 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Motion-robust free-running cardiovascular MRI
Aug 04, 2023
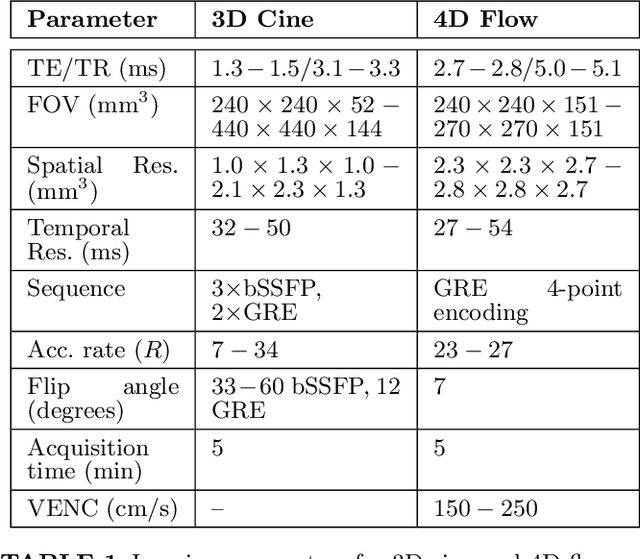
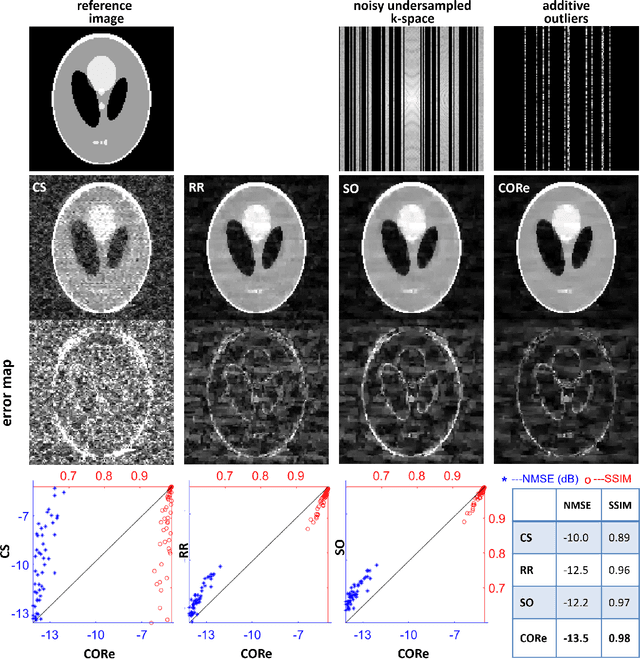
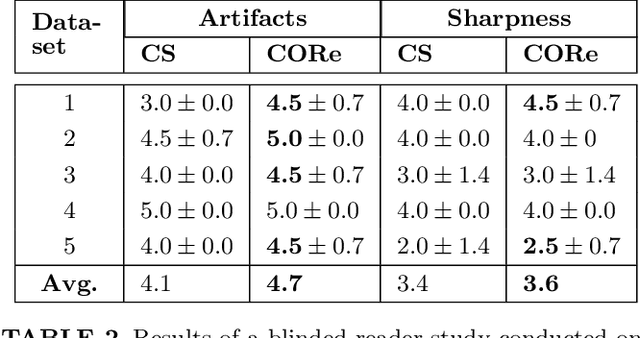
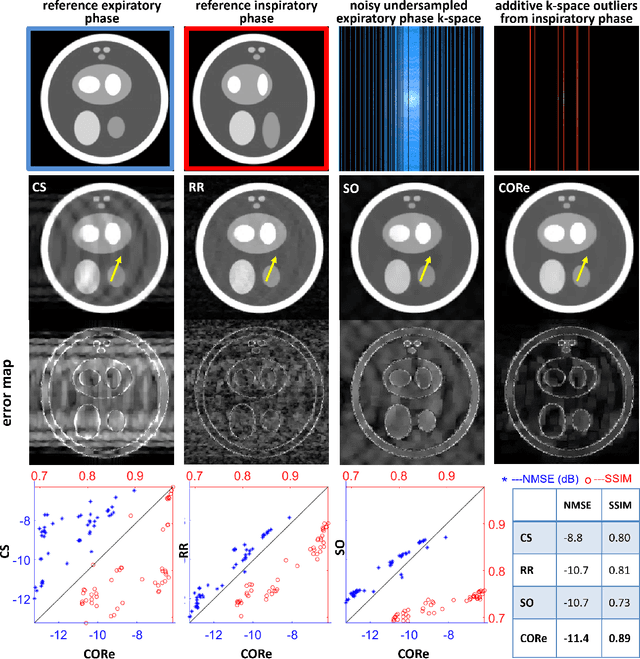
PURPOSE: To present and validate an outlier rejection method that makes free-running cardiovascular MRI (CMR) more motion robust. METHODS: The proposed method, called compressive recovery with outlier rejection (CORe), models outliers as an auxiliary variable that is added to the measured data. We enforce MR physics-guided group-sparsity on the auxiliary variable and jointly estimate it along with the image using an iterative algorithm. For validation, CORe is first compared to traditional compressed sensing (CS), robust regression (RR), and another outlier rejection method using two simulation studies. Then, CORe is compared to CS using five 3D cine and ten rest and stress 4D flow imaging datasets. RESULTS: Our simulation studies show that CORe outperforms CS, RR, and the outlier rejection method in terms of normalized mean squared error (NMSE) and structural similarity index (SSIM) across 50 different realizations. The expert reader evaluation of 3D cine images demonstrates that CORe is more effective in suppressing artifacts while maintaining or improving image sharpness. The flow consistency evaluation in 4D flow images show that CORe yields more consistent flow measurements, especially under exercise stress. CONCLUSION: An outlier rejection method is presented and validated using simulated and measured data. This method can help suppress motion artifacts in a wide range of free-running CMR applications. CODE: MATLAB implementation code is available on GitHub at https://github.com/syedmurtazaarshad/motion-robust-CMR
