 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DMCVR: Morphology-Guided Diffusion Model for 3D Cardiac Volume Reconstruction
Aug 18, 2023
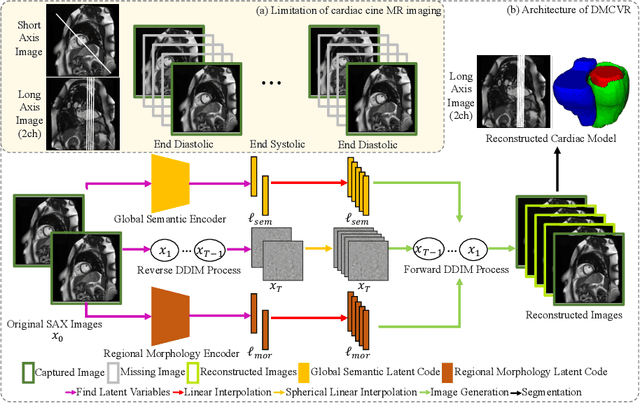
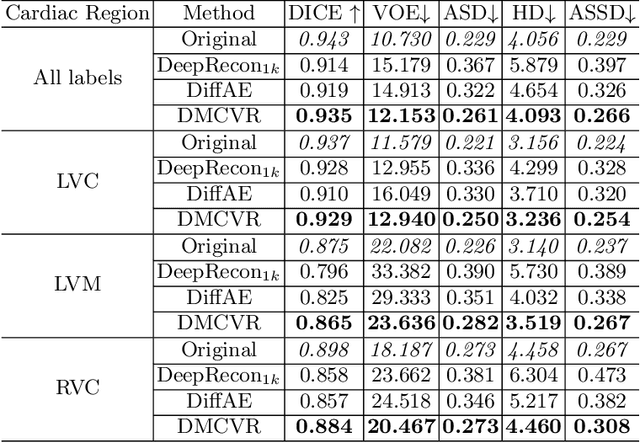
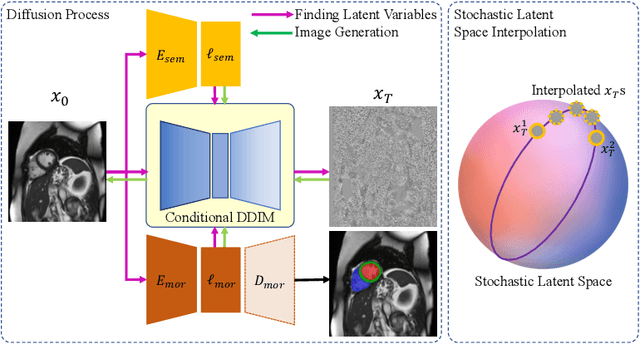
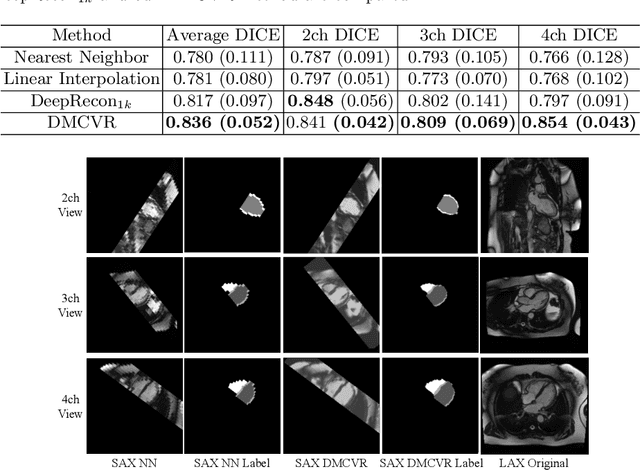
Accurate 3D cardiac reconstruction from cine magnetic resonance imaging (cMRI) is crucial for improved cardiovascular disease diagnosis and understanding of the heart's motion. However, current cardiac MRI-based reconstruction technology used in clinical settings is 2D with limited through-plane resolution, resulting in low-quality reconstructed cardiac volumes. To better reconstruct 3D cardiac volumes from sparse 2D image stacks, we propose a morphology-guided diffusion model for 3D cardiac volume reconstruction, DMCVR, that synthesizes high-resolution 2D images and corresponding 3D reconstructed volumes. Our method outperforms previous approaches by conditioning the cardiac morphology on the generative model, eliminating the time-consuming iterative optimization process of the latent code, and improving generation quality. The learned latent spaces provide global semantics, local cardiac morphology and details of each 2D cMRI slice with highly interpretable value to reconstruct 3D cardiac shape. Our experiments show that DMCVR is highly effective in several aspects, such as 2D generation and 3D reconstruction performance. With DMCVR, we can produce high-resolution 3D cardiac MRI reconstructions, surpassing current techniques. Our proposed framework has great potential for improving the accuracy of cardiac disease diagnosis and treatment planning. Code can be accessed at https://github.com/hexiaoxiao-cs/DMCVR.
