 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Entropy Transformer Networks: A Learning Approach via Tangent Bundle Data Manifold
Jul 24, 2023
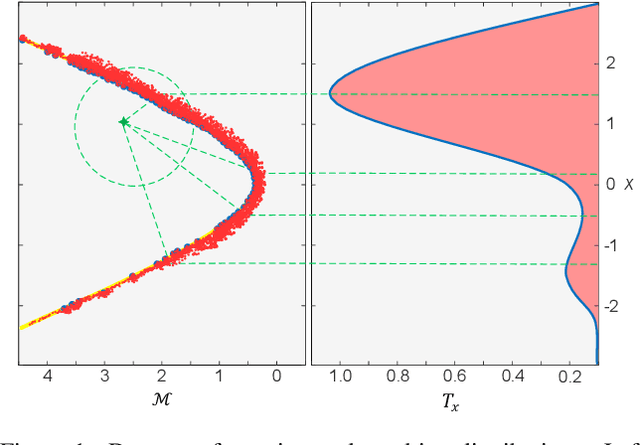

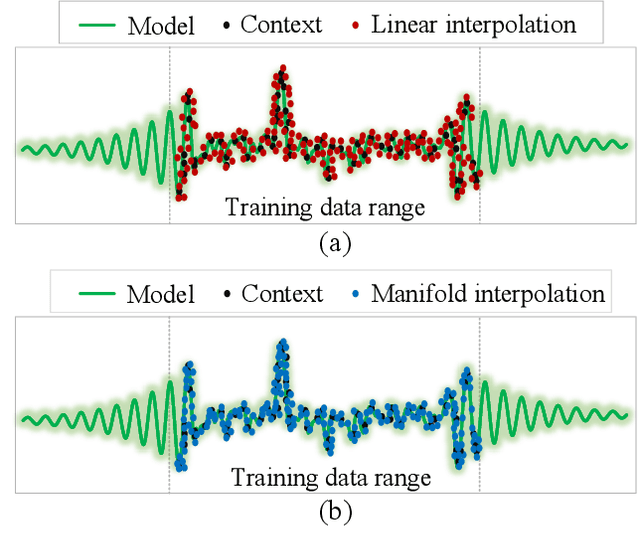

This paper focuses on an accurate and fast interpolation approach for image transformation employed in the design of CNN architectures. Standard Spatial Transformer Networks (STNs) use bilinear or linear interpolation as their interpolation, with unrealistic assumptions about the underlying data distributions, which leads to poor performance under scale variations. Moreover, STNs do not preserve the norm of gradients in propagation due to their dependency on sparse neighboring pixels. To address this problem, a novel Entropy STN (ESTN) is proposed that interpolates on the data manifold distributions. In particular, random samples are generated for each pixel in association with the tangent space of the data manifold and construct a linear approximation of their intensity values with an entropy regularizer to compute the transformer parameters. A simple yet effective technique is also proposed to normalize the non-zero values of the convolution operation, to fine-tune the layers for gradients' norm-regularization during training. Experiments on challenging benchmarks show that the proposed ESTN can improve predictive accuracy over a range of computer vision tasks, including image reconstruction, and classification, while reducing the computational cost.
