 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
Jul 27, 2023
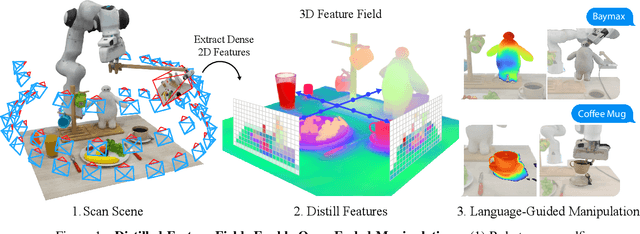
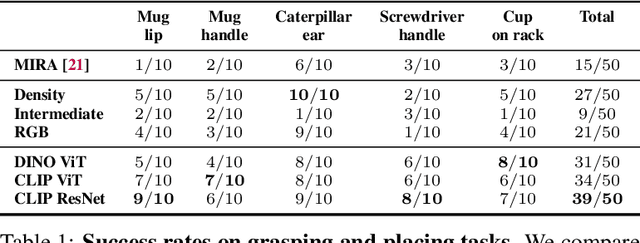
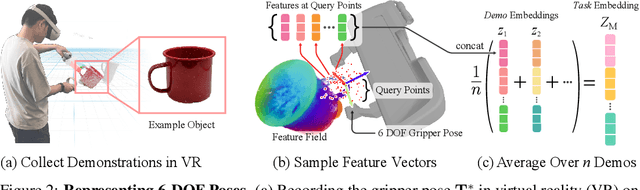
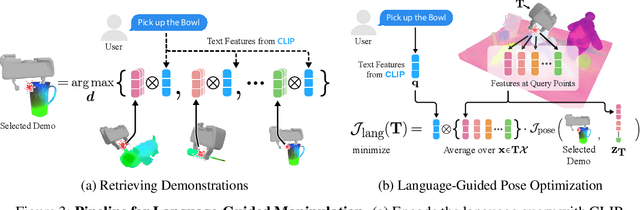
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
Low-field magnetic resonance image enhancement via stochastic image quality transfer
Apr 26, 2023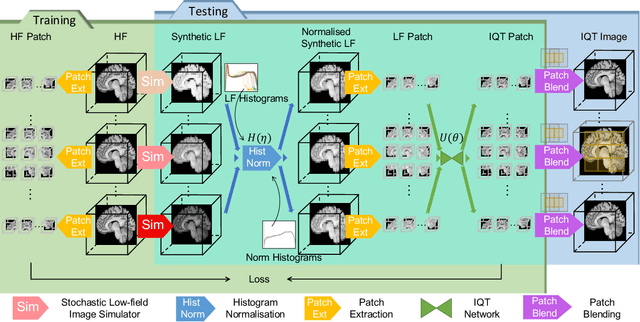
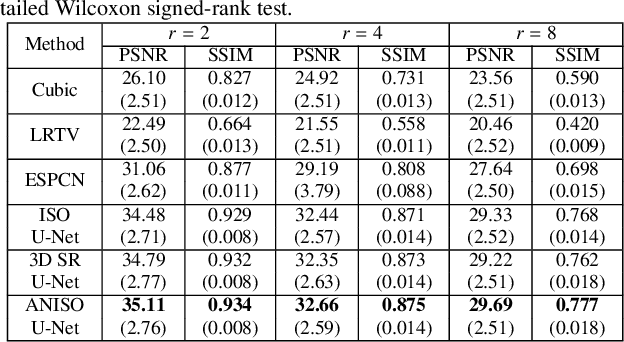
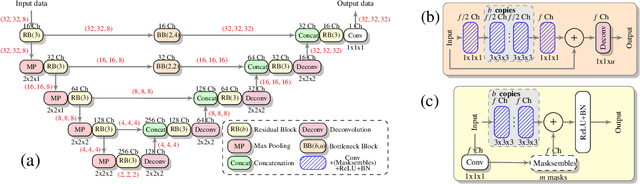
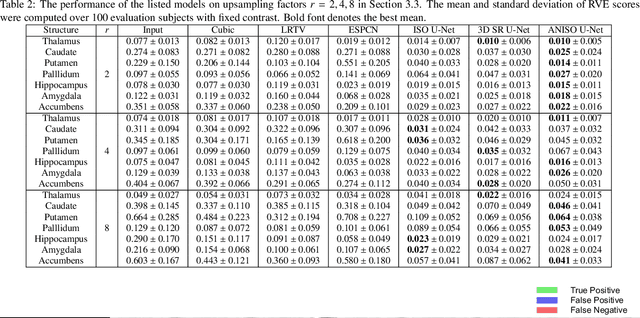
Low-field (<1T) magnetic resonance imaging (MRI) scanners remain in widespread use in low- and middle-income countries (LMICs) and are commonly used for some applications in higher income countries e.g. for small child patients with obesity, claustrophobia, implants, or tattoos. However, low-field MR images commonly have lower resolution and poorer contrast than images from high field (1.5T, 3T, and above). Here, we present Image Quality Transfer (IQT) to enhance low-field structural MRI by estimating from a low-field image the image we would have obtained from the same subject at high field. Our approach uses (i) a stochastic low-field image simulator as the forward model to capture uncertainty and variation in the contrast of low-field images corresponding to a particular high-field image, and (ii) an anisotropic U-Net variant specifically designed for the IQT inverse problem. We evaluate the proposed algorithm both in simulation and using multi-contrast (T1-weighted, T2-weighted, and fluid attenuated inversion recovery (FLAIR)) clinical low-field MRI data from an LMIC hospital. We show the efficacy of IQT in improving contrast and resolution of low-field MR images. We demonstrate that IQT-enhanced images have potential for enhancing visualisation of anatomical structures and pathological lesions of clinical relevance from the perspective of radiologists. IQT is proved to have capability of boosting the diagnostic value of low-field MRI, especially in low-resource settings.
