 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Translation-Enhanced Multilingual Text-to-Image Generation
May 30, 2023
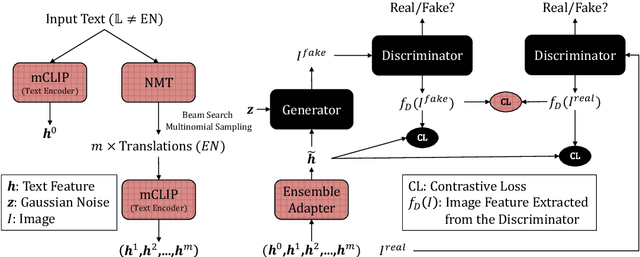
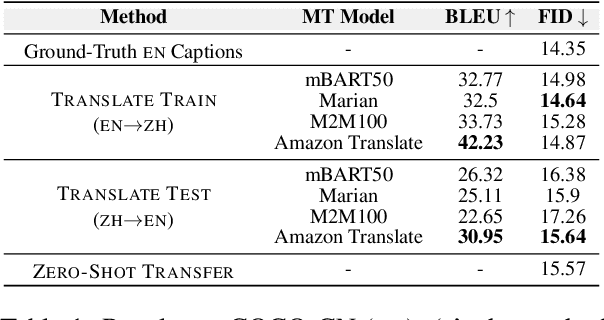
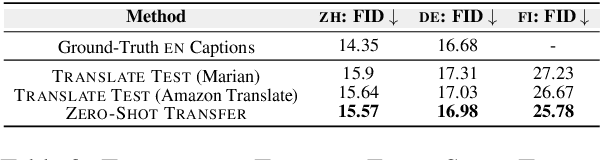

Research on text-to-image generation (TTI) still predominantly focuses on the English language due to the lack of annotated image-caption data in other languages; in the long run, this might widen inequitable access to TTI technology. In this work, we thus investigate multilingual TTI (termed mTTI) and the current potential of neural machine translation (NMT) to bootstrap mTTI systems. We provide two key contributions. 1) Relying on a multilingual multi-modal encoder, we provide a systematic empirical study of standard methods used in cross-lingual NLP when applied to mTTI: Translate Train, Translate Test, and Zero-Shot Transfer. 2) We propose Ensemble Adapter (EnsAd), a novel parameter-efficient approach that learns to weigh and consolidate the multilingual text knowledge within the mTTI framework, mitigating the language gap and thus improving mTTI performance. Our evaluations on standard mTTI datasets COCO-CN, Multi30K Task2, and LAION-5B demonstrate the potential of translation-enhanced mTTI systems and also validate the benefits of the proposed EnsAd which derives consistent gains across all datasets. Further investigations on model variants, ablation studies, and qualitative analyses provide additional insights on the inner workings of the proposed mTTI approaches.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
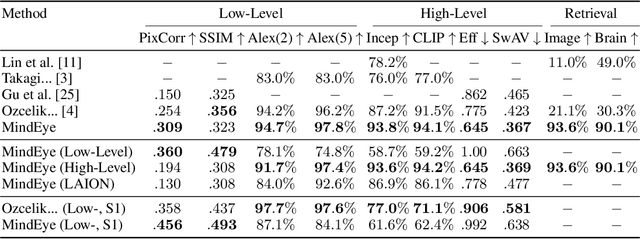
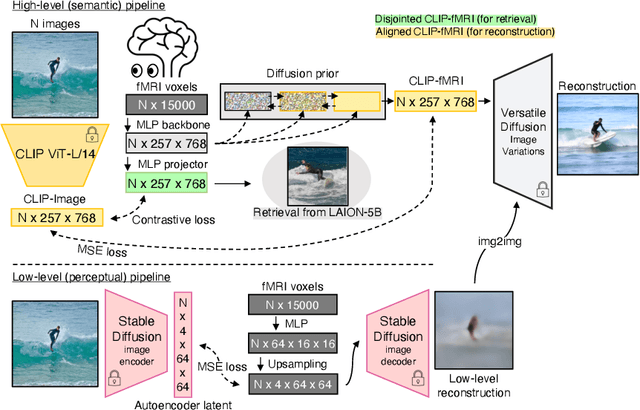
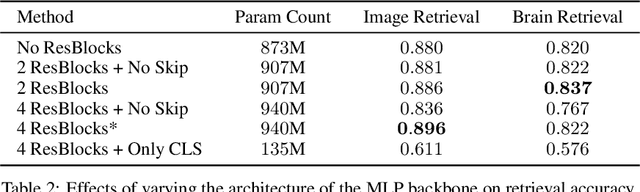
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
ZYN: Zero-Shot Reward Models with Yes-No Questions
