 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Explainable Model-Agnostic Algorithm for CNN-based Biometrics Verification
Jul 25, 2023

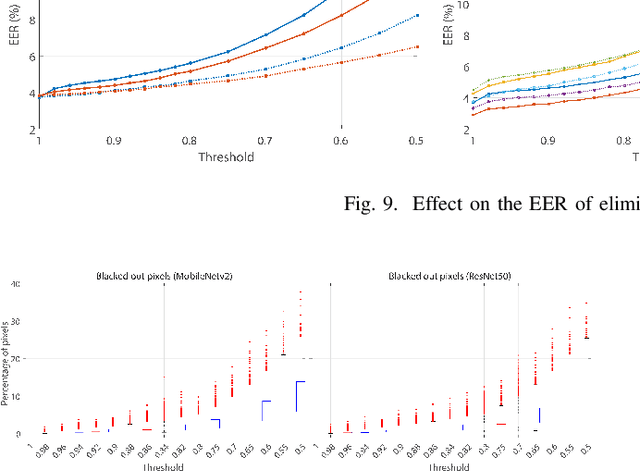

This paper describes an adaptation of the Local Interpretable Model-Agnostic Explanations (LIME) AI method to operate under a biometric verification setting. LIME was initially proposed for networks with the same output classes used for training, and it employs the softmax probability to determine which regions of the image contribute the most to classification. However, in a verification setting, the classes to be recognized have not been seen during training. In addition, instead of using the softmax output, face descriptors are usually obtained from a layer before the classification layer. The model is adapted to achieve explainability via cosine similarity between feature vectors of perturbated versions of the input image. The method is showcased for face biometrics with two CNN models based on MobileNetv2 and ResNet50.
Statistically Significant Concept-based Explanation of Image Classifiers via Model Knockoffs
May 31, 2023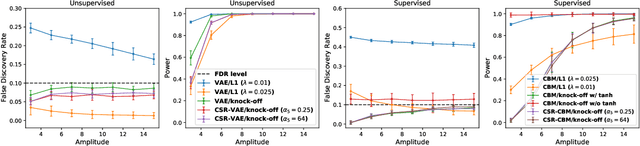
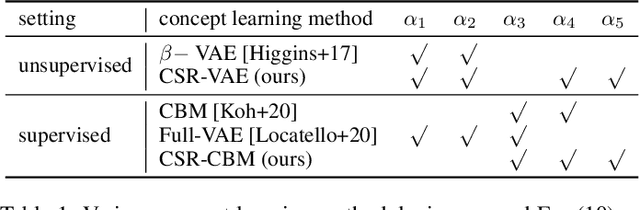
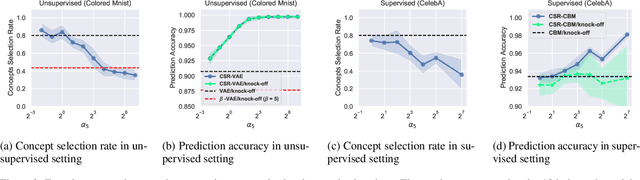
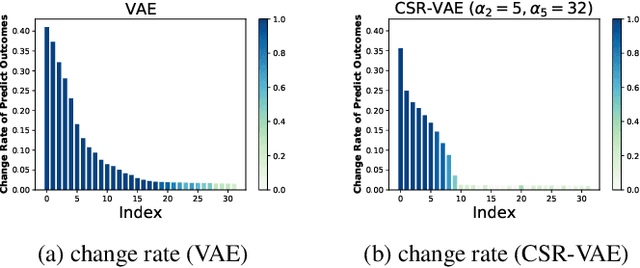
A concept-based classifier can explain the decision process of a deep learning model by human-understandable concepts in image classification problems. However, sometimes concept-based explanations may cause false positives, which misregards unrelated concepts as important for the prediction task. Our goal is to find the statistically significant concept for classification to prevent misinterpretation. In this study, we propose a method using a deep learning model to learn the image concept and then using the Knockoff samples to select the important concepts for prediction by controlling the False Discovery Rate (FDR) under a certain value. We evaluate the proposed method in our synthetic and real data experiments. Also, it shows that our method can control the FDR properly while selecting highly interpretable concepts to improve the trustworthiness of the model.