Principal Uncertainty Quantification with Spatial Correlation for Image Restoration Problems
May 17, 2023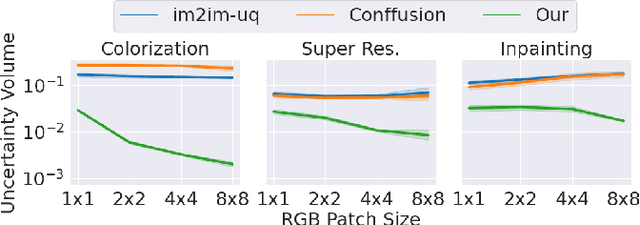


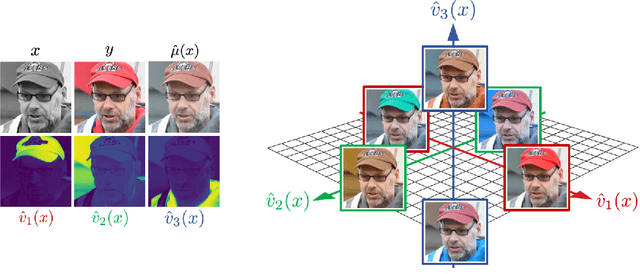
Uncertainty quantification for inverse problems in imaging has drawn much attention lately. Existing approaches towards this task define uncertainty regions based on probable values per pixel, while ignoring spatial correlations within the image, resulting in an exaggerated volume of uncertainty. In this paper, we propose PUQ (Principal Uncertainty Quantification) -- a novel definition and corresponding analysis of uncertainty regions that takes into account spatial relationships within the image, thus providing reduced volume regions. Using recent advancements in stochastic generative models, we derive uncertainty intervals around principal components of the empirical posterior distribution, forming an ambiguity region that guarantees the inclusion of true unseen values with a user confidence probability. To improve computational efficiency and interpretability, we also guarantee the recovery of true unseen values using only a few principal directions, resulting in ultimately more informative uncertainty regions. Our approach is verified through experiments on image colorization, super-resolution, and inpainting; its effectiveness is shown through comparison to baseline methods, demonstrating significantly tighter uncertainty regions.
A Critical Look at the Current Usage of Foundation Model for Dense Recognition Task
Aug 01, 2023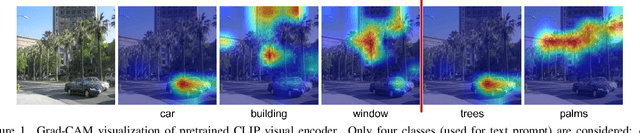
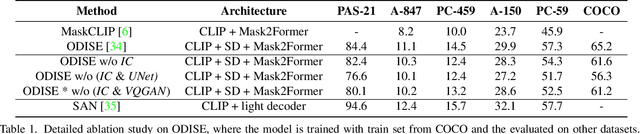


In recent years large model trained on huge amount of cross-modality data, which is usually be termed as foundation model, achieves conspicuous accomplishment in many fields, such as image recognition and generation. Though achieving great success in their original application case, it is still unclear whether those foundation models can be applied to other different downstream tasks. In this paper, we conduct a short survey on the current methods for discriminative dense recognition tasks, which are built on the pretrained foundation model. And we also provide some preliminary experimental analysis of an existing open-vocabulary segmentation method based on Stable Diffusion, which indicates the current way of deploying diffusion model for segmentation is not optimal. This aims to provide insights for future research on adopting foundation model for downstream task.
Detecting Cloud Presence in Satellite Images Using the RGB-based CLIP Vision-Language Model
Aug 01, 2023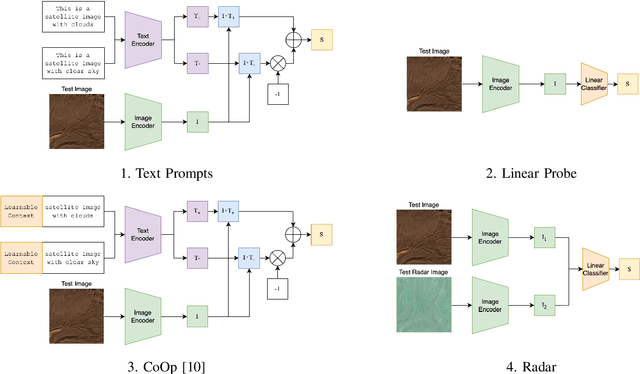
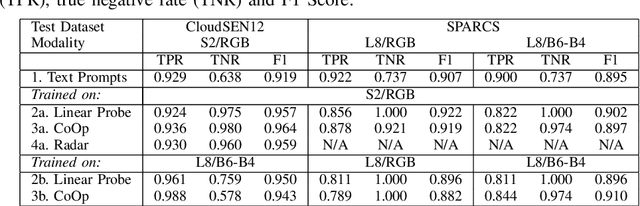
This work explores capabilities of the pre-trained CLIP vision-language model to identify satellite images affected by clouds. Several approaches to using the model to perform cloud presence detection are proposed and evaluated, including a purely zero-shot operation with text prompts and several fine-tuning approaches. Furthermore, the transferability of the methods across different datasets and sensor types (Sentinel-2 and Landsat-8) is tested. The results that CLIP can achieve non-trivial performance on the cloud presence detection task with apparent capability to generalise across sensing modalities and sensing bands. It is also found that a low-cost fine-tuning stage leads to a strong increase in true negative rate. The results demonstrate that the representations learned by the CLIP model can be useful for satellite image processing tasks involving clouds.
