 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On-Manifold Projected Gradient Descent
Aug 23, 2023
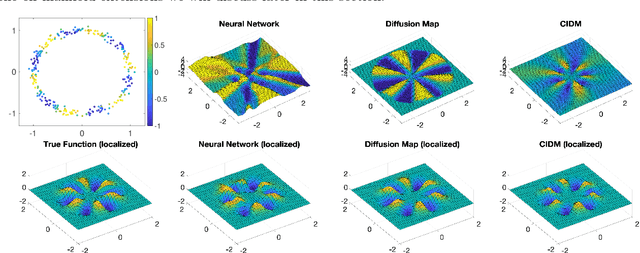
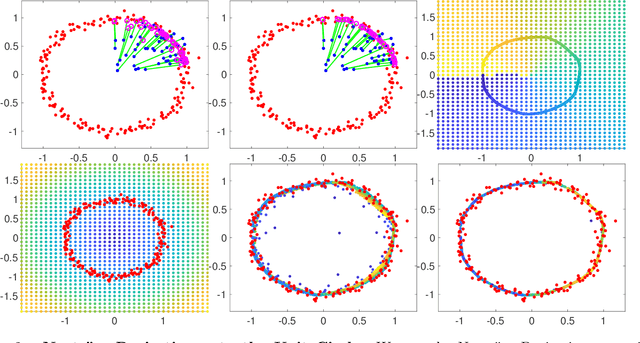
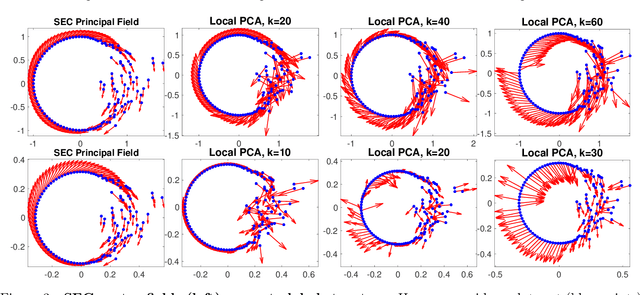
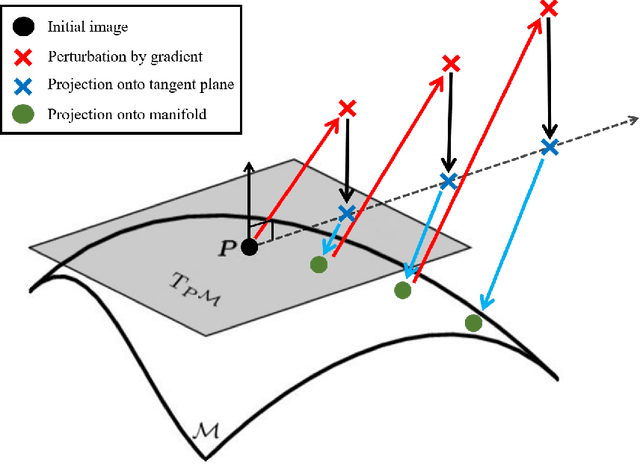
This work provides a computable, direct, and mathematically rigorous approximation to the differential geometry of class manifolds for high-dimensional data, along with nonlinear projections from input space onto these class manifolds. The tools are applied to the setting of neural network image classifiers, where we generate novel, on-manifold data samples, and implement a projected gradient descent algorithm for on-manifold adversarial training. The susceptibility of neural networks (NNs) to adversarial attack highlights the brittle nature of NN decision boundaries in input space. Introducing adversarial examples during training has been shown to reduce the susceptibility of NNs to adversarial attack; however, it has also been shown to reduce the accuracy of the classifier if the examples are not valid examples for that class. Realistic "on-manifold" examples have been previously generated from class manifolds in the latent of an autoencoder. Our work explores these phenomena in a geometric and computational setting that is much closer to the raw, high-dimensional input space than can be provided by VAE or other black box dimensionality reductions. We employ conformally invariant diffusion maps (CIDM) to approximate class manifolds in diffusion coordinates, and develop the Nystr\"{o}m projection to project novel points onto class manifolds in this setting. On top of the manifold approximation, we leverage the spectral exterior calculus (SEC) to determine geometric quantities such as tangent vectors of the manifold. We use these tools to obtain adversarial examples that reside on a class manifold, yet fool a classifier. These misclassifications then become explainable in terms of human-understandable manipulations within the data, by expressing the on-manifold adversary in the semantic basis on the manifold.