DISCount: Counting in Large Image Collections with Detector-Based Importance Sampling
Jun 05, 2023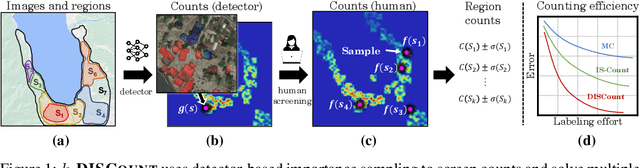
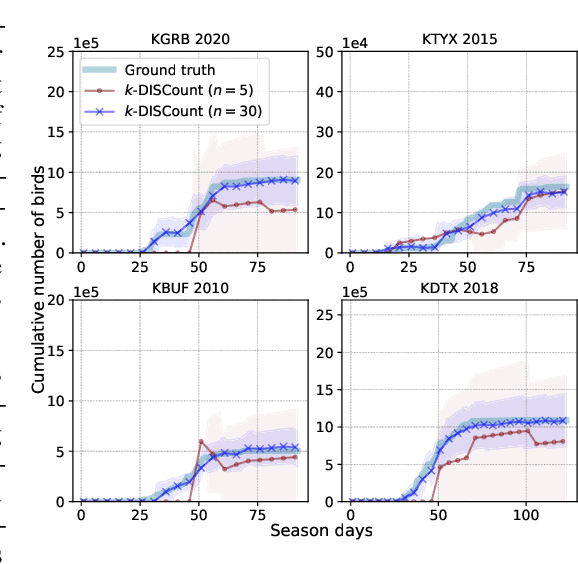
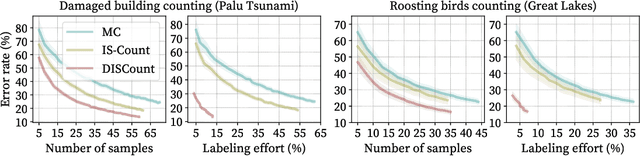
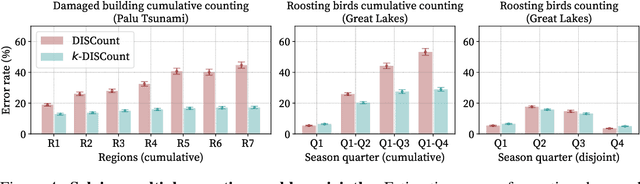
Many modern applications use computer vision to detect and count objects in massive image collections. However, when the detection task is very difficult or in the presence of domain shifts, the counts may be inaccurate even with significant investments in training data and model development. We propose DISCount -- a detector-based importance sampling framework for counting in large image collections that integrates an imperfect detector with human-in-the-loop screening to produce unbiased estimates of counts. We propose techniques for solving counting problems over multiple spatial or temporal regions using a small number of screened samples and estimate confidence intervals. This enables end-users to stop screening when estimates are sufficiently accurate, which is often the goal in a scientific study. On the technical side we develop variance reduction techniques based on control variates and prove the (conditional) unbiasedness of the estimators. DISCount leads to a 9-12x reduction in the labeling costs over naive screening for tasks we consider, such as counting birds in radar imagery or estimating damaged buildings in satellite imagery, and also surpasses alternative covariate-based screening approaches in efficiency.
MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection
Jul 18, 2023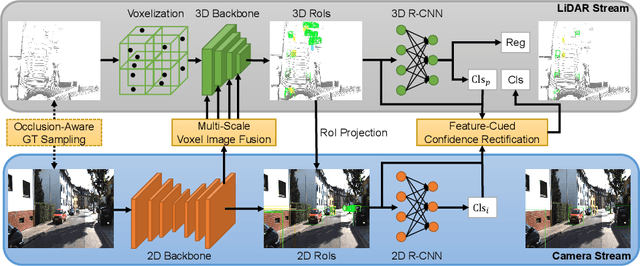
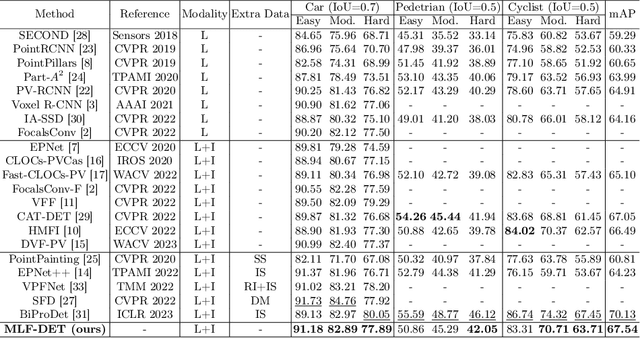
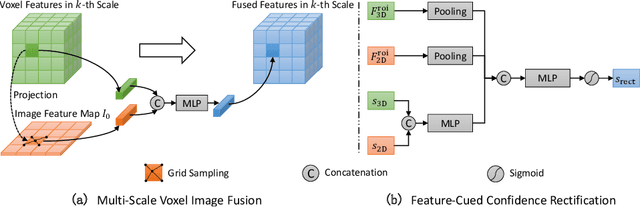
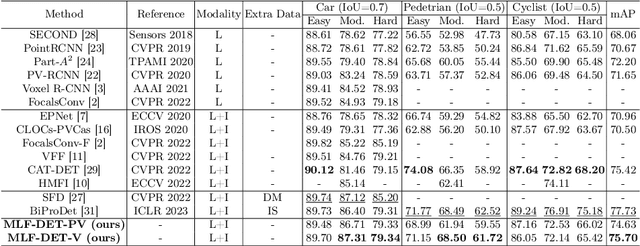
In this paper, we propose a novel and effective Multi-Level Fusion network, named as MLF-DET, for high-performance cross-modal 3D object DETection, which integrates both the feature-level fusion and decision-level fusion to fully utilize the information in the image. For the feature-level fusion, we present the Multi-scale Voxel Image fusion (MVI) module, which densely aligns multi-scale voxel features with image features. For the decision-level fusion, we propose the lightweight Feature-cued Confidence Rectification (FCR) module which further exploits image semantics to rectify the confidence of detection candidates. Besides, we design an effective data augmentation strategy termed Occlusion-aware GT Sampling (OGS) to reserve more sampled objects in the training scenes, so as to reduce overfitting. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our method. Notably, on the extremely competitive KITTI car 3D object detection benchmark, our method reaches 82.89% moderate AP and achieves state-of-the-art performance without bells and whistles.
Lightweight Structure-aware Transformer Network for VHR Remote Sensing Image Change Detection
Jun 03, 2023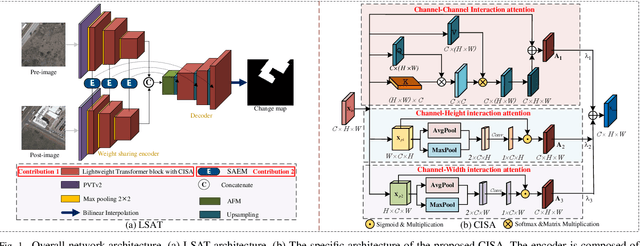
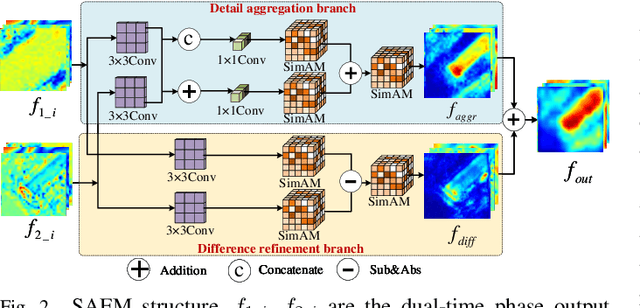
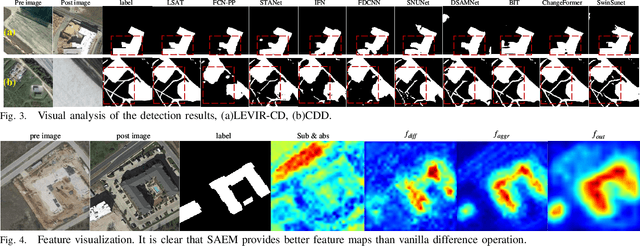
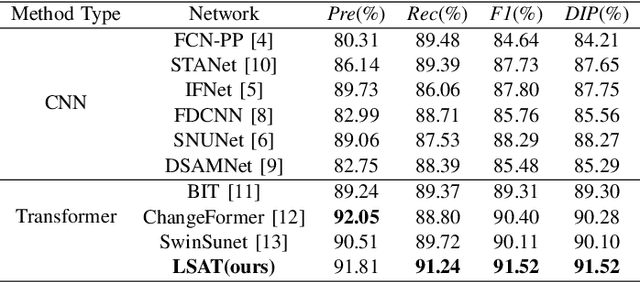
