framework. Compared to plug-and-play IR methods that rely on discriminative Gaussian denoisers, DiffPIR is expected to inherit the generative ability of diffusion models. Experimental results on three representative IR tasks, including super-resolution, image deblurring, and inpainting, demonstrate that DiffPIR achieves state-of-the-art performance on both the FFHQ and ImageNet datasets in terms of reconstruction faithfulness and perceptual quality with no more than 100 NFEs. The source code is available at {\url{https://github.com/yuanzhi-zhu/DiffPIR}}
Isomer: Isomerous Transformer for Zero-shot Video Object Segmentation
Aug 13, 2023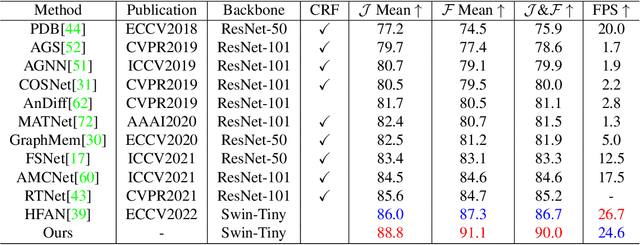
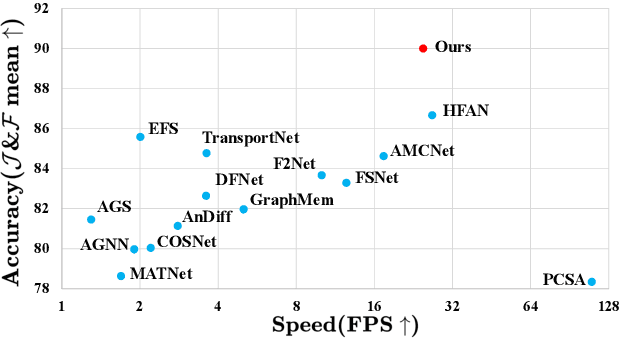

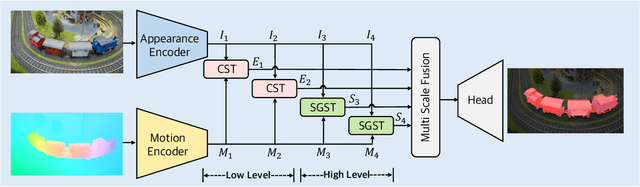
Recent leading zero-shot video object segmentation (ZVOS) works devote to integrating appearance and motion information by elaborately designing feature fusion modules and identically applying them in multiple feature stages. Our preliminary experiments show that with the strong long-range dependency modeling capacity of Transformer, simply concatenating the two modality features and feeding them to vanilla Transformers for feature fusion can distinctly benefit the performance but at a cost of heavy computation. Through further empirical analysis, we find that attention dependencies learned in Transformer in different stages exhibit completely different properties: global query-independent dependency in the low-level stages and semantic-specific dependency in the high-level stages. Motivated by the observations, we propose two Transformer variants: i) Context-Sharing Transformer (CST) that learns the global-shared contextual information within image frames with a lightweight computation. ii) Semantic Gathering-Scattering Transformer (SGST) that models the semantic correlation separately for the foreground and background and reduces the computation cost with a soft token merging mechanism. We apply CST and SGST for low-level and high-level feature fusions, respectively, formulating a level-isomerous Transformer framework for ZVOS task. Compared with the baseline that uses vanilla Transformers for multi-stage fusion, ours significantly increase the speed by 13 times and achieves new state-of-the-art ZVOS performance. Code is available at https://github.com/DLUT-yyc/Isomer.
SimMatchV2: Semi-Supervised Learning with Graph Consistency
Aug 13, 2023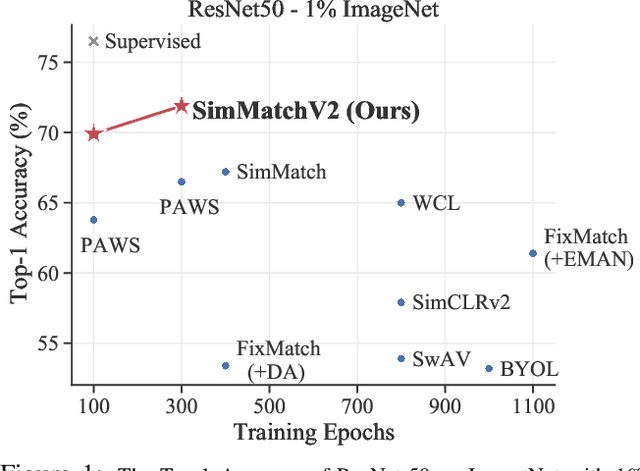
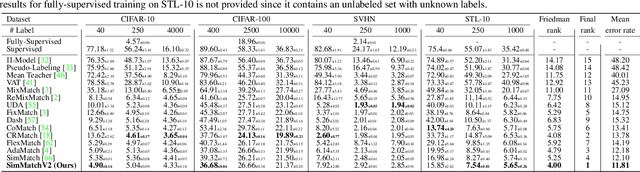
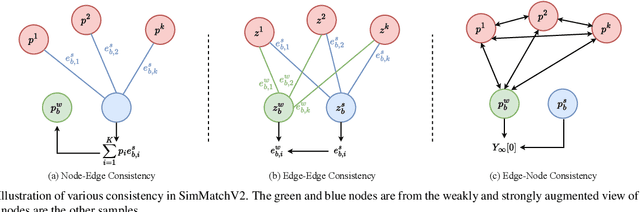
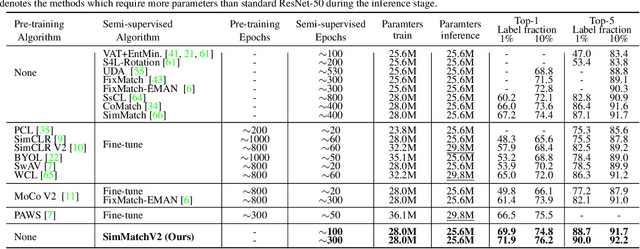
Semi-Supervised image classification is one of the most fundamental problem in computer vision, which significantly reduces the need for human labor. In this paper, we introduce a new semi-supervised learning algorithm - SimMatchV2, which formulates various consistency regularizations between labeled and unlabeled data from the graph perspective. In SimMatchV2, we regard the augmented view of a sample as a node, which consists of a label and its corresponding representation. Different nodes are connected with the edges, which are measured by the similarity of the node representations. Inspired by the message passing and node classification in graph theory, we propose four types of consistencies, namely 1) node-node consistency, 2) node-edge consistency, 3) edge-edge consistency, and 4) edge-node consistency. We also uncover that a simple feature normalization can reduce the gaps of the feature norm between different augmented views, significantly improving the performance of SimMatchV2. Our SimMatchV2 has been validated on multiple semi-supervised learning benchmarks. Notably, with ResNet-50 as our backbone and 300 epochs of training, SimMatchV2 achieves 71.9\% and 76.2\% Top-1 Accuracy with 1\% and 10\% labeled examples on ImageNet, which significantly outperforms the previous methods and achieves state-of-the-art performance. Code and pre-trained models are available at \href{https://github.com/mingkai-zheng/SimMatchV2}{https://github.com/mingkai-zheng/SimMatchV2}.