 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SegMatch: A semi-supervised learning method for surgical instrument segmentation
Aug 09, 2023
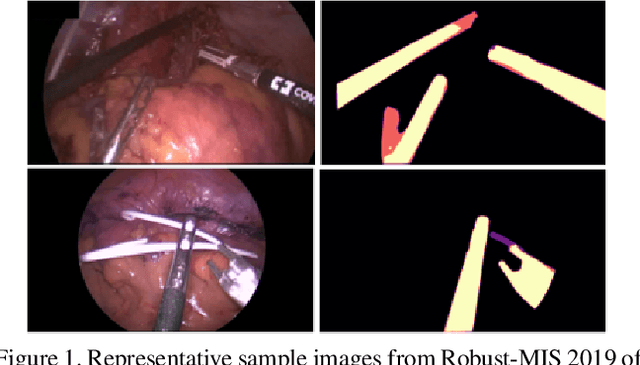
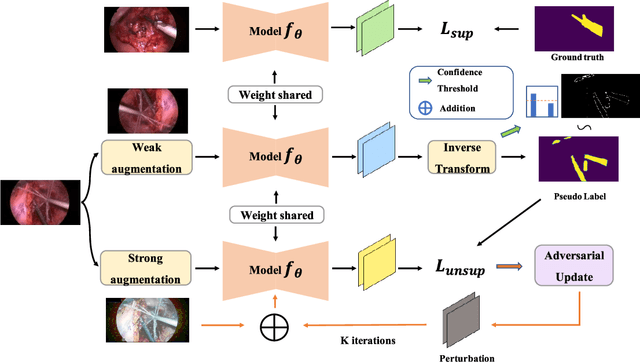
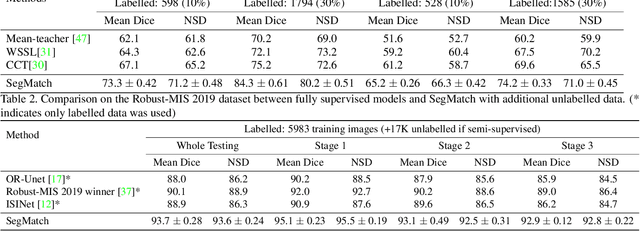
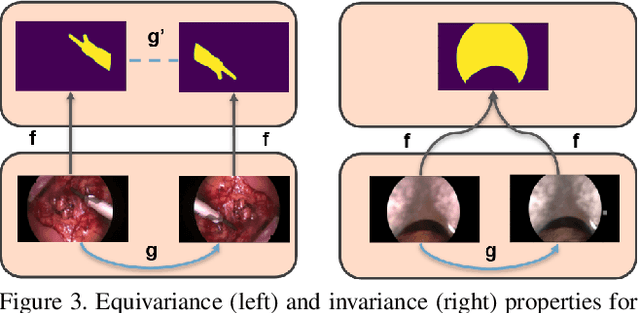
Surgical instrument segmentation is recognised as a key enabler to provide advanced surgical assistance and improve computer assisted interventions. In this work, we propose SegMatch, a semi supervised learning method to reduce the need for expensive annotation for laparoscopic and robotic surgical images. SegMatch builds on FixMatch, a widespread semi supervised classification pipeline combining consistency regularization and pseudo labelling, and adapts it for the purpose of segmentation. In our proposed SegMatch, the unlabelled images are weakly augmented and fed into the segmentation model to generate a pseudo-label to enforce the unsupervised loss against the output of the model for the adversarial augmented image on the pixels with a high confidence score. Our adaptation for segmentation tasks includes carefully considering the equivariance and invariance properties of the augmentation functions we rely on. To increase the relevance of our augmentations, we depart from using only handcrafted augmentations and introduce a trainable adversarial augmentation strategy. Our algorithm was evaluated on the MICCAI Instrument Segmentation Challenge datasets Robust-MIS 2019 and EndoVis 2017. Our results demonstrate that adding unlabelled data for training purposes allows us to surpass the performance of fully supervised approaches which are limited by the availability of training data in these challenges. SegMatch also outperforms a range of state-of-the-art semi-supervised learning semantic segmentation models in different labelled to unlabelled data ratios.
