 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Unseen Triples: Effective Text-Image-joint Learning for Scene Graph Generation
Jun 23, 2023
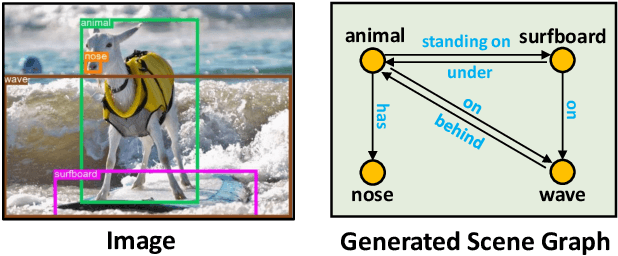
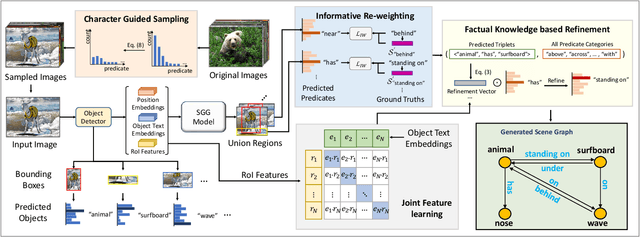


Scene Graph Generation (SGG) aims to structurally and comprehensively represent objects and their connections in images, it can significantly benefit scene understanding and other related downstream tasks. Existing SGG models often struggle to solve the long-tailed problem caused by biased datasets. However, even if these models can fit specific datasets better, it may be hard for them to resolve the unseen triples which are not included in the training set. Most methods tend to feed a whole triple and learn the overall features based on statistical machine learning. Such models have difficulty predicting unseen triples because the objects and predicates in the training set are combined differently as novel triples in the test set. In this work, we propose a Text-Image-joint Scene Graph Generation (TISGG) model to resolve the unseen triples and improve the generalisation capability of the SGG models. We propose a Joint Fearture Learning (JFL) module and a Factual Knowledge based Refinement (FKR) module to learn object and predicate categories separately at the feature level and align them with corresponding visual features so that the model is no longer limited to triples matching. Besides, since we observe the long-tailed problem also affects the generalization ability, we design a novel balanced learning strategy, including a Charater Guided Sampling (CGS) and an Informative Re-weighting (IR) module, to provide tailor-made learning methods for each predicate according to their characters. Extensive experiments show that our model achieves state-of-the-art performance. In more detail, TISGG boosts the performances by 11.7% of zR@20(zero-shot recall) on the PredCls sub-task on the Visual Genome dataset.
On the Fly Neural Style Smoothing for Risk-Averse Domain Generalization
Jul 17, 2023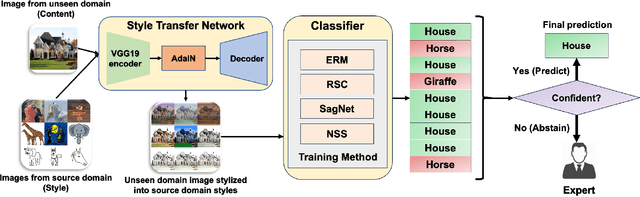
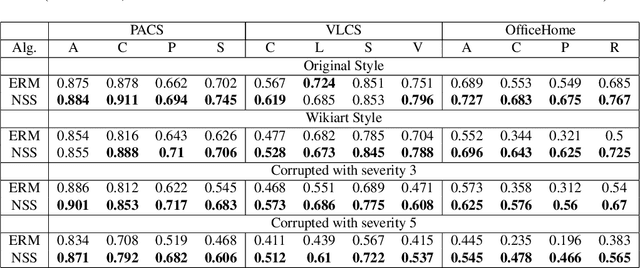
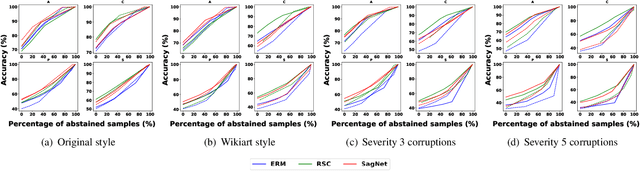
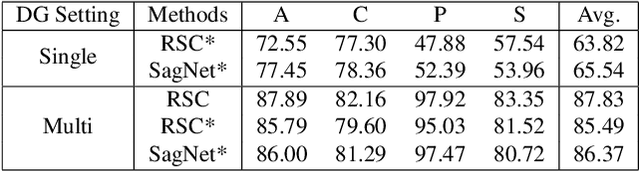
Achieving high accuracy on data from domains unseen during training is a fundamental challenge in domain generalization (DG). While state-of-the-art DG classifiers have demonstrated impressive performance across various tasks, they have shown a bias towards domain-dependent information, such as image styles, rather than domain-invariant information, such as image content. This bias renders them unreliable for deployment in risk-sensitive scenarios such as autonomous driving where a misclassification could lead to catastrophic consequences. To enable risk-averse predictions from a DG classifier, we propose a novel inference procedure, Test-Time Neural Style Smoothing (TT-NSS), that uses a "style-smoothed" version of the DG classifier for prediction at test time. Specifically, the