 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computer vision-enriched discrete choice models, with an application to residential location choice
Aug 16, 2023
Visual imagery is indispensable to many multi-attribute decision situations. Examples of such decision situations in travel behaviour research include residential location choices, vehicle choices, tourist destination choices, and various safety-related choices. However, current discrete choice models cannot handle image data and thus cannot incorporate information embedded in images into their representations of choice behaviour. This gap between discrete choice models' capabilities and the real-world behaviour it seeks to model leads to incomplete and, possibly, misleading outcomes. To solve this gap, this study proposes "Computer Vision-enriched Discrete Choice Models" (CV-DCMs). CV-DCMs can handle choice tasks involving numeric attributes and images by integrating computer vision and traditional discrete choice models. Moreover, because CV-DCMs are grounded in random utility maximisation principles, they maintain the solid behavioural foundation of traditional discrete choice models. We demonstrate the proposed CV-DCM by applying it to data obtained through a novel stated choice experiment involving residential location choices. In this experiment, respondents faced choice tasks with trade-offs between commute time, monthly housing cost and street-level conditions, presented using images. As such, this research contributes to the growing body of literature in the travel behaviour field that seeks to integrate discrete choice modelling and machine learning.
DDF-HO: Hand-Held Object Reconstruction via Conditional Directed Distance Field
Aug 16, 2023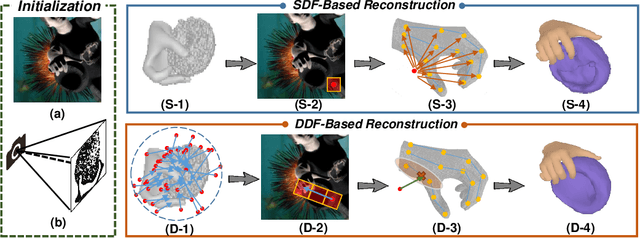
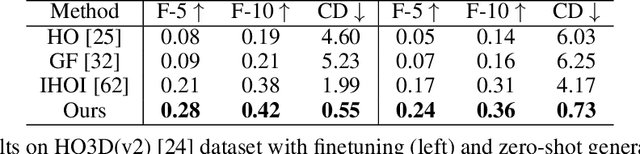

Reconstructing hand-held objects from a single RGB image is an important and challenging problem. Existing works utilizing Signed Distance Fields (SDF) reveal limitations in comprehensively capturing the complex hand-object interactions, since SDF is only reliable within the proximity of the target, and hence, infeasible to simultaneously encode local hand and object cues. To address this issue, we propose DDF-HO, a novel approach leveraging Directed Distance Field (DDF) as the shape representation. Unlike SDF, DDF maps a ray in 3D space, consisting of an origin and a direction, to corresponding DDF values, including a binary visibility signal determining whether the ray intersects the objects and a distance value measuring the distance from origin to target in the given direction. We randomly sample multiple rays and collect local to global geometric features for them by introducing a novel 2D ray-based feature aggregation scheme and a 3D intersection-aware hand pose embedding, combining 2D-3D features to model hand-object interactions. Extensive experiments on synthetic and real-world datasets demonstrate that DDF-HO consistently outperforms all baseline methods by a large margin, especially under Chamfer Distance, with about 80% leap forward. Codes and trained models will be released soon.
