 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AC-Norm: Effective Tuning for Medical Image Analysis via Affine Collaborative Normalization
Jul 28, 2023
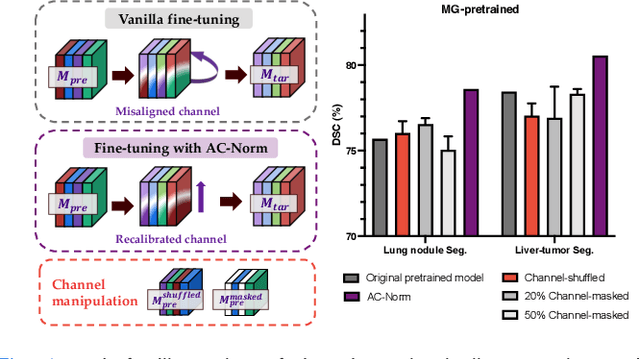
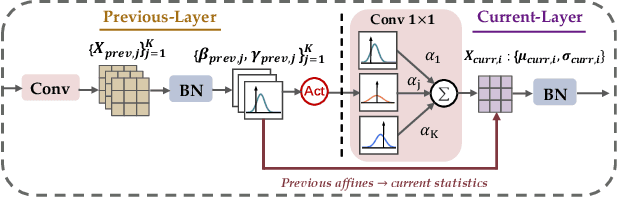
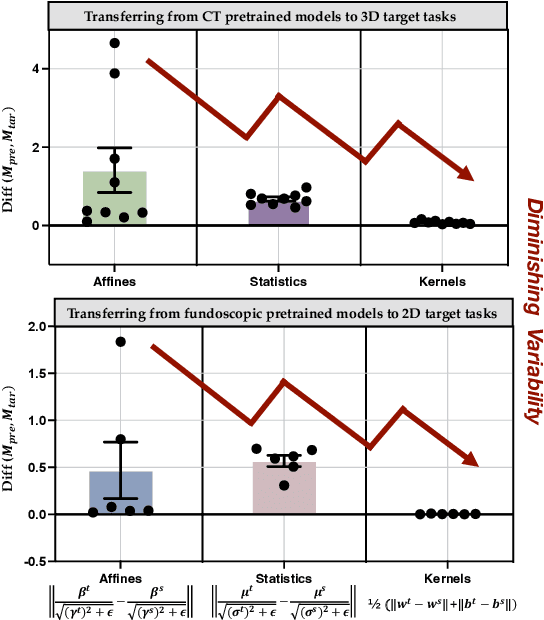
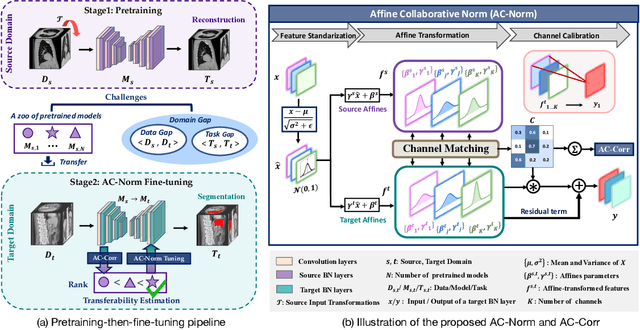
Driven by the latest trend towards self-supervised learning (SSL), the paradigm of "pretraining-then-finetuning" has been extensively explored to enhance the performance of clinical applications with limited annotations. Previous literature on model finetuning has mainly focused on regularization terms and specific policy models, while the misalignment of channels between source and target models has not received sufficient attention. In this work, we revisited the dynamics of batch normalization (BN) layers and observed that the trainable affine parameters of BN serve as sensitive indicators of domain information. Therefore, Affine Collaborative Normalization (AC-Norm) is proposed for finetuning, which dynamically recalibrates the channels in the target model according to the cross-domain channel-wise correlations without adding extra parameters. Based on a single-step backpropagation, AC-Norm can also be utilized to measure the transferability of pretrained models. We evaluated AC-Norm against the vanilla finetuning and state-of-the-art fine-tuning methods on transferring diverse pretrained models to the diabetic retinopathy grade classification, retinal vessel segmentation, CT lung nodule segmentation/classification, CT liver-tumor segmentation and MRI cardiac segmentation tasks. Extensive experiments demonstrate that AC-Norm unanimously outperforms the vanilla finetuning by up to 4% improvement, even under significant domain shifts where the state-of-the-art methods bring no gains. We also prove the capability of AC-Norm in fast transferability estimation. Our code is available at https://github.com/EndoluminalSurgicalVision-IMR/ACNorm.
