 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
JOTR: 3D Joint Contrastive Learning with Transformers for Occluded Human Mesh Recovery
Aug 17, 2023
In this study, we focus on the problem of 3D human mesh recovery from a single image under obscured conditions. Most state-of-the-art methods aim to improve 2D alignment technologies, such as spatial averaging and 2D joint sampling. However, they tend to neglect the crucial aspect of 3D alignment by improving 3D representations. Furthermore, recent methods struggle to separate the target human from occlusion or background in crowded scenes as they optimize the 3D space of target human with 3D joint coordinates as local supervision. To address these issues, a desirable method would involve a framework for fusing 2D and 3D features and a strategy for optimizing the 3D space globally. Therefore, this paper presents 3D JOint contrastive learning with TRansformers (JOTR) framework for handling occluded 3D human mesh recovery. Our method includes an encoder-decoder transformer architecture to fuse 2D and 3D representations for achieving 2D$\&$3D aligned results in a coarse-to-fine manner and a novel 3D joint contrastive learning approach for adding explicitly global supervision for the 3D feature space. The contrastive learning approach includes two contrastive losses: joint-to-joint contrast for enhancing the similarity of semantically similar voxels (i.e., human joints), and joint-to-non-joint contrast for ensuring discrimination from others (e.g., occlusions and background). Qualitative and quantitative analyses demonstrate that our method outperforms state-of-the-art competitors on both occlusion-specific and standard benchmarks, significantly improving the reconstruction of occluded humans.
SurgicalSAM: Efficient Class Promptable Surgical Instrument Segmentation
Aug 17, 2023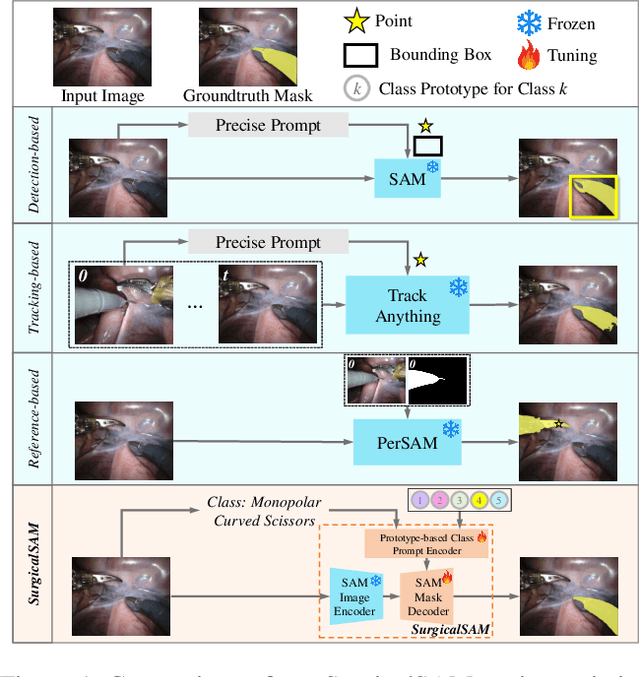
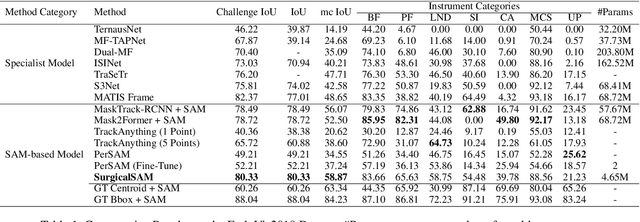
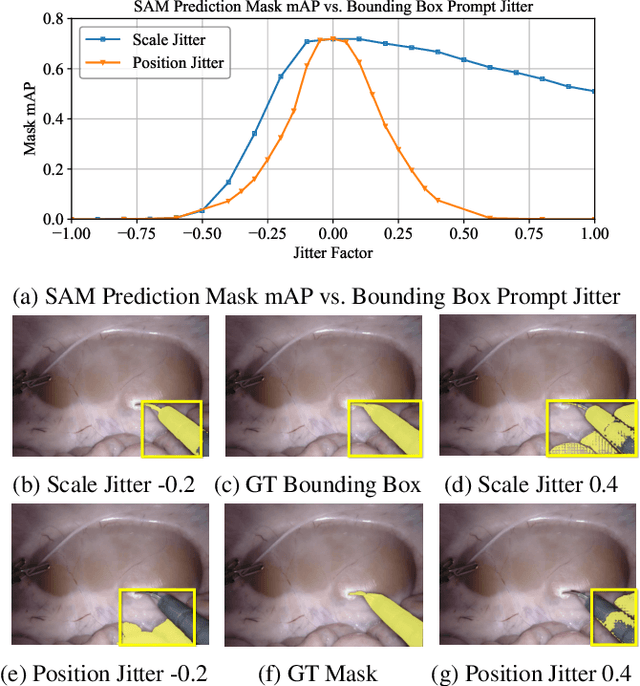
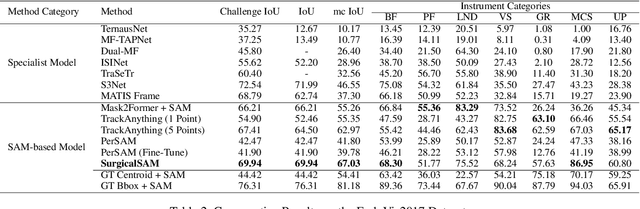
The Segment Anything Model (SAM) is a powerful foundation model that has revolutionised image segmentation. To apply SAM to surgical instrument segmentation, a common approach is to locate precise points or boxes of instruments and then use them as prompts for SAM in a zero-shot manner. However, we observe two problems with this naive pipeline: (1) the domain gap between natural objects and surgical instruments leads to poor generalisation of SAM; and (2) SAM relies on precise point or box locations for accurate segmentation, requiring either extensive manual guidance or a well-performing specialist detector for prompt preparation, which leads to a complex multi-stage pipeline. To address these problems, we introduce SurgicalSAM, a novel end-to-end efficient-tuning