 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-based Visual Servo Control for Aerial Manipulation Using a Fully-Actuated UAV
Jun 28, 2023


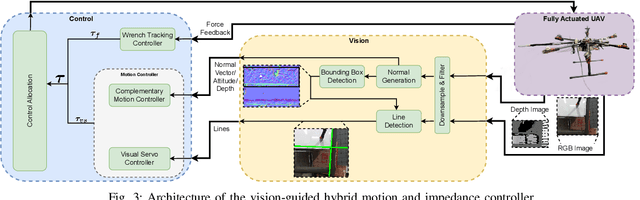
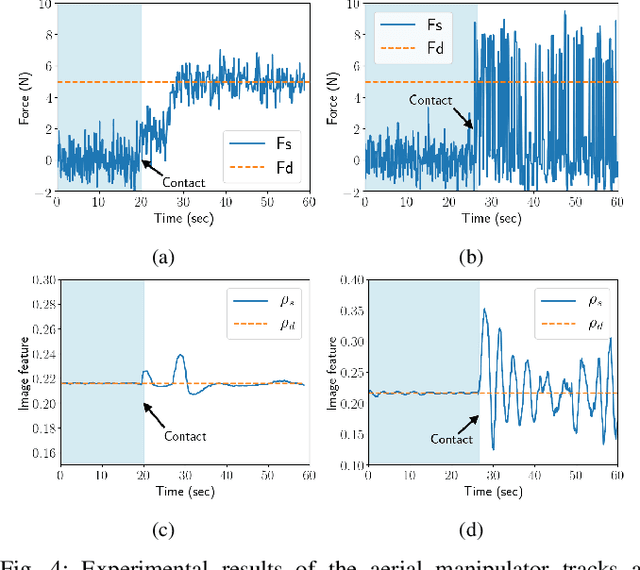
Using Unmanned Aerial Vehicles (UAVs) to perform high-altitude manipulation tasks beyond just passive visual application can reduce the time, cost, and risk of human workers. Prior research on aerial manipulation has relied on either ground truth state estimate or GPS/total station with some Simultaneous Localization and Mapping (SLAM) algorithms, which may not be practical for many applications close to infrastructure with degraded GPS signal or featureless environments. Visual servo can avoid the need to estimate robot pose. Existing works on visual servo for aerial manipulation either address solely end-effector position control or rely on precise velocity measurement and pre-defined visual visual marker with known pattern. Furthermore, most of previous work used under-actuated UAVs, resulting in complicated mechanical and hence control design for the end-effector. This paper develops an image-based visual servo control strategy for bridge maintenance using a fully-actuated UAV. The main components are (1) a visual line detection and tracking system, (2) a hybrid impedance force and motion control system. Our approach does not rely on either robot pose/velocity estimation from an external localization system or pre-defined visual markers. The complexity of the mechanical system and controller architecture is also minimized due to the fully-actuated nature. Experiments show that the system can effectively execute motion tracking and force holding using only the visual guidance for the bridge painting. To the best of our knowledge, this is one of the first studies on aerial manipulation using visual servo that is capable of achieving both motion and force control without the need of external pose/velocity information or pre-defined visual guidance.
