 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation
Jul 31, 2023
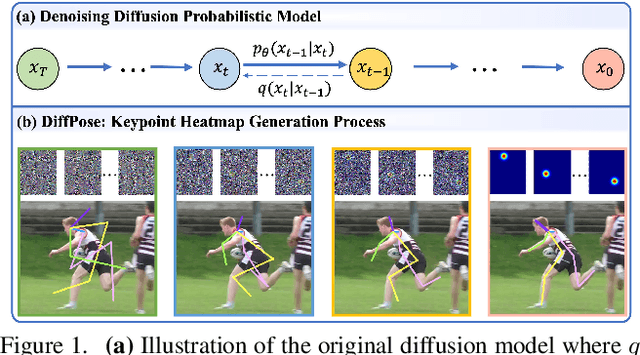
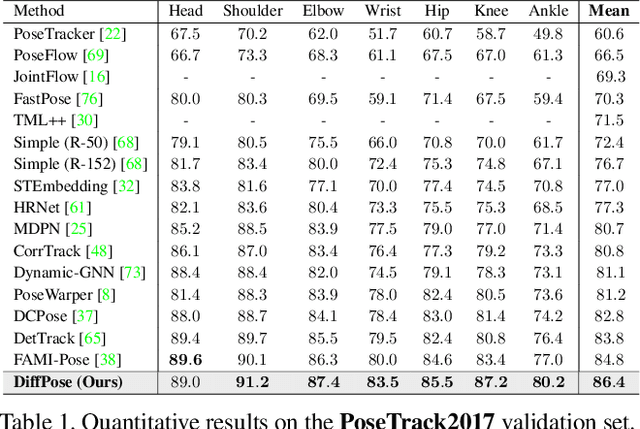
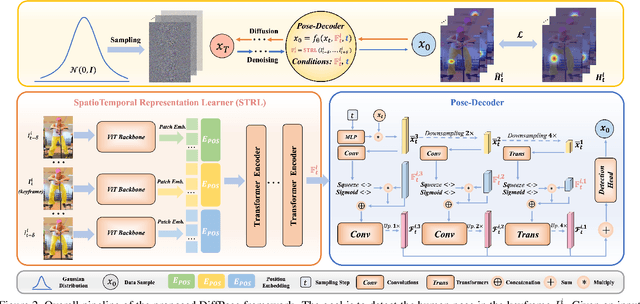
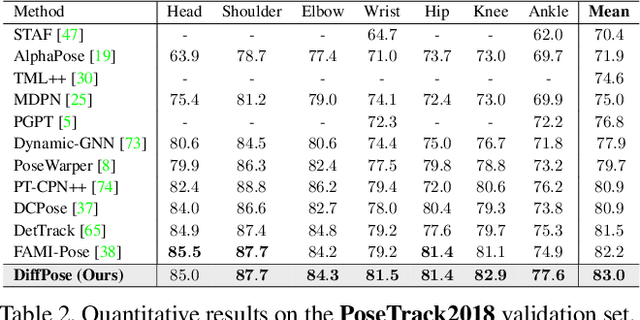
Denoising diffusion probabilistic models that were initially proposed for realistic image generation have recently shown success in various perception tasks (e.g., object detection and image segmentation) and are increasingly gaining attention in computer vision. However, extending such models to multi-frame human pose estimation is non-trivial due to the presence of the additional temporal dimension in videos. More importantly, learning representations that focus on keypoint regions is crucial for accurate localization of human joints. Nevertheless, the adaptation of the diffusion-based methods remains unclear on how to achieve such objective. In this paper, we present DiffPose, a novel diffusion architecture that formulates video-based human pose estimation as a conditional heatmap generation problem. First, to better leverage temporal information, we propose SpatioTemporal Representation Learner which aggregates visual evidences across frames and uses the resulting features in each denoising step as a condition. In addition, we present a mechanism called Lookup-based MultiScale Feature Interaction that determines the correlations between local joints and global contexts across multiple scales. This mechanism generates delicate representations that focus on keypoint regions. Altogether, by extending diffusion models, we show two unique characteristics from DiffPose on pose estimation task: (i) the ability to combine multiple sets of pose estimates to improve prediction accuracy, particularly for challenging joints, and (ii) the ability to adjust the number of iterative steps for feature refinement without retraining the model. DiffPose sets new state-of-the-art results on three benchmarks: PoseTrack2017, PoseTrack2018, and PoseTrack21.