On Gradient-like Explanation under a Black-box Setting: When Black-box Explanations Become as Good as White-box
Aug 18, 2023Attribution methods shed light on the explainability of data-driven approaches such as deep learning models by revealing the most contributing features to decisions that have been made. A widely accepted way of deriving feature attributions is to analyze the gradients of the target function with respect to input features. Analysis of gradients requires full access to the target system, meaning that solutions of this kind treat the target system as a white-box. However, the white-box assumption may be untenable due to security and safety concerns, thus limiting their practical applications. As an answer to the limited flexibility, this paper presents GEEX (gradient-estimation-based explanation), an explanation method that delivers gradient-like explanations under a black-box setting. Furthermore, we integrate the proposed method with a path method. The resulting approach iGEEX (integrated GEEX) satisfies the four fundamental axioms of attribution methods: sensitivity, insensitivity, implementation invariance, and linearity. With a focus on image data, the exhaustive experiments empirically show that the proposed methods outperform state-of-the-art black-box methods and achieve competitive performance compared to the ones with full access.
T2IAT: Measuring Valence and Stereotypical Biases in Text-to-Image Generation
Jun 01, 2023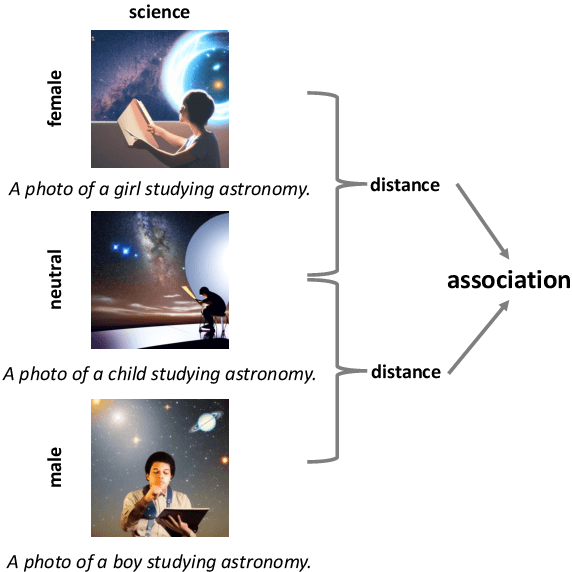


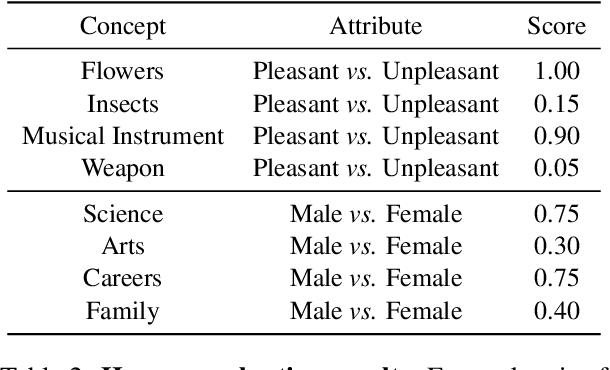
Warning: This paper contains several contents that may be toxic, harmful, or offensive. In the last few years, text-to-image generative models have gained remarkable success in generating images with unprecedented quality accompanied by a breakthrough of inference speed. Despite their rapid progress, human biases that manifest in the training examples, particularly with regard to common stereotypical biases, like gender and skin tone, still have been found in these generative models. In this work, we seek to measure more complex human biases exist in the task of text-to-image generations. Inspired by the well-known Implicit Association Test (IAT) from social psychology, we propose a novel Text-to-Image Association Test (T2IAT) framework that quantifies the implicit stereotypes between concepts and valence, and those in the images. We replicate the previously documented bias tests on generative models, including morally neutral tests on flowers and insects as well as demographic stereotypical tests on diverse social attributes. The results of these experiments demonstrate the presence of complex stereotypical behaviors in image generations.
