 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SaaFormer: Spectral-spatial Axial Aggregation Transformer for Hyperspectral Image Classification
Jun 29, 2023
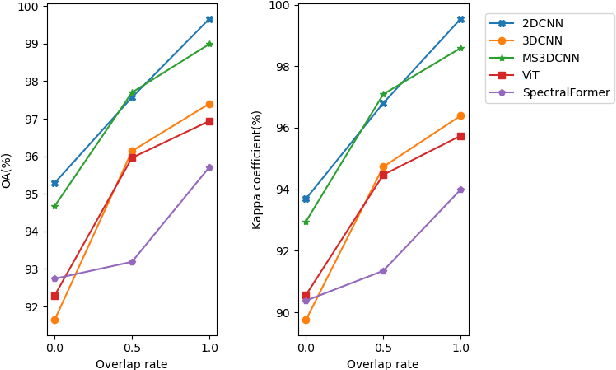
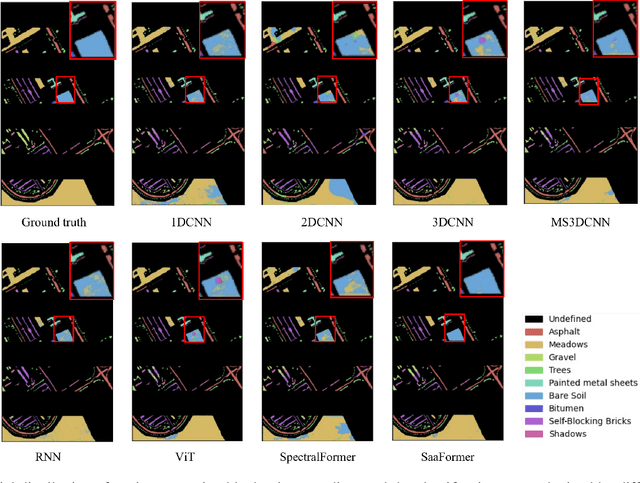
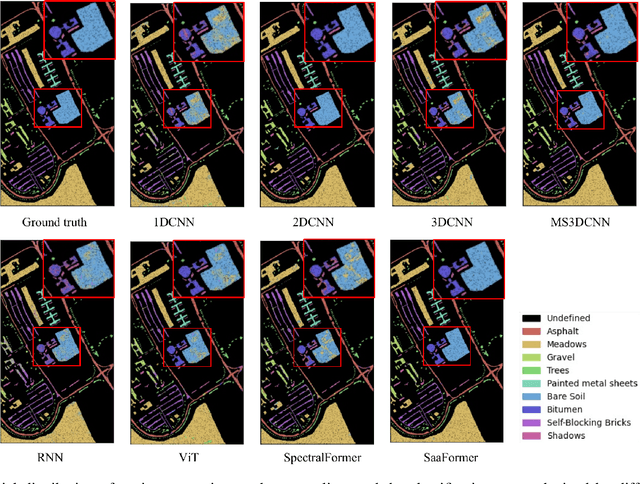
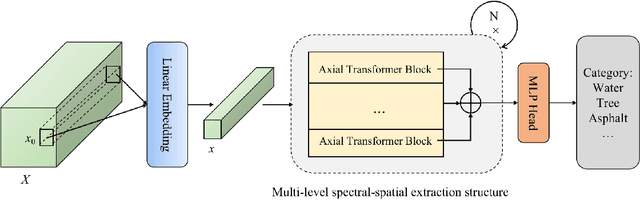
Hyperspectral images (HSI) captured from earth observing satellites and aircraft is becoming increasingly important for applications in agriculture, environmental monitoring, mining, etc. Due to the limited available hyperspectral datasets, the pixel-wise random sampling is the most commonly used training-test dataset partition approach, which has significant overlap between samples in training and test datasets. Furthermore, our experimental observations indicates that regions with larger overlap often exhibit higher classification accuracy. Consequently, the pixel-wise random sampling approach poses a risk of data leakage. Thus, we propose a block-wise sampling method to minimize the potential for data leakage. Our experimental findings also confirm the presence of data leakage in models such as 2DCNN. Further, We propose a spectral-spatial axial aggregation transformer model, namely SaaFormer, to address the challenges associated with hyperspectral image classifier that considers HSI as long sequential three-dimensional images. The model comprises two primary components: axial aggregation attention and multi-level spectral-spatial extraction. The axial aggregation attention mechanism effectively exploits the continuity and correlation among spectral bands at each pixel position in hyperspectral images, while aggregating spatial dimension features. This enables SaaFormer to maintain high precision even under block-wise sampling. The multi-level spectral-spatial extraction structure is designed to capture the sensitivity of different material components to specific spectral bands, allowing the model to focus on a broader range of spectral details. The results on six publicly available datasets demonstrate that our model exhibits comparable performance when using random sampling, while significantly outperforming other methods when employing block-wise sampling partition.
