 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Representations' Study of Latent Image Manifolds
May 31, 2023
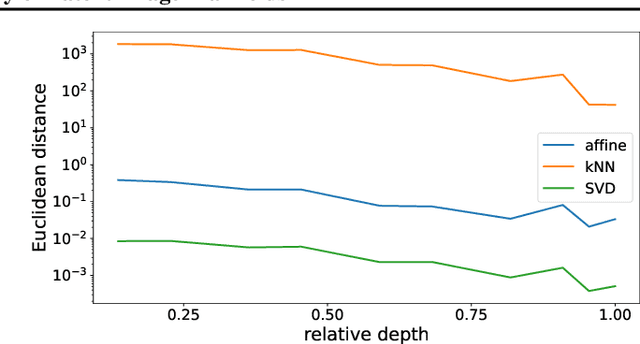
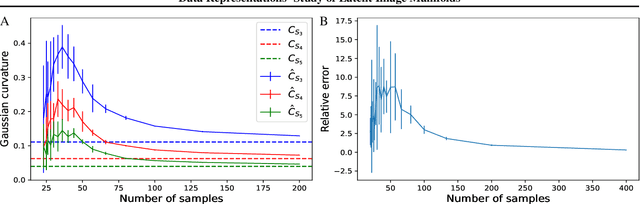
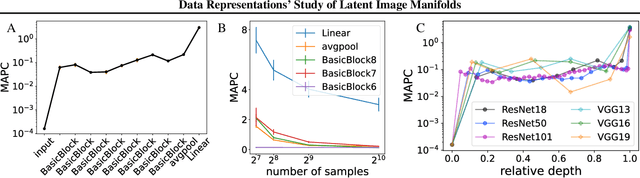
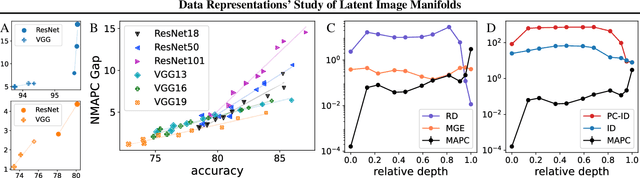
Deep neural networks have been demonstrated to achieve phenomenal success in many domains, and yet their inner mechanisms are not well understood. In this paper, we investigate the curvature of image manifolds, i.e., the manifold deviation from being flat in its principal directions. We find that state-of-the-art trained convolutional neural networks for image classification have a characteristic curvature profile along layers: an initial steep increase, followed by a long phase of a plateau, and followed by another increase. In contrast, this behavior does not appear in untrained networks in which the curvature flattens. We also show that the curvature gap between the last two layers has a strong correlation with the generalization capability of the network. Moreover, we find that the intrinsic dimension of latent codes is not necessarily indicative of curvature. Finally, we observe that common regularization methods such as mixup yield flatter representations when compared to other methods. Our experiments show consistent results over a variety of deep learning architectures and multiple data sets. Our code is publicly available at https://github.com/azencot-group/CRLM
Enhancing Nucleus Segmentation with HARU-Net: A Hybrid Attention Based Residual U-Blocks Network
Aug 07, 2023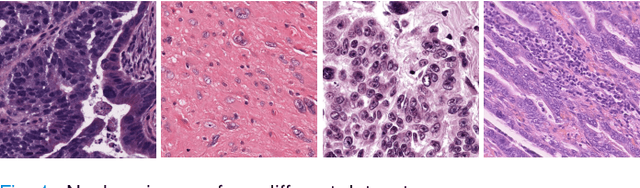