Whale Detection Enhancement through Synthetic Satellite Images
Aug 15, 2023
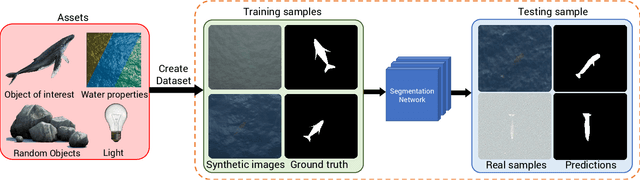
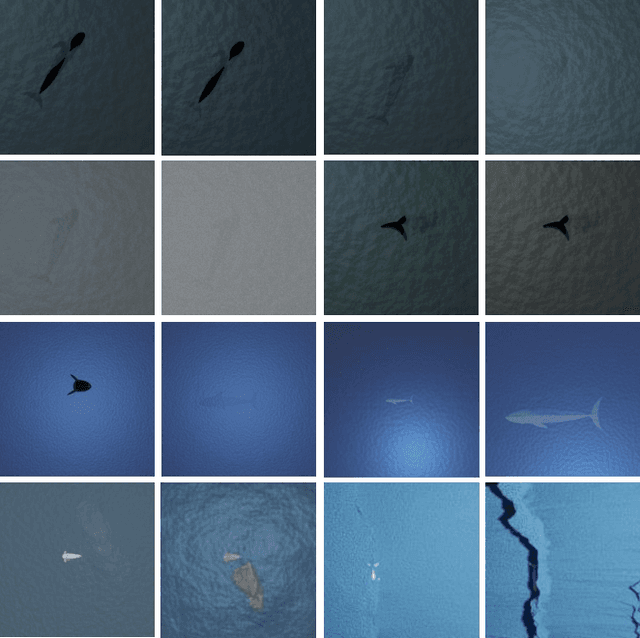

With a number of marine populations in rapid decline, collecting and analyzing data about marine populations has become increasingly important to develop effective conservation policies for a wide range of marine animals, including whales. Modern computer vision algorithms allow us to detect whales in images in a wide range of domains, further speeding up and enhancing the monitoring process. However, these algorithms heavily rely on large training datasets, which are challenging and time-consuming to collect particularly in marine or aquatic environments. Recent advances in AI however have made it possible to synthetically create datasets for training machine learning algorithms, thus enabling new solutions that were not possible before. In this work, we present a solution - SeaDroneSim2 benchmark suite, which addresses this challenge by generating aerial, and satellite synthetic image datasets to improve the detection of whales and reduce the effort required for training data collection. We show that we can achieve a 15% performance boost on whale detection compared to using the real data alone for training, by augmenting a 10% real data. We open source both the code of the simulation platform SeaDroneSim2 and the dataset generated through it.
ChartDETR: A Multi-shape Detection Network for Visual Chart Recognition
Aug 15, 2023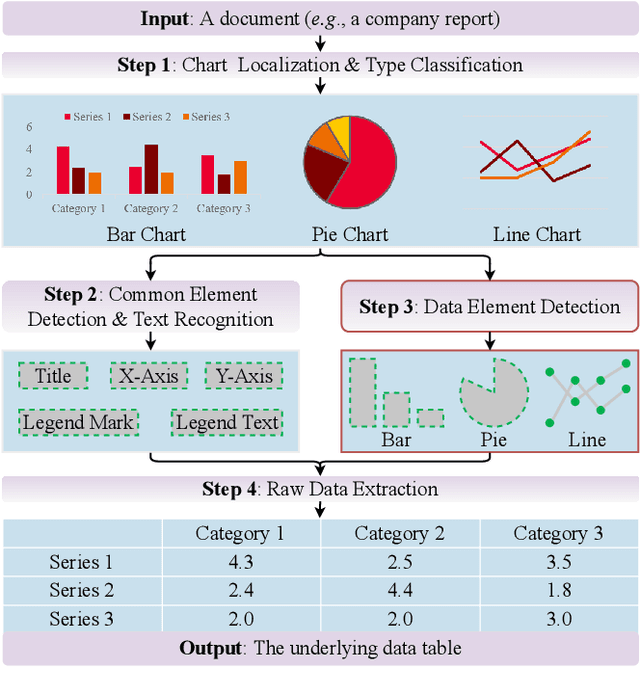
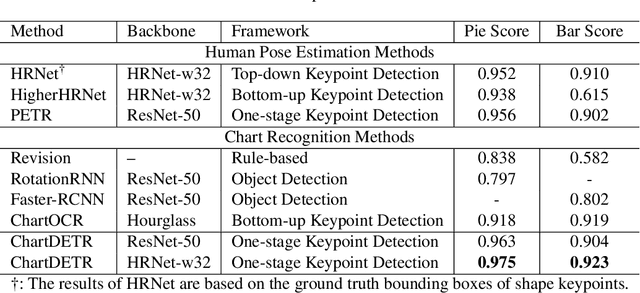
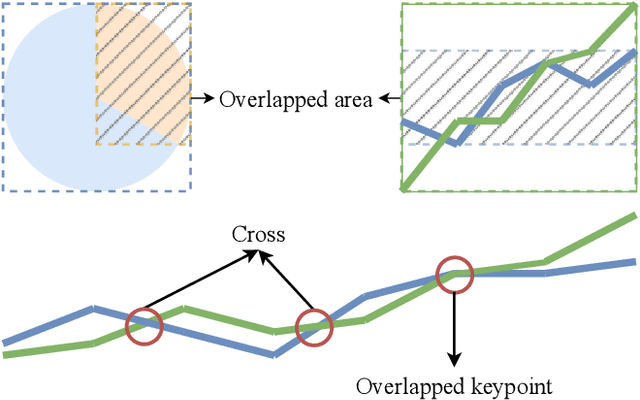
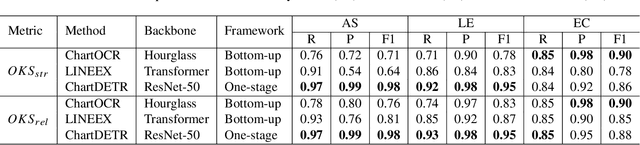
Visual chart recognition systems are gaining increasing attention due to the growing demand for automatically identifying table headers and values from chart images. Current methods rely on keypoint detection to estimate data element shapes in charts but suffer from grouping errors in post-processing. To address this issue, we propose ChartDETR, a transformer-based multi-shape detector that localizes keypoints at the corners of regular shapes to reconstruct multiple data elements in a single chart