 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Temporal Uncertainty Localization to Enable Human-in-the-loop Analysis of Dynamic Contrast-enhanced Cardiac MRI Datasets
Aug 25, 2023
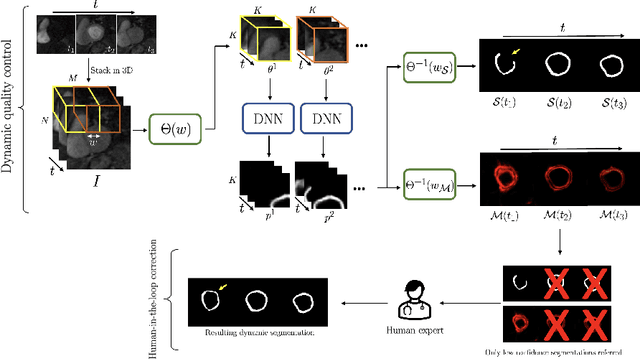

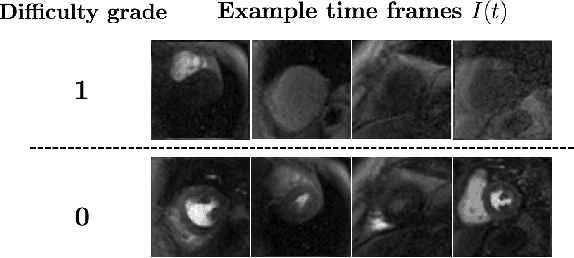
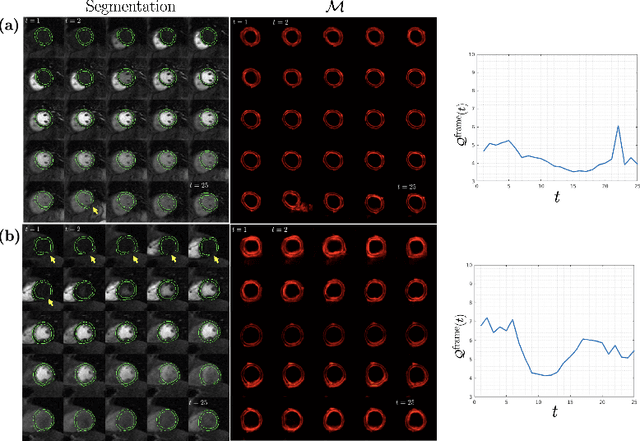
Dynamic contrast-enhanced (DCE) cardiac magnetic resonance imaging (CMRI) is a widely used modality for diagnosing myocardial blood flow (perfusion) abnormalities. During a typical free-breathing DCE-CMRI scan, close to 300 time-resolved images of myocardial perfusion are acquired at various contrast "wash in/out" phases. Manual segmentation of myocardial contours in each time-frame of a DCE image series can be tedious and time-consuming, particularly when non-rigid motion correction has failed or is unavailable. While deep neural networks (DNNs) have shown promise for analyzing DCE-CMRI datasets, a "dynamic quality control" (dQC) technique for reliably detecting failed segmentations is lacking. Here we propose a new space-time uncertainty metric as a dQC tool for DNN-based segmentation of free-breathing DCE-CMRI datasets by validating the proposed metric on an external dataset and establishing a human-in-the-loop framework to improve the segmentation results. In the proposed approach, we referred the top 10% most uncertain segmentations as detected by our dQC tool to the human expert for refinement. This approach resulted in a significant increase in the Dice score (p<0.001) and a notable decrease in the number of images with failed segmentation (16.2% to 11.3%) whereas the alternative approach of randomly selecting the same number of segmentations for human referral did not achieve any significant improvement. Our results suggest that the proposed dQC framework has the potential to accurately identify poor-quality segmentations and may enable efficient DNN-based analysis of DCE-CMRI in a human-in-the-loop pipeline for clinical interpretation and reporting of dynamic CMRI datasets.