Teeth And Root Canals Segmentation Using ZXYFormer With Uncertainty Guidance And Weight Transfer
Aug 14, 2023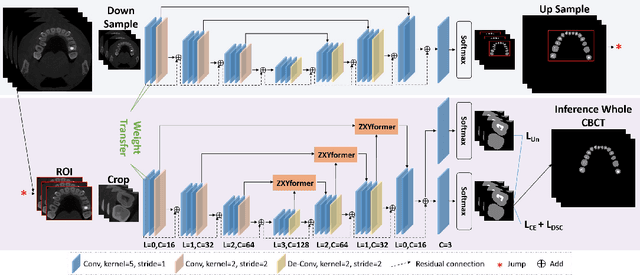

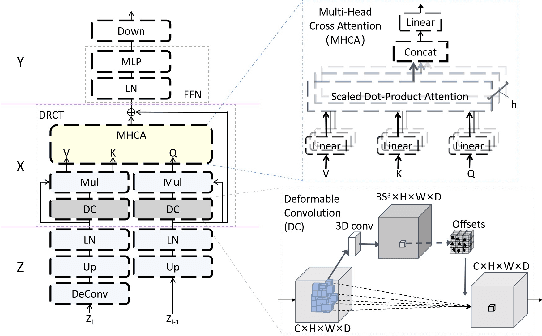

This study attempts to segment teeth and root-canals simultaneously from CBCT images, but there are very challenging problems in this process. First, the clinical CBCT image data is very large (e.g., 672 *688 * 688), and the use of downsampling operation will lose useful information about teeth and root canals. Second, teeth and root canals are very different in morphology, and it is difficult for a simple network to identify them precisely. In addition, there are weak edges at the tooth, between tooth and root canal, which makes it very difficult to segment such weak edges. To this end, we propose a coarse-to-fine segmentation method based on inverse feature fusion transformer and uncertainty estimation to address above challenging problems. First, we use the downscaled volume data (e.g., 128 * 128 * 128) to conduct coarse segmentation and map it to the original volume to obtain the area of teeth and root canals. Then, we design a transformer with reverse feature fusion, which can bring better segmentation effect of different morphological objects by transferring deeper features to shallow features. Finally, we design an auxiliary branch to calculate and refine the difficult areas in order to improve the weak edge segmentation performance of teeth and root canals. Through the combined tooth and root canal segmentation experiment of 157 clinical high-resolution CBCT data, it is verified that the proposed method is superior to the existing tooth or root canal segmentation methods.