image. Our method predicts all data element shapes at once by introducing query groups in set prediction, eliminating the need for further postprocessing. This property allows ChartDETR to serve as a unified framework capable of representing various chart types without altering the network architecture, effectively detecting data elements of diverse shapes. We evaluated ChartDETR on three datasets, achieving competitive results across all chart types without any additional enhancements. For example, ChartDETR achieved an F1 score of 0.98 on Adobe Synthetic, significantly outperforming the previous best model with a 0.71 F1 score. Additionally, we obtained a new state-of-the-art result of 0.97 on ExcelChart400k. The code will be made publicly available.
Supervised Homography Learning with Realistic Dataset Generation
Aug 15, 2023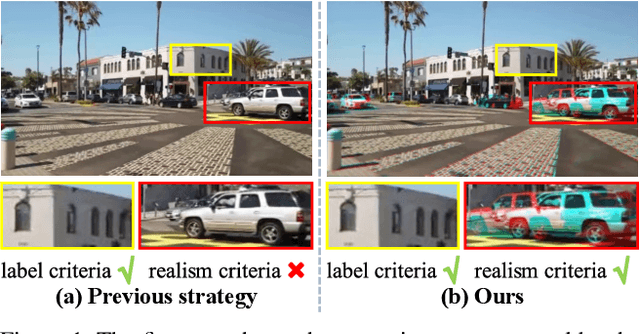
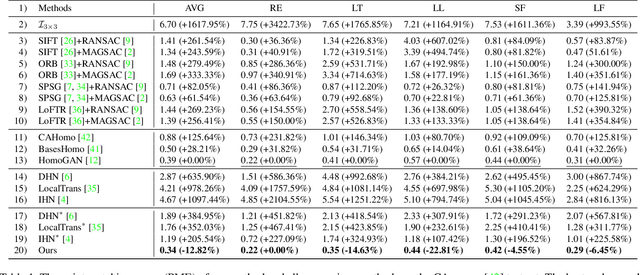
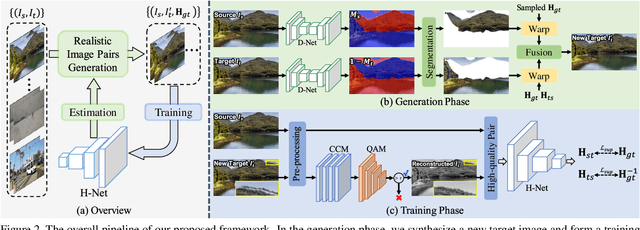
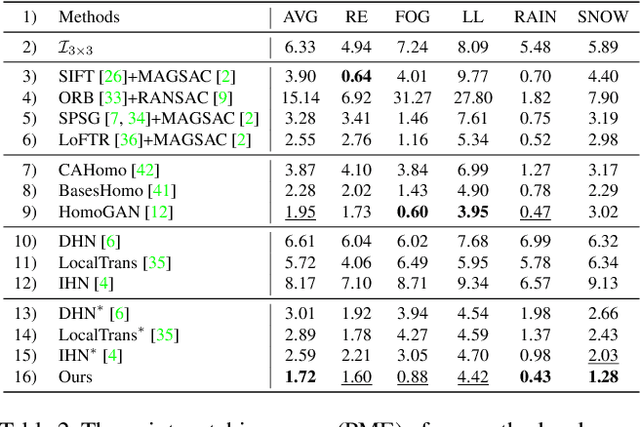
In this paper, we propose an iterative framework, which consists of two phases: a generation phase and a training phase, to generate realistic training data and yield a supervised homography network. In the generation phase, given an unlabeled image pair, we utilize the pre-estimated dominant plane masks and homography of the pair, along with another sampled homography that serves as ground truth to generate a new labeled training pair with realistic motion. In the training phase, the generated data is used to train the supervised homography network, in which the training data is refined via a content consistency module and a quality assessment module. Once an iteration is finished, the trained network is used in the next data generation phase to update the pre-estimated homography. Through such an iterative strategy, the quality of the dataset and the performance of the network can be gradually and simultaneously improved. Experimental results show that our method achieves state-of-the-art performance and existing supervised methods can be also improved based on the generated dataset. Code and dataset are available at https://github.com/JianghaiSCU/RealSH.
