 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
D-IF: Uncertainty-aware Human Digitization via Implicit Distribution Field
Aug 17, 2023
Realistic virtual humans play a crucial role in numerous industries, such as metaverse, intelligent healthcare, and self-driving simulation. But creating them on a large scale with high levels of realism remains a challenge. The utilization of deep implicit function sparks a new era of image-based 3D clothed human reconstruction, enabling pixel-aligned shape recovery with fine details. Subsequently, the vast majority of works locate the surface by regressing the deterministic implicit value for each point. However, should all points be treated equally regardless of their proximity to the surface? In this paper, we propose replacing the implicit value with an adaptive uncertainty distribution, to differentiate between points based on their distance to the surface. This simple ``value to distribution'' transition yields significant improvements on nearly all the baselines. Furthermore, qualitative results demonstrate that the models trained using our uncertainty distribution loss, can capture more intricate wrinkles, and realistic limbs. Code and models are available for research purposes at https://github.com/psyai-net/D-IF_release.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Aug 17, 2023
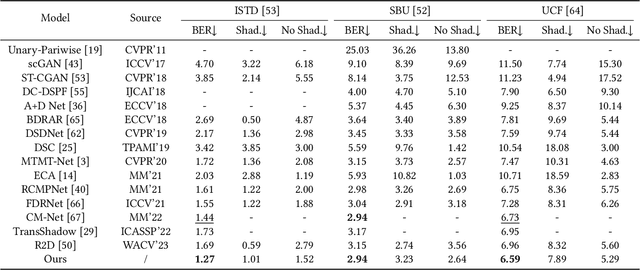
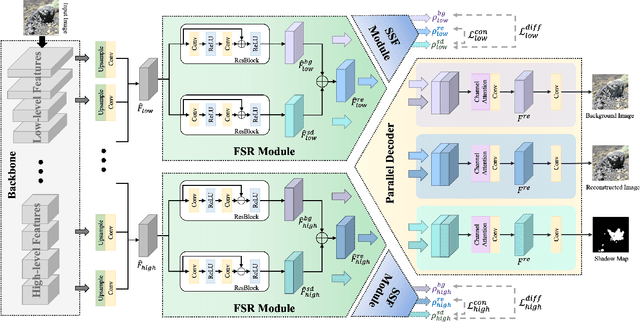
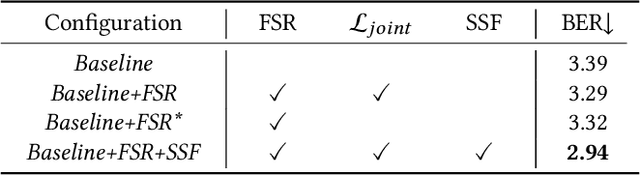
Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds. Drawing inspiration from the human visual system, we treat the input shadow image as a composition of a background layer and a shadow layer, and design a Style-guided Dual-layer Disentanglement Network (SDDNet) to model these layers independently. To achieve this, we devise a Feature Separation and Recombination (FSR) module that decomposes multi-level features into shadow-related and background-related components by offering specialized supervision for each component, while preserving information integrity and avoiding redundancy through the reconstruction constraint. Moreover, we propose a Shadow Style Filter (SSF) module to guide the feature disentanglement by focusing on style differentiation and uniformization. With these two modules and our overall pipeline, our model effectively minimizes the detrimental effects of background color, yielding superior performance on three public datasets with a real-time inference speed of 32 FPS.
Estimating fire Duration using regression methods
Aug 17, 2023Wildfire forecasting problems usually rely on complex grid-based mathematical models, mostly involving Computational fluid dynamics(CFD) and Celluar Automata, but these methods have always been computationally expensive and difficult to deliver a fast decision pattern. In this paper, we provide machine learning based approaches that solve the problem of high computational effort and time consumption. This paper predicts the burning duration of a known wildfire by RF(random forest), KNN, and XGBoost regression models and also image-based, like CNN and Encoder. Model inputs are based on the map of landscape features provided by satellites and the corresponding historical fire data in this area. This model is trained by happened fire data and landform feature maps and tested with the most recent real value in the same area. By processing the input differently to obtain the optimal outcome, the system is able to make fast and relatively accurate future predictions based on landscape images of known fires.