The Algonauts Project 2023 Challenge: UARK-UAlbany Team Solution
Aug 01, 2023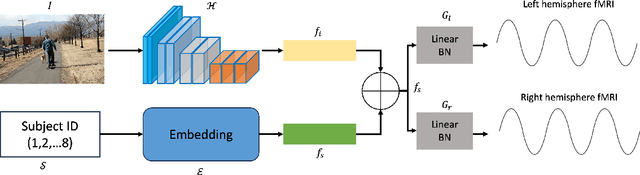

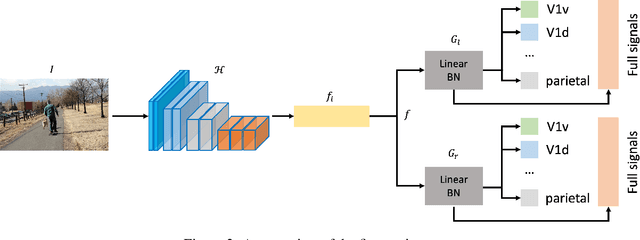
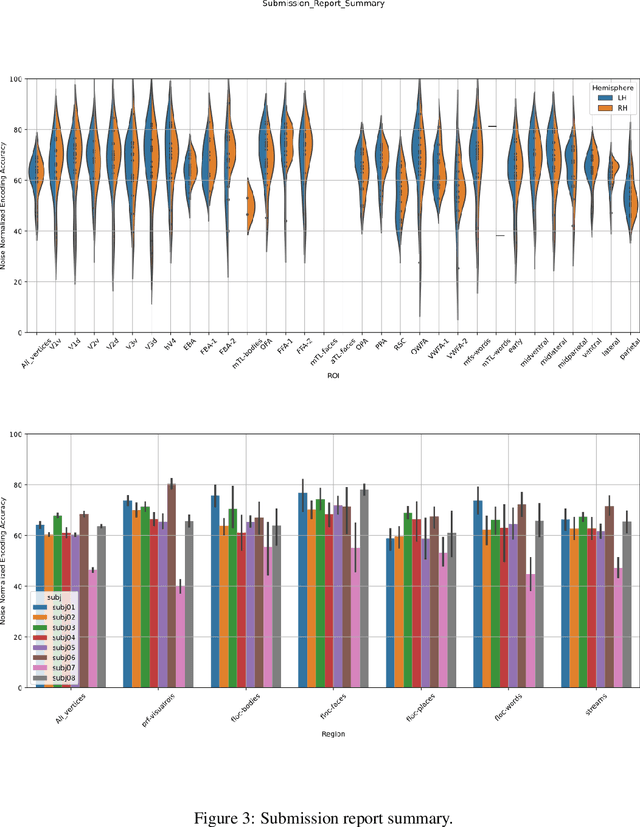
This work presents our solutions to the Algonauts Project 2023 Challenge. The primary objective of the challenge revolves around employing computational models to anticipate brain responses captured during participants' observation of intricate natural visual scenes. The goal is to predict brain responses across the entire visual brain, as it is the region where the most reliable responses to images have been observed. We constructed an image-based brain encoder through a two-step training process to tackle this challenge. Initially, we created a pretrained encoder using data from all subjects. Next, we proceeded to fine-tune individual subjects. Each step employed different training strategies, such as different loss functions and objectives, to introduce diversity. Ultimately, our solution constitutes an ensemble of multiple unique encoders. The code is available at https://github.com/uark-cviu/Algonauts2023