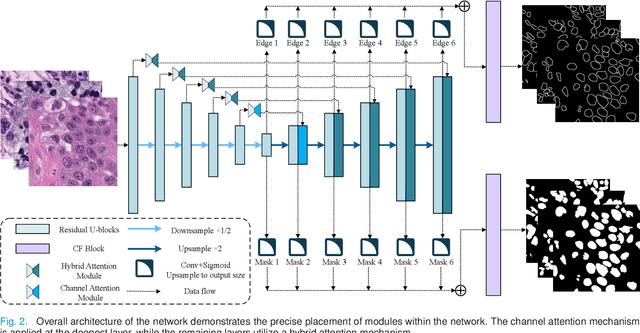
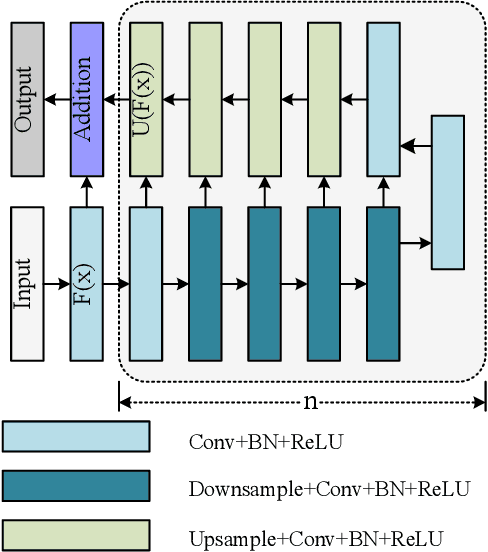
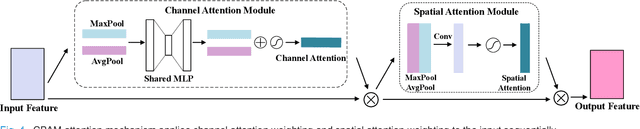
Nucleus image segmentation is a crucial step in the analysis, pathological diagnosis, and classification, which heavily relies on the quality of nucleus segmentation. However, the complexity of issues such as variations in nucleus size, blurred nucleus contours, uneven staining, cell clustering, and overlapping cells poses significant challenges. Current methods for nucleus segmentation primarily rely on nuclear morphology or contour-based approaches. Nuclear morphology-based methods exhibit limited generalization ability and struggle to effectively predict irregular-shaped nuclei, while contour-based extraction methods face challenges in accurately segmenting overlapping nuclei. To address the aforementioned issues, we propose a dual-branch network using hybrid attention based residual U-blocks for nucleus instance segmentation. The network simultaneously predicts target information and target contours. Additionally, we introduce a post-processing method that combines the target information and target contours to distinguish overlapping nuclei and generate an instance segmentation image. Within the network, we propose a context fusion block (CF-block) that effectively extracts and merges contextual information from the network. Extensive quantitative evaluations are conducted to assess the performance of our method. Experimental results demonstrate the superior performance of the proposed method compared to state-of-the-art approaches on the BNS, MoNuSeg, CoNSeg, and CPM-17 datasets.
