 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Few-shot Class-Incremental Semantic Segmentation via Pseudo-Labeling and Knowledge Distillation
Aug 05, 2023
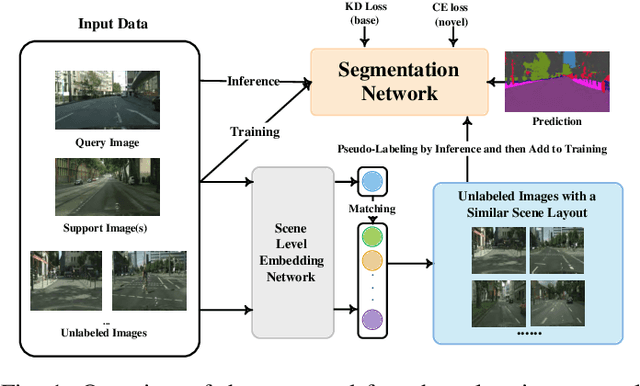


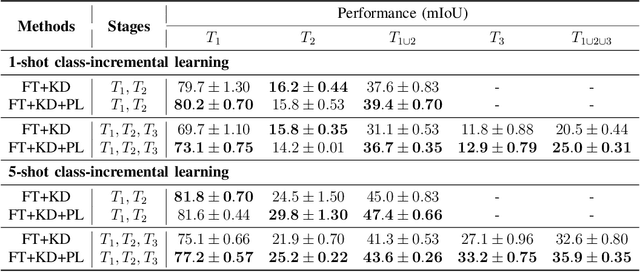
We address the problem of learning new classes for semantic segmentation models from few examples, which is challenging because of the following two reasons. Firstly, it is difficult to learn from limited novel data to capture the underlying class distribution. Secondly, it is challenging to retain knowledge for existing classes and to avoid catastrophic forgetting. For learning from limited data, we propose a pseudo-labeling strategy to augment the few-shot training annotations in order to learn novel classes more effectively. Given only one or a few images labeled with the novel classes and a much larger set of unlabeled images, we transfer the knowledge from labeled images to unlabeled images with a coarse-to-fine pseudo-labeling approach in two steps. Specifically, we first match each labeled image to its nearest neighbors in the unlabeled image set at the scene level, in order to obtain images with a similar scene layout. This is followed by obtaining pseudo-labels within this neighborhood by applying classifiers learned on the few-shot annotations. In addition, we use knowledge distillation on both labeled and unlabeled data to retain knowledge on existing classes. We integrate the above steps into a single convolutional neural network with a unified learning objective. Extensive experiments on the Cityscapes and KITTI datasets validate the efficacy of the proposed approach in the self-driving domain. Code is available from https://github.com/ChasonJiang/FSCILSS.
OmniZoomer: Learning to Move and Zoom in on Sphere at High-Resolution
Aug 16, 2023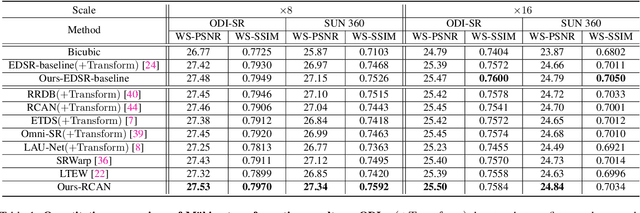
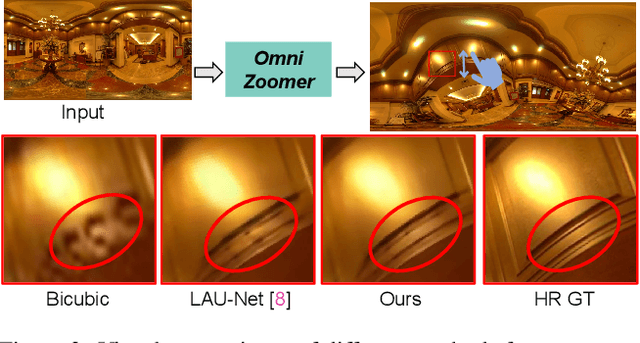
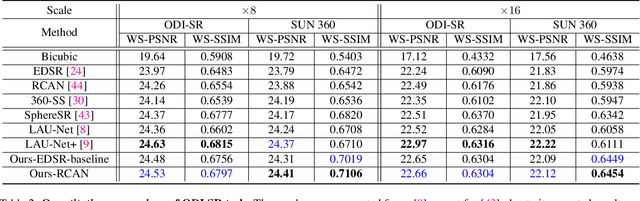
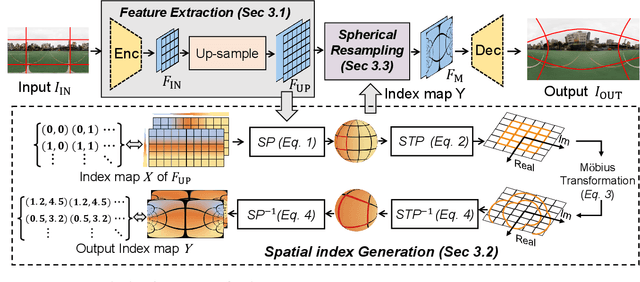
Omnidirectional images (ODIs) have become increasingly popular, as their large field-of-view (FoV) can offer viewers the chance to freely choose the view directions in immersive environments such as virtual reality. The M\"obius transformation is typically employed to further provide the opportunity for movement and zoom on ODIs, but applying it to the image level often results in blurry effect and aliasing problem. In this paper, we propose a novel deep learning-based approach, called \textbf{OmniZoomer}, to incorporate the M\"obius transformation into the network for movement and zoom on ODIs. By learning various transformed feature maps under