Normalization-Equivariant Neural Networks with Application to Image Denoising
Jun 08, 2023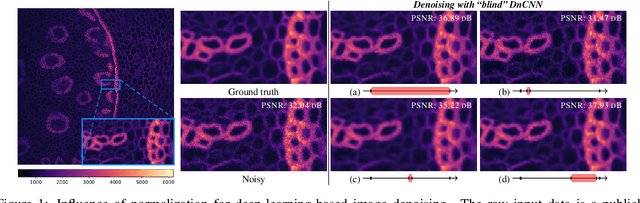

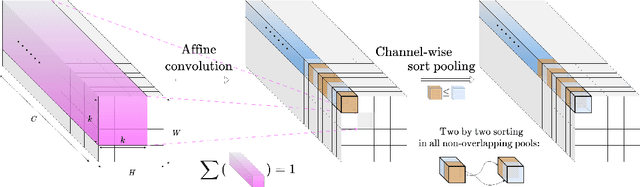
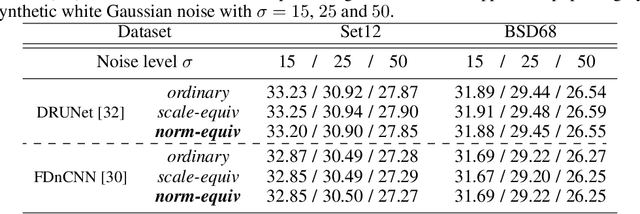
In many information processing systems, it may be desirable to ensure that any change of the input, whether by shifting or scaling, results in a corresponding change in the system response. While deep neural networks are gradually replacing all traditional automatic processing methods, they surprisingly do not guarantee such normalization-equivariance (scale + shift) property, which can be detrimental in many applications. To address this issue, we propose a methodology for adapting existing neural networks so that normalization-equivariance holds by design. Our main claim is that not only ordinary convolutional layers, but also all activation functions, including the ReLU (rectified linear unit), which are applied element-wise to the pre-activated neurons, should be completely removed from neural networks and replaced by better conditioned alternatives. To this end, we introduce affine-constrained convolutions and channel-wise sort pooling layers as surrogates and show that these two architectural modifications do preserve normalization-equivariance without loss of performance. Experimental results in image denoising show that normalization-equivariant neural networks, in addition to their better conditioning, also provide much better generalization across noise levels.
Memory Encoding Model
Aug 02, 2023We explore a new class of brain encoding model by adding memory-related information as input. Memory is an essential brain mechanism that works alongside visual stimuli. During a vision-memory cognitive task, we found the non-visual brain is largely predictable using previously seen images. Our Memory Encoding Model (Mem) won the Algonauts 2023 visual brain competition even without model ensemble (single model score 66.8, ensemble score 70.8). Our ensemble model without memory input (61.4) can also stand a 3rd place. Furthermore, we observe periodic delayed brain response correlated to 6th-7th prior image, and hippocampus also showed correlated activity timed with this periodicity. We conjuncture that the periodic replay could be related to memory mechanism to enhance the working memory.