Comparison of Point Cloud and Image-based Models for Calorimeter Fast Simulation
Jul 31, 2023
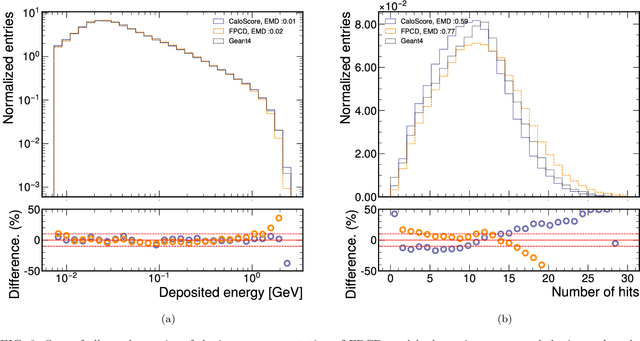
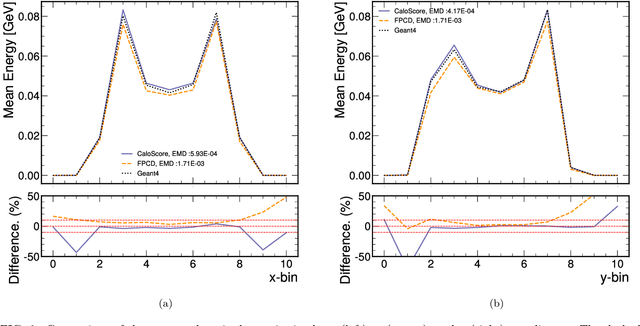
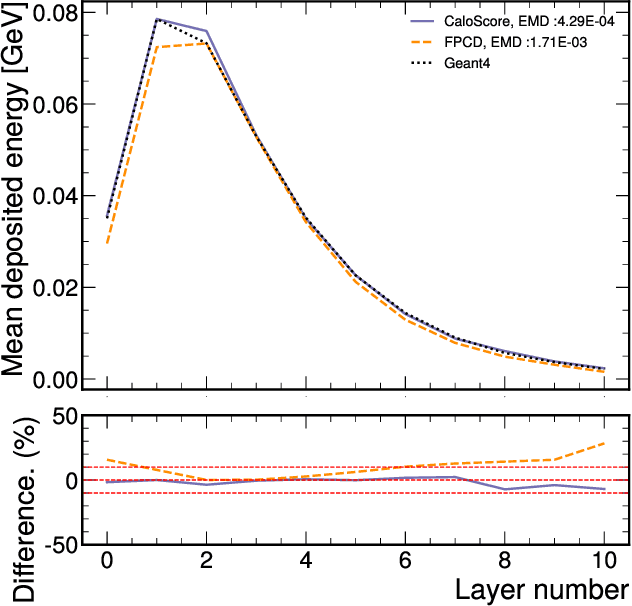
Score based generative models are a new class of generative models that have been shown to accurately generate high dimensional calorimeter datasets. Recent advances in generative models have used images with 3D voxels to represent and model complex calorimeter showers. Point clouds, however, are likely a more natural representation of calorimeter showers, particularly in calorimeters with high granularity. Point clouds preserve all of the information of the original simulation, more naturally deal with sparse datasets, and can be implemented with more compact models and data files. In this work, two state-of-the-art score based models are trained on the same set of calorimeter simulation and directly compared.
