 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
May 25, 2023
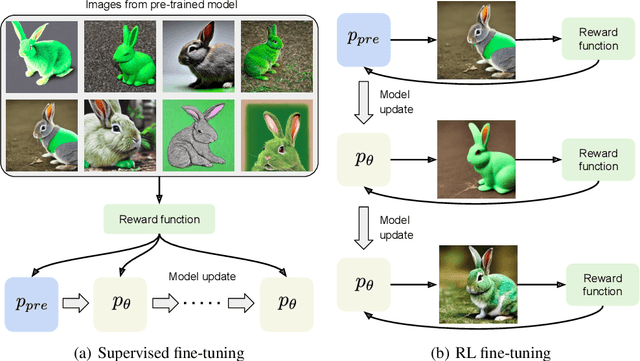


Learning from human feedback has been shown to improve text-to-image models. These techniques first learn a reward function that captures what humans care about in the task and then improve the models based on the learned reward function. Even though relatively simple approaches (e.g., rejection sampling based on reward scores) have been investigated, fine-tuning text-to-image models with the reward function remains challenging. In this work, we propose using online reinforcement learning (RL) to fine-tune text-to-image models. We focus on diffusion models, defining the fine-tuning task as an RL problem, and updating the pre-trained text-to-image diffusion models using policy gradient to maximize the feedback-trained reward. Our approach, coined DPOK, integrates policy optimization with KL regularization. We conduct an analysis of KL regularization for both RL fine-tuning and supervised fine-tuning. In our experiments, we show that DPOK is generally superior to supervised fine-tuning with respect to both image-text alignment and image quality.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023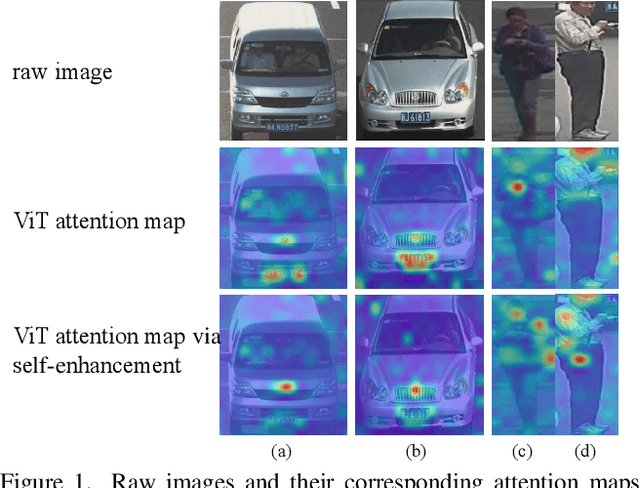
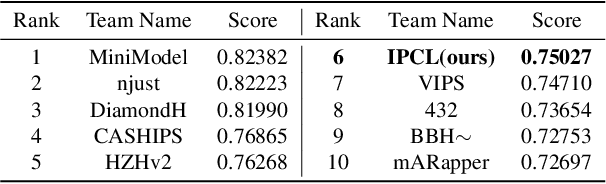
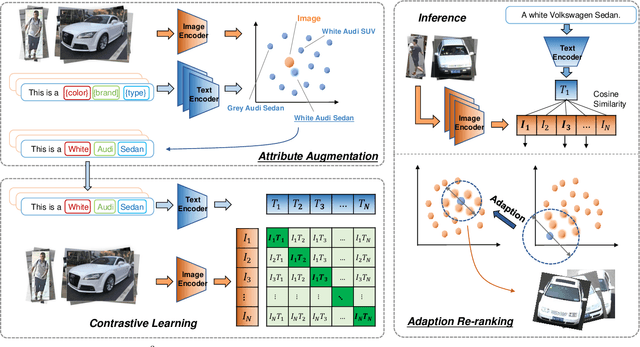

