 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CortexMorph: fast cortical thickness estimation via diffeomorphic registration using VoxelMorph
Jul 21, 2023
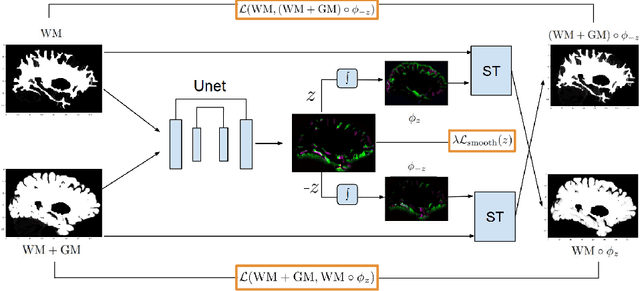
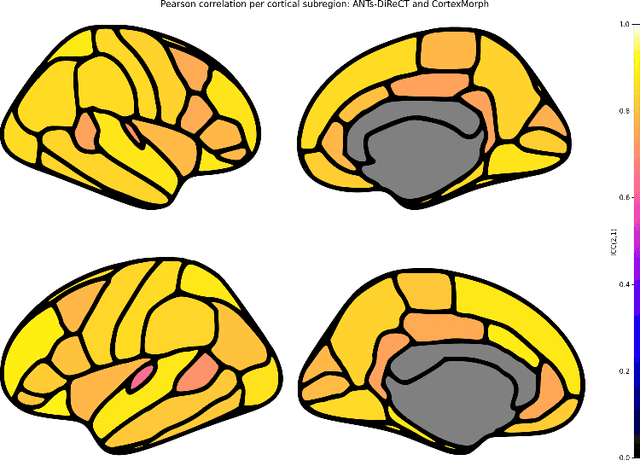
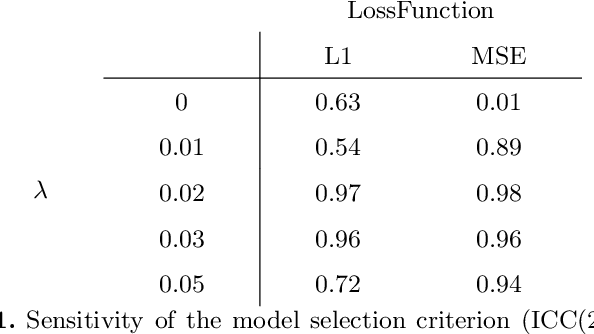
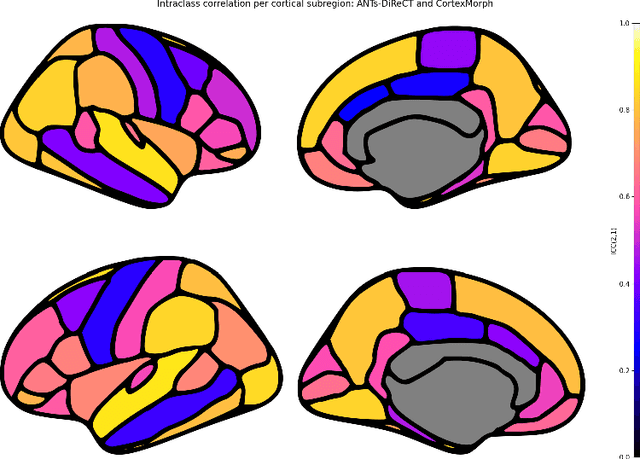
The thickness of the cortical band is linked to various neurological and psychiatric conditions, and is often estimated through surface-based methods such as Freesurfer in MRI studies. The DiReCT method, which calculates cortical thickness using a diffeomorphic deformation of the gray-white matter interface towards the pial surface, offers an alternative to surface-based methods. Recent studies using a synthetic cortical thickness phantom have demonstrated that the combination of DiReCT and deep-learning-based segmentation is more sensitive to subvoxel cortical thinning than Freesurfer. While anatomical segmentation of a T1-weighted image now takes seconds, existing implementations of DiReCT rely on iterative image registration methods which can take up to an hour per volume. On the other hand, learning-based deformable image registration methods like VoxelMorph have been shown to be faster than classical methods while improving registration accuracy. This paper proposes CortexMorph, a new method that employs unsupervised deep learning to directly regress the deformation field needed for DiReCT. By combining CortexMorph with a deep-learning-based segmentation model, it is possible to estimate region-wise thickness in seconds from a T1-weighted image, while maintaining the ability to detect cortical atrophy. We validate this claim on the OASIS-3 dataset and the synthetic cortical thickness phantom of Rusak et al.
