 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Contextformer: Spatio-Channel Window Attention for Fast Context Modeling in Learned Image Compression
Jun 25, 2023

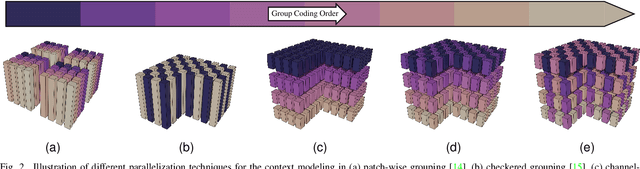
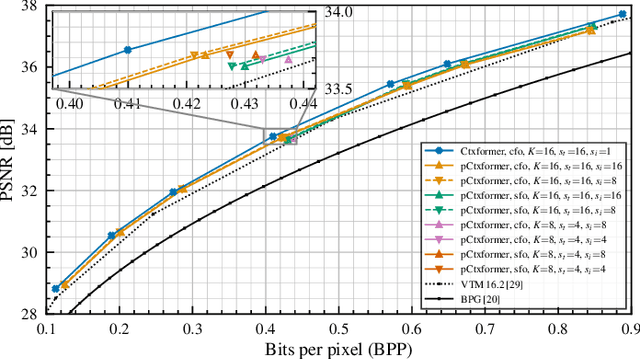
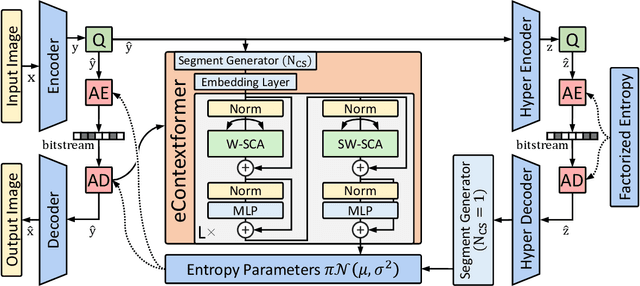
In this work, we introduce Efficient Contextformer (eContextformer) for context modeling in lossy learned image compression, which is built upon our previous work, Contextformer. The eContextformer combines the recent advancements in efficient transformers and fast context models with the spatio-channel attention mechanism. The proposed model enables content-adaptive exploitation of the spatial and channel-wise latent dependencies for a high performance and efficient entropy modeling. By incorporating several innovations, the eContextformer features improved decoding speed, model complexity and rate-distortion performance over previous work. For instance, compared to Contextformer, the eContextformer requires 145x less model complexity, 210x less decoding speed and achieves higher average bit savings on the Kodak, CLIC2020 and Tecnick datasets. Compared to the standard Versatile Video Coding (VVC) Test Model (VTM) 16.2, the proposed model provides up to 17.1% bitrate savings and surpasses various learning-based models.
InvVis: Large-Scale Data Embedding for Invertible Visualization
Jul 30, 2023
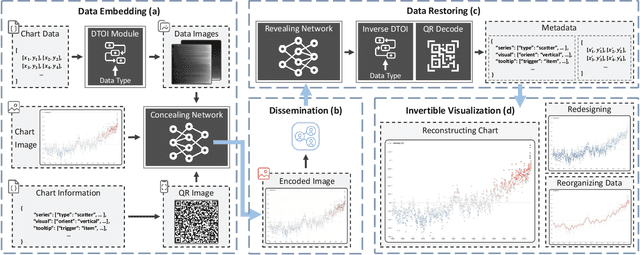
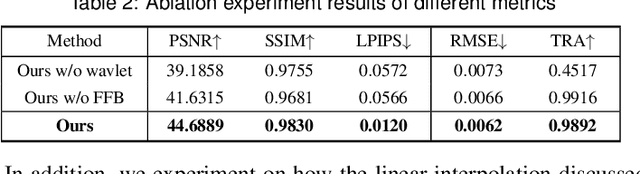
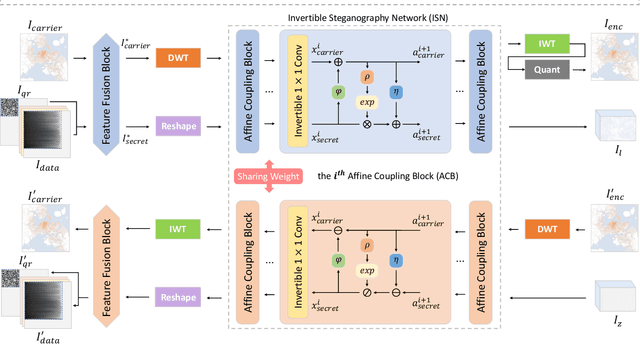
We present InvVis, a new approach for invertible visualization, which is reconstructing or further modifying a visualization from an image. InvVis allows the embedding of a significant amount of data, such as chart data, chart information, source code, etc., into visualization images. The encoded image is perceptually indistinguishable from the original one. We propose a new method to efficiently express chart data in the form of images, enabling large-capacity data embedding. We also outline a model based on the invertible neural network to achieve high-quality data concealing and revealing. We explore and implement a variety of application scenarios of InvVis. Additionally, we conduct a series of evaluation experiments to assess our method from multiple perspectives, including data embedding quality, data restoration accuracy, data encoding capacity, etc. The result of our experiments demonstrates the great potential of InvVis in invertible visualization.