Integrating Geometric Control into Text-to-Image Diffusion Models for High-Quality Detection Data Generation via Text Prompt
Jun 09, 2023
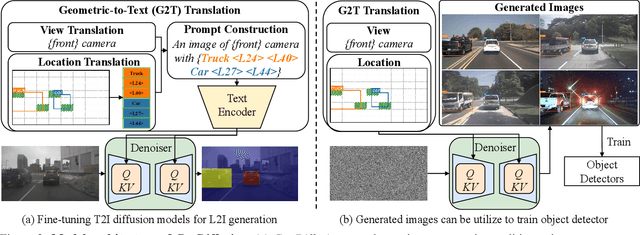
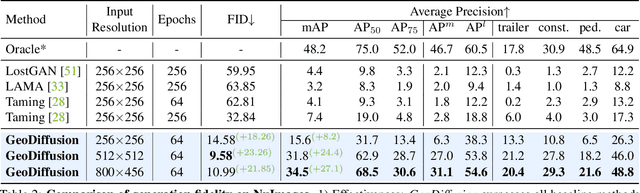
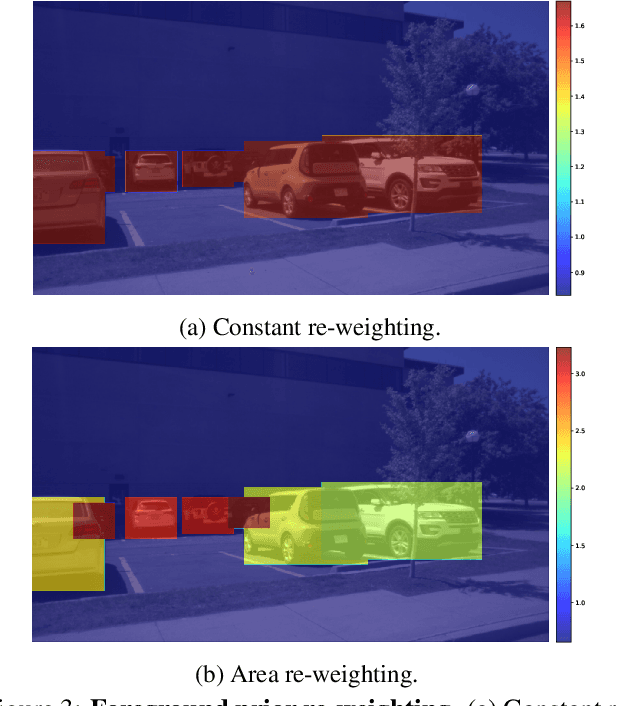
Diffusion models have attracted significant attention due to their remarkable ability to create content and generate data for tasks such as image classification. However, the usage of diffusion models to generate high-quality object detection data remains an underexplored area, where not only the image-level perceptual quality but also geometric conditions such as bounding boxes and camera views are essential. Previous studies have utilized either copy-paste synthesis or layout-to-image (L2I) generation with specifically designed modules to encode semantic layouts. In this paper, we propose GeoDiffusion, a simple framework that can flexibly translate various geometric conditions into text prompts and empower the pre-trained text-to-image (T2I) diffusion models for high-quality detection data generation. Unlike previous L2I methods, our GeoDiffusion is able to encode not only bounding boxes but also extra geometric conditions such as camera views in self-driving scenes. Extensive experiments demonstrate GeoDiffusion outperforms previous L2I methods while maintaining 4x training time faster. To the best of our knowledge, this is the first work to adopt diffusion models for layout-to-image generation with geometric conditions and demonstrate that L2I-generated images can be beneficial for improving the performance of object detectors.