Investigating and Improving Latent Density Segmentation Models for Aleatoric Uncertainty Quantification in Medical Imaging
Jul 31, 2023


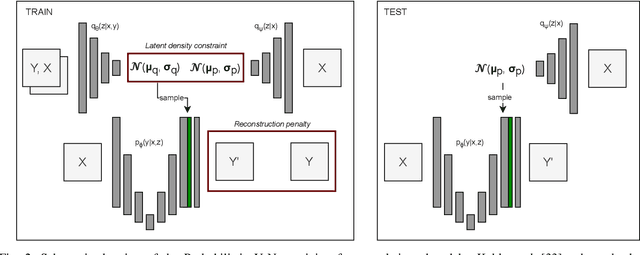
Data uncertainties, such as sensor noise or occlusions, can introduce irreducible ambiguities in images, which result in varying, yet plausible, semantic hypotheses. In Machine Learning, this ambiguity is commonly referred to as aleatoric uncertainty. Latent density models can be utilized to address this problem in image segmentation. The most popular approach is the Probabilistic U-Net (PU-Net), which uses latent Normal densities to optimize the conditional data log-likelihood Evidence Lower Bound. In this work, we demonstrate that the PU- Net latent space is severely inhomogenous. As a result, the effectiveness of gradient descent is inhibited and the model becomes extremely sensitive to the localization of the latent space samples, resulting in defective predictions. To address this, we present the Sinkhorn PU-Net (SPU-Net), which uses the Sinkhorn Divergence to promote homogeneity across all latent dimensions, effectively improving gradient-descent updates and model robustness. Our results show that by applying this on public datasets of various clinical segmentation problems, the SPU-Net receives up to 11% performance gains compared against preceding latent variable models for probabilistic segmentation on the Hungarian-Matched metric. The results indicate that by encouraging a homogeneous latent space, one can significantly improve latent density modeling for medical image segmentation.
NexToU: Efficient Topology-Aware U-Net for Medical Image Segmentation
May 25, 2023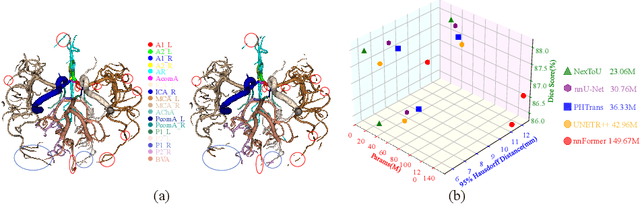



Convolutional neural networks (CNN) and Transformer variants have emerged as the leading medical image segmentation backbones. Nonetheless, due to their limitations in either preserving global image context or efficiently processing irregular shapes in visual objects, these backbones struggle to effectively integrate information from diverse anatomical regions and reduce inter-individual variability, particularly for the vasculature. Motivated by the successful breakthroughs of graph neural networks (GNN) in capturing topological properties and non-Euclidean relationships across various fields, we propose NexToU, a novel hybrid architecture for medical image segmentation. NexToU comprises improved Pool GNN and Swin GNN modules from Vision GNN (ViG) for learning both global and local topological representations while minimizing computational costs. To address the containment and exclusion relationships among various anatomical structures, we reformulate the topological interaction (TI) module based on the nature of binary trees, rapidly encoding the topological constraints into NexToU. Extensive experiments conducted on three datasets (including distinct imaging dimensions, disease types, and imaging modalities) demonstrate that our method consistently outperforms other state-of-the-art (SOTA) architectures. All the code is publicly available at https://github.com/PengchengShi1220/NexToU.