Patch-wise Auto-Encoder for Visual Anomaly Detection
Aug 01, 2023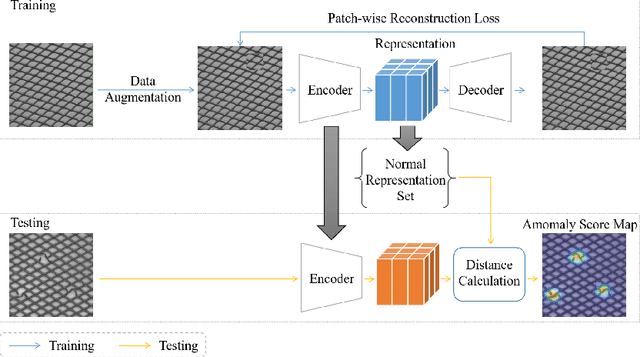
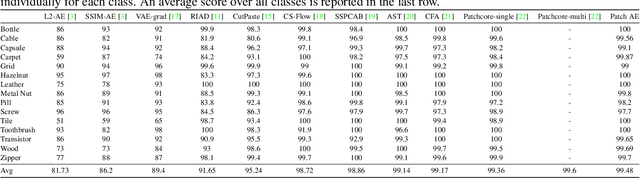
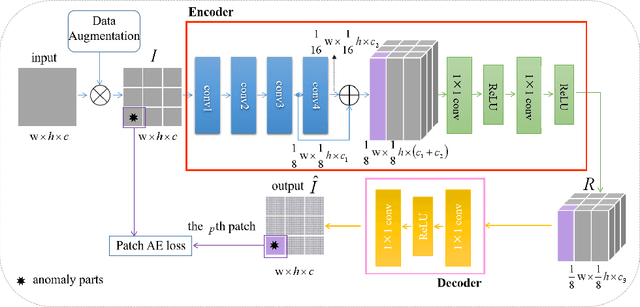
Anomaly detection without priors of the anomalies is challenging. In the field of unsupervised anomaly detection, traditional auto-encoder (AE) tends to fail based on the assumption that by training only on normal images, the model will not be able to reconstruct abnormal images correctly. On the contrary, we propose a novel patch-wise auto-encoder (Patch AE) framework, which aims at enhancing the reconstruction ability of AE to anomalies instead of weakening it. Each patch of image is reconstructed by corresponding spatially distributed feature vector of the learned feature representation, i.e., patch-wise reconstruction, which ensures anomaly-sensitivity of AE. Our method is simple and efficient. It advances the state-of-the-art performances on Mvtec AD benchmark, which proves the effectiveness of our model. It shows great potential in practical industrial application scenarios.