LIST: Learning Implicitly from Spatial Transformers for Single-View 3D Reconstruction
Jul 23, 2023
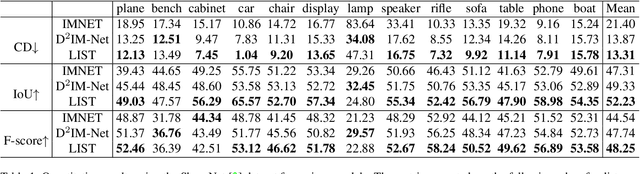
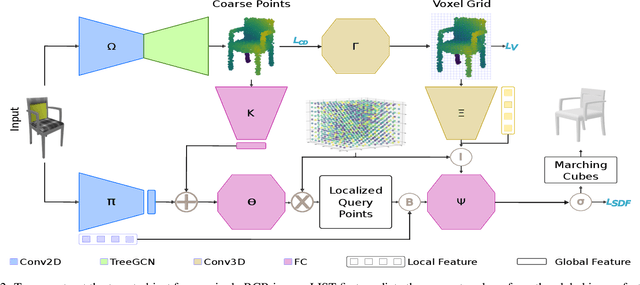
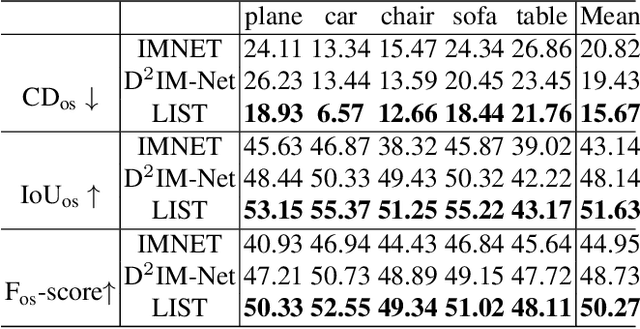
Accurate reconstruction of both the geometric and topological details of a 3D object from a single 2D image embodies a fundamental challenge in computer vision. Existing explicit/implicit solutions to this problem struggle to recover self-occluded geometry and/or faithfully reconstruct topological shape structures. To resolve this dilemma, we introduce LIST, a novel neural architecture that leverages local and global image features to accurately reconstruct the geometric and topological structure of a 3D object from a single image. We utilize global 2D features to predict a coarse shape of the target object and then use it as a base for higher-resolution reconstruction. By leveraging both local 2D features from the image and 3D features from the coarse prediction, we can predict the signed distance between an arbitrary point and the target surface via an implicit predictor with great accuracy. Furthermore, our model does not require camera estimation or pixel alignment. It provides an uninfluenced reconstruction from the input-view direction. Through qualitative and quantitative analysis, we show the superiority of our model in reconstructing 3D objects from both synthetic and real-world images against the state of the art.
