 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image is First-order Norm+Linear Autoregressive
May 25, 2023
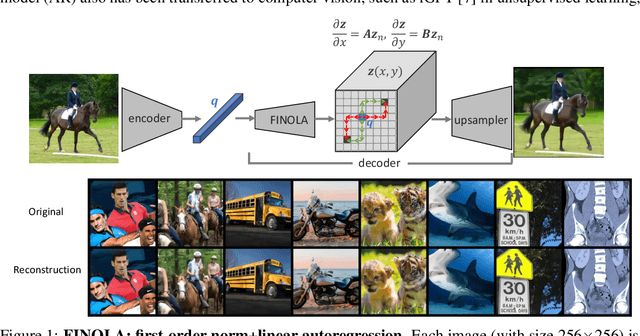
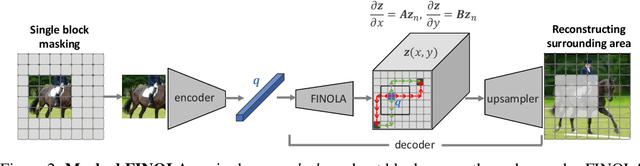
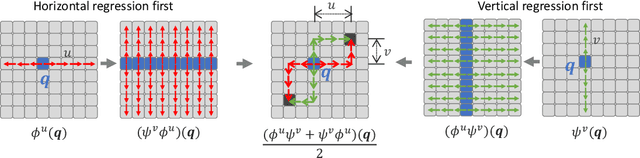
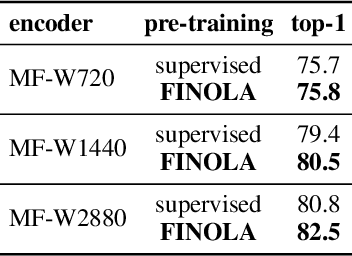
This paper reveals that every image can be understood as a first-order norm+linear autoregressive process, referred to as FINOLA, where norm+linear denotes the use of normalization before the linear model. We demonstrate that images of size 256$\times$256 can be reconstructed from a compressed vector using autoregression up to a 16$\times$16 feature map, followed by upsampling and convolution. This discovery sheds light on the underlying partial differential equations (PDEs) governing the latent feature space. Additionally, we investigate the application of FINOLA for self-supervised learning through a simple masked prediction technique. By encoding a single unmasked quadrant block, we can autoregressively predict the surrounding masked region. Remarkably, this pre-trained representation proves effective for image classification and object detection tasks, even in lightweight networks, without requiring fine-tuning. The code will be made publicly available.
Distance Matters For Improving Performance Estimation Under Covariate Shift