style-smoothed classifier classifies a test image as the most probable class predicted by the DG classifier on random re-stylizations of the test image. TT-NSS uses a neural style transfer module to stylize a test image on the fly, requires only black-box access to the DG classifier, and crucially, abstains when predictions of the DG classifier on the stylized test images lack consensus. Additionally, we propose a neural style smoothing (NSS) based training procedure that can be seamlessly integrated with existing DG methods. This procedure enhances prediction consistency, improving the performance of TT-NSS on non-abstained samples. Our empirical results demonstrate the effectiveness of TT-NSS and NSS at producing and improving risk-averse predictions on unseen domains from DG classifiers trained with SOTA training methods on various benchmark datasets and their variations.
Robust Single-view Cone-beam X-ray Pose Estimation with Neural Tuned Tomography (NeTT) and Masked Neural Radiance Fields (mNeRF)
Aug 01, 2023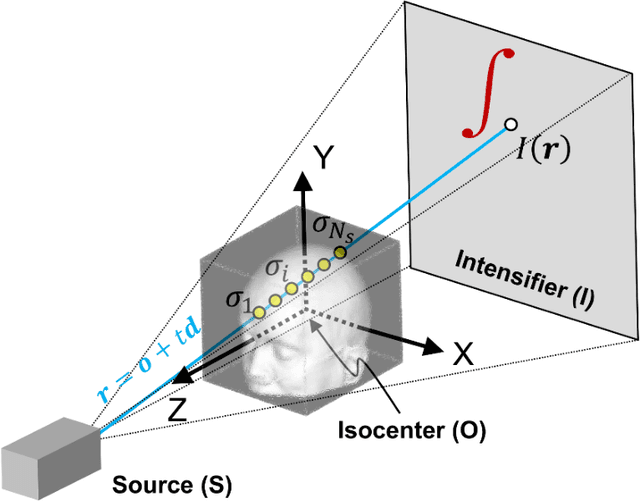

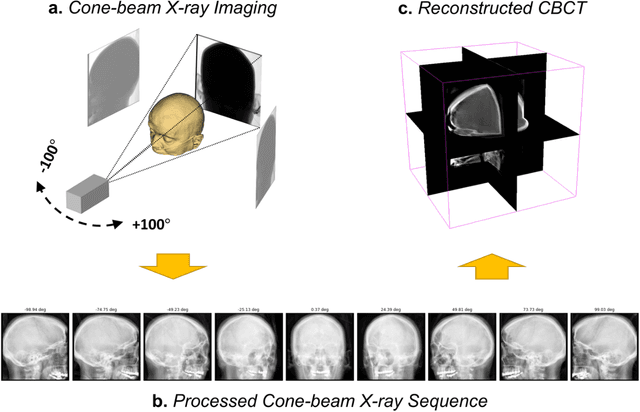

Many tasks performed in image-guided, mini-invasive, medical procedures can be cast as pose estimation problems, where an X-ray projection is utilized to reach a target in 3D space. Recent advances in the differentiable rendering of optically reflective materials have enabled state-of-the-art performance in RGB camera view synthesis and pose estimation. Expanding on these prior works, we introduce new methods for pose estimation of radiolucent objects using X-ray projections, and we demonstrate the critical role of optimal view synthesis in performing this task. We first develop an algorithm (DiffDRR) that efficiently computes Digitally Reconstructed Radiographs (DRRs) and leverages automatic differentiation within TensorFlow. In conjunction with classic CBCT reconstruction algorithms, we perform pose estimation by gradient descent using a loss function that quantifies the similarity of the DRR synthesized from a randomly initialized pose and the true fluoroscopic image at the target pose. We propose two novel methods for high-fidelity view synthesis, Neural Tuned Tomography (NeTT) and masked Neural Radiance Fields (mNeRF). Both methods rely on classic CBCT; NeTT directly optimizes the CBCT densities, while the non-zero values of mNeRF are constrained by a 3D mask of the anatomic region segmented from CBCT. We demonstrate that both NeTT and mNeRF distinctly improve pose estimation within our framework. By defining a successful pose estimate to be a 3D angle error of less than 3 deg, we find that NeTT and mNeRF can achieve similar results, both with overall success rates more than 93%. Furthermore, we show that a NeTT trained for a single subject can generalize to synthesize high-fidelity DRRs and ensure robust pose estimations for all other subjects. Therefore, we suggest that NeTT is an attractive option for robust pose estimation using fluoroscopic projections.