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
Aug 02, 2023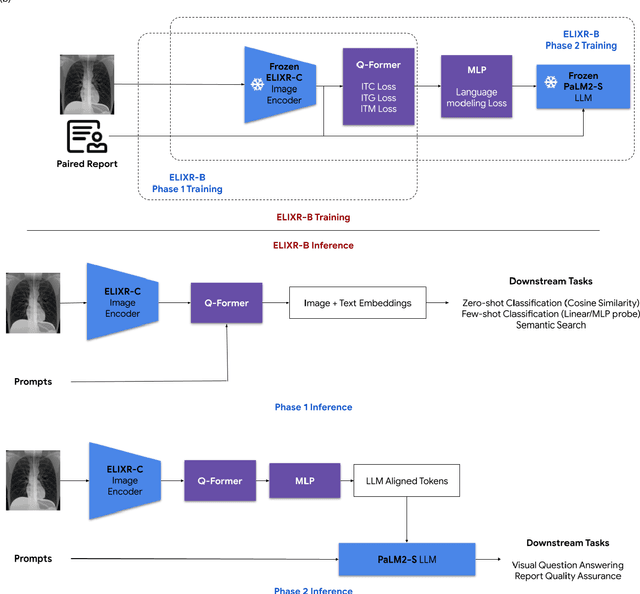
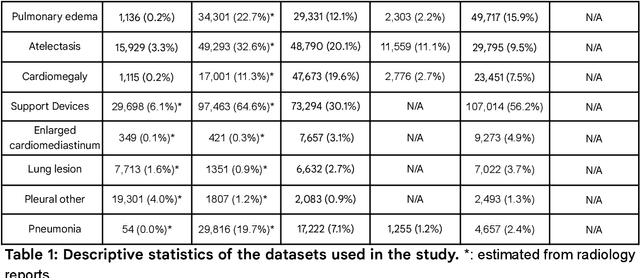
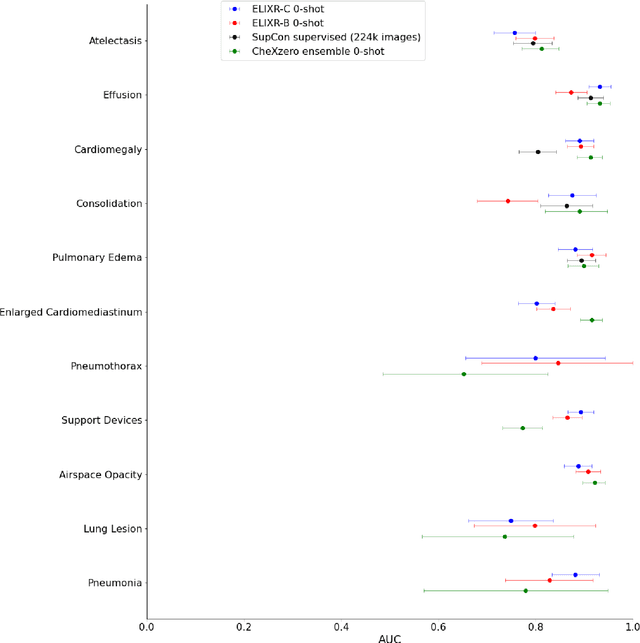
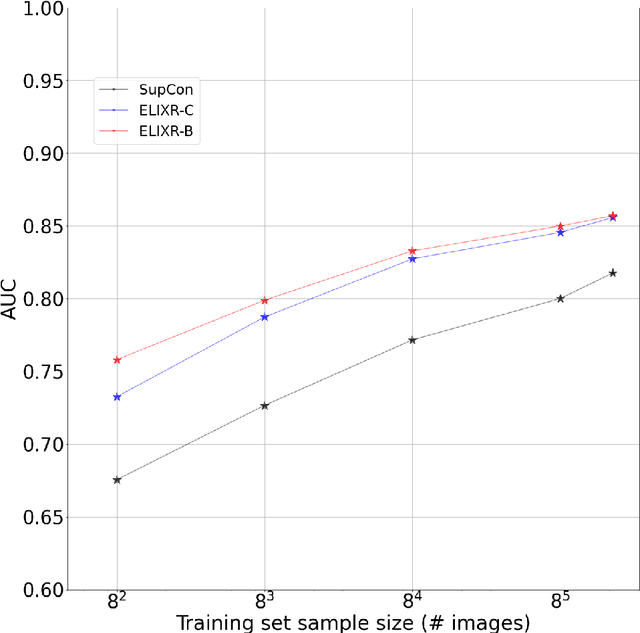
Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
VisoGender: A dataset for benchmarking gender bias in image-text pronoun resolution
Jun 21, 2023We introduce VisoGender, a novel dataset for benchmarking gender bias in vision-language models. We focus on occupation-related gender biases, inspired by Winograd and Winogender schemas, where each image is associated with a caption containing a pronoun relationship of subjects and objects in the scene. VisoGender is balanced by gender representation in professional roles, supporting bias evaluation in two ways: i) resolution bias, where we evaluate the difference between gender resolution accuracies for men and women and ii) retrieval bias, where we compare ratios of male and female professionals retrieved for a gender-neutral search query. We benchmark several state-of-the-art vision-language models and find that they lack the reasoning abilities to correctly resolve gender in complex scenes. While the direction and magnitude of gender bias depends on the task and the model being evaluated, captioning models generally are more accurate and less biased than CLIP-like models. Dataset and code are available at https://github.com/oxai/visogender