T-former: An Efficient Transformer for Image Inpainting
May 19, 2023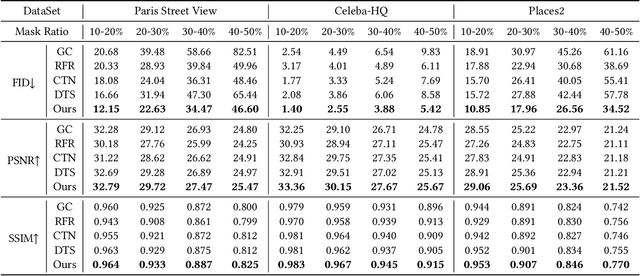
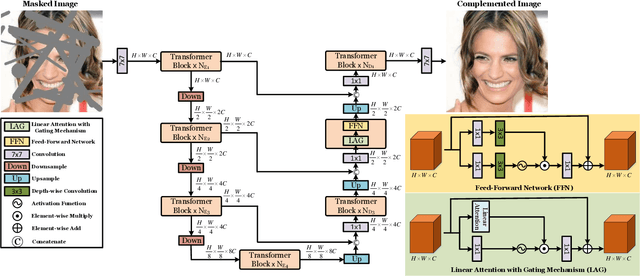


Benefiting from powerful convolutional neural networks (CNNs), learning-based image inpainting methods have made significant breakthroughs over the years. However, some nature of CNNs (e.g. local prior, spatially shared parameters) limit the performance in the face of broken images with diverse and complex forms. Recently, a class of attention-based network architectures, called transformer, has shown significant performance on natural language processing fields and high-level vision tasks. Compared with CNNs, attention operators are better at long-range modeling and have dynamic weights, but their computational complexity is quadratic in spatial resolution, and thus less suitable for applications involving higher resolution images, such as image inpainting. In this paper, we design a novel attention linearly related to the resolution according to Taylor expansion. And based on this attention, a network called $T$-former is designed for image inpainting. Experiments on several benchmark datasets demonstrate that our proposed method achieves state-of-the-art accuracy while maintaining a relatively low number of parameters and computational complexity. The code can be found at \href{https://github.com/dengyecode/T-former_image_inpainting}{github.com/dengyecode/T-former\_image\_inpainting}
TokenFlow: Consistent Diffusion Features for Consistent Video Editing
Jul 23, 2023
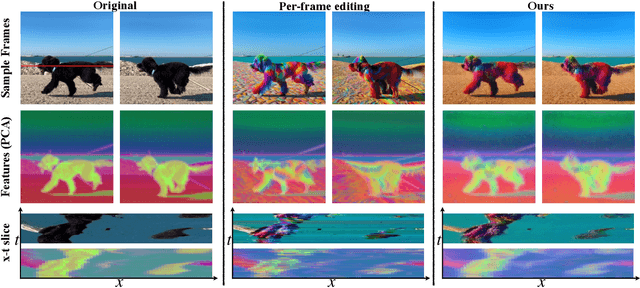

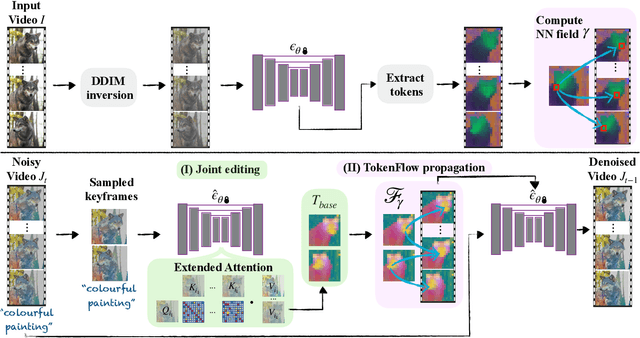