SABRE: Robust Bayesian Peer-to-Peer Federated Learning
Aug 04, 2023We introduce SABRE, a novel framework for robust variational Bayesian peer-to-peer federated learning. We analyze the robustness of the known variational Bayesian peer-to-peer federated learning framework (BayP2PFL) against poisoning attacks and subsequently show that BayP2PFL is not robust against those attacks. The new SABRE aggregation methodology is then devised to overcome the limitations of the existing frameworks. SABRE works well in non-IID settings, does not require the majority of the benign nodes over the compromised ones, and even outperforms the baseline algorithm in benign settings. We theoretically prove the robustness of our algorithm against data / model poisoning attacks in a decentralized linear regression setting. Proof-of-Concept evaluations on benchmark data from image classification demonstrate the superiority of SABRE over the existing frameworks under various poisoning attacks.
Image Segmentation Keras : Implementation of Segnet, FCN, UNet, PSPNet and other models in Keras
Jul 25, 2023



Semantic segmentation plays a vital role in computer vision tasks, enabling precise pixel-level understanding of images. In this paper, we present a comprehensive library for semantic segmentation, which contains implementations of popular segmentation models like SegNet, FCN, UNet, and PSPNet. We also evaluate and compare these models on several datasets, offering researchers and practitioners a powerful toolset for tackling diverse segmentation challenges.
On the Effectiveness of Spectral Discriminators for Perceptual Quality Improvement
Jul 22, 2023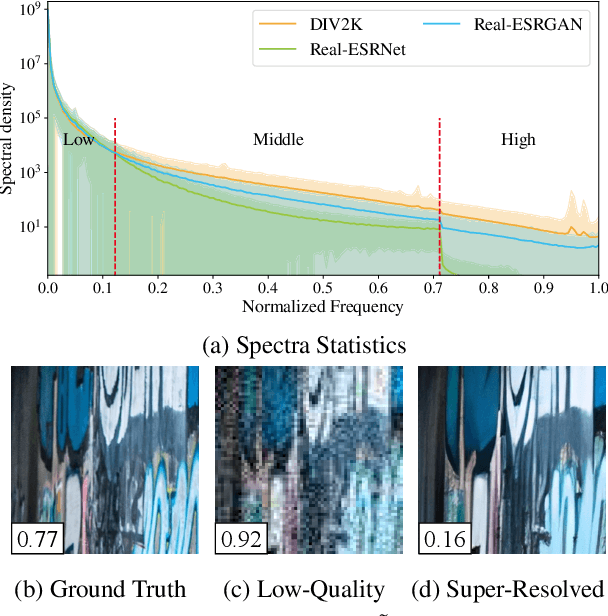

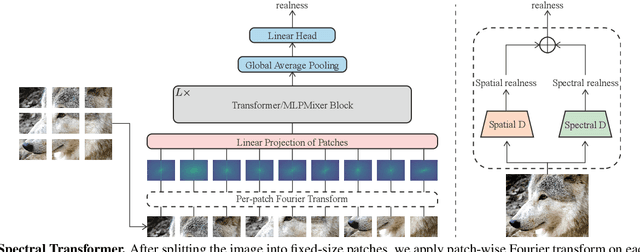
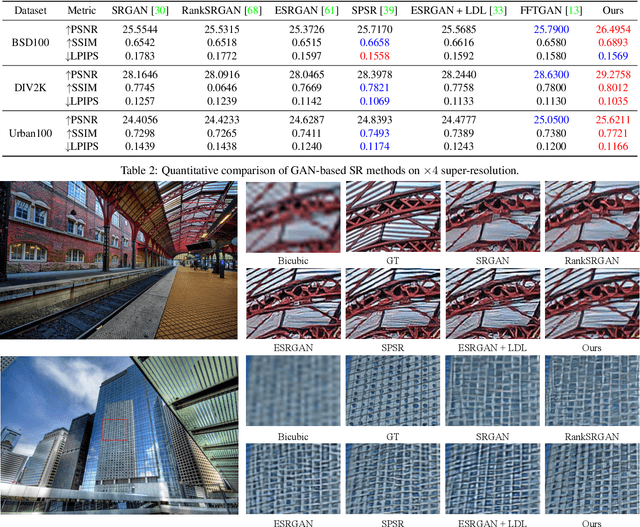
Several recent studies advocate the use of spectral discriminators, which evaluate the Fourier spectra of images for generative modeling. However, the effectiveness of the spectral discriminators is not well interpreted yet. We tackle this issue by examining the spectral discriminators in the context of perceptual image super-resolution (i.e., GAN-based SR), as SR image quality is susceptible to spectral changes. Our analyses reveal that the spectral discriminator indeed performs better than the ordinary (a.k.a. spatial) discriminator in identifying the differences in the high-frequency range; however, the spatial discriminator holds an advantage in the low-frequency range. Thus, we suggest that the spectral and spatial discriminators shall be used simultaneously. Moreover, we improve the spectral discriminators by first calculating the patch-wise Fourier spectrum and then aggregating the spectra by Transformer. We verify the effectiveness of the proposed method twofold. On the one hand, thanks to the additional spectral discriminator, our obtained SR images have their spectra better aligned to those of the real images, which leads to a better PD tradeoff. On the other hand, our ensembled discriminator predicts the perceptual quality more accurately, as evidenced in the no-reference image quality assessment task.
SA-BEV: Generating Semantic-Aware Bird's-Eye-View Feature for Multi-view 3D Object Detection
Jul 21, 2023
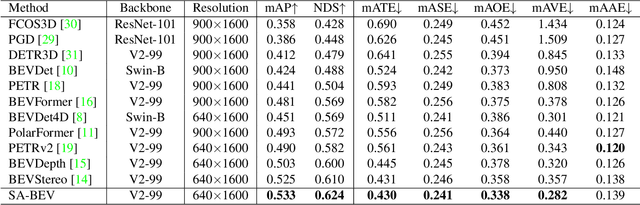
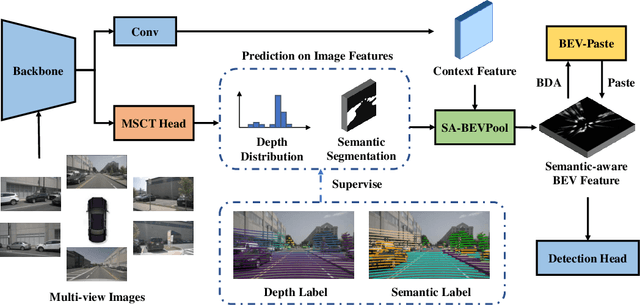
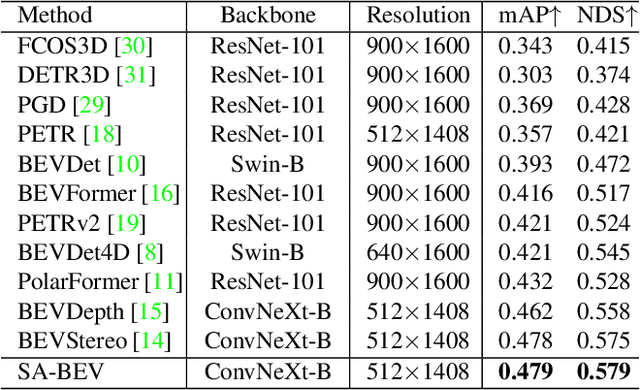
Recently, the pure camera-based Bird's-Eye-View (BEV) perception provides a feasible solution for economical autonomous driving. However, the existing BEV-based multi-view 3D detectors generally transform all image features into BEV features, without considering the problem that the large proportion of background information may submerge the object information. In this paper, we propose Semantic-Aware BEV Pooling (SA-BEVPool), which can filter out background information according to the semantic segmentation of image features and transform image features into semantic-aware BEV features. Accordingly, we propose BEV-Paste, an effective data augmentation strategy that closely matches with semantic-aware BEV feature. In addition, we design a Multi-Scale Cross-Task (MSCT) head, which combines task-specific and cross-task information to predict depth distribution and semantic segmentation more accurately, further improving the quality of semantic-aware BEV feature. Finally, we integrate the above modules into a novel multi-view 3D object detection framework, namely SA-BEV. Experiments on nuScenes show that SA-BEV achieves state-of-the-art performance. Code has been available at https://github.com/mengtan00/SA-BEV.git.