DFM-X: Augmentation by Leveraging Prior Knowledge of Shortcut Learning
Aug 12, 2023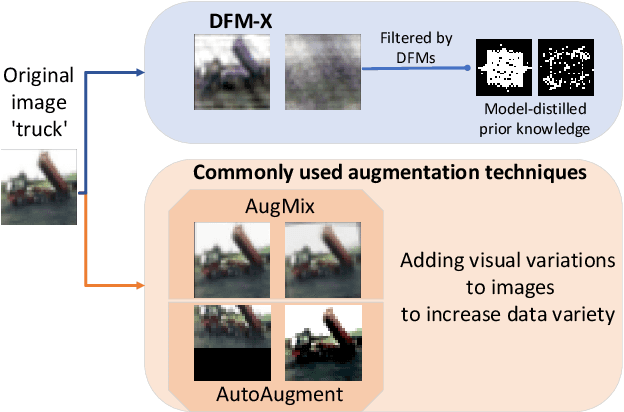
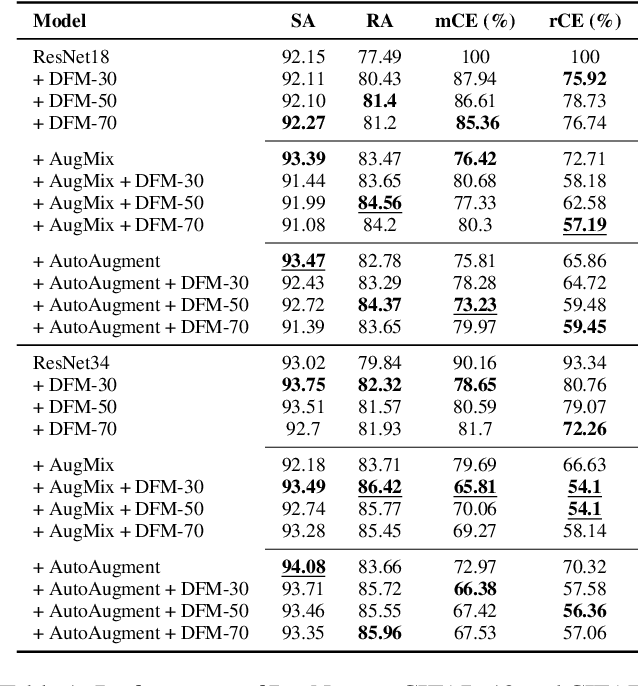
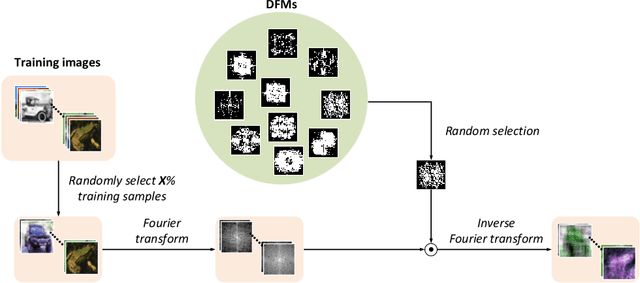
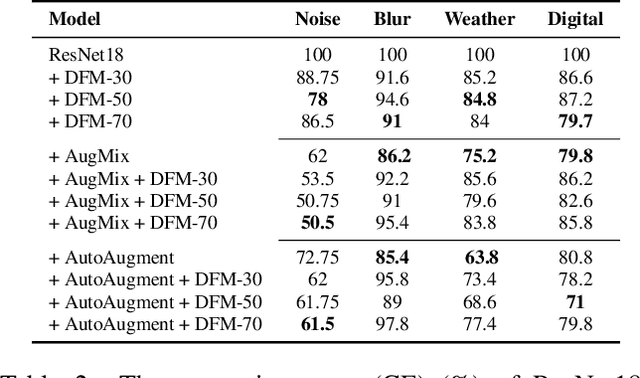
Neural networks are prone to learn easy solutions from superficial statistics in the data, namely shortcut learning, which impairs generalization and robustness of models. We propose a data augmentation strategy, named DFM-X, that leverages knowledge about frequency shortcuts, encoded in Dominant Frequencies Maps computed for image classification models. We randomly select X% training images of certain classes for augmentation, and process them by retaining the frequencies included in the DFMs of other classes. This strategy compels the models to leverage a broader range of frequencies for classification, rather than relying on specific frequency sets. Thus, the models learn more deep and task-related semantics compared to their counterpart trained with standard setups. Unlike other commonly used augmentation techniques which focus on increasing the visual variations of training data, our