 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning
Aug 14, 2023
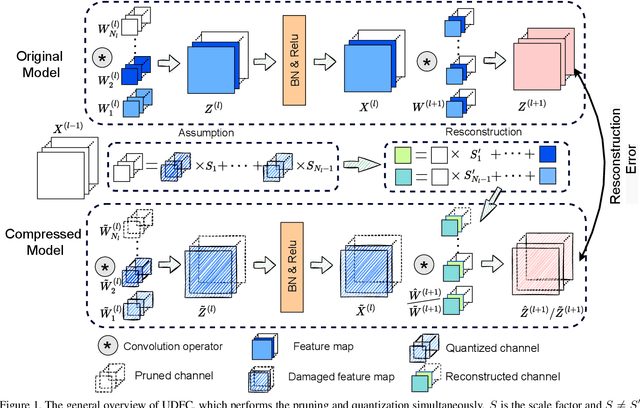
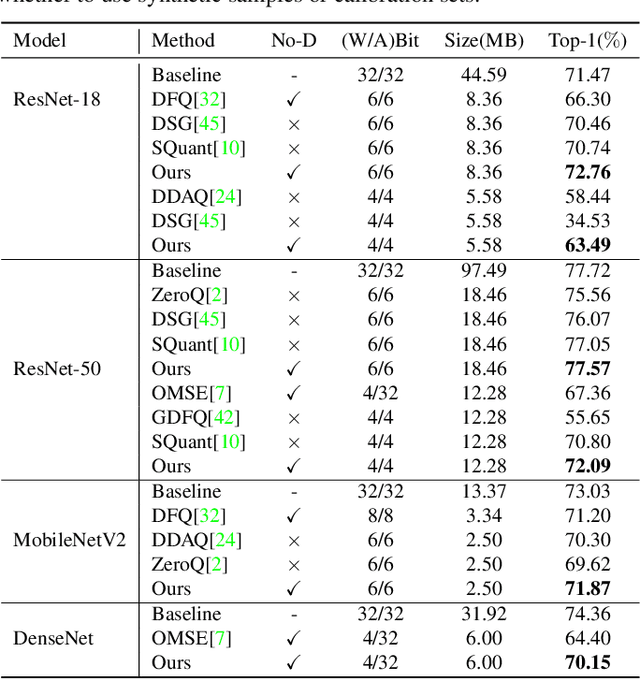
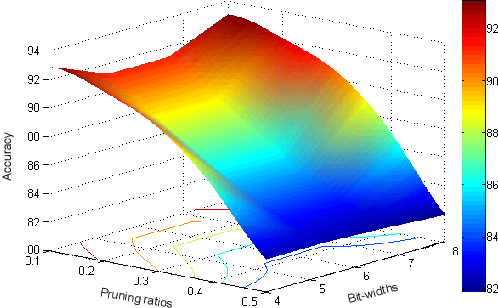
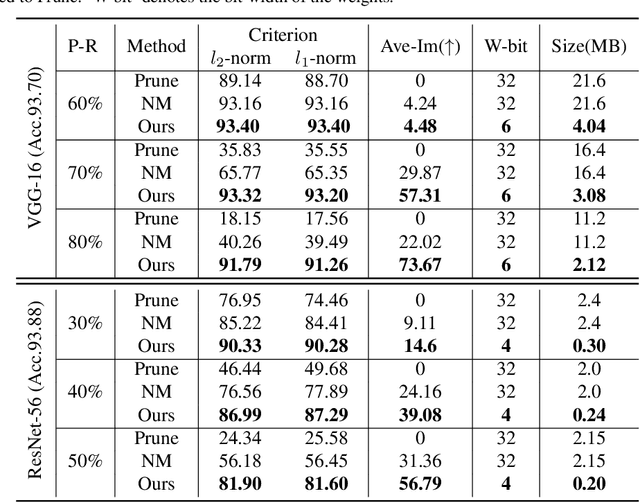
Structured pruning and quantization are promising approaches for reducing the inference time and memory footprint of neural networks. However, most existing methods require the original training dataset to fine-tune the model. This not only brings heavy resource consumption but also is not possible for applications with sensitive or proprietary data due to privacy and security concerns. Therefore, a few data-free methods are proposed to address this problem, but they perform data-free pruning and quantization separately, which does not explore the complementarity of pruning and quantization. In this paper, we propose a novel framework named Unified Data-Free Compression(UDFC), which performs pruning and quantization simultaneously without any data and fine-tuning process. Specifically, UDFC starts with the assumption that the partial information of a damaged(e.g., pruned or quantized) channel can be preserved by a linear combination of other channels, and then derives the reconstruction form from the assumption to restore the information loss due to compression. Finally, we formulate the reconstruction error between the original network and its compressed network, and theoretically deduce the closed-form solution. We evaluate the UDFC on the large-scale image classification task and obtain significant improvements over various network architectures and compression methods. For example, we achieve a 20.54% accuracy improvement on ImageNet dataset compared to SOTA method with 30% pruning ratio and 6-bit quantization on ResNet-34.