Lowis3D: Language-Driven Open-World Instance-Level 3D Scene Understanding
Aug 01, 2023
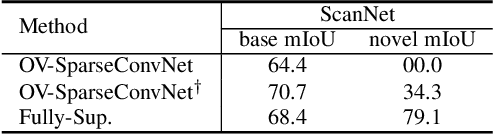
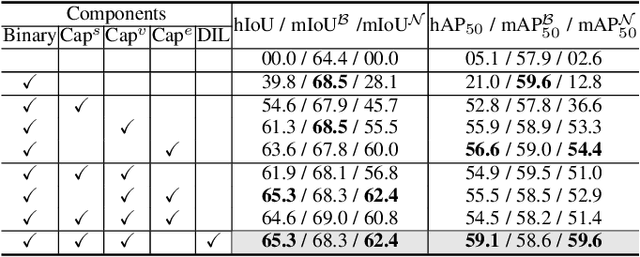

Open-world instance-level scene understanding aims to locate and recognize unseen object categories that are not present in the annotated dataset. This task is challenging because the model needs to both localize novel 3D objects and infer their semantic categories. A key factor for the recent progress in 2D open-world perception is the availability of large-scale image-text pairs from the Internet, which cover a wide range of vocabulary concepts. However, this success is hard to replicate in 3D scenarios due to the scarcity of 3D-text pairs. To address this challenge, we propose to harness pre-trained vision-language (VL) foundation models that encode extensive knowledge from image-text pairs to generate captions for multi-view images of 3D scenes. This allows us to establish explicit associations between 3D shapes and semantic-rich captions. Moreover, to enhance the fine-grained visual-semantic representation learning from captions for object-level categorization, we design hierarchical point-caption association methods to learn semantic-aware embeddings that exploit the 3D geometry between 3D points and multi-view images. In addition, to tackle the localization challenge for novel classes in the open-world setting, we develop debiased instance localization, which involves training object grouping modules on unlabeled data using instance-level pseudo supervision. This significantly improves the generalization capabilities of instance grouping and thus the ability to accurately locate novel objects. We conduct extensive experiments on 3D semantic, instance, and panoptic segmentation tasks, covering indoor and outdoor scenes across three datasets. Our method outperforms baseline methods by a significant margin in semantic segmentation (e.g. 34.5%$\sim$65.3%), instance segmentation (e.g. 21.8%$\sim$54.0%) and panoptic segmentation (e.g. 14.7%$\sim$43.3%). Code will be available.