Maximal Independent Sets for Pooling in Graph Neural Networks
Jul 24, 2023

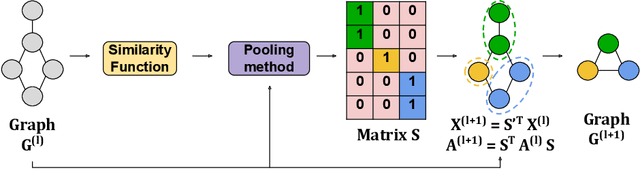
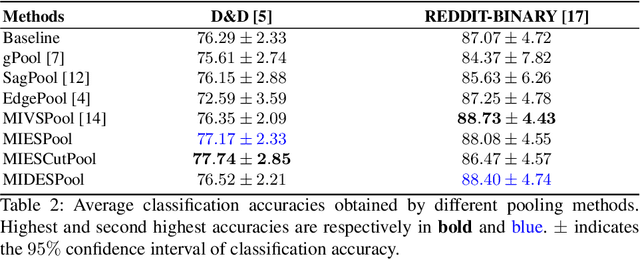
Convolutional Neural Networks (CNNs) have enabled major advances in image classification through convolution and pooling. In particular, image pooling transforms a connected discrete lattice into a reduced lattice with the same connectivity and allows reduction functions to consider all pixels in an image. However, there is no pooling that satisfies these properties for graphs. In fact, traditional graph pooling methods suffer from at least one of the following drawbacks: Graph disconnection or overconnection, low decimation ratio, and deletion of large parts of graphs. In this paper, we present three pooling methods based on the notion of maximal independent sets that avoid these pitfalls. Our experimental results confirm the relevance of maximal independent set constraints for graph pooling.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023


Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
Aug 15, 2023
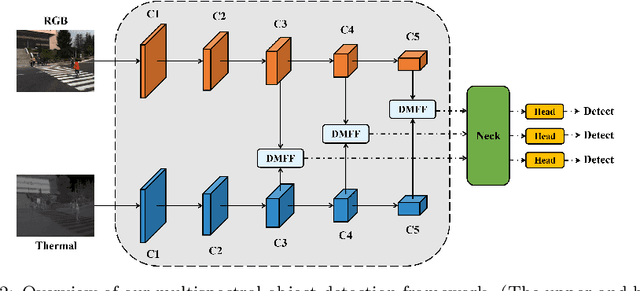
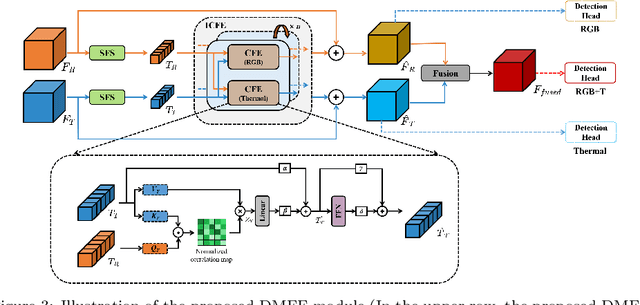
Effective feature fusion of multispectral images plays a crucial role in multi-spectral object detection. Previous studies have demonstrated the effectiveness of feature fusion using convolutional neural networks, but these methods are sensitive to image misalignment due to the inherent deffciency in local-range feature interaction resulting in the performance degradation. To address this issue, a novel feature fusion framework of dual cross-attention transformers is proposed to model global feature interaction and capture complementary information across modalities simultaneously. This framework enhances the discriminability of object features through the query-guided cross-attention mechanism, leading to improved performance. However, stacking multiple transformer blocks for feature enhancement incurs a large number of parameters and high spatial complexity. To handle this, inspired by the human process of reviewing knowledge, an iterative interaction mechanism is proposed to share parameters among block-wise multimodal transformers, reducing model complexity and computation cost. The proposed method is general and effective to be integrated into different detection frameworks and used with different backbones. Experimental results on KAIST, FLIR, and VEDAI datasets show that the proposed method achieves superior performance and faster inference, making it suitable for various practical scenarios. Code will be available at https://github.com/chanchanchan97/ICAFusion.