High-Fidelity Image Compression with Score-based Generative Models
May 26, 2023
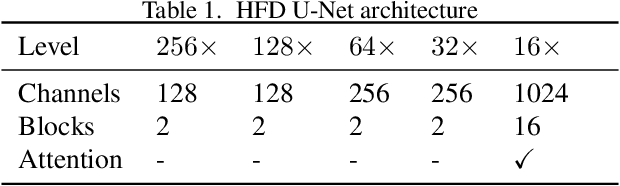


Despite the tremendous success of diffusion generative models in text-to-image generation, replicating this success in the domain of image compression has proven difficult. In this paper, we demonstrate that diffusion can significantly improve perceptual quality at a given bit-rate, outperforming state-of-the-art approaches PO-ELIC and HiFiC as measured by FID score. This is achieved using a simple but theoretically motivated two-stage approach combining an autoencoder targeting MSE followed by a further score-based decoder. However, as we will show, implementation details matter and the optimal design decisions can differ greatly from typical text-to-image models.
A Novel Cross-Perturbation for Single Domain Generalization
Aug 02, 2023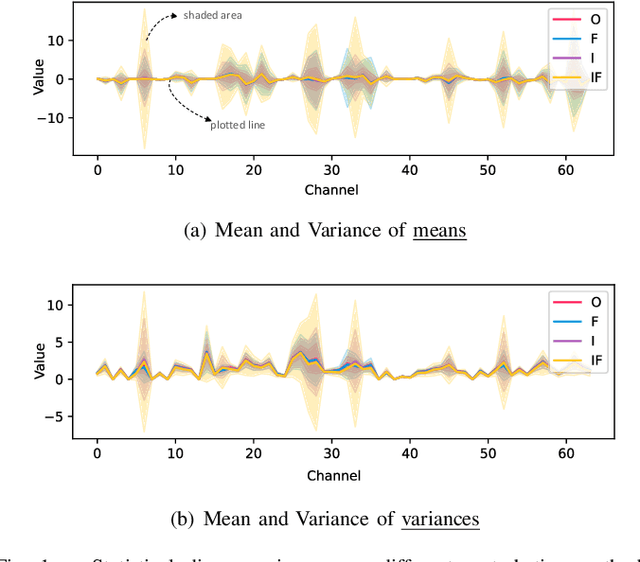
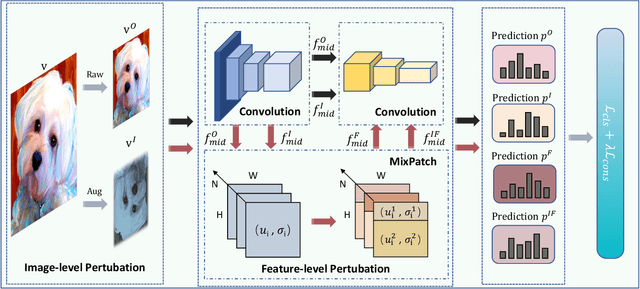
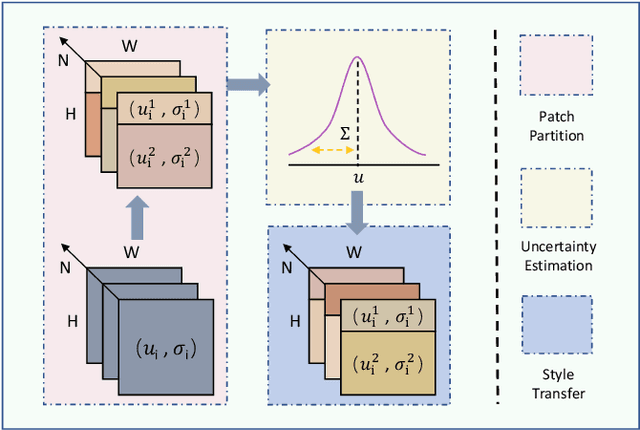

Single domain generalization aims to enhance the ability of the model to generalize to unknown domains when trained on a single source domain. However, the limited diversity in the training data hampers the learning of domain-invariant features, resulting in compromised generalization performance. To address this, data perturbation (augmentation) has emerged as a crucial method to increase data diversity. Nevertheless, existing perturbation methods often focus on either image-level or feature-level perturbations independently, neglecting their synergistic effects. To overcome these limitations, we propose CPerb, a simple yet effective cross-perturbation method. Specifically, CPerb utilizes both horizontal and vertical operations. Horizontally, it applies image-level and feature-level perturbations to enhance the diversity of the training data, mitigating the issue of limited