The generative AI revolution has recently expanded to videos. Nevertheless, current state-of-the-art video models are still lagging behind image models in terms of visual quality and user control over the generated content. In this work, we present a framework that harnesses the power of a text-to-image diffusion model for the task of text-driven video editing. Specifically, given a source video and a target text-prompt, our method generates a high-quality video that adheres to the target text, while preserving the spatial layout and motion of the input video. Our method is based on a key observation that consistency in the edited video can be obtained by enforcing consistency in the diffusion feature space. We achieve this by explicitly propagating diffusion features based on inter-frame correspondences, readily available in the model. Thus, our framework does not require any training or fine-tuning, and can work in conjunction with any off-the-shelf text-to-image editing method. We demonstrate state-of-the-art editing results on a variety of real-world videos. Webpage: https://diffusion-tokenflow.github.io/
Automating Wood Species Detection and Classification in Microscopic Images of Fibrous Materials with Deep Learning
Jul 24, 2023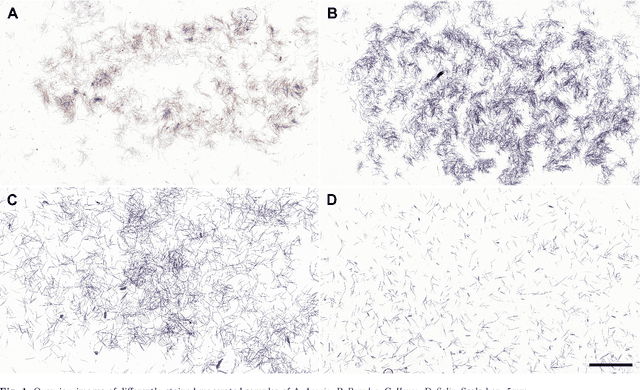
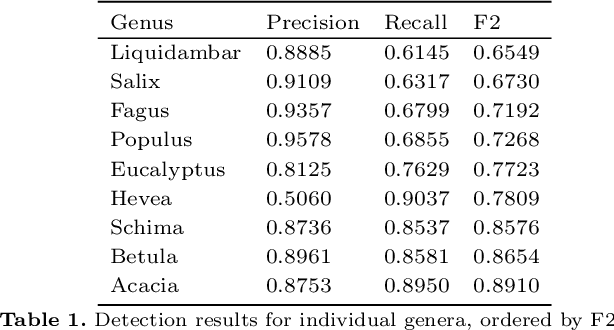

We have developed a methodology for the systematic generation of a large image dataset of macerated wood references, which we used to generate image data for nine hardwood genera. This is the basis for a substantial approach to automate, for the first time, the identification of hardwood species in microscopic images of fibrous materials by deep learning. Our methodology includes a flexible pipeline for easy annotation of vessel elements. We compare the performance of different neural network architectures and hyperparameters. Our proposed method performs similarly well to human experts. In the future, this will improve controls on global wood fiber product flows to protect forests.