Ske2Grid: Skeleton-to-Grid Representation Learning for Action Recognition
Aug 15, 2023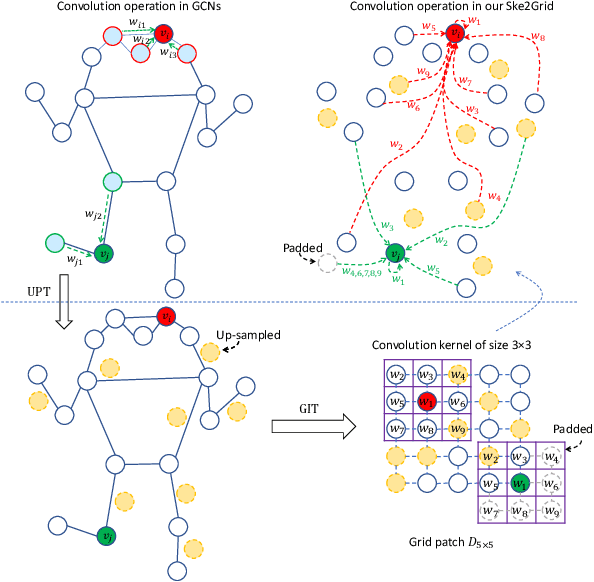
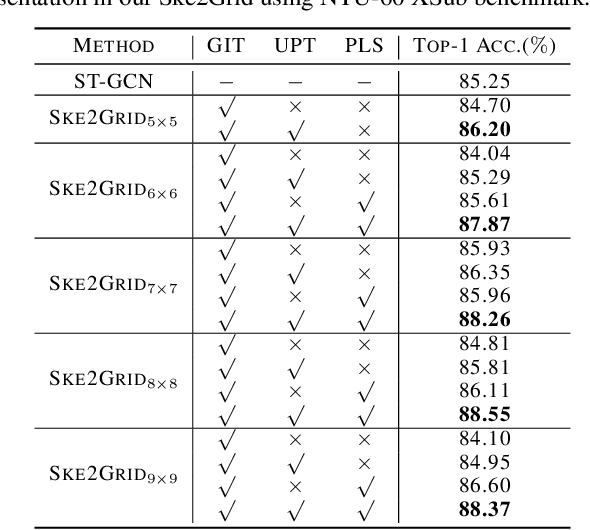
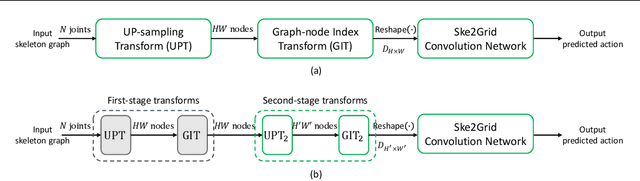
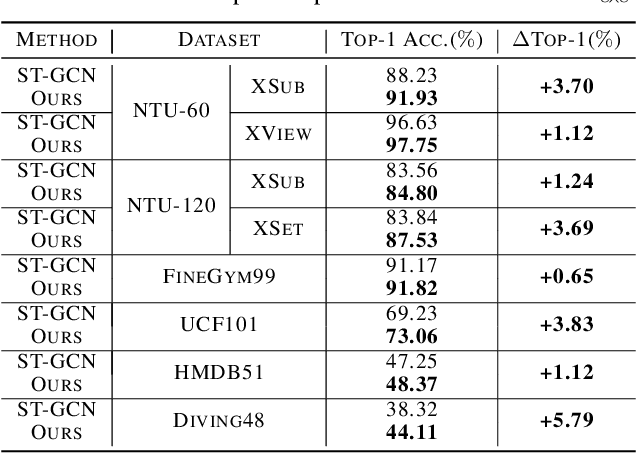
This paper presents Ske2Grid, a new representation learning framework for improved skeleton-based action recognition. In Ske2Grid, we define a regular convolution operation upon a novel grid representation of human skeleton, which is a compact image-like grid patch constructed and learned through three novel designs. Specifically, we propose a graph-node index transform (GIT) to construct a regular grid patch through assigning the nodes in the skeleton graph one by one to the desired grid cells. To ensure that GIT is a bijection and enrich the expressiveness of the grid representation, an up-sampling transform (UPT) is learned to interpolate the skeleton graph nodes for filling the grid patch to the full. To resolve the problem when the one-step UPT is aggressive and further exploit the representation capability of the grid patch with increasing spatial size, a progressive learning strategy (PLS) is proposed which decouples the UPT into multiple steps and aligns them to multiple paired GITs through a compact cascaded design learned progressively. We construct networks upon prevailing graph convolution networks and conduct experiments on six mainstream skeleton-based action recognition datasets. Experiments show that our Ske2Grid significantly outperforms existing GCN-based solutions under different benchmark settings, without bells and whistles. Code and models are available at https://github.com/OSVAI/Ske2Grid