MixBCT: Towards Self-Adapting Backward-Compatible Training
Aug 14, 2023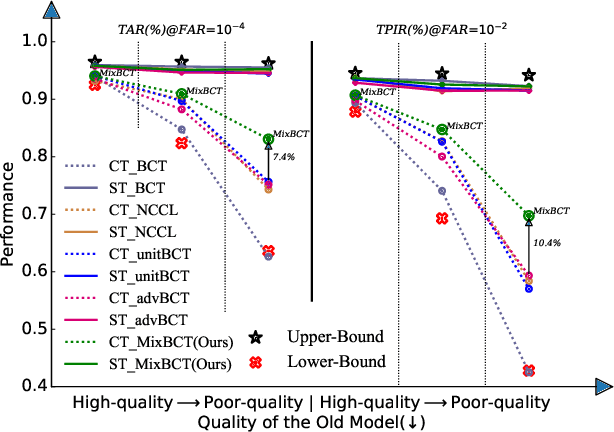

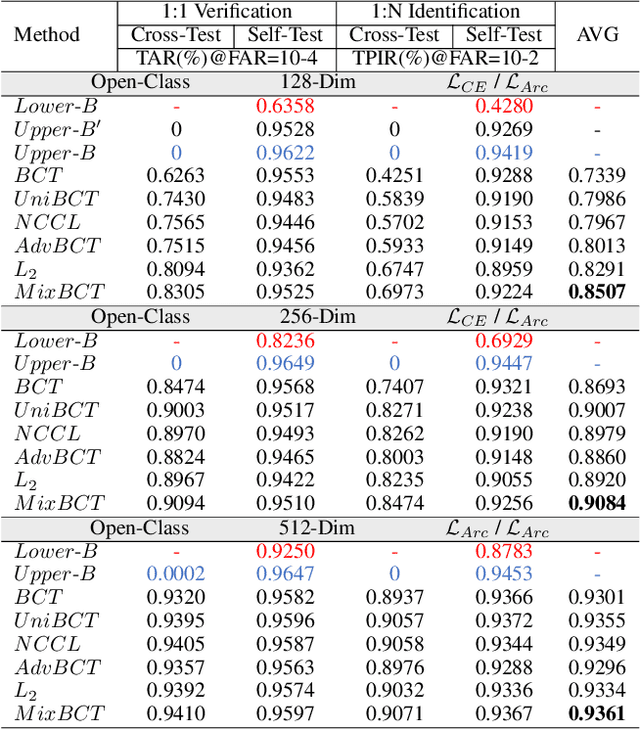
The exponential growth of data, alongside advancements in model structures and loss functions, has necessitated the enhancement of image retrieval systems through the utilization of new models with superior feature embeddings. However, the expensive process of updating the old retrieval database by replacing embeddings poses a challenge. As a solution, backward-compatible training can be employed to avoid the necessity of updating old retrieval datasets. While previous methods achieved backward compatibility by aligning prototypes of the old model, they often overlooked the distribution of the old features, thus limiting their effectiveness when the old model's low quality leads to a weakly discriminative feature distribution. On the other hand, instance-based methods like L2 regression take into account the distribution of old features but impose strong constraints on the performance of the new model itself. In this paper, we propose MixBCT, a simple yet highly effective backward-compatible training method that serves as a unified framework for old models of varying qualities. Specifically, we summarize four constraints that are essential for ensuring backward compatibility in an ideal scenario, and we construct a single loss function to facilitate backward-compatible training. Our approach adaptively adjusts the constraint domain for new features based on the distribution of the old embeddings. We conducted extensive experiments on the large-scale face recognition datasets MS1Mv3 and IJB-C to verify the effectiveness of our method. The experimental results clearly demonstrate its superiority over previous methods. Code is available at https://github.com/yuleung/MixBCT
