 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WALT3D: Generating Realistic Training Data from Time-Lapse Imagery for Reconstructing Dynamic Objects under Occlusion
Mar 27, 2024
Current methods for 2D and 3D object understanding struggle with severe occlusions in busy urban environments, partly due to the lack of large-scale labeled ground-truth annotations for learning occlusion. In this work, we introduce a novel framework for automatically generating a large, realistic dataset of dynamic objects under occlusions using freely available time-lapse imagery. By leveraging off-the-shelf 2D (bounding box, segmentation, keypoint) and 3D (pose, shape) predictions as pseudo-groundtruth, unoccluded 3D objects are identified automatically and composited into the background in a clip-art style, ensuring realistic appearances and physically accurate occlusion configurations. The resulting clip-art image with pseudo-groundtruth enables efficient training of object reconstruction methods that are robust to occlusions. Our method demonstrates significant improvements in both 2D and 3D reconstruction, particularly in scenarios with heavily occluded objects like vehicles and people in urban scenes.
ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
Mar 27, 2024Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approaches, we propose a practical solution centered on a \q{counterfactual} dataset. Our method involves capturing a scene before and after removing a single object, while minimizing other changes. By fine-tuning a diffusion model on this dataset, we are able to not only remove objects but also their effects on the scene. However, we find that applying this approach for photorealistic object insertion requires an impractically large dataset. To tackle this challenge, we propose bootstrap supervision; leveraging our object removal model trained on a small counterfactual dataset, we synthetically expand this dataset considerably. Our approach significantly outperforms prior methods in photorealistic object removal and insertion, particularly at modeling the effects of objects on the scene.
ContourDiff: Unpaired Image Translation with Contour-Guided Diffusion Models
Mar 16, 2024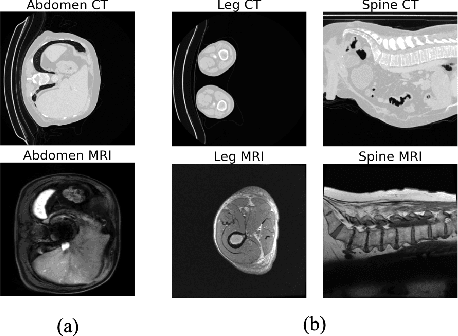
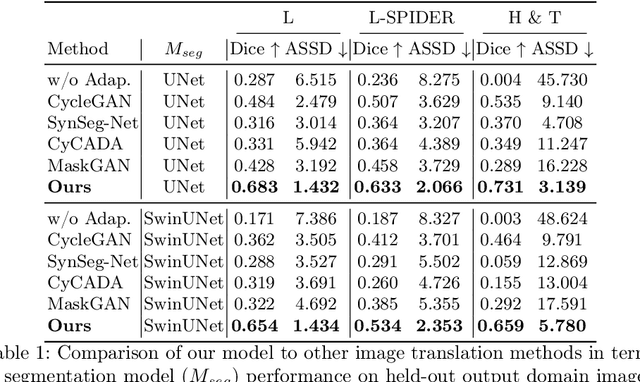
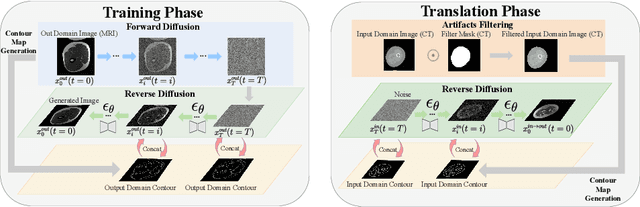
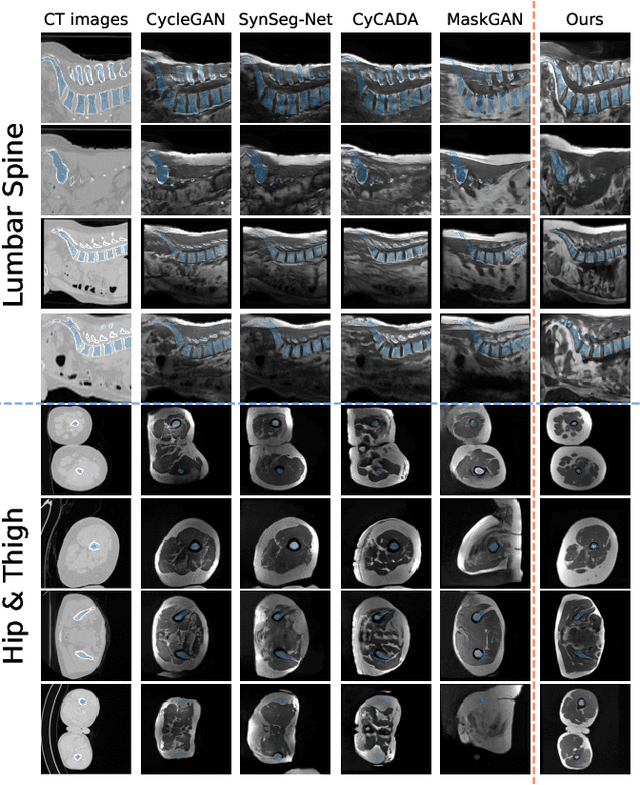
Accurately translating medical images across different modalities (e.g., CT to MRI) has numerous downstream clinical and machine learning applications. While several methods have been proposed to achieve this, they often prioritize perceptual quality with respect to output domain features over preserving anatomical fidelity. However, maintaining anatomy during translation is essential for many tasks, e.g., when leveraging masks from the input domain to develop a segmentation model with images translated to the output