CTP: Towards Vision-Language Continual Pretraining via Compatible Momentum Contrast and Topology Preservation
Aug 14, 2023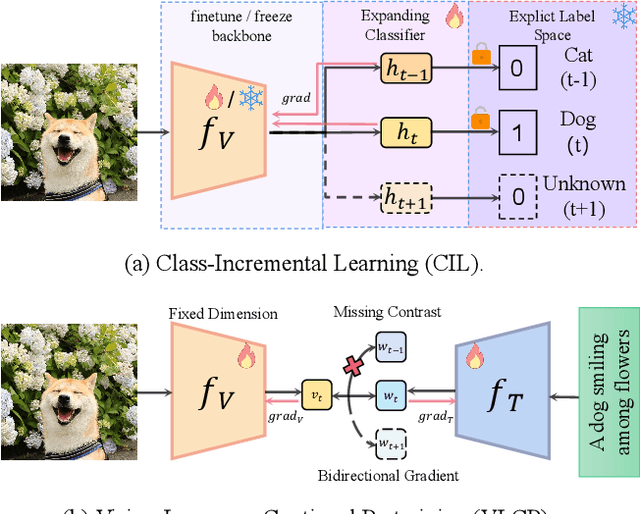
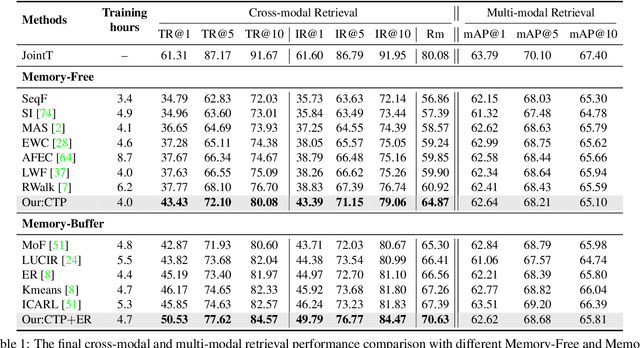
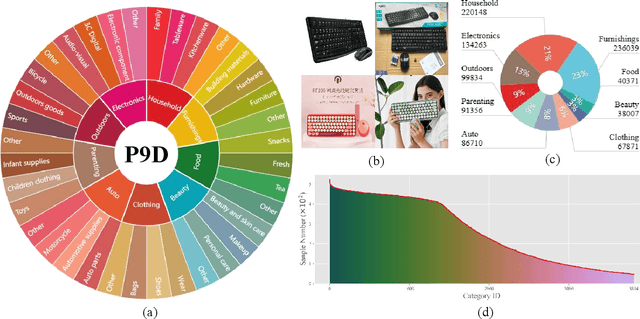
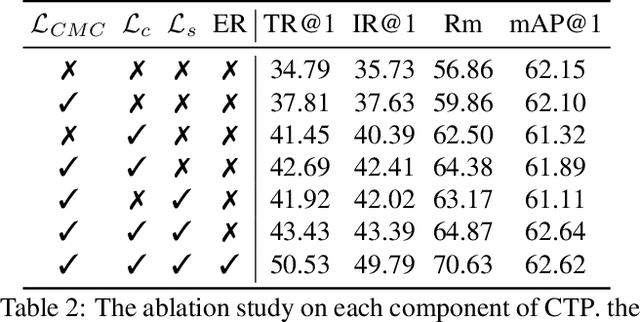
Vision-Language Pretraining (VLP) has shown impressive results on diverse downstream tasks by offline training on large-scale datasets. Regarding the growing nature of real-world data, such an offline training paradigm on ever-expanding data is unsustainable, because models lack the continual learning ability to accumulate knowledge constantly. However, most continual learning studies are limited to uni-modal classification and existing multi-modal datasets cannot simulate continual non-stationary data stream scenarios. To support the study of Vision-Language Continual Pretraining (VLCP), we first contribute a comprehensive and unified benchmark dataset P9D which contains over one million product image-text pairs from 9 industries. The data from each industry as an independent task supports continual learning and conforms to the real-world long-tail nature to simulate pretraining on web data. We comprehensively study the characteristics and challenges of VLCP, and propose a new algorithm: Compatible momentum contrast with Topology Preservation, dubbed CTP. The compatible momentum model absorbs the knowledge of the current and previous-task models to flexibly update the modal feature. Moreover, Topology Preservation transfers the knowledge of embedding across tasks while preserving the flexibility of feature adjustment. The experimental results demonstrate our method not only achieves superior performance compared with other baselines but also does not bring an expensive training burden. Dataset and codes are available at https://github.com/KevinLight831/CTP.
Downstream-agnostic Adversarial Examples
Aug 14, 2023
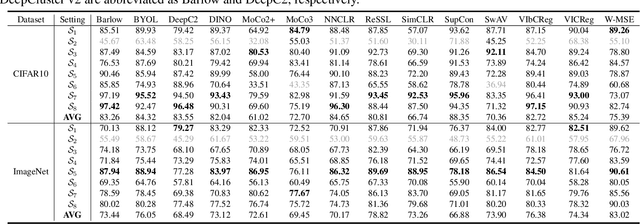
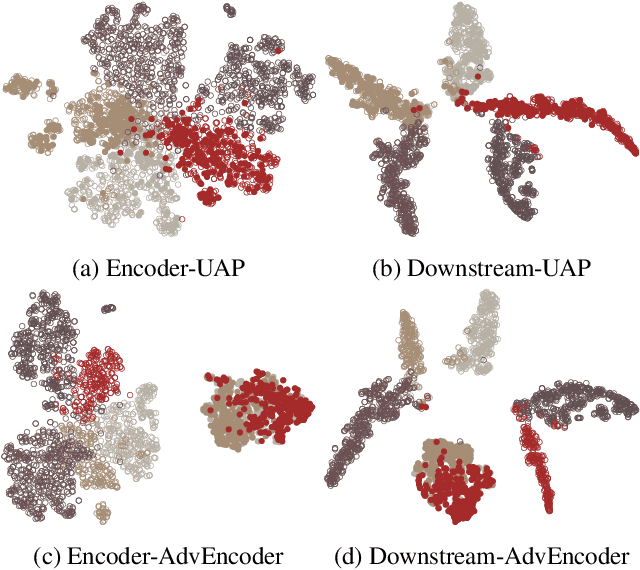
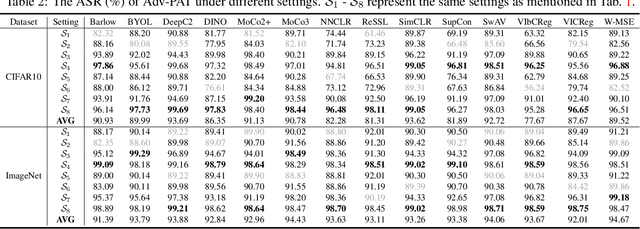