ZeroAvatar: Zero-shot 3D Avatar Generation from a Single Image
May 25, 2023
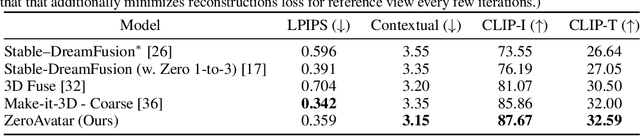
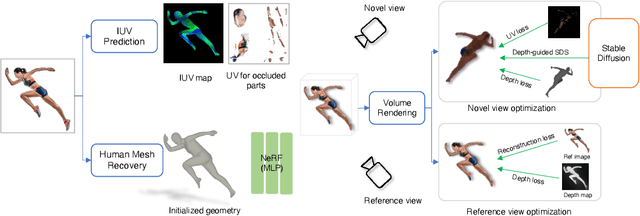

Recent advancements in text-to-image generation have enabled significant progress in zero-shot 3D shape generation. This is achieved by score distillation, a methodology that uses pre-trained text-to-image diffusion models to optimize the parameters of a 3D neural presentation, e.g. Neural Radiance Field (NeRF). While showing promising results, existing methods are often not able to preserve the geometry of complex shapes, such as human bodies. To address this challenge, we present ZeroAvatar, a method that introduces the explicit 3D human body prior to the optimization process. Specifically, we first estimate and refine the parameters of a parametric human body from a single image. Then during optimization, we use the posed parametric body as additional geometry constraint to regularize the diffusion model as well as the underlying density field. Lastly, we propose a UV-guided texture regularization term to further guide the completion of texture on invisible body parts. We show that ZeroAvatar significantly enhances the robustness and 3D consistency of optimization-based image-to-3D avatar generation, outperforming existing zero-shot image-to-3D methods.
Dual self-distillation of U-shaped networks for 3D medical image segmentation
Jun 05, 2023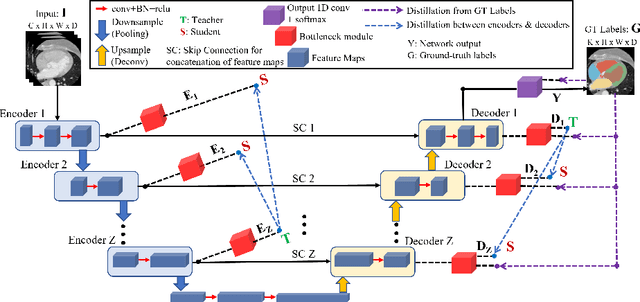
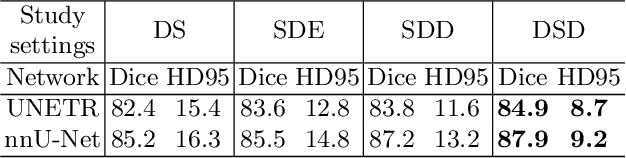
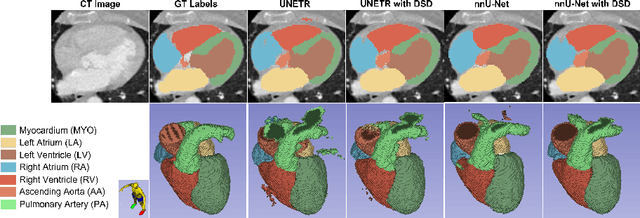
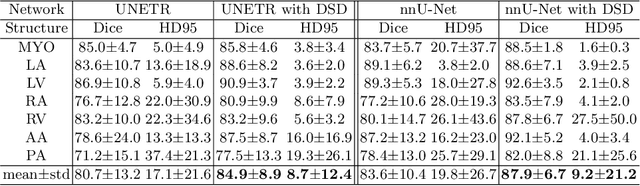
U-shaped networks and its variants have demonstrated exceptional results for medical image segmentation. In this paper, we propose a novel dual self-distillation (DSD) framework for U-shaped networks for 3D medical image segmentation. DSD distills knowledge from the ground-truth segmentation labels to the decoder layers and also between the encoder and decoder layers of a single U-shaped network. DSD is a generalized training strategy that could be attached to the backbone architecture of any U-shaped network to further improve its segmentation performance. We attached DSD on two state-of-the-art U-shaped backbones, and extensive experiments on two public 3D medical image segmentation datasets (cardiac substructure and brain tumor) demonstrated significant improvement over those backbones. On average, after attaching DSD to the U-shaped backbones, we observed an improvement of 4.25% and 3.15% in Dice similarity score for cardiac substructure and brain tumor segmentation respectively.
