 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023



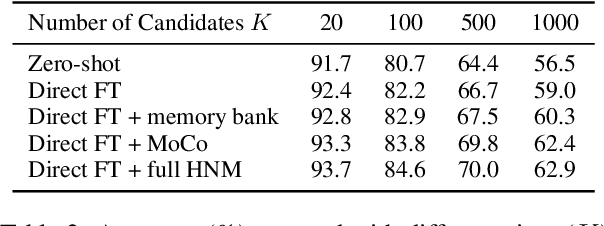
Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
ViT-Lens: Towards Omni-modal Representations
Aug 20, 2023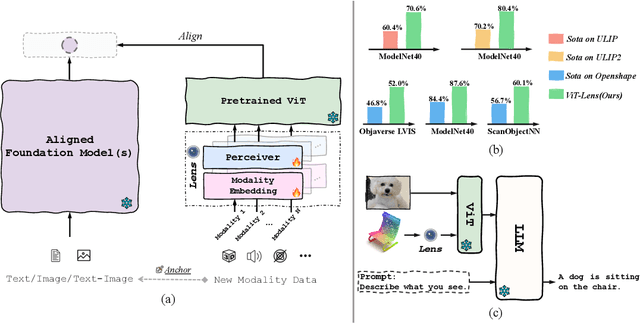
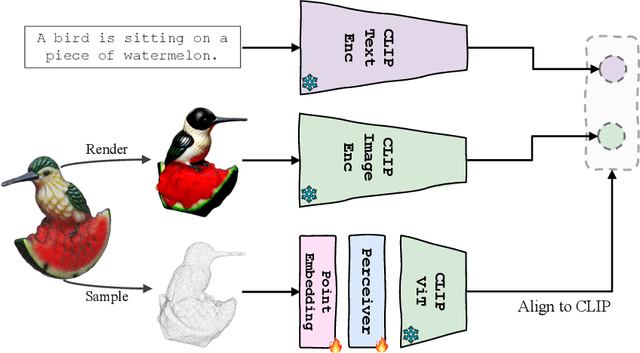
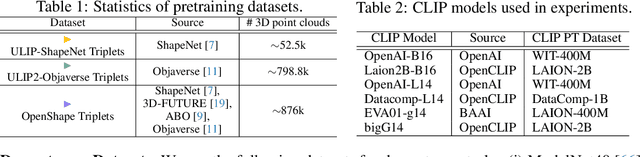
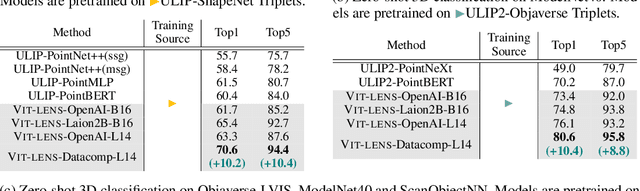
Though the success of CLIP-based training recipes in vision-language models, their scalability to more modalities (e.g., 3D, audio, etc.) is limited to large-scale data, which is expensive or even inapplicable for rare modalities. In this paper, we present ViT-Lens that facilitates efficient omni-modal representation learning by perceiving novel modalities with a pretrained ViT and aligning to a pre-defined space. Specifically, the modality-specific lens is tuned to project multimodal signals to the shared embedding space, which are then processed by a strong ViT that carries pre-trained image knowledge. The encoded multimodal representations are optimized toward aligning with the modal-independent space, pre-defined by off-the-shelf foundation models. A well-trained lens with a ViT backbone has the potential to serve as one of these foundation models, supervising the learning of subsequent modalities. ViT-Lens provides a unified solution for representation learning of increasing modalities with two appealing benefits: (i) Exploiting the pretrained ViT across tasks and domains effectively with efficient data regime; (ii) Emergent downstream capabilities of novel modalities are demonstrated due to the modality alignment space. We evaluate ViT-Lens in the context of 3D as an initial verification. In zero-shot 3D classification, ViT-Lens achieves substantial improvements over previous state-of-the-art, showing 52.0% accuracy on Objaverse-LVIS, 87.4% on ModelNet40, and 60.6% on ScanObjectNN. Furthermore, we enable zero-shot 3D question-answering by simply integrating the trained 3D lens into the InstructBLIP model without any adaptation. We will release the results of ViT-Lens on more modalities in the near future.