Image is First-order Norm+Linear Autoregressive
May 25, 2023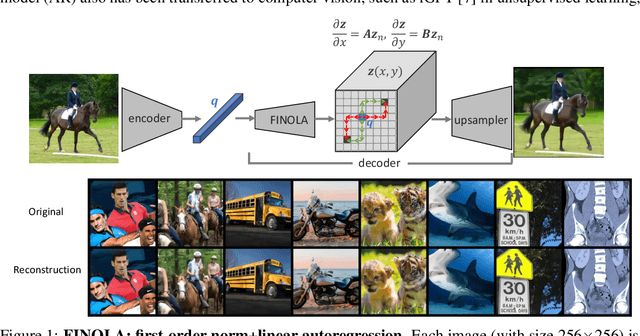
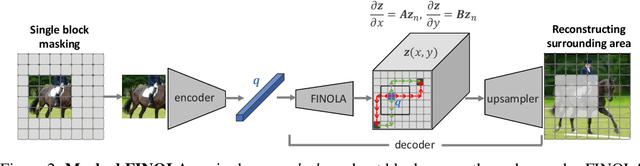
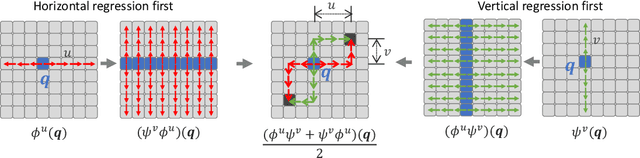
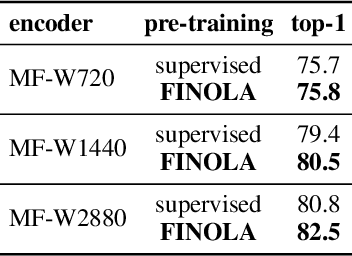
This paper reveals that every image can be understood as a first-order norm+linear autoregressive process, referred to as FINOLA, where norm+linear denotes the use of normalization before the linear model. We demonstrate that images of size 256$\times$256 can be reconstructed from a compressed vector using autoregression up to a 16$\times$16 feature map, followed by upsampling and convolution. This discovery sheds light on the underlying partial differential equations (PDEs) governing the latent feature space. Additionally, we investigate the application of FINOLA for self-supervised learning through a simple masked prediction technique. By encoding a single unmasked quadrant block, we can autoregressively predict the surrounding masked region. Remarkably, this pre-trained representation proves effective for image classification and object detection tasks, even in lightweight networks, without requiring fine-tuning. The code will be made publicly available.