Popular Transformer networks have been successfully applied to remote sensing (RS) image change detection (CD) identifications and achieve better results than most convolutional neural networks (CNNs), but they still suffer from two main problems. First, the computational complexity of the Transformer grows quadratically with the increase of image spatial resolution, which is unfavorable to very high-resolution (VHR) RS images. Second, these popular Transformer networks tend to ignore the importance of fine-grained features, which results in poor edge integrity and internal tightness for largely changed objects and leads to the loss of small changed objects. To address the above issues, this Letter proposes a Lightweight Structure-aware Transformer (LSAT) network for RS image CD. The proposed LSAT has two advantages. First, a Cross-dimension Interactive Self-attention (CISA) module with linear complexity is designed to replace the vanilla self-attention in visual Transformer, which effectively reduces the computational complexity while improving the feature representation ability of the proposed LSAT. Second, a Structure-aware Enhancement Module (SAEM) is designed to enhance difference features and edge detail information, which can achieve double enhancement by difference refinement and detail aggregation so as to obtain fine-grained features of bi-temporal RS images. Experimental results show that the proposed LSAT achieves significant improvement in detection accuracy and offers a better tradeoff between accuracy and computational costs than most state-of-the-art CD methods for VHR RS images.
Language-based Action Concept Spaces Improve Video Self-Supervised Learning
Jul 20, 2023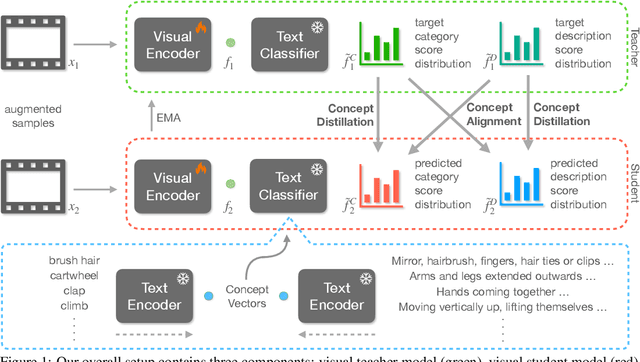
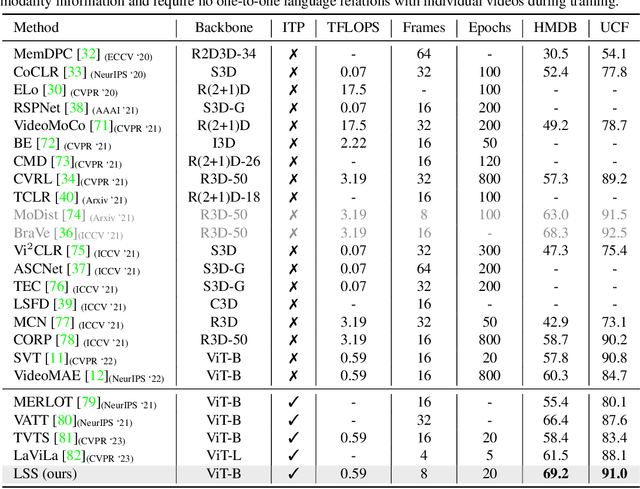
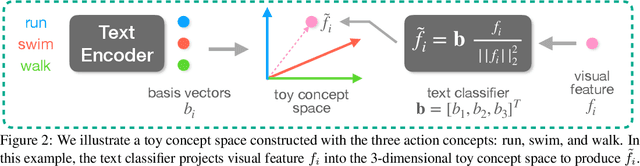
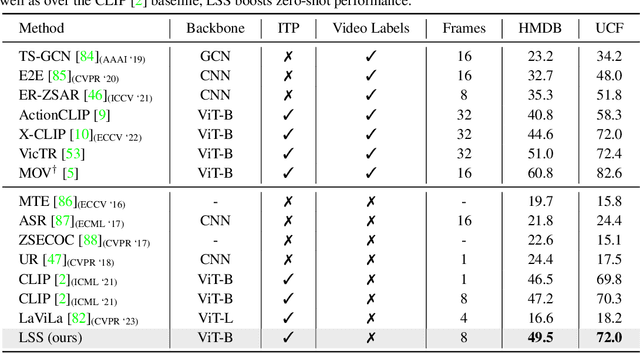