Inversion-by-Inversion: Exemplar-based Sketch-to-Photo Synthesis via Stochastic Differential Equations without Training
Aug 15, 2023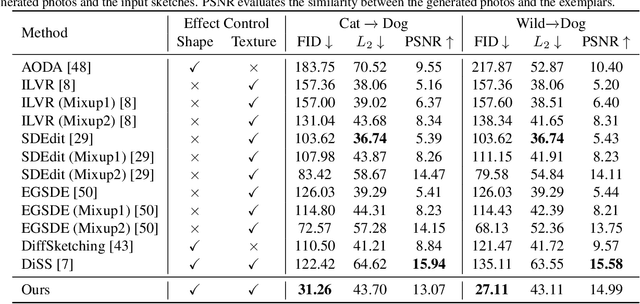
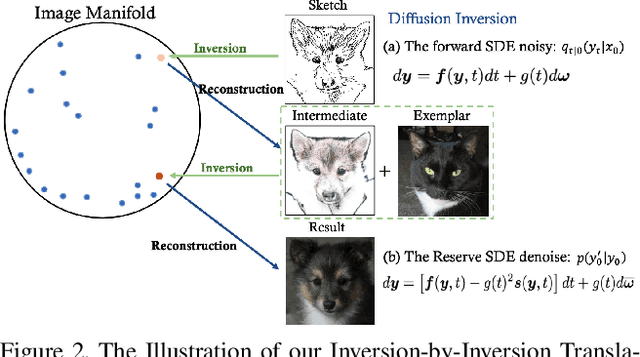
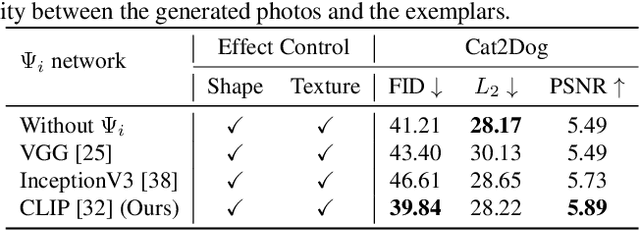
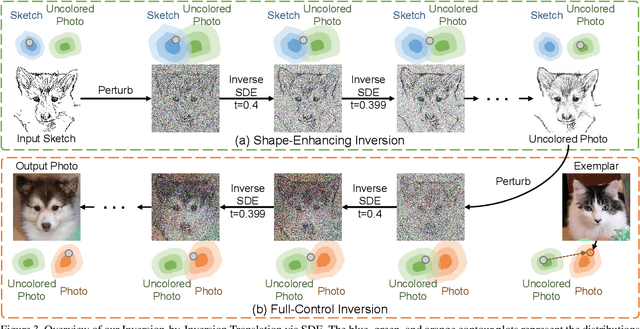
Exemplar-based sketch-to-photo synthesis allows users to generate photo-realistic images based on sketches. Recently, diffusion-based methods have achieved impressive performance on image generation tasks, enabling highly-flexible control through text-driven generation or energy functions. However, generating photo-realistic images with color and texture from sketch images remains challenging for diffusion models. Sketches typically consist of only a few strokes, with most regions left blank, making it difficult for diffusion-based methods to produce photo-realistic images. In this work, we propose a two-stage method named ``Inversion-by-Inversion" for exemplar-based sketch-to-photo synthesis. This approach includes shape-enhancing inversion and full-control inversion. During the shape-enhancing inversion process, an uncolored photo is generated with the guidance of a shape-energy function. This step is essential to ensure control over the shape of the generated photo. In the full-control inversion process, we propose an appearance-energy function to control the color and texture of the final generated photo.Importantly, our Inversion-by-Inversion pipeline is training-free and can accept different types of exemplars for color and texture control. We conducted extensive experiments to evaluate our proposed method, and the results demonstrate its effectiveness.