Improving Generalization of Synthetically Trained Sonar Image Descriptors for Underwater Place Recognition
Aug 02, 2023
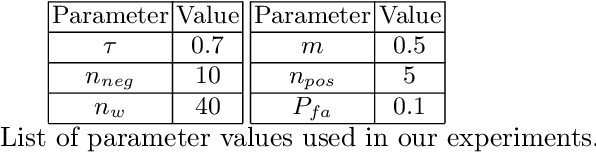

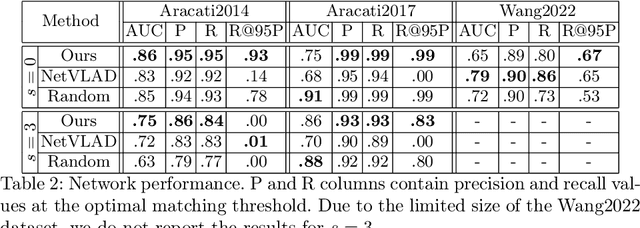
Autonomous navigation in underwater environments presents challenges due to factors such as light absorption and water turbidity, limiting the effectiveness of optical sensors. Sonar systems are commonly used for perception in underwater operations as they are unaffected by these limitations. Traditional computer vision algorithms are less effective when applied to sonar-generated acoustic images, while convolutional neural networks (CNNs) typically require large amounts of labeled training data that are often unavailable or difficult to acquire. To this end, we propose a novel compact deep sonar descriptor pipeline that can generalize to real scenarios while being trained exclusively on synthetic data. Our architecture is based on a ResNet18 back-end and a properly parameterized random Gaussian projection layer, whereas input sonar data is enhanced with standard ad-hoc normalization/prefiltering techniques. A customized synthetic data generation procedure is also presented. The proposed method has been evaluated extensively using both synthetic and publicly available real data, demonstrating its effectiveness compared to state-of-the-art methods.
CRoSS: Diffusion Model Makes Controllable, Robust and Secure Image Steganography
May 26, 2023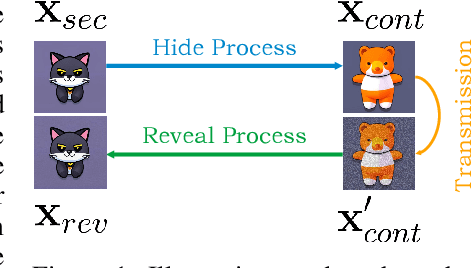
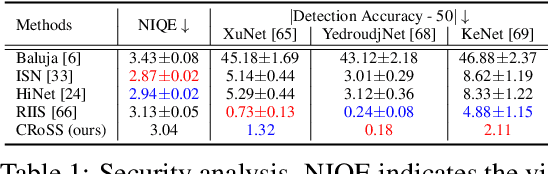


Current image steganography techniques are mainly focused on cover-based methods, which commonly have the risk of leaking secret images and poor robustness against degraded container images. Inspired by recent developments in diffusion models, we discovered that two properties of diffusion models, the ability to achieve translation between two images without training, and robustness to noisy data, can be used to improve security and natural robustness in image steganography tasks. For the choice of diffusion model, we selected Stable Diffusion, a type of conditional diffusion model, and fully utilized the latest tools from open-source communities, such as LoRAs and ControlNets, to improve the controllability and diversity of container images. In summary, we propose a novel image steganography framework, named Controllable, Robust and Secure Image Steganography (CRoSS), which has significant advantages in controllability, robustness, and security compared to cover-based image steganography methods. These benefits are obtained without additional training. To our knowledge, this is the first work to introduce diffusion models to the field of image steganography. In the experimental section, we conducted detailed experiments to demonstrate the advantages of our proposed CRoSS framework in controllability, robustness, and security.