different conditions, the network is enhanced to handle the increasing edge curvatures, which alleviates the blurry effect. Moreover, to address the aliasing problem, we propose two key components. Firstly, to compensate for the lack of pixels for describing curves, we enhance the feature maps in the high-resolution (HR) space and calculate the transformed index map with a spatial index generation module. Secondly, considering that ODIs are inherently represented in the spherical space, we propose a spherical resampling module that combines the index map and HR feature maps to transform the feature maps for better spherical correlation. The transformed feature maps are decoded to output a zoomed ODI. Experiments show that our method can produce HR and high-quality ODIs with the flexibility to move and zoom in to the object of interest. Project page is available at http://vlislab22.github.io/OmniZoomer/.
Robust Autonomous Vehicle Pursuit without Expert Steering Labels
Aug 16, 2023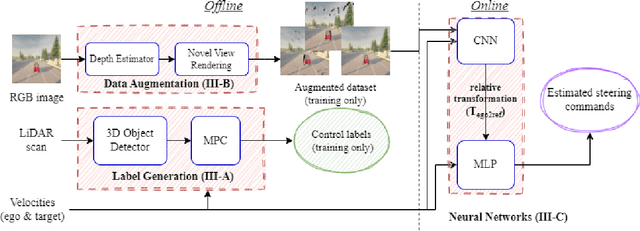

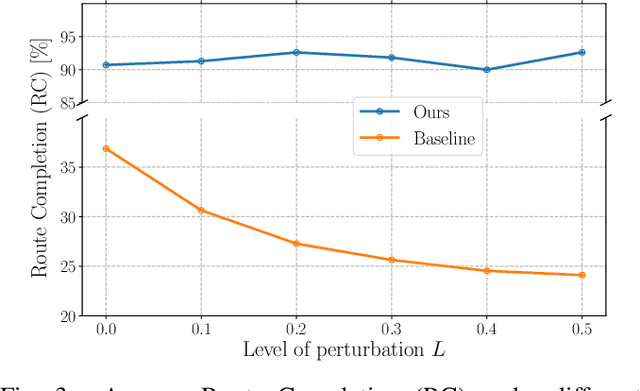
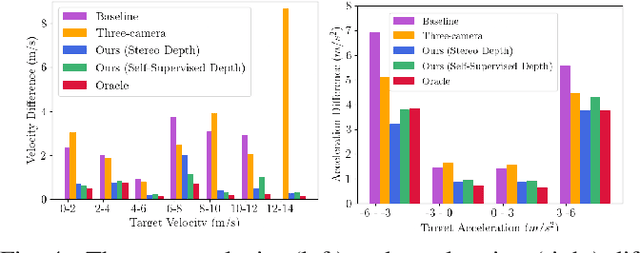
In this work, we present a learning method for lateral and longitudinal motion control of an ego-vehicle for vehicle pursuit. The car being controlled does not have a pre-defined route, rather it reactively adapts to follow a target vehicle while maintaining a safety distance. To train our model, we do not rely on steering labels recorded from an expert driver but effectively leverage a classical controller as an offline label generation tool. In addition, we account for the errors in the predicted control values, which can lead to a loss of tracking and catastrophic crashes of the controlled vehicle. To this end, we propose an effective data augmentation approach, which allows to train a network capable of handling different views of the target vehicle. During the pursuit, the target vehicle is firstly localized using a Convolutional Neural Network. The network takes a single RGB image along with cars' velocities and estimates the target vehicle's pose with respect to the ego-vehicle. This information is then fed to a Multi-Layer Perceptron, which regresses the control commands for the ego-vehicle, namely throttle and steering angle. We extensively validate our approach using the CARLA simulator on a wide range of terrains. Our method demonstrates real-time performance and robustness to different scenarios including unseen trajectories and high route completion. The project page containing code and multimedia can be publicly accessed here: https://changyaozhou.github.io/Autonomous-Vehicle-Pursuit/.