Aug 11, 2023In this work, we address the problem of directing the text generations of a LLM towards a desired behavior, aligning the generated text with the preferences of the human operator. We propose using another language model as a critic, reward model in a zero-shot way thanks to the prompt of a Yes-No question that represents the user preferences, without requiring further labeled data. This zero-shot reward model provides the learning signal to further fine-tune the base LLM using reinforcement learning, as in RLAIF; yet our approach is also compatible in other contexts such as quality-diversity search. Extensive evidence of the capabilities of the proposed ZYN framework is provided through experiments in different domains related to text generation, including detoxification; optimizing sentiment of movie reviews, or any other attribute; steering the opinion about a particular topic the model may have; and personalizing prompt generators for text-to-image tasks. Code to be released at \url{https://github.com/vicgalle/zero-shot-reward-models/}.
VAST: Vivify Your Talking Avatar via Zero-Shot Expressive Facial Style Transfer
Aug 11, 2023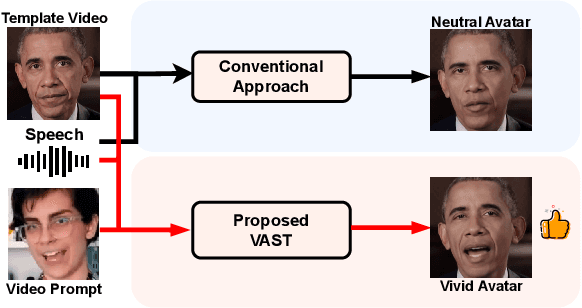

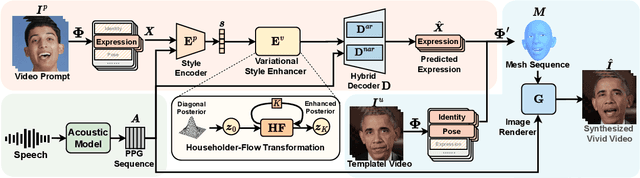
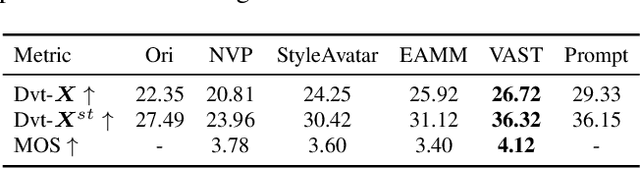
Current talking face generation methods mainly focus on speech-lip synchronization. However, insufficient investigation on the facial talking style leads to a lifeless and monotonous avatar. Most previous works fail to imitate expressive styles from arbitrary video prompts and ensure the authenticity of the generated video. This paper proposes an unsupervised variational style transfer model (VAST) to vivify the neutral photo-realistic avatars. Our model consists of three key components: a style encoder that extracts facial style representations from the given video prompts; a hybrid facial expression decoder to model accurate speech-related movements; a variational style enhancer that enhances the style space to be highly expressive and meaningful. With our essential designs on facial style learning, our model is able to flexibly capture the expressive facial style from arbitrary video prompts and transfer it onto a personalized image renderer in a zero-shot manner. Experimental results demonstrate the proposed approach contributes to a more vivid talking avatar with higher authenticity and richer expressiveness.