diversity in single-source domains. Vertically, it introduces multi-route perturbation to learn domain-invariant features from different perspectives of samples with the same semantic category, thereby enhancing the generalization capability of the model. Additionally, we propose MixPatch, a novel feature-level perturbation method that exploits local image style information to further diversify the training data. Extensive experiments on various benchmark datasets validate the effectiveness of our method.
Cross-Modal Concept Learning and Inference for Vision-Language Models
Jul 28, 2023Large-scale pre-trained Vision-Language Models (VLMs), such as CLIP, establish the correlation between texts and images, achieving remarkable success on various downstream tasks with fine-tuning. In existing fine-tuning methods, the class-specific text description is matched against the whole image. We recognize that this whole image matching is not effective since images from the same class often contain a set of different semantic objects, and an object further consists of a set of semantic parts or concepts. Individual semantic parts or concepts may appear in image samples from different classes. To address this issue, in this paper, we develop a new method called cross-model concept learning and inference (CCLI). Using the powerful text-image correlation capability of CLIP, our method automatically learns a large set of distinctive visual concepts from images using a set of semantic text concepts. Based on these visual concepts, we construct a discriminative representation of images and learn a concept inference network to perform downstream image classification tasks, such as few-shot learning and domain generalization. Extensive experimental results demonstrate that our CCLI method is able to improve the performance upon the current state-of-the-art methods by large margins, for example, by up to 8.0% improvement on few-shot learning and by up to 1.3% for domain generalization.