BAVS: Bootstrapping Audio-Visual Segmentation by Integrating Foundation Knowledge
Aug 20, 2023
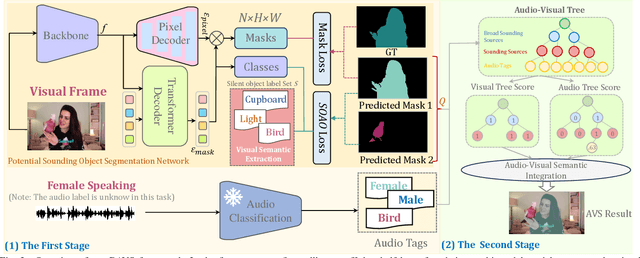
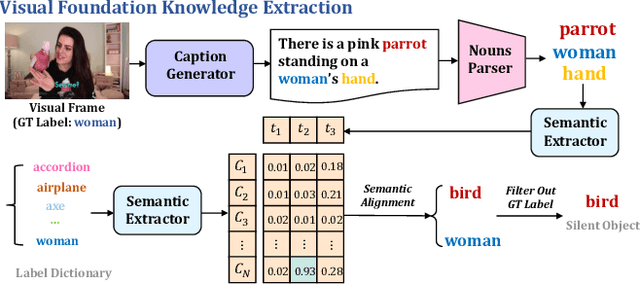
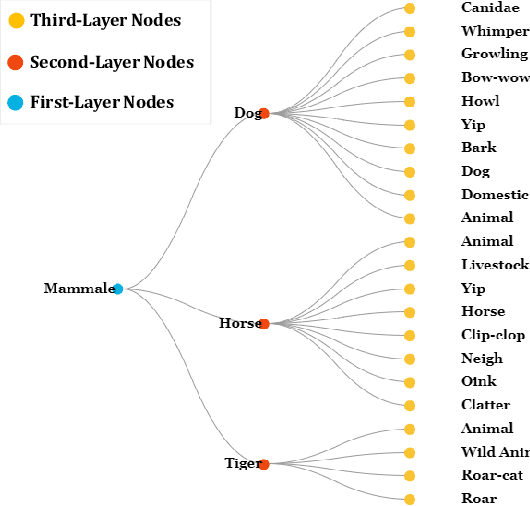
Given an audio-visual pair, audio-visual segmentation (AVS) aims to locate sounding sources by predicting pixel-wise maps. Previous methods assume that each sound component in an audio signal always has a visual counterpart in the image. However, this assumption overlooks that off-screen sounds and background noise often contaminate the audio recordings in real-world scenarios. They impose significant challenges on building a consistent semantic mapping between audio and visual signals for AVS models and thus impede precise sound localization. In this work, we propose a two-stage bootstrapping audio-visual segmentation framework by incorporating multi-modal foundation knowledge. In a nutshell, our BAVS is designed to eliminate the interference of background noise or off-screen sounds in segmentation by establishing the audio-visual correspondences in an explicit manner. In the first stage, we employ a segmentation model to localize potential sounding objects from visual data without being affected by contaminated audio signals. Meanwhile, we also utilize a foundation audio classification model to discern audio semantics. Considering the audio tags provided by the audio foundation model are noisy, associating object masks with audio tags is not trivial. Thus, in the second stage, we develop an audio-visual semantic integration strategy (AVIS) to localize the authentic-sounding objects. Here, we construct an audio-visual tree based on the hierarchical correspondence between sounds and object categories. We then examine the label concurrency between the localized objects and classified audio tags by tracing the audio-visual tree. With AVIS, we can effectively segment real-sounding objects. Extensive experiments demonstrate the superiority of our method on AVS datasets, particularly in scenarios involving background noise. Our project website is https://yenanliu.github.io/AVSS.github.io/.