method targets exploiting the original data efficiently, by distilling prior knowledge about destructive learning behavior of models from data. Our experimental results demonstrate that DFM-X improves robustness against common corruptions and adversarial attacks. It can be seamlessly integrated with other augmentation techniques to further enhance the robustness of models.
Link-Context Learning for Multimodal LLMs
Aug 15, 2023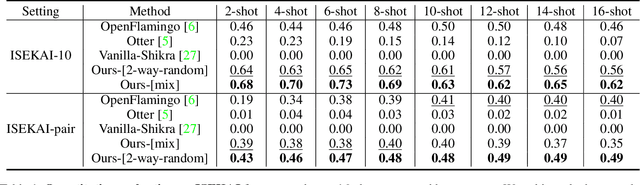
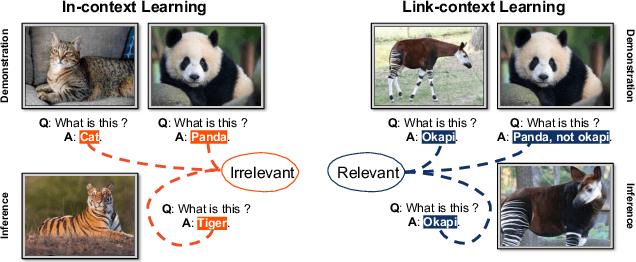
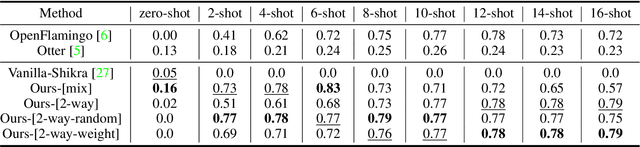
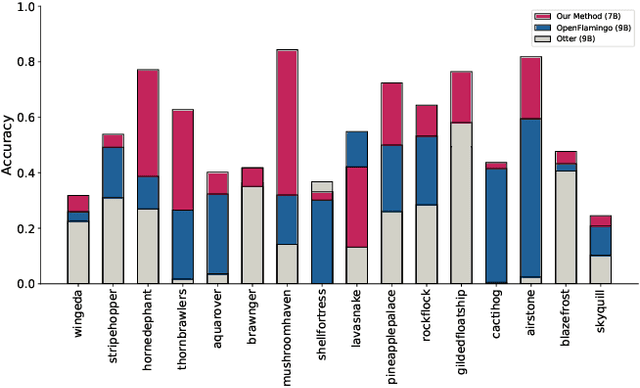
The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations. Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to ``learn to learn" from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes "reasoning from cause and effect" to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. To facilitate the evaluation of this novel approach, we introduce the ISEKAI dataset, comprising exclusively of unseen generated image-label pairs designed for link-context learning. Extensive experiments show that our LCL-MLLM exhibits strong link-context learning capabilities to novel concepts over vanilla MLLMs. Code and data will be released at https://github.com/isekai-portal/Link-Context-Learning.