HQ-50K: A Large-scale, High-quality Dataset for Image Restoration
Jun 08, 2023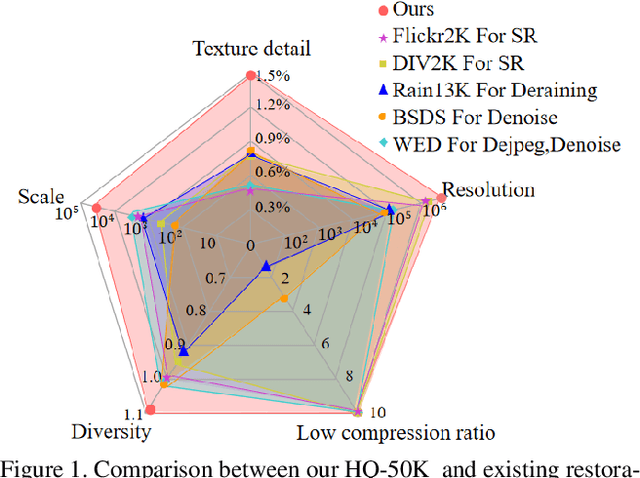
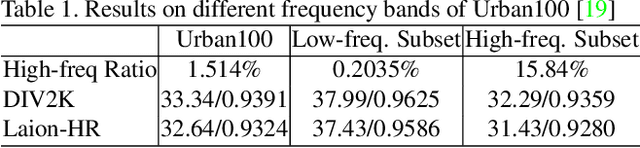
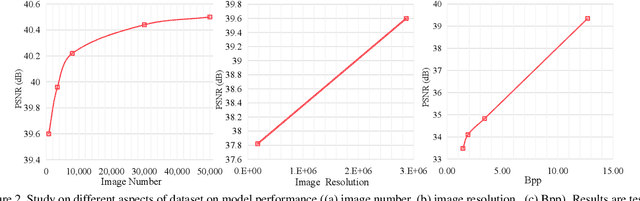

This paper introduces a new large-scale image restoration dataset, called HQ-50K, which contains 50,000 high-quality images with rich texture details and semantic diversity. We analyze existing image restoration datasets from five different perspectives, including data scale, resolution, compression rates, texture details, and semantic coverage. However, we find that all of these datasets are deficient in some aspects. In contrast, HQ-50K considers all of these five aspects during the data curation process and meets all requirements. We also present a new Degradation-Aware Mixture of Expert (DAMoE) model, which enables a single model to handle multiple corruption types and unknown levels. Our extensive experiments demonstrate that HQ-50K consistently improves the performance on various image restoration tasks, such as super-resolution, denoising, dejpeg, and deraining. Furthermore, our proposed DAMoE, trained on our \dataset, outperforms existing state-of-the-art unified models designed for multiple restoration tasks and levels. The dataset and code are available at \url{https://github.com/littleYaang/HQ-50K}.