Towards a Visual-Language Foundation Model for Computational Pathology
Jul 24, 2023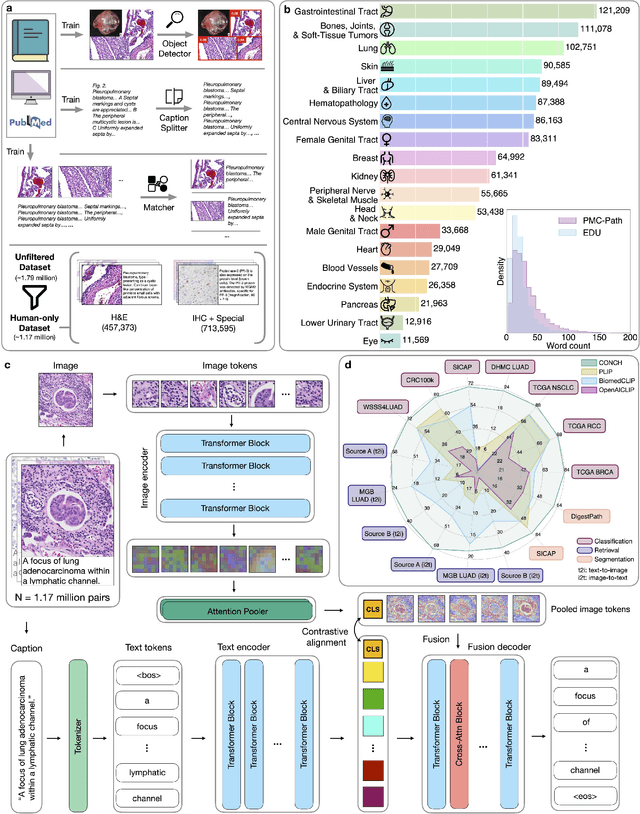
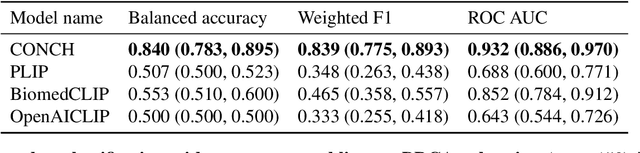
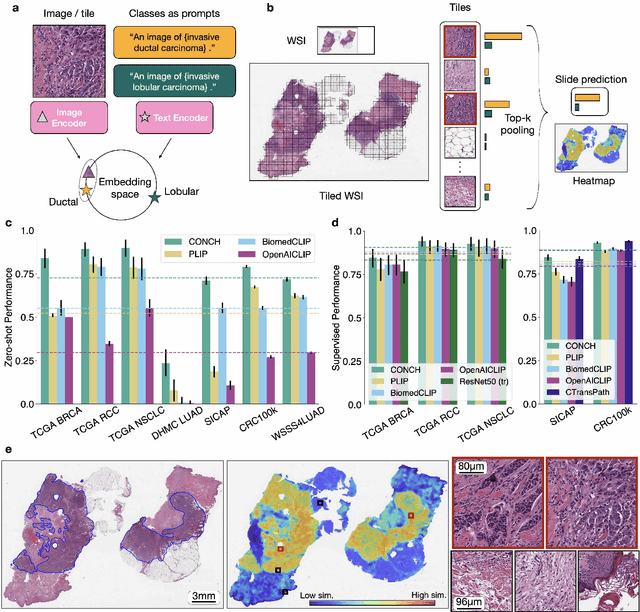
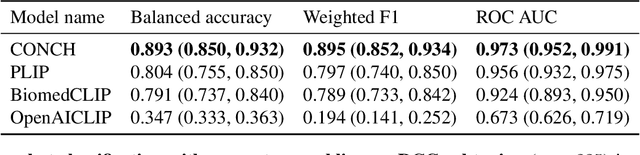
The accelerated adoption of digital pathology and advances in deep learning have enabled the development of powerful models for various pathology tasks across a diverse array of diseases and patient cohorts. However, model training is often difficult due to label scarcity in the medical domain and the model's usage is limited by the specific task and disease for which it is trained. Additionally, most models in histopathology leverage only image data, a stark contrast to how humans teach each other and reason about histopathologic entities. We introduce CONtrastive learning from Captions for Histopathology (CONCH), a visual-language foundation model developed using diverse sources of histopathology images, biomedical text, and notably over 1.17 million image-caption pairs via task-agnostic pretraining. Evaluated on a suite of 13 diverse benchmarks, CONCH can be transferred to a wide range of downstream tasks involving either or both histopathology images and text, achieving state-of-the-art performance on histology image classification, segmentation, captioning, text-to-image and image-to-text retrieval. CONCH represents a substantial leap over concurrent visual-language pretrained systems for histopathology, with the potential to directly facilitate a wide array of machine learning-based workflows requiring minimal or no further supervised fine-tuning.