DiffPose: SpatioTemporal Diffusion Model for Video-Based Human Pose Estimation
Aug 05, 2023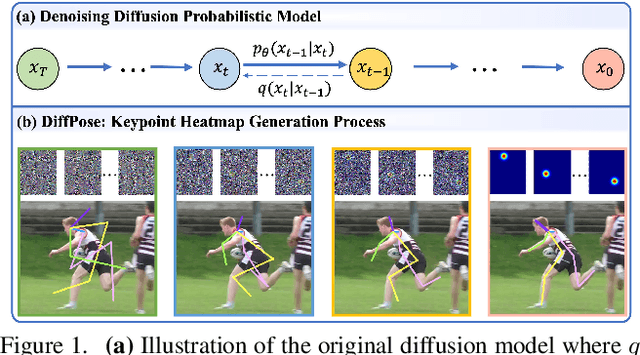
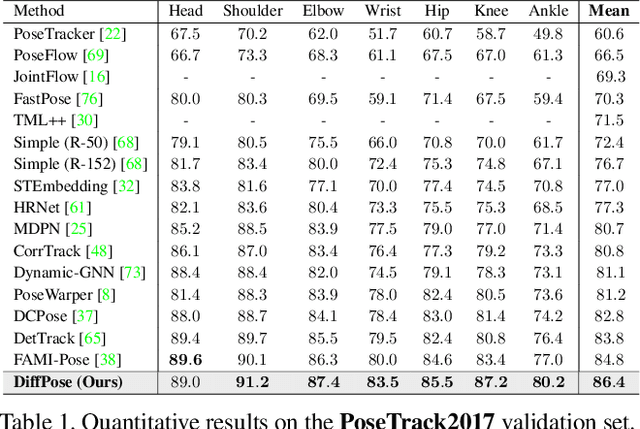
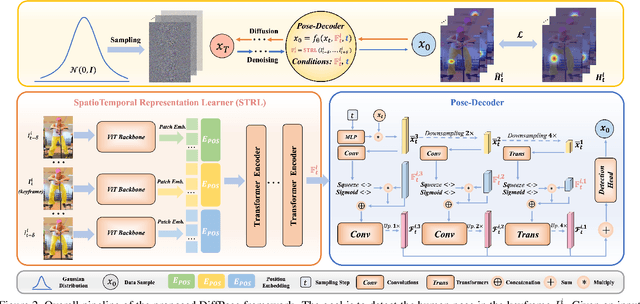
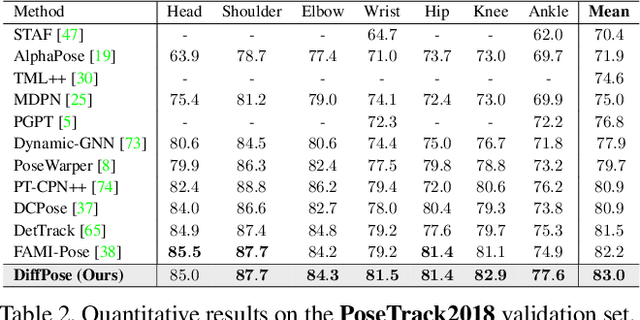
Denoising diffusion probabilistic models that were initially proposed for realistic image generation have recently shown success in various perception tasks (e.g., object detection and image segmentation) and are increasingly gaining attention in computer vision. However, extending such models to multi-frame human pose estimation is non-trivial due to the presence of the additional temporal dimension in videos. More importantly, learning representations that focus on keypoint regions is crucial for accurate localization of human joints. Nevertheless, the adaptation of the diffusion-based methods remains unclear on how to achieve such objective. In this paper, we present DiffPose, a novel diffusion architecture that formulates video-based human pose estimation as a conditional heatmap generation problem. First, to better leverage temporal information, we propose SpatioTemporal Representation Learner which aggregates visual evidences across frames and uses the resulting features in each denoising step as a condition. In addition, we present a mechanism called Lookup-based MultiScale Feature Interaction that determines the correlations between local joints and global contexts across multiple scales. This mechanism generates delicate representations that focus on keypoint regions. Altogether, by extending diffusion models, we show two unique characteristics from DiffPose on pose estimation task: (i) the ability to combine multiple sets of pose estimates to improve prediction accuracy, particularly for challenging joints, and (ii) the ability to adjust the number of iterative steps for feature refinement without retraining the model. DiffPose sets new state-of-the-art results on three benchmarks: PoseTrack2017, PoseTrack2018, and PoseTrack21.