Vision-based Semantic Communications for Metaverse Services: A Contest Theoretic Approach
Aug 15, 2023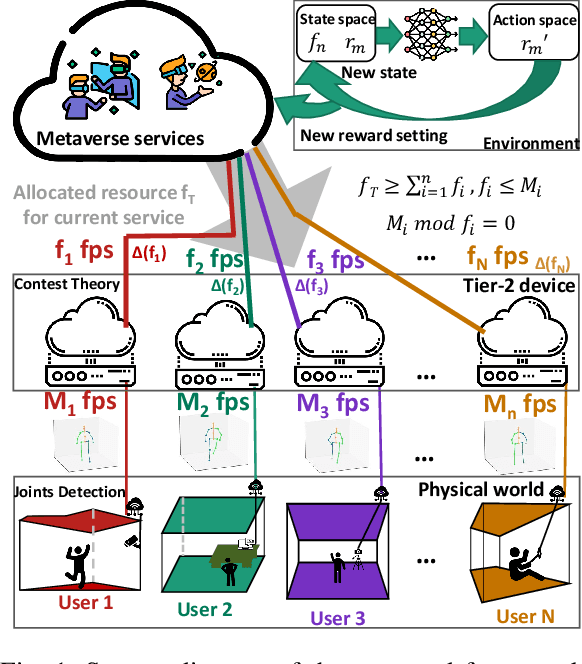
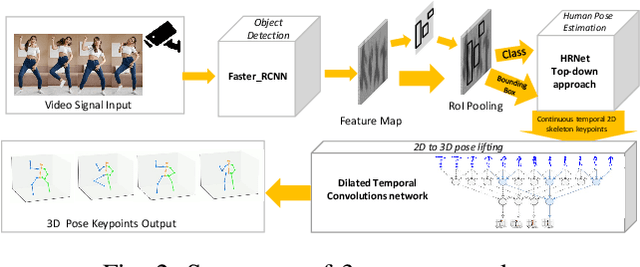
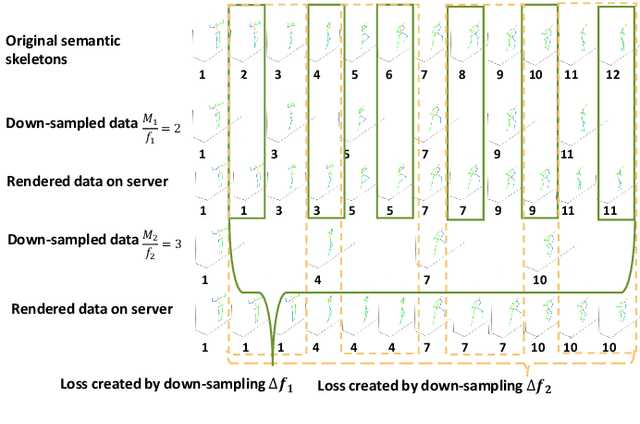
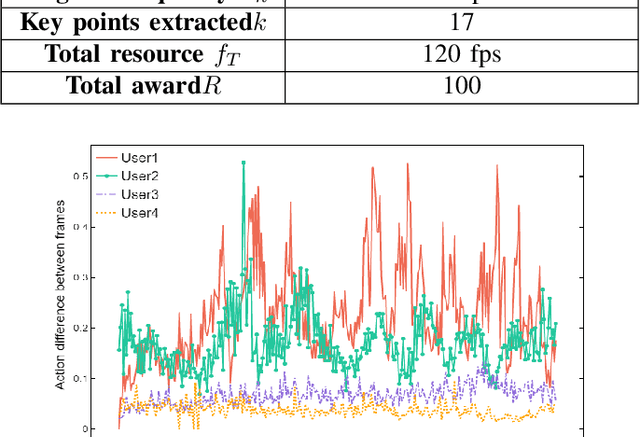
The popularity of Metaverse as an entertainment, social, and work platform has led to a great need for seamless avatar integration in the virtual world. In Metaverse, avatars must be updated and rendered to reflect users' behaviour. Achieving real-time synchronization between the virtual bilocation and the user is complex, placing high demands on the Metaverse Service Provider (MSP)'s rendering resource allocation scheme. To tackle this issue, we propose a semantic communication framework that leverages contest theory to model the interactions between users and MSPs and determine optimal resource allocation for each user. To reduce the consumption of network resources in wireless transmission, we use the semantic communication technique to reduce the amount of data to be transmitted. Under our simulation settings, the encoded semantic data only contains 51 bytes of skeleton coordinates instead of the image size of 8.243 megabytes. Moreover, we implement Deep Q-Network to optimize reward settings for maximum performance and efficient resource allocation. With the optimal reward setting, users are incentivized to select their respective suitable uploading frequency, reducing down-sampling loss due to rendering resource constraints by 66.076\% compared with the traditional average distribution method. The framework provides a novel solution to resource allocation for avatar association in VR environments, ensuring a smooth and immersive experience for all users.