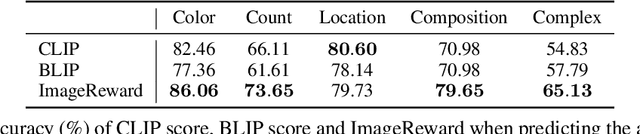
The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
Heuristic Hyperparameter Choice for Image Anomaly Detection
Jul 20, 2023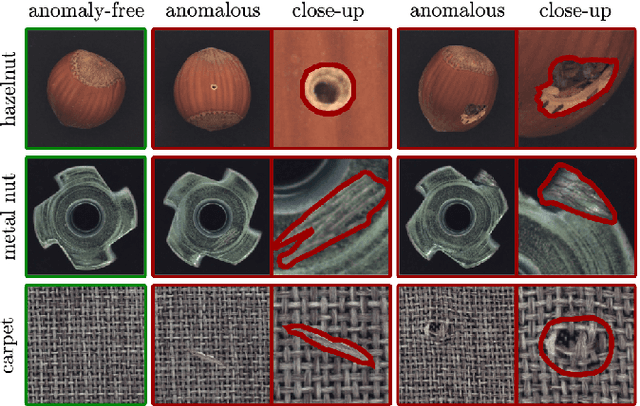
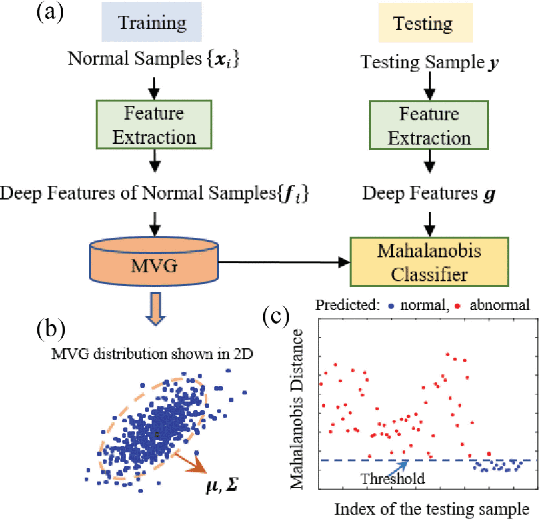


Anomaly detection (AD) in images is a fundamental computer vision problem by deep learning neural network to identify images deviating significantly from normality. The deep features extracted from pretrained models have been proved to be essential for AD based on multivariate Gaussian distribution analysis. However, since models are usually pretrained on a large dataset for classification tasks such as ImageNet, they might produce lots of redundant features for AD, which increases computational cost and degrades the performance. We aim to do the dimension reduction of Negated Principal Component Analysis (NPCA) for these features. So we proposed some heuristic to choose hyperparameter of NPCA algorithm for getting as fewer components of features as possible while ensuring a good performance.
Breast Ultrasound Tumor Classification Using a Hybrid Multitask CNN-Transformer Network
Aug 04, 2023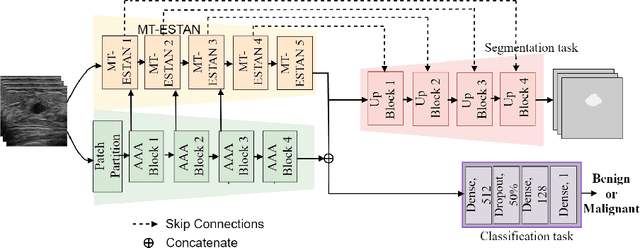

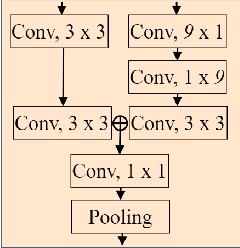
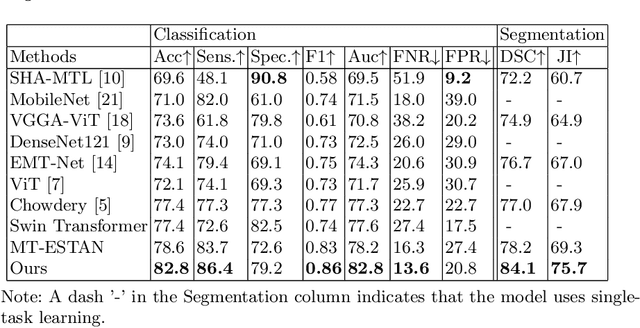
Capturing global contextual information plays a critical role in breast ultrasound (BUS) image classification. Although convolutional neural networks (CNNs) have demonstrated reliable performance in tumor classification, they have inherent limitations for modeling global and long-range dependencies due to the localized nature of convolution operations. Vision Transformers have an improved capability of capturing global contextual information but may distort the local image patterns due to the tokenization operations. In this study, we proposed a hybrid multitask deep neural network called Hybrid-MT-ESTAN, designed to perform BUS tumor classification and segmentation using a hybrid architecture composed of CNNs and Swin Transformer components. The proposed approach was compared to nine BUS classification methods and evaluated using seven quantitative metrics on a dataset of 3,320 BUS images. The results indicate that Hybrid-MT-ESTAN achieved the highest accuracy, sensitivity, and F1 score of 82.7%, 86.4%, and 86.0%, respectively.
Towards Adaptable and Interactive Image Captioning with Data Augmentation and Episodic Memory
Jun 06, 2023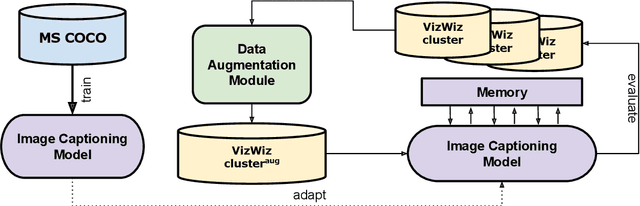
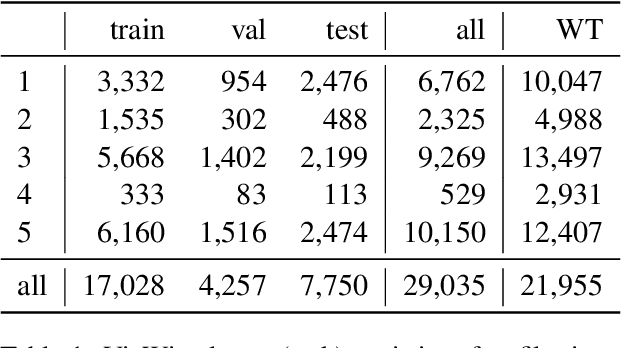