approach for SAM to effectively integrate surgical-specific information with SAM's pre-trained knowledge for improved generalisation. Specifically, we propose a lightweight prototype-based class prompt encoder for tuning, which directly generates prompt embeddings from class prototypes and eliminates the use of explicit prompts for improved robustness and a simpler pipeline. In addition, to address the low inter-class variance among surgical instrument categories, we propose contrastive prototype learning, further enhancing the discrimination of the class prototypes for more accurate class prompting. The results of extensive experiments on both EndoVis2018 and EndoVis2017 datasets demonstrate that SurgicalSAM achieves state-of-the-art performance while only requiring a small number of tunable parameters. The source code will be released at https://github.com/wenxi-yue/SurgicalSAM.
Text-Only Image Captioning with Multi-Context Data Generation
May 29, 2023
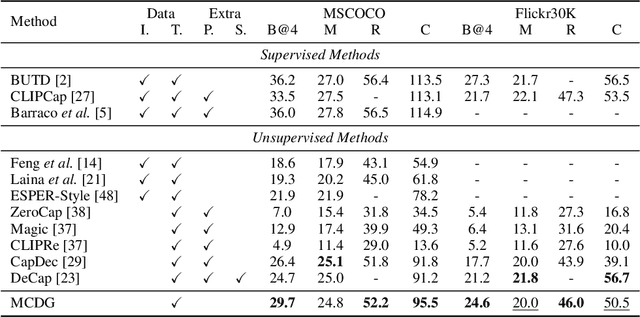
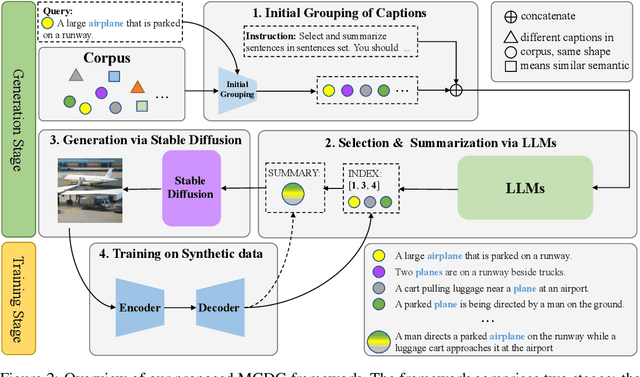
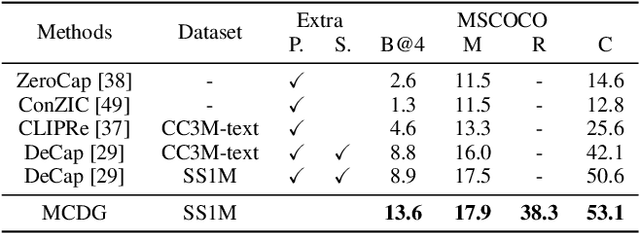
Text-only Image Captioning (TIC) is an approach that aims to construct a model solely based on text that can accurately describe images. Recently, diffusion models have demonstrated remarkable capabilities in generating high-quality images that are semantically coherent with given texts. This presents an opportunity to generate synthetic training images for TIC. However, we have identified a challenge that the images generated from simple descriptions typically exhibit a single perspective with one or limited contexts, which is not aligned with the complexity of real-world scenes in the image domain. In this paper, we propose a novel framework that addresses this issue by introducing multi-context data generation. Starting with an initial text corpus, our framework employs a large language model to select multiple sentences that describe the same scene from various perspectives. These sentences are then summarized into a single sentence with multiple contexts. We generate simple images using the straightforward sentences and complex images using the summarized sentences through diffusion models. Finally, we train the model exclusively using the synthetic image-text pairs obtained from this process. Experimental results demonstrate that our proposed framework effectively tackles the central challenge we have identified, achieving the state-of-the-art performance on popular datasets such as MSCOCO, Flickr30k, and SS1M.
ViCo: Detail-Preserving Visual Condition for Personalized Text-to-Image Generation
Jun 01, 2023

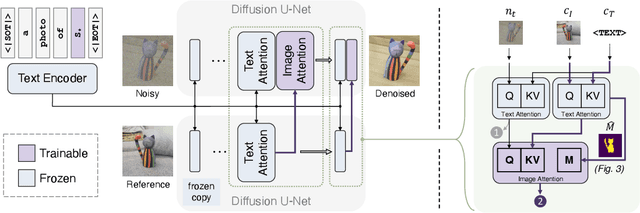
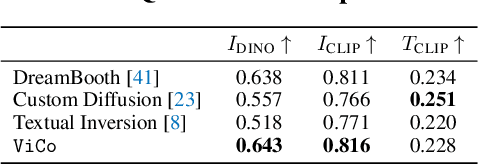