Target Detection on Hyperspectral Images Using MCMC and VI Trained Bayesian Neural Networks
Aug 11, 2023

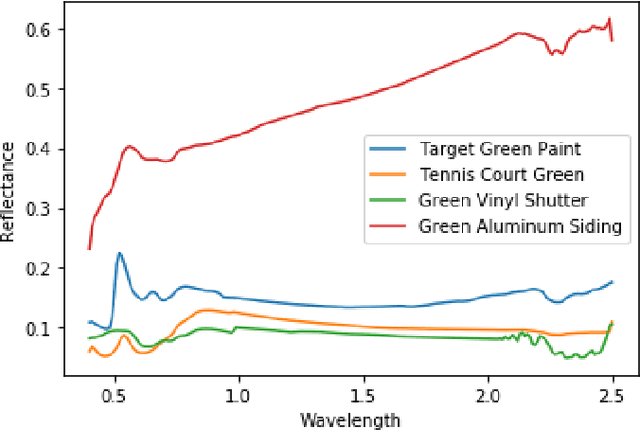
Neural networks (NN) have become almost ubiquitous with image classification, but in their standard form produce point estimates, with no measure of confidence. Bayesian neural networks (BNN) provide uncertainty quantification (UQ) for NN predictions and estimates through the posterior distribution. As NN are applied in more high-consequence applications, UQ is becoming a requirement. BNN provide a solution to this problem by not only giving accurate predictions and estimates, but also an interval that includes reasonable values within a desired probability. Despite their positive attributes, BNN are notoriously difficult and time consuming to train. Traditional Bayesian methods use Markov Chain Monte Carlo (MCMC), but this is often brushed aside as being too slow. The most common method is variational inference (VI) due to its fast computation, but there are multiple concerns with its efficacy. We apply and compare MCMC- and VI-trained BNN in the context of target detection in hyperspectral imagery (HSI), where materials of interest can be identified by their unique spectral signature. This is a challenging field, due to the numerous permuting effects practical collection of HSI has on measured spectra. Both models are trained using out-of-the-box tools on a high fidelity HSI target detection scene. Both MCMC- and VI-trained BNN perform well overall at target detection on a simulated HSI scene. This paper provides an example of how to utilize the benefits of UQ, but also to increase awareness that different training methods can give different results for the same model. If sufficient computational resources are available, the best approach rather than the fastest or most efficient should be used, especially for high consequence problems.
Evidence of Human-Like Visual-Linguistic Integration in Multimodal Large Language Models During Predictive Language Processing
Aug 11, 2023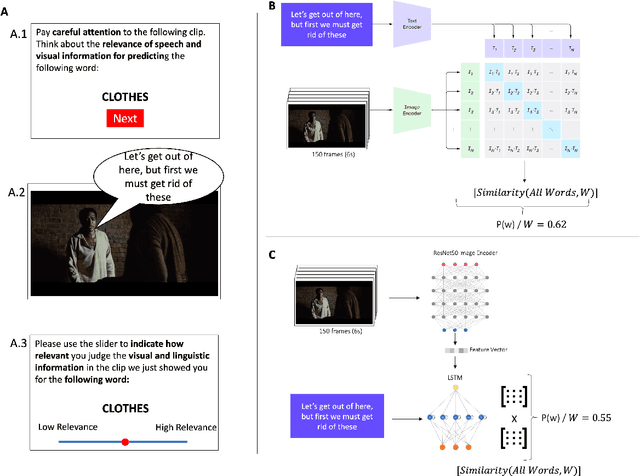
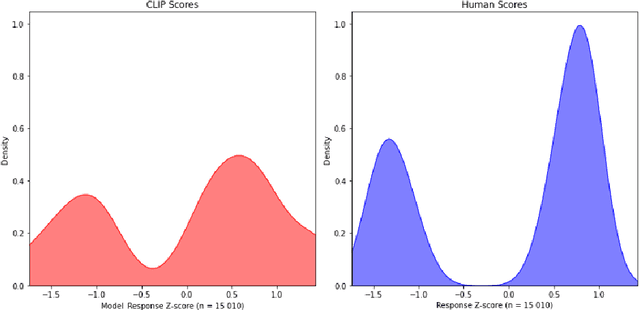
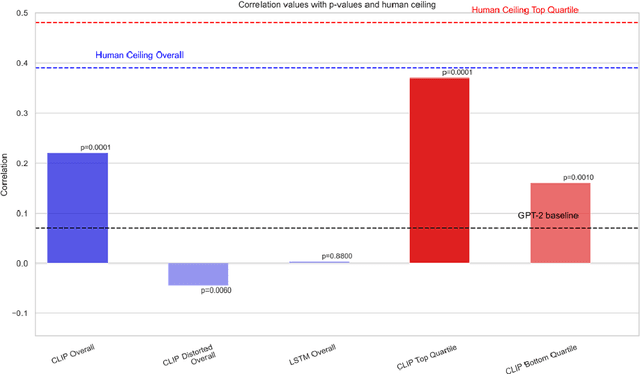
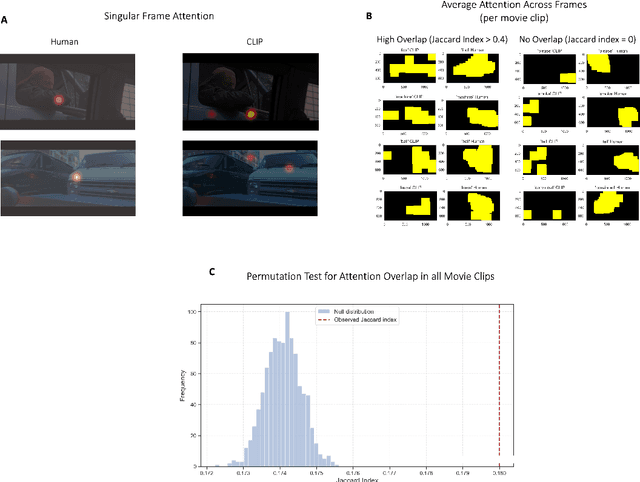