Graph-Segmenter: Graph Transformer with Boundary-aware Attention for Semantic Segmentation
Aug 15, 2023The transformer-based semantic segmentation approaches, which divide the image into different regions by sliding windows and model the relation inside each window, have achieved outstanding success. However, since the relation modeling between windows was not the primary emphasis of previous work, it was not fully utilized. To address this issue, we propose a Graph-Segmenter, including a Graph Transformer and a Boundary-aware Attention module, which is an effective network for simultaneously modeling the more profound relation between windows in a global view and various pixels inside each window as a local one, and for substantial low-cost boundary adjustment. Specifically, we treat every window and pixel inside the window as nodes to construct graphs for both views and devise the Graph Transformer. The introduced boundary-aware attention module optimizes the edge information of the target objects by modeling the relationship between the pixel on the object's edge. Extensive experiments on three widely used semantic segmentation datasets (Cityscapes, ADE-20k and PASCAL Context) demonstrate that our proposed network, a Graph Transformer with Boundary-aware Attention, can achieve state-of-the-art segmentation performance.
Shortcut-V2V: Compression Framework for Video-to-Video Translation based on Temporal Redundancy Reduction
Aug 15, 2023Video-to-video translation aims to generate video frames of a target domain from an input video. Despite its usefulness, the existing networks require enormous computations, necessitating their model compression for wide use. While there exist compression methods that improve computational efficiency in various image/video tasks, a generally-applicable compression method for video-to-video translation has not been studied much. In response, we present Shortcut-V2V, a general-purpose compression framework for video-to-video translation. Shourcut-V2V avoids full inference for every neighboring video frame by approximating the intermediate features of a current frame from those of the