MIS-FM: 3D Medical Image Segmentation using Foundation Models Pretrained on a Large-Scale Unannotated Dataset
Jun 29, 2023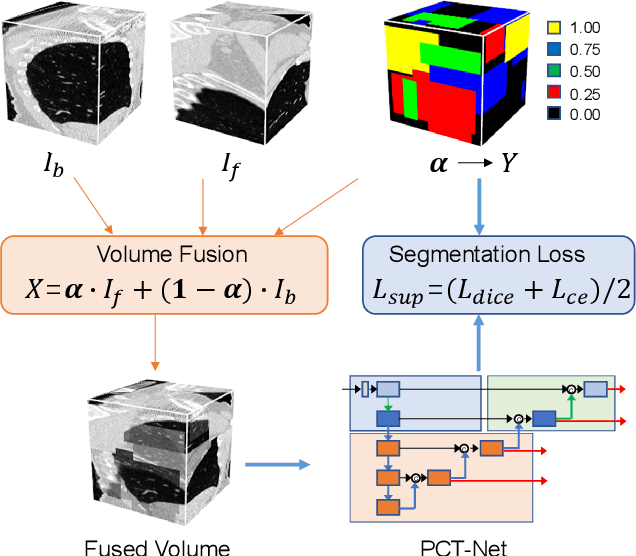
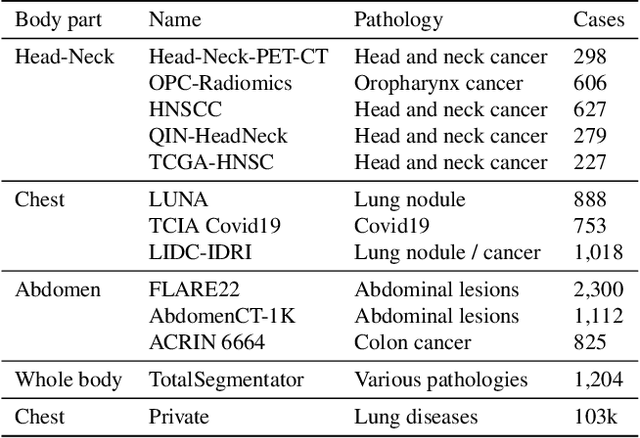

Pretraining with large-scale 3D volumes has a potential for improving the segmentation performance on a target medical image dataset where the training images and annotations are limited. Due to the high cost of acquiring pixel-level segmentation annotations on the large-scale pretraining dataset, pretraining with unannotated images is highly desirable. In this work, we propose a novel self-supervised learning strategy named Volume Fusion (VF) for pretraining 3D segmentation models. It fuses several random patches from a foreground sub-volume to a background sub-volume based on a predefined set of discrete fusion coefficients, and forces the model to predict the fusion coefficient of each voxel, which is formulated as a self-supervised segmentation task without manual annotations. Additionally, we propose a novel network architecture based on parallel convolution and transformer blocks that is suitable to be transferred to different downstream segmentation tasks with various scales of organs and lesions. The proposed model was pretrained with 110k unannotated 3D CT volumes, and experiments with different downstream segmentation targets including head and neck organs, thoracic/abdominal organs showed that our pretrained model largely outperformed training from scratch and several state-of-the-art self-supervised training methods and segmentation models. The code and pretrained model are available at https://github.com/openmedlab/MIS-FM.
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023
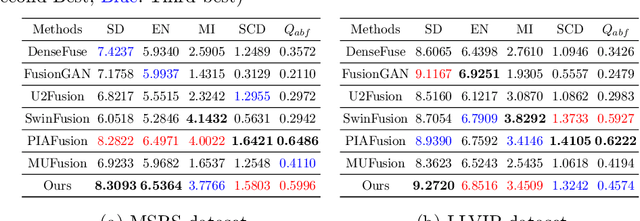
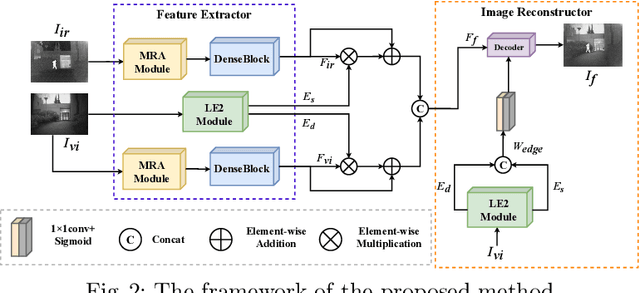
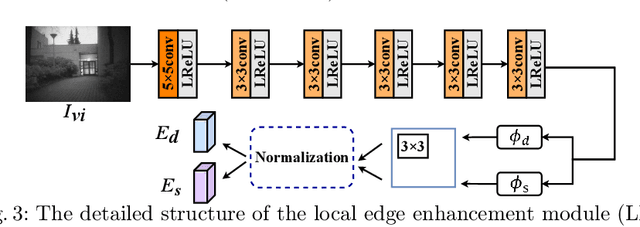
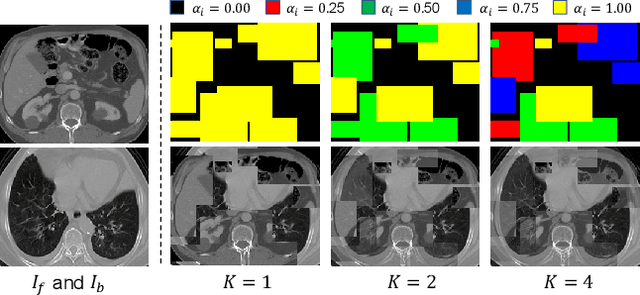
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.
