 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Downstream-agnostic Adversarial Examples
Aug 14, 2023
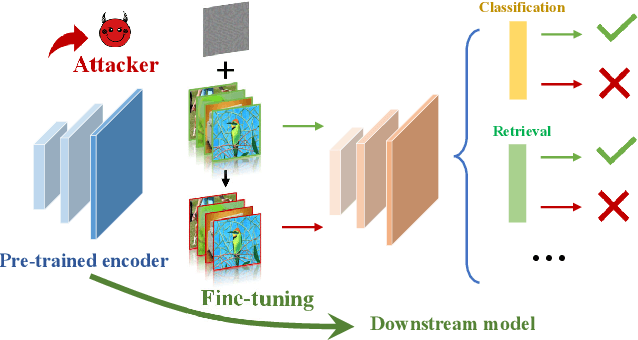
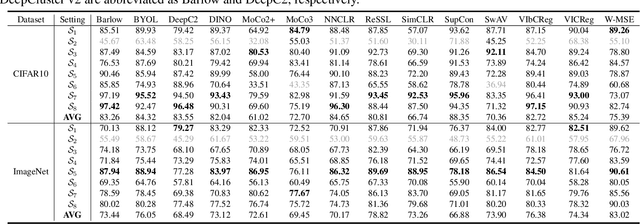
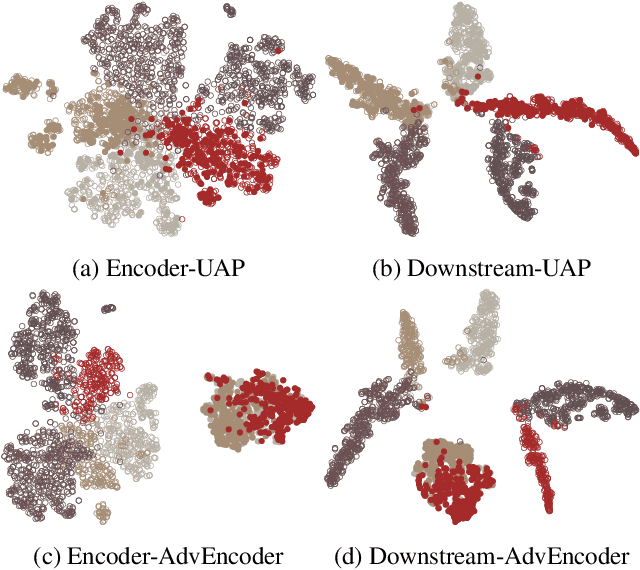
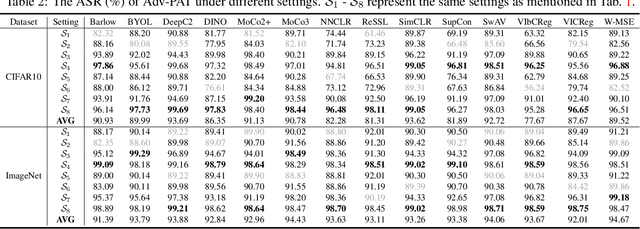
Self-supervised learning usually uses a large amount of unlabeled data to pre-train an encoder which can be used as a general-purpose feature extractor, such that downstream users only need to perform fine-tuning operations to enjoy the benefit of "large model". Despite this promising prospect, the security of pre-trained encoder has not been thoroughly investigated yet, especially when the pre-trained encoder is publicly available for commercial use. In this paper, we propose AdvEncoder, the first framework for generating downstream-agnostic universal adversarial examples based on the pre-trained encoder. AdvEncoder aims to construct a universal adversarial perturbation or patch for a set of natural images that can fool all the downstream tasks inheriting the victim pre-trained encoder. Unlike traditional adversarial example works, the pre-trained encoder only outputs feature vectors rather than classification labels. Therefore, we first exploit the high frequency component information of the image to guide the generation of adversarial examples. Then we design a generative attack framework to construct adversarial perturbations/patches by learning the distribution of the attack surrogate dataset to improve their attack success rates and transferability. Our results show that an attacker can successfully attack downstream tasks without knowing either the pre-training dataset or the downstream dataset. We also tailor four defenses for pre-trained encoders, the results of which further prove the attack ability of AdvEncoder.