Masked Diffusion as Self-supervised Representation Learner
Aug 10, 2023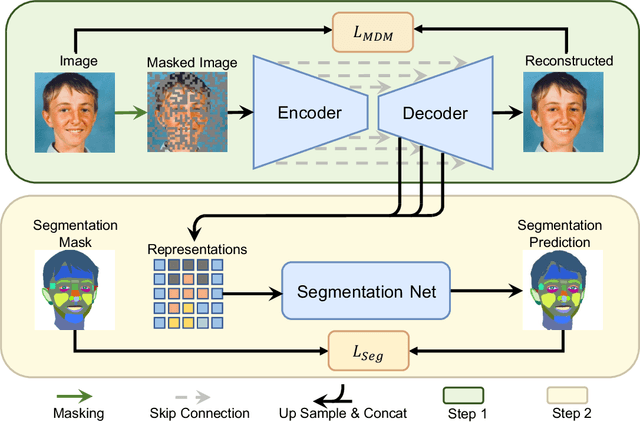
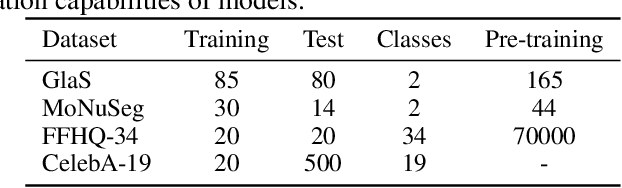
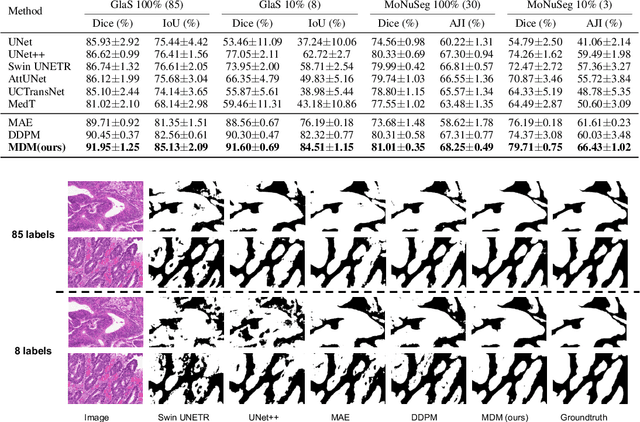

Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present masked diffusion model (MDM), a scalable self-supervised representation learner that substitutes the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly within the context of few-shot scenario.
More Context, Less Distraction: Visual Classification by Inferring and Conditioning on Contextual Attributes
Aug 02, 2023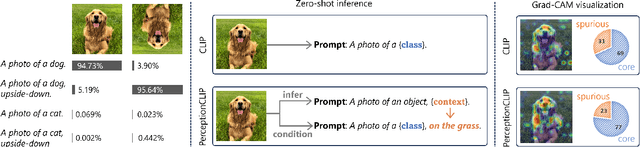

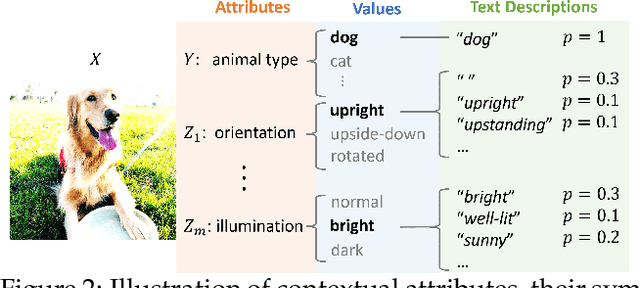
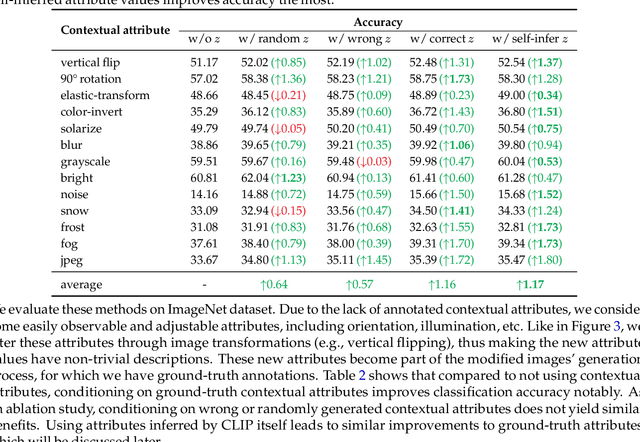
CLIP, as a foundational vision language model, is widely used in zero-shot image classification due to its ability to understand various visual concepts and natural language descriptions. However, how to fully leverage CLIP's unprecedented human-like understanding capabilities to achieve better zero-shot classification is still an open question. This paper draws inspiration from the human visual perception process: a modern neuroscience view suggests that in classifying an object, humans first infer its class-independent attributes (e.g., background and orientation) which help separate the foreground object from the background, and then make decisions based on this information. Inspired by this, we observe that providing CLIP with contextual attributes improves zero-shot classification and mitigates reliance on spurious features. We also observe that CLIP itself can reasonably infer the attributes from an image. With these observations, we propose a training-free, two-step zero-shot classification method named PerceptionCLIP. Given an image, it first infers contextual