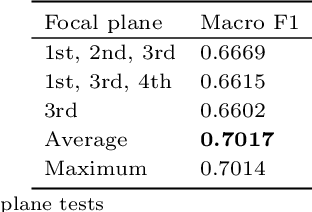
Image Clustering via the Principle of Rate Reduction in the Age of Pretrained Models
Jun 09, 2023
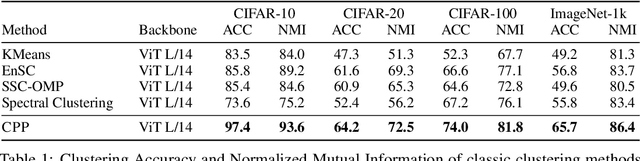
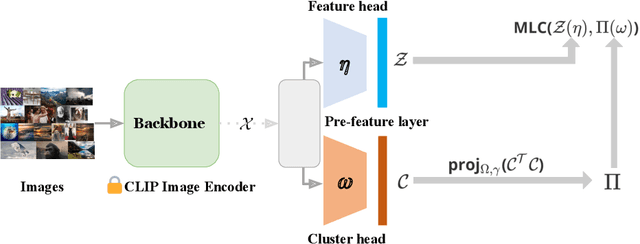
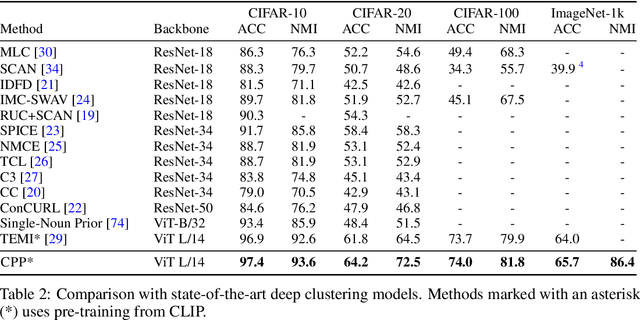
The advent of large pre-trained models has brought about a paradigm shift in both visual representation learning and natural language processing. However, clustering unlabeled images, as a fundamental and classic machine learning problem, still lacks effective solution, particularly for large-scale datasets. In this paper, we propose a novel image clustering pipeline that leverages the powerful feature representation of large pre-trained models such as CLIP and cluster images effectively and efficiently at scale. We show that the pre-trained features are significantly more structured by further optimizing the rate reduction objective. The resulting features may significantly improve the clustering accuracy, e.g., from 57\% to 66\% on ImageNet-1k. Furthermore, by leveraging CLIP's image-text binding, we show how the new clustering method leads to a simple yet effective self-labeling algorithm that successfully works on unlabeled large datasets such as MS-COCO and LAION-Aesthetics. We will release the code in https://github.com/LeslieTrue/CPP.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Jul 22, 2023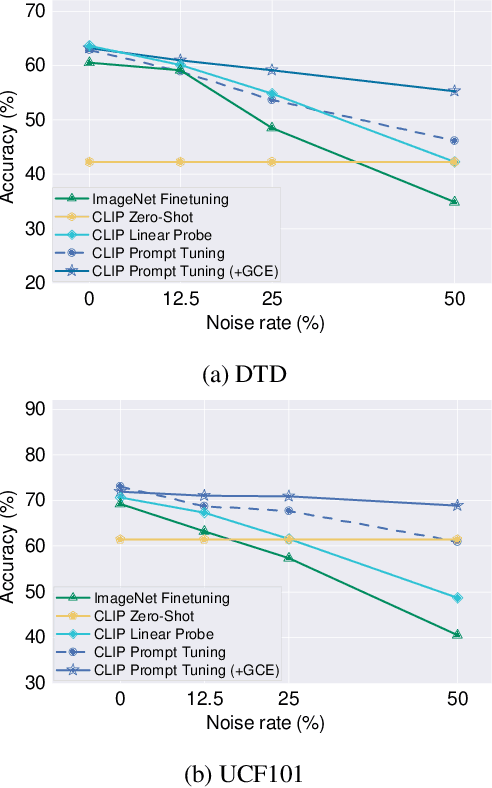
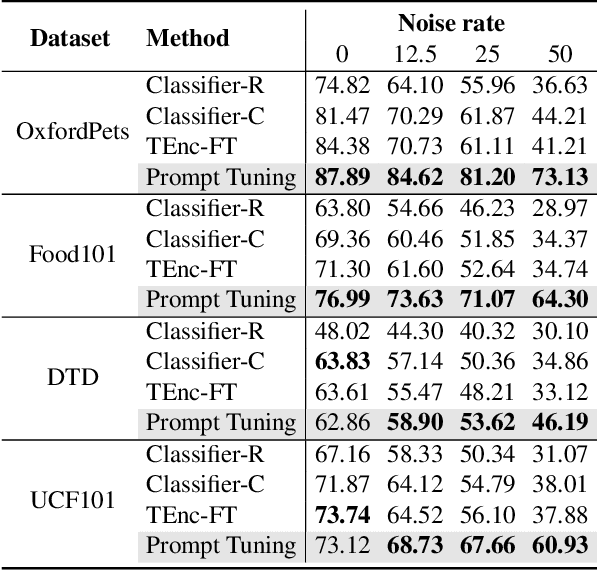

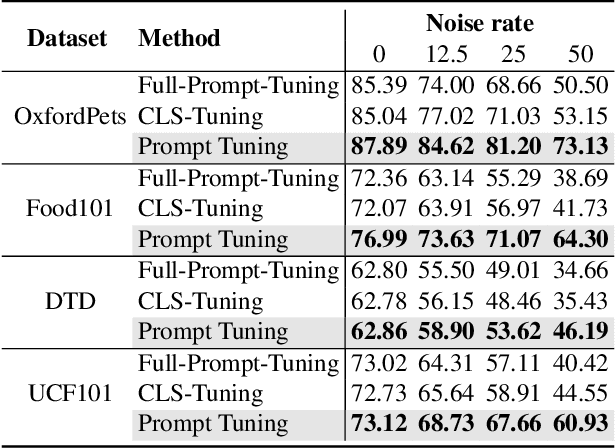