previous frame. Moreover, in our framework, a newly-proposed block called AdaBD adaptively blends and deforms features of neighboring frames, which makes more accurate predictions of the intermediate features possible. We conduct quantitative and qualitative evaluations using well-known video-to-video translation models on various tasks to demonstrate the general applicability of our framework. The results show that Shourcut-V2V achieves comparable performance compared to the original video-to-video translation model while saving 3.2-5.7x computational cost and 7.8-44x memory at test time.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
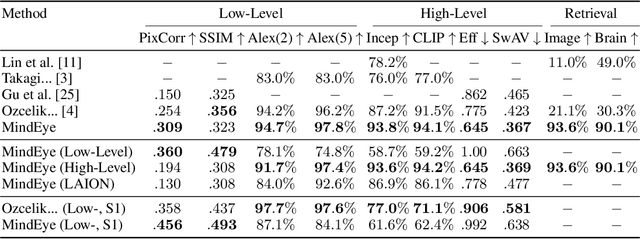
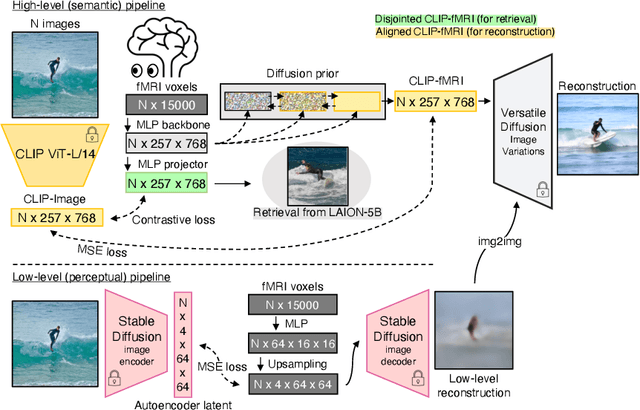
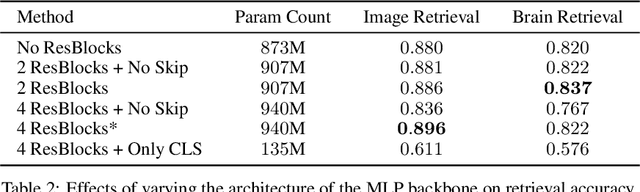
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
WaveDM: Wavelet-Based Diffusion Models for Image Restoration
May 23, 2023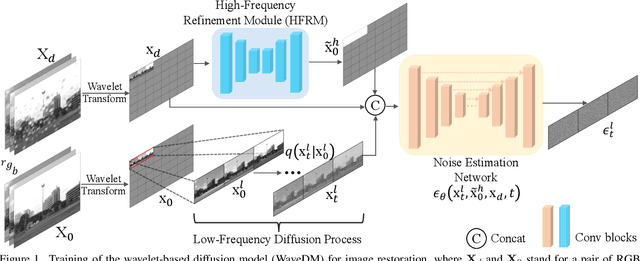
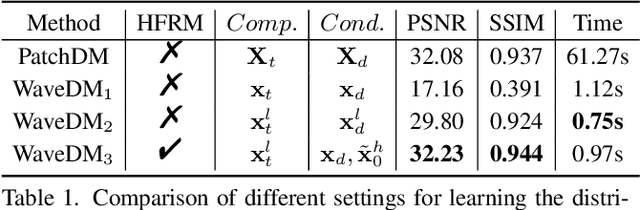
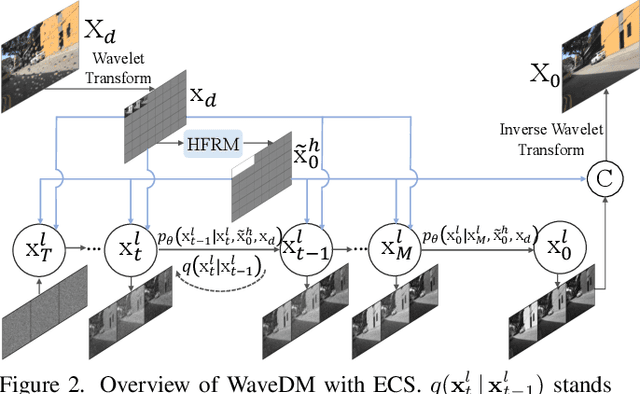
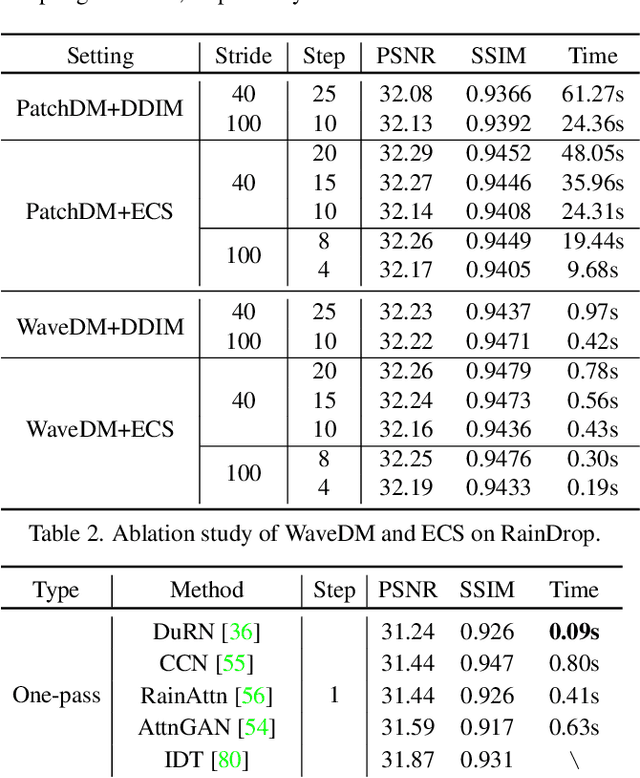
Latest diffusion-based methods for many image restoration tasks outperform traditional models, but they encounter the long-time inference problem. To tackle it, this paper proposes a Wavelet-Based Diffusion Model (WaveDM) with an Efficient Conditional Sampling (ECS) strategy. WaveDM learns the distribution of clean images in the wavelet domain conditioned on the wavelet spectrum of degraded images after wavelet transform, which is more time-saving in each step of sampling than modeling in the spatial domain. In addition, ECS follows the same procedure as the deterministic implicit sampling in the initial sampling period and then stops to predict clean images directly, which reduces the number of total sampling steps to around 5. Evaluations on four benchmark datasets including image raindrop removal, defocus deblurring, demoir\'eing, and denoising demonstrate that WaveDM achieves state-of-the-art performance with the efficiency that is comparable to traditional one-pass methods and over 100 times faster than existing image restoration methods using vanilla diffusion models.