domain. To address these challenges, we propose ContourDiff, a novel framework that leverages domain-invariant anatomical contour representations of images. These representations are simple to extract from images, yet form precise spatial constraints on their anatomical content. We introduce a diffusion model that converts contour representations of images from arbitrary input domains into images in the output domain of interest. By applying the contour as a constraint at every diffusion sampling step, we ensure the preservation of anatomical content. We evaluate our method by training a segmentation model on images translated from CT to MRI with their original CT masks and testing its performance on real MRIs. Our method outperforms other unpaired image translation methods by a significant margin, furthermore without the need to access any input domain information during training.
ELGC-Net: Efficient Local-Global Context Aggregation for Remote Sensing Change Detection
Mar 26, 2024Deep learning has shown remarkable success in remote sensing change detection (CD), aiming to identify semantic change regions between co-registered satellite image pairs acquired at distinct time stamps. However, existing convolutional neural network and transformer-based frameworks often struggle to accurately segment semantic change regions. Moreover, transformers-based methods with standard self-attention suffer from quadratic computational complexity with respect to the image resolution, making them less practical for CD tasks with limited training data. To address these issues, we propose an efficient change detection framework, ELGC-Net, which leverages rich contextual information to precisely estimate change regions while reducing the model size. Our ELGC-Net comprises a Siamese encoder, fusion modules, and a decoder. The focus of our design is the introduction of an Efficient Local-Global Context Aggregator module within the encoder, capturing enhanced global context and local spatial information through a novel pooled-transpose (PT) attention and depthwise convolution, respectively. The PT attention employs pooling operations for robust feature extraction and minimizes computational cost with transposed attention. Extensive experiments on three challenging CD datasets demonstrate that ELGC-Net outperforms existing methods. Compared to the recent transformer-based CD approach (ChangeFormer), ELGC-Net achieves a 1.4% gain in intersection over union metric on the LEVIR-CD dataset, while significantly reducing trainable parameters. Our proposed ELGC-Net sets a new state-of-the-art performance in remote sensing change detection benchmarks. Finally, we also introduce ELGC-Net-LW, a lighter variant with significantly reduced computational complexity, suitable for resource-constrained settings, while achieving comparable performance. Project url https://github.com/techmn/elgcnet.