Vision-language models such as CLIP learn a generic text-image embedding from large-scale training data. A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises. This intrigues us to study the key reasons contributing to the robustness of the prompt tuning paradigm. We conducted extensive experiments to explore this property and find the key factors are: 1) the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples; 2) the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification. Further, we demonstrate that noisy zero-shot predictions from CLIP can be used to tune its own prompt, significantly enhancing prediction accuracy in the unsupervised setting. The code is available at https://github.com/CEWu/PTNL.
Pre-Pruning and Gradient-Dropping Improve Differentially Private Image Classification
Jun 19, 2023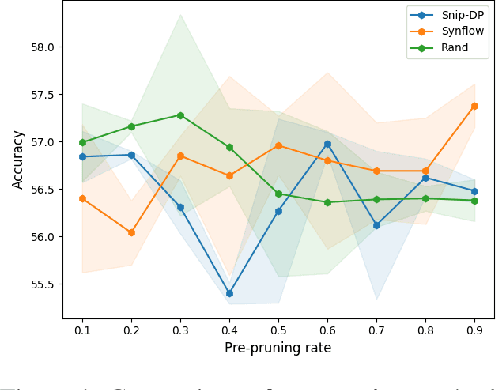
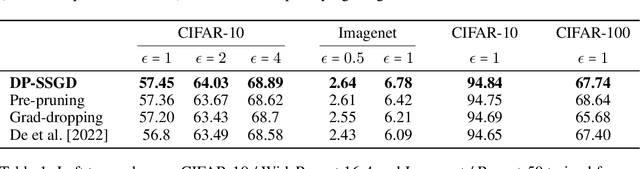
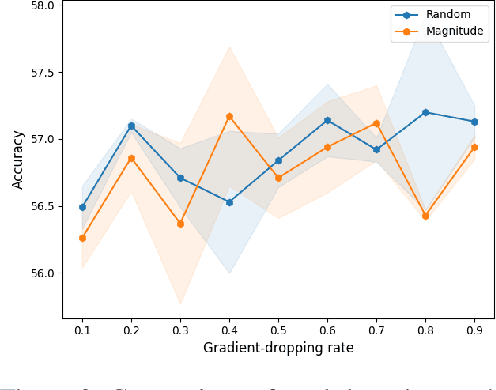
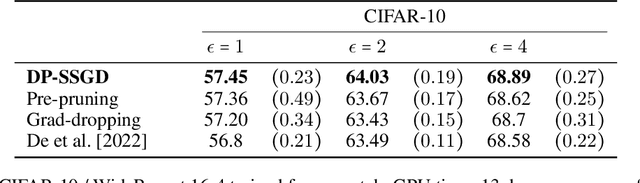
Scalability is a significant challenge when it comes to applying differential privacy to training deep neural networks. The commonly used DP-SGD algorithm struggles to maintain a high level of privacy protection while achieving high accuracy on even moderately sized models. To tackle this challenge, we take advantage of the fact that neural networks are overparameterized, which allows us to improve neural network training with differential privacy. Specifically, we introduce a new training paradigm that uses \textit{pre-pruning} and \textit{gradient-dropping} to reduce the parameter space and improve scalability. The process starts with pre-pruning the parameters of the original network to obtain a smaller model that is then trained with DP-SGD. During training, less important gradients are dropped, and only selected gradients are updated. Our training paradigm introduces a tension between the rates of pre-pruning and