SACReg: Scene-Agnostic Coordinate Regression for Visual Localization
Jul 21, 2023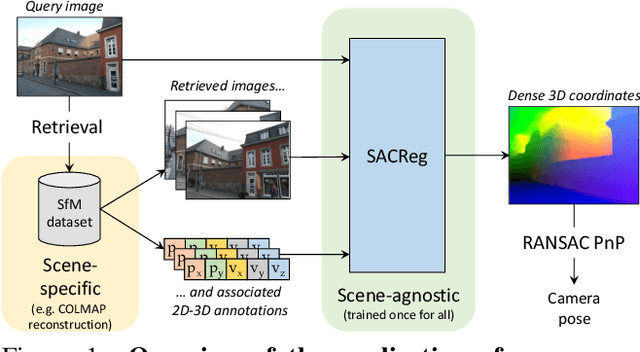
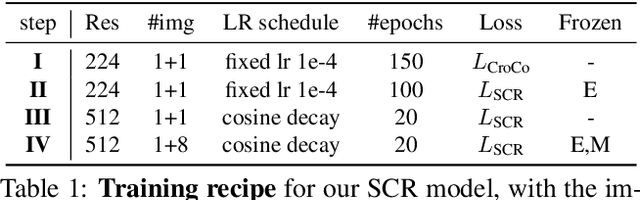
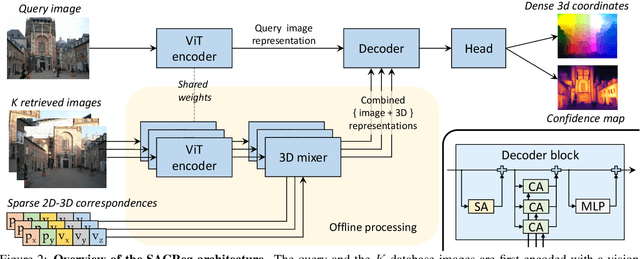
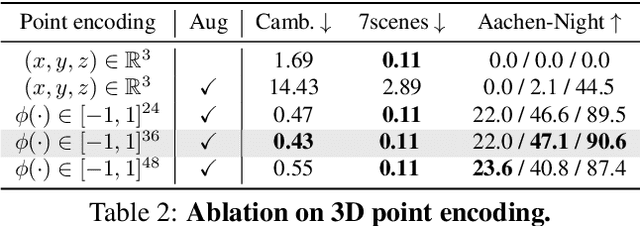
Scene coordinates regression (SCR), i.e., predicting 3D coordinates for every pixel of a given image, has recently shown promising potential. However, existing methods remain mostly scene-specific or limited to small scenes and thus hardly scale to realistic datasets. In this paper, we propose a new paradigm where a single generic SCR model is trained once to be then deployed to new test scenes, regardless of their scale and without further finetuning. For a given query image, it collects inputs from off-the-shelf image retrieval techniques and Structure-from-Motion databases: a list of relevant database images with sparse pointwise 2D-3D annotations. The model is based on the transformer architecture and can take a variable number of images and sparse 2D-3D annotations as input. It is trained on a few diverse datasets and significantly outperforms other scene regression approaches on several benchmarks, including scene-specific models, for visual localization. In particular, we set a new state of the art on the Cambridge localization benchmark, even outperforming feature-matching-based approaches.