Learning Concise and Descriptive Attributes for Visual Recognition
Aug 07, 2023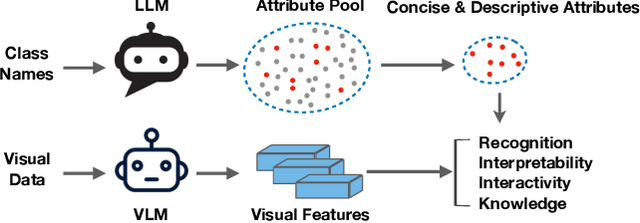
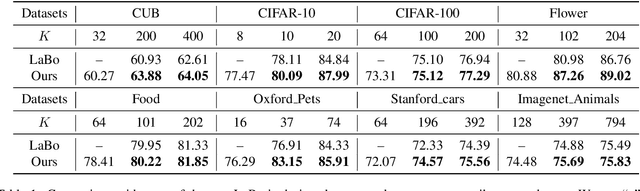
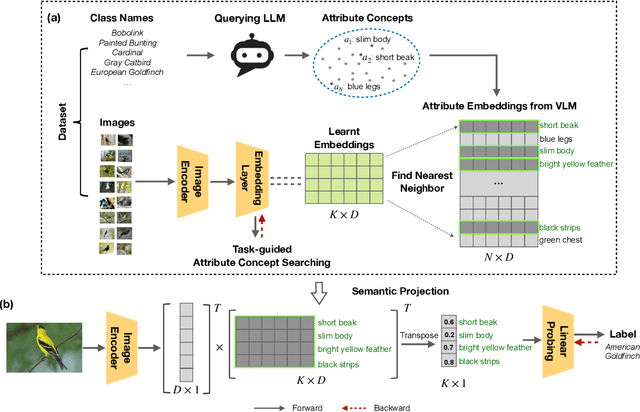
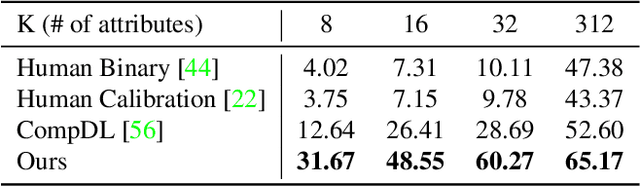
Recent advances in foundation models present new opportunities for interpretable visual recognition -- one can first query Large Language Models (LLMs) to obtain a set of attributes that describe each class, then apply vision-language models to classify images via these attributes. Pioneering work shows that querying thousands of attributes can achieve performance competitive with image features. However, our further investigation on 8 datasets reveals that LLM-generated attributes in a large quantity perform almost the same as random words. This surprising finding suggests that significant noise may be present in these attributes. We hypothesize that there exist subsets of attributes that can maintain the classification performance with much smaller sizes, and propose a novel learning-to-search method to discover those concise sets of attributes. As a result, on the CUB dataset, our method achieves performance close to that of massive LLM-generated attributes (e.g., 10k attributes for CUB), yet using only 32 attributes in total to distinguish 200 bird species. Furthermore, our new paradigm demonstrates several additional benefits: higher interpretability and interactivity for humans, and the ability to summarize knowledge for a recognition task.
Fixed Inter-Neuron Covariability Induces Adversarial Robustness
Aug 07, 2023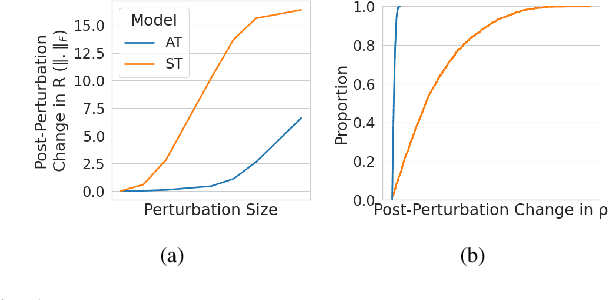
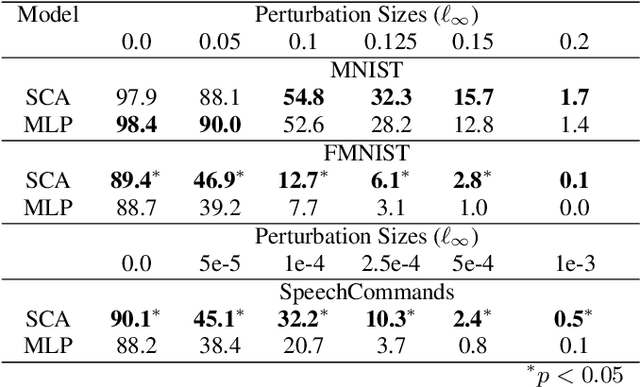
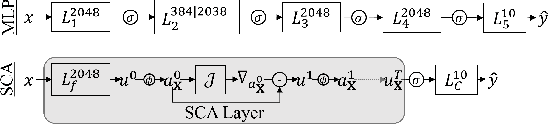
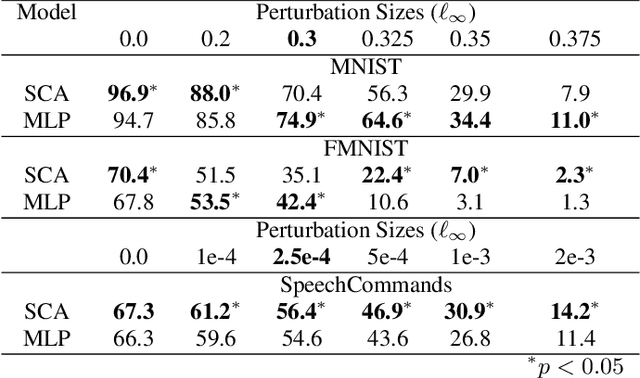
The vulnerability to adversarial perturbations is a major flaw of Deep Neural Networks (DNNs) that raises question about their reliability when in real-world scenarios. On the other hand, human perception, which DNNs are supposed to emulate, is highly robust to such perturbations, indicating that there may be certain features of the human perception that make it robust but are not represented in the current class of DNNs. One such feature is that the activity of