Personalized text-to-image generation using diffusion models has recently been proposed and attracted lots of attention. Given a handful of images containing a novel concept (e.g., a unique toy), we aim to tune the generative model to capture fine visual details of the novel concept and generate photorealistic images following a text condition. We present a plug-in method, named ViCo, for fast and lightweight personalized generation. Specifically, we propose an image attention module to condition the diffusion process on the patch-wise visual semantics. We introduce an attention-based object mask that comes almost at no cost from the attention module. In addition, we design a simple regularization based on the intrinsic properties of text-image attention maps to alleviate the common overfitting degradation. Unlike many existing models, our method does not finetune any parameters of the original diffusion model. This allows more flexible and transferable model deployment. With only light parameter training (~6% of the diffusion U-Net), our method achieves comparable or even better performance than all state-of-the-art models both qualitatively and quantitatively.
Virtual Mirrors: Non-Line-of-Sight Imaging Beyond the Third Bounce
Jul 26, 2023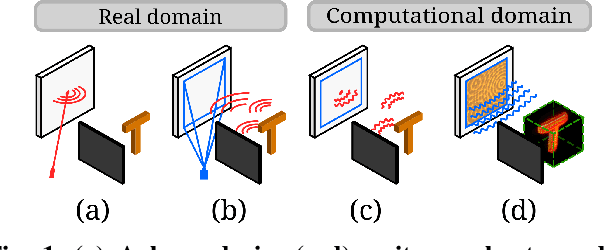
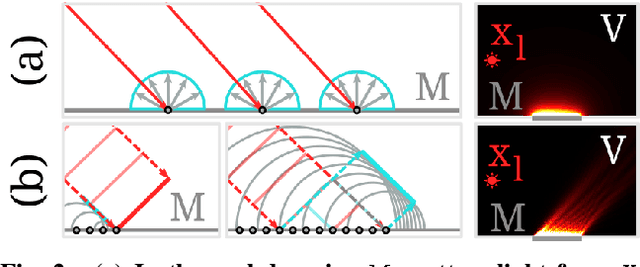

Non-line-of-sight (NLOS) imaging methods are capable of reconstructing complex scenes that are not visible to an observer using indirect illumination. However, they assume only third-bounce illumination, so they are currently limited to single-corner configurations, and present limited visibility when imaging surfaces at certain orientations. To reason about and tackle these limitations, we make the key observation that planar diffuse surfaces behave specularly at wavelengths used in the computational wave-based NLOS imaging domain. We call such surfaces virtual mirrors. We leverage this observation to expand the capabilities of NLOS imaging using illumination beyond the third bounce, addressing two problems: imaging single-corner objects at limited visibility angles, and imaging objects hidden behind two corners. To image objects at limited visibility angles, we first analyze the reflections of the known illuminated point on surfaces of the scene as an estimator of the position and orientation of objects with limited visibility. We then image those limited visibility objects by computationally building secondary apertures at other surfaces that observe the target object from a direct visibility perspective. Beyond single-corner NLOS imaging, we exploit the specular behavior of virtual mirrors to image objects hidden behind a second corner by imaging the space behind such virtual mirrors, where the mirror image of objects hidden around two corners is formed. No specular surfaces were involved in the making of this paper.