Seed Feature Maps-based CNN Models for LEO Satellite Remote Sensing Services
Aug 12, 2023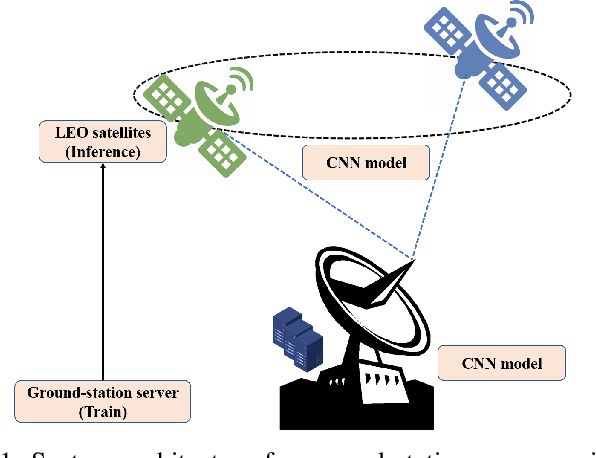

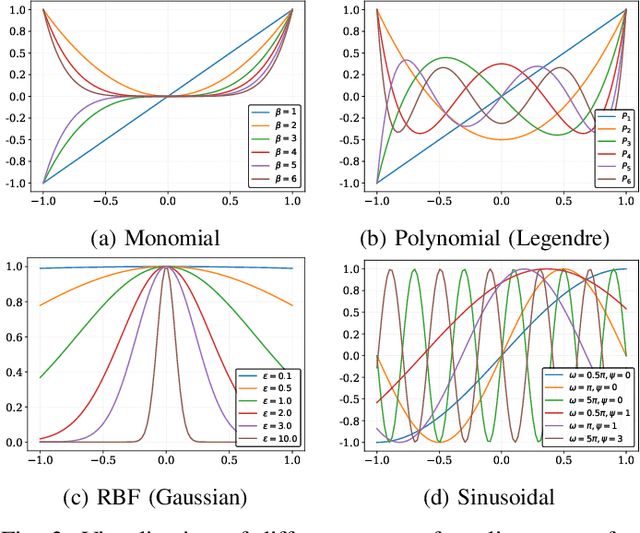
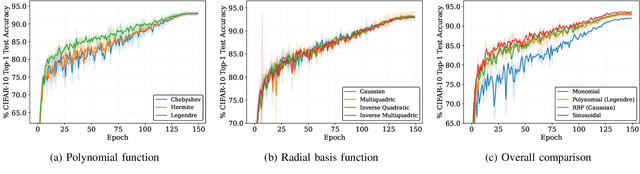
Deploying high-performance convolutional neural network (CNN) models on low-earth orbit (LEO) satellites for rapid remote sensing image processing has attracted significant interest from industry and academia. However, the limited resources available on LEO satellites contrast with the demands of resource-intensive CNN models, necessitating the adoption of ground-station server assistance for training and updating these models. Existing approaches often require large floating-point operations (FLOPs) and substantial model parameter transmissions, presenting considerable challenges. To address these issues, this paper introduces a ground-station server-assisted framework. With the proposed framework, each layer of the CNN model contains only one learnable feature map (called the seed feature map) from which other feature maps are generated based on specific rules. The hyperparameters of these rules are randomly generated instead of being trained, thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing FLOPs. Furthermore, since the random hyperparameters can be saved using a few random seeds, the ground station server assistance can be facilitated in updating the CNN model deployed on the LEO satellite. Experimental results on the ISPRS Vaihingen, ISPRS Potsdam, UAVid, and LoveDA datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state-of-the-art approaches. In particular, the SineFM-based model achieves a higher mIoU than the UNetFormer on the UAVid dataset, with 3.3x fewer parameters and 2.2x fewer FLOPs.