Recent contrastive language image pre-training has led to learning highly transferable and robust image representations. However, adapting these models to video domains with minimal supervision remains an open problem. We explore a simple step in that direction, using language tied self-supervised learning to adapt an image CLIP model to the video domain. A backbone modified for temporal modeling is trained under self-distillation settings with train objectives operating in an action concept space. Feature vectors of various action concepts extracted from a language encoder using relevant textual prompts construct this space. We introduce two train objectives, concept distillation and concept alignment, that retain generality of original representations while enforcing relations between actions and their attributes. Our approach improves zero-shot and linear probing performance on three action recognition benchmarks.
Advancing Volumetric Medical Image Segmentation via Global-Local Masked Autoencoder
Jun 15, 2023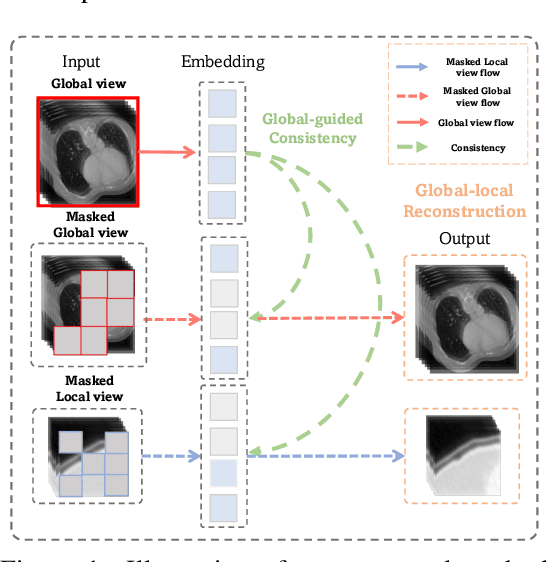
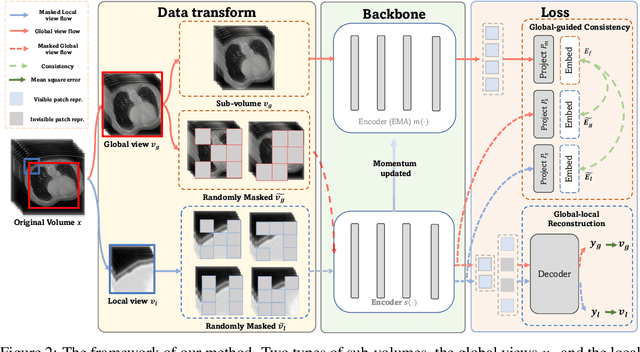
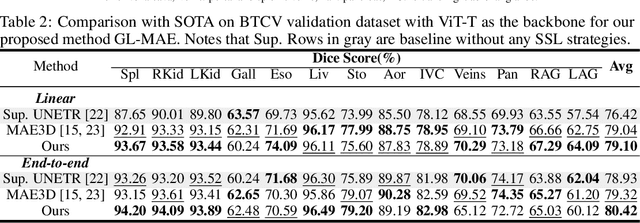
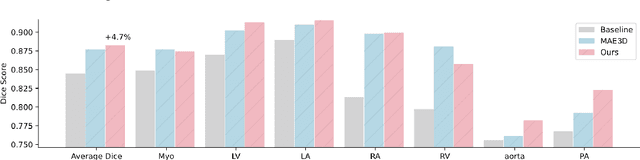
Masked autoencoder (MAE) has emerged as a promising self-supervised pretraining technique to enhance the representation learning of a neural network without human intervention. To adapt MAE onto volumetric medical images, existing methods exhibit two challenges: first, the global information crucial for understanding the clinical context of the holistic data is lacked; second, there was no guarantee of stabilizing the representations learned from the randomly masked inputs. To tackle these limitations, we proposed Global-Local Masked AutoEncoder (GL-MAE), a simple yet effective self-supervised pre-training strategy. GL-MAE reconstructs both the masked global and masked local volumes, which enables learning the essential local details as well as the global context. We further introduced global-to-global consistency and