Optimizing Performance of Feedforward and Convolutional Neural Networks through Dynamic Activation Functions
Aug 10, 2023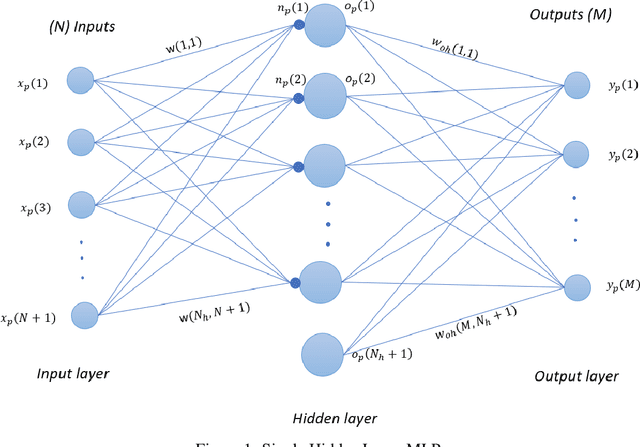
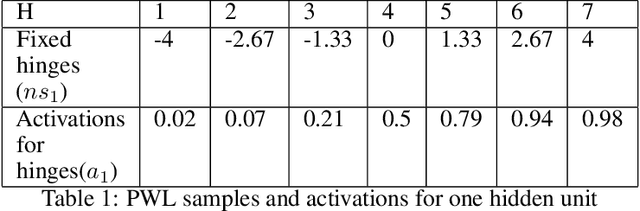
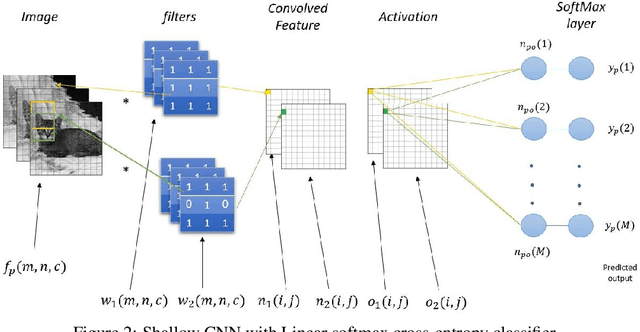
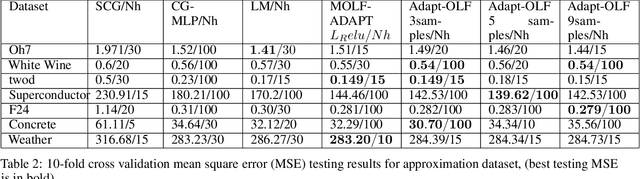
Deep learning training training algorithms are a huge success in recent years in many fields including speech, text,image video etc. Deeper and deeper layers are proposed with huge success with resnet structures having around 152 layers. Shallow convolution neural networks(CNN's) are still an active research, where some phenomena are still unexplained. Activation functions used in the network are of utmost importance, as they provide non linearity to the networks. Relu's are the most commonly used activation function.We show a complex piece-wise linear(PWL) activation in the hidden layer. We show that these PWL activations work much better than relu activations in our networks for convolution neural networks and multilayer perceptrons. Result comparison in PyTorch for shallow and deep CNNs are given to further strengthen our case.