Revisiting DETR Pre-training for Object Detection
Aug 02, 2023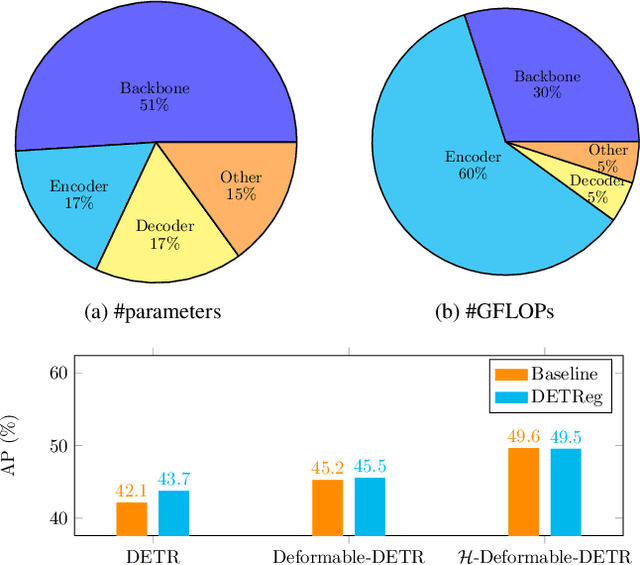
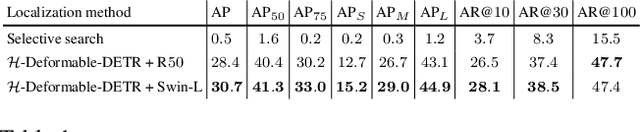

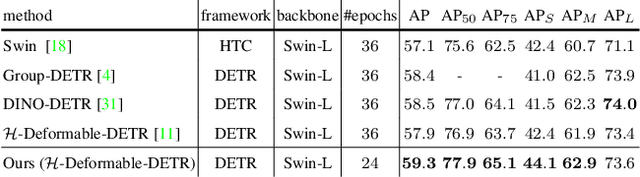
Motivated by that DETR-based approaches have established new records on COCO detection and segmentation benchmarks, many recent endeavors show increasing interest in how to further improve DETR-based approaches by pre-training the Transformer in a self-supervised manner while keeping the backbone frozen. Some studies already claimed significant improvements in accuracy. In this paper, we take a closer look at their experimental methodology and check if their approaches are still effective on the very recent state-of-the-art such as $\mathcal{H}$-Deformable-DETR. We conduct thorough experiments on COCO object detection tasks to study the influence of the choice of pre-training datasets, localization, and classification target generation schemes. Unfortunately, we find the previous representative self-supervised approach such as DETReg, fails to boost the performance of the strong DETR-based approaches on full data regimes. We further analyze the reasons and find that simply combining a more accurate box predictor and Objects$365$ benchmark can significantly improve the results in follow-up experiments. We demonstrate the effectiveness of our approach by achieving strong object detection results of AP=$59.3\%$ on COCO val set, which surpasses $\mathcal{H}$-Deformable-DETR + Swin-L by +$1.4\%$. Last, we generate a series of synthetic pre-training datasets by combining the very recent image-to-text captioning models (LLaVA) and text-to-image generative models (SDXL). Notably, pre-training on these synthetic datasets leads to notable improvements in object detection performance. Looking ahead, we anticipate substantial advantages through the future expansion of the synthetic pre-training dataset.