Helping Hands: An Object-Aware Ego-Centric Video Recognition Model
Aug 15, 2023We introduce an object-aware decoder for improving the performance of spatio-temporal representations on ego-centric videos. The key idea is to enhance object-awareness during training by tasking the model to predict hand positions, object positions, and the semantic label of the objects using paired captions when available. At inference time the model only requires RGB frames as inputs, and is able to track and ground objects (although it has not been trained explicitly for this). We demonstrate the performance of the object-aware representations learnt by our model, by: (i) evaluating it for strong transfer, i.e. through zero-shot testing, on a number of downstream video-text retrieval and classification benchmarks; and (ii) by using the representations learned as input for long-term video understanding tasks (e.g. Episodic Memory in Ego4D). In all cases the performance improves over the state of the art -- even compared to networks trained with far larger batch sizes. We also show that by using noisy image-level detection as pseudo-labels in training, the model learns to provide better bounding boxes using video consistency, as well as grounding the words in the associated text descriptions. Overall, we show that the model can act as a drop-in replacement for an ego-centric video model to improve performance through visual-text grounding.
Enhancing Network Initialization for Medical AI Models Using Large-Scale, Unlabeled Natural Images
Aug 15, 2023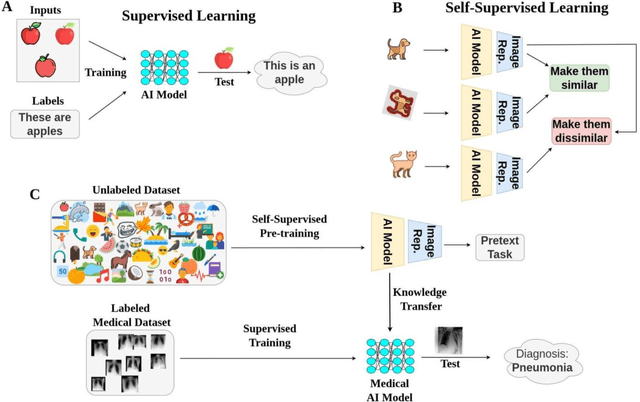
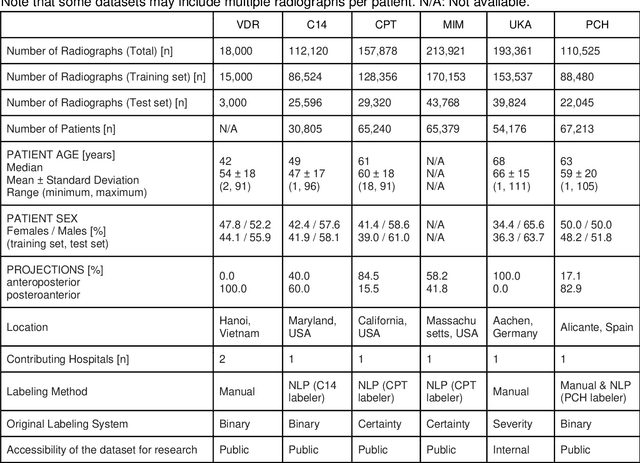
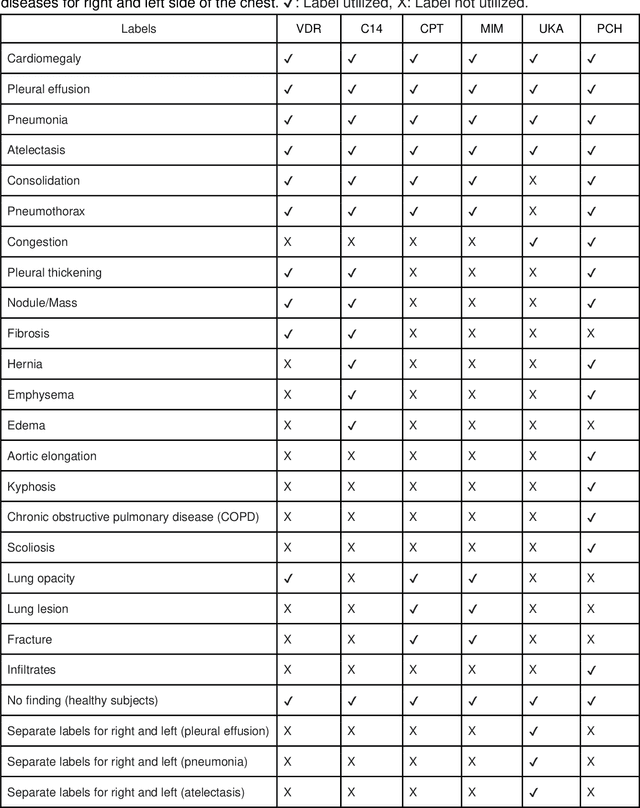
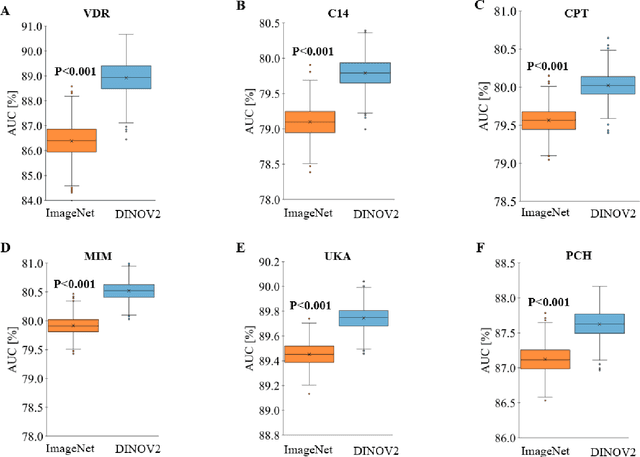