IFaceUV: Intuitive Motion Facial Image Generation by Identity Preservation via UV map
Jun 08, 2023
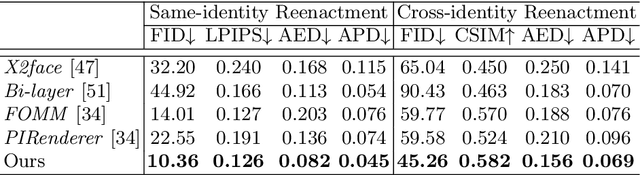
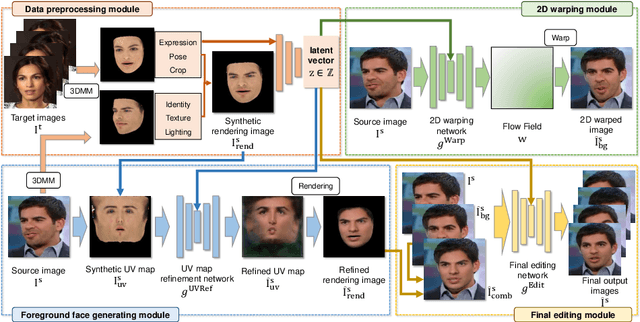
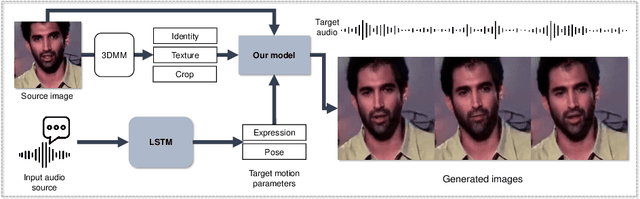
Reenacting facial images is an important task that can find numerous applications. We proposed IFaceUV, a fully differentiable pipeline that properly combines 2D and 3D information to conduct the facial reenactment task. The three-dimensional morphable face models (3DMMs) and corresponding UV maps are utilized to intuitively control facial motions and textures, respectively. Two-dimensional techniques based on 2D image warping is further required to compensate for missing components of the 3DMMs such as backgrounds, ear, hair and etc. In our pipeline, we first extract 3DMM parameters and corresponding UV maps from source and target images. Then, initial UV maps are refined by the UV map refinement network and it is rendered to the image with the motion manipulated 3DMM parameters. In parallel, we warp the source image according to the 2D flow field obtained from the 2D warping network. Rendered and warped images are combined in the final editing network to generate the final reenactment image. Additionally, we tested our model for the audio-driven facial reenactment task. Extensive qualitative and quantitative experiments illustrate the remarkable performance of our method compared to other state-of-the-art methods.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 26, 2023
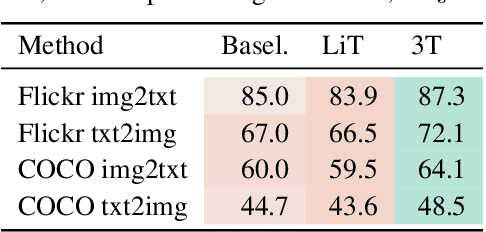
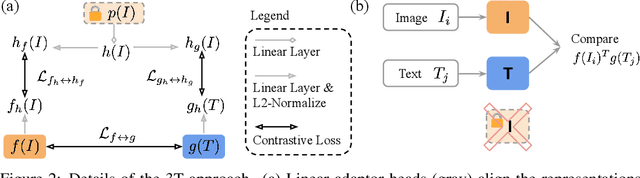
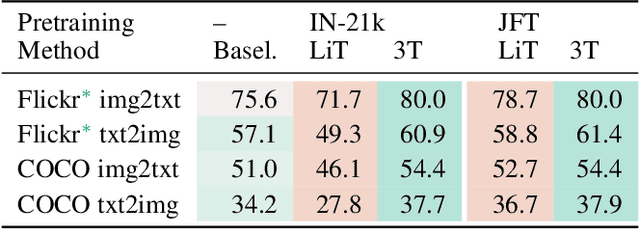
We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
ResBuilder: Automated Learning of Depth with Residual Structures
Aug 16, 2023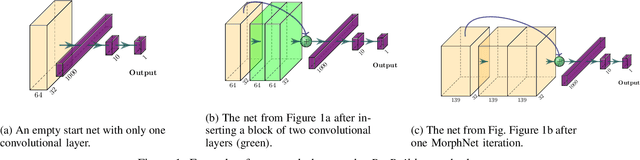
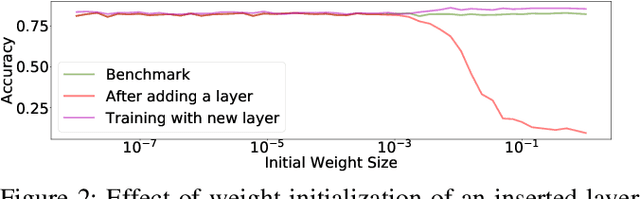
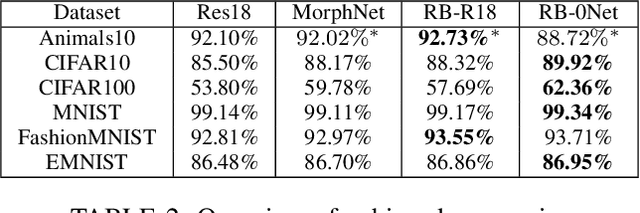
In this work, we develop a neural architecture search algorithm, termed Resbuilder, that develops ResNet architectures from scratch that achieve high accuracy at moderate computational cost. It can also be used to modify existing architectures and has the capability to remove and insert ResNet blocks, in this way searching for suitable architectures in the space of ResNet architectures. In our experiments on different image classification datasets, Resbuilder achieves close to state-of-the-art performance while saving computational cost compared to off-the-shelf ResNets. Noteworthy, we once tune the parameters on CIFAR10 which yields a suitable default choice for all other datasets. We demonstrate that this property generalizes even to industrial applications by applying our method with default parameters on a proprietary fraud detection dataset.