Detection of Children Abuse by Voice and Audio Classification by Short-Time Fourier Transform Machine Learning implemented on Nvidia Edge GPU device
Jul 27, 2023
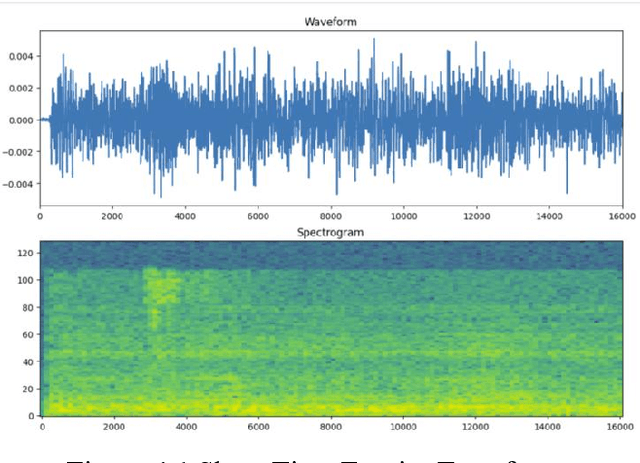
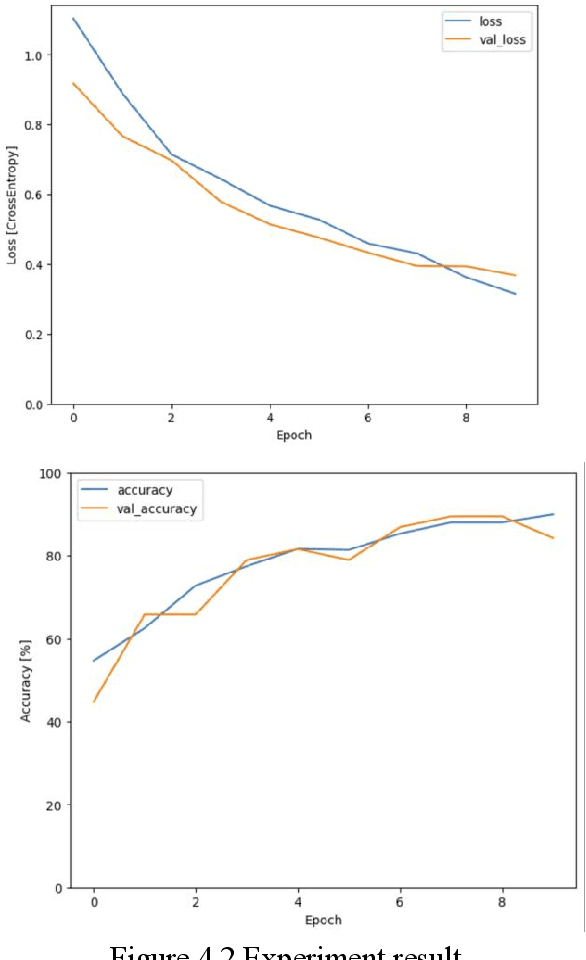
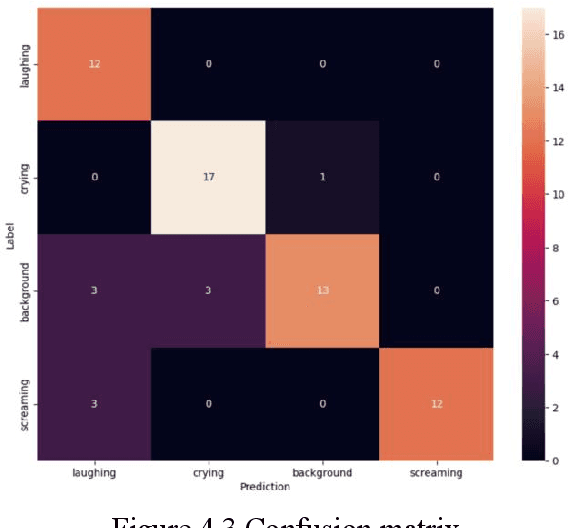
The safety of children in children home has become an increasing social concern, and the purpose of this experiment is to use machine learning applied to detect the scenarios of child abuse to increase the safety of children. This experiment uses machine learning to classify and recognize a child's voice and predict whether the current sound made by the child is crying, screaming or laughing. If a child is found to be crying or screaming, an alert is immediately sent to the relevant personnel so that they can perceive what the child may be experiencing in a surveillance blind spot and respond in a timely manner. Together with a hybrid use of video image classification, the accuracy of child abuse detection can be significantly increased. This greatly reduces the likelihood that a child will receive violent abuse in the nursery and allows personnel to stop an imminent or incipient child abuse incident in time. The datasets collected from this experiment is entirely from sounds recorded on site at the children home, including crying, laughing, screaming sound and background noises. These sound files are transformed into spectrograms using Short-Time Fourier Transform, and then these image data are imported into a CNN neural network for classification, and the final trained model can achieve an accuracy of about 92% for sound detection.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023
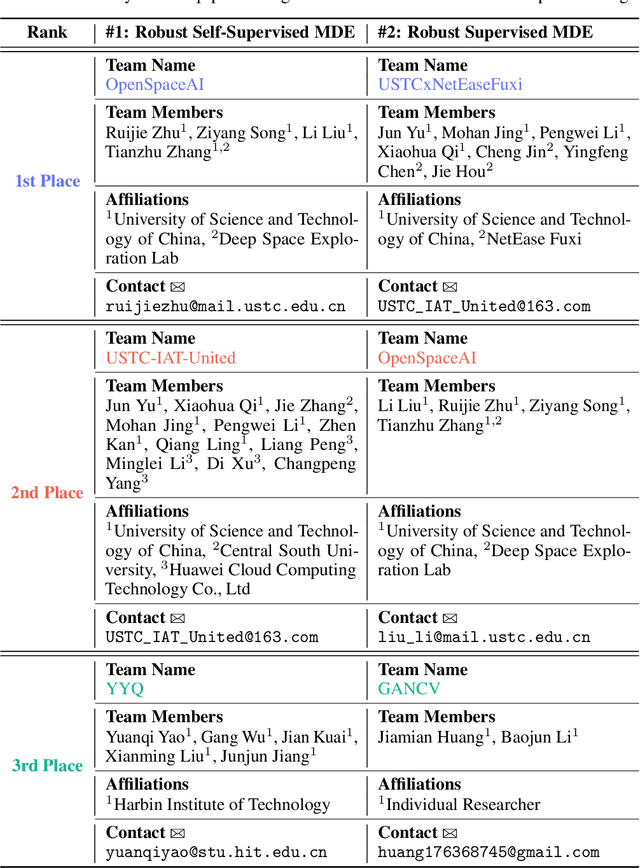