biological neurons is correlated and the structure of this correlation tends to be rather rigid over long spans of times, even if it hampers performance and learning. We hypothesize that integrating such constraints on the activations of a DNN would improve its adversarial robustness, and, to test this hypothesis, we have developed the Self-Consistent Activation (SCA) layer, which comprises of neurons whose activations are consistent with each other, as they conform to a fixed, but learned, covariability pattern. When evaluated on image and sound recognition tasks, the models with a SCA layer achieved high accuracy, and exhibited significantly greater robustness than multi-layer perceptron models to state-of-the-art Auto-PGD adversarial attacks \textit{without being trained on adversarially perturbed data
Screen-based 3D Subjective Experiment Software
Aug 07, 2023
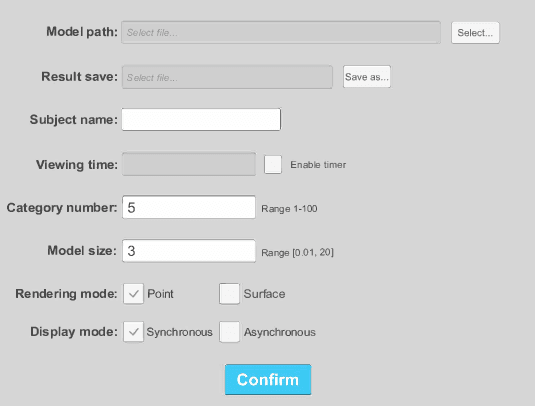

Recently, widespread 3D graphics (e.g., point clouds and meshes) have drawn considerable efforts from academia and industry to assess their perceptual quality by conducting subjective experiments. However, lacking a handy software for 3D subjective experiments complicates the construction of 3D graphics quality assessment datasets, thus hindering the prosperity of relevant fields. In this paper, we develop a powerful platform with which users can flexibly design their 3D subjective methodologies and build high-quality datasets, easing a broad spectrum of 3D graphics subjective quality study. To accurately illustrate the perceptual quality differences of 3D stimuli, our software can simultaneously render the source stimulus and impaired stimulus and allows both stimuli to respond synchronously to viewer interactions. Compared with amateur 3D visualization tool-based or image/video rendering-based schemes, our approach embodies typical 3D applications while minimizing cognitive overload during subjective experiments. We organized a subjective experiment involving 40 participants to verify the validity of the proposed software. Experimental analyses demonstrate that subjective tests on our software can produce reasonable subjective quality scores of 3D models. All resources in this paper can be found at https://openi.pcl.ac.cn/OpenDatasets/3DQA.