Virtual histological staining of unlabeled autopsy tissue
Aug 02, 2023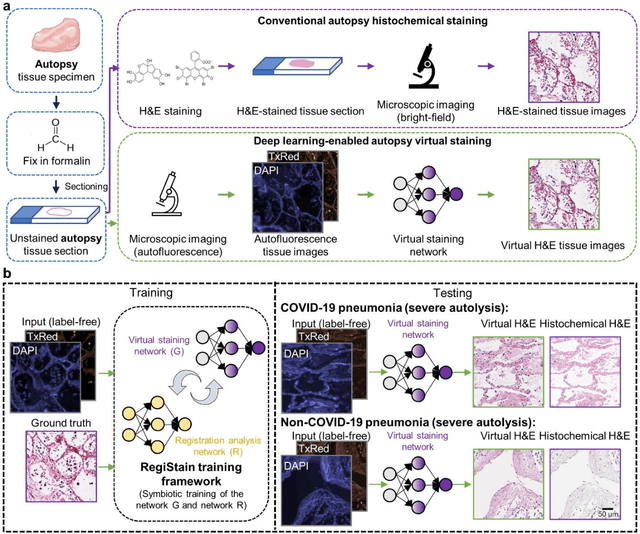
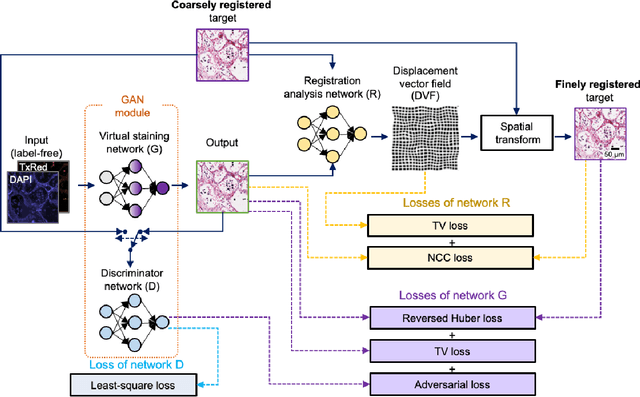
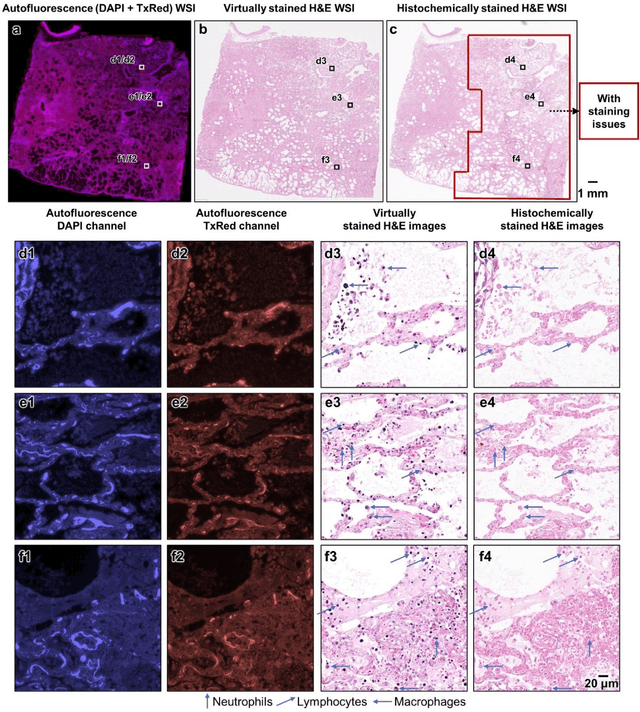
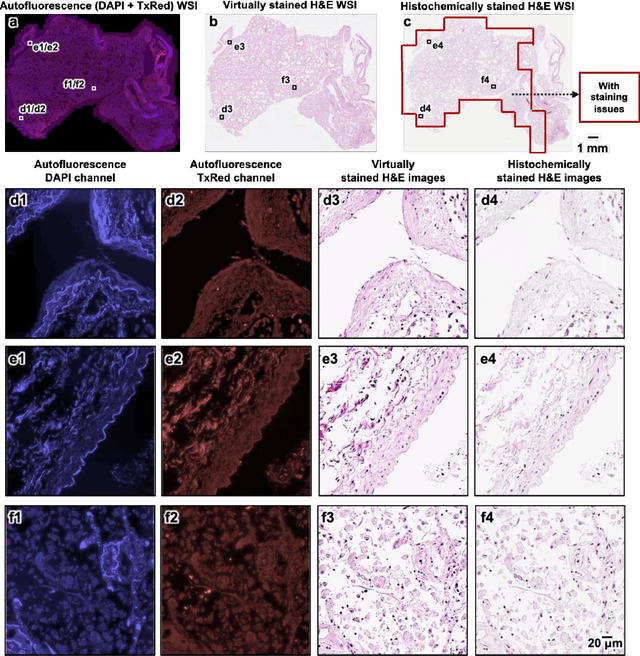
Histological examination is a crucial step in an autopsy; however, the traditional histochemical staining of post-mortem samples faces multiple challenges, including the inferior staining quality due to autolysis caused by delayed fixation of cadaver tissue, as well as the resource-intensive nature of chemical staining procedures covering large tissue areas, which demand substantial labor, cost, and time. These challenges can become more pronounced during global health crises when the availability of histopathology services is limited, resulting in further delays in tissue fixation and more severe staining artifacts. Here, we report the first demonstration of virtual staining of autopsy tissue and show that a trained neural network can rapidly transform autofluorescence images of label-free autopsy tissue sections into brightfield equivalent images that match hematoxylin and eosin (H&E) stained versions of the same samples, eliminating autolysis-induced severe staining artifacts inherent in traditional histochemical staining of autopsied tissue. Our virtual H&E model was trained using >0.7 TB of image data and a data-efficient collaboration scheme that integrates the virtual staining network with an image registration network. The trained model effectively accentuated nuclear, cytoplasmic and extracellular features in new autopsy tissue samples that experienced severe autolysis, such as COVID-19 samples never seen before, where the traditional histochemical staining failed to provide