 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VLM-CPL: Consensus Pseudo Labels from Vision-Language Models for Human Annotation-Free Pathological Image Classification
Mar 23, 2024
Despite that deep learning methods have achieved remarkable performance in pathology image classification, they heavily rely on labeled data, demanding extensive human annotation efforts. In this study, we present a novel human annotation-free method for pathology image classification by leveraging pre-trained Vision-Language Models (VLMs). Without human annotation, pseudo labels of the training set are obtained by utilizing the zero-shot inference capabilities of VLM, which may contain a lot of noise due to the domain shift between the pre-training data and the target dataset. To address this issue, we introduce VLM-CPL, a novel approach based on consensus pseudo labels that integrates two noisy label filtering techniques with a semi-supervised learning strategy. Specifically, we first obtain prompt-based pseudo labels with uncertainty estimation by zero-shot inference with the VLM using multiple augmented views of an input. Then, by leveraging the feature representation ability of VLM, we obtain feature-based pseudo labels via sample clustering in the feature space. Prompt-feature consensus is introduced to select reliable samples based on the consensus between the two types of pseudo labels. By rejecting low-quality pseudo labels, we further propose High-confidence Cross Supervision (HCS) to learn from samples with reliable pseudo labels and the remaining unlabeled samples. Experimental results showed that our method obtained an accuracy of 87.1% and 95.1% on the HPH and LC25K datasets, respectively, and it largely outperformed existing zero-shot classification and noisy label learning methods. The code is available at https://github.com/lanfz2000/VLM-CPL.