Deterministic Neural Illumination Mapping for Efficient Auto-White Balance Correction
Aug 07, 2023Auto-white balance (AWB) correction is a critical operation in image signal processors for accurate and consistent color correction across various illumination scenarios. This paper presents a novel and efficient AWB correction method that achieves at least 35 times faster processing with equivalent or superior performance on high-resolution images for the current state-of-the-art methods. Inspired by deterministic color style transfer, our approach introduces deterministic illumination color mapping, leveraging learnable projection matrices for both canonical illumination form and AWB-corrected output. It involves feeding high-resolution images and corresponding latent representations into a mapping module to derive a canonical form, followed by another mapping module that maps the pixel values to those for the corrected version. This strategy is designed as resolution-agnostic and also enables seamless integration of any pre-trained AWB network as the backbone. Experimental results confirm the effectiveness of our approach, revealing significant performance improvements and reduced time complexity compared to state-of-the-art methods. Our method provides an efficient deep learning-based AWB correction solution, promising real-time, high-quality color correction for digital imaging applications. Source code is available at https://github.com/birdortyedi/DeNIM/
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 08, 2023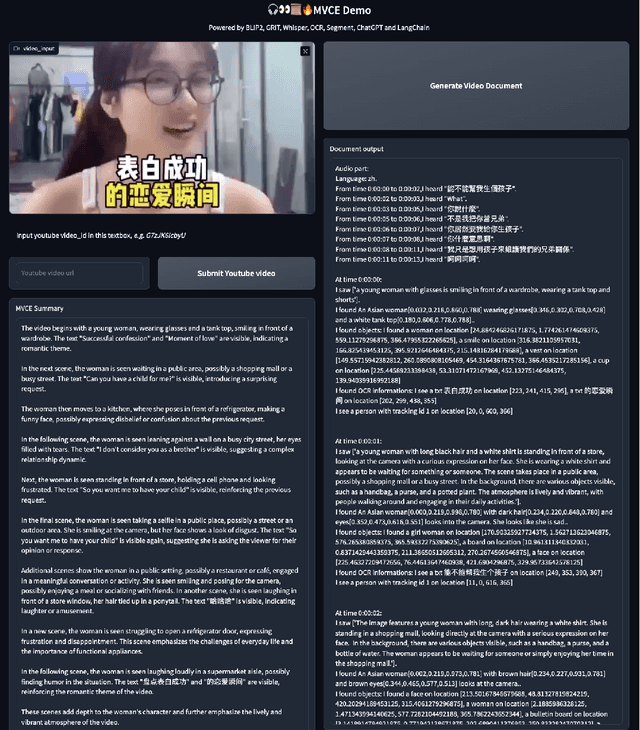
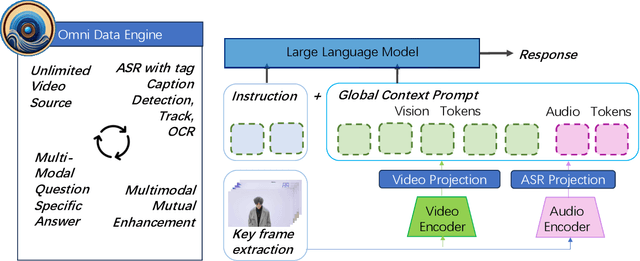

This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Application for White Spot Syndrome Virus (WSSV) Monitoring using Edge Machine Learning
Aug 08, 2023The aquaculture industry, strongly reliant on shrimp exports, faces challenges due to viral infections like the White Spot Syndrome Virus (WSSV) that severely impact output yields. In this context, computer vision can play a significant role in identifying features not immediately evident to skilled or untrained eyes, potentially reducing the time required to report WSSV infections. In this study, the challenge of limited data for WSSV recognition was addressed. A mobile application dedicated to data collection and monitoring was developed to facilitate the creation of an image dataset to train a WSSV recognition model and improve country-wide disease surveillance. The study also includes a thorough analysis of WSSV recognition to address the challenge of imbalanced learning and on-device inference. The models explored, MobileNetV3-Small and EfficientNetV2-B0, gained an F1-Score of 0.72 and 0.99 respectively. The saliency heatmaps of both models were also observed to uncover the "black-box" nature of these models and to gain insight as to what features in the images are most important in making a prediction. These results highlight the effectiveness and limitations of using models designed for resource-constrained devices and balancing their performance in accurately recognizing WSSV, providing valuable information and direction in the use of computer vision in this domain.