Probing Image Compression For Class-Incremental Learning
Mar 10, 2024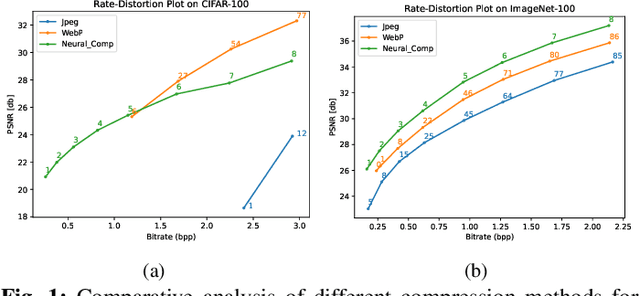
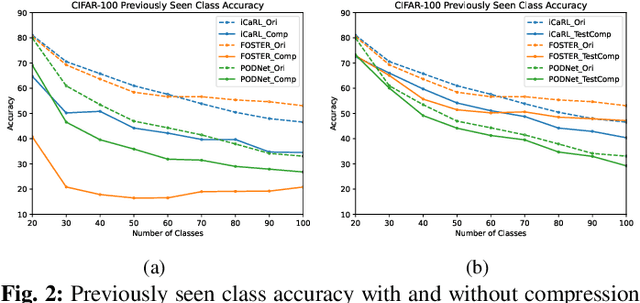
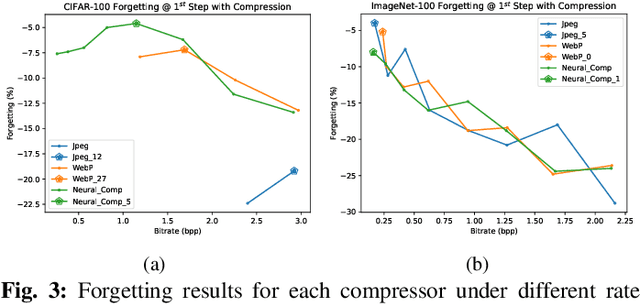
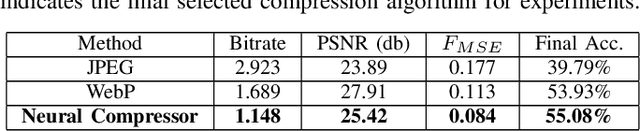
Image compression emerges as a pivotal tool in the efficient handling and transmission of digital images. Its ability to substantially reduce file size not only facilitates enhanced data storage capacity but also potentially brings advantages to the development of continual machine learning (ML) systems, which learn new knowledge incrementally from sequential data. Continual ML systems often rely on storing representative samples, also known as exemplars, within a limited memory constraint to maintain the performance on previously learned data. These methods are known as memory replay-based algorithms and have proven effective at mitigating the detrimental effects of catastrophic forgetting. Nonetheless, the limited memory buffer size often falls short of adequately representing the entire data distribution. In this paper, we explore the use of image compression as a strategy to enhance the buffer's capacity, thereby increasing exemplar diversity. However, directly using compressed exemplars introduces domain shift during continual ML, marked by a discrepancy between compressed training data and uncompressed testing data. Additionally, it is essential to determine the appropriate compression algorithm and select the most effective rate for continual ML systems to balance the trade-off between exemplar quality and quantity. To this end, we introduce a new framework to incorporate image compression for continual ML including a pre-processing data compression step and an efficient compression rate/algorithm selection method. We conduct extensive experiments on CIFAR-100 and ImageNet datasets and show that our method significantly improves image classification accuracy in continual ML settings.