Link-Context Learning for Multimodal LLMs
Aug 15, 2023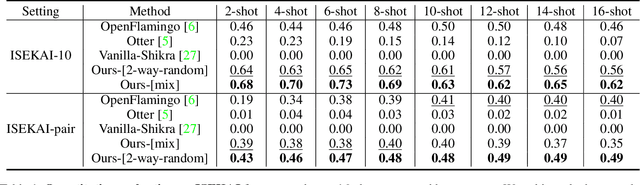
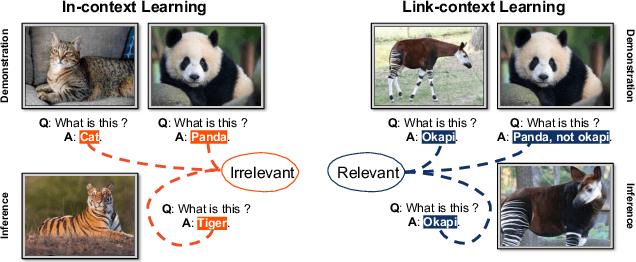
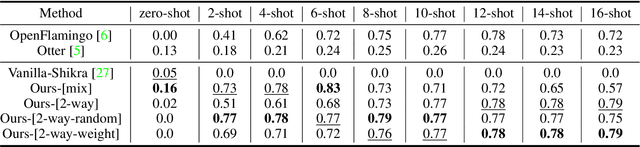
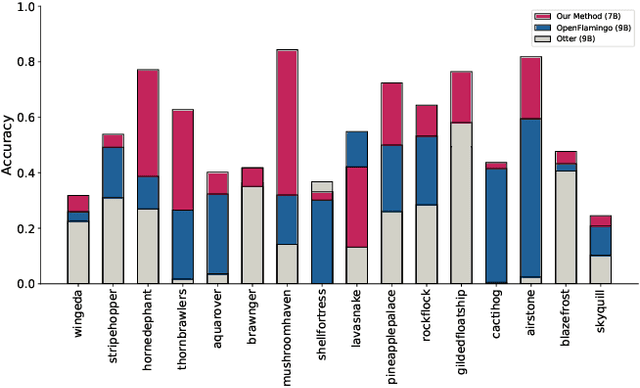
The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations. Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to ``learn to learn" from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes "reasoning from cause and effect" to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. To facilitate the evaluation of this novel approach, we introduce the ISEKAI dataset, comprising exclusively of unseen generated image-label pairs designed for link-context learning. Extensive experiments show that our LCL-MLLM exhibits strong link-context learning capabilities to novel concepts over vanilla MLLMs. Code and data will be released at https://github.com/isekai-portal/Link-Context-Learning.
Helping Hands: An Object-Aware Ego-Centric Video Recognition Model
Aug 15, 2023We introduce an object-aware decoder for improving the performance of spatio-temporal representations on ego-centric videos. The key idea is to enhance object-awareness during training by tasking the model to predict hand positions, object positions, and the semantic label of the objects using paired captions when available. At inference time the model only requires RGB frames as inputs, and is able to track and ground objects (although it has not been trained explicitly for this). We demonstrate the performance of the object-aware representations learnt by our model, by: (i) evaluating it for strong transfer, i.e. through zero-shot testing, on a number of downstream video-text retrieval and classification benchmarks; and (ii) by using the representations learned as input for long-term video understanding tasks (e.g. Episodic Memory in Ego4D). In all cases the performance improves over the state of the art -- even compared to networks trained with far larger batch sizes. We also show that by using noisy image-level detection as pseudo-labels in training, the model learns to provide better bounding boxes using video consistency, as well as grounding the words in the associated text descriptions. Overall, we show that the model can act as a drop-in replacement for an ego-centric video model to improve performance through visual-text grounding.