Self-supervised learning usually uses a large amount of unlabeled data to pre-train an encoder which can be used as a general-purpose feature extractor, such that downstream users only need to perform fine-tuning operations to enjoy the benefit of "large model". Despite this promising prospect, the security of pre-trained encoder has not been thoroughly investigated yet, especially when the pre-trained encoder is publicly available for commercial use. In this paper, we propose AdvEncoder, the first framework for generating downstream-agnostic universal adversarial examples based on the pre-trained encoder. AdvEncoder aims to construct a universal adversarial perturbation or patch for a set of natural images that can fool all the downstream tasks inheriting the victim pre-trained encoder. Unlike traditional adversarial example works, the pre-trained encoder only outputs feature vectors rather than classification labels. Therefore, we first exploit the high frequency component information of the image to guide the generation of adversarial examples. Then we design a generative attack framework to construct adversarial perturbations/patches by learning the distribution of the attack surrogate dataset to improve their attack success rates and transferability. Our results show that an attacker can successfully attack downstream tasks without knowing either the pre-training dataset or the downstream dataset. We also tailor four defenses for pre-trained encoders, the results of which further prove the attack ability of AdvEncoder.
U-Turn Diffusion
Aug 14, 2023We present a comprehensive examination of score-based diffusion models of AI for generating synthetic images. These models hinge upon a dynamic auxiliary time mechanism driven by stochastic differential equations, wherein the score function is acquired from input images. Our investigation unveils a criterion for evaluating efficiency of the score-based diffusion models: the power of the generative process depends on the ability to de-construct fast correlations during the reverse/de-noising phase. To improve the quality of the produced synthetic images, we introduce an approach coined "U-Turn Diffusion". The U-Turn Diffusion technique starts with the standard forward diffusion process, albeit with a condensed duration compared to conventional settings. Subsequently, we execute