Neural Video Depth Stabilizer
Aug 10, 2023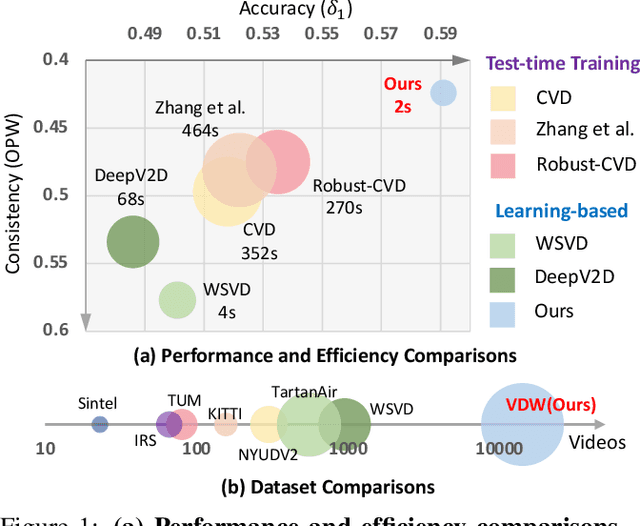
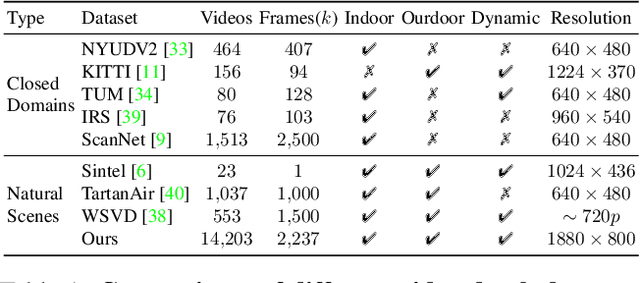
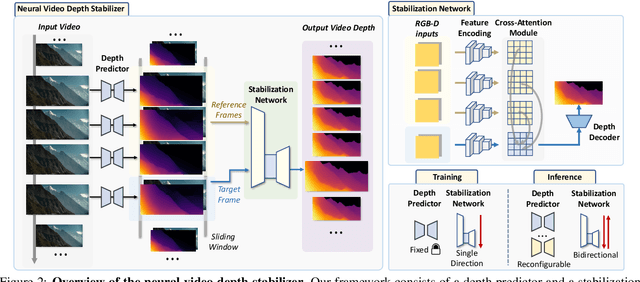
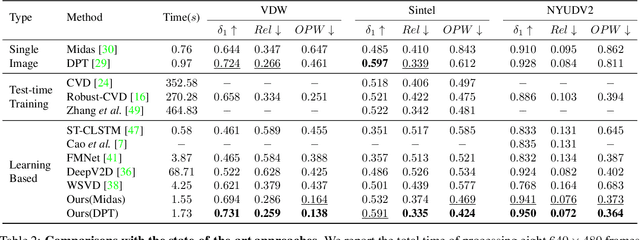
Video depth estimation aims to infer temporally consistent depth. Some methods achieve temporal consistency by finetuning a single-image depth model during test time using geometry and re-projection constraints, which is inefficient and not robust. An alternative approach is to learn how to enforce temporal consistency from data, but this requires well-designed models and sufficient video depth data. To address these challenges, we propose a plug-and-play framework called Neural Video Depth Stabilizer (NVDS) that stabilizes inconsistent depth estimations and can be applied to different single-image depth models without extra effort. We also introduce a large-scale dataset, Video Depth in the Wild (VDW), which consists of 14,203 videos with over two million frames, making it the largest natural-scene video depth dataset to our knowledge. We evaluate our method on the VDW dataset as well as two public benchmarks and demonstrate significant improvements in consistency, accuracy, and efficiency compared to previous approaches. Our work serves as a solid baseline and provides a data foundation for learning-based video depth models. We will release our dataset and code for future research.