Local Consensus Enhanced Siamese Network with Reciprocal Loss for Two-view Correspondence Learning
Aug 06, 2023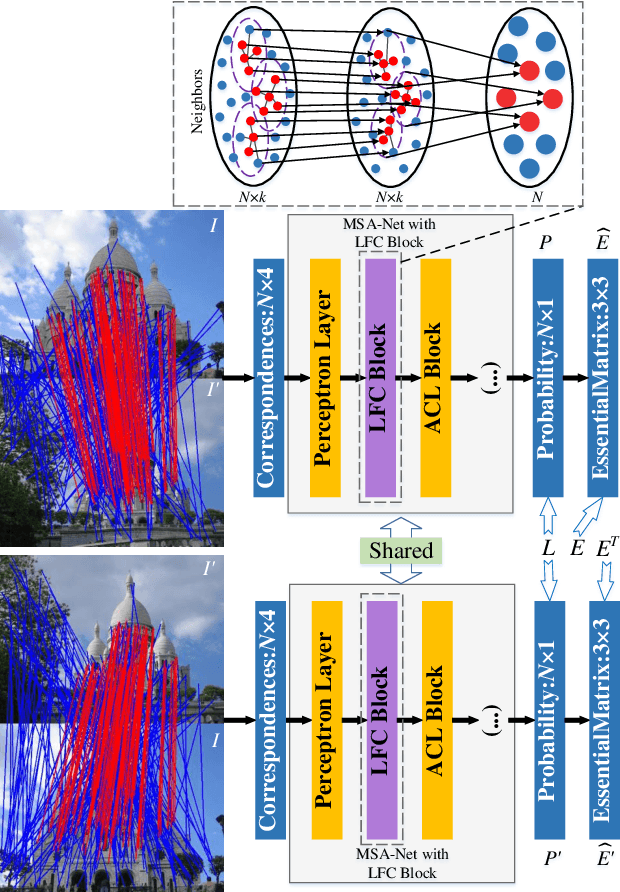
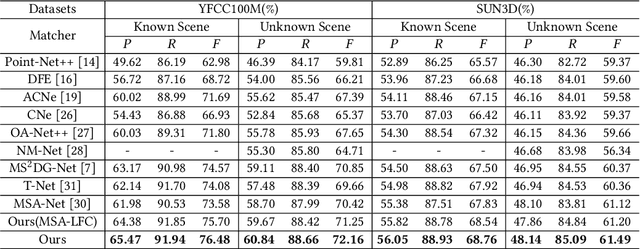
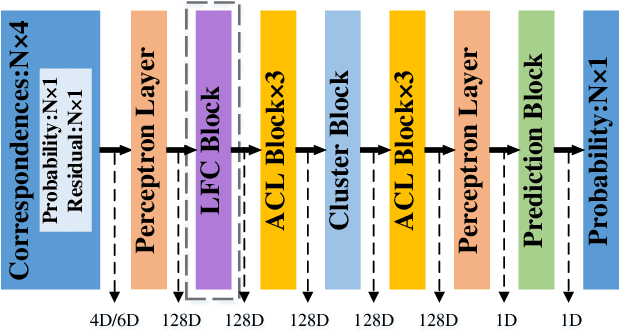
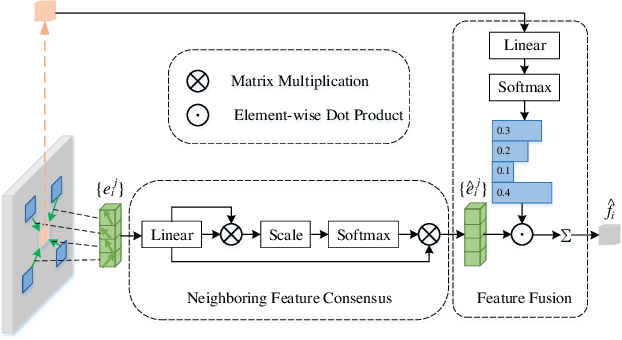
Recent studies of two-view correspondence learning usually establish an end-to-end network to jointly predict correspondence reliability and relative pose. We improve such a framework from two aspects. First, we propose a Local Feature Consensus (LFC) plugin block to augment the features of existing models. Given a correspondence feature, the block augments its neighboring features with mutual neighborhood consensus and aggregates them to produce an enhanced feature. As inliers obey a uniform cross-view transformation and share more consistent learned features than outliers, feature consensus strengthens inlier correlation and suppresses outlier distraction, which makes output features more discriminative for classifying inliers/outliers. Second, existing approaches supervise network training with the ground truth correspondences and essential matrix projecting one image to the other for an input image pair, without considering the information from the reverse mapping. We extend existing models to a Siamese network with a reciprocal loss that exploits the supervision of mutual projection, which considerably promotes the matching performance without introducing additional model parameters. Building upon MSA-Net, we implement the two proposals and experimentally achieve state-of-the-art performance on benchmark datasets.