the standard reverse dynamics, initialized with the concluding configuration from the forward process. This U-Turn Diffusion procedure, combining forward, U-turn, and reverse processes, creates a synthetic image approximating an independent and identically distributed (i.i.d.) sample from the probability distribution implicitly described via input samples. To analyze relevant time scales we employ various analytical tools, including auto-correlation analysis, weighted norm of the score-function analysis, and Kolmogorov-Smirnov Gaussianity test. The tools guide us to establishing that the Kernel Intersection Distance, a metric comparing the quality of synthetic samples with real data samples, is minimized at the optimal U-turn time.
ConceptBed: Evaluating Concept Learning Abilities of Text-to-Image Diffusion Models
Jun 07, 2023The ability to understand visual concepts and replicate and compose these concepts from images is a central goal for computer vision. Recent advances in text-to-image (T2I) models have lead to high definition and realistic image quality generation by learning from large databases of images and their descriptions. However, the evaluation of T2I models has focused on photorealism and limited qualitative measures of visual understanding. To quantify the ability of T2I models in learning and synthesizing novel visual concepts, we introduce ConceptBed, a large-scale dataset that consists of 284 unique visual concepts, 5K unique concept compositions, and 33K composite text prompts. Along with the dataset, we propose an evaluation metric, Concept Confidence Deviation (CCD), that uses the confidence of oracle concept classifiers to measure the alignment between concepts generated by T2I generators and concepts contained in ground truth images. We evaluate visual concepts that are either objects, attributes, or styles, and also evaluate four dimensions of compositionality: counting, attributes, relations, and actions. Our human study shows that CCD is highly correlated with human understanding of concepts. Our results point to a trade-off between learning the concepts and preserving the compositionality which existing approaches struggle to overcome.