A Comprehensive Overview of Computational Nuclei Segmentation Methods in Digital Pathology
Aug 16, 2023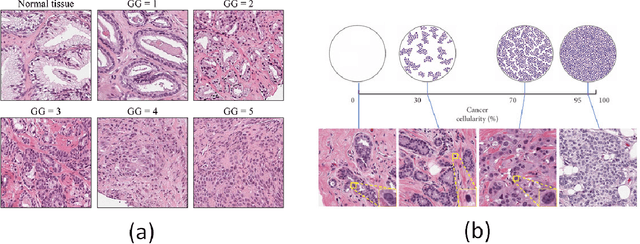

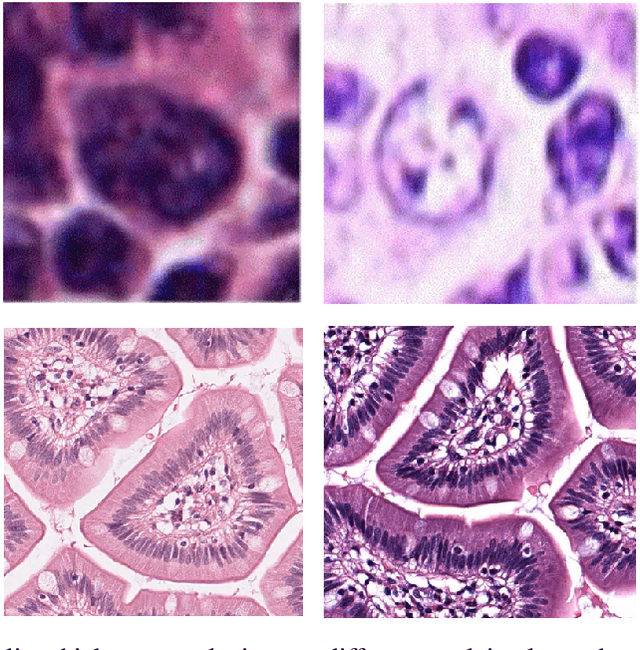
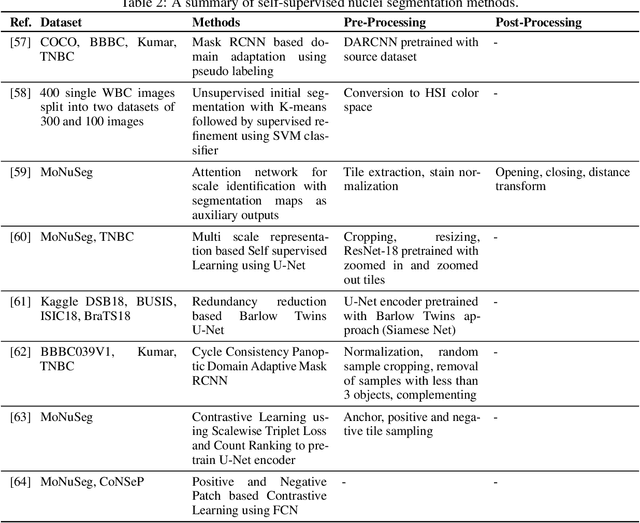
In the cancer diagnosis pipeline, digital pathology plays an instrumental role in the identification, staging, and grading of malignant areas on biopsy tissue specimens. High resolution histology images are subject to high variance in appearance, sourcing either from the acquisition devices or the H\&E staining process. Nuclei segmentation is an important task, as it detects the nuclei cells over background tissue and gives rise to the topology, size, and count of nuclei which are determinant factors for cancer detection. Yet, it is a fairly time consuming task for pathologists, with reportedly high subjectivity. Computer Aided Diagnosis (CAD) tools empowered by modern Artificial Intelligence (AI) models enable the automation of nuclei segmentation. This can reduce the subjectivity in analysis and reading time. This paper provides an extensive review, beginning from earlier works use traditional image processing techniques and reaching up to modern approaches following the Deep Learning (DL) paradigm. Our review also focuses on the weak supervision aspect of the problem, motivated by the fact that annotated data is scarce. At the end, the advantages of different models and types of supervision are thoroughly discussed. Furthermore, we try to extrapolate and envision how future research lines will potentially be, so as to minimize the need for labeled data while maintaining high performance. Future methods should emphasize efficient and explainable models with a transparent underlying process so that physicians can trust their output.