Optimizing Performance of Feedforward and Convolutional Neural Networks through Dynamic Activation Functions
Aug 10, 2023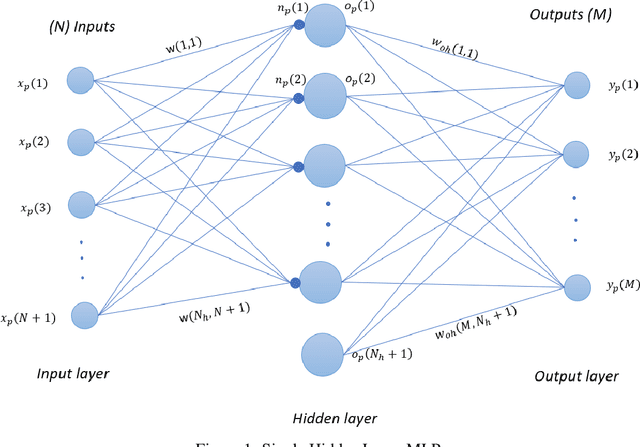
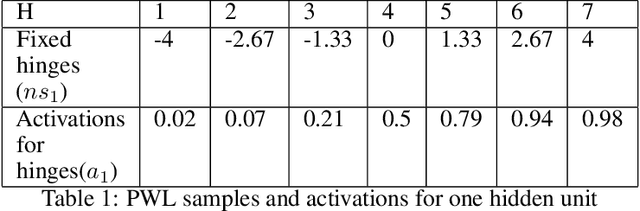
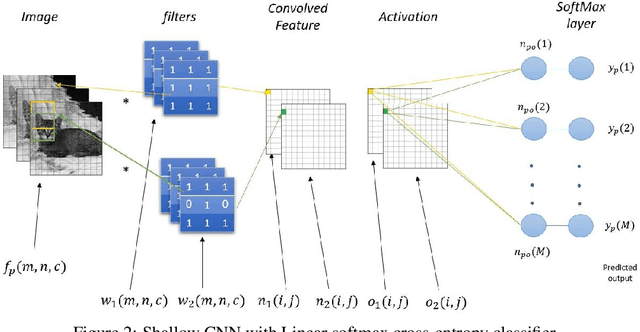
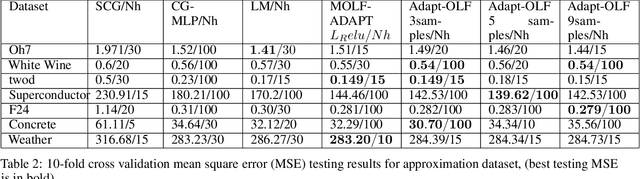
Deep learning training training algorithms are a huge success in recent years in many fields including speech, text,image video etc. Deeper and deeper layers are proposed with huge success with resnet structures having around 152 layers. Shallow convolution neural networks(CNN's) are still an active research, where some phenomena are still unexplained. Activation functions used in the network are of utmost importance, as they provide non linearity to the networks. Relu's are the most commonly used activation function.We show a complex piece-wise linear(PWL) activation in the hidden layer. We show that these PWL activations work much better than relu activations in our networks for convolution neural networks and multilayer perceptrons. Result comparison in PyTorch for shallow and deep CNNs are given to further strengthen our case.
Approximate and Weighted Data Reconstruction Attack in Federated Learning
Aug 13, 2023Federated Learning (FL) is a distributed learning paradigm that enables multiple clients to collaborate on building a machine learning model without sharing their private data. Although FL is considered privacy-preserved by design, recent data reconstruction attacks demonstrate that an attacker can recover clients' training data based on the parameters shared in FL. However, most existing methods fail to attack the most widely used horizontal Federated Averaging (FedAvg) scenario, where clients share model parameters after multiple local training steps. To tackle this issue, we propose an interpolation-based approximation method, which makes attacking FedAvg scenarios feasible by generating the intermediate model updates of the clients' local training processes. Then, we design a layer-wise weighted loss function to improve the data quality of reconstruction. We assign different weights to model updates in different layers concerning the neural network structure, with the weights tuned by Bayesian optimization. Finally, experimental results validate the superiority of our proposed approximate and weighted attack (AWA) method over the other state-of-the-art methods, as demonstrated by the substantial improvement in different evaluation metrics for image data reconstructions.