Thin On-Sensor Nanophotonic Array Cameras
Aug 05, 2023

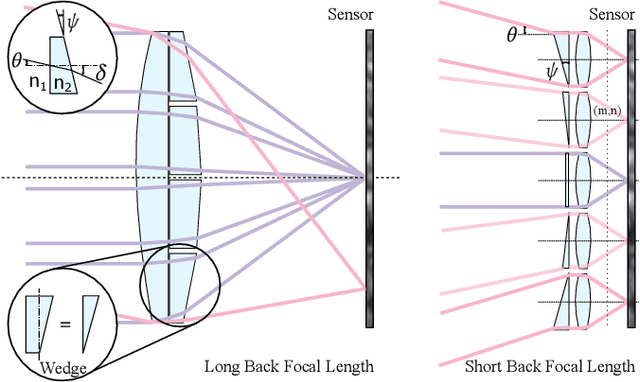
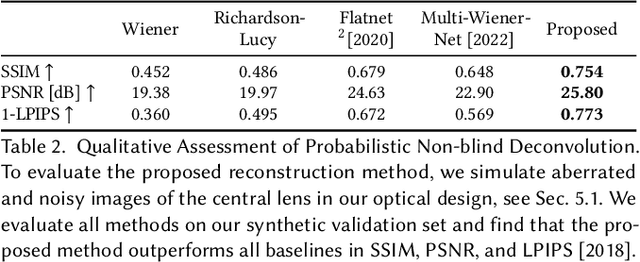
Today's commodity camera systems rely on compound optics to map light originating from the scene to positions on the sensor where it gets recorded as an image. To record images without optical aberrations, i.e., deviations from Gauss' linear model of optics, typical lens systems introduce increasingly complex stacks of optical elements which are responsible for the height of existing commodity cameras. In this work, we investigate \emph{flat nanophotonic computational cameras} as an alternative that employs an array of skewed lenslets and a learned reconstruction approach. The optical array is embedded on a metasurface that, at 700~nm height, is flat and sits on the sensor cover glass at 2.5~mm focal distance from the sensor. To tackle the highly chromatic response of a metasurface and design the array over the entire sensor, we propose a differentiable optimization method that continuously samples over the visible spectrum and factorizes the optical modulation for different incident fields into individual lenses. We reconstruct a megapixel image from our flat imager with a \emph{learned probabilistic reconstruction} method that employs a generative diffusion model to sample an implicit prior. To tackle \emph{scene-dependent aberrations in broadband}, we propose a method for acquiring paired captured training data in varying illumination conditions. We assess the proposed flat camera design in simulation and with an experimental prototype, validating that the method is capable of recovering images from diverse scenes in broadband with a single nanophotonic layer.
Few-shot Class-Incremental Semantic Segmentation via Pseudo-Labeling and Knowledge Distillation
Aug 05, 2023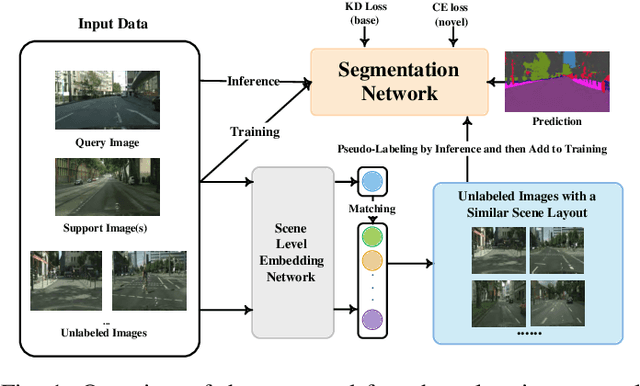


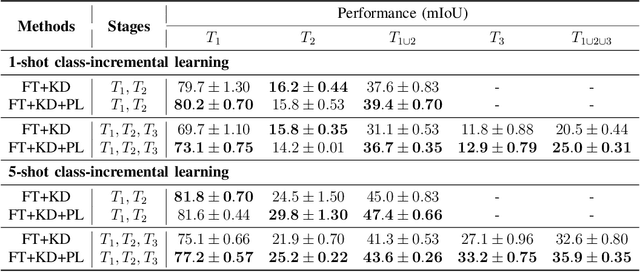
We address the problem of learning new classes for semantic segmentation models from few examples, which is challenging because of the following two reasons. Firstly, it is difficult to learn from limited novel data to capture the underlying class distribution. Secondly, it is challenging to retain knowledge for existing classes and to avoid catastrophic forgetting. For learning from limited data, we propose a pseudo-labeling strategy to augment the few-shot training annotations in order to learn novel classes more effectively. Given only one or a few images labeled with the novel classes and a much larger set of unlabeled images, we transfer the knowledge from labeled images to unlabeled images with a coarse-to-fine pseudo-labeling approach in two steps. Specifically, we first match each labeled image to its nearest neighbors in the unlabeled image set at the scene level, in order to obtain images with a similar scene layout. This is followed by obtaining pseudo-labels within this neighborhood by applying classifiers learned on the few-shot annotations. In addition, we use knowledge distillation on both labeled and unlabeled data to retain knowledge on existing classes. We integrate the above steps into a single convolutional neural network with a unified learning objective. Extensive experiments on the Cityscapes and KITTI datasets validate the efficacy of the proposed approach in the self-driving domain. Code is available from https://github.com/ChasonJiang/FSCILSS.