Limitations of Out-of-Distribution Detection in 3D Medical Image Segmentation
Jun 23, 2023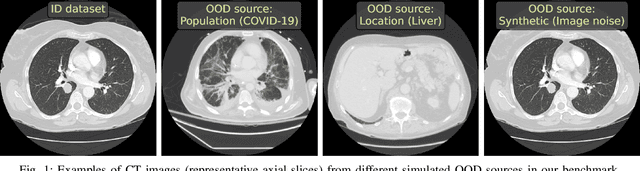
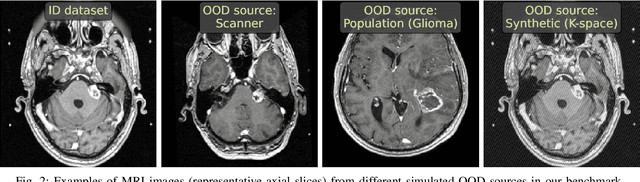
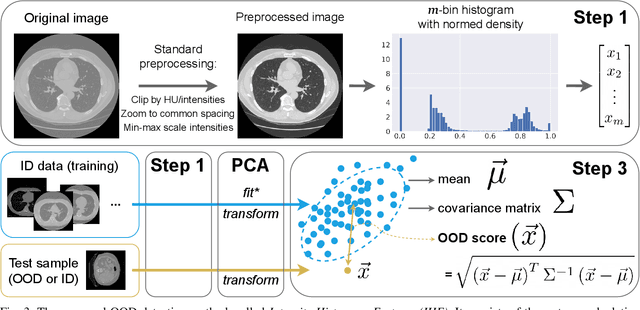
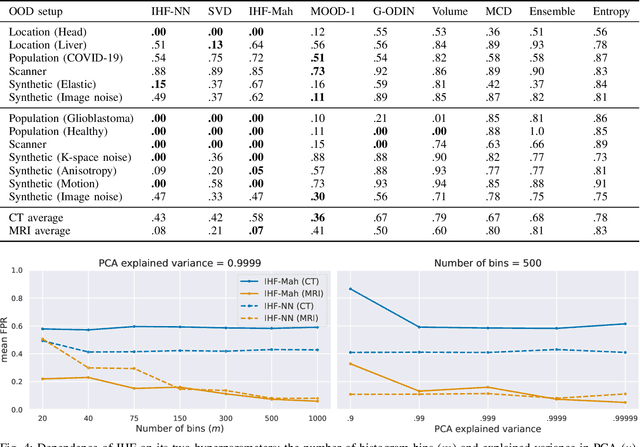
Deep Learning models perform unreliably when the data comes from a distribution different from the training one. In critical applications such as medical imaging, out-of-distribution (OOD) detection methods help to identify such data samples, preventing erroneous predictions. In this paper, we further investigate the OOD detection effectiveness when applied to 3D medical image segmentation. We design several OOD challenges representing clinically occurring cases and show that none of these methods achieve acceptable performance. Methods not dedicated to segmentation severely fail to perform in the designed setups; their best mean false positive rate at 95% true positive rate (FPR) is 0.59. Segmentation-dedicated ones still achieve suboptimal performance, with the best mean FPR of 0.31 (lower is better). To indicate this suboptimality, we develop a simple method called Intensity Histogram Features (IHF), which performs comparable or better in the same challenges, with a mean FPR of 0.25. Our findings highlight the limitations of the existing OOD detection methods on 3D medical images and present a promising avenue for improving them. To facilitate research in this area, we release the designed challenges as a publicly available benchmark and formulate practical criteria to test the OOD detection generalization beyond the suggested benchmark. We also propose IHF as a solid baseline to contest the emerging methods.