Aug 14, 2023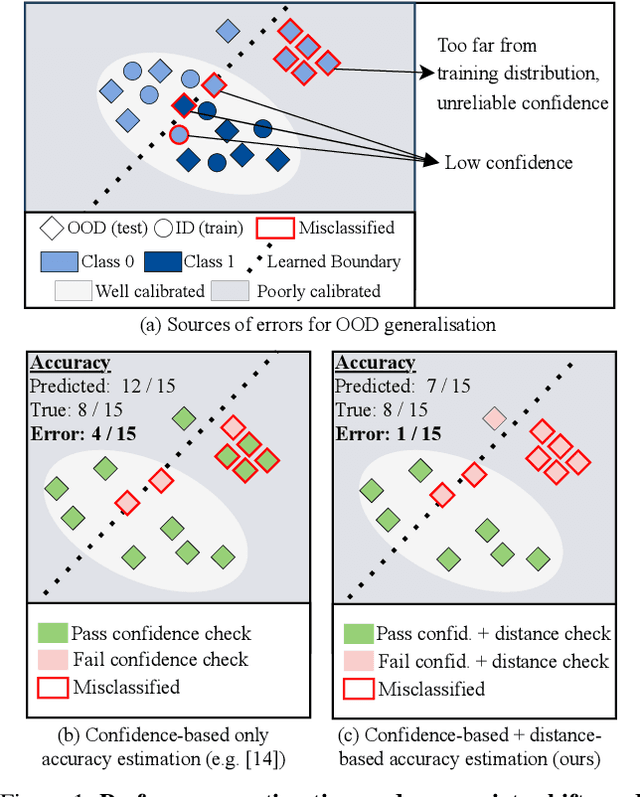
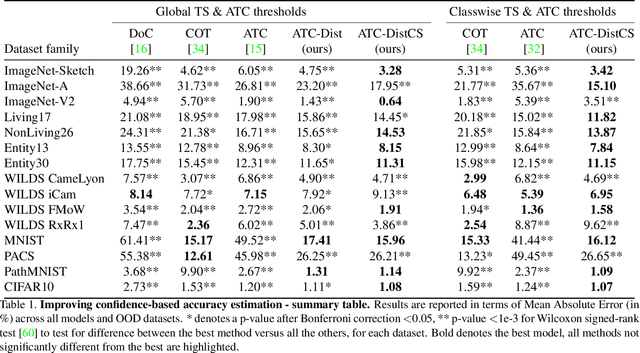
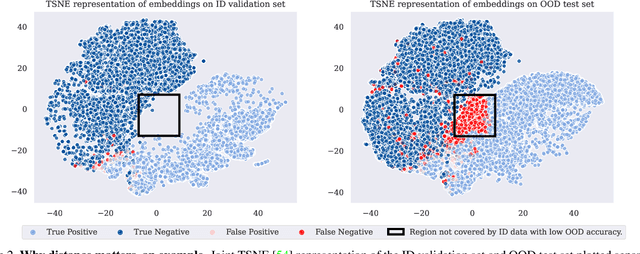
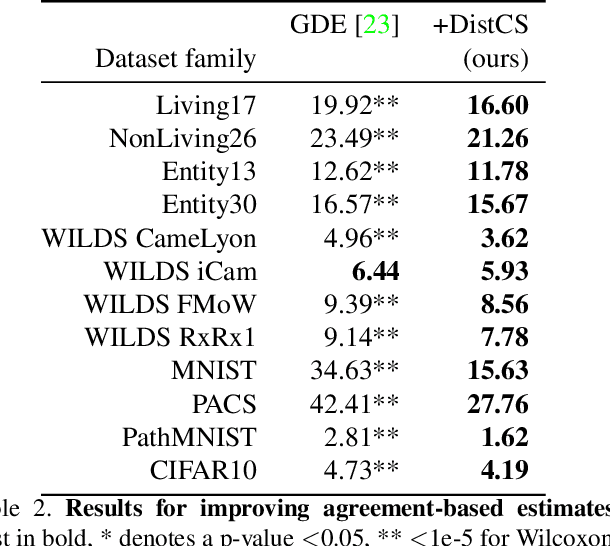
Performance estimation under covariate shift is a crucial component of safe AI model deployment, especially for sensitive use-cases. Recently, several solutions were proposed to tackle this problem, most leveraging model predictions or softmax confidence to derive accuracy estimates. However, under dataset shifts, confidence scores may become ill-calibrated if samples are too far from the training distribution. In this work, we show that taking into account distances of test samples to their expected training distribution can significantly improve performance estimation under covariate shift. Precisely, we introduce a "distance-check" to flag samples that lie too far from the expected distribution, to avoid relying on their untrustworthy model outputs in the accuracy estimation step. We demonstrate the effectiveness of this method on 13 image classification tasks, across a wide-range of natural and synthetic distribution shifts and hundreds of models, with a median relative MAE improvement of 27% over the best baseline across all tasks, and SOTA performance on 10 out of 13 tasks. Our code is publicly available at https://github.com/melanibe/distance_matters_performance_estimation.