attributes (e.g., background) and then performs object classification conditioning on them. Our experiments show that PerceptionCLIP achieves better generalization, group robustness, and better interpretability. For example, PerceptionCLIP with ViT-L/14 improves the worst group accuracy by 16.5% on the Waterbirds dataset and by 3.5% on CelebA.
Towards Robust GAN-generated Image Detection: a Multi-view Completion Representation
Jun 02, 2023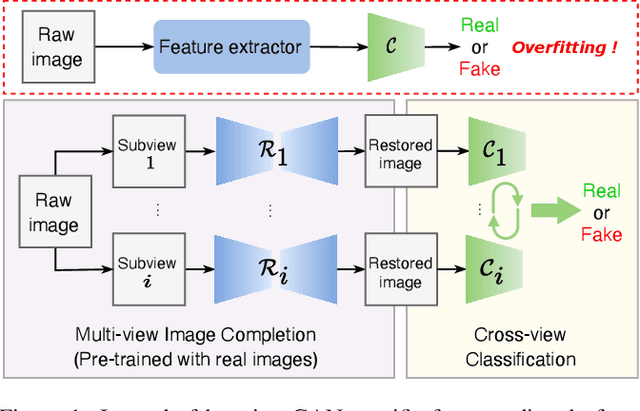

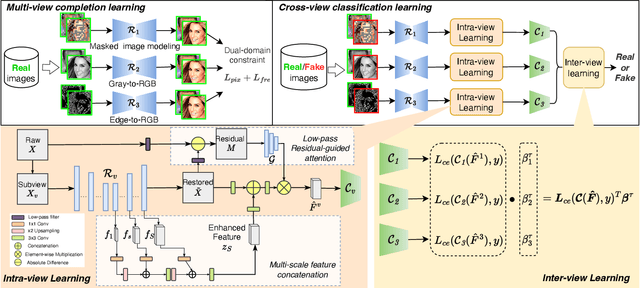
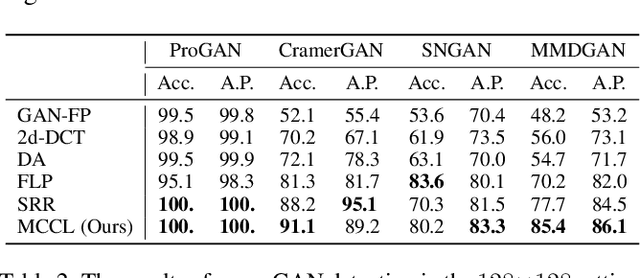
GAN-generated image detection now becomes the first line of defense against the malicious uses of machine-synthesized image manipulations such as deepfakes. Although some existing detectors work well in detecting clean, known GAN samples, their success is largely attributable to overfitting unstable features such as frequency artifacts, which will cause failures when facing unknown GANs or perturbation attacks. To overcome the issue, we propose a robust detection framework based on a novel multi-view image completion representation. The framework first learns various view-to-image tasks to model the diverse distributions of genuine images. Frequency-irrelevant features can be represented from the distributional discrepancies characterized by the completion models, which are stable, generalized, and robust for detecting unknown fake patterns. Then, a multi-view classification is devised with elaborated intra- and inter-view learning strategies to enhance view-specific feature representation and cross-view feature aggregation, respectively. We evaluated the generalization ability of our framework across six popular GANs at different resolutions and its robustness against a broad range of perturbation attacks. The results confirm our method's improved effectiveness, generalization, and robustness over various baselines.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 08, 2023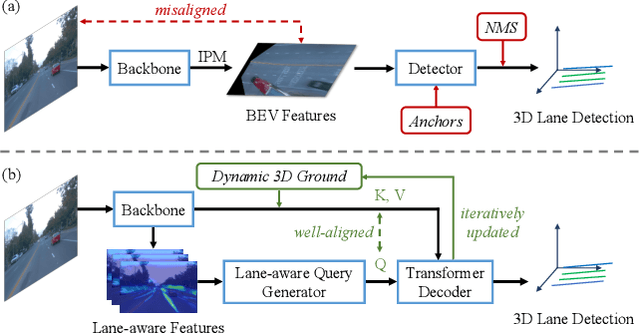