Enlighten-anything:When Segment Anything Model Meets Low-light Image Enhancement
Jun 21, 2023
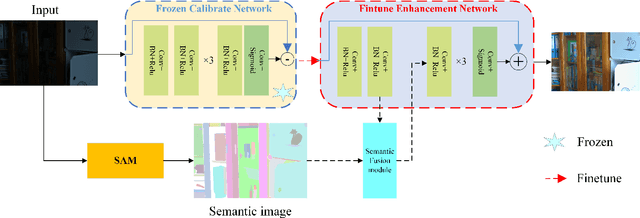


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten-anything can be obtained from https://github.com/zhangbaijin/enlighten-anything
EDIS: Entity-Driven Image Search over Multimodal Web Content
May 23, 2023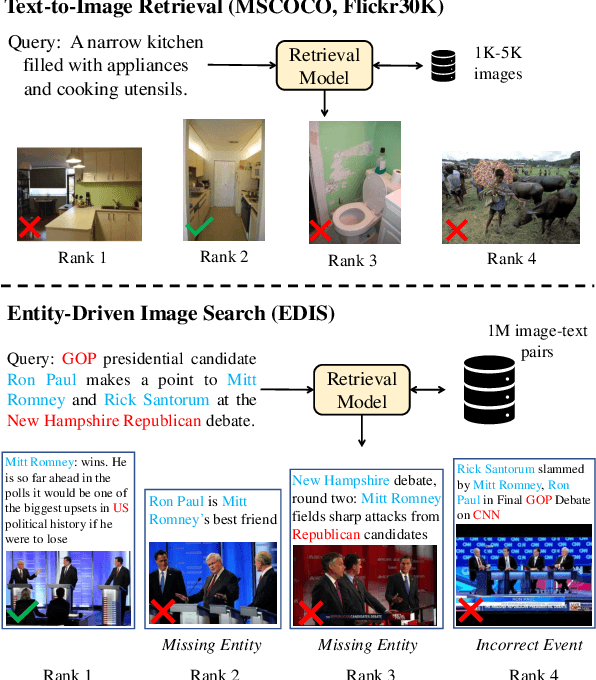
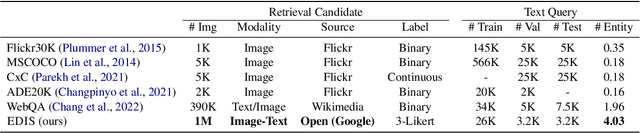


Making image retrieval methods practical for real-world search applications requires significant progress in dataset scales, entity comprehension, and multimodal information fusion. In this work, we introduce \textbf{E}ntity-\textbf{D}riven \textbf{I}mage \textbf{S}earch (EDIS), a challenging dataset for cross-modal image search in the news domain. EDIS consists of 1 million web images from actual search engine results and curated datasets, with each image paired with a textual description. Unlike datasets that assume a small set of single-modality candidates, EDIS reflects real-world web image search scenarios by including a million multimodal image-text pairs as candidates. EDIS encourages the development of retrieval models that simultaneously address cross-modal information fusion and matching. To achieve accurate ranking results, a model must: 1) understand named entities and events from text queries, 2) ground entities onto images or text descriptions, and 3) effectively fuse textual and visual representations. Our experimental results show that EDIS challenges state-of-the-art methods with dense entities and a large-scale candidate set. The ablation study also proves that fusing textual features with visual features is critical in improving retrieval results.