Contrastive Learning for Lane Detection via Cross-Similarity
Aug 21, 2023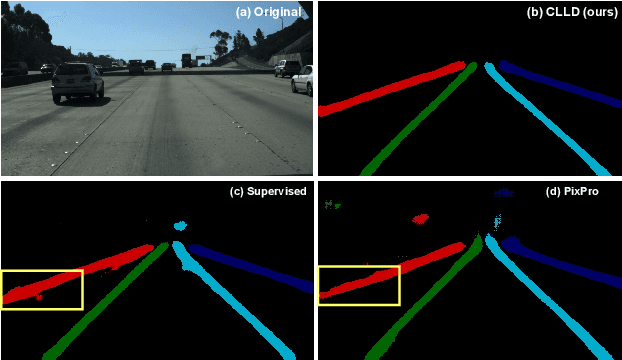
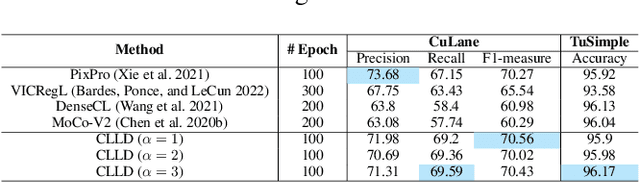
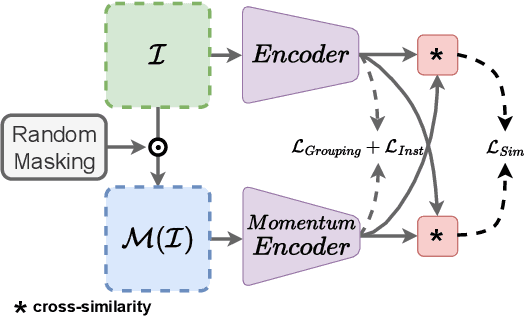
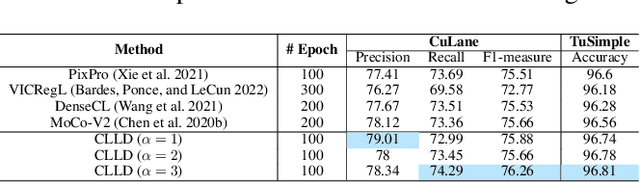
Detecting road lanes is challenging due to intricate markings vulnerable to unfavorable conditions. Lane markings have strong shape priors, but their visibility is easily compromised. Factors like lighting, weather, vehicles, pedestrians, and aging colors challenge the detection. A large amount of data is required to train a lane detection approach that can withstand natural variations caused by low visibility. This is because there are numerous lane shapes and natural variations that exist. Our solution, Contrastive Learning for Lane Detection via cross-similarity (CLLD), is a self-supervised learning method that tackles this challenge by enhancing lane detection models resilience to real-world conditions that cause lane low visibility. CLLD is a novel multitask contrastive learning that trains lane detection approaches to detect lane markings even in low visible situations by integrating local feature contrastive learning (CL) with our new proposed operation cross-similarity. Local feature CL focuses on extracting features for small image parts, which is necessary to localize lane segments, while cross-similarity captures global features to detect obscured lane segments using their surrounding. We enhance cross-similarity by randomly masking parts of input images for augmentation. Evaluated on benchmark datasets, CLLD outperforms state-of-the-art contrastive learning, especially in visibility-impairing conditions like shadows. Compared to supervised learning, CLLD excels in scenarios like shadows and crowded scenes.