FuseCap: Leveraging Large Language Models to Fuse Visual Data into Enriched Image Captions
May 28, 2023
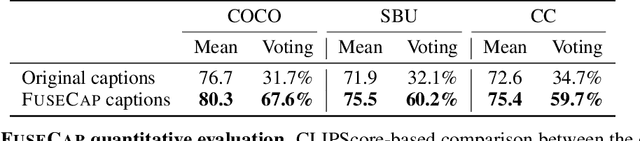
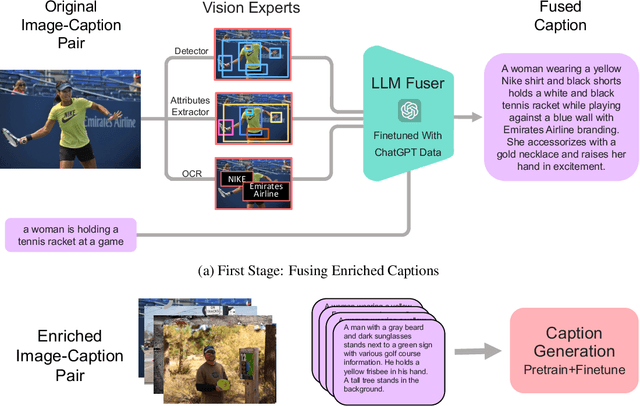
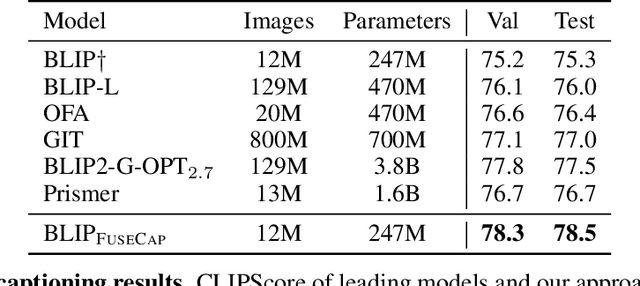
Image captioning is a central task in computer vision which has experienced substantial progress following the advent of vision-language pre-training techniques. In this paper, we highlight a frequently overlooked limitation of captioning models that often fail to capture semantically significant elements. This drawback can be traced back to the text-image datasets; while their captions typically offer a general depiction of image content, they frequently omit salient details. To mitigate this limitation, we propose FuseCap - a novel method for enriching captions with additional visual information, obtained from vision experts, such as object detectors, attribute recognizers, and Optical Character Recognizers (OCR). Our approach fuses the outputs of such vision experts with the original caption using a large language model (LLM), yielding enriched captions that present a comprehensive image description. We validate the effectiveness of the proposed caption enrichment method through both quantitative and qualitative analysis. Our method is then used to curate the training set of a captioning model based BLIP which surpasses current state-of-the-art approaches in generating accurate and detailed captions while using significantly fewer parameters and training data. As additional contributions, we provide a dataset comprising of 12M image-enriched caption pairs and show that the proposed method largely improves image-text retrieval.