Attention-based 3D CNN with Multi-layer Features for Alzheimer's Disease Diagnosis using Brain Images
Aug 10, 2023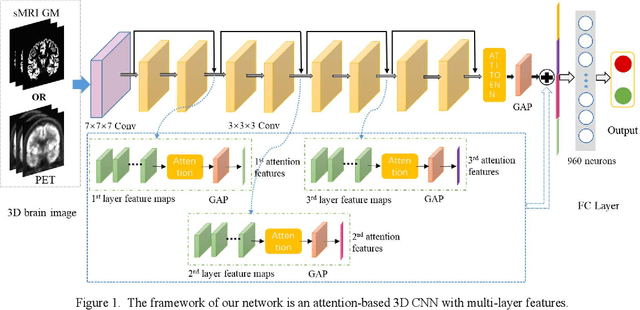
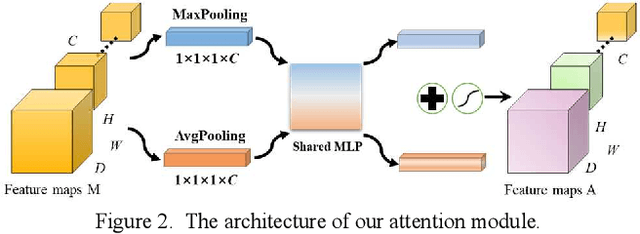

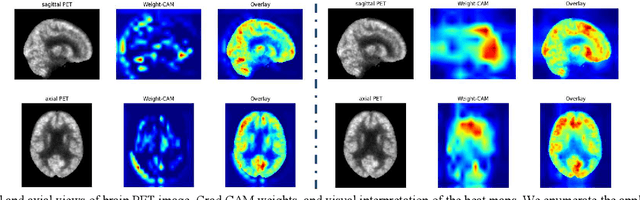
Structural MRI and PET imaging play an important role in the diagnosis of Alzheimer's disease (AD), showing the morphological changes and glucose metabolism changes in the brain respectively. The manifestations in the brain image of some cognitive impairment patients are relatively inconspicuous, for example, it still has difficulties in achieving accurate diagnosis through sMRI in clinical practice. With the emergence of deep learning, convolutional neural network (CNN) has become a valuable method in AD-aided diagnosis, but some CNN methods cannot effectively learn the features of brain image, making the diagnosis of AD still presents some challenges. In this work, we propose an end-to-end 3D CNN framework for AD diagnosis based on ResNet, which integrates multi-layer features obtained under the effect of the attention mechanism to better capture subtle differences in brain images. The attention maps showed our model can focus on key brain regions related to the disease diagnosis. Our method was verified in ablation experiments with two modality images on 792 subjects from the ADNI database, where AD diagnostic accuracies of 89.71% and 91.18% were achieved based on sMRI and PET respectively, and also outperformed some state-of-the-art methods.