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Mar 28, 2024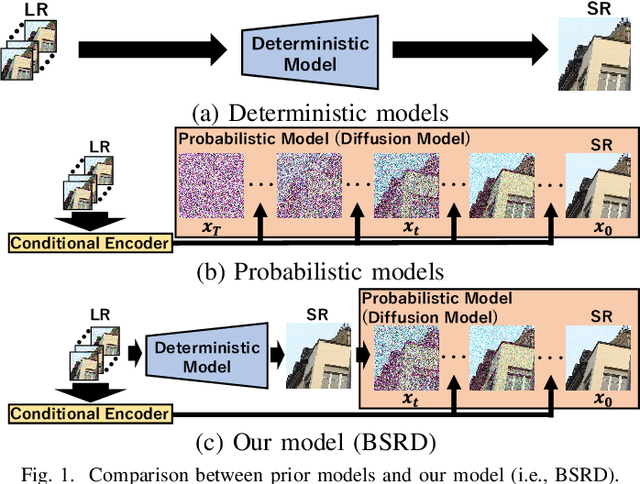
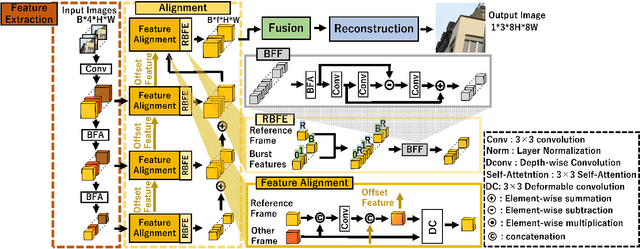
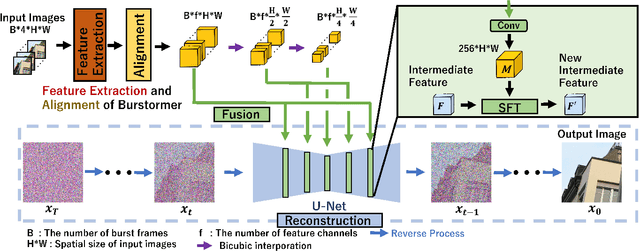
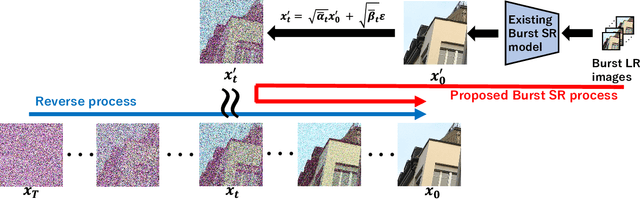
While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD
Low-Trace Adaptation of Zero-shot Self-supervised Blind Image Denoising
Mar 19, 2024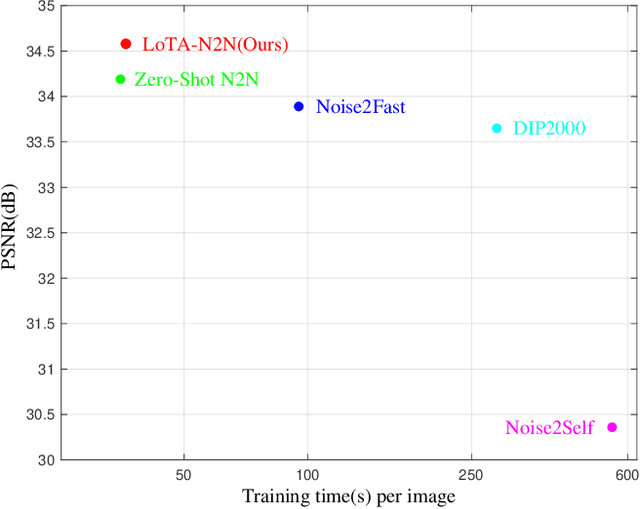
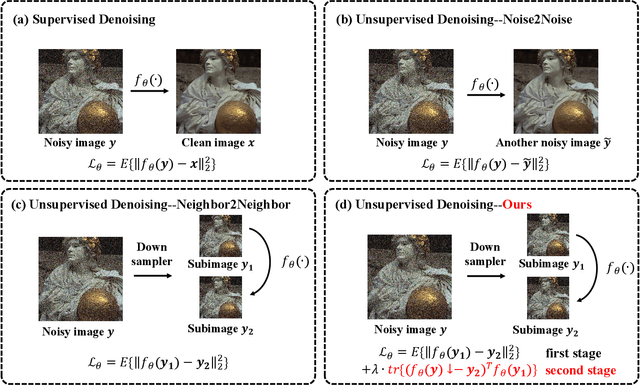
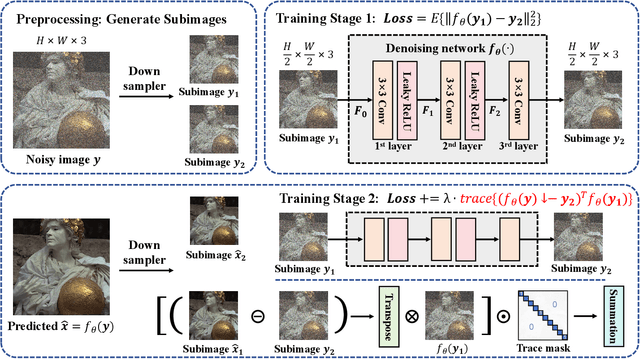

Deep learning-based denoiser has been the focus of recent development on image denoising. In the past few years, there has been increasing interest in developing self-supervised denoising networks that only require noisy images, without the need for clean ground truth for training. However, a performance gap remains between current self-supervised methods and their supervised counterparts. Additionally, these methods commonly depend on assumptions about noise characteristics, thereby constraining their applicability in real-world scenarios. Inspired by the properties of the Frobenius norm expansion, we discover that incorporating a trace term reduces the optimization goal disparity between self-supervised and supervised methods, thereby enhancing the performance of self-supervised learning. To exploit this insight, we propose a trace-constraint loss function and design the low-trace adaptation Noise2Noise (LoTA-N2N) model that bridges the gap between self-supervised and supervised learning. Furthermore, we have discovered that several existing self-supervised denoising frameworks naturally fall within the proposed trace-constraint loss as subcases. Extensive experiments conducted on natural and confocal image datasets indicate that our method achieves state-of-the-art performance within the realm of zero-shot self-supervised image denoising approaches, without relying on any assumptions regarding the noise.
HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach
Apr 01, 2024Our paper addresses the complex task of transferring a hairstyle from a reference image to an input photo for virtual hair try-on. This task is challenging due to the need to adapt to various photo poses, the sensitivity of hairstyles, and the lack of objective metrics. The current state of the art hairstyle transfer methods use an optimization process for different parts of the approach, making them inexcusably slow. At the same time, faster encoder-based models are of very low quality because they either operate in StyleGAN's W+ space or use other low-dimensional image generators. Additionally, both approaches have a problem with hairstyle transfer when the source pose is very different from the target pose, because they either don't consider the pose at all or deal with it inefficiently. In our paper, we present the HairFast model, which uniquely solves these problems and achieves high resolution, near real-time performance, and superior reconstruction compared to optimization problem-based methods. Our solution includes a new architecture operating in the FS latent space of StyleGAN, an enhanced inpainting approach, and improved encoders for better alignment, color transfer, and a new encoder for post-processing. The effectiveness of our approach is demonstrated on realism metrics after random hairstyle transfer and reconstruction when the original hairstyle is transferred. In the most difficult scenario of transferring both shape and color of a hairstyle from different images, our method performs in less than a second on the Nvidia V100. Our code is available at https://github.com/AIRI-Institute/HairFastGAN.
Adversarial Attacks and Dimensionality in Text Classifiers
Apr 03, 2024Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
Ultraman: Single Image 3D Human Reconstruction with Ultra Speed and Detail
Mar 18, 2024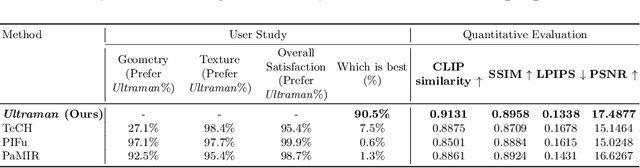
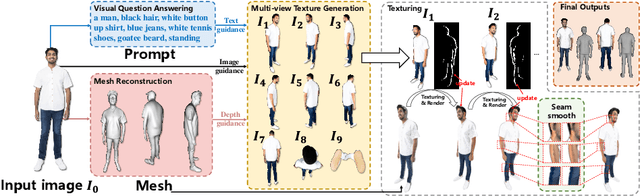
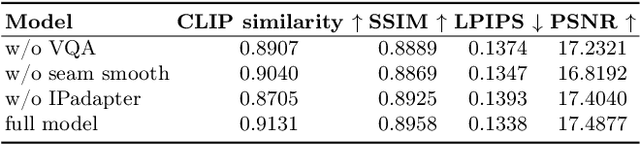
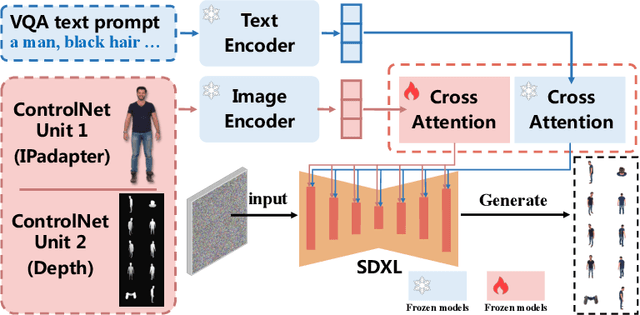
3D human body reconstruction has been a challenge in the field of computer vision. Previous methods are often time-consuming and difficult to capture the detailed appearance of the human body. In this paper, we propose a new method called \emph{Ultraman} for fast reconstruction of textured 3D human models from a single image. Compared to existing techniques, \emph{Ultraman} greatly improves the reconstruction speed and accuracy while preserving high-quality texture details. We present a set of new frameworks for human reconstruction consisting of three parts, geometric reconstruction, texture generation and texture mapping. Firstly, a mesh reconstruction framework is used, which accurately extracts 3D human shapes from a single image. At the same time, we propose a method to generate a multi-view consistent image of the human body based on a single image. This is finally combined with a novel texture mapping method to optimize texture details and ensure color consistency during reconstruction. Through extensive experiments and evaluations, we demonstrate the superior performance of \emph{Ultraman} on various standard datasets. In addition, \emph{Ultraman} outperforms state-of-the-art methods in terms of human rendering quality and speed. Upon acceptance of the article, we will make the code and data publicly available.