Feature-Suppressed Contrast for Self-Supervised Food Pre-training
Aug 21, 2023
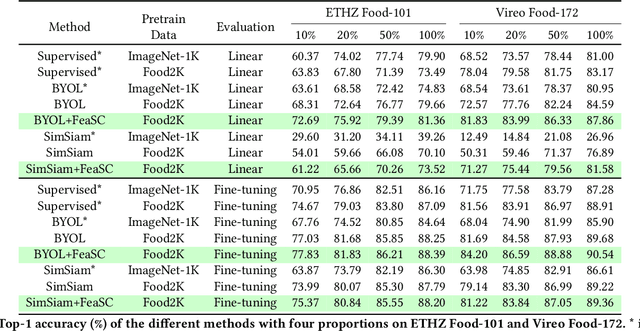

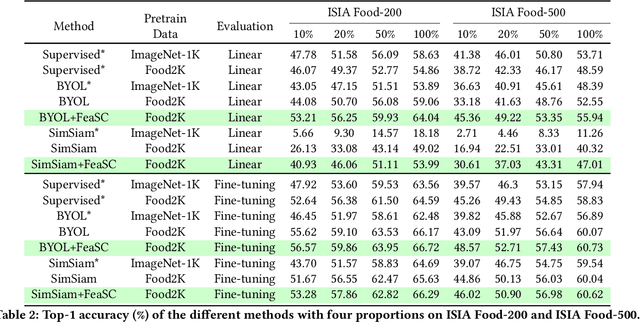
Most previous approaches for analyzing food images have relied on extensively annotated datasets, resulting in significant human labeling expenses due to the varied and intricate nature of such images. Inspired by the effectiveness of contrastive self-supervised methods in utilizing unlabelled data, weiqing explore leveraging these techniques on unlabelled food images. In contrastive self-supervised methods, two views are randomly generated from an image by data augmentations. However, regarding food images, the two views tend to contain similar informative contents, causing large mutual information, which impedes the efficacy of contrastive self-supervised learning. To address this problem, we propose Feature Suppressed Contrast (FeaSC) to reduce mutual information between views. As the similar contents of the two views are salient or highly responsive in the feature map, the proposed FeaSC uses a response-aware scheme to localize salient features in an unsupervised manner. By suppressing some salient features in one view while leaving another contrast view unchanged, the mutual information between the two views is reduced, thereby enhancing the effectiveness of contrast learning for self-supervised food pre-training. As a plug-and-play module, the proposed method consistently improves BYOL and SimSiam by 1.70\% $\sim$ 6.69\% classification accuracy on four publicly available food recognition datasets. Superior results have also been achieved on downstream segmentation tasks, demonstrating the effectiveness of the proposed method.