Enhancing Network Initialization for Medical AI Models Using Large-Scale, Unlabeled Natural Images
Aug 15, 2023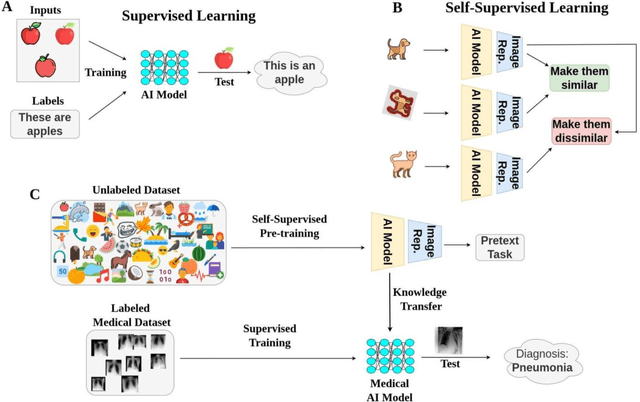
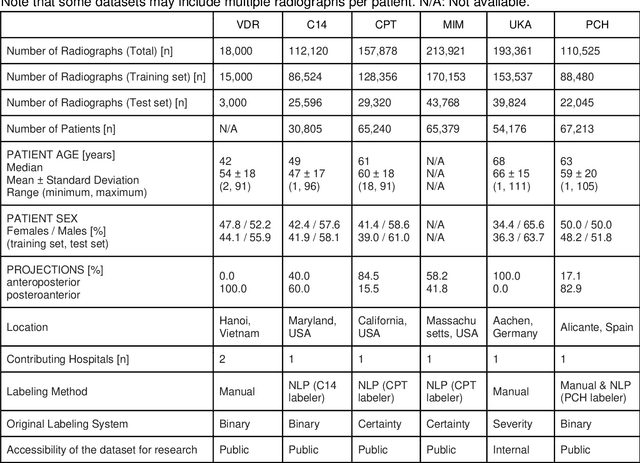
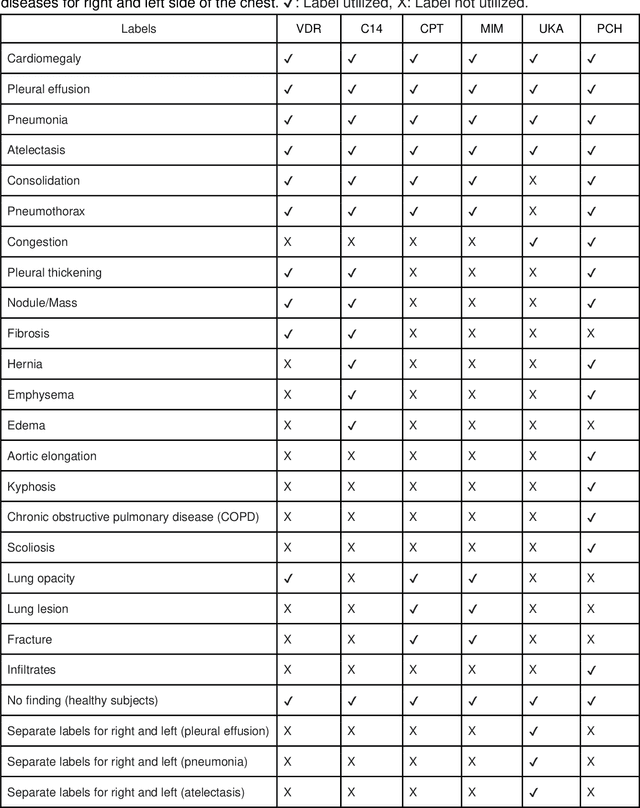
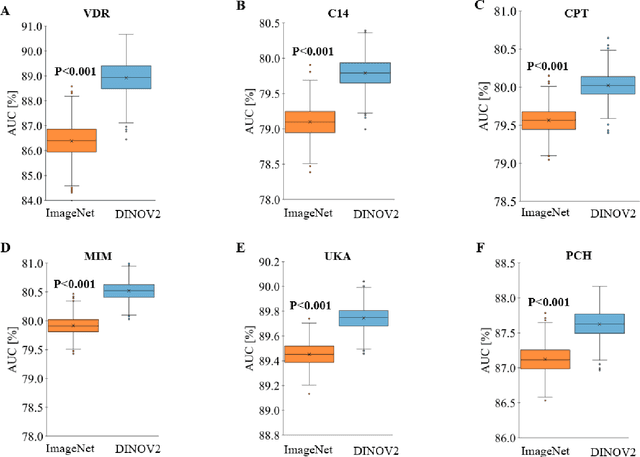
Pre-training datasets, like ImageNet, have become the gold standard in medical image analysis. However, the emergence of self-supervised learning (SSL), which leverages unlabeled data to learn robust features, presents an opportunity to bypass the intensive labeling process. In this study, we explored if SSL for pre-training on non-medical images can be applied to chest radiographs and how it compares to supervised pre-training on non-medical images and on medical images. We utilized a vision transformer and initialized its weights based on (i) SSL pre-training on natural images (DINOv2), (ii) SL pre-training on natural images (ImageNet dataset), and (iii) SL pre-training on chest radiographs from the MIMIC-CXR database. We tested our approach on over 800,000 chest radiographs from six large global datasets, diagnosing more than 20 different imaging findings. Our SSL pre-training on curated images not only outperformed ImageNet-based pre-training (P<0.001 for all datasets) but, in certain cases, also exceeded SL on the MIMIC-CXR dataset. Our findings suggest that selecting the right pre-training strategy, especially with SSL, can be pivotal for improving artificial intelligence (AI)'s diagnostic accuracy in medical imaging. By demonstrating the promise of SSL in chest radiograph analysis, we underline a transformative shift towards more efficient and accurate AI models in medical imaging.
InstructEdit: Improving Automatic Masks for Diffusion-based Image Editing With User Instructions