ViT2EEG: Leveraging Hybrid Pretrained Vision Transformers for EEG Data
Aug 01, 2023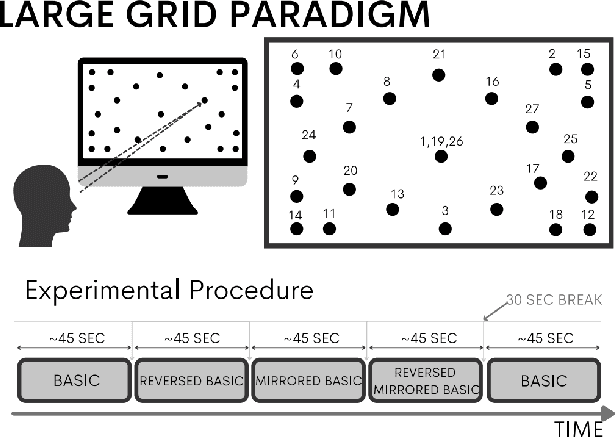
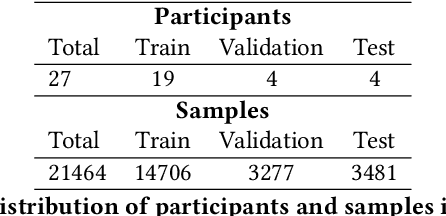
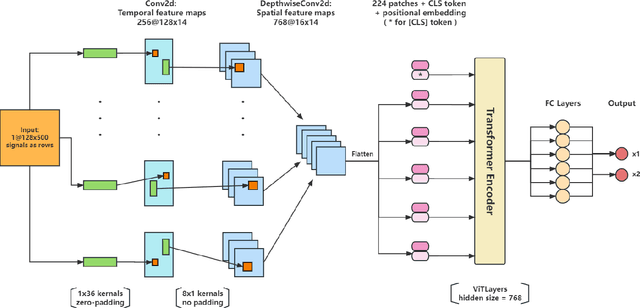

In this study, we demonstrate the application of a hybrid Vision Transformer (ViT) model, pretrained on ImageNet, on an electroencephalogram (EEG) regression task. Despite being originally trained for image classification tasks, when fine-tuned on EEG data, this model shows a notable increase in performance compared to other models, including an identical architecture ViT trained without the ImageNet weights. This discovery challenges the traditional understanding of model generalization, suggesting that Transformer models pretrained on seemingly unrelated image data can provide valuable priors for EEG regression tasks with an appropriate fine-tuning pipeline. The success of this approach suggests that the features extracted by ViT models in the context of visual tasks can be readily transformed for the purpose of EEG predictive modeling. We recommend utilizing this methodology not only in neuroscience and related fields, but generally for any task where data collection is limited by practical, financial, or ethical constraints. Our results illuminate the potential of pretrained models on tasks that are clearly distinct from their original purpose.