Parameter-Efficient Fine-Tuning for Medical Image Analysis: The Missed Opportunity
May 24, 2023
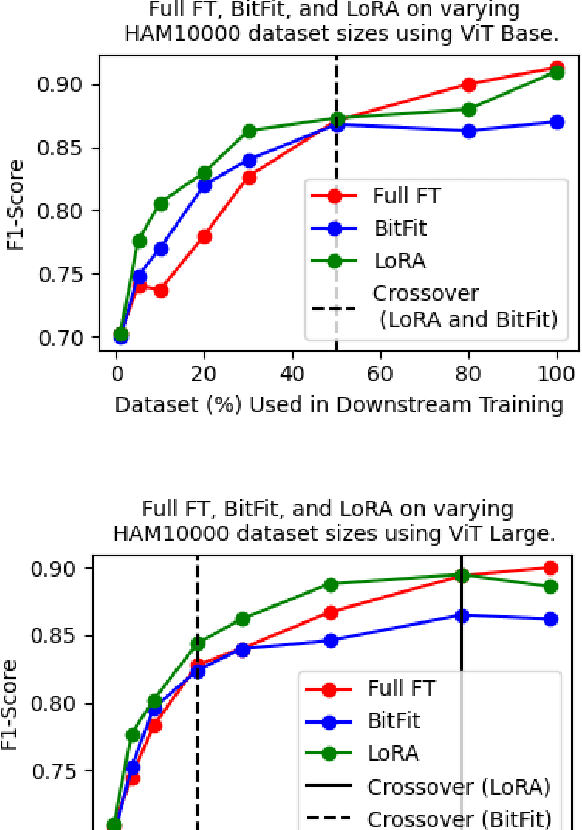
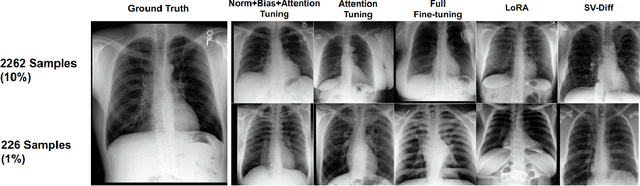
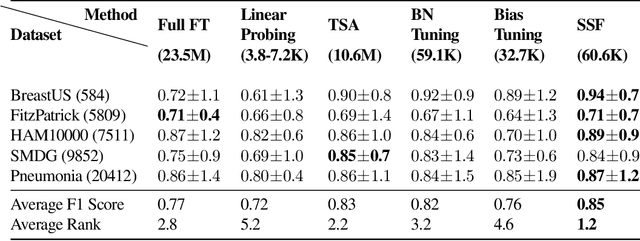
We present a comprehensive evaluation of Parameter-Efficient Fine-Tuning (PEFT) techniques for diverse medical image analysis tasks. PEFT is increasingly exploited as a valuable approach for knowledge transfer from pre-trained models in natural language processing, vision, speech, and cross-modal tasks, such as vision-language and text-to-image generation. However, its application in medical image analysis remains relatively unexplored. As foundation models are increasingly exploited in the medical domain, it is crucial to investigate and comparatively assess various strategies for knowledge transfer that can bolster a range of downstream tasks. Our study, the first of its kind (to the best of our knowledge), evaluates 16 distinct PEFT methodologies proposed for convolutional and transformer-based networks, focusing on image classification and text-to-image generation tasks across six medical datasets ranging in size, modality, and complexity. Through a battery of more than 600 controlled experiments, we demonstrate performance gains of up to 22% under certain scenarios and demonstrate the efficacy of PEFT for medical text-to-image generation. Further, we reveal the instances where PEFT methods particularly dominate over conventional fine-tuning approaches by studying their relationship with downstream data volume.