May 29, 2023
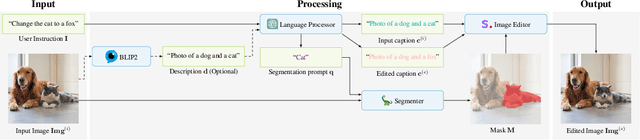


Recent works have explored text-guided image editing using diffusion models and generated edited images based on text prompts. However, the models struggle to accurately locate the regions to be edited and faithfully perform precise edits. In this work, we propose a framework termed InstructEdit that can do fine-grained editing based on user instructions. Our proposed framework has three components: language processor, segmenter, and image editor. The first component, the language processor, processes the user instruction using a large language model. The goal of this processing is to parse the user instruction and output prompts for the segmenter and captions for the image editor. We adopt ChatGPT and optionally BLIP2 for this step. The second component, the segmenter, uses the segmentation prompt provided by the language processor. We employ a state-of-the-art segmentation framework Grounded Segment Anything to automatically generate a high-quality mask based on the segmentation prompt. The third component, the image editor, uses the captions from the language processor and the masks from the segmenter to compute the edited image. We adopt Stable Diffusion and the mask-guided generation from DiffEdit for this purpose. Experiments show that our method outperforms previous editing methods in fine-grained editing applications where the input image contains a complex object or multiple objects. We improve the mask quality over DiffEdit and thus improve the quality of edited images. We also show that our framework can accept multiple forms of user instructions as input. We provide the code at https://github.com/QianWangX/InstructEdit.