consistent staining quality. This virtual autopsy staining technique can also be extended to necrotic tissue, and can rapidly and cost-effectively generate artifact-free H&E stains despite severe autolysis and cell death, also reducing labor, cost and infrastructure requirements associated with the standard histochemical staining.
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
May 25, 2023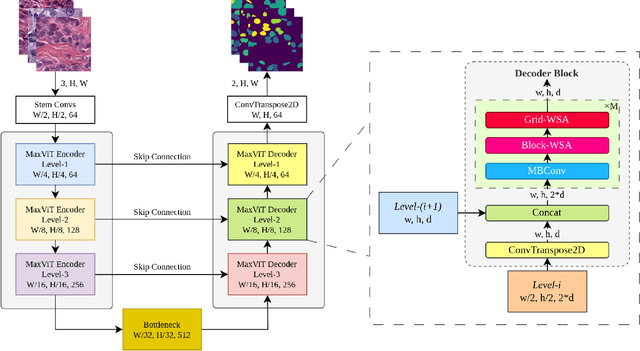
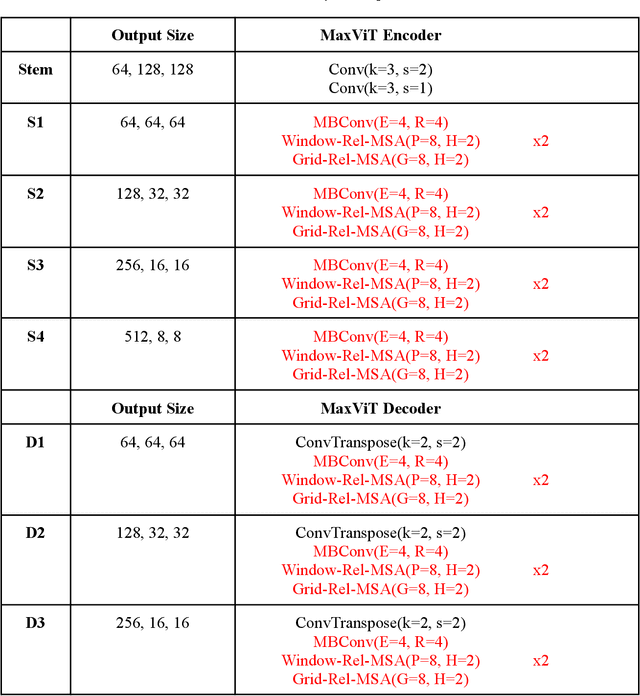
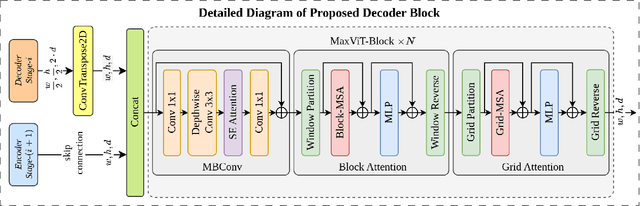
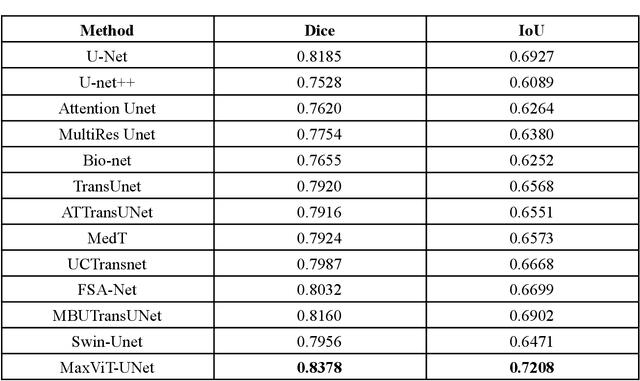
Convolutional neural networks have made significant strides in medical image analysis in recent years. However, the local nature of the convolution operator inhibits the CNNs from capturing global and long-range interactions. Recently, Transformers have gained popularity in the computer vision community and also medical image segmentation. But scalability issues of self-attention mechanism and lack of the CNN like inductive bias have limited their adoption. In this work, we present MaxViT-UNet, an Encoder-Decoder based hybrid vision transformer for medical image segmentation. The proposed hybrid decoder, also based on MaxViT-block, is designed to harness the power of convolution and self-attention mechanism at each decoding stage with minimal computational burden. The multi-axis self-attention in each decoder stage helps in differentiating between the object and background regions much more efficiently. The hybrid decoder block initially fuses the lower level features upsampled via transpose convolution, with skip-connection features coming from hybrid encoder, then fused features are refined using multi-axis attention mechanism. The proposed decoder block is