NightHaze: Nighttime Image Dehazing via Self-Prior Learning
Mar 12, 2024
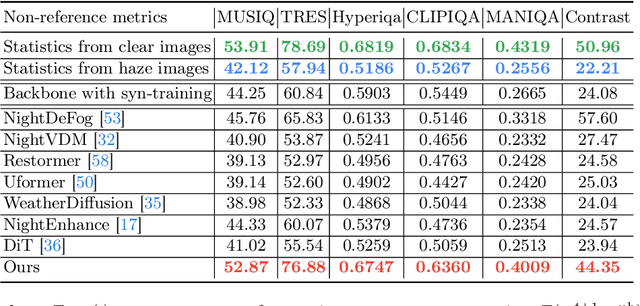
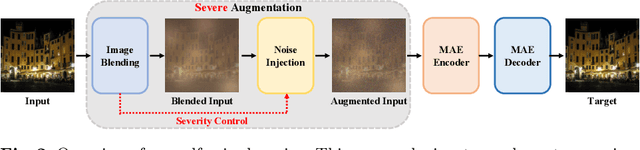
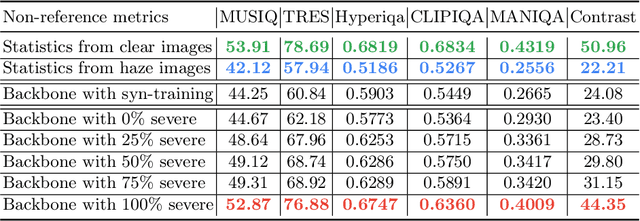
Masked autoencoder (MAE) shows that severe augmentation during training produces robust representations for high-level tasks. This paper brings the MAE-like framework to nighttime image enhancement, demonstrating that severe augmentation during training produces strong network priors that are resilient to real-world night haze degradations. We propose a novel nighttime image dehazing method with self-prior learning. Our main novelty lies in the design of severe augmentation, which allows our model to learn robust priors. Unlike MAE that uses masking, we leverage two key challenging factors of nighttime images as augmentation: light effects and noise. During training, we intentionally degrade clear images by blending them with light effects as well as by adding noise, and subsequently restore the clear images. This enables our model to learn clear background priors. By increasing the noise values to approach as high as the pixel intensity values of the glow and light effect blended images, our augmentation becomes severe, resulting in stronger priors. While our self-prior learning is considerably effective in suppressing glow and revealing details of background scenes, in some cases, there are still some undesired artifacts that remain, particularly in the forms of over-suppression. To address these artifacts, we propose a self-refinement module based on the semi-supervised teacher-student framework. Our NightHaze, especially our MAE-like self-prior learning, shows that models trained with severe augmentation effectively improve the visibility of input haze images, approaching the clarity of clear nighttime images. Extensive experiments demonstrate that our NightHaze achieves state-of-the-art performance, outperforming existing nighttime image dehazing methods by a substantial margin of 15.5% for MUSIQ and 23.5% for ClipIQA.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024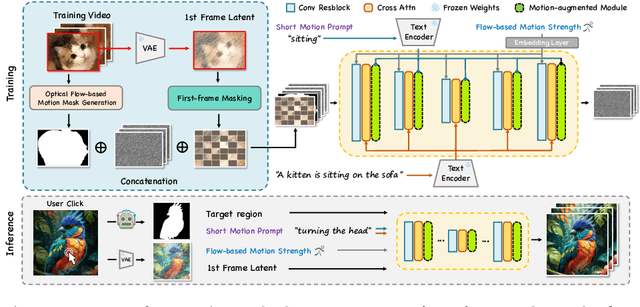
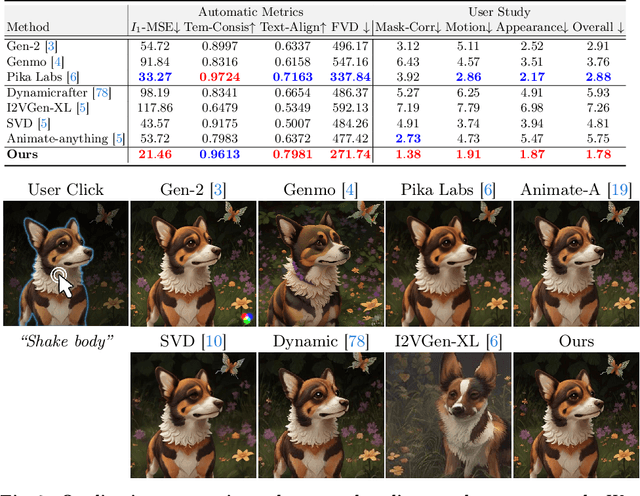
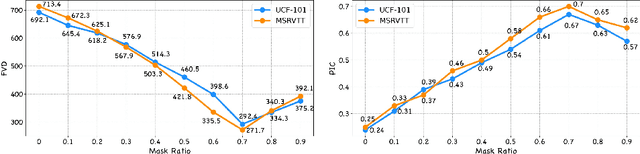

Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
CoherentGS: Sparse Novel View Synthesis with Coherent 3D Gaussians
Mar 28, 2024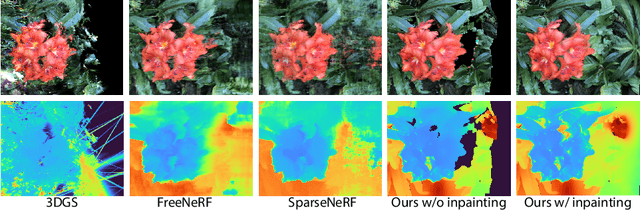
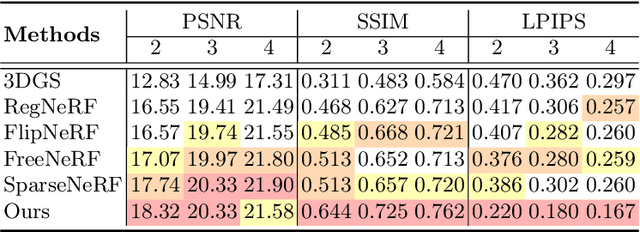

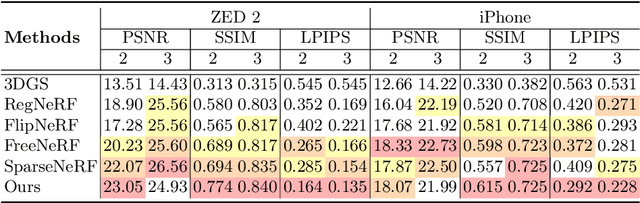
The field of 3D reconstruction from images has rapidly evolved in the past few years, first with the introduction of Neural Radiance Field (NeRF) and more recently with 3D Gaussian Splatting (3DGS). The latter provides a significant edge over NeRF in terms of the training and inference speed, as well as the reconstruction quality. Although 3DGS works well for dense input images, the unstructured point-cloud like representation quickly overfits to the more challenging setup of extremely sparse input images (e.g., 3 images), creating a representation that appears as a jumble of