* 4 pages, 4 figures
A Diffusion Probabilistic Prior for Low-Dose CT Image Denoising
May 25, 2023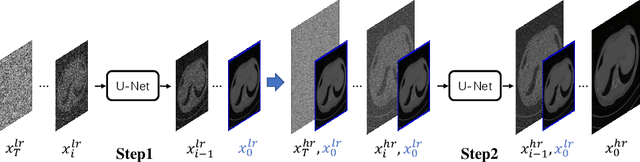

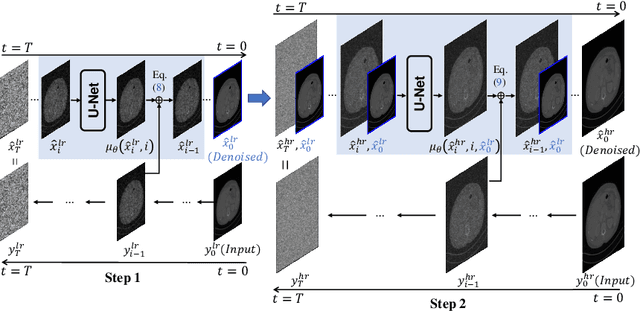

Low-dose computed tomography (CT) image denoising is crucial in medical image computing. Recent years have been remarkable improvement in deep learning-based methods for this task. However, training deep denoising neural networks requires low-dose and normal-dose CT image pairs, which are difficult to obtain in the clinic settings. To address this challenge, we propose a novel fully unsupervised method for low-dose CT image denoising, which is based on denoising diffusion probabilistic model -- a powerful generative model. First, we train an unconditional denoising diffusion probabilistic model capable of generating high-quality normal-dose CT images from random noise. Subsequently, the probabilistic priors of the pre-trained diffusion model are incorporated into a Maximum A Posteriori (MAP) estimation framework for iteratively solving the image denoising problem. Our method ensures the diffusion model produces high-quality normal-dose CT images while keeping the image content consistent with the input low-dose CT images. We evaluate our method on a widely used low-dose CT image denoising benchmark, and it outperforms several supervised low-dose CT image denoising methods in terms of both quantitative and visual performance.
Equivariant Multi-Modality Image Fusion
May 19, 2023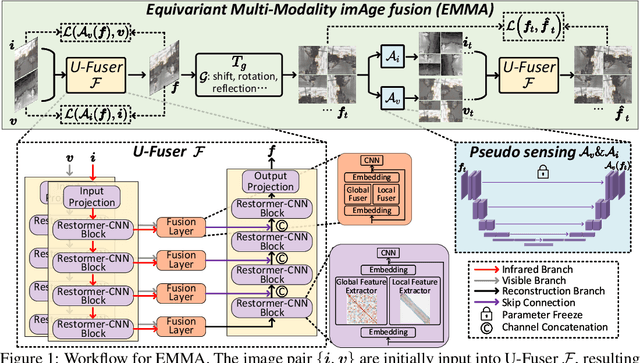
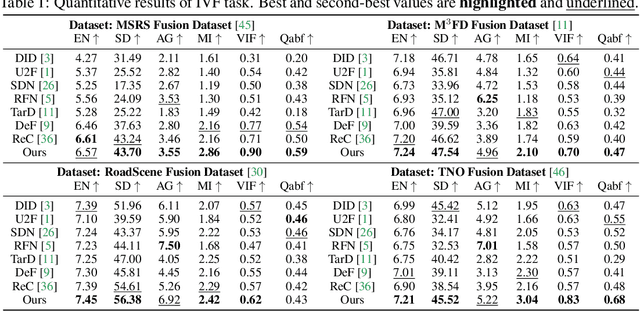


Multi-modality image fusion is a technique used to combine information from different sensors or modalities, allowing the fused image to retain complementary features from each modality, such as functional highlights and texture details. However, effectively training such fusion models is difficult due to the lack of ground truth fusion data. To address this issue, we propose the Equivariant Multi-Modality imAge fusion (EMMA) paradigm for end-to-end self-supervised learning. Our approach is based on the prior knowledge that natural images are equivariant to specific transformations. Thus, we introduce a novel training framework that includes a fusion module and a learnable pseudo-sensing module, which allow the network training to follow the principles of physical sensing and imaging process, and meanwhile satisfy the equivariant prior for natural images. Our extensive experiments demonstrate that our method produces high-quality fusion results for both infrared-visible and medical images, while facilitating downstream multi-modal segmentation and detection tasks. The code will be released.