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024
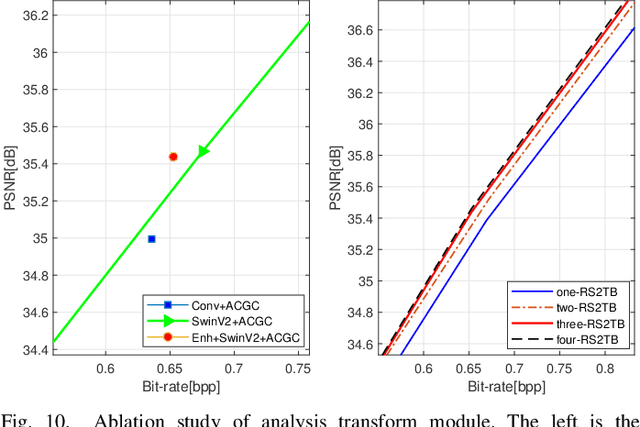


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
IsoBench: Benchmarking Multimodal Foundation Models on Isomorphic Representations
Apr 02, 2024Current foundation models exhibit impressive capabilities when prompted either with text only or with both image and text inputs. But do their capabilities change depending on the input modality? In this work, we propose $\textbf{IsoBench}$, a benchmark dataset containing problems from four major areas: math, science, algorithms, and games. Each example is presented with multiple $\textbf{isomorphic representations}$ of inputs, such as visual, textual, and mathematical presentations. IsoBench provides fine-grained feedback to diagnose performance gaps caused by the form of the representation. Across various foundation models, we observe that on the same problem, models have a consistent preference towards textual representations. Most prominently, when evaluated on all IsoBench problems, Claude-3 Opus performs 28.7 points worse when provided with images instead of text; similarly, GPT-4 Turbo is 18.7 points worse and Gemini Pro is 14.9 points worse. Finally, we present two prompting techniques, $\textit{IsoCombination}$ and $\textit{IsoScratchPad}$, which improve model performance by considering combinations of, and translations between, different input representations.
Upsample Guidance: Scale Up Diffusion Models without Training
Apr 02, 2024Diffusion models have demonstrated superior performance across various generative tasks including images, videos, and audio. However, they encounter difficulties in directly generating high-resolution samples. Previously proposed solutions to this issue involve modifying the architecture, further training, or partitioning the sampling process into multiple stages. These methods have the limitation of not being able to directly utilize pre-trained models as-is, requiring additional work. In this paper, we introduce upsample guidance, a technique that adapts pretrained diffusion model (e.g., $512^2$) to generate higher-resolution images (e.g., $1536^2$) by adding only a single term in the sampling process. Remarkably, this technique does not necessitate any additional training or relying on external models. We demonstrate that upsample guidance can be applied to various models, such as pixel-space, latent space, and video diffusion models. We also observed that the proper selection of guidance scale can improve image quality, fidelity, and prompt alignment.
Release of Pre-Trained Models for the Japanese Language
Apr 02, 2024AI democratization aims to create a world in which the average person can utilize AI techniques. To achieve this goal, numerous research institutes have attempted to make their results accessible to the public. In particular, large pre-trained models trained on large-scale data have shown unprecedented potential, and their release has had a significant impact. However, most of the released models specialize in the English language, and thus, AI democratization in non-English-speaking communities is lagging significantly. To reduce this gap in AI access, we released Generative Pre-trained Transformer (GPT), Contrastive Language and Image Pre-training (CLIP), Stable Diffusion, and Hidden-unit Bidirectional Encoder Representations from Transformers (HuBERT) pre-trained in Japanese. By providing these models, users can freely interface with AI that aligns with Japanese cultural values and ensures the identity of Japanese culture, thus enhancing the democratization of AI. Additionally, experiments showed that pre-trained models specialized for Japanese can efficiently achieve high performance in Japanese tasks.