FunnyBirds: A Synthetic Vision Dataset for a Part-Based Analysis of Explainable AI Methods
Aug 11, 2023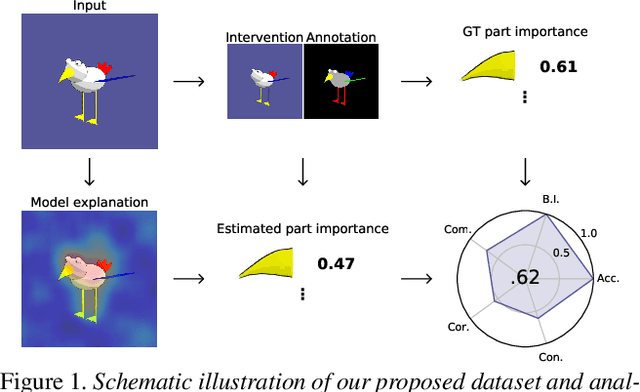

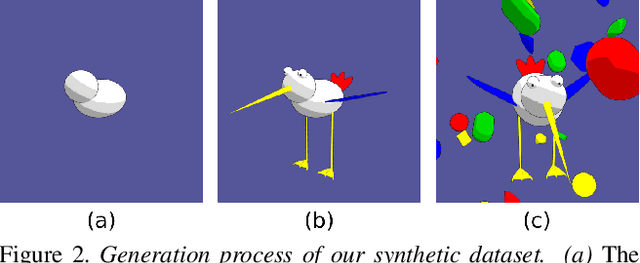
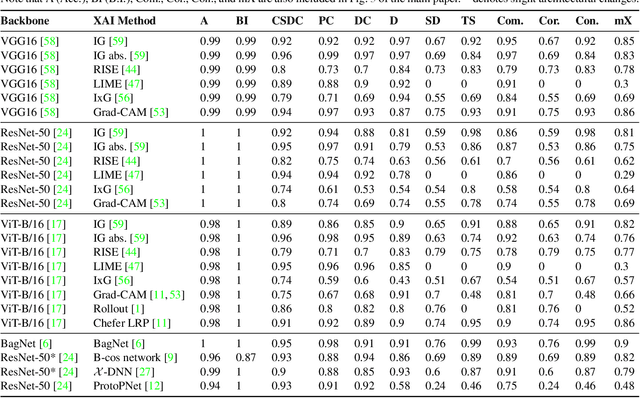
The field of explainable artificial intelligence (XAI) aims to uncover the inner workings of complex deep neural models. While being crucial for safety-critical domains, XAI inherently lacks ground-truth explanations, making its automatic evaluation an unsolved problem. We address this challenge by proposing a novel synthetic vision dataset, named FunnyBirds, and accompanying automatic evaluation protocols. Our dataset allows performing semantically meaningful image interventions, e.g., removing individual object parts, which has three important implications. First, it enables analyzing explanations on a part level, which is closer to human comprehension than existing methods that evaluate on a pixel level. Second, by comparing the model output for inputs with removed parts, we can estimate ground-truth part importances that should be reflected in the explanations. Third, by mapping individual explanations into a common space of part importances, we can analyze a variety of different explanation types in a single common framework. Using our tools, we report results for 24 different combinations of neural models and XAI methods, demonstrating the strengths and weaknesses of the assessed methods in a fully automatic and systematic manner.
Phase Diverse Phase Retrieval for Microscopy: Comparison of Gaussian and Poisson Approaches
Aug 01, 2023Phase diversity is a widefield aberration correction method that uses multiple images to estimate the phase aberration at the pupil plane of an imaging system by solving an optimization problem. This estimated aberration can then be used to deconvolve the aberrated image or to reacquire it with aberration corrections applied to a deformable mirror. The optimization problem for aberration estimation has been formulated for both Gaussian and Poisson noise models but the Poisson model has never been studied in microscopy nor compared with the Gaussian model. Here, the Gaussian- and Poisson-based estimation algorithms are implemented and compared for widefield microscopy in simulation. The Poisson algorithm is found to match or outperform the Gaussian algorithm in a variety of situations, and converges in a similar or decreased amount of time. The Gaussian algorithm does perform better in low-light regimes when image noise is dominated by additive Gaussian noise. The Poisson algorithm is also found to be more robust to the effects of spatially variant aberration and phase noise. Finally, the relative advantages of re-acquisition with aberration correction and deconvolution with aberrated point spread functions are compared.