Seeing Behind Dynamic Occlusions with Event Cameras
Aug 01, 2023
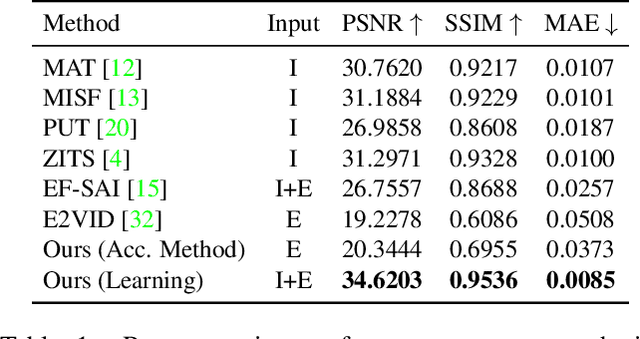
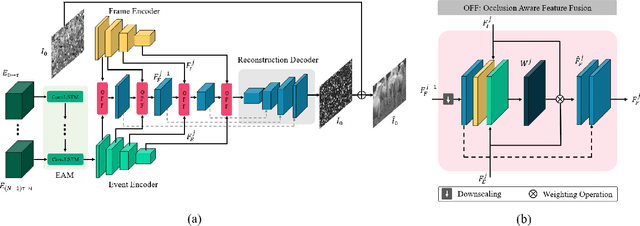
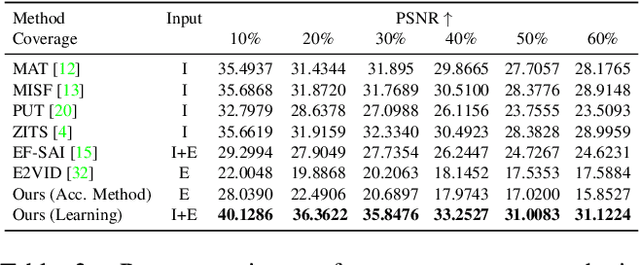
Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We present the first large-scale dataset consisting of synchronized images and event sequences to evaluate our approach. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
HSR-Diff:Hyperspectral Image Super-Resolution via Conditional Diffusion Models
Jun 21, 2023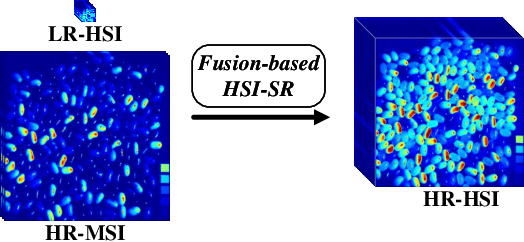
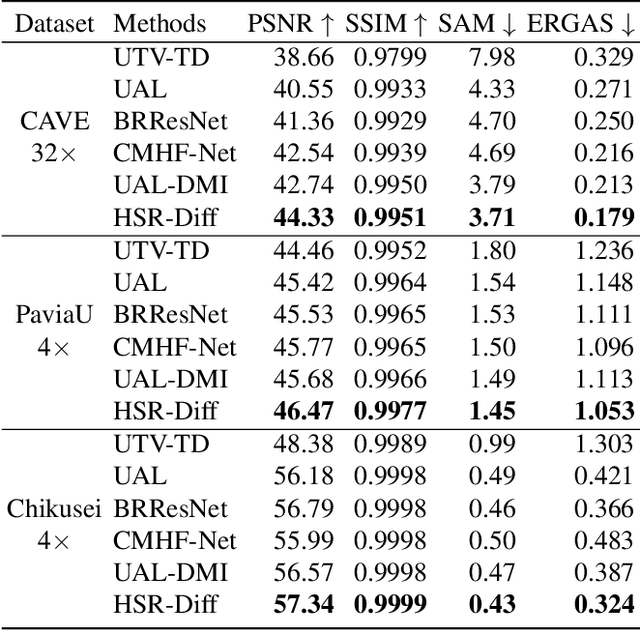
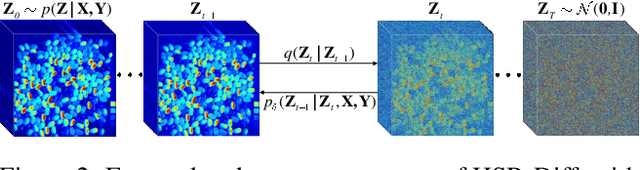
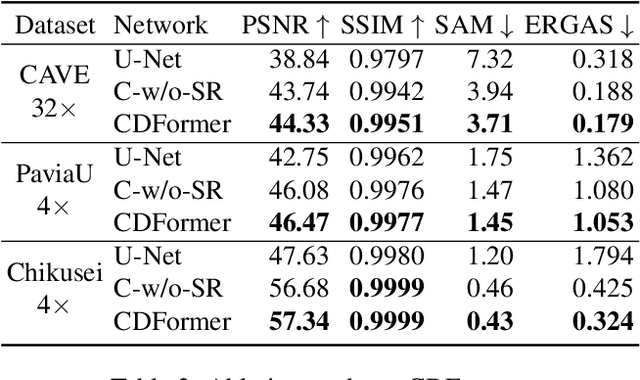
Despite the proven significance of hyperspectral images (HSIs) in performing various computer vision tasks, its potential is adversely affected by the low-resolution (LR) property in the spatial domain, resulting from multiple physical factors. Inspired by recent advancements in deep generative models, we propose an HSI Super-resolution (SR) approach with Conditional Diffusion Models (HSR-Diff) that merges a high-resolution (HR) multispectral image (MSI) with the corresponding LR-HSI. HSR-Diff generates an HR-HSI via repeated refinement, in which the HR-HSI is initialized with pure Gaussian noise and iteratively refined. At each iteration, the noise is removed with a Conditional Denoising Transformer (CDF ormer) that is trained on denoising at different noise levels, conditioned on the hierarchical feature maps of HR-MSI and LR-HSI. In addition, a progressive learning strategy is employed to exploit the global information of full-resolution images. Systematic experiments have been conducted on four public datasets, demonstrating that HSR-Diff outperforms state-of-the-art methods.