MOSAIC: Masked Optimisation with Selective Attention for Image Reconstruction
Jun 01, 2023
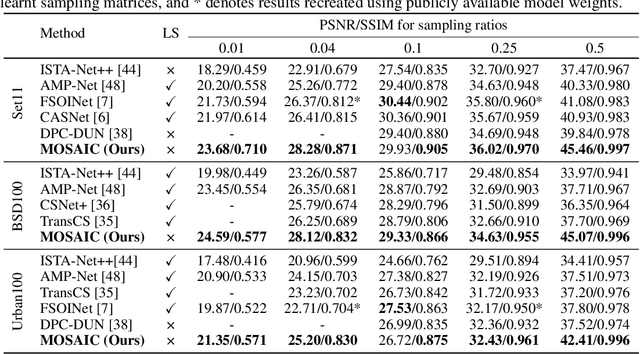
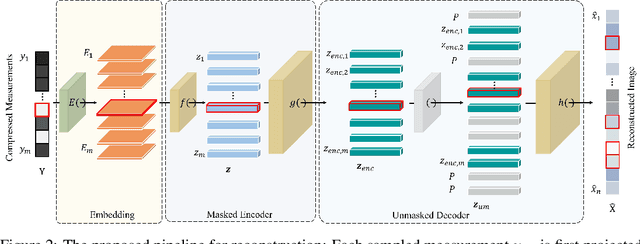
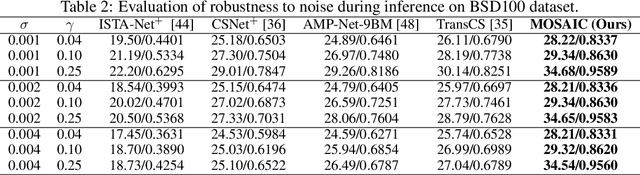
Compressive sensing (CS) reconstructs images from sub-Nyquist measurements by solving a sparsity-regularized inverse problem. Traditional CS solvers use iterative optimizers with hand crafted sparsifiers, while early data-driven methods directly learn an inverse mapping from the low-dimensional measurement space to the original image space. The latter outperforms the former, but is restrictive to a pre-defined measurement domain. More recent, deep unrolling methods combine traditional proximal gradient methods and data-driven approaches to iteratively refine an image approximation. To achieve higher accuracy, it has also been suggested to learn both the sampling matrix, and the choice of measurement vectors adaptively. Contrary to the current trend, in this work we hypothesize that a general inverse mapping from a random set of compressed measurements to the image domain exists for a given measurement basis, and can be learned. Such a model is single-shot, non-restrictive and does not parametrize the sampling process. To this end, we propose MOSAIC, a novel compressive sensing framework to reconstruct images given any random selection of measurements, sampled using a fixed basis. Motivated by the uneven distribution of information across measurements, MOSAIC incorporates an embedding technique to efficiently apply attention mechanisms on an encoded sequence of measurements, while dispensing the need to use unrolled deep networks. A range of experiments validate our proposed architecture as a promising alternative for existing CS reconstruction methods, by achieving the state-of-the-art for metrics of reconstruction accuracy on standard datasets.