T-Fusion Net: A Novel Deep Neural Network Augmented with Multiple Localizations based Spatial Attention Mechanisms for Covid-19 Detection
Jul 31, 2023
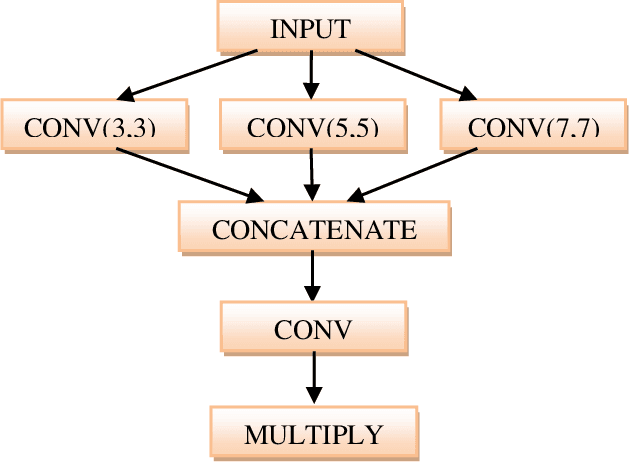
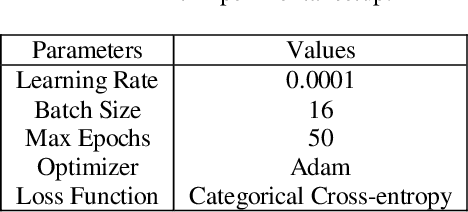
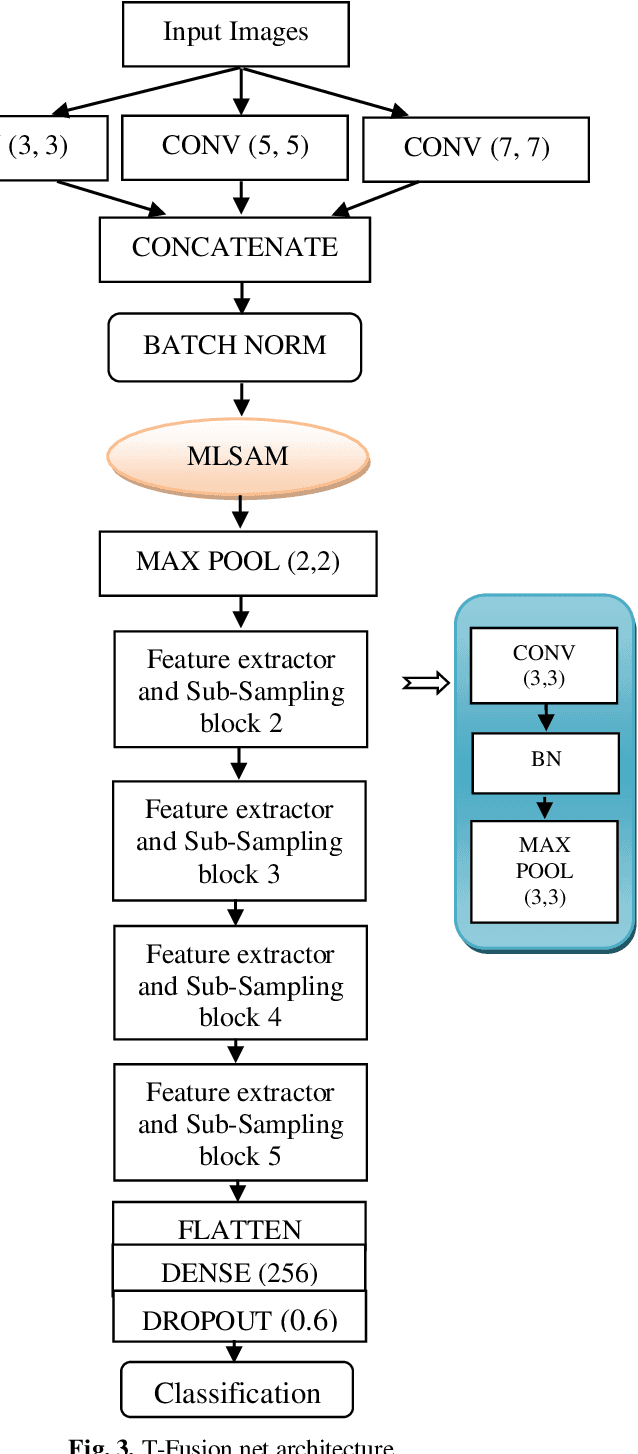
In recent years, deep neural networks are yielding better performance in image classification tasks. However, the increasing complexity of datasets and the demand for improved performance necessitate the exploration of innovative techniques. The present work proposes a new deep neural network (called as, T-Fusion Net) that augments multiple localizations based spatial attention. This attention mechanism allows the network to focus on relevant image regions, improving its discriminative power. A homogeneous ensemble of the said network is further used to enhance image classification accuracy. For ensembling, the proposed approach considers multiple instances of individual T-Fusion Net. The model incorporates fuzzy max fusion to merge the outputs of individual nets. The fusion process is optimized through a carefully chosen parameter to strike a balance on the contributions of the individual models. Experimental evaluations on benchmark Covid-19 (SARS-CoV-2 CT scan) dataset demonstrate the effectiveness of the proposed T-Fusion Net as well as its ensemble. The proposed T-Fusion Net and the homogeneous ensemble model exhibit better performance, as compared to other state-of-the-art methods, achieving accuracy of 97.59% and 98.4%, respectively.