Decomposing and Coupling Saliency Map for Lesion Segmentation in Ultrasound Images
Aug 02, 2023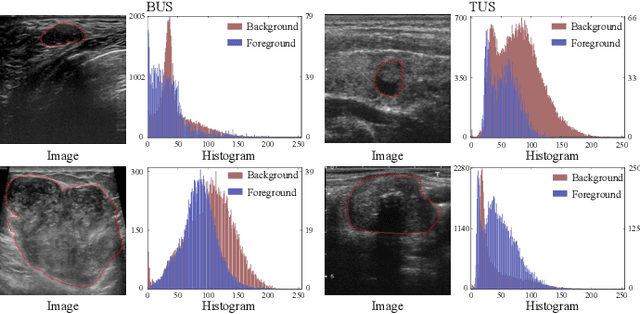

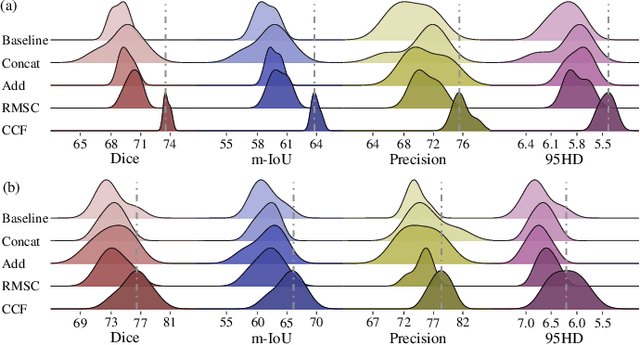
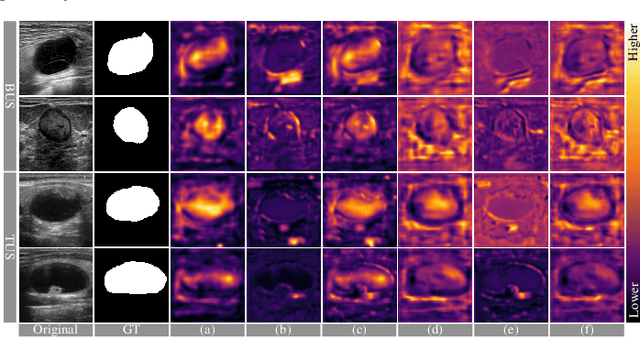
Complex scenario of ultrasound image, in which adjacent tissues (i.e., background) share similar intensity with and even contain richer texture patterns than lesion region (i.e., foreground), brings a unique challenge for accurate lesion segmentation. This work presents a decomposition-coupling network, called DC-Net, to deal with this challenge in a (foreground-background) saliency map disentanglement-fusion manner. The DC-Net consists of decomposition and coupling subnets, and the former preliminarily disentangles original image into foreground and background saliency maps, followed by the latter for accurate segmentation under the assistance of saliency prior fusion. The coupling subnet involves three aspects of fusion strategies, including: 1) regional feature aggregation (via differentiable context pooling operator in the encoder) to adaptively preserve local contextual details with the larger receptive field during dimension reduction; 2) relation-aware representation fusion (via cross-correlation fusion module in the decoder) to efficiently fuse low-level visual characteristics and high-level semantic features during resolution restoration; 3) dependency-aware prior incorporation (via coupler) to reinforce foreground-salient representation with the complementary information derived from background representation. Furthermore, a harmonic loss function is introduced to encourage the network to focus more attention on low-confidence and hard samples. The proposed method is evaluated on two ultrasound lesion segmentation tasks, which demonstrates the remarkable performance improvement over existing state-of-the-art methods.