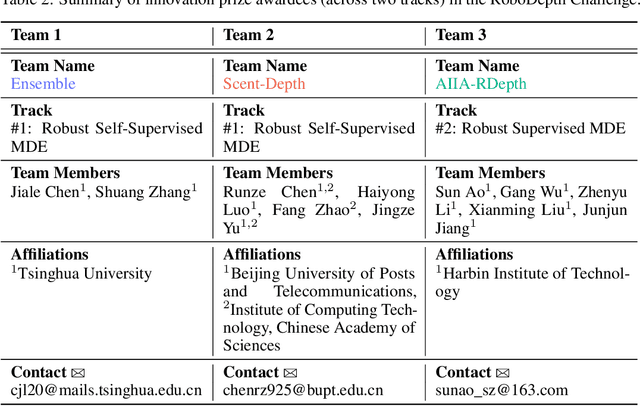
Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Unsupervised Camouflaged Object Segmentation as Domain Adaptation
Aug 08, 2023Deep learning for unsupervised image segmentation remains challenging due to the absence of human labels. The common idea is to train a segmentation head, with the supervision of pixel-wise pseudo-labels generated based on the representation of self-supervised backbones. By doing so, the model performance depends much on the distance between the distributions of target datasets and the pre-training dataset (e.g., ImageNet). In this work, we investigate a new task, namely unsupervised camouflaged object segmentation (UCOS), where the target objects own a common rarely-seen attribute, i.e., camouflage. Unsurprisingly, we find that the state-of-the-art unsupervised models struggle in adapting UCOS, due to the domain gap between the properties of generic and camouflaged objects. To this end, we formulate the UCOS as a source-free unsupervised domain adaptation task (UCOS-DA), where both source labels and target labels are absent during the whole model training process. Specifically, we define a source model consisting of self-supervised vision transformers pre-trained on ImageNet. On the other hand, the target domain includes a simple linear layer (i.e., our target model) and unlabeled camouflaged objects. We then design a pipeline for foreground-background-contrastive self-adversarial domain adaptation, to achieve robust UCOS. As a result, our baseline model achieves superior segmentation performance when compared with competing unsupervised models on the UCOS benchmark, with the training set which's scale is only one tenth of the supervised COS counterpart.