The CLIP Model is Secretly an Image-to-Prompt Converter
May 22, 2023
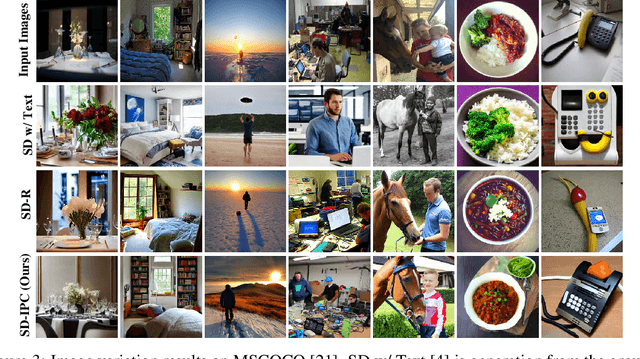


The Stable Diffusion model is a prominent text-to-image generation model that relies on a text prompt as its input, which is encoded using the Contrastive Language-Image Pre-Training (CLIP). However, text prompts have limitations when it comes to incorporating implicit information from reference images. Existing methods have attempted to address this limitation by employing expensive training procedures involving millions of training samples for image-to-image generation. In contrast, this paper demonstrates that the CLIP model, as utilized in Stable Diffusion, inherently possesses the ability to instantaneously convert images into text prompts. Such an image-to-prompt conversion can be achieved by utilizing a linear projection matrix that is calculated in a closed form. Moreover, the paper showcases that this capability can be further enhanced by either utilizing a small amount of similar-domain training data (approximately 100 images) or incorporating several online training steps (around 30 iterations) on the reference images. By leveraging these approaches, the proposed method offers a simple and flexible solution to bridge the gap between images and text prompts. This methodology can be applied to various tasks such as image variation and image editing, facilitating more effective and seamless interaction between images and textual prompts.
Controllable Text-to-Image Generation with GPT-4
May 29, 2023

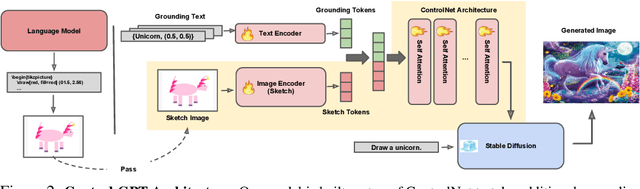

Current text-to-image generation models often struggle to follow textual instructions, especially the ones requiring spatial reasoning. On the other hand, Large Language Models (LLMs), such as GPT-4, have shown remarkable precision in generating code snippets for sketching out text inputs graphically, e.g., via TikZ. In this work, we introduce Control-GPT to guide the diffusion-based text-to-image pipelines with programmatic sketches generated by GPT-4, enhancing their abilities for instruction following. Control-GPT works by querying GPT-4 to write TikZ code, and the generated sketches are used as references alongside the text instructions for diffusion models (e.g., ControlNet) to generate photo-realistic images. One major challenge to training our pipeline is the lack of a dataset containing aligned text, images, and sketches. We address the issue by converting instance masks in existing datasets into polygons to mimic the sketches used at test time. As a result, Control-GPT greatly boosts the controllability of image generation. It establishes a new state-of-art on the spatial arrangement and object positioning generation and enhances users' control of object positions, sizes, etc., nearly doubling the accuracy of prior models. Our work, as a first attempt, shows the potential for employing LLMs to enhance the performance in computer vision tasks.
Testing the Depth of ChatGPT's Comprehension via Cross-Modal Tasks Based on ASCII-Art: GPT3.5's Abilities in Regard to Recognizing and Generating ASCII-Art Are Not Totally Lacking
Jul 28, 2023Over the eight months since its release, ChatGPT and its underlying model, GPT3.5, have garnered massive attention, due to their potent mix of capability and accessibility. While a niche-industry of papers have emerged examining the scope of capabilities these models possess, the information fed to and extracted from these networks has been either natural language text or stylized, code-like language. Drawing inspiration from the prowess we expect a truly human-level intelligent agent to have across multiple signal modalities, in this work we examine GPT3.5's aptitude for visual tasks, where the inputs feature content provided as ASCII-art without overt distillation into a lingual summary. We conduct experiments analyzing the model's performance on image recognition tasks after various transforms typical in visual settings, trials investigating knowledge of image parts, and tasks covering image generation.