repeated multiple times to accurately segment the nuclei regions. Experimental results on MoNuSeg dataset proves the effectiveness of the proposed technique. Our MaxViT-UNet outperformed the previous CNN only (UNet) and Transformer only (Swin-UNet) techniques by a large margin of 2.36% and 5.31% on Dice metric respectively.
Improving Mass Detection in Mammography Images: A Study of Weakly Supervised Learning and Class Activation Map Methods
Aug 07, 2023In recent years, weakly supervised models have aided in mass detection using mammography images, decreasing the need for pixel-level annotations. However, most existing models in the literature rely on Class Activation Maps (CAM) as the activation method, overlooking the potential benefits of exploring other activation techniques. This work presents a study that explores and compares different activation maps in conjunction with state-of-the-art methods for weakly supervised training in mammography images. Specifically, we investigate CAM, GradCAM, GradCAM++, XGradCAM, and LayerCAM methods within the framework of the GMIC model for mass detection in mammography images. The evaluation is conducted on the VinDr-Mammo dataset, utilizing the metrics Accuracy, True Positive Rate (TPR), False Negative Rate (FNR), and False Positive Per Image (FPPI). Results show that using different strategies of activation maps during training and test stages leads to an improvement of the model. With this strategy, we improve the results of the GMIC method, decreasing the FPPI value and increasing TPR.
Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023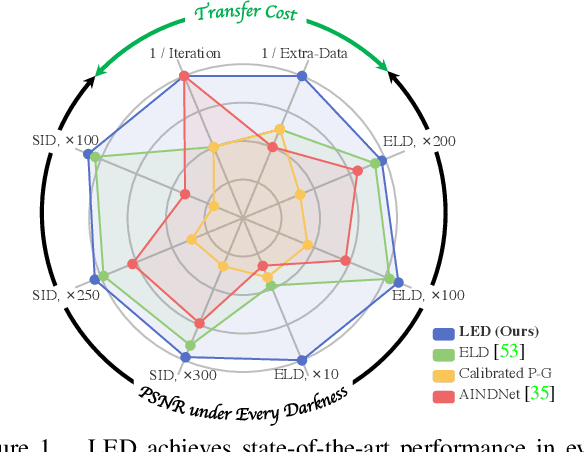
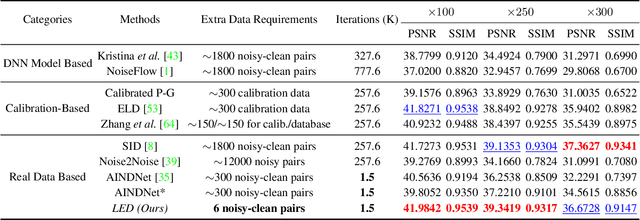
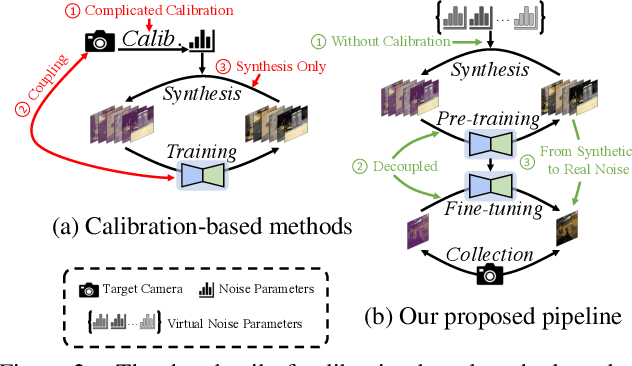