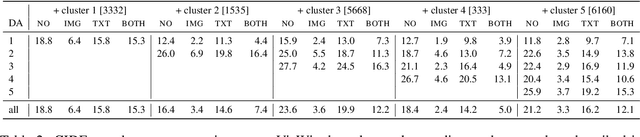
Interactive machine learning (IML) is a beneficial learning paradigm in cases of limited data availability, as human feedback is incrementally integrated into the training process. In this paper, we present an IML pipeline for image captioning which allows us to incrementally adapt a pre-trained image captioning model to a new data distribution based on user input. In order to incorporate user input into the model, we explore the use of a combination of simple data augmentation methods to obtain larger data batches for each newly annotated data instance and implement continual learning methods to prevent catastrophic forgetting from repeated updates. For our experiments, we split a domain-specific image captioning dataset, namely VizWiz, into non-overlapping parts to simulate an incremental input flow for continually adapting the model to new data. We find that, while data augmentation worsens results, even when relatively small amounts of data are available, episodic memory is an effective strategy to retain knowledge from previously seen clusters.
Improving Diversity in Zero-Shot GAN Adaptation with Semantic Variations
Aug 21, 2023
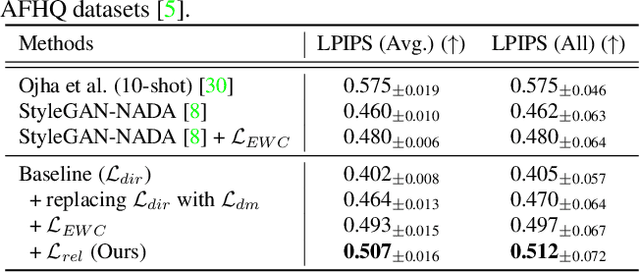
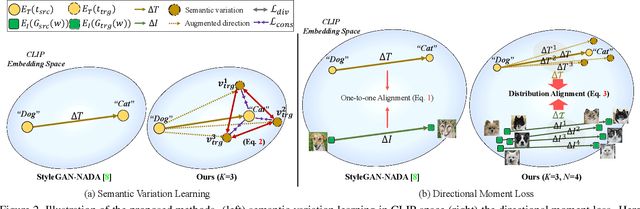