The advanced language processing abilities of large language models (LLMs) have stimulated debate over their capacity to replicate human-like cognitive processes. One differentiating factor between language processing in LLMs and humans is that language input is often grounded in more than one perceptual modality, whereas most LLMs process solely text-based information. Multimodal grounding allows humans to integrate - e.g. visual context with linguistic information and thereby place constraints on the space of upcoming words, reducing cognitive load and improving perception and comprehension. Recent multimodal LLMs (mLLMs) combine visual and linguistic embedding spaces with a transformer type attention mechanism for next-word prediction. To what extent does predictive language processing based on multimodal input align in mLLMs and humans? To answer this question, 200 human participants watched short audio-visual clips and estimated the predictability of an upcoming verb or noun. The same clips were processed by the mLLM CLIP, with predictability scores based on a comparison of image and text feature vectors. Eye-tracking was used to estimate what visual features participants attended to, and CLIP's visual attention weights were recorded. We find that human estimates of predictability align significantly with CLIP scores, but not for a unimodal LLM of comparable parameter size. Further, alignment vanished when CLIP's visual attention weights were perturbed, and when the same input was fed to a multimodal model without attention. Analysing attention patterns, we find a significant spatial overlap between CLIP's visual attention weights and human eye-tracking data. Results suggest that comparable processes of integrating multimodal information, guided by attention to relevant visual features, supports predictive language processing in mLLMs and humans.
Collaborative Auto-encoding for Blind Image Quality Assessment
May 24, 2023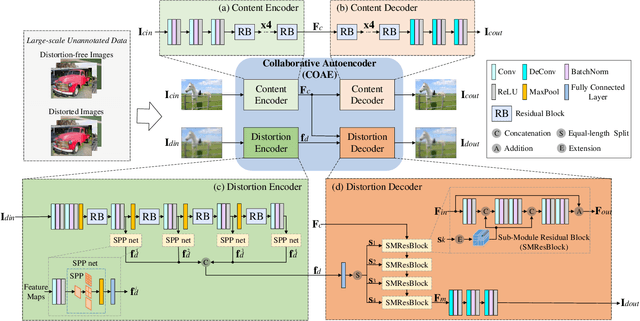
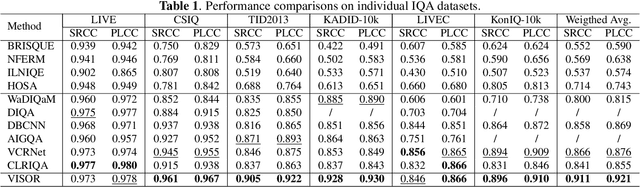
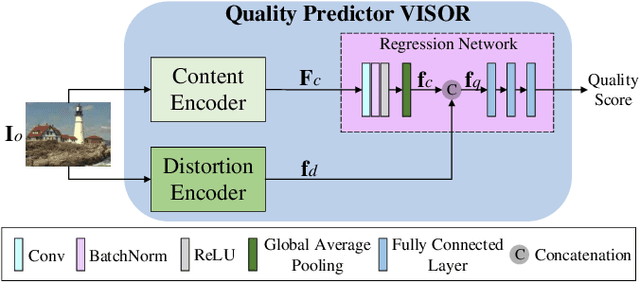
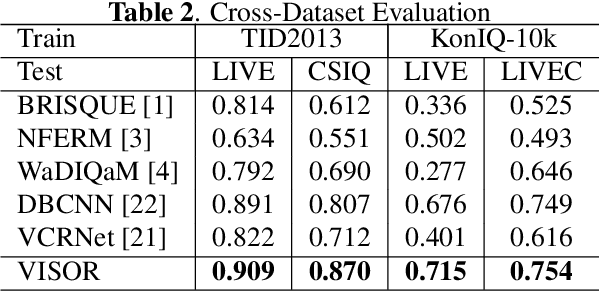