Analysis of Adversarial Image Manipulations
May 10, 2023
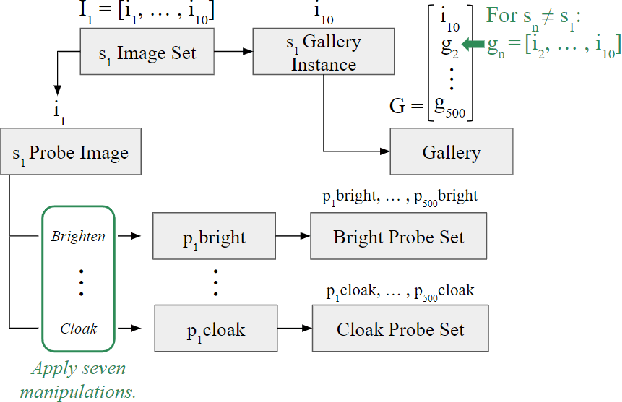
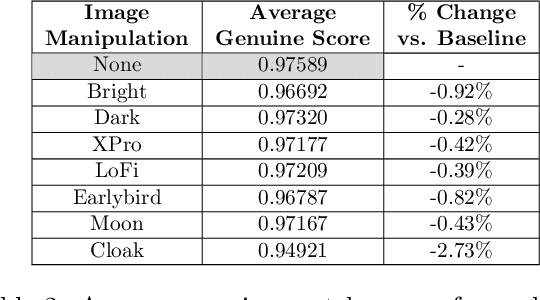
As virtual and physical identity grow increasingly intertwined, the importance of privacy and security in the online sphere becomes paramount. In recent years, multiple news stories have emerged of private companies scraping web content and doing research with or selling the data. Images uploaded online can be scraped without users' consent or knowledge. Users of social media platforms whose images are scraped may be at risk of being identified in other uploaded images or in real-world identification situations. This paper investigates how simple, accessible image manipulation techniques affect the accuracy of facial recognition software in identifying an individual's various face images based on one unique image.
HySpecNet-11k: A Large-Scale Hyperspectral Dataset for Benchmarking Learning-Based Hyperspectral Image Compression Methods
Jun 02, 2023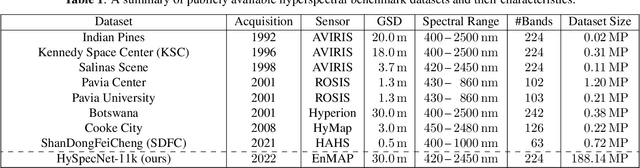

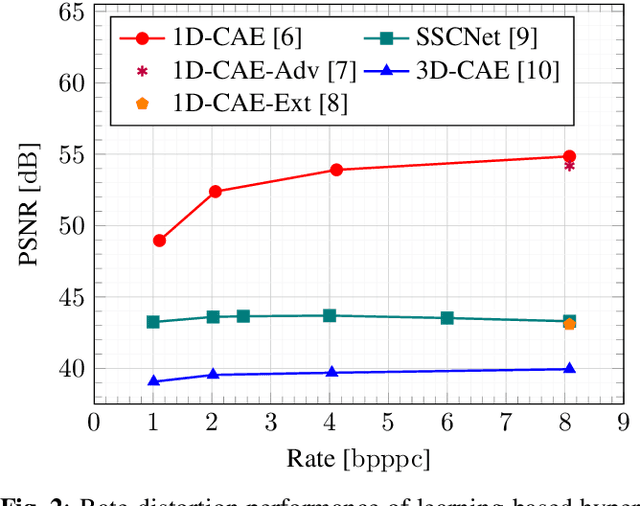
The development of learning-based hyperspectral image compression methods has recently attracted great attention in remote sensing. Such methods require a high number of hyperspectral images to be used during training to optimize all parameters and reach a high compression performance. However, existing hyperspectral datasets are not sufficient to train and evaluate learning-based compression methods, which hinders the research in this field. To address this problem, in this paper we present HySpecNet-11k that is a large-scale hyperspectral benchmark dataset made up of 11,483 nonoverlapping image patches. Each patch is a portion of 128 $\times$ 128 pixels with 224 spectral bands and a ground sample distance of 30 m. We exploit HySpecNet-11k to benchmark the current state of the art in