Self-supervised Few-shot Learning for Semantic Segmentation: An Annotation-free Approach
Jul 26, 2023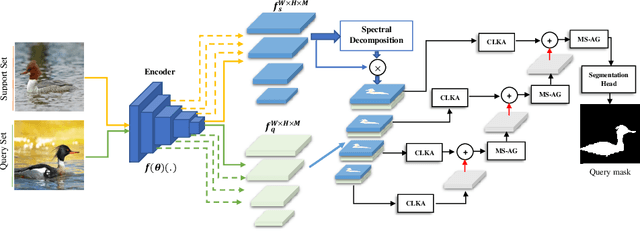
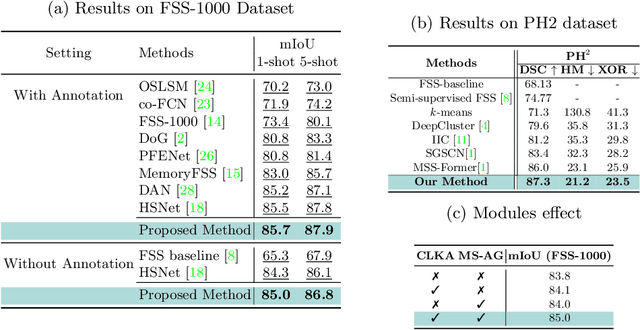
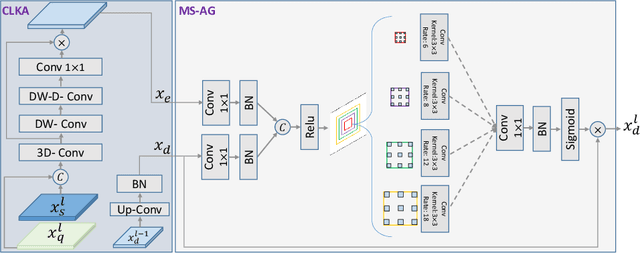

Few-shot semantic segmentation (FSS) offers immense potential in the field of medical image analysis, enabling accurate object segmentation with limited training data. However, existing FSS techniques heavily rely on annotated semantic classes, rendering them unsuitable for medical images due to the scarcity of annotations. To address this challenge, multiple contributions are proposed: First, inspired by spectral decomposition methods, the problem of image decomposition is reframed as a graph partitioning task. The eigenvectors of the Laplacian matrix, derived from the feature affinity matrix of self-supervised networks, are analyzed to estimate the distribution of the objects of interest from the support images. Secondly, we propose a novel self-supervised FSS framework that does not rely on any annotation. Instead, it adaptively estimates the query mask by leveraging the eigenvectors obtained from the support images. This approach eliminates the need for manual annotation, making it particularly suitable for medical images with limited annotated data. Thirdly, to further enhance the decoding of the query image based on the information provided by the support image, we introduce a multi-scale large kernel attention module. By selectively emphasizing relevant features and details, this module improves the segmentation process and contributes to better object delineation. Evaluations on both natural and medical image datasets demonstrate the efficiency and effectiveness of our method. Moreover, the proposed approach is characterized by its generality and model-agnostic nature, allowing for seamless integration with various deep architectures. The code is publicly available at \href{https://github.com/mindflow-institue/annotation_free_fewshot}{\textcolor{magenta}{GitHub}}.
Towards Head Computed Tomography Image Reconstruction Standardization with Deep Learning Assisted Automatic Detection
Jul 31, 2023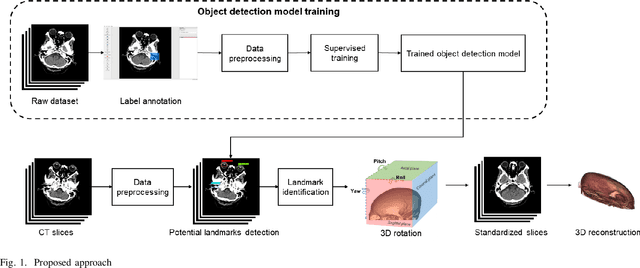
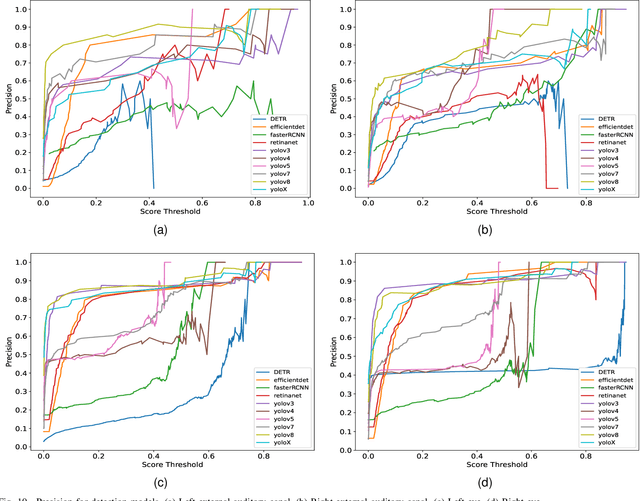
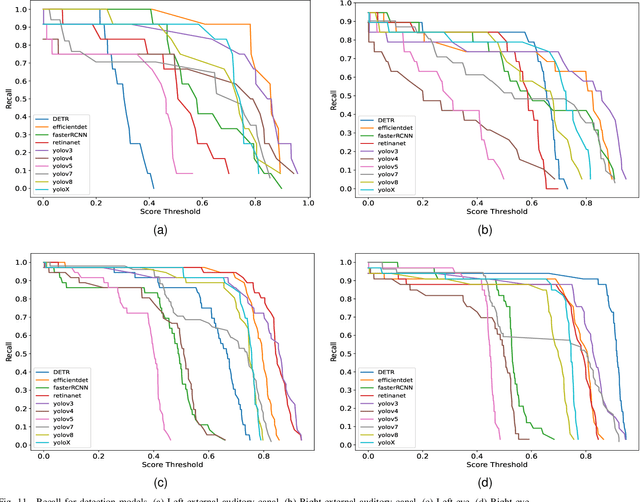