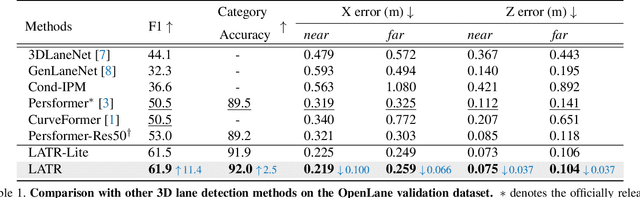
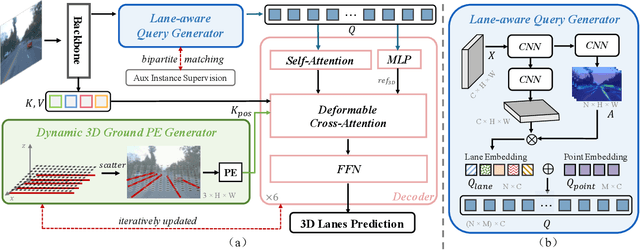
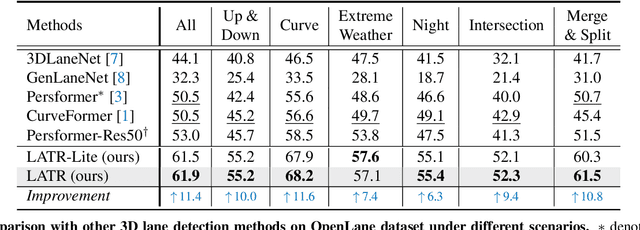
3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) that are built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance the lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo and realistic OpenLane by large margins (e.g., 11.4 gains in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR.
Diffusion Model for Camouflaged Object Detection
Aug 01, 2023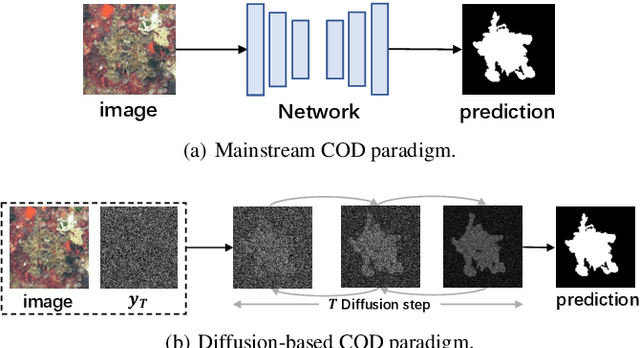
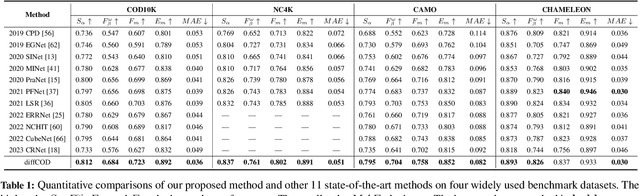
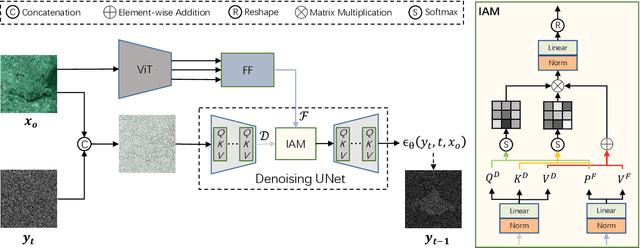
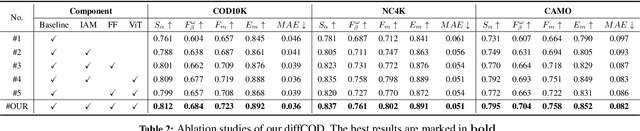
Camouflaged object detection is a challenging task that aims to identify objects that are highly similar to their background. Due to the powerful noise-to-image denoising capability of denoising diffusion models, in this paper, we propose a diffusion-based framework for camouflaged object detection, termed diffCOD, a new framework that considers the camouflaged object segmentation task as a denoising diffusion process from noisy masks to object masks. Specifically, the object mask diffuses from the ground-truth masks to a random distribution, and the designed model learns to reverse this noising process. To strengthen the denoising learning, the input image prior is encoded and integrated into the denoising diffusion model to guide the diffusion process. Furthermore, we design an injection attention module (IAM) to interact conditional semantic features extracted from the image with the