CCDWT-GAN: Generative Adversarial Networks Based on Color Channel Using Discrete Wavelet Transform for Document Image Binarization
May 27, 2023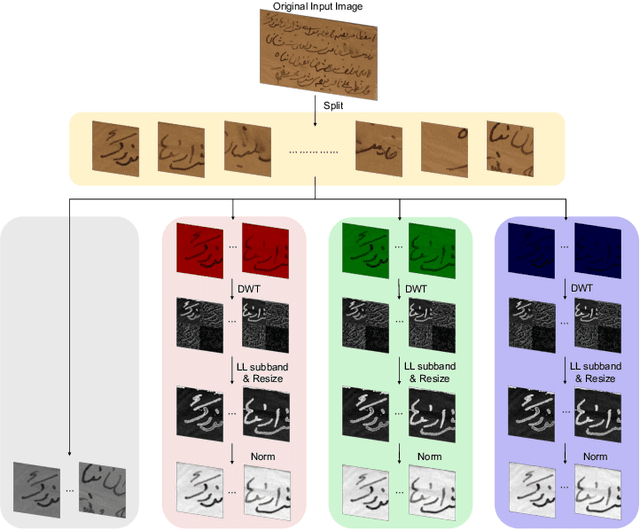
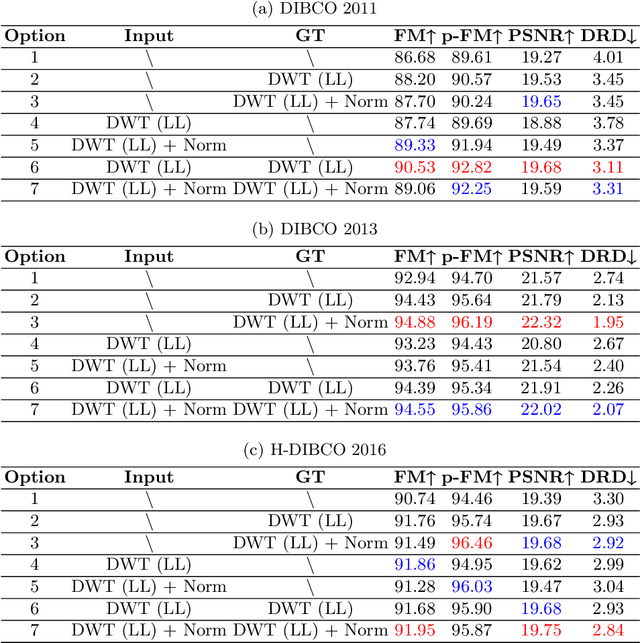
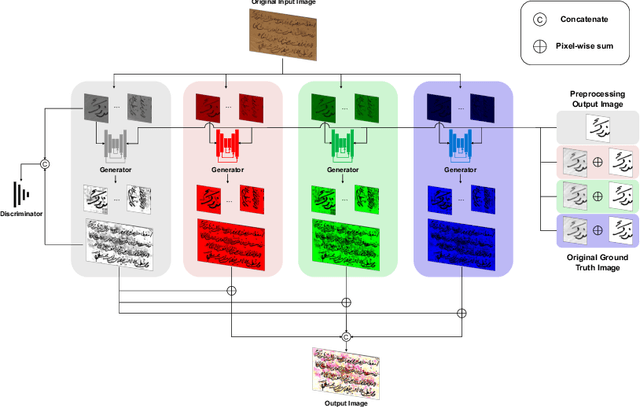
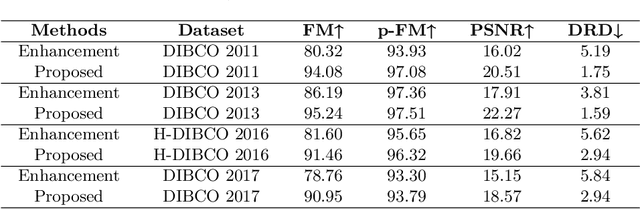
To efficiently extract the textual information from color degraded document images is an important research topic. Long-term imperfect preservation of ancient documents has led to various types of degradation such as page staining, paper yellowing, and ink bleeding; these degradations badly impact the image processing for information extraction. In this paper, we present CCDWT-GAN, a generative adversarial network (GAN) that utilizes the discrete wavelet transform (DWT) on RGB (red, green, blue) channel splited images. The proposed method comprises three stages: image preprocessing, image enhancement, and image binarization. This work conducts comparative experiments in the image preprocessing stage to determine the optimal selection of DWT with normalization. Additionally, we perform an ablation study on the results of the image enhancement stage and the image binarization stage to validate their positive effect on the model performance. This work compares the performance of the proposed method with other state-of-the-art (SOTA) methods on DIBCO and H-DIBCO ((Handwritten) Document Image Binarization Competition) datasets. The experimental results demonstrate that CCDWT-GAN achieves a top two performance on multiple benchmark datasets, and outperforms other SOTA methods.