U-Turn Diffusion
Aug 14, 2023We present a comprehensive examination of score-based diffusion models of AI for generating synthetic images. These models hinge upon a dynamic auxiliary time mechanism driven by stochastic differential equations, wherein the score function is acquired from input images. Our investigation unveils a criterion for evaluating efficiency of the score-based diffusion models: the power of the generative process depends on the ability to de-construct fast correlations during the reverse/de-noising phase. To improve the quality of the produced synthetic images, we introduce an approach coined "U-Turn Diffusion". The U-Turn Diffusion technique starts with the standard forward diffusion process, albeit with a condensed duration compared to conventional settings. Subsequently, we execute the standard reverse dynamics, initialized with the concluding configuration from the forward process. This U-Turn Diffusion procedure, combining forward, U-turn, and reverse processes, creates a synthetic image approximating an independent and identically distributed (i.i.d.) sample from the probability distribution implicitly described via input samples. To analyze relevant time scales we employ various analytical tools, including auto-correlation analysis, weighted norm of the score-function analysis, and Kolmogorov-Smirnov Gaussianity test. The tools guide us to establishing that the Kernel Intersection Distance, a metric comparing the quality of synthetic samples with real data samples, is minimized at the optimal U-turn time.
Exploring Effective Priors and Efficient Models for Weakly-Supervised Change Detection
Jul 22, 2023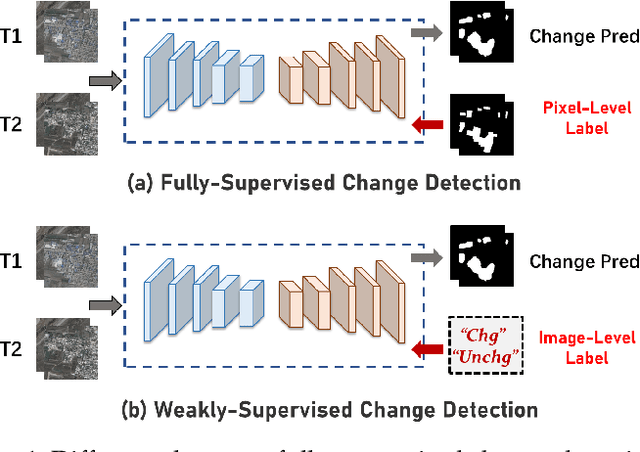
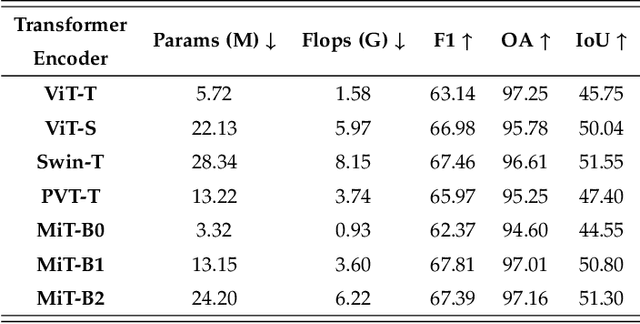

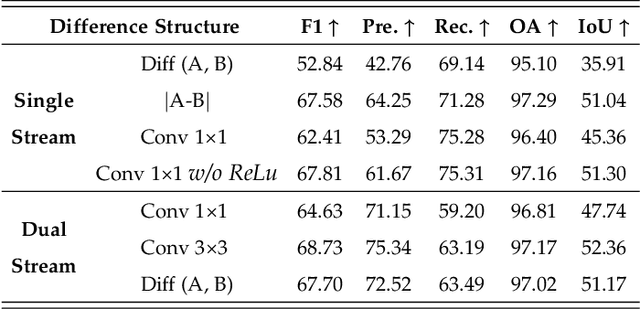
Weakly-supervised change detection (WSCD) aims to detect pixel-level changes with only image-level annotations. Owing to its label efficiency, WSCD is drawing increasing attention recently. However, current WSCD methods often encounter the challenge of change missing and fabricating, i.e., the inconsistency between image-level annotations and pixel-level predictions. Specifically, change missing refer to the situation that the WSCD model fails to predict any changed pixels, even though the image-level label indicates changed, and vice versa for change fabricating. To address this challenge, in this work, we leverage global-scale and local-scale priors in WSCD and propose two components: a Dilated Prior (DP) decoder and a Label Gated (LG) constraint. The DP decoder decodes samples with the changed image-level label, skips samples with the unchanged label, and replaces them with an all-unchanged pixel-level label. The LG constraint is derived from the correspondence between changed representations and image-level labels, penalizing the model when it mispredicts the change status. Additionally, we develop TransWCD, a simple yet powerful transformer-based model, showcasing the potential of weakly-supervised learning in change detection. By integrating the DP decoder and LG constraint into TransWCD, we form TransWCD-DL. Our proposed TransWCD and TransWCD-DL achieve significant +6.33% and +9.55% F1 score improvements over the state-of-the-art methods on the WHU-CD dataset, respectively. Some performance metrics even exceed several fully-supervised change detection (FSCD) competitors. Code will be available at https://github.com/zhenghuizhao/TransWCD.