Training deep generative models usually requires a large amount of data. To alleviate the data collection cost, the task of zero-shot GAN adaptation aims to reuse well-trained generators to synthesize images of an unseen target domain without any further training samples. Due to the data absence, the textual description of the target domain and the vision-language models, e.g., CLIP, are utilized to effectively guide the generator. However, with only a single representative text feature instead of real images, the synthesized images gradually lose diversity as the model is optimized, which is also known as mode collapse. To tackle the problem, we propose a novel method to find semantic variations of the target text in the CLIP space. Specifically, we explore diverse semantic variations based on the informative text feature of the target domain while regularizing the uncontrolled deviation of the semantic information. With the obtained variations, we design a novel directional moment loss that matches the first and second moments of image and text direction distributions. Moreover, we introduce elastic weight consolidation and a relation consistency loss to effectively preserve valuable content information from the source domain, e.g., appearances. Through extensive experiments, we demonstrate the efficacy of the proposed methods in ensuring sample diversity in various scenarios of zero-shot GAN adaptation. We also conduct ablation studies to validate the effect of each proposed component. Notably, our model achieves a new state-of-the-art on zero-shot GAN adaptation in terms of both diversity and quality.
Introducing A Novel Method For Adaptive Thresholding In Brain Tumor Medical Image Segmentation
Jun 27, 2023One of the most significant challenges in the field of deep learning and medical image segmentation is to determine an appropriate threshold for classifying each pixel. This threshold is a value above which the model's output is considered to belong to a specific class. Manual thresholding based on personal experience is error-prone and time-consuming, particularly for complex problems such as medical images. Traditional methods for thresholding are not effective for determining the threshold value for such problems. To tackle this challenge, automatic thresholding methods using deep learning have been proposed. However, the main issue with these methods is that they often determine the threshold value statically without considering changes in input data. Since input data can be dynamic and may change over time, threshold determination should be adaptive and consider input data and environmental conditions.
The Performance of Transferability Metrics does not Translate to Medical Tasks
Aug 14, 2023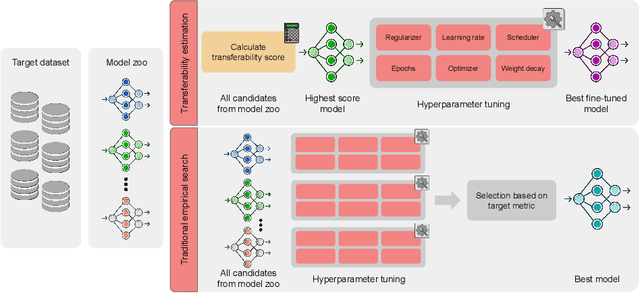

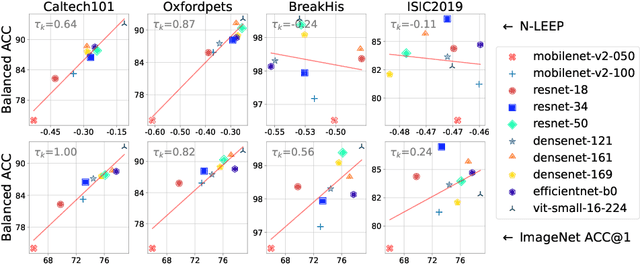
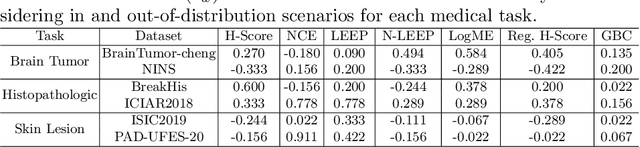
Transfer learning boosts the performance of medical image analysis by enabling deep learning (DL) on small datasets through the knowledge acquired from large ones. As the number of DL architectures explodes, exhaustively attempting all candidates becomes unfeasible, motivating cheaper alternatives for choosing them. Transferability scoring methods emerge as an enticing solution, allowing to efficiently calculate a score that correlates with the architecture accuracy on any target dataset. However, since transferability scores have not been evaluated on medical datasets, their use in this context remains uncertain, preventing them from benefiting practitioners. We fill that gap in this work, thoroughly evaluating seven transferability scores in three medical applications, including out-of-distribution scenarios. Despite promising results in general-purpose datasets, our results show that no transferability score can reliably and consistently estimate target performance in medical contexts, inviting further work in that direction.
ContriMix: Unsupervised disentanglement of content and attribute for domain generalization in microscopy image analysis
Jul 03, 2023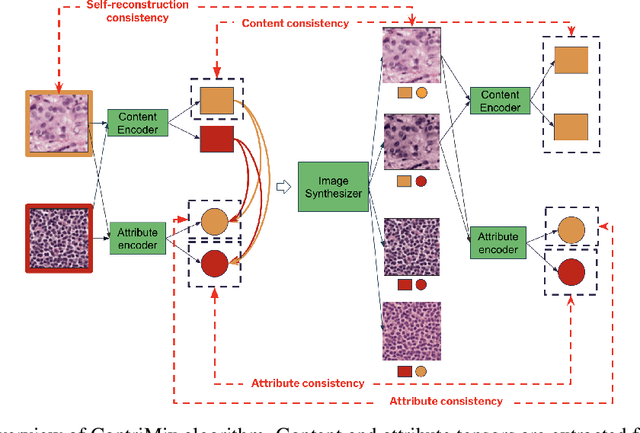