local-to-global correspondence via global-guided consistency learning to enhance and stabilize the representation learning of the masked volumes. Finetuning results on multiple datasets illustrate the superiority of our method over other state-of-the-art self-supervised algorithms, demonstrating its effectiveness on versatile volumetric medical image segmentation tasks, even when annotations are scarce. Codes and models will be released upon acceptance.
LE2Fusion: A novel local edge enhancement module for infrared and visible image fusion
May 27, 2023
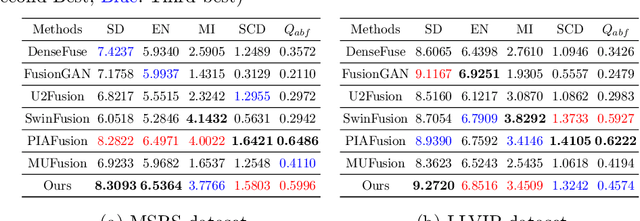
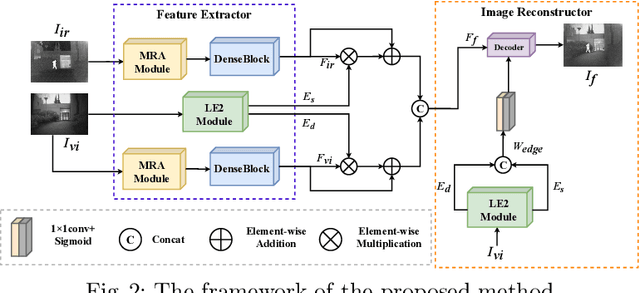
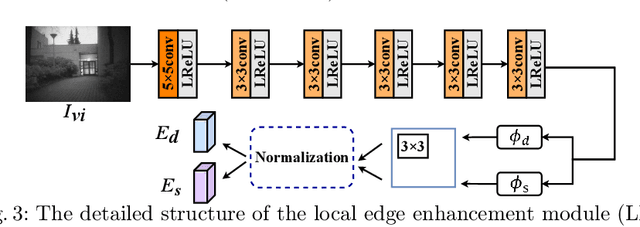
Infrared and visible image fusion task aims to generate a fused image which contains salient features and rich texture details from multi-source images. However, under complex illumination conditions, few algorithms pay attention to the edge information of local regions which is crucial for downstream tasks. To this end, we propose a fusion network based on the local edge enhancement, named LE2Fusion. Specifically, a local edge enhancement (LE2) module is proposed to improve the edge information under complex illumination conditions and preserve the essential features of image. For feature extraction, a multi-scale residual attention (MRA) module is applied to extract rich features. Then, with LE2, a set of enhancement weights are generated which are utilized in feature fusion strategy and used to guide the image reconstruction. To better preserve the local detail information and structure information, the pixel intensity loss function based on the local region is also presented. The experiments demonstrate that the proposed method exhibits better fusion performance than the state-of-the-art fusion methods on public datasets.