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 05, 2023
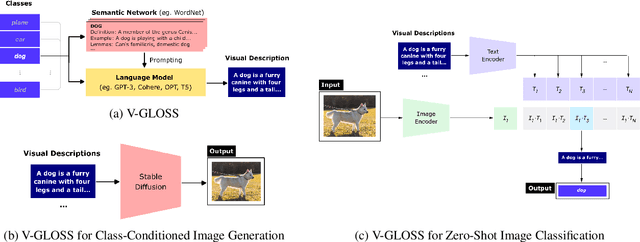

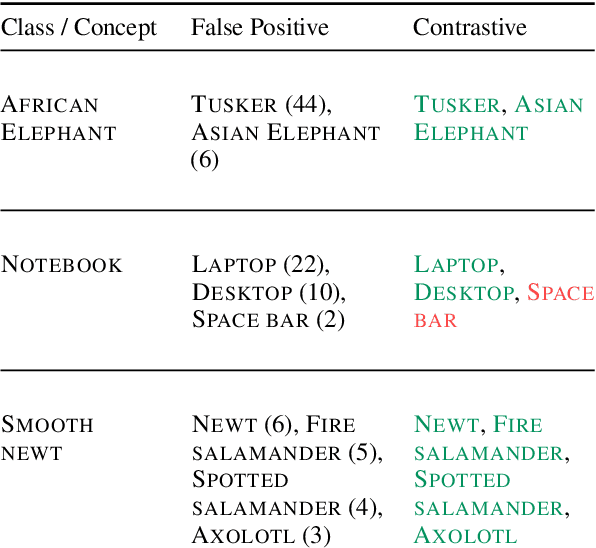
Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.
Distributionally Robust Optimization and Invariant Representation Learning for Addressing Subgroup Underrepresentation: Mechanisms and Limitations
Aug 12, 2023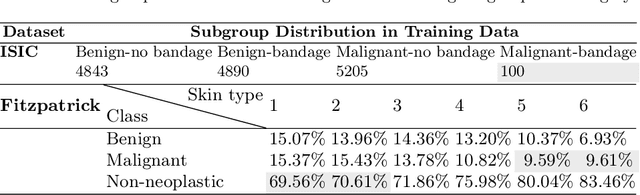
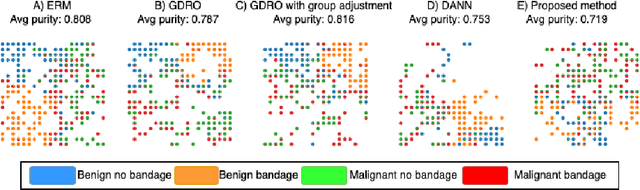
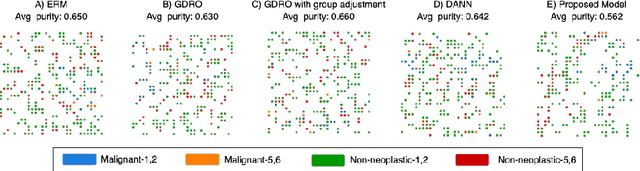
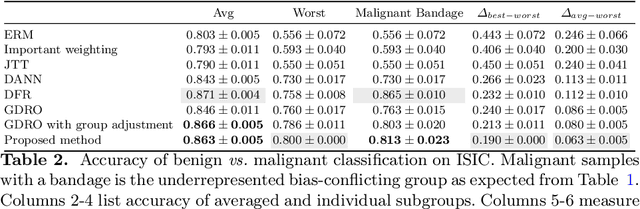
Spurious correlation caused by subgroup underrepresentation has received increasing attention as a source of bias that can be perpetuated by deep neural networks (DNNs). Distributionally robust optimization has shown success in addressing this bias, although the underlying working mechanism mostly relies on upweighting under-performing samples as surrogates for those underrepresented in data. At the same time, while invariant representation learning has been a powerful choice for removing nuisance-sensitive features, it has been little considered in settings where spurious correlations are caused by significant underrepresentation of subgroups. In this paper, we take the first step to better understand and improve the mechanisms for debiasing spurious correlation due to subgroup underrepresentation in medical image classification. Through a comprehensive evaluation study, we first show that 1) generalized reweighting of under-performing samples can be problematic when bias is not the only cause for poor performance, while 2) naive invariant representation learning suffers from spurious correlations itself. We then present a novel approach that leverages robust optimization to facilitate the learning of invariant representations at the presence of spurious correlations. Finetuned classifiers utilizing such representation demonstrated improved abilities to reduce subgroup performance disparity, while maintaining high average and worst-group performance.
PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
Aug 13, 2023
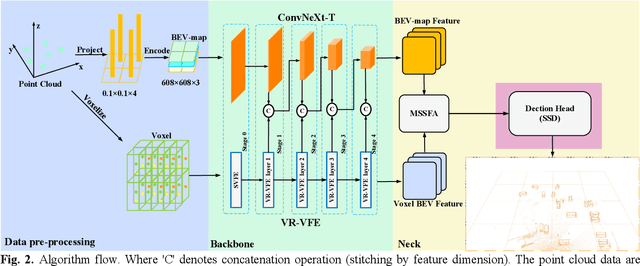
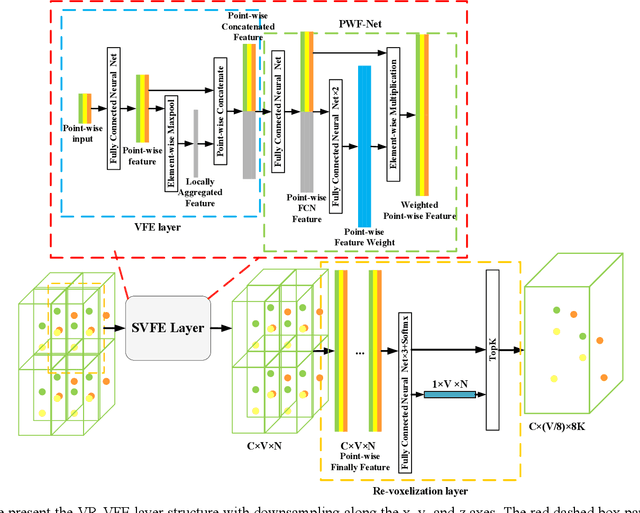
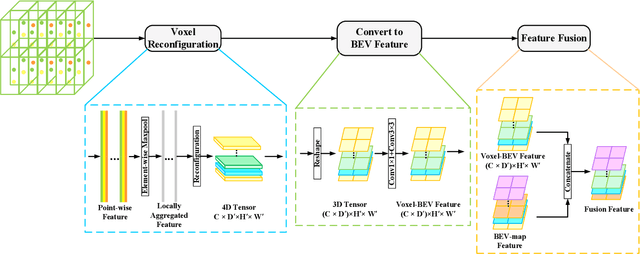
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.