Rethinking Person Re-identification from a Projection-on-Prototypes Perspective
Aug 21, 2023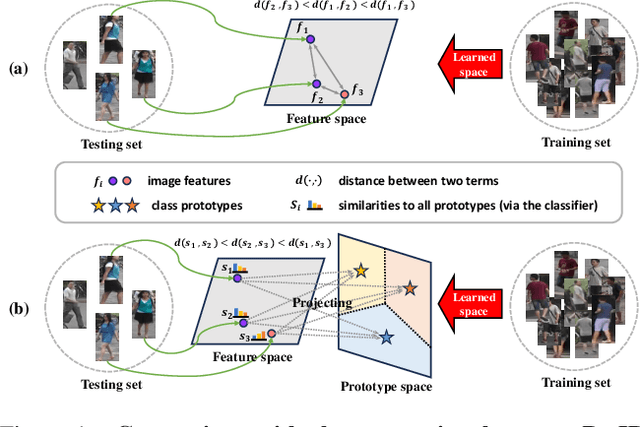
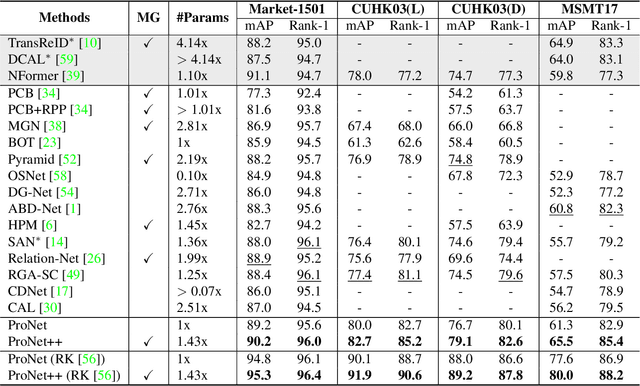
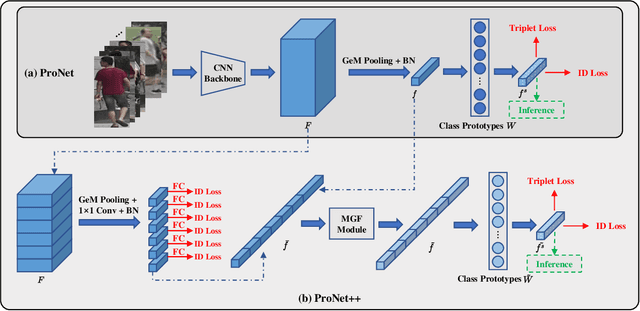
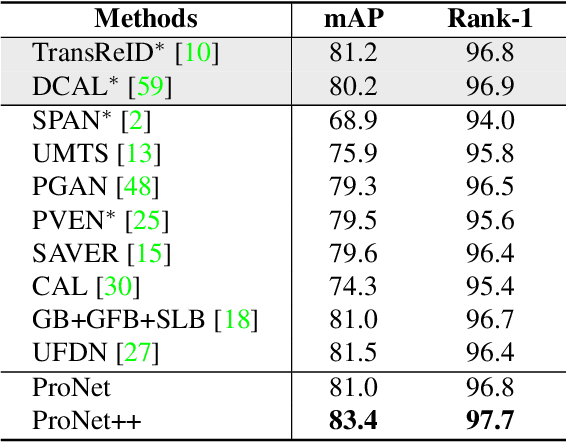
Person Re-IDentification (Re-ID) as a retrieval task, has achieved tremendous development over the past decade. Existing state-of-the-art methods follow an analogous framework to first extract features from the input images and then categorize them with a classifier. However, since there is no identity overlap between training and testing sets, the classifier is often discarded during inference. Only the extracted features are used for person retrieval via distance metrics. In this paper, we rethink the role of the classifier in person Re-ID, and advocate a new perspective to conceive the classifier as a projection from image features to class prototypes. These prototypes are exactly the learned parameters of the classifier. In this light, we describe the identity of input images as similarities to all prototypes, which are then utilized as more discriminative features to perform person Re-ID. We thereby propose a new baseline ProNet, which innovatively reserves the function of the classifier at the inference stage. To facilitate the learning of class prototypes, both triplet loss and identity classification loss are applied to features that undergo the projection by the classifier. An improved version of ProNet++ is presented by further incorporating multi-granularity designs. Experiments on four benchmarks demonstrate that our proposed ProNet is simple yet effective, and significantly beats previous baselines. ProNet++ also achieves competitive or even better results than transformer-based competitors.