Visibility Enhancement for Low-light Hazy Scenarios
Aug 01, 2023
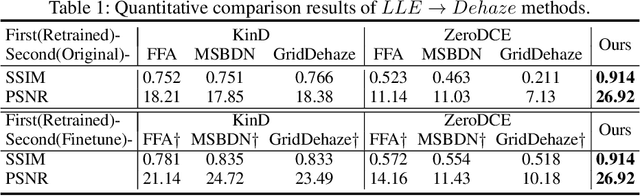
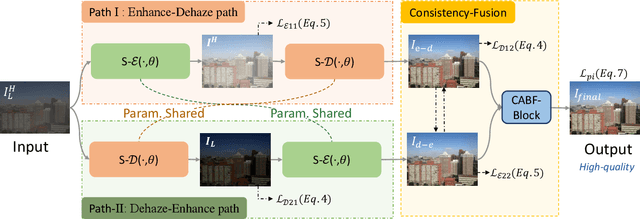
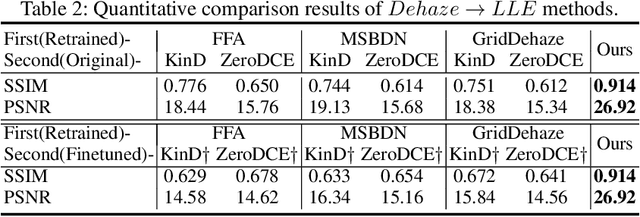
Low-light hazy scenes commonly appear at dusk and early morning. The visual enhancement for low-light hazy images is an ill-posed problem. Even though numerous methods have been proposed for image dehazing and low-light enhancement respectively, simply integrating them cannot deliver pleasing results for this particular task. In this paper, we present a novel method to enhance visibility for low-light hazy scenarios. To handle this challenging task, we propose two key techniques, namely cross-consistency dehazing-enhancement framework and physically based simulation for low-light hazy dataset. Specifically, the framework is designed for enhancing visibility of the input image via fully utilizing the clues from different sub-tasks. The simulation is designed for generating the dataset with ground-truths by the proposed low-light hazy imaging model. The extensive experimental results show that the proposed method outperforms the SOTA solutions on different metrics including SSIM (9.19%) and PSNR(5.03%). In addition, we conduct a user study on real images to demonstrate the effectiveness and necessity of the proposed method by human visual perception.
Kidnapping Deep Learning-based Multirotors using Optimized Flying Adversarial Patches
Aug 01, 2023
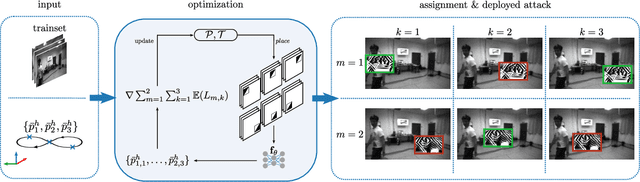
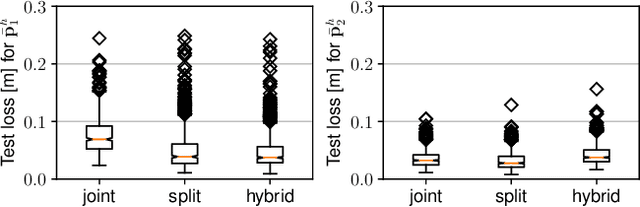
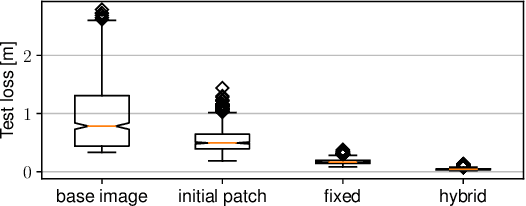
Autonomous flying robots, such as multirotors, often rely on deep learning models that makes predictions based on a camera image, e.g. for pose estimation. These models can predict surprising results if applied to input images outside the training domain. This fault can be exploited by adversarial attacks, for example, by computing small images, so-called adversarial patches, that can be placed in the environment to manipulate the neural network's prediction. We introduce flying adversarial patches, where multiple images are mounted on at least one other flying robot and therefore can be placed anywhere in the field of view of a victim multirotor. By introducing the attacker robots, the system is extended to an adversarial multi-robot system. For an effective attack, we compare three methods that simultaneously optimize multiple adversarial patches and their position in the input image. We show that our methods scale well with the number of adversarial patches. Moreover, we demonstrate physical flights with two robots, where we employ a novel attack policy that uses the computed adversarial patches to kidnap a robot that was supposed to follow a human.