learning-based hyperspectral image compression by focussing our attention on various 1D, 2D and 3D convolutional autoencoder architectures. Nevertheless, HySpecNet-11k can be used for any unsupervised learning task in the framework of hyperspectral image analysis. The dataset, our code and the pre-trained weights are publicly available at https://hyspecnet.rsim.berlin
PV-SSD: A Projection and Voxel-based Double Branch Single-Stage 3D Object Detector
Aug 13, 2023
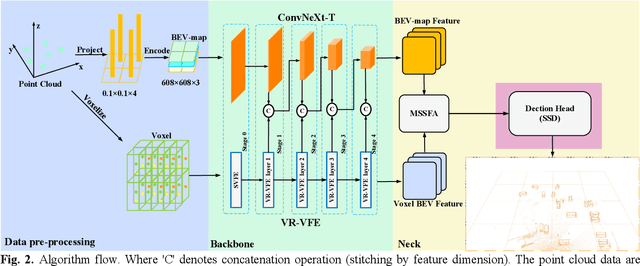
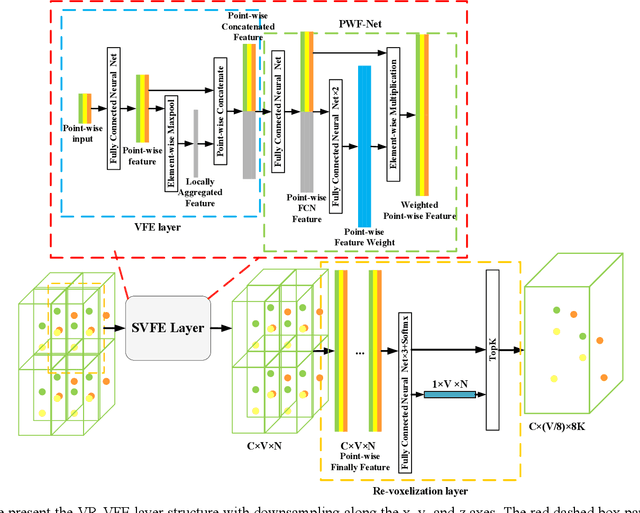
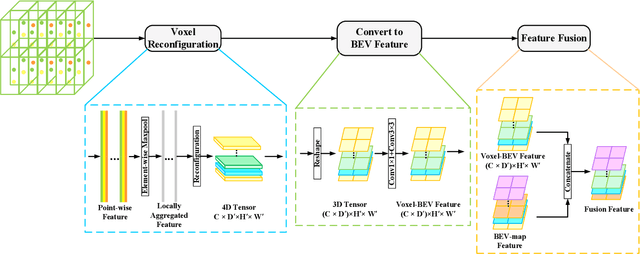
LIDAR-based 3D object detection and classification is crucial for autonomous driving. However, inference in real-time from extremely sparse 3D data poses a formidable challenge. To address this issue, a common approach is to project point clouds onto a bird's-eye or perspective view, effectively converting them into an image-like data format. However, this excessive compression of point cloud data often leads to the loss of information. This paper proposes a 3D object detector based on voxel and projection double branch feature extraction (PV-SSD) to address the problem of information loss. We add voxel features input containing rich local semantic information, which is fully fused with the projected features in the feature extraction stage to reduce the local information loss caused by projection. A good performance is achieved compared to the previous work. In addition, this paper makes the following contributions: 1) a voxel feature extraction method with variable receptive fields is proposed; 2) a feature point sampling method by weight sampling is used to filter out the feature points that are more conducive to the detection task; 3) the MSSFA module is proposed based on the SSFA module. To verify the effectiveness of our method, we designed comparison experiments.