Microvasculature Segmentation in Human BioMolecular Atlas Program (HuBMAP)
Aug 06, 2023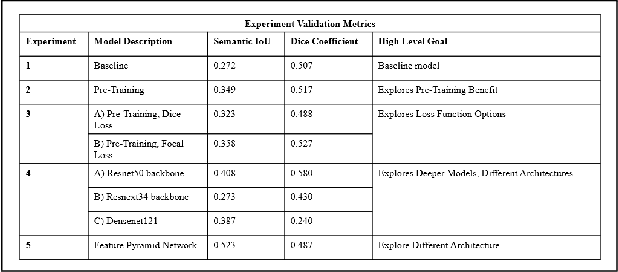
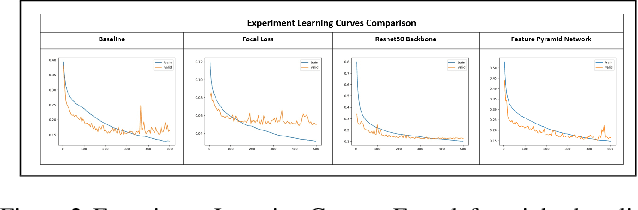
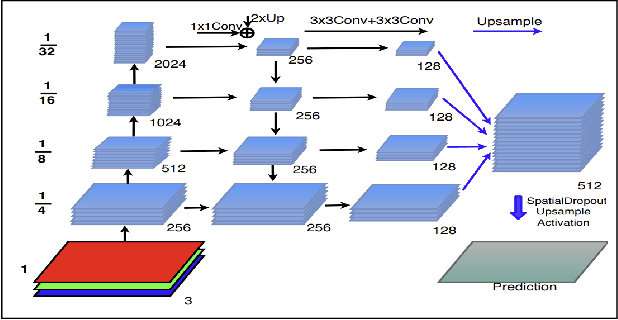
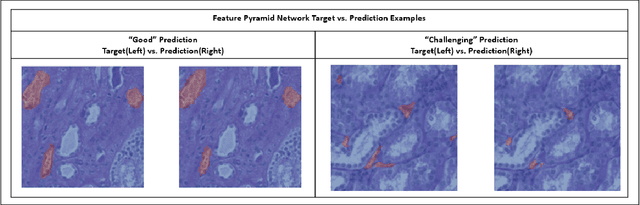
Image segmentation serves as a critical tool across a range of applications, encompassing autonomous driving's pedestrian detection and pre-operative tumor delineation in the medical sector. Among these applications, we focus on the National Institutes of Health's (NIH) Human BioMolecular Atlas Program (HuBMAP), a significant initiative aimed at creating detailed cellular maps of the human body. In this study, we concentrate on segmenting various microvascular structures in human kidneys, utilizing 2D Periodic Acid-Schiff (PAS)-stained histology images. Our methodology begins with a foundational FastAI U-Net model, upon which we investigate alternative backbone architectures, delve into deeper models, and experiment with Feature Pyramid Networks. We rigorously evaluate these varied approaches by benchmarking their performance against our baseline U-Net model. This study thus offers a comprehensive exploration of cutting-edge segmentation techniques, providing valuable insights for future research in the field.