Learning to Generate Training Datasets for Robust Semantic Segmentation
Aug 01, 2023
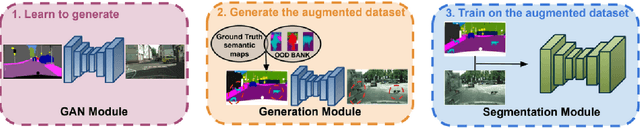
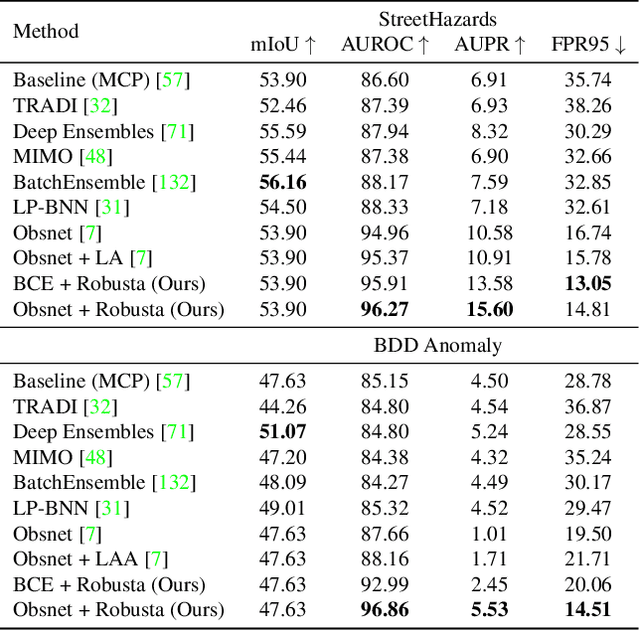
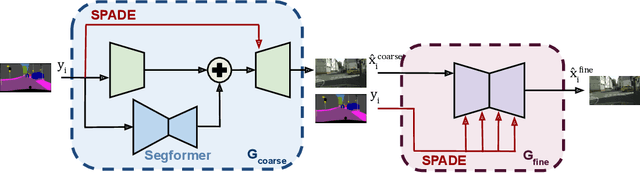
Semantic segmentation techniques have shown significant progress in recent years, but their robustness to real-world perturbations and data samples not seen during training remains a challenge, particularly in safety-critical applications. In this paper, we propose a novel approach to improve the robustness of semantic segmentation techniques by leveraging the synergy between label-to-image generators and image-to-label segmentation models. Specifically, we design and train Robusta, a novel robust conditional generative adversarial network to generate realistic and plausible perturbed or outlier images that can be used to train reliable segmentation models. We conduct in-depth studies of the proposed generative model, assess the performance and robustness of the downstream segmentation network, and demonstrate that our approach can significantly enhance the robustness of semantic segmentation techniques in the face of real-world perturbations, distribution shifts, and out-of-distribution samples. Our results suggest that this approach could be valuable in safety-critical applications, where the reliability of semantic segmentation techniques is of utmost importance and comes with a limited computational budget in inference. We will release our code shortly.
Motion-robust free-running cardiovascular MRI
Aug 04, 2023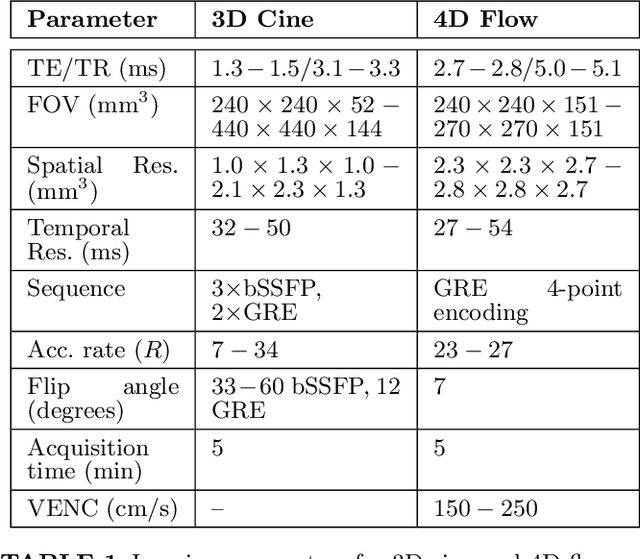
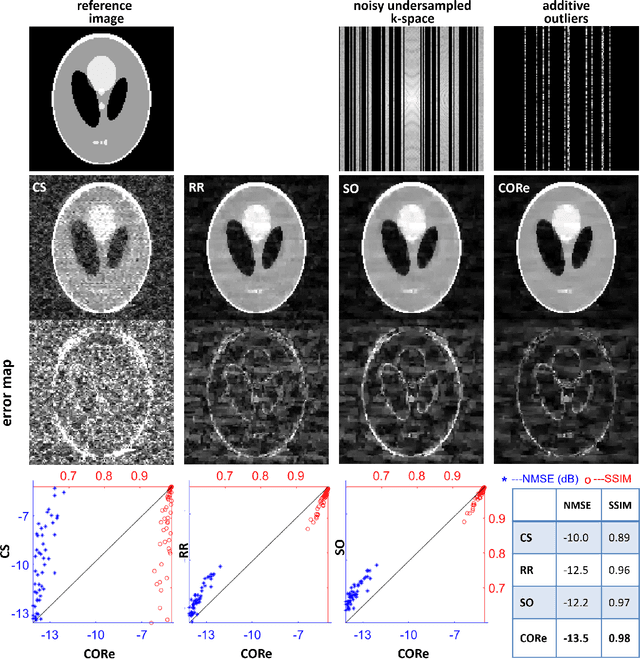