ARAI-MVSNet: A multi-view stereo depth estimation network with adaptive depth range and depth interval
Aug 17, 2023Multi-View Stereo~(MVS) is a fundamental problem in geometric computer vision which aims to reconstruct a scene using multi-view images with known camera parameters. However, the mainstream approaches represent the scene with a fixed all-pixel depth range and equal depth interval partition, which will result in inadequate utilization of depth planes and imprecise depth estimation. In this paper, we present a novel multi-stage coarse-to-fine framework to achieve adaptive all-pixel depth range and depth interval. We predict a coarse depth map in the first stage, then an Adaptive Depth Range Prediction module is proposed in the second stage to zoom in the scene by leveraging the reference image and the obtained depth map in the first stage and predict a more accurate all-pixel depth range for the following stages. In the third and fourth stages, we propose an Adaptive Depth Interval Adjustment module to achieve adaptive variable interval partition for pixel-wise depth range. The depth interval distribution in this module is normalized by Z-score, which can allocate dense depth hypothesis planes around the potential ground truth depth value and vice versa to achieve more accurate depth estimation. Extensive experiments on four widely used benchmark datasets~(DTU, TnT, BlendedMVS, ETH 3D) demonstrate that our model achieves state-of-the-art performance and yields competitive generalization ability. Particularly, our method achieves the highest Acc and Overall on the DTU dataset, while attaining the highest Recall and $F_{1}$-score on the Tanks and Temples intermediate and advanced dataset. Moreover, our method also achieves the lowest $e_{1}$ and $e_{3}$ on the BlendedMVS dataset and the highest Acc and $F_{1}$-score on the ETH 3D dataset, surpassing all listed methods.Project website: https://github.com/zs670980918/ARAI-MVSNet
Federated Model Aggregation via Self-Supervised Priors for Highly Imbalanced Medical Image Classification
Jul 27, 2023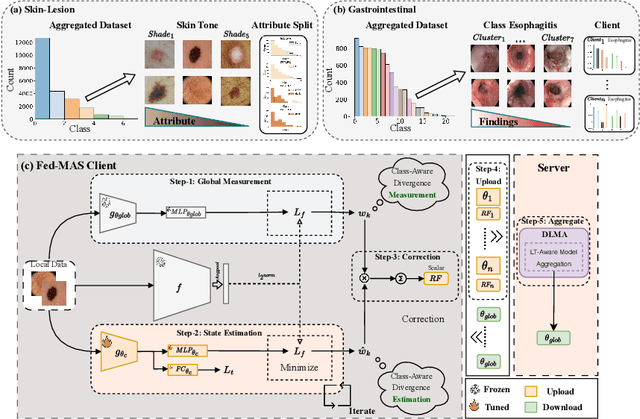
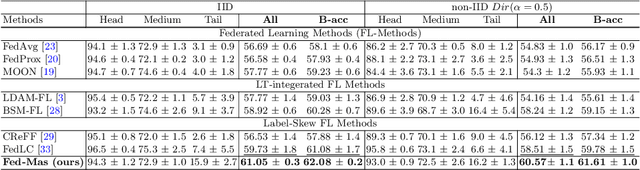
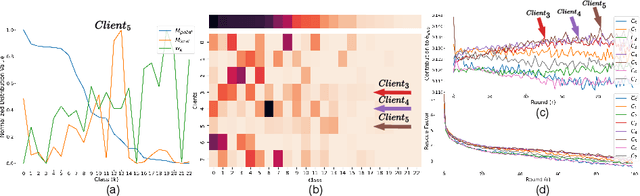

In the medical field, federated learning commonly deals with highly imbalanced datasets, including skin lesions and gastrointestinal images. Existing federated methods under highly imbalanced datasets primarily focus on optimizing a global model without incorporating the intra-class variations that can arise in medical imaging due to different populations, findings, and scanners. In this paper, we study the inter-client intra-class variations with publicly available self-supervised auxiliary networks. Specifically, we find that employing a shared auxiliary pre-trained model, like MoCo-V2, locally on every client yields consistent divergence measurements. Based on these findings, we derive a dynamic balanced model aggregation via self-supervised priors (MAS) to guide the global model optimization. Fed-MAS can be utilized with different local learning methods for effective model aggregation toward a highly robust and unbiased global model. Our code is available at \url{https://github.com/xmed-lab/Fed-MAS}.