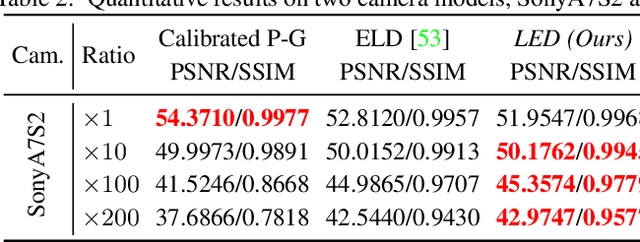
Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
Advancing Visual Grounding with Scene Knowledge: Benchmark and Method
Jul 21, 2023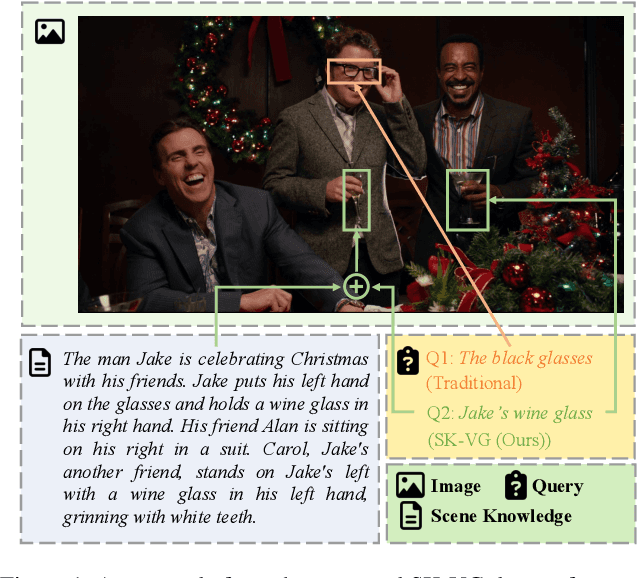

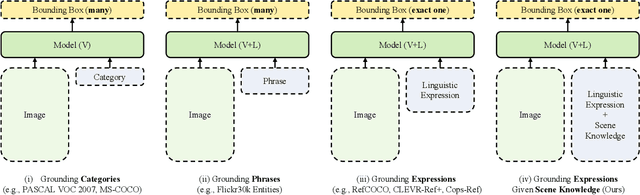
Visual grounding (VG) aims to establish fine-grained alignment between vision and language. Ideally, it can be a testbed for vision-and-language models to evaluate their understanding of the images and texts and their reasoning abilities over their joint space. However, most existing VG datasets are constructed using simple description texts, which do not require sufficient reasoning over the images and texts. This has been demonstrated in a recent study~\cite{luo2022goes}, where a simple LSTM-based text encoder without pretraining can achieve state-of-the-art performance on mainstream VG datasets. Therefore, in this paper, we propose a novel benchmark of \underline{S}cene \underline{K}nowledge-guided \underline{V}isual \underline{G}rounding (SK-VG), where the image content and referring expressions are not sufficient to ground the target objects, forcing the models to have a reasoning ability on the long-form scene knowledge. To perform this task, we propose two approaches to accept the triple-type input, where the former embeds knowledge into the image features before the image-query interaction; the latter leverages linguistic structure to assist in computing the image-text matching. We conduct extensive experiments to analyze the above methods and show that the proposed approaches achieve promising results but still leave room for improvement, including performance and interpretability. The dataset and code are available at \url{https://github.com/zhjohnchan/SK-VG}.