Arc-to-line frame registration method for ultrasound and photoacoustic image-guided intraoperative robot-assisted laparoscopic prostatectomy
Jun 21, 2023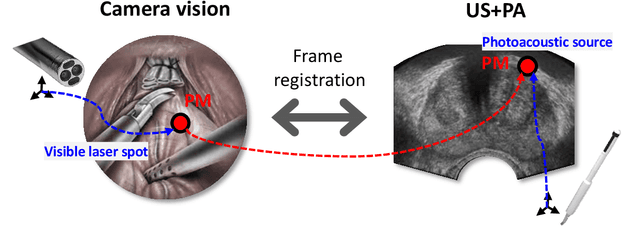
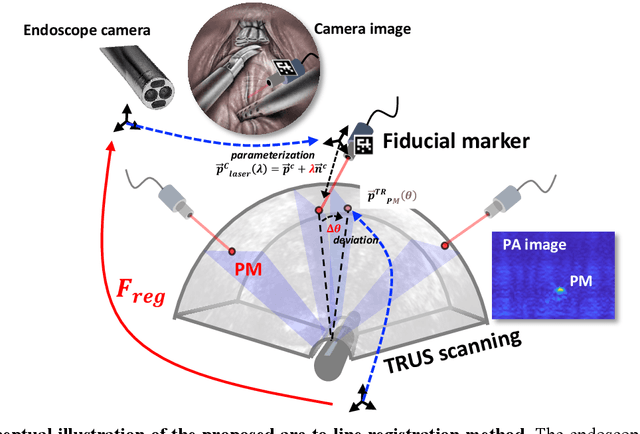
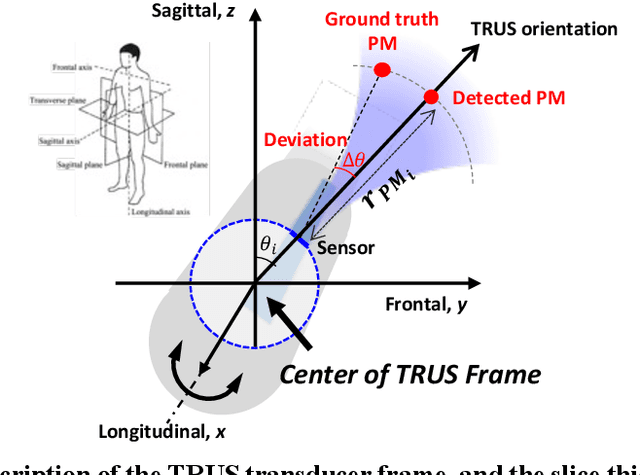

Purpose: To achieve effective robot-assisted laparoscopic prostatectomy, the integration of transrectal ultrasound (TRUS) imaging system which is the most widely used imaging modelity in prostate imaging is essential. However, manual manipulation of the ultrasound transducer during the procedure will significantly interfere with the surgery. Therefore, we propose an image co-registration algorithm based on a photoacoustic marker method, where the ultrasound / photoacoustic (US/PA) images can be registered to the endoscopic camera images to ultimately enable the TRUS transducer to automatically track the surgical instrument Methods: An optimization-based algorithm is proposed to co-register the images from the two different imaging modalities. The principles of light propagation and an uncertainty in PM detection were assumed in this algorithm to improve the stability and accuracy of the algorithm. The algorithm is validated using the previously developed US/PA image-guided system with a da Vinci surgical robot. Results: The target-registration-error (TRE) is measured to evaluate the proposed algorithm. In both simulation and experimental demonstration, the proposed algorithm achieved a sub-centimeter accuracy which is acceptable in practical clinics. The result is also comparable with our previous approach, and the proposed method can be implemented with a normal white light stereo camera and doesn't require highly accurate localization of the PM. Conclusion: The proposed frame registration algorithm enabled a simple yet efficient integration of commercial US/PA imaging system into laparoscopic surgical setting by leveraging the characteristic properties of acoustic wave propagation and laser excitation, contributing to automated US/PA image-guided surgical intervention applications.
InfoStyler: Disentanglement Information Bottleneck for Artistic Style Transfer
Jul 30, 2023
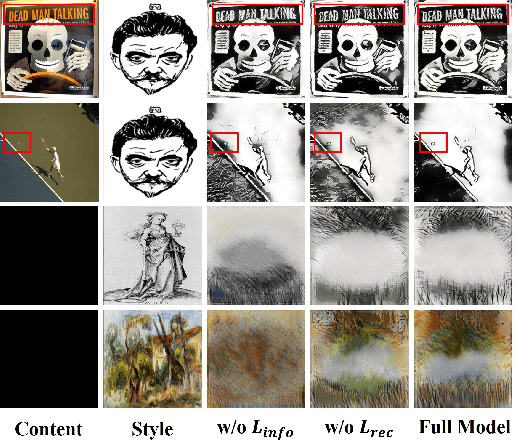


Artistic style transfer aims to transfer the style of an artwork to a photograph while maintaining its original overall content. Many prior works focus on designing various transfer modules to transfer the style statistics to the content image. Although effective, ignoring the clear disentanglement of the content features and the style features from the first beginning, they have difficulty in balancing between content preservation and style transferring. To tackle this problem, we propose a novel information disentanglement method, named InfoStyler, to capture the minimal sufficient information for both content and style representations from the pre-trained encoding network. InfoStyler formulates the disentanglement representation learning as an information compression problem by eliminating style statistics from the content image and removing the content structure from the style image. Besides, to further facilitate disentanglement learning, a cross-domain Information Bottleneck (IB) learning strategy is proposed by reconstructing the content and style domains. Extensive experiments demonstrate that our InfoStyler can synthesize high-quality stylized images while balancing content structure preservation and style pattern richness.