gradient-dropping, privacy loss, and classification accuracy. Too much pre-pruning and gradient-dropping reduces the model's capacity and worsens accuracy, while training a smaller model requires less privacy budget for achieving good accuracy. We evaluate the interplay between these factors and demonstrate the effectiveness of our training paradigm for both training from scratch and fine-tuning pre-trained networks on several benchmark image classification datasets. The tools can also be readily incorporated into existing training paradigms.
Redesigning Out-of-Distribution Detection on 3D Medical Images
Aug 07, 2023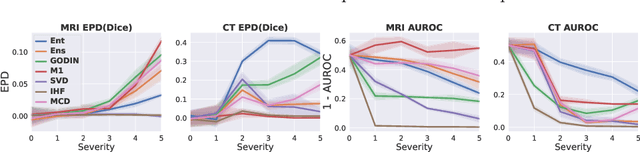
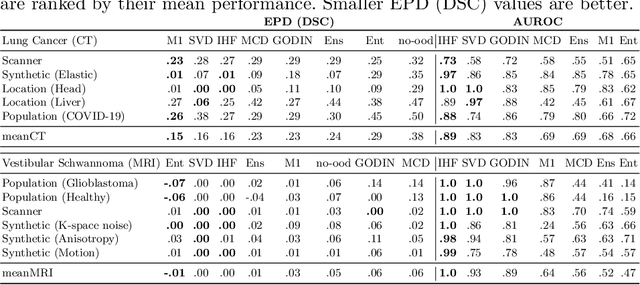

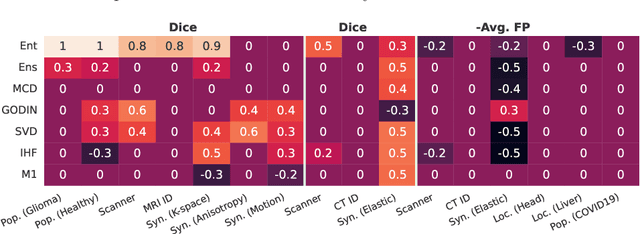
Detecting out-of-distribution (OOD) samples for trusted medical image segmentation remains a significant challenge. The critical issue here is the lack of a strict definition of abnormal data, which often results in artificial problem settings without measurable clinical impact. In this paper, we redesign the OOD detection problem according to the specifics of volumetric medical imaging and related downstream tasks (e.g., segmentation). We propose using the downstream model's performance as a pseudometric between images to define abnormal samples. This approach enables us to weigh different samples based on their performance impact without an explicit ID/OOD distinction. We incorporate this weighting in a new metric called Expected Performance Drop (EPD). EPD is our core contribution to the new problem design, allowing us to rank methods based on their clinical impact. We demonstrate the effectiveness of EPD-based evaluation in 11 CT and MRI OOD detection challenges.