Extraction of Text from Optic Nerve Optical Coherence Tomography Reports
Aug 21, 2023
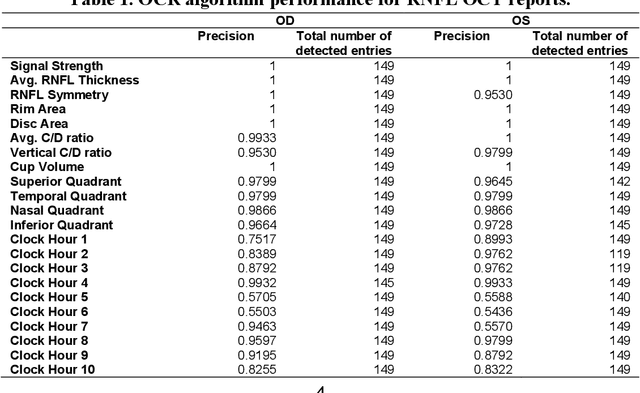
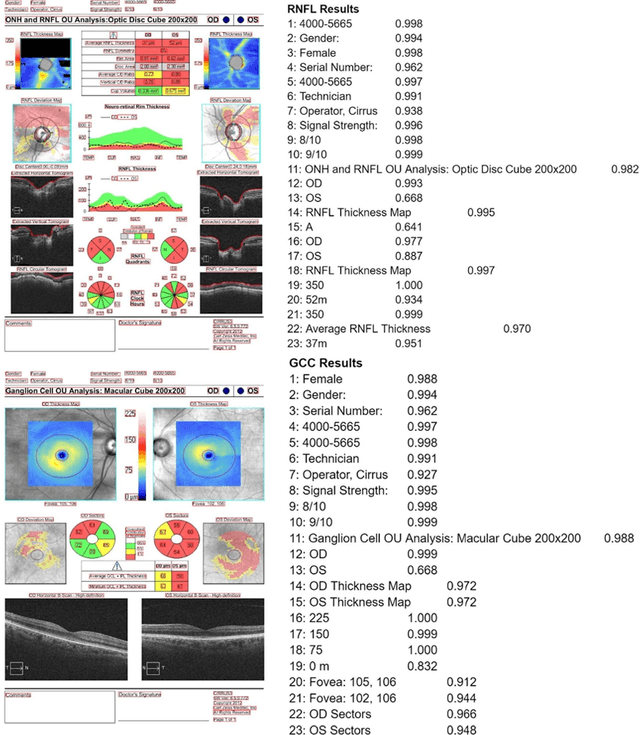
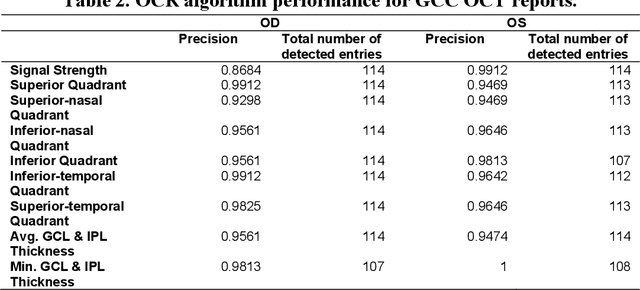
Purpose: The purpose of this study was to develop and evaluate rule-based algorithms to enhance the extraction of text data, including retinal nerve fiber layer (RNFL) values and other ganglion cell count (GCC) data, from Zeiss Cirrus optical coherence tomography (OCT) scan reports. Methods: DICOM files that contained encapsulated PDF reports with RNFL or Ganglion Cell in their document titles were identified from a clinical imaging repository at a single academic ophthalmic center. PDF reports were then converted into image files and processed using the PaddleOCR Python package for optical character recognition. Rule-based algorithms were designed and iteratively optimized for improved performance in extracting RNFL and GCC data. Evaluation of the algorithms was conducted through manual review of a set of RNFL and GCC reports. Results: The developed algorithms demonstrated high precision in extracting data from both RNFL and GCC scans. Precision was slightly better for the right eye in RNFL extraction (OD: 0.9803 vs. OS: 0.9046), and for the left eye in GCC extraction (OD: 0.9567 vs. OS: 0.9677). Some values presented more challenges in extraction, particularly clock hours 5 and 6 for RNFL thickness, and signal strength for GCC. Conclusions: A customized optical character recognition algorithm can identify numeric results from optical coherence scan reports with high precision. Automated processing of PDF reports can greatly reduce the time to extract OCT results on a large scale.