Pre-training datasets, like ImageNet, have become the gold standard in medical image analysis. However, the emergence of self-supervised learning (SSL), which leverages unlabeled data to learn robust features, presents an opportunity to bypass the intensive labeling process. In this study, we explored if SSL for pre-training on non-medical images can be applied to chest radiographs and how it compares to supervised pre-training on non-medical images and on medical images. We utilized a vision transformer and initialized its weights based on (i) SSL pre-training on natural images (DINOv2), (ii) SL pre-training on natural images (ImageNet dataset), and (iii) SL pre-training on chest radiographs from the MIMIC-CXR database. We tested our approach on over 800,000 chest radiographs from six large global datasets, diagnosing more than 20 different imaging findings. Our SSL pre-training on curated images not only outperformed ImageNet-based pre-training (P<0.001 for all datasets) but, in certain cases, also exceeded SL on the MIMIC-CXR dataset. Our findings suggest that selecting the right pre-training strategy, especially with SSL, can be pivotal for improving artificial intelligence (AI)'s diagnostic accuracy in medical imaging. By demonstrating the promise of SSL in chest radiograph analysis, we underline a transformative shift towards more efficient and accurate AI models in medical imaging.
Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach
Aug 15, 2023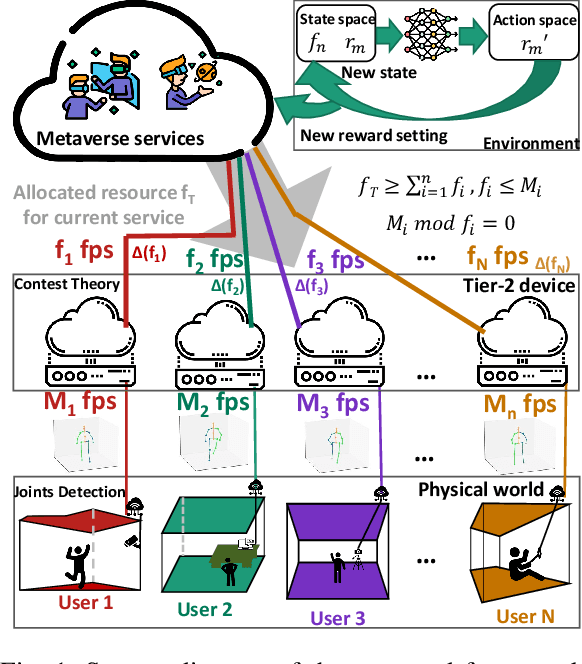
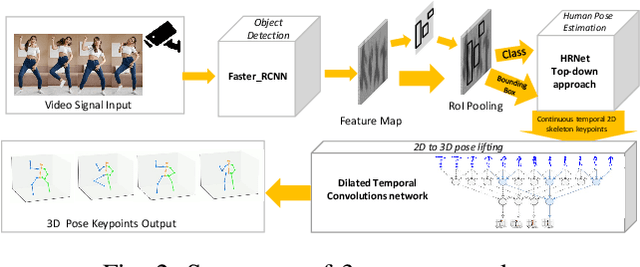
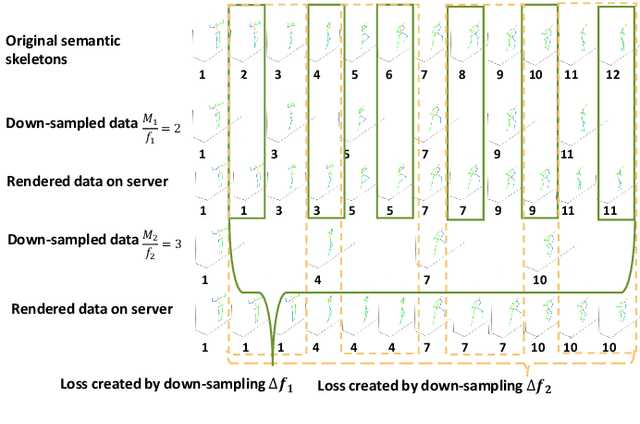
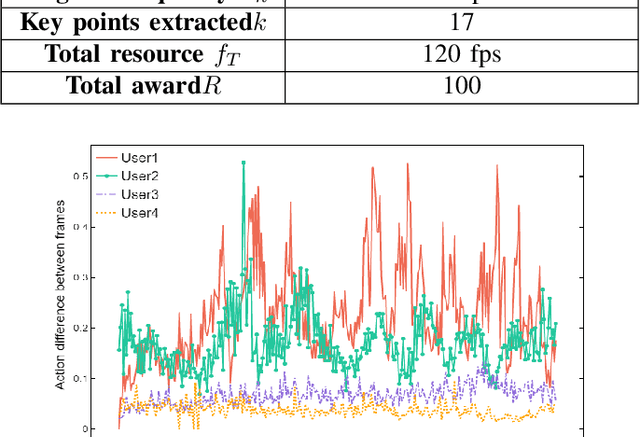
The popularity of Metaverse as an entertainment, social, and work platform has led to a great need for seamless avatar integration in the virtual world. In Metaverse, avatars must be updated and rendered to reflect users' behaviour. Achieving real-time synchronization between the virtual bilocation and the user is complex, placing high demands on the Metaverse Service Provider (MSP)'s