"Let's not Quote out of Context": Unified Vision-Language Pretraining for Context Assisted Image Captioning
Jun 01, 2023
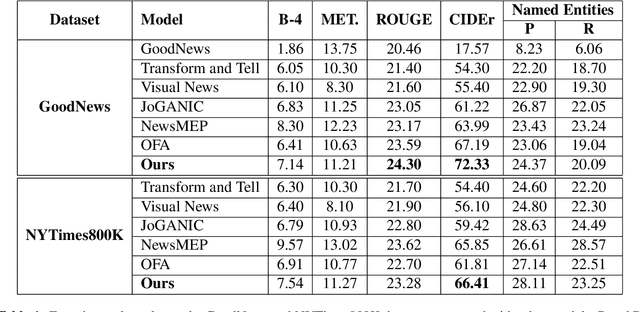
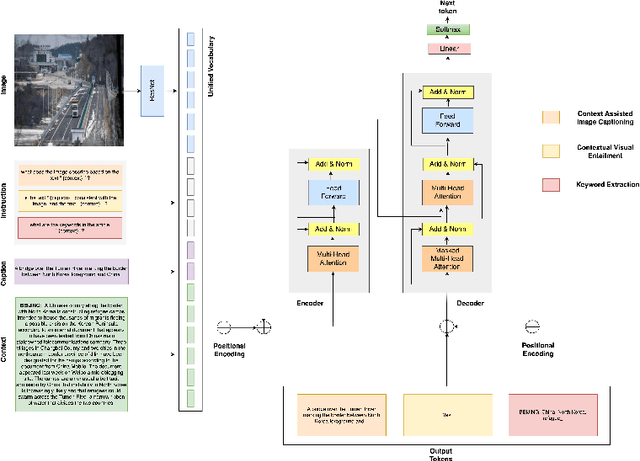
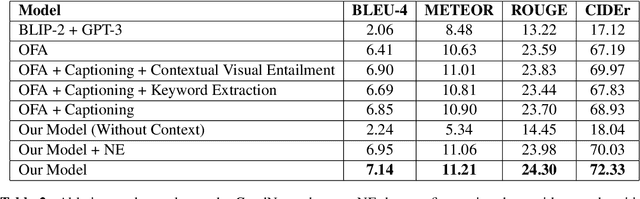
Well-formed context aware image captions and tags in enterprise content such as marketing material are critical to ensure their brand presence and content recall. Manual creation and updates to ensure the same is non trivial given the scale and the tedium towards this task. We propose a new unified Vision-Language (VL) model based on the One For All (OFA) model, with a focus on context-assisted image captioning where the caption is generated based on both the image and its context. Our approach aims to overcome the context-independent (image and text are treated independently) nature of the existing approaches. We exploit context by pretraining our model with datasets of three tasks: news image captioning where the news article is the context, contextual visual entailment, and keyword extraction from the context. The second pretraining task is a new VL task, and we construct and release two datasets for the task with 1.1M and 2.2K data instances. Our system achieves state-of-the-art results with an improvement of up to 8.34 CIDEr score on the benchmark news image captioning datasets. To the best of our knowledge, ours is the first effort at incorporating contextual information in pretraining the models for the VL tasks.
Study for Performance of MobileNetV1 and MobileNetV2 Based on Breast Cancer
Aug 06, 2023Artificial intelligence is constantly evolving and can provide effective help in all aspects of people's lives. The experiment is mainly to study the use of artificial intelligence in the field of medicine. The purpose of this experiment was to compare which of MobileNetV1 and MobileNetV2 models was better at detecting histopathological images of the breast downloaded at Kaggle. When the doctor looks at the pathological image, there may be errors that lead to errors in judgment, and the observation speed is slow. Rational use of artificial intelligence can effectively reduce the error of doctor diagnosis in breast cancer judgment and speed up doctor diagnosis. The dataset was downloaded from Kaggle and then normalized. The basic principle of the experiment is to let the neural network model learn the downloaded data set. Then find the pattern and be able to judge on your own whether breast tissue is cancer. In the dataset, benign tumor pictures and malignant tumor pictures have been classified, of which 198738 are benign tumor pictures and 78, 786 are malignant tumor pictures. After calling MobileNetV1 and MobileNetV2, the dataset is trained separately, the training accuracy and validation accuracy rate are obtained, and the image is drawn. It can be observed that MobileNetV1 has better validation accuracy and overfit during MobileNetV2 training. From the experimental results, it can be seen that in the case of processing this dataset, MobileNetV1 is much better than MobileNetV2.