LMCap: Few-shot Multilingual Image Captioning by Retrieval Augmented Language Model Prompting
May 31, 2023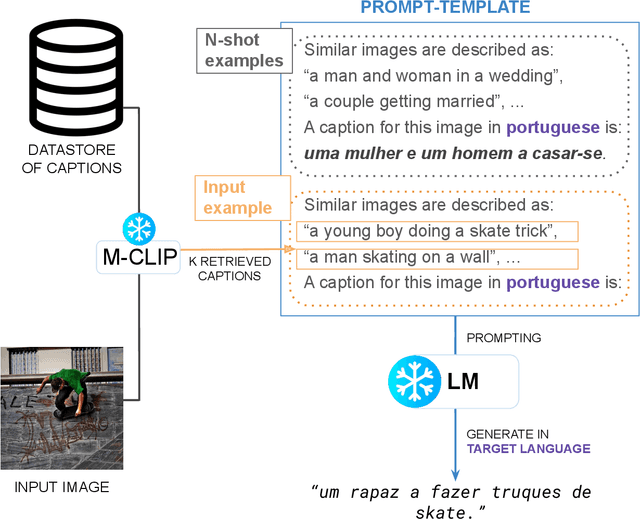
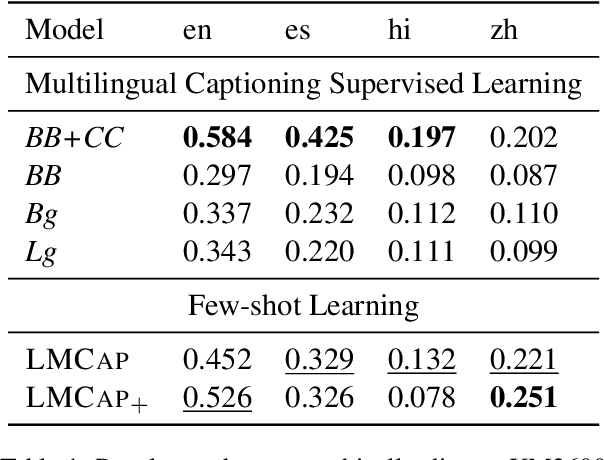
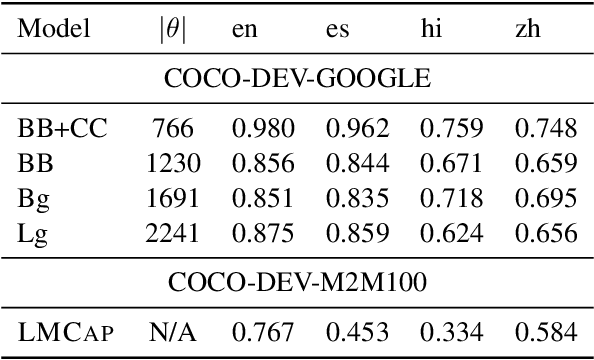
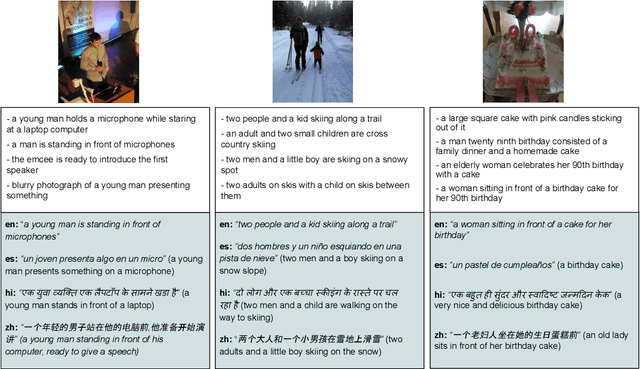
Multilingual image captioning has recently been tackled by training with large-scale machine translated data, which is an expensive, noisy, and time-consuming process. Without requiring any multilingual caption data, we propose LMCap, an image-blind few-shot multilingual captioning model that works by prompting a language model with retrieved captions. Specifically, instead of following the standard encoder-decoder paradigm, given an image, LMCap first retrieves the captions of similar images using a multilingual CLIP encoder. These captions are then combined into a prompt for an XGLM decoder, in order to generate captions in the desired language. In other words, the generation model does not directly process the image, instead processing retrieved captions. Experiments on the XM3600 dataset of geographically diverse images show that our model is competitive with fully-supervised multilingual captioning models, without requiring any supervised training on any captioning data.