rendering resource allocation scheme. To tackle this issue, we propose a semantic communication framework that leverages contest theory to model the interactions between users and MSPs and determine optimal resource allocation for each user. To reduce the consumption of network resources in wireless transmission, we use the semantic communication technique to reduce the amount of data to be transmitted. Under our simulation settings, the encoded semantic data only contains 51 bytes of skeleton coordinates instead of the image size of 8.243 megabytes. Moreover, we implement Deep Q-Network to optimize reward settings for maximum performance and efficient resource allocation. With the optimal reward setting, users are incentivized to select their respective suitable uploading frequency, reducing down-sampling loss due to rendering resource constraints by 66.076\% compared with the traditional average distribution method. The framework provides a novel solution to resource allocation for avatar association in VR environments, ensuring a smooth and immersive experience for all users.
Preliminary Design of the Dragonfly Navigation Filter
Jul 25, 2023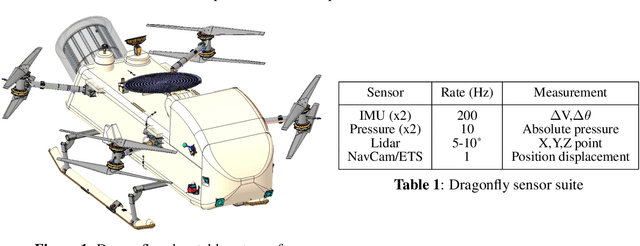


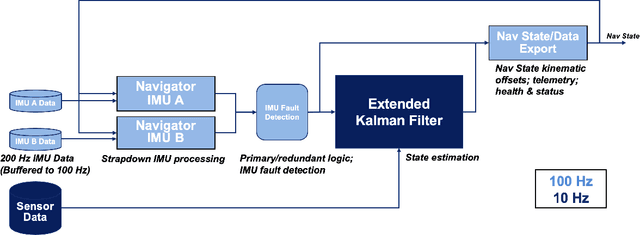
Dragonfly is scheduled to begin exploring Titan by 2034 using a series of multi-kilometer surface flights. This paper outlines the preliminary design of the navigation filter for the Dragonfly Mobility subsystem. The software architecture and filter formulation for lidar, visual odometry, pressure sensors, and redundant IMUs are described in detail. Special discussion is given to developments to achieve multi-kilometer surface flights, including optimizing sequential image baselines, modeling correlating image processing errors, and an efficient approximation to the Simultaneous Localization and Mapping (SLAM) problem.