Blind Motion Deblurring with Pixel-Wise Kernel Estimation via Kernel Prediction Networks
Aug 05, 2023



In recent years, the removal of motion blur in photographs has seen impressive progress in the hands of deep learning-based methods, trained to map directly from blurry to sharp images. For this reason, approaches that explicitly use a forward degradation model received significantly less attention. However, a well-defined specification of the blur genesis, as an intermediate step, promotes the generalization and explainability of the method. Towards this goal, we propose a learning-based motion deblurring method based on dense non-uniform motion blur estimation followed by a non-blind deconvolution approach. Specifically, given a blurry image, a first network estimates the dense per-pixel motion blur kernels using a lightweight representation composed of a set of image-adaptive basis motion kernels and the corresponding mixing coefficients. Then, a second network trained jointly with the first one, unrolls a non-blind deconvolution method using the motion kernel field estimated by the first network. The model-driven aspect is further promoted by training the networks on sharp/blurry pairs synthesized according to a convolution-based, non-uniform motion blur degradation model. Qualitative and quantitative evaluation shows that the kernel prediction network produces accurate motion blur estimates, and that the deblurring pipeline leads to restorations of real blurred images that are competitive or superior to those obtained with existing end-to-end deep learning-based methods. Code and trained models are available at https://github.com/GuillermoCarbajal/J-MKPD/.
Enhanced Masked Image Modeling for Analysis of Dental Panoramic Radiographs
Jun 18, 2023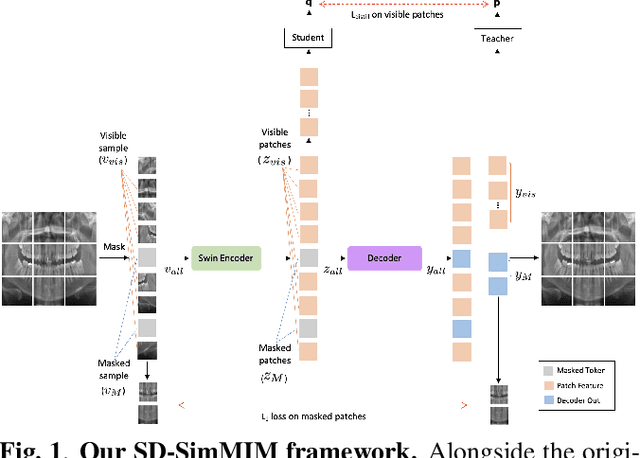
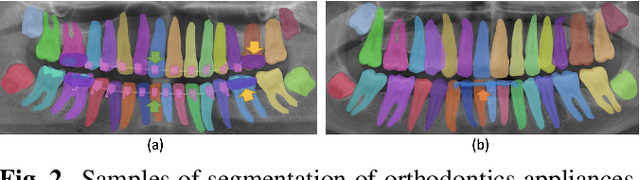
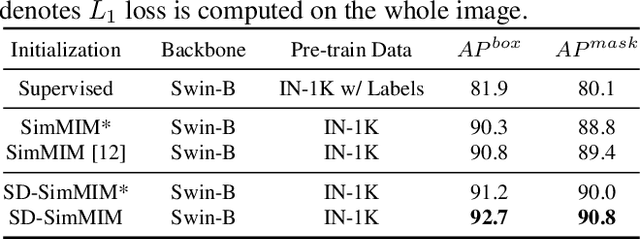
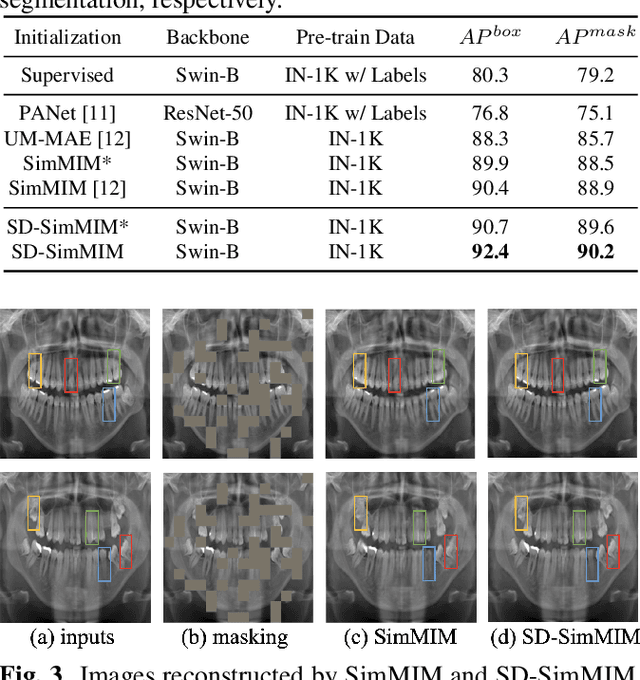
The computer-assisted radiologic informative report has received increasing research attention to facilitate diagnosis and treatment planning for dental care providers. However, manual interpretation of dental images is limited, expensive, and time-consuming. Another barrier in dental imaging is the limited number of available images for training, which is a challenge in the era of deep learning. This study proposes a novel self-distillation (SD) enhanced self-supervised learning on top of the masked image modeling (SimMIM) Transformer, called SD-SimMIM, to improve the outcome with a limited number of dental radiographs. In addition to the prediction loss on masked patches, SD-SimMIM computes the self-distillation loss on the visible patches. We apply SD-SimMIM on dental panoramic X-rays for teeth numbering, detection of dental restorations and orthodontic appliances, and instance segmentation tasks. Our results show that SD-SimMIM outperforms other self-supervised learning methods. Furthermore, we augment and improve the annotation of an existing dataset of panoramic X-rays.