Blind image quality assessment (BIQA) is a challenging problem with important real-world applications. Recent efforts attempting to exploit powerful representations by deep neural networks (DNN) are hindered by the lack of subjectively annotated data. This paper presents a novel BIQA method which overcomes this fundamental obstacle. Specifically, we design a pair of collaborative autoencoders (COAE) consisting of a content autoencoder (CAE) and a distortion autoencoder (DAE) that work together to extract content and distortion representations, which are shown to be highly descriptive of image quality. While the CAE follows a standard codec procedure, we introduce the CAE-encoded feature as an extra input to the DAE's decoder for reconstructing distorted images, thus effectively forcing DAE's encoder to extract distortion representations. The self-supervised learning framework allows the COAE including two feature extractors to be trained by almost unlimited amount of data, thus leaving limited samples with annotations to finetune a BIQA model. We will show that the proposed BIQA method achieves state-of-the-art performance and has superior generalization capability over other learning based models. The codes are available at: https://github.com/Macro-Zhou/NRIQA-VISOR/.
MultiFusion: Fusing Pre-Trained Models for Multi-Lingual, Multi-Modal Image Generation
May 24, 2023



The recent popularity of text-to-image diffusion models (DM) can largely be attributed to the intuitive interface they provide to users. The intended generation can be expressed in natural language, with the model producing faithful interpretations of text prompts. However, expressing complex or nuanced ideas in text alone can be difficult. To ease image generation, we propose MultiFusion that allows one to express complex and nuanced concepts with arbitrarily interleaved inputs of multiple modalities and languages. MutliFusion leverages pre-trained models and aligns them for integration into a cohesive system, thereby avoiding the need for extensive training from scratch. Our experimental results demonstrate the efficient transfer of capabilities from individual modules to the downstream model. Specifically, the fusion of all independent components allows the image generation module to utilize multilingual, interleaved multimodal inputs despite being trained solely on monomodal data in a single language.
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
May 14, 2023
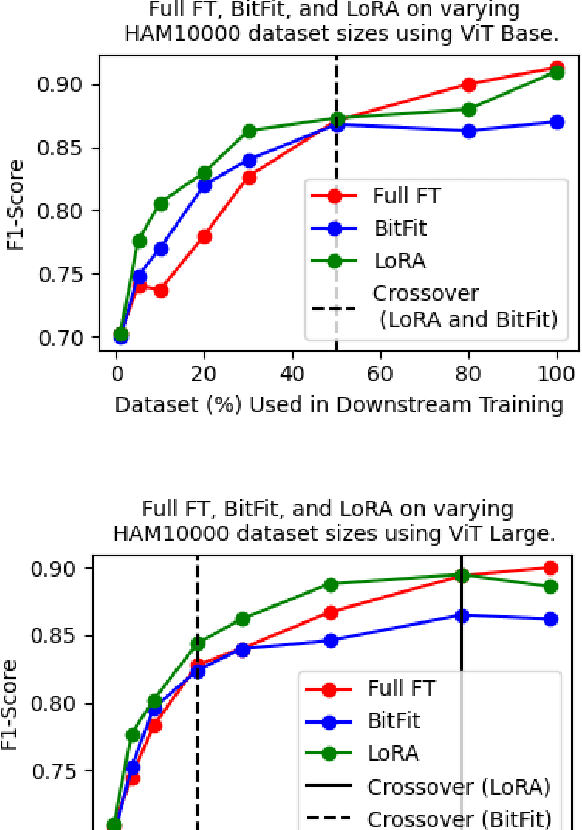
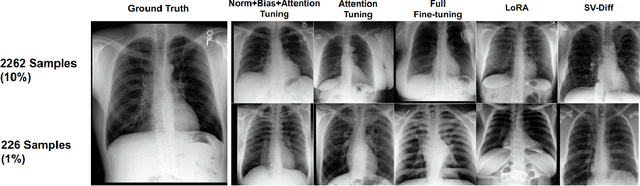
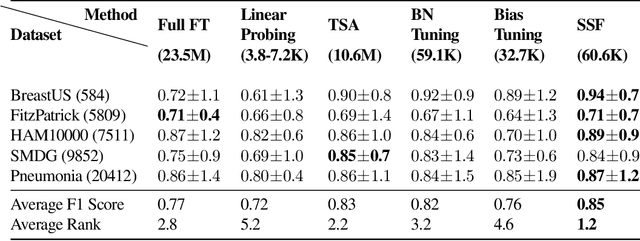