StarSRGAN: Improving Real-World Blind Super-Resolution
Jul 30, 2023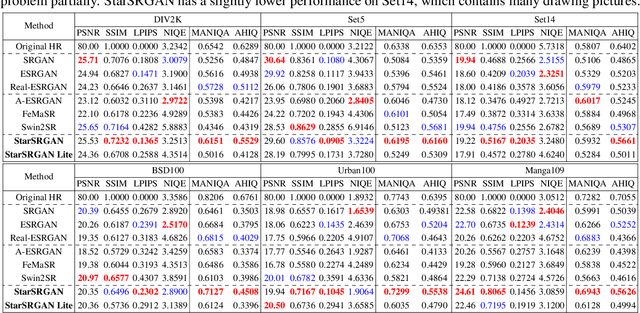
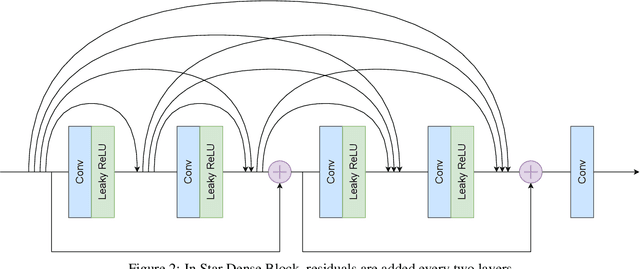
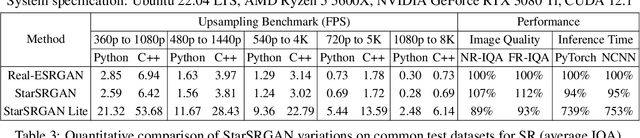
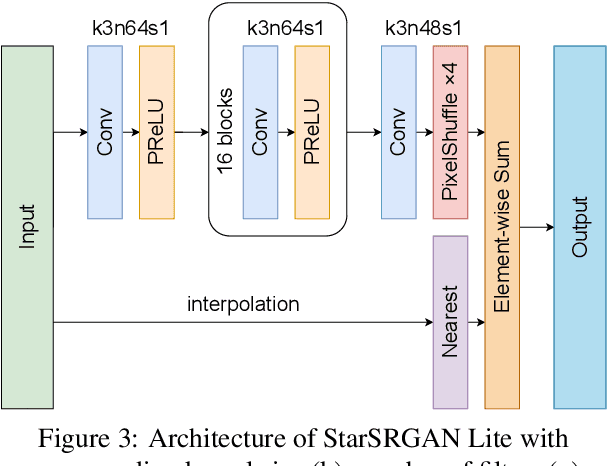
The aim of blind super-resolution (SR) in computer vision is to improve the resolution of an image without prior knowledge of the degradation process that caused the image to be low-resolution. The State of the Art (SOTA) model Real-ESRGAN has advanced perceptual loss and produced visually compelling outcomes using more complex degradation models to simulate real-world degradations. However, there is still room to improve the super-resolved quality of Real-ESRGAN by implementing recent techniques. This research paper introduces StarSRGAN, a novel GAN model designed for blind super-resolution tasks that utilize 5 various architectures. Our model provides new SOTA performance with roughly 10% better on the MANIQA and AHIQ measures, as demonstrated by experimental comparisons with Real-ESRGAN. In addition, as a compact version, StarSRGAN Lite provides approximately 7.5 times faster reconstruction speed (real-time upsampling from 540p to 4K) but can still keep nearly 90% of image quality, thereby facilitating the development of a real-time SR experience for future research. Our codes are released at https://github.com/kynthesis/StarSRGAN.