needles from novel views. To address this issue, we propose regularized optimization and depth-based initialization. Our key idea is to introduce a structured Gaussian representation that can be controlled in 2D image space. We then constraint the Gaussians, in particular their position, and prevent them from moving independently during optimization. Specifically, we introduce single and multiview constraints through an implicit convolutional decoder and a total variation loss, respectively. With the coherency introduced to the Gaussians, we further constrain the optimization through a flow-based loss function. To support our regularized optimization, we propose an approach to initialize the Gaussians using monocular depth estimates at each input view. We demonstrate significant improvements compared to the state-of-the-art sparse-view NeRF-based approaches on a variety of scenes.
Neural Fields for 3D Tracking of Anatomy and Surgical Instruments in Monocular Laparoscopic Video Clips
Mar 28, 2024Laparoscopic video tracking primarily focuses on two target types: surgical instruments and anatomy. The former could be used for skill assessment, while the latter is necessary for the projection of virtual overlays. Where instrument and anatomy tracking have often been considered two separate problems, in this paper, we propose a method for joint tracking of all structures simultaneously. Based on a single 2D monocular video clip, we train a neural field to represent a continuous spatiotemporal scene, used to create 3D tracks of all surfaces visible in at least one frame. Due to the small size of instruments, they generally cover a small part of the image only, resulting in decreased tracking accuracy. Therefore, we propose enhanced class weighting to improve the instrument tracks. We evaluate tracking on video clips from laparoscopic cholecystectomies, where we find mean tracking accuracies of 92.4% for anatomical structures and 87.4% for instruments. Additionally, we assess the quality of depth maps obtained from the method's scene reconstructions. We show that these pseudo-depths have comparable quality to a state-of-the-art pre-trained depth estimator. On laparoscopic videos in the SCARED dataset, the method predicts depth with an MAE of 2.9 mm and a relative error of 9.2%. These results show the feasibility of using neural fields for monocular 3D reconstruction of laparoscopic scenes.
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
Mar 28, 2024Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demonstrate that our method achieves competitive performance across various downstream image classification tasks, all while maintaining comparable new parameters. We believe this work takes a step forward in offering a unified perspective for interpreting existing methods and serves as motivation for the development of new approaches that move closer to effectively considering the crucial trade-off mentioned above. Our code is available at \href{https://github.com/zstarN70/RLRR.git}{https://github.com/zstarN70/RLRR.git}.