We present a comprehensive evaluation of Parameter-Efficient Fine-Tuning (PEFT) techniques for diverse medical image analysis tasks. PEFT is increasingly exploited as a valuable approach for knowledge transfer from pre-trained models in natural language processing, vision, speech, and cross-modal tasks, such as vision-language and text-to-image generation. However, its application in medical image analysis remains relatively unexplored. As foundation models are increasingly exploited in the medical domain, it is crucial to investigate and comparatively assess various strategies for knowledge transfer that can bolster a range of downstream tasks. Our study, the first of its kind (to the best of our knowledge), evaluates 16 distinct PEFT methodologies proposed for convolutional and transformer-based networks, focusing on image classification and text-to-image generation tasks across six medical datasets ranging in size, modality, and complexity. Through a battery of more than 600 controlled experiments, we demonstrate performance gains of up to 22% under certain scenarios and demonstrate the efficacy of PEFT for medical text-to-image generation. Further, we reveal the instances where PEFT methods particularly dominate over conventional fine-tuning approaches by studying their relationship with downstream data volume.
Hierarchical Spatiotemporal Transformers for Video Object Segmentation
Jul 17, 2023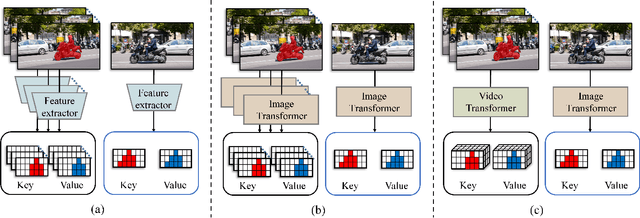
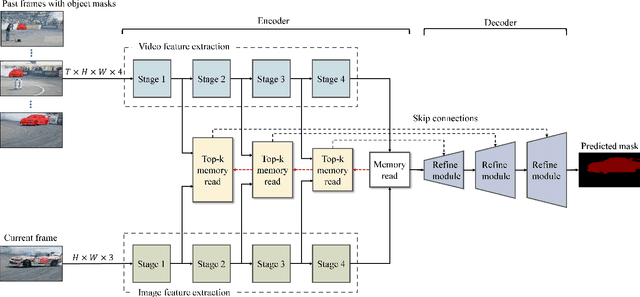

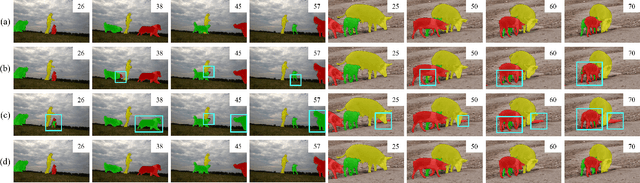
This paper presents a novel framework called HST for semi-supervised video object segmentation (VOS). HST extracts image and video features using the latest Swin Transformer and Video Swin Transformer to inherit their inductive bias for the spatiotemporal locality, which is essential for temporally coherent VOS. To take full advantage of the image and video features, HST casts image and video features as a query and memory, respectively. By applying efficient memory read operations at multiple scales, HST produces hierarchical features for the precise reconstruction of object masks. HST shows effectiveness and robustness in handling challenging scenarios with occluded and fast-moving objects under cluttered backgrounds. In particular, HST-B outperforms the state-of-the-art competitors on multiple popular benchmarks, i.e., YouTube-VOS (85.0%), DAVIS 2017 (85.9%), and DAVIS 2016 (94.0%).