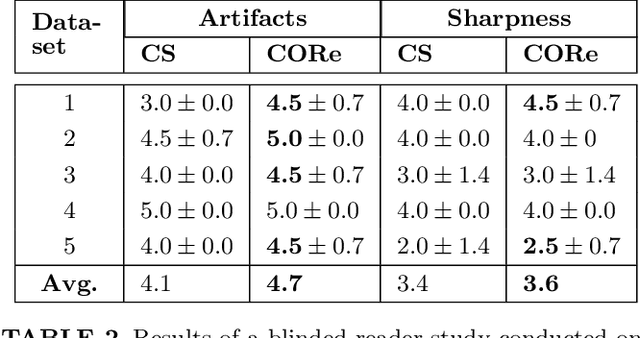
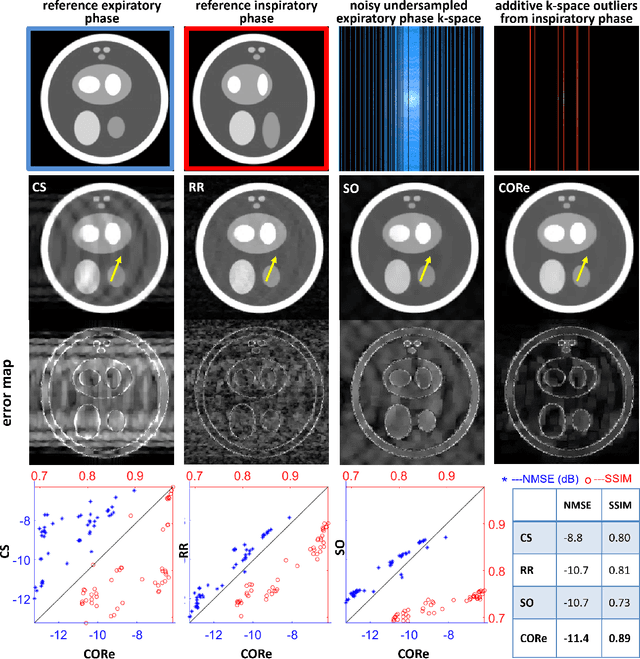
PURPOSE: To present and validate an outlier rejection method that makes free-running cardiovascular MRI (CMR) more motion robust. METHODS: The proposed method, called compressive recovery with outlier rejection (CORe), models outliers as an auxiliary variable that is added to the measured data. We enforce MR physics-guided group-sparsity on the auxiliary variable and jointly estimate it along with the image using an iterative algorithm. For validation, CORe is first compared to traditional compressed sensing (CS), robust regression (RR), and another outlier rejection method using two simulation studies. Then, CORe is compared to CS using five 3D cine and ten rest and stress 4D flow imaging datasets. RESULTS: Our simulation studies show that CORe outperforms CS, RR, and the outlier rejection method in terms of normalized mean squared error (NMSE) and structural similarity index (SSIM) across 50 different realizations. The expert reader evaluation of 3D cine images demonstrates that CORe is more effective in suppressing artifacts while maintaining or improving image sharpness. The flow consistency evaluation in 4D flow images show that CORe yields more consistent flow measurements, especially under exercise stress. CONCLUSION: An outlier rejection method is presented and validated using simulated and measured data. This method can help suppress motion artifacts in a wide range of free-running CMR applications. CODE: MATLAB implementation code is available on GitHub at https://github.com/syedmurtazaarshad/motion-robust-CMR