SAMFlow: Eliminating Any Fragmentation in Optical Flow with Segment Anything Model
Aug 16, 2023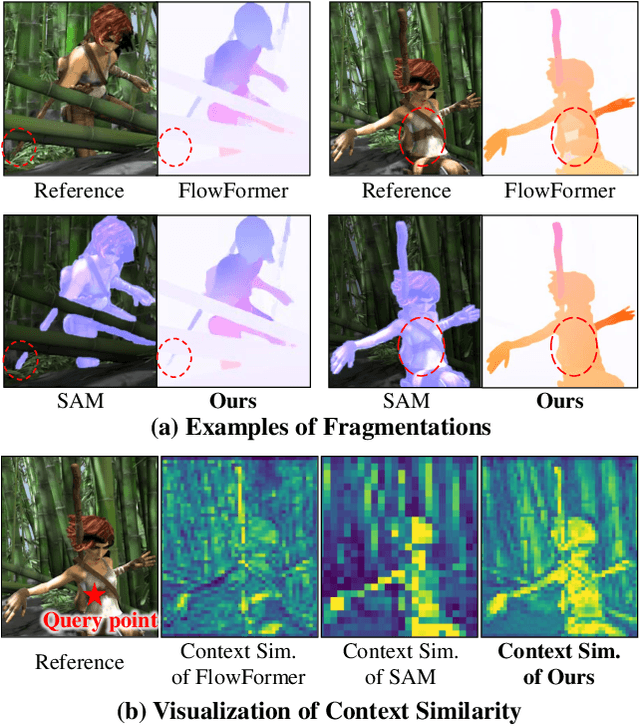
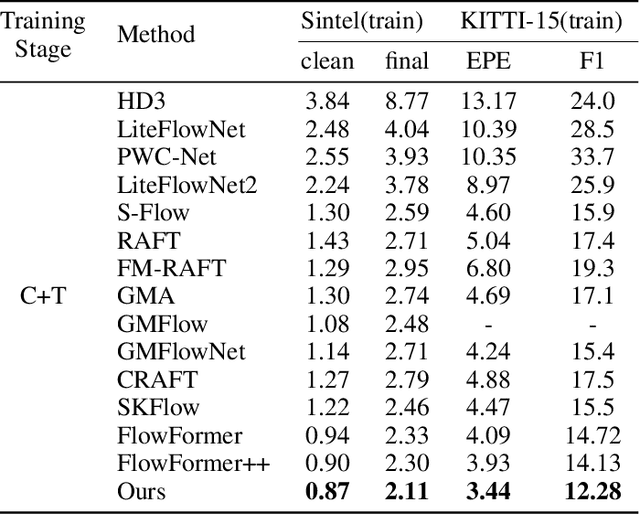

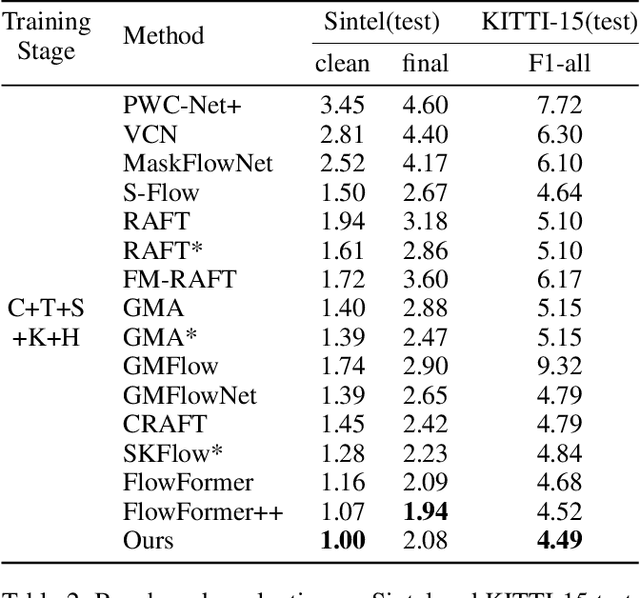
Optical Flow Estimation aims to find the 2D dense motion field between two frames. Due to the limitation of model structures and training datasets, existing methods often rely too much on local clues and ignore the integrity of objects, resulting in fragmented motion estimation. Through theoretical analysis, we find the pre-trained large vision models are helpful in optical flow estimation, and we notice that the recently famous Segment Anything Model (SAM) demonstrates a strong ability to segment complete objects, which is suitable for solving the fragmentation problem. We thus propose a solution to embed the frozen SAM image encoder into FlowFormer to enhance object perception. To address the challenge of in-depth utilizing SAM in non-segmentation tasks like optical flow estimation, we propose an Optical Flow Task-Specific Adaption scheme, including a Context Fusion Module to fuse the SAM encoder with the optical flow context encoder, and a Context Adaption Module to adapt the SAM features for optical flow task with Learned Task-Specific Embedding. Our proposed SAMFlow model reaches 0.86/2.10 clean/final EPE and 3.55/12.32 EPE/F1-all on Sintel and KITTI-15 training set, surpassing Flowformer by 8.5%/9.9% and 13.2%/16.3%. Furthermore, our model achieves state-of-the-art performance on the Sintel and KITTI-15 benchmarks, ranking #1 among all two-frame methods on Sintel clean pass.