Fairness in Image Search: A Study of Occupational Stereotyping in Image Retrieval and its Debiasing
May 06, 2023


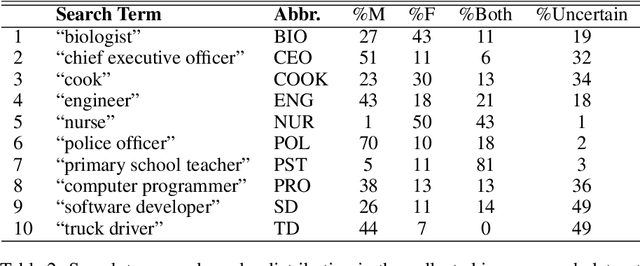
Multi-modal search engines have experienced significant growth and widespread use in recent years, making them the second most common internet use. While search engine systems offer a range of services, the image search field has recently become a focal point in the information retrieval community, as the adage goes, "a picture is worth a thousand words". Although popular search engines like Google excel at image search accuracy and agility, there is an ongoing debate over whether their search results can be biased in terms of gender, language, demographics, socio-cultural aspects, and stereotypes. This potential for bias can have a significant impact on individuals' perceptions and influence their perspectives. In this paper, we present our study on bias and fairness in web search, with a focus on keyword-based image search. We first discuss several kinds of biases that exist in search systems and why it is important to mitigate them. We narrow down our study to assessing and mitigating occupational stereotypes in image search, which is a prevalent fairness issue in image retrieval. For the assessment of stereotypes, we take gender as an indicator. We explore various open-source and proprietary APIs for gender identification from images. With these, we examine the extent of gender bias in top-tanked image search results obtained for several occupational keywords. To mitigate the bias, we then propose a fairness-aware re-ranking algorithm that optimizes (a) relevance of the search result with the keyword and (b) fairness w.r.t genders identified. We experiment on 100 top-ranked images obtained for 10 occupational keywords and consider random re-ranking and re-ranking based on relevance as baselines. Our experimental results show that the fairness-aware re-ranking algorithm produces rankings with better fairness scores and competitive relevance scores than the baselines.
Make-A-Volume: Leveraging Latent Diffusion Models for Cross-Modality 3D Brain MRI Synthesis
Jul 19, 2023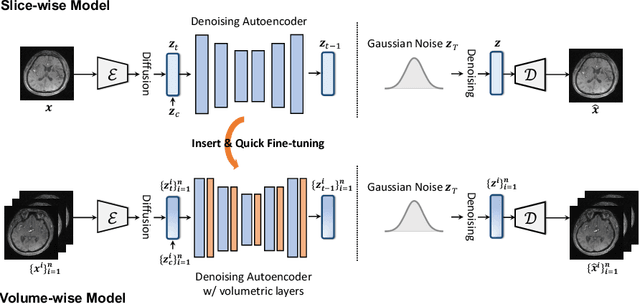
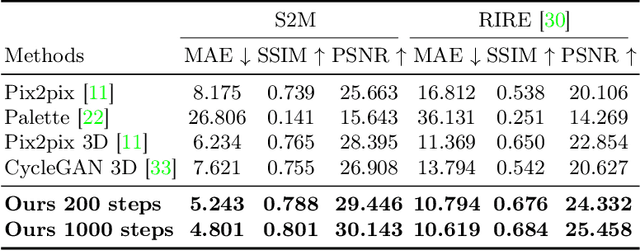
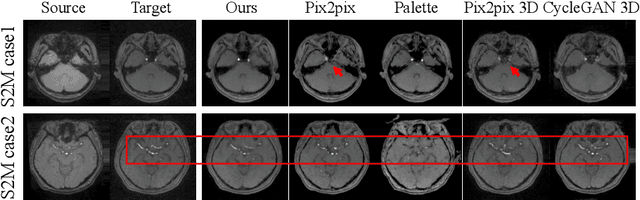

Cross-modality medical image synthesis is a critical topic and has the potential to facilitate numerous applications in the medical imaging field. Despite recent successes in deep-learning-based generative models, most current medical image synthesis methods rely on generative adversarial networks and suffer from notorious mode collapse and unstable training. Moreover, the 2D backbone-driven approaches would easily result in volumetric inconsistency, while 3D backbones are challenging and impractical due to the tremendous memory cost and training difficulty. In this paper, we introduce a new paradigm for volumetric medical data synthesis by leveraging 2D backbones and present a diffusion-based framework, Make-A-Volume, for cross-modality 3D medical image synthesis. To learn the cross-modality slice-wise mapping, we employ a latent diffusion model and learn a low-dimensional latent space, resulting in high computational efficiency. To enable the 3D image synthesis and mitigate volumetric inconsistency, we further insert a series of volumetric layers in the 2D slice-mapping model and fine-tune them with paired 3D data. This paradigm extends the 2D image diffusion model to a volumetric version with a slightly increasing number of parameters and computation, offering a principled solution for generic cross-modality 3D medical image synthesis. We showcase the effectiveness of our Make-A-Volume framework on an in-house SWI-MRA brain MRI dataset and a public T1-T2 brain MRI dataset. Experimental results demonstrate that our framework achieves superior synthesis results with volumetric consistency.