Differential Privacy for Adaptive Weight Aggregation in Federated Tumor Segmentation
Aug 01, 2023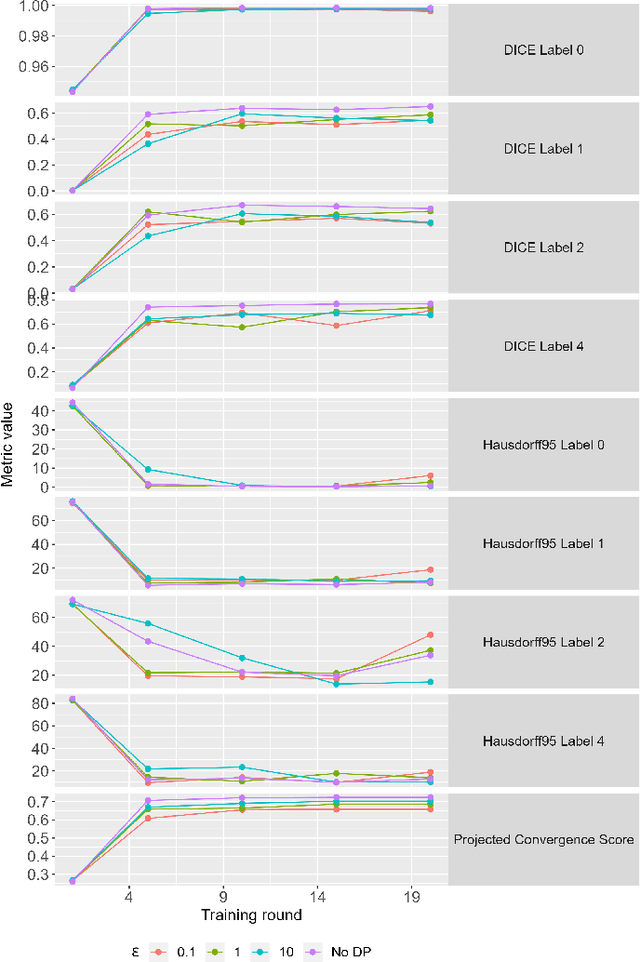
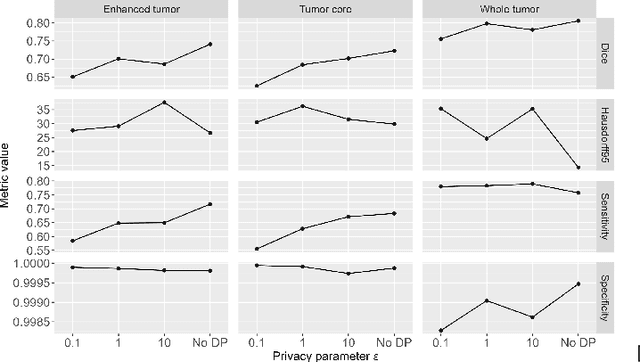
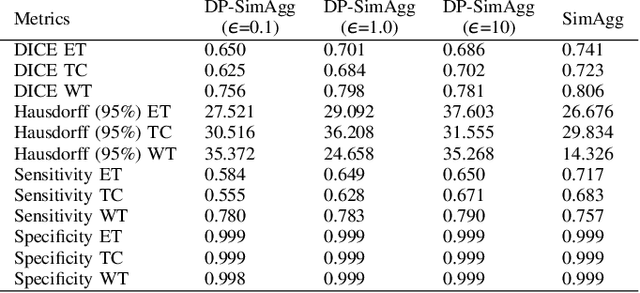
Federated Learning (FL) is a distributed machine learning approach that safeguards privacy by creating an impartial global model while respecting the privacy of individual client data. However, the conventional FL method can introduce security risks when dealing with diverse client data, potentially compromising privacy and data integrity. To address these challenges, we present a differential privacy (DP) federated deep learning framework in medical image segmentation. In this paper, we extend our similarity weight aggregation (SimAgg) method to DP-SimAgg algorithm, a differentially private similarity-weighted aggregation algorithm for brain tumor segmentation in multi-modal magnetic resonance imaging (MRI). Our DP-SimAgg method not only enhances model segmentation capabilities but also provides an additional layer of privacy preservation. Extensive benchmarking and evaluation of our framework, with computational performance as a key consideration, demonstrate that DP-SimAgg enables accurate and robust brain tumor segmentation while minimizing communication costs during model training. This advancement is crucial for preserving the privacy of medical image data and safeguarding sensitive information. In conclusion, adding a differential privacy layer in the global weight aggregation phase of the federated brain tumor segmentation provides a promising solution to privacy concerns without compromising segmentation model efficacy. By leveraging DP, we ensure the protection of client data against adversarial attacks and malicious participants.
Robust Spatiotemporal Fusion of Satellite Images: A Constrained Convex Optimization Approach
Aug 01, 2023This paper proposes a novel spatiotemporal (ST) fusion framework for satellite images, named Robust Optimization-based Spatiotemporal Fusion (ROSTF). ST fusion is a promising approach to resolve a trade-off between the temporal and spatial resolution of satellite images. Although many ST fusion methods have been proposed, most of them are not designed to explicitly account for noise in observed images, despite the inevitable influence of noise caused by the measurement equipment and environment. Our ROSTF addresses this challenge by treating the noise removal of the observed images and the estimation of the target high-resolution image as a single optimization problem. Specifically, first, we define observation models for satellite images possibly contaminated with random noise, outliers, and/or missing values, and then introduce certain assumptions that would naturally hold between the observed images and the target high-resolution image. Then, based on these models and assumptions, we formulate the fusion problem as a constrained optimization problem and develop an efficient algorithm based on a preconditioned primal-dual splitting method for solving the problem. The performance of ROSTF was verified using simulated and real data. The results show that ROSTF performs comparably to several state-of-the-art ST fusion methods in noiseless cases and outperforms them in noisy cases.