Neural Networks at a Fraction with Pruned Quaternions
Aug 13, 2023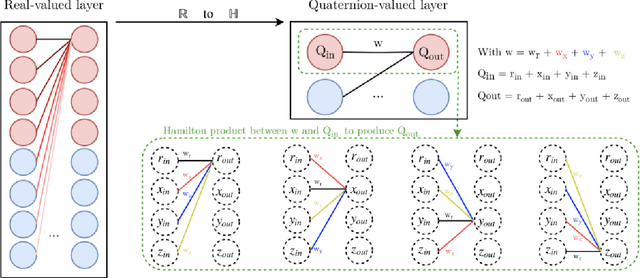
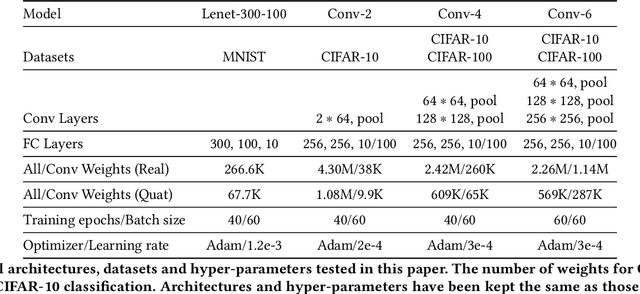
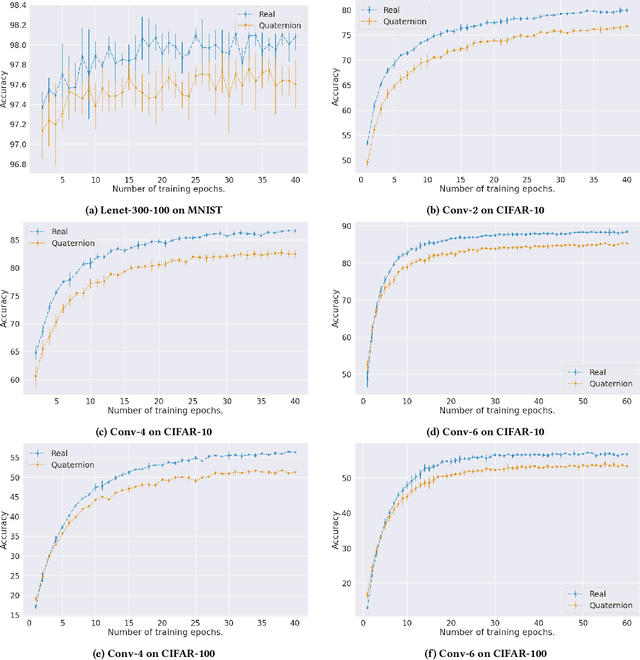
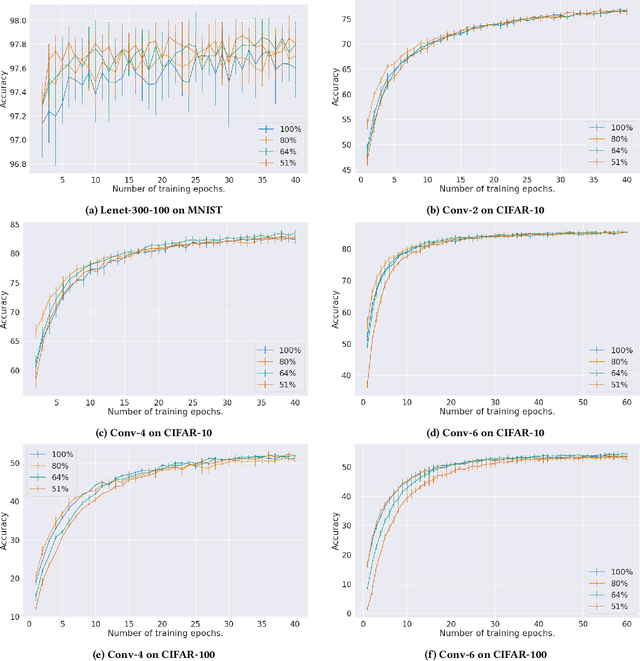
Contemporary state-of-the-art neural networks have increasingly large numbers of parameters, which prevents their deployment on devices with limited computational power. Pruning is one technique to remove unnecessary weights and reduce resource requirements for training and inference. In addition, for ML tasks where the input data is multi-dimensional, using higher-dimensional data embeddings such as complex numbers or quaternions has been shown to reduce the parameter count while maintaining accuracy. In this work, we conduct pruning on real and quaternion-valued implementations of different architectures on classification tasks. We find that for some architectures, at very high sparsity levels, quaternion models provide higher accuracies than their real counterparts. For example, at the task of image classification on CIFAR-10 using Conv-4, at $3\%$ of the number of parameters as the original model, the pruned quaternion version outperforms the pruned real by more than $10\%$. Experiments on various network architectures and datasets show that for deployment in extremely resource-constrained environments, a sparse quaternion network might be a better candidate than a real sparse model of similar architecture.