Relieving Triplet Ambiguity: Consensus Network for Language-Guided Image Retrieval
Jun 03, 2023
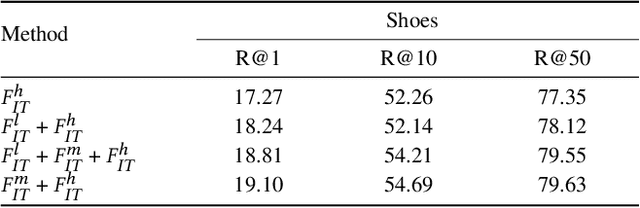
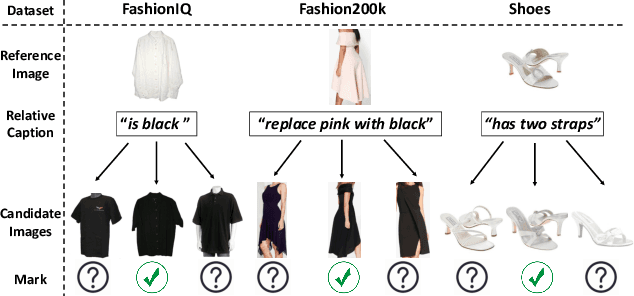

Language-guided image retrieval enables users to search for images and interact with the retrieval system more naturally and expressively by using a reference image and a relative caption as a query. Most existing studies mainly focus on designing image-text composition architecture to extract discriminative visual-linguistic relations. Despite great success, we identify an inherent problem that obstructs the extraction of discriminative features and considerably compromises model training: \textbf{triplet ambiguity}. This problem stems from the annotation process wherein annotators view only one triplet at a time. As a result, they often describe simple attributes, such as color, while neglecting fine-grained details like location and style. This leads to multiple false-negative candidates matching the same modification text. We propose a novel Consensus Network (Css-Net) that self-adaptively learns from noisy triplets to minimize the negative effects of triplet ambiguity. Inspired by the psychological finding that groups perform better than individuals, Css-Net comprises 1) a consensus module featuring four distinct compositors that generate diverse fused image-text embeddings and 2) a Kullback-Leibler divergence loss, which fosters learning among the compositors, enabling them to reduce biases learned from noisy triplets and reach a consensus. The decisions from four compositors are weighted during evaluation to further achieve consensus. Comprehensive experiments on three datasets demonstrate that Css-Net can alleviate triplet ambiguity, achieving competitive performance on benchmarks, such as $+2.77\%$ R@10 and $+6.67\%$ R@50 on FashionIQ.