Synthesizing Artistic Cinemagraphs from Text
Jul 12, 2023
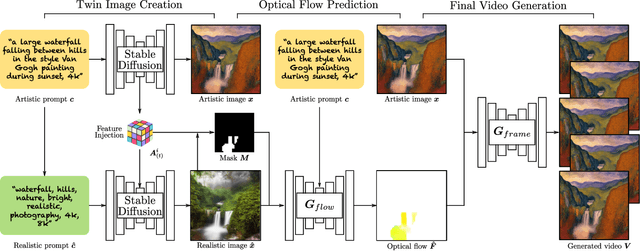


We introduce Text2Cinemagraph, a fully automated method for creating cinemagraphs from text descriptions - an especially challenging task when prompts feature imaginary elements and artistic styles, given the complexity of interpreting the semantics and motions of these images. Existing single-image animation methods fall short on artistic inputs, and recent text-based video methods frequently introduce temporal inconsistencies, struggling to keep certain regions static. To address these challenges, we propose an idea of synthesizing image twins from a single text prompt - a pair of an artistic image and its pixel-aligned corresponding natural-looking twin. While the artistic image depicts the style and appearance detailed in our text prompt, the realistic counterpart greatly simplifies layout and motion analysis. Leveraging existing natural image and video datasets, we can accurately segment the realistic image and predict plausible motion given the semantic information. The predicted motion can then be transferred to the artistic image to create the final cinemagraph. Our method outperforms existing approaches in creating cinemagraphs for natural landscapes as well as artistic and other-worldly scenes, as validated by automated metrics and user studies. Finally, we demonstrate two extensions: animating existing paintings and controlling motion directions using text.
Implicit Neural Representation in Medical Imaging: A Comparative Survey
Jul 30, 2023
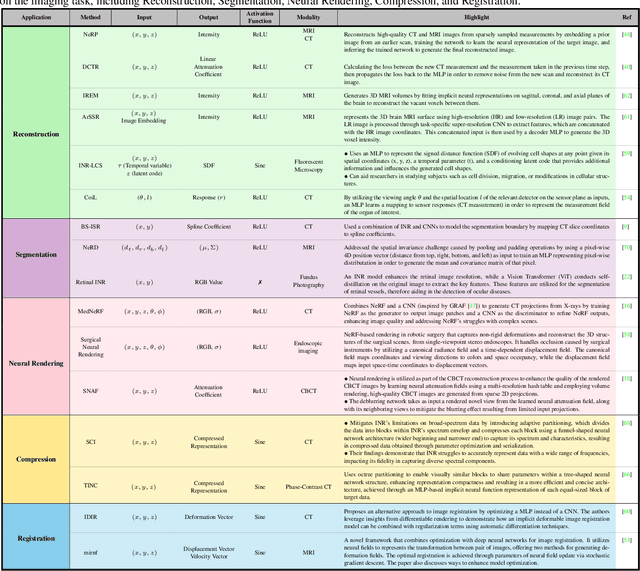
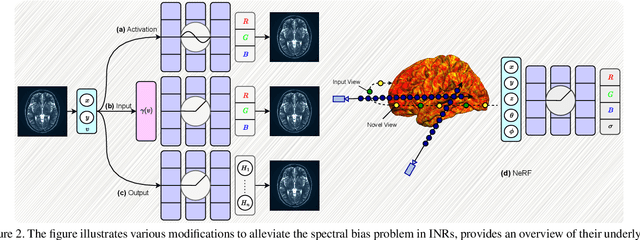

Implicit neural representations (INRs) have gained prominence as a powerful paradigm in scene reconstruction and computer graphics, demonstrating remarkable results. By utilizing neural networks to parameterize data through implicit continuous functions, INRs offer several benefits. Recognizing the potential of INRs beyond these domains, this survey aims to provide a comprehensive overview of INR models in the field of medical imaging. In medical settings, numerous challenging and ill-posed problems exist, making INRs an attractive solution. The survey explores the application of INRs in various medical imaging tasks, such as image reconstruction, segmentation, registration, novel view synthesis, and compression. It discusses the advantages and limitations of INRs, highlighting their resolution-agnostic nature, memory efficiency, ability to avoid locality biases, and differentiability, enabling adaptation to different tasks. Furthermore, the survey addresses the challenges and considerations specific to medical imaging data, such as data availability, computational complexity, and dynamic clinical scene analysis. It also identifies future research directions and opportunities, including integration with multi-modal imaging, real-time and interactive systems, and domain adaptation for clinical decision support. To facilitate further exploration and implementation of INRs in medical image analysis, we have provided a compilation of cited studies along with their available open-source implementations on \href{https://github.com/mindflow-institue/Awesome-Implicit-Neural-Representations-in-Medical-imaging}. Finally, we aim to consistently incorporate the most recent and relevant papers regularly.