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder
May 25, 2023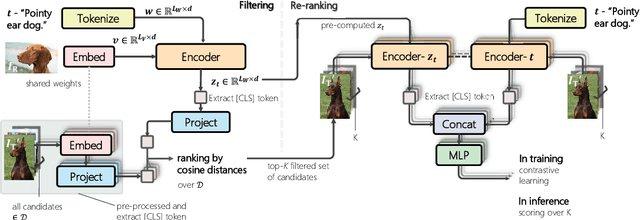
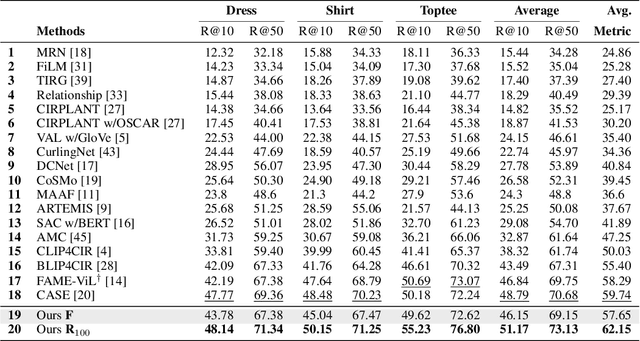
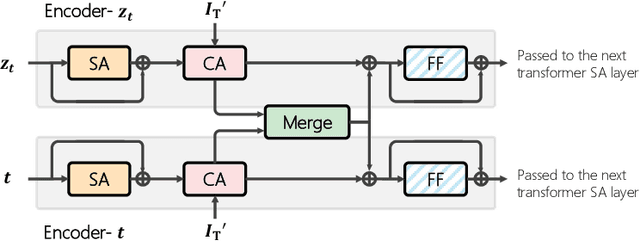
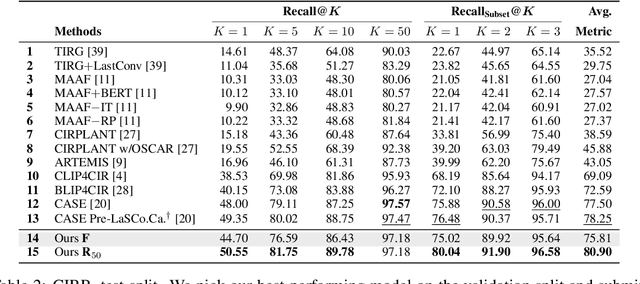
Composed image retrieval aims to find an image that best matches a given multi-modal user query consisting of a reference image and text pair. Existing methods commonly pre-compute image embeddings over the entire corpus and compare these to a reference image embedding modified by the query text at test time. Such a pipeline is very efficient at test time since fast vector distances can be used to evaluate candidates, but modifying the reference image embedding guided only by a short textual description can be difficult, especially independent of potential candidates. An alternative approach is to allow interactions between the query and every possible candidate, i.e., reference-text-candidate triplets, and pick the best from the entire set. Though this approach is more discriminative, for large-scale datasets the computational cost is prohibitive since pre-computation of candidate embeddings is no longer possible. We propose to combine the merits of both schemes using a two-stage model. Our first stage adopts the conventional vector distancing metric and performs a fast pruning among candidates. Meanwhile, our second stage employs a dual-encoder architecture, which effectively attends to the input triplet of reference-text-candidate and re-ranks the candidates. Both stages utilize a vision-and-language pre-trained network, which has proven beneficial for various downstream tasks. Our method consistently outperforms state-of-the-art approaches on standard benchmarks for the task.
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
Jun 01, 2023

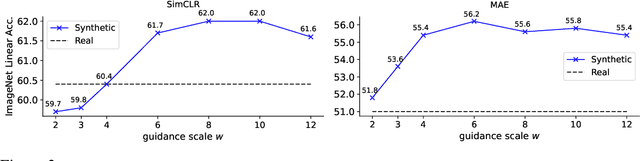
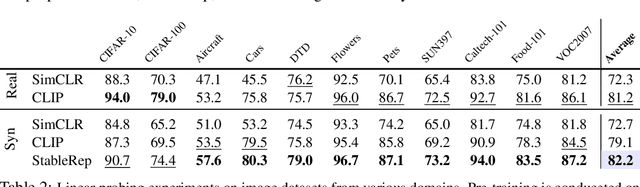
We investigate the potential of learning visual representations using synthetic images generated by text-to-image models. This is a natural question in the light of the excellent performance of such models in generating high-quality images. We consider specifically the Stable Diffusion, one of the leading open source text-to-image models. We show that (1) when the generative model is configured with proper classifier-free guidance scale, training self-supervised methods on synthetic images can match or beat the real image counterpart; (2) by treating the multiple images generated from the same text prompt as positives for each other, we develop a multi-positive contrastive learning method, which we call StableRep. With solely synthetic images, the representations learned by StableRep surpass the performance of representations learned by SimCLR and CLIP using the same set of text prompts and corresponding real images, on large scale datasets. When we further add language supervision, StableRep trained with 20M synthetic images achieves better accuracy than CLIP trained with 50M real images.