ProSpect: Expanded Conditioning for the Personalization of Attribute-aware Image Generation
May 25, 2023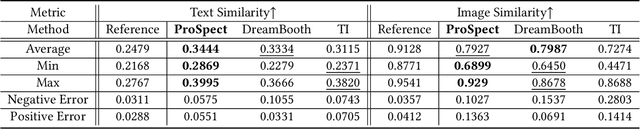
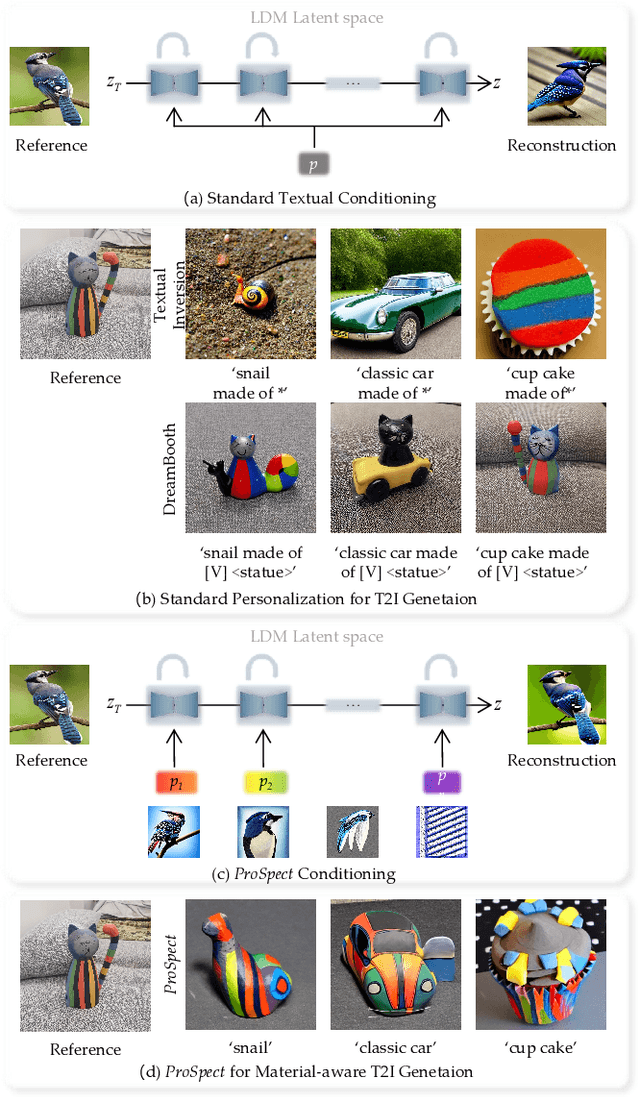

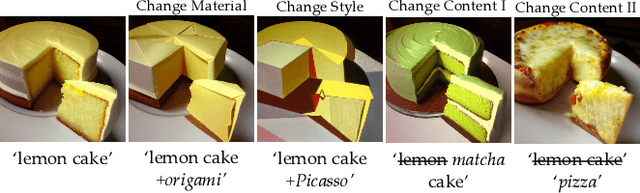
Personalizing generative models offers a way to guide image generation with user-provided references. Current personalization methods can invert an object or concept into the textual conditioning space and compose new natural sentences for text-to-image diffusion models. However, representing and editing specific visual attributes like material, style, layout, etc. remains a challenge, leading to a lack of disentanglement and editability. To address this, we propose a novel approach that leverages the step-by-step generation process of diffusion models, which generate images from low- to high-frequency information, providing a new perspective on representing, generating, and editing images. We develop Prompt Spectrum Space P*, an expanded textual conditioning space, and a new image representation method called ProSpect. ProSpect represents an image as a collection of inverted textual token embeddings encoded from per-stage prompts, where each prompt corresponds to a specific generation stage (i.e., a group of consecutive steps) of the diffusion model. Experimental results demonstrate that P* and ProSpect offer stronger disentanglement and controllability compared to existing methods. We apply ProSpect in various personalized attribute-aware image generation applications, such as image/text-guided material/style/layout transfer/editing, achieving previously unattainable results with a single image input without fine-tuning the diffusion models.