PREIM3D: 3D Consistent Precise Image Attribute Editing from a Single Image
Apr 20, 2023
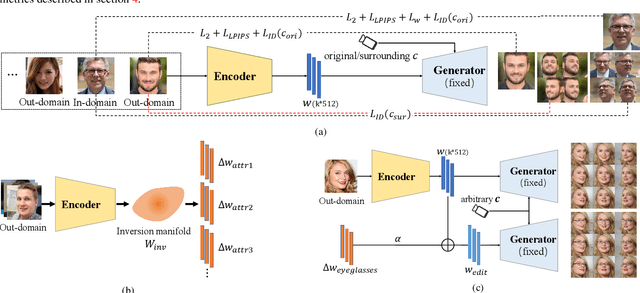
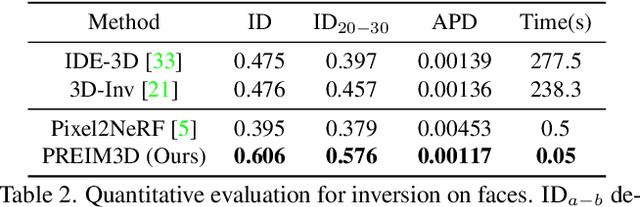
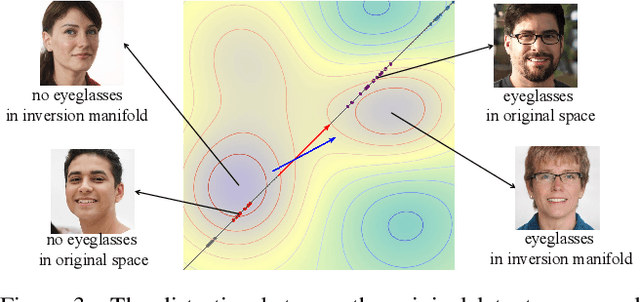
We study the 3D-aware image attribute editing problem in this paper, which has wide applications in practice. Recent methods solved the problem by training a shared encoder to map images into a 3D generator's latent space or by per-image latent code optimization and then edited images in the latent space. Despite their promising results near the input view, they still suffer from the 3D inconsistency of produced images at large camera poses and imprecise image attribute editing, like affecting unspecified attributes during editing. For more efficient image inversion, we train a shared encoder for all images. To alleviate 3D inconsistency at large camera poses, we propose two novel methods, an alternating training scheme and a multi-view identity loss, to maintain 3D consistency and subject identity. As for imprecise image editing, we attribute the problem to the gap between the latent space of real images and that of generated images. We compare the latent space and inversion manifold of GAN models and demonstrate that editing in the inversion manifold can achieve better results in both quantitative and qualitative evaluations. Extensive experiments show that our method produces more 3D consistent images and achieves more precise image editing than previous work. Source code and pretrained models can be found on our project page: https://mybabyyh.github.io/Preim3D/
Aphid Cluster Recognition and Detection in the Wild Using Deep Learning Models
Aug 10, 2023Aphid infestation poses a significant threat to crop production, rural communities, and global food security. While chemical pest control is crucial for maximizing yields, applying chemicals across entire fields is both environmentally unsustainable and costly. Hence, precise localization and management of aphids are essential for targeted pesticide application. The paper primarily focuses on using deep learning models for detecting aphid clusters. We propose a novel approach for estimating infection levels by detecting aphid clusters. To facilitate this research, we have captured a large-scale dataset from sorghum fields, manually selected 5,447 images containing aphids, and annotated each individual aphid cluster within these images. To facilitate the use of machine learning models, we further process the images by cropping them into patches, resulting in a labeled dataset comprising 151,380 image patches. Then, we implemented and compared the performance of four state-of-the-art object detection models (VFNet, GFLV2, PAA, and ATSS) on the aphid dataset. Extensive experimental results show that all models yield stable similar performance in terms of average precision and recall. We then propose to merge close neighboring clusters and remove tiny clusters caused by cropping, and the performance is further boosted by around 17%. The study demonstrates the feasibility of automatically detecting and managing insects using machine learning models. The labeled dataset will be made openly available to the research community.