Exploring Lightweight Hierarchical Vision Transformers for Efficient Visual Tracking
Aug 14, 2023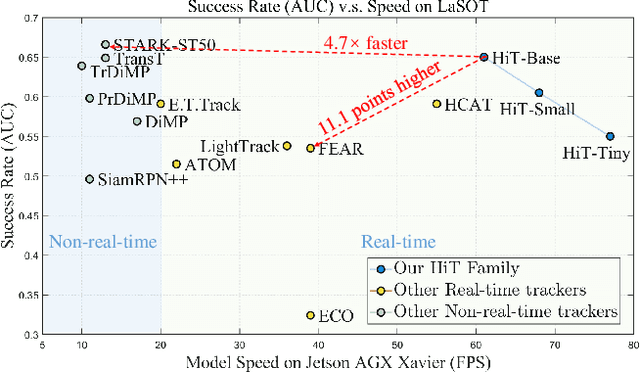
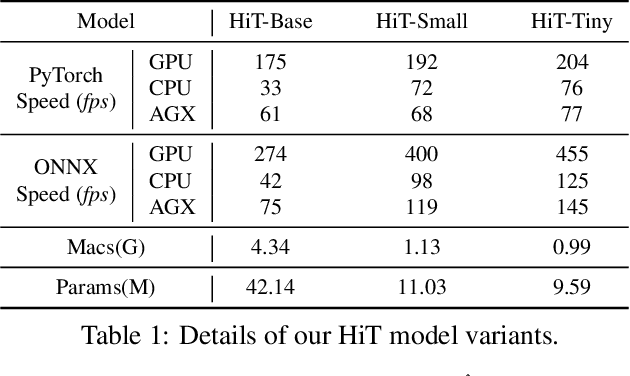
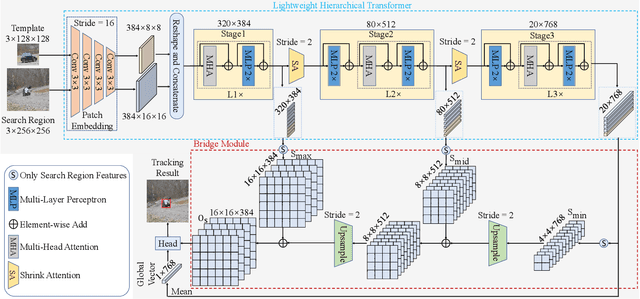
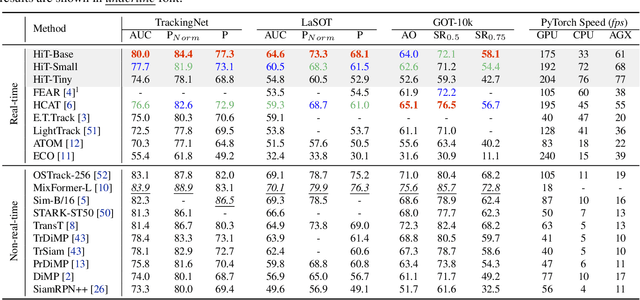
Transformer-based visual trackers have demonstrated significant progress owing to their superior modeling capabilities. However, existing trackers are hampered by low speed, limiting their applicability on devices with limited computational power. To alleviate this problem, we propose HiT, a new family of efficient tracking models that can run at high speed on different devices while retaining high performance. The central idea of HiT is the Bridge Module, which bridges the gap between modern lightweight transformers and the tracking framework. The Bridge Module incorporates the high-level information of deep features into the shallow large-resolution features. In this way, it produces better features for the tracking head. We also propose a novel dual-image position encoding technique that simultaneously encodes the position information of both the search region and template images. The HiT model achieves promising speed with competitive performance. For instance, it runs at 61 frames per second (fps) on the Nvidia Jetson AGX edge device. Furthermore, HiT attains 64.6% AUC on the LaSOT benchmark, surpassing all previous efficient trackers.
When Deep Learning Meets Multi-Task Learning in SAR ATR: Simultaneous Target Recognition and Segmentation
Aug 14, 2023
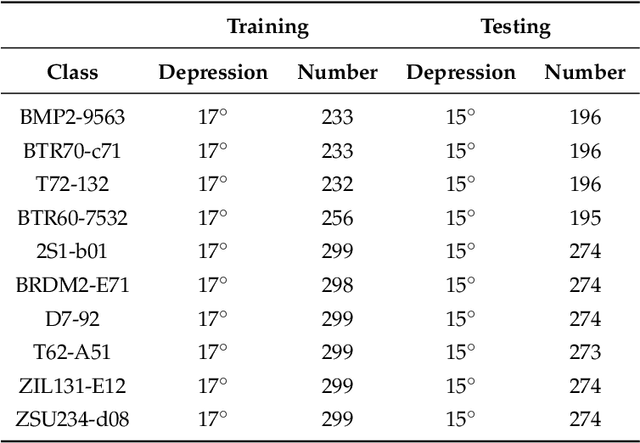
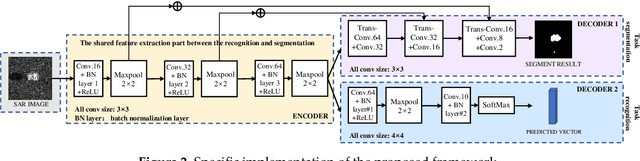
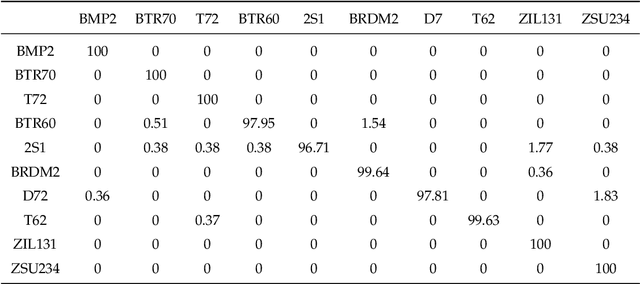
With the recent advances of deep learning, automatic target recognition (ATR) of synthetic aperture radar (SAR) has achieved superior performance. By not being limited to the target category, the SAR ATR system could benefit from the simultaneous extraction of multifarious target attributes. In this paper, we propose a new multi-task learning approach for SAR ATR, which could obtain the accurate category and precise shape of the targets simultaneously. By introducing deep learning theory into multi-task learning, we first propose a novel multi-task deep learning framework with two main structures: encoder and decoder. The encoder is constructed to extract sufficient image features in different scales for the decoder, while the decoder is a tasks-specific structure which employs these extracted features adaptively and optimally to meet the different feature demands of the recognition and segmentation. Therefore, the proposed framework has the ability to achieve superior recognition and segmentation performance. Based on the Moving and Stationary Target Acquisition and Recognition (MSTAR) dataset, experimental results show the superiority of the proposed framework in terms of recognition and segmentation.