Learnable Weight Initialization for Volumetric Medical Image Segmentation
Jun 19, 2023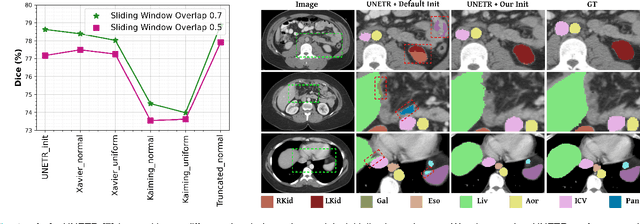
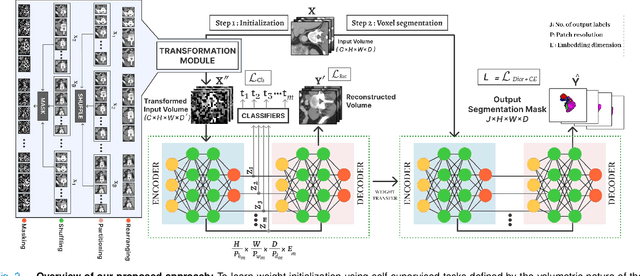
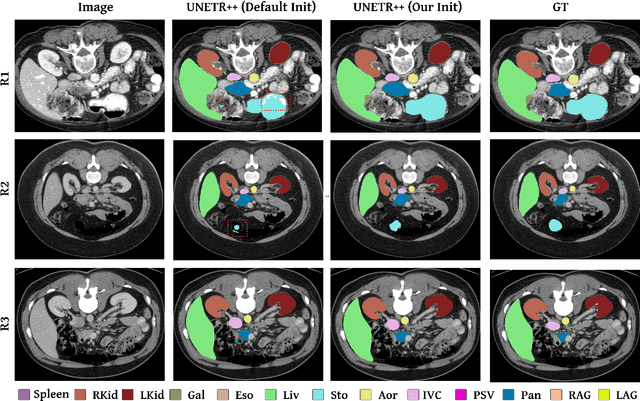
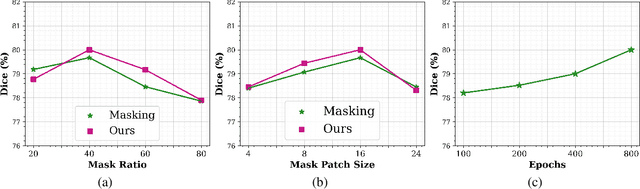
Hybrid volumetric medical image segmentation models, combining the advantages of local convolution and global attention, have recently received considerable attention. While mainly focusing on architectural modifications, most existing hybrid approaches still use conventional data-independent weight initialization schemes which restrict their performance due to ignoring the inherent volumetric nature of the medical data. To address this issue, we propose a learnable weight initialization approach that utilizes the available medical training data to effectively learn the contextual and structural cues via the proposed self-supervised objectives. Our approach is easy to integrate into any hybrid model and requires no external training data. Experiments on multi-organ and lung cancer segmentation tasks demonstrate the effectiveness of our approach, leading to state-of-the-art segmentation performance. Our source code and models are available at: https://github.com/ShahinaKK/LWI-VMS.