A full-resolution training framework for Sentinel-2 image fusion
Jul 27, 2023
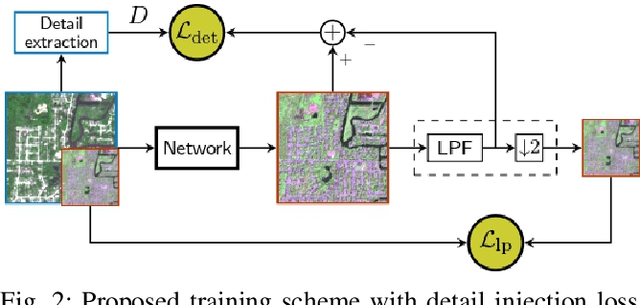
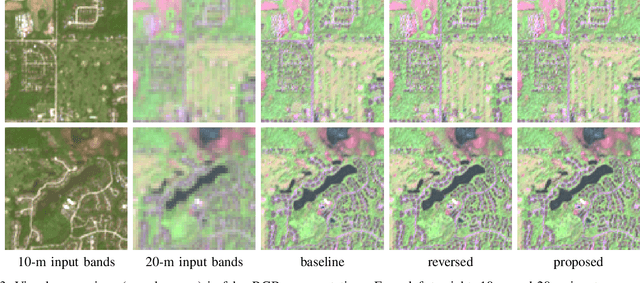
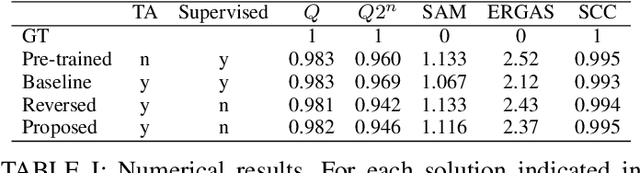
This work presents a new unsupervised framework for training deep learning models for super-resolution of Sentinel-2 images by fusion of its 10-m and 20-m bands. The proposed scheme avoids the resolution downgrade process needed to generate training data in the supervised case. On the other hand, a proper loss that accounts for cycle-consistency between the network prediction and the input components to be fused is proposed. Despite its unsupervised nature, in our preliminary experiments the proposed scheme has shown promising results in comparison to the supervised approach. Besides, by construction of the proposed loss, the resulting trained network can be ascribed to the class of multi-resolution analysis methods.
MDB: Interactively Querying Datasets and Models
Aug 13, 2023



As models are trained and deployed, developers need to be able to systematically debug errors that emerge in the machine learning pipeline. We present MDB, a debugging framework for interactively querying datasets and models. MDB integrates functional programming with relational algebra to build expressive queries over a database of datasets and model predictions. Queries are reusable and easily modified, enabling debuggers to rapidly iterate and refine queries to discover and characterize errors and model behaviors. We evaluate MDB on object detection, bias discovery, image classification, and data imputation tasks across self-driving videos, large language models, and medical records. Our experiments show that MDB enables up to 10x faster and 40\% shorter queries than other baselines. In a user study, we find developers can successfully construct complex queries that describe errors of machine learning models.