Probabilistic MIMO U-Net: Efficient and Accurate Uncertainty Estimation for Pixel-wise Regression
Aug 14, 2023Uncertainty estimation in machine learning is paramount for enhancing the reliability and interpretability of predictive models, especially in high-stakes real-world scenarios. Despite the availability of numerous methods, they often pose a trade-off between the quality of uncertainty estimation and computational efficiency. Addressing this challenge, we present an adaptation of the Multiple-Input Multiple-Output (MIMO) framework -- an approach exploiting the overparameterization of deep neural networks -- for pixel-wise regression tasks. Our MIMO variant expands the applicability of the approach from simple image classification to broader computer vision domains. For that purpose, we adapted the U-Net architecture to train multiple subnetworks within a single model, harnessing the overparameterization in deep neural networks. Additionally, we introduce a novel procedure for synchronizing subnetwork performance within the MIMO framework. Our comprehensive evaluations of the resulting MIMO U-Net on two orthogonal datasets demonstrate comparable accuracy to existing models, superior calibration on in-distribution data, robust out-of-distribution detection capabilities, and considerable improvements in parameter size and inference time. Code available at github.com/antonbaumann/MIMO-Unet
SACReg: Scene-Agnostic Coordinate Regression for Visual Localization
Jul 28, 2023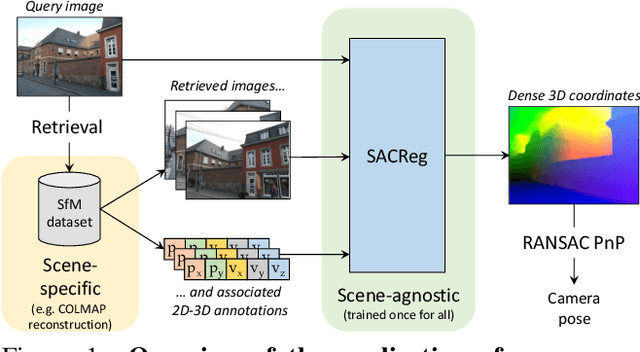
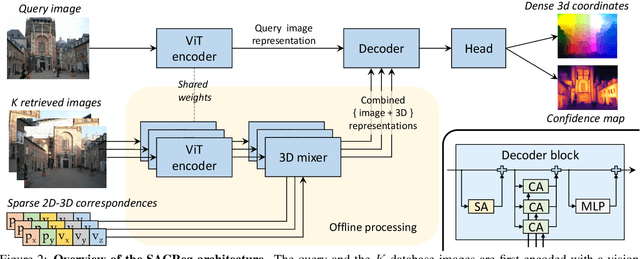
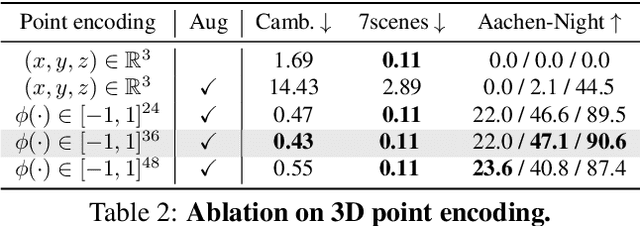
Scene coordinates regression (SCR), i.e., predicting 3D coordinates for every pixel of a given image, has recently shown promising potential. However, existing methods remain mostly scene-specific or limited to small scenes and thus hardly scale to realistic datasets. In this paper, we propose a new paradigm where a single generic SCR model is trained once to be then deployed to new test scenes, regardless of their scale and without further finetuning. For a given query image, it collects inputs from off-the-shelf image retrieval techniques and Structure-from-Motion databases: a list of relevant database images with sparse pointwise 2D-3D annotations. The model is based on the transformer architecture and can take a variable number of images and sparse 2D-3D annotations as input. It is trained on a few diverse datasets and significantly outperforms other scene regression approaches on several benchmarks, including scene-specific models, for visual localization. In particular, we set a new state of the art on the Cambridge localization benchmark, even outperforming feature-matching-based approaches.