diffusion noise embedding via the cross-attention mechanism to enhance denoising learning. Extensive experiments on four widely used COD benchmark datasets demonstrate that the proposed method achieves favorable performance compared to the existing 11 state-of-the-art methods, especially in the detailed texture segmentation of camouflaged objects. Our code will be made publicly available at: https://github.com/ZNan-Chen/diffCOD.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023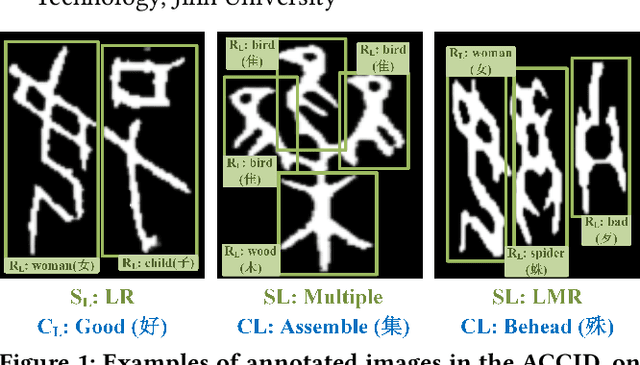
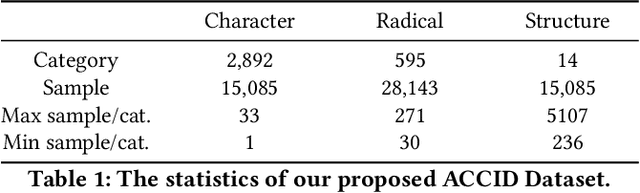
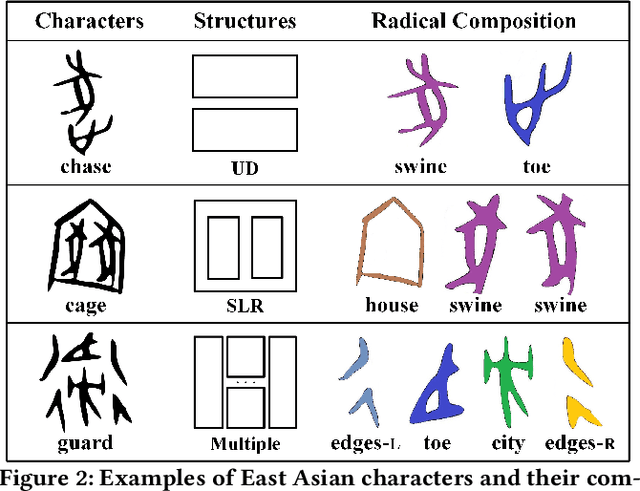

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
Improved mirror ball projection for more accurate merging of multiple camera outputs and process monitoring
Aug 15, 2023Using spherical mirrors in place of wide-angle cameras allows for cost-effective monitoring of manufacturing processes in hazardous environment, where a camera would normally not operate. This includes environments of high heat, vacuum and strong electromagnetic fields. Moreover, it allows the layering of multiple camera types (e.g., color image, near-infrared, long-wavelength infrared, ultraviolet) into a single wide-angle output, whilst accounting for the different camera placements and lenses used. Normally, the different camera positions introduce a parallax shift between the images, but with a spherical projection as produced by a spherical mirror, this parallax shift is reduced, depending on mirror size and distance to the monitoring target. This paper introduces a variation of the 'mirror ball projection', that accounts for distortion produced by a perspective camera at the pole of the projection. Finally, the efficacy of process monitoring via a mirror ball is evaluated.