Modality-Agnostic Learning for Medical Image Segmentation Using Multi-modality Self-distillation
Jun 06, 2023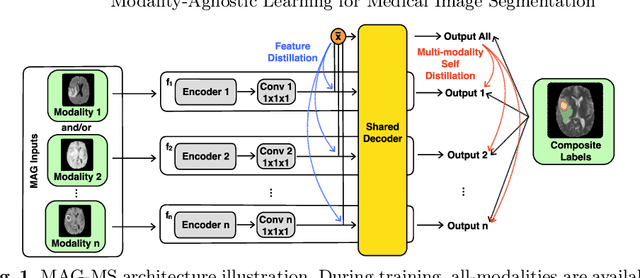
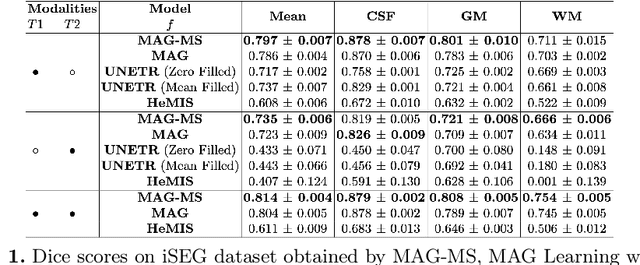
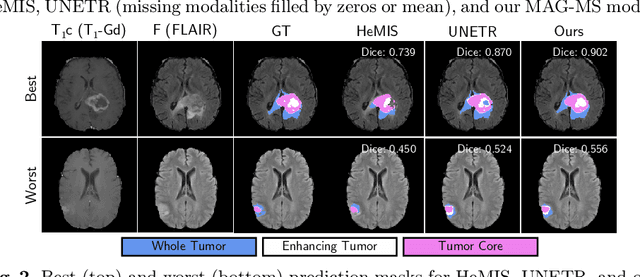
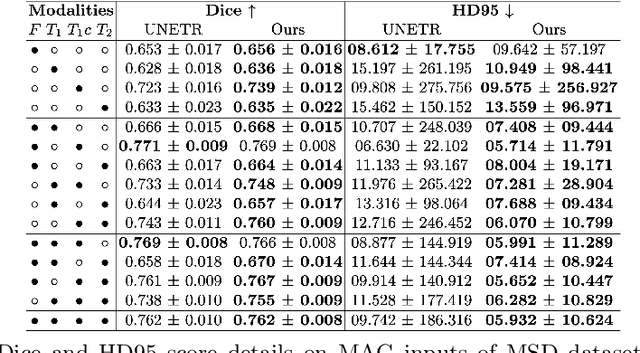
Medical image segmentation of tumors and organs at risk is a time-consuming yet critical process in the clinic that utilizes multi-modality imaging (e.g, different acquisitions, data types, and sequences) to increase segmentation precision. In this paper, we propose a novel framework, Modality-Agnostic learning through Multi-modality Self-dist-illation (MAG-MS), to investigate the impact of input modalities on medical image segmentation. MAG-MS distills knowledge from the fusion of multiple modalities and applies it to enhance representation learning for individual modalities. Thus, it provides a versatile and efficient approach to handle limited modalities during testing. Our extensive experiments on benchmark datasets demonstrate the high efficiency of MAG-MS and its superior segmentation performance than current state-of-the-art methods. Furthermore, using MAG-MS, we provide valuable insight and guidance on selecting input modalities for medical image segmentation tasks.
User-friendly Image Editing with Minimal Text Input: Leveraging Captioning and Injection Techniques
Jun 05, 2023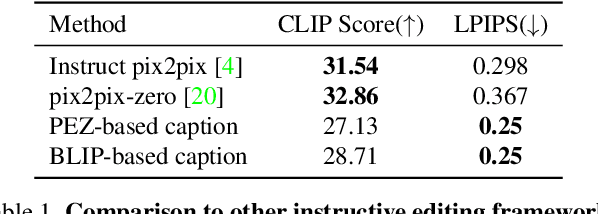


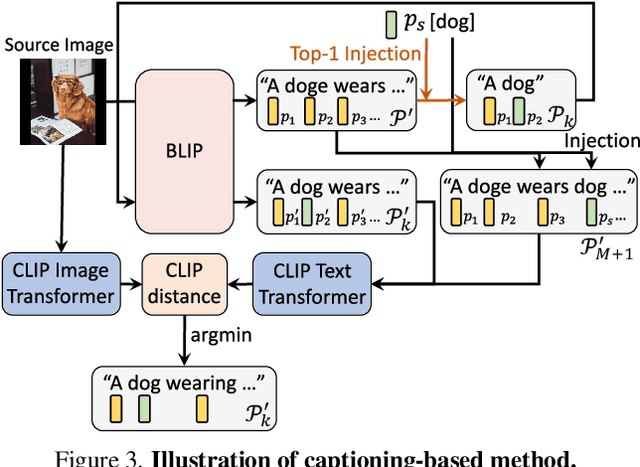
Recent text-driven image editing in diffusion models has shown remarkable success. However, the existing methods assume that the user's description sufficiently grounds the contexts in the source image, such as objects, background, style, and their relations. This assumption is unsuitable for real-world applications because users have to manually engineer text prompts to find optimal descriptions for different images. From the users' standpoint, prompt engineering is a labor-intensive process, and users prefer to provide a target word for editing instead of a full sentence. To address this problem, we first demonstrate the importance of a detailed text description of the source image, by dividing prompts into three categories based on the level of semantic details. Then, we propose simple yet effective methods by combining prompt generation frameworks, thereby making the prompt engineering process more user-friendly. Extensive qualitative and quantitative experiments demonstrate the importance of prompts in text-driven image editing and our method is comparable to ground-truth prompts.