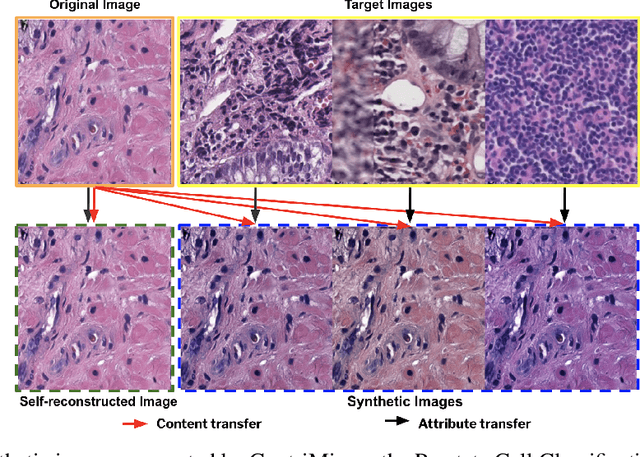
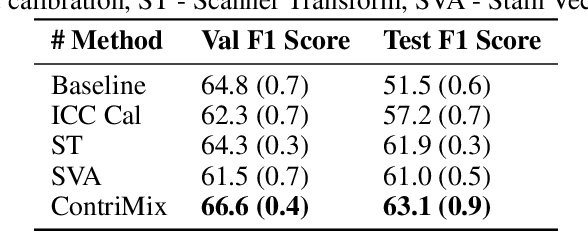
Domain generalization is critical for real-world applications of machine learning models to microscopy images, including histopathology and fluorescence imaging. Artifacts in histopathology arise through a complex combination of factors relating to tissue collection and laboratory processing, as well as factors intrinsic to patient samples. In fluorescence imaging, these artifacts stem from variations across experimental batches. The complexity and subtlety of these artifacts make the enumeration of data domains intractable. Therefore, augmentation-based methods of domain generalization that require domain identifiers and manual fine-tuning are inadequate in this setting. To overcome this challenge, we introduce ContriMix, a domain generalization technique that learns to generate synthetic images by disentangling and permuting the biological content ("content") and technical variations ("attributes") in microscopy images. ContriMix does not rely on domain identifiers or handcrafted augmentations and makes no assumptions about the input characteristics of images. We assess the performance of ContriMix on two pathology datasets (Camelyon17-WILDS and a prostate cell classification dataset) and one fluorescence microscopy dataset (RxRx1-WILDS). ContriMix outperforms current state-of-the-art methods in all datasets, motivating its usage for microscopy image analysis in real-world settings where domain information is hard to come by.
ZeroAvatar: Zero-shot 3D Avatar Generation from a Single Image
May 25, 2023
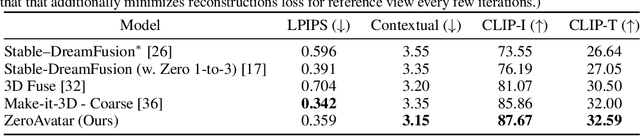
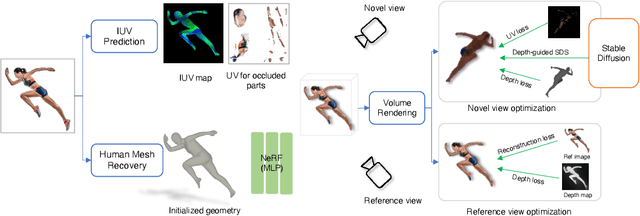

Recent advancements in text-to-image generation have enabled significant progress in zero-shot 3D shape generation. This is achieved by score distillation, a methodology that uses pre-trained text-to-image diffusion models to optimize the parameters of a 3D neural presentation, e.g. Neural Radiance Field (NeRF). While showing promising results, existing methods are often not able to preserve the geometry of complex shapes, such as human bodies. To address this challenge, we present ZeroAvatar, a method that introduces the explicit 3D human body prior to the optimization process. Specifically, we first estimate and refine the parameters of a parametric human body from a single image. Then during optimization, we use the posed parametric body as additional geometry constraint to regularize the diffusion model as well as the underlying density field. Lastly, we propose a UV-guided texture regularization term to further guide the completion of texture on invisible body parts. We show that ZeroAvatar significantly enhances the robustness and 3D consistency of optimization-based image-to-3D avatar generation, outperforming existing zero-shot image-to-3D methods.