DocDeshadower: Frequency-aware Transformer for Document Shadow Removal
Jul 28, 2023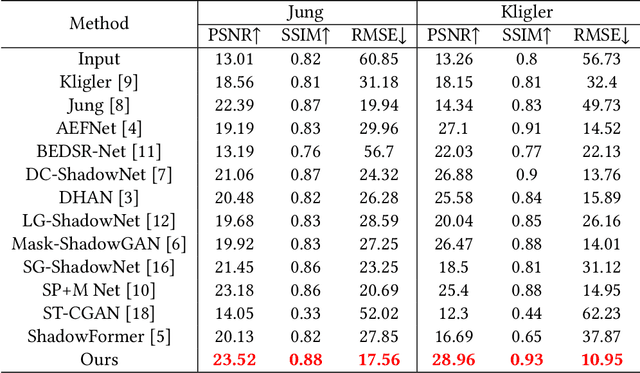
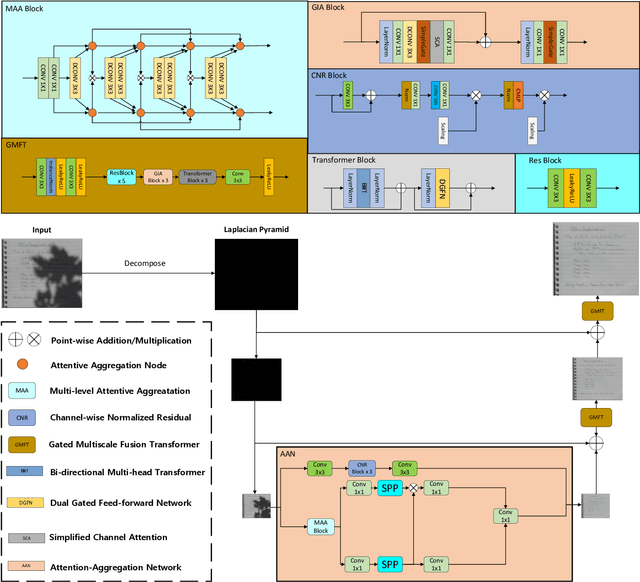
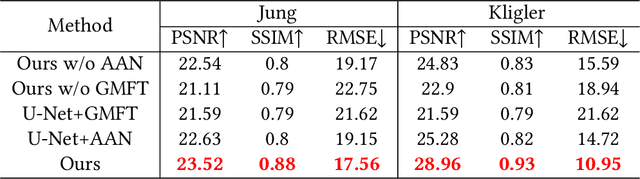

The presence of shadows significantly impacts the visual quality of scanned documents. However, the existing traditional techniques and deep learning methods used for shadow removal have several limitations. These methods either rely heavily on heuristics, resulting in suboptimal performance, or require large datasets to learn shadow-related features. In this study, we propose the DocDeshadower, a multi-frequency Transformer-based model built on Laplacian Pyramid. DocDeshadower is designed to remove shadows at different frequencies in a coarse-to-fine manner. To achieve this, we decompose the shadow image into different frequency bands using Laplacian Pyramid. In addition, we introduce two novel components to this model: the Attention-Aggregation Network and the Gated Multi-scale Fusion Transformer. The Attention-Aggregation Network is designed to remove shadows in the low-frequency part of the image, whereas the Gated Multi-scale Fusion Transformer refines the entire image at a global scale with its large perceptive field. Our extensive experiments demonstrate that DocDeshadower outperforms the current state-of-the-art methods in both qualitative and quantitative terms.