Three-dimensional (3D) reconstruction of head Computed Tomography (CT) images elucidates the intricate spatial relationships of tissue structures, thereby assisting in accurate diagnosis. Nonetheless, securing an optimal head CT scan without deviation is challenging in clinical settings, owing to poor positioning by technicians, patient's physical constraints, or CT scanner tilt angle restrictions. Manual formatting and reconstruction not only introduce subjectivity but also strain time and labor resources. To address these issues, we propose an efficient automatic head CT images 3D reconstruction method, improving accuracy and repeatability, as well as diminishing manual intervention. Our approach employs a deep learning-based object detection algorithm, identifying and evaluating orbitomeatal line landmarks to automatically reformat the images prior to reconstruction. Given the dearth of existing evaluations of object detection algorithms in the context of head CT images, we compared ten methods from both theoretical and experimental perspectives. By exploring their precision, efficiency, and robustness, we singled out the lightweight YOLOv8 as the aptest algorithm for our task, with an mAP of 92.91% and impressive robustness against class imbalance. Our qualitative evaluation of standardized reconstruction results demonstrates the clinical practicability and validity of our method.
Integrating Geometric Control into Text-to-Image Diffusion Models for High-Quality Detection Data Generation via Text Prompt
Jun 09, 2023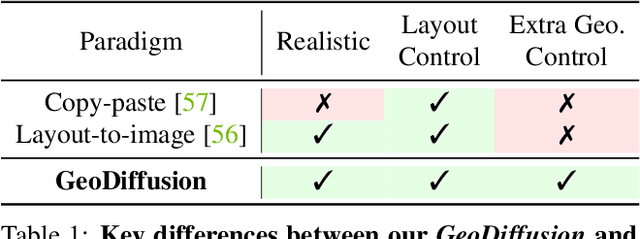
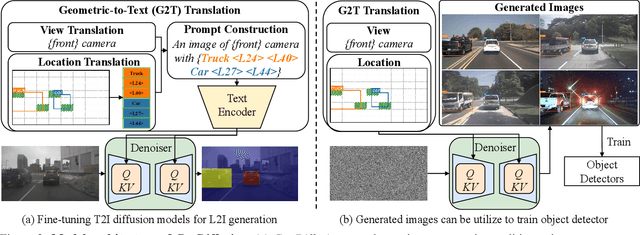
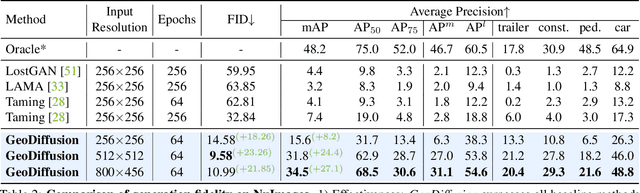
Diffusion models have attracted significant attention due to their remarkable ability to create content and generate data for tasks such as image classification. However, the usage of diffusion models to generate high-quality object detection data remains an underexplored area, where not only the image-level perceptual quality but also geometric conditions such as bounding boxes and camera views are essential. Previous studies have utilized either copy-paste synthesis or layout-to-image (L2I) generation with specifically designed modules to encode semantic layouts. In this paper, we propose GeoDiffusion, a simple framework that can flexibly translate various geometric conditions into text prompts and empower the pre-trained text-to-image (T2I) diffusion models for high-quality detection data generation. Unlike previous L2I methods, our GeoDiffusion is able to encode not only bounding boxes but also extra geometric conditions such as camera views in self-driving scenes. Extensive experiments demonstrate GeoDiffusion outperforms previous L2I methods while maintaining 4x training time faster. To the best of our knowledge, this is the first work to adopt diffusion models for layout-to-image generation with geometric conditions and demonstrate that L2I-generated images can be beneficial for improving the performance of object detectors.