FastSurfer-HypVINN: Automated sub-segmentation of the hypothalamus and adjacent structures on high-resolutional brain MRI
Aug 24, 2023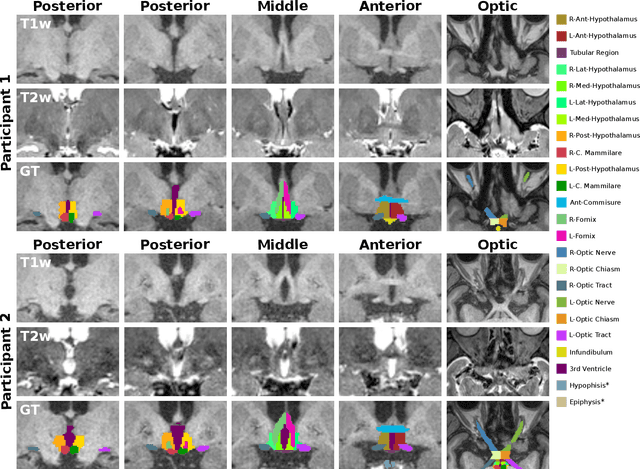
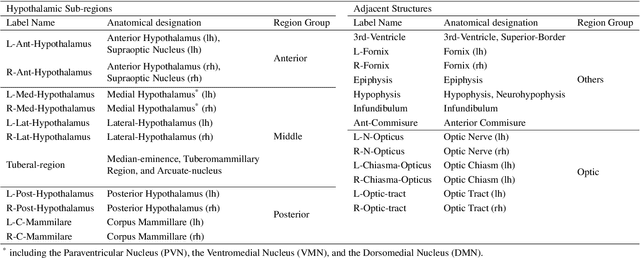
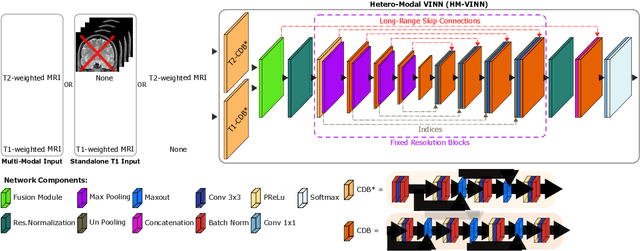
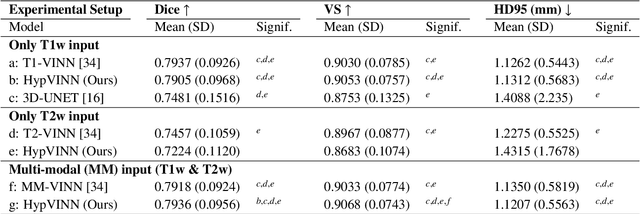
The hypothalamus plays a crucial role in the regulation of a broad range of physiological, behavioural, and cognitive functions. However, despite its importance, only a few small-scale neuroimaging studies have investigated its substructures, likely due to the lack of fully automated segmentation tools to address scalability and reproducibility issues of manual segmentation. While the only previous attempt to automatically sub-segment the hypothalamus with a neural network showed promise for 1.0 mm isotropic T1-weighted (T1w) MRI, there is a need for an automated tool to sub-segment also high-resolutional (HiRes) MR scans, as they are becoming widely available, and include structural detail also from multi-modal MRI. We, therefore, introduce a novel, fast, and fully automated deep learning method named HypVINN for sub-segmentation of the hypothalamus and adjacent structures on 0.8 mm isotropic T1w and T2w brain MR images that is robust to missing modalities. We extensively validate our model with respect to segmentation accuracy, generalizability, in-session test-retest reliability, and sensitivity to replicate hypothalamic volume effects (e.g. sex-differences). The proposed method exhibits high segmentation performance both for standalone T1w images as well as for T1w/T2w image pairs. Even with the additional capability to accept flexible inputs, our model matches or exceeds the performance of state-of-the-art methods with fixed inputs. We, further, demonstrate the generalizability of our method in experiments with 1.0 mm MR scans from both the Rhineland Study and the UK Biobank. Finally, HypVINN can perform the segmentation in less than a minute (GPU) and will be available in the open source FastSurfer neuroimaging software suite, offering a validated, efficient, and scalable solution for evaluating imaging-derived phenotypes of the hypothalamus.