Universal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023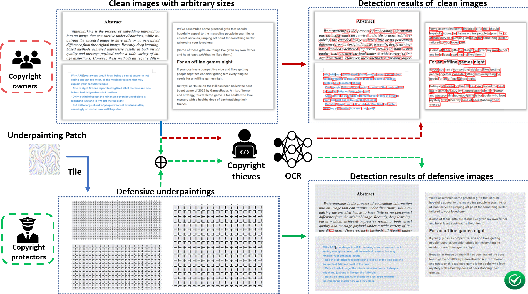

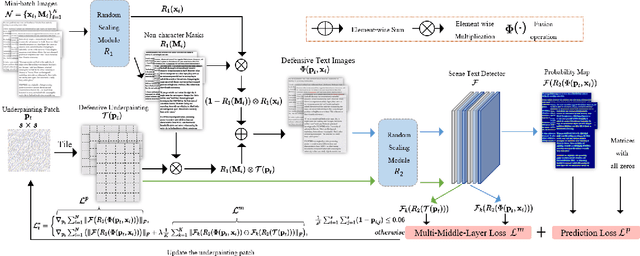
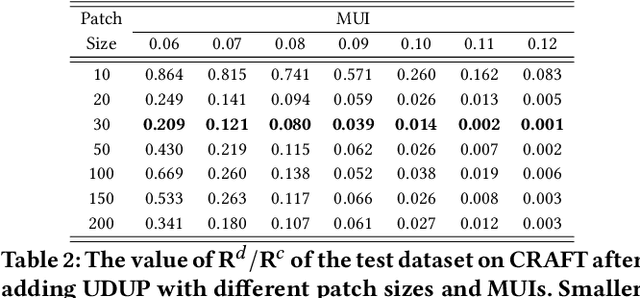
Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
Exploring Part-Informed Visual-Language Learning for Person Re-Identification
Aug 04, 2023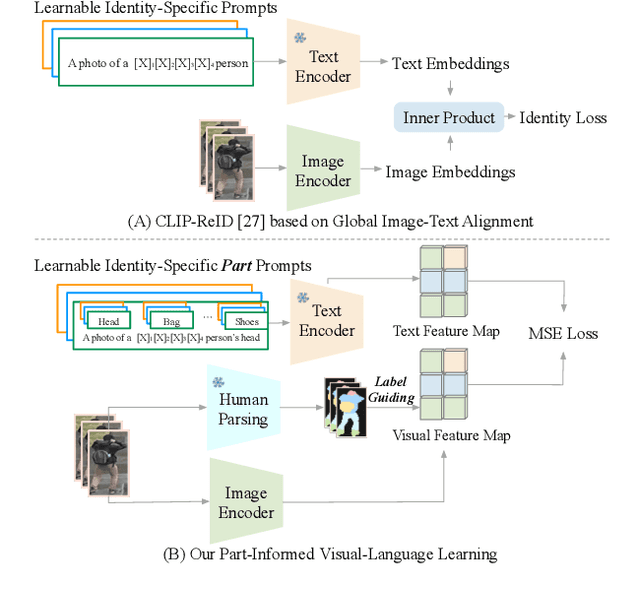
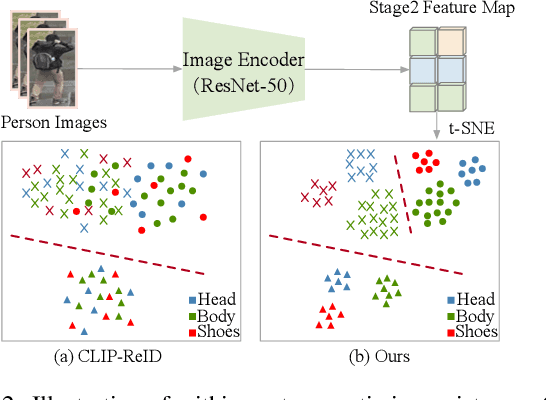
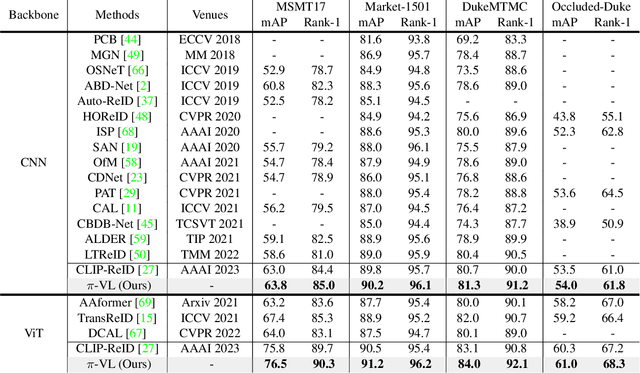
Recently, visual-language learning has shown great potential in enhancing visual-based person re-identification (ReID). Existing visual-language learning-based ReID methods often focus on whole-body scale image-text feature alignment, while neglecting supervisions on fine-grained part features. This choice simplifies the learning process but cannot guarantee within-part feature semantic consistency thus hindering the final performance. Therefore, we propose to enhance fine-grained visual features with part-informed language supervision for ReID tasks. The proposed method, named Part-Informed Visual-language Learning ($\pi$-VL), suggests that (i) a human parsing-guided prompt tuning strategy and (ii) a hierarchical fusion-based visual-language alignment paradigm play essential roles in ensuring within-part feature semantic consistency. Specifically, we combine both identity labels and parsing maps to constitute pixel-level text prompts and fuse multi-stage visual features with a light-weight auxiliary head to perform fine-grained image-text alignment. As a plug-and-play and inference-free solution, our $\pi$-VL achieves substantial improvements over previous state-of-the-arts on four common-used ReID benchmarks, especially reporting 90.3% Rank-1 and 76.5% mAP for the most challenging MSMT17 database without bells and whistles.
