 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Robust Approach Towards Distinguishing Natural and Computer Generated Images using Multi-Colorspace fused and Enriched Vision Transformer
Aug 14, 2023
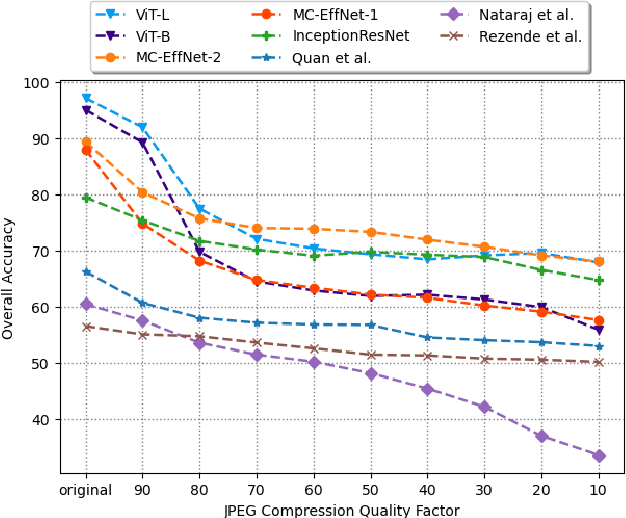
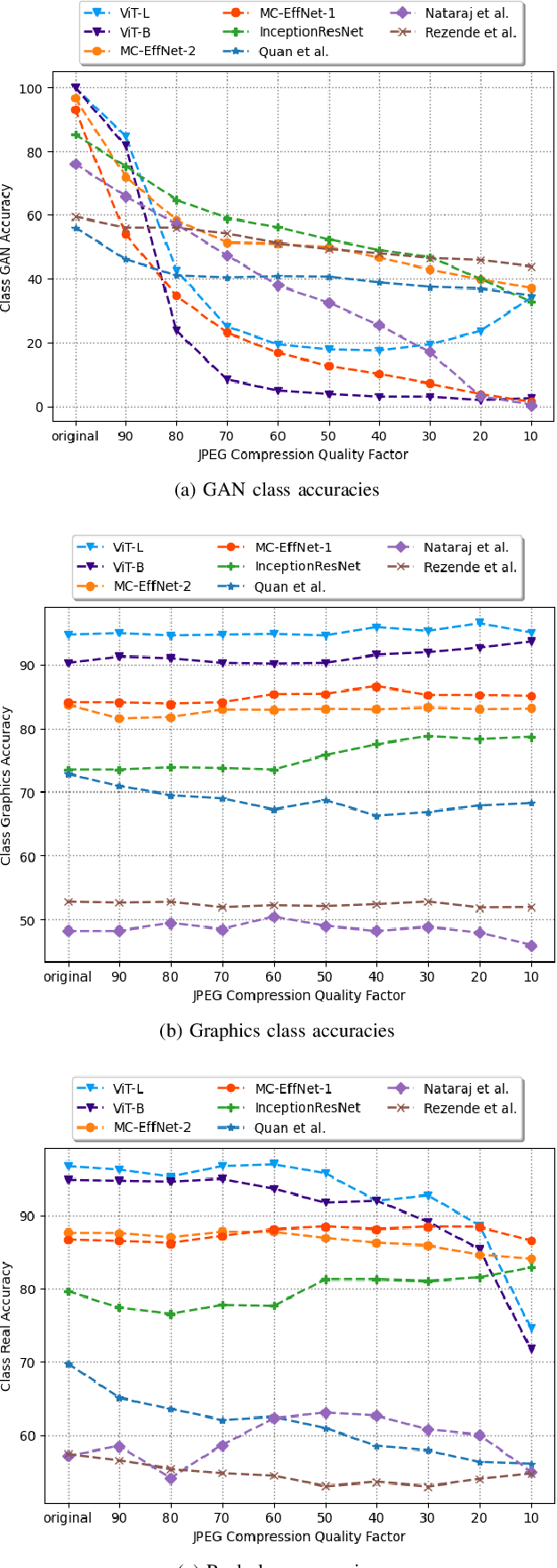