WaveDM: Wavelet-Based Diffusion Models for Image Restoration
May 23, 2023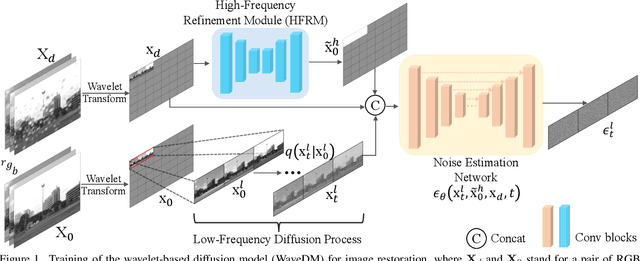
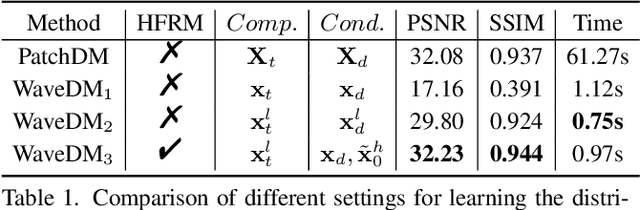
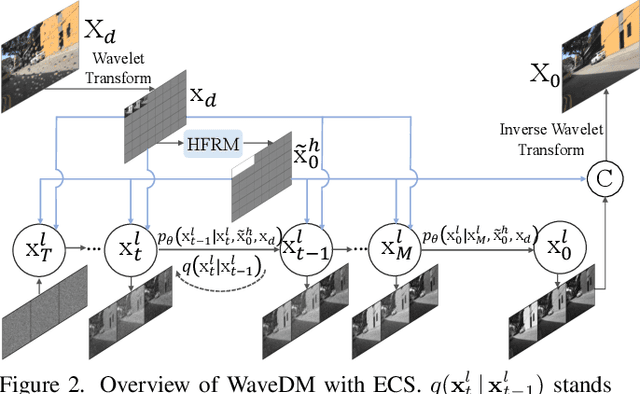
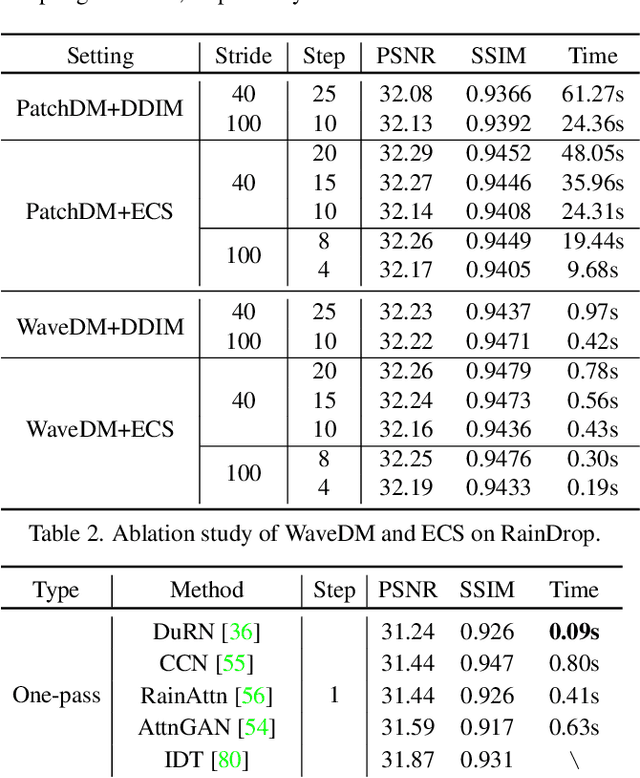
Latest diffusion-based methods for many image restoration tasks outperform traditional models, but they encounter the long-time inference problem. To tackle it, this paper proposes a Wavelet-Based Diffusion Model (WaveDM) with an Efficient Conditional Sampling (ECS) strategy. WaveDM learns the distribution of clean images in the wavelet domain conditioned on the wavelet spectrum of degraded images after wavelet transform, which is more time-saving in each step of sampling than modeling in the spatial domain. In addition, ECS follows the same procedure as the deterministic implicit sampling in the initial sampling period and then stops to predict clean images directly, which reduces the number of total sampling steps to around 5. Evaluations on four benchmark datasets including image raindrop removal, defocus deblurring, demoir\'eing, and denoising demonstrate that WaveDM achieves state-of-the-art performance with the efficiency that is comparable to traditional one-pass methods and over 100 times faster than existing image restoration methods using vanilla diffusion models.