Synthetic Augmentation with Large-scale Unconditional Pre-training
Aug 08, 2023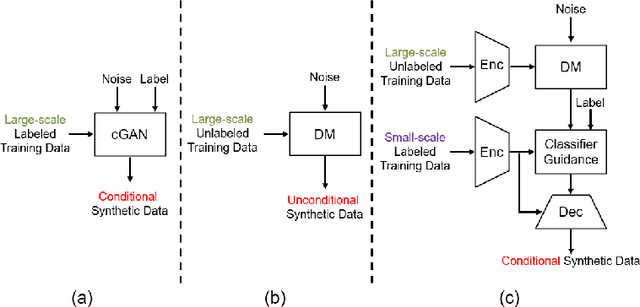
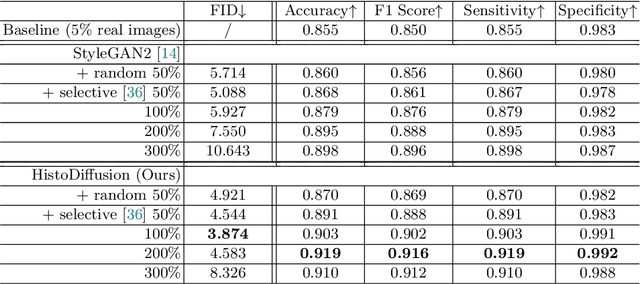
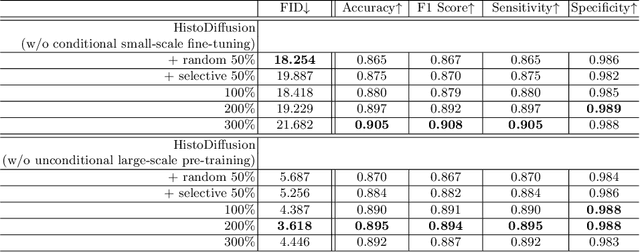
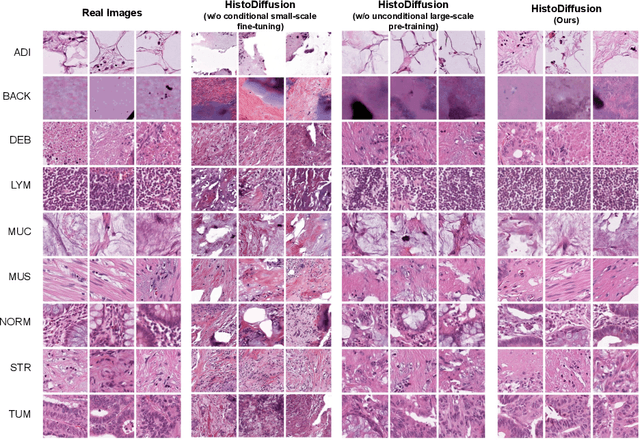
Deep learning based medical image recognition systems often require a substantial amount of training data with expert annotations, which can be expensive and time-consuming to obtain. Recently, synthetic augmentation techniques have been proposed to mitigate the issue by generating realistic images conditioned on class labels. However, the effectiveness of these methods heavily depends on the representation capability of the trained generative model, which cannot be guaranteed without sufficient labeled training data. To further reduce the dependency on annotated data, we propose a synthetic augmentation method called HistoDiffusion, which can be pre-trained on large-scale unlabeled datasets and later applied to a small-scale labeled dataset for augmented training. In particular, we train a latent diffusion model (LDM) on diverse unlabeled datasets to learn common features and generate realistic images without conditional inputs. Then, we fine-tune the model with classifier guidance in latent space on an unseen labeled dataset so that the model can synthesize images of specific categories. Additionally, we adopt a selective mechanism to only add synthetic samples with high confidence of matching to target labels. We evaluate our proposed method by pre-training on three histopathology datasets and testing on a histopathology dataset of colorectal cancer (CRC) excluded from the pre-training datasets. With HistoDiffusion augmentation, the classification accuracy of a backbone classifier is remarkably improved by 6.4% using a small set of the original labels. Our code is available at https://github.com/karenyyy/HistoDiffAug.