Controlling Geometric Abstraction and Texture for Artistic Images
Jul 31, 2023



We present a novel method for the interactive control of geometric abstraction and texture in artistic images. Previous example-based stylization methods often entangle shape, texture, and color, while generative methods for image synthesis generally either make assumptions about the input image, such as only allowing faces or do not offer precise editing controls. By contrast, our holistic approach spatially decomposes the input into shapes and a parametric representation of high-frequency details comprising the image's texture, thus enabling independent control of color and texture. Each parameter in this representation controls painterly attributes of a pipeline of differentiable stylization filters. The proposed decoupling of shape and texture enables various options for stylistic editing, including interactive global and local adjustments of shape, stroke, and painterly attributes such as surface relief and contours. Additionally, we demonstrate optimization-based texture style-transfer in the parametric space using reference images and text prompts, as well as the training of single- and arbitrary style parameter prediction networks for real-time texture decomposition.
ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation
Jun 01, 2023

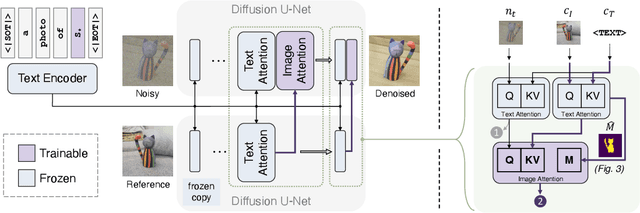
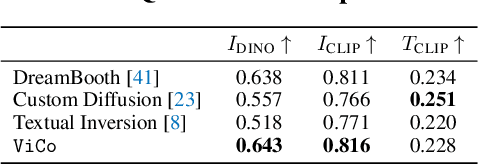
Personalized text-to-image generation using diffusion models has recently been proposed and attracted lots of attention. Given a handful of images containing a novel concept (e.g., a unique toy), we aim to tune the generative model to capture fine visual details of the novel concept and generate photorealistic images following a text condition. We present a plug-in method, named ViCo, for fast and lightweight personalized generation. Specifically, we propose an image attention module to condition the diffusion process on the patch-wise visual semantics. We introduce an attention-based object mask that comes almost at no cost from the attention module. In addition, we design a simple regularization based on the intrinsic properties of text-image attention maps to alleviate the common overfitting degradation. Unlike many existing models, our method does not finetune any parameters of the original diffusion model. This allows more flexible and transferable model deployment. With only light parameter training (~6% of the diffusion U-Net), our method achieves comparable or even better performance than all state-of-the-art models both qualitatively and quantitatively.