Multi-attacks: Many images $+$ the same adversarial attack $\to$ many target labels
Aug 04, 2023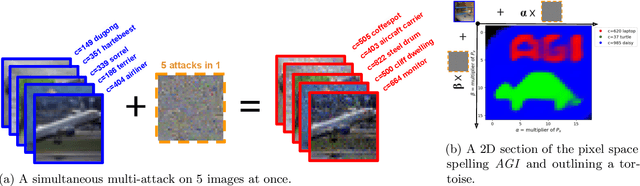
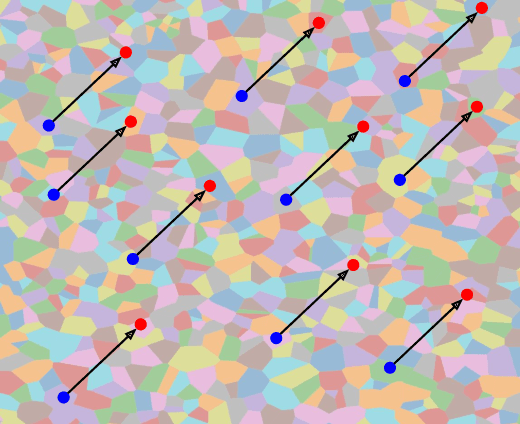
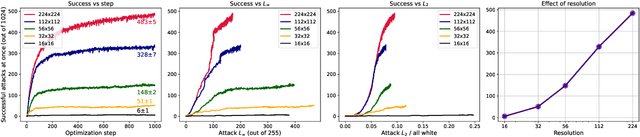
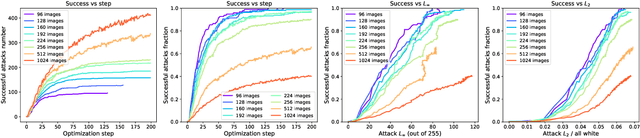
We show that we can easily design a single adversarial perturbation $P$ that changes the class of $n$ images $X_1,X_2,\dots,X_n$ from their original, unperturbed classes $c_1, c_2,\dots,c_n$ to desired (not necessarily all the same) classes $c^*_1,c^*_2,\dots,c^*_n$ for up to hundreds of images and target classes at once. We call these \textit{multi-attacks}. Characterizing the maximum $n$ we can achieve under different conditions such as image resolution, we estimate the number of regions of high class confidence around a particular image in the space of pixels to be around $10^{\mathcal{O}(100)}$, posing a significant problem for exhaustive defense strategies. We show several immediate consequences of this: adversarial attacks that change the resulting class based on their intensity, and scale-independent adversarial examples. To demonstrate the redundancy and richness of class decision boundaries in the pixel space, we look for its two-dimensional sections that trace images and spell words using particular classes. We also show that ensembling reduces susceptibility to multi-attacks, and that classifiers trained on random labels are more susceptible. Our code is available on GitHub.