Asynchronous Evolution of Deep Neural Network Architectures
Aug 08, 2023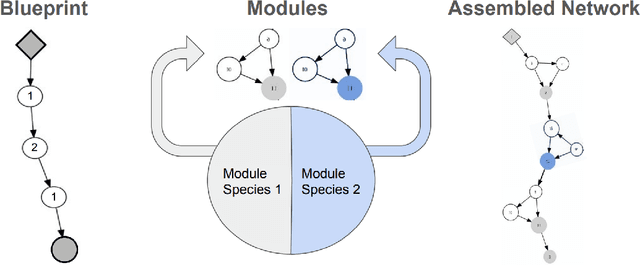
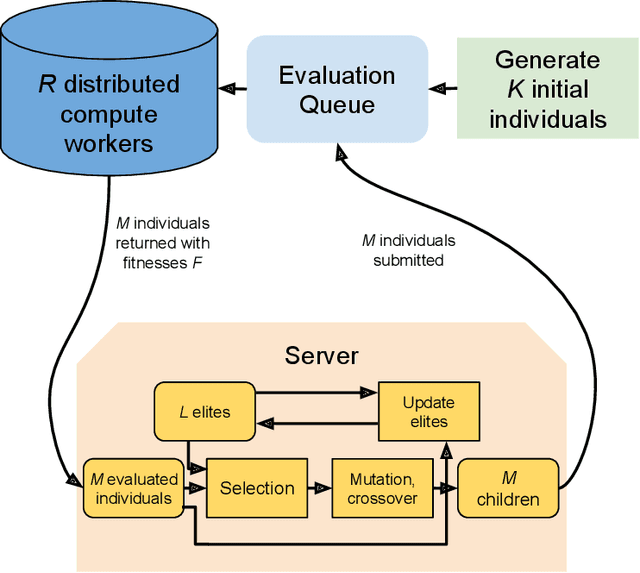
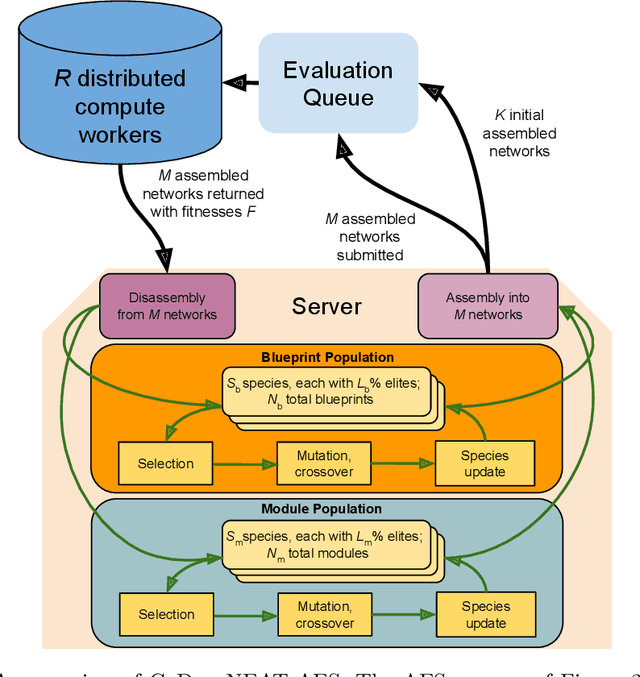
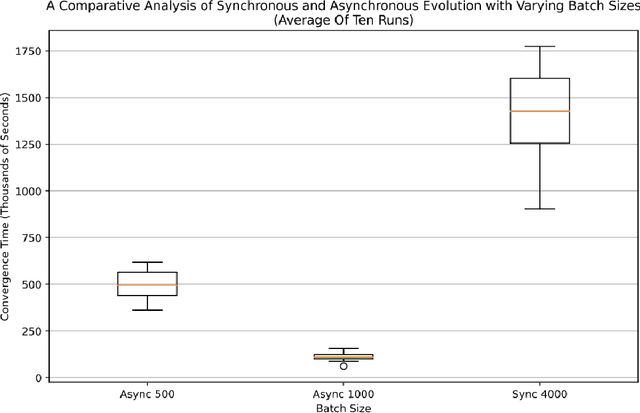
Many evolutionary algorithms (EAs) take advantage of parallel evaluation of candidates. However, if evaluation times vary significantly, many worker nodes (i.e.,\ compute clients) are idle much of the time, waiting for the next generation to be created. Evolutionary neural architecture search (ENAS), a class of EAs that optimizes the architecture and hyperparameters of deep neural networks, is particularly vulnerable to this issue. This paper proposes a generic asynchronous evaluation strategy (AES) that is then adapted to work with ENAS. AES increases throughput by maintaining a queue of upto $K$ individuals ready to be sent to the workers for evaluation and proceeding to the next generation as soon as $M<<K$ individuals have been evaluated by the workers. A suitable value for $M$ is determined experimentally, balancing diversity and efficiency. To showcase the generality and power of AES, it was first evaluated in 11-bit multiplexer design (a single-population verifiable discovery task) and then scaled up to ENAS for image captioning (a multi-population open-ended-optimization task). In both problems, a multifold performance improvement was observed, suggesting that AES is a promising method for parallelizing the evolution of complex systems with long and variable evaluation times, such as those in ENAS.