Compositional Feature Augmentation for Unbiased Scene Graph Generation
Aug 13, 2023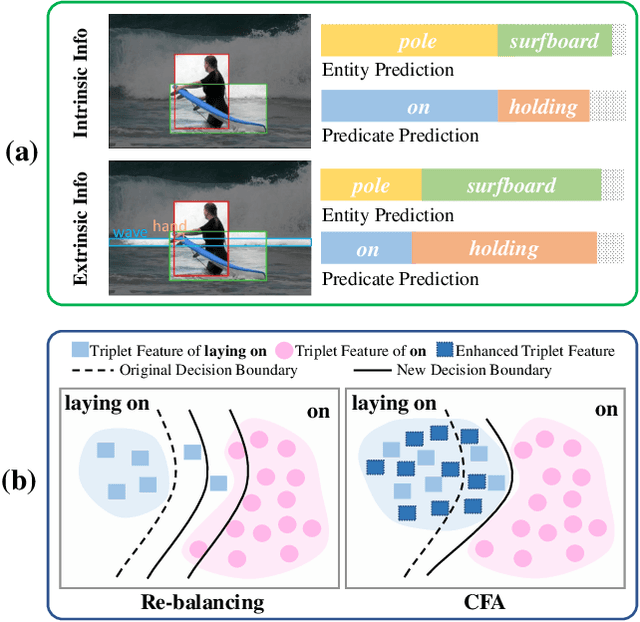
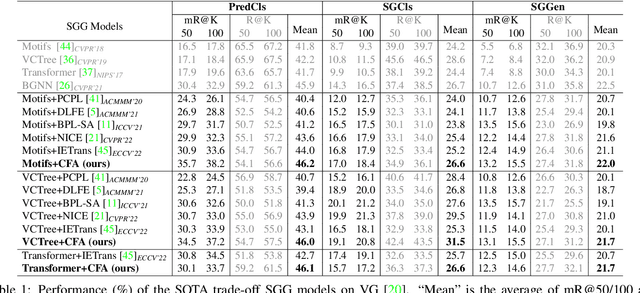
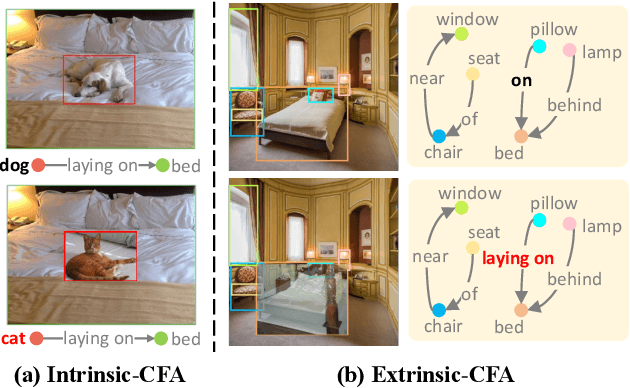
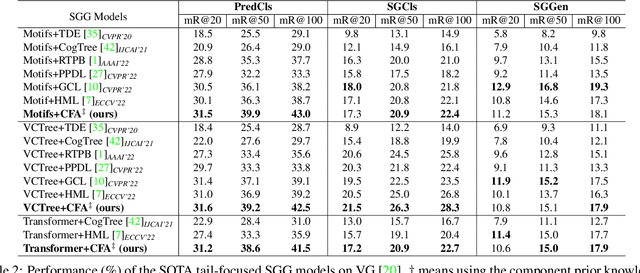
Scene Graph Generation (SGG) aims to detect all the visual relation triplets <sub, pred, obj> in a given image. With the emergence of various advanced techniques for better utilizing both the intrinsic and extrinsic information in each relation triplet, SGG has achieved great progress over the recent years. However, due to the ubiquitous long-tailed predicate distributions, today's SGG models are still easily biased to the head predicates. Currently, the most prevalent debiasing solutions for SGG are re-balancing methods, e.g., changing the distributions of original training samples. In this paper, we argue that all existing re-balancing strategies fail to increase the diversity of the relation triplet features of each predicate, which is critical for robust SGG. To this end, we propose a novel Compositional Feature Augmentation (CFA) strategy, which is the first unbiased SGG work to mitigate the bias issue from the perspective of increasing the diversity of triplet features. Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively. Then, we design two different feature augmentation modules to enrich the feature diversity of original relation triplets by replacing or mixing up either their intrinsic or extrinsic features from other samples. Due to its model-agnostic nature, CFA can be seamlessly incorporated into various SGG frameworks. Extensive ablations have shown that CFA achieves a new state-of-the-art performance on the trade-off between different metrics.