Augmenting CLIP with Improved Visio-Linguistic Reasoning
Jul 27, 2023
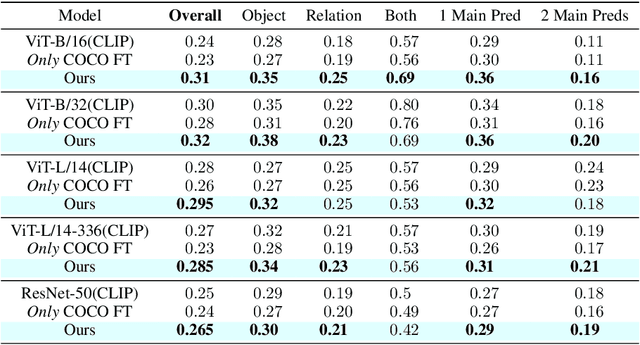
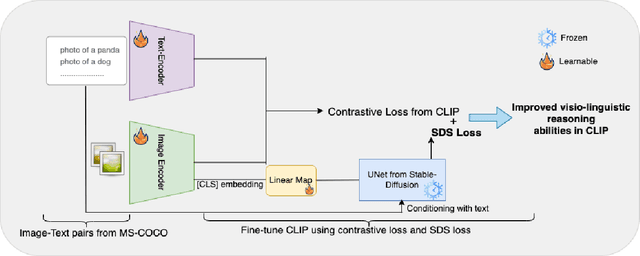
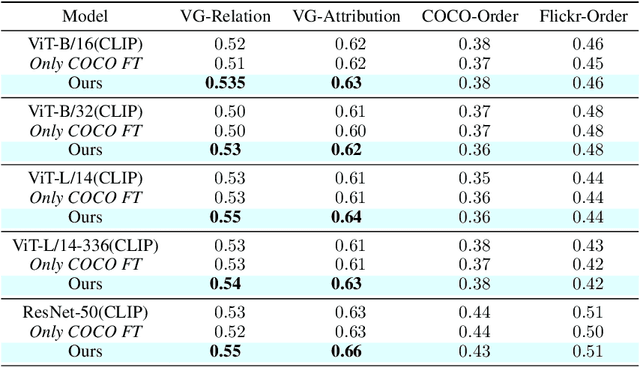
Image-text contrastive models such as CLIP are useful for a variety of downstream applications including zero-shot classification, image-text retrieval and transfer learning. However, these contrastively trained vision-language models often fail on compositional visio-linguistic tasks such as Winoground with performance equivalent to random chance. In our paper, we address this issue and propose a sample-efficient light-weight method called SDS-CLIP to improve the compositional visio-linguistic reasoning capabilities of CLIP. The core idea of our method is to use differentiable image parameterizations to fine-tune CLIP with a distillation objective from large text-to-image generative models such as Stable-Diffusion which are relatively good at visio-linguistic reasoning tasks. On the challenging Winoground compositional reasoning benchmark, our method improves the absolute visio-linguistic performance of different CLIP models by up to 7%, while on the ARO dataset, our method improves the visio-linguistic performance by upto 3%. As a byproduct of inducing visio-linguistic reasoning into CLIP, we also find that the zero-shot performance improves marginally on a variety of downstream datasets. Our method reinforces that carefully designed distillation objectives from generative models can be leveraged to extend existing contrastive image-text models with improved visio-linguistic reasoning capabilities.