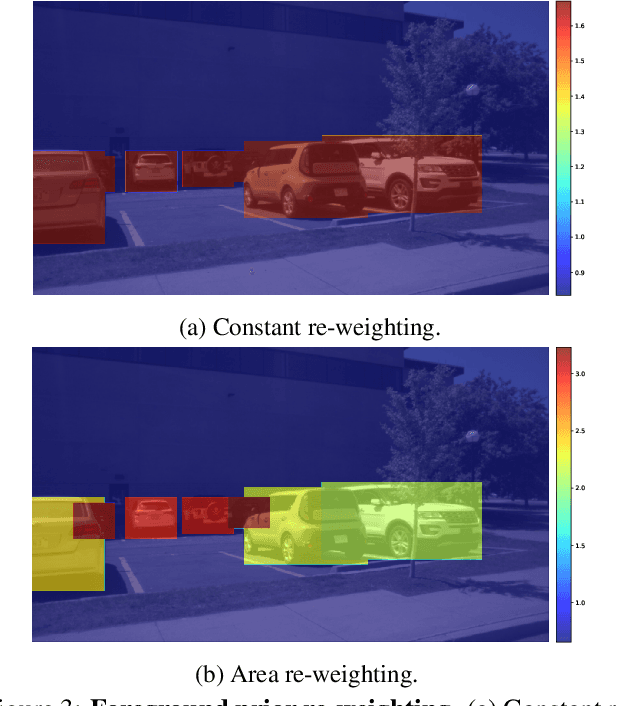
Multi-level Multiple Instance Learning with Transformer for Whole Slide Image Classification
Jun 08, 2023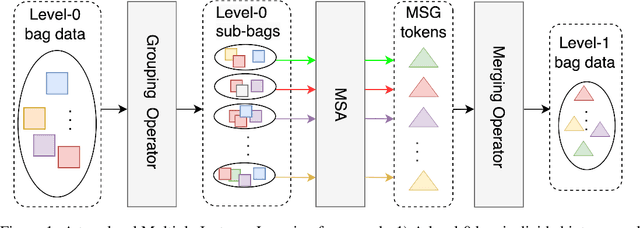
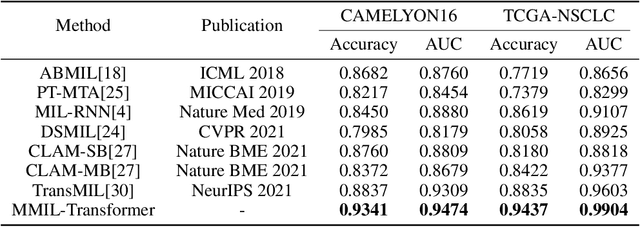
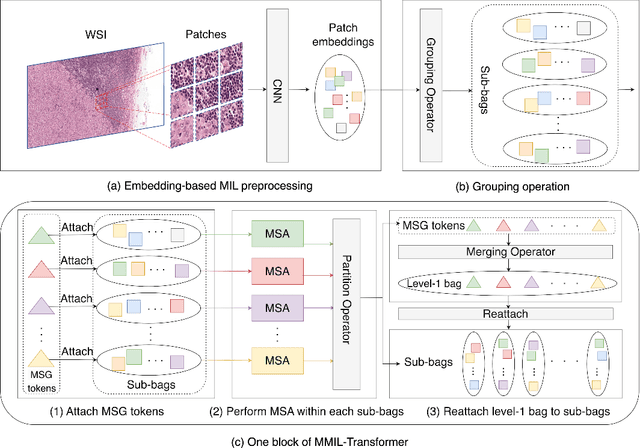
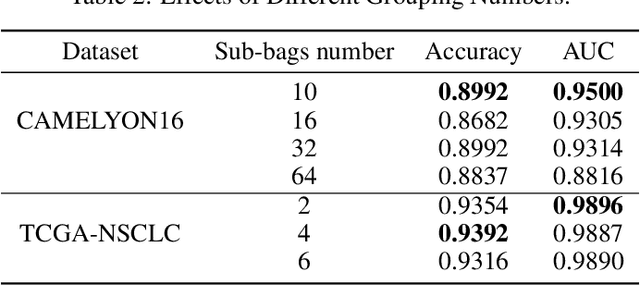
Whole slide image (WSI) refers to a type of high-resolution scanned tissue image, which is extensively employed in computer-assisted diagnosis (CAD). The extremely high resolution and limited availability of region-level annotations make it challenging to employ deep learning methods for WSI-based digital diagnosis. Multiple instance learning (MIL) is a powerful tool to address the weak annotation problem, while Transformer has shown great success in the field of visual tasks. The combination of both should provide new insights for deep learning based image diagnosis. However, due to the limitations of single-level MIL and the attention mechanism's constraints on sequence length, directly applying Transformer to WSI-based MIL tasks is not practical. To tackle this issue, we propose a Multi-level MIL with Transformer (MMIL-Transformer) approach. By introducing a hierarchical structure to MIL, this approach enables efficient handling of MIL tasks that involve a large number of instances. To validate its effectiveness, we conducted a set of experiments on WSIs classification task, where MMIL-Transformer demonstrate superior performance compared to existing state-of-the-art methods. Our proposed approach achieves test AUC 94.74% and test accuracy 93.41% on CAMELYON16 dataset, test AUC 99.04% and test accuracy 94.37% on TCGA-NSCLC dataset, respectively. All code and pre-trained models are available at: https://github.com/hustvl/MMIL-Transformer
Devil is in Channels: Contrastive Single Domain Generalization for Medical Image Segmentation
Jun 08, 2023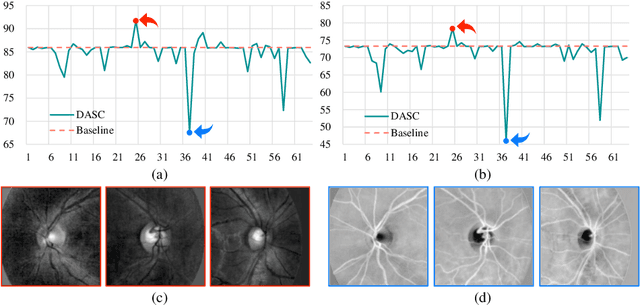
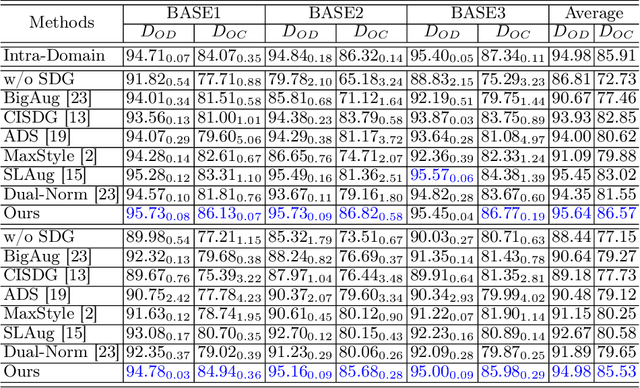
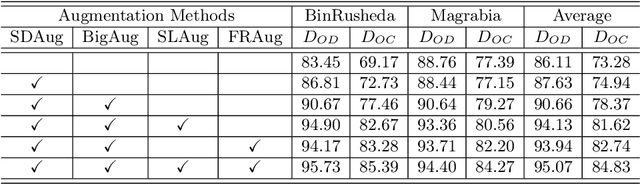
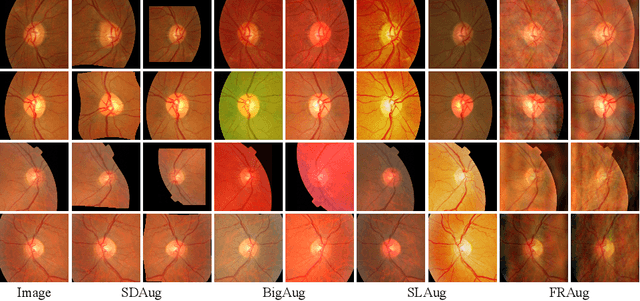
Deep learning-based medical image segmentation models suffer from performance degradation when deployed to a new healthcare center. To address this issue, unsupervised domain adaptation and multi-source domain generalization methods have been proposed, which, however, are less favorable for clinical practice due to the cost of acquiring target-domain data and the privacy concerns associated with redistributing the data from multiple source domains. In this paper, we propose a \textbf{C}hannel-level \textbf{C}ontrastive \textbf{S}ingle \textbf{D}omain \textbf{G}eneralization (\textbf{C$^2$SDG}) model for medical image segmentation. In C$^2$SDG, the shallower features of each image and its style-augmented counterpart are extracted and used for contrastive training, resulting in the disentangled style representations and structure representations. The segmentation is performed based solely on the structure representations. Our method is novel in the contrastive perspective that enables channel-wise feature disentanglement using a single source domain. We evaluated C$^2$SDG against six SDG methods on a multi-domain joint optic cup and optic disc segmentation benchmark. Our results suggest the effectiveness of each module in C$^2$SDG and also indicate that C$^2$SDG outperforms the baseline and all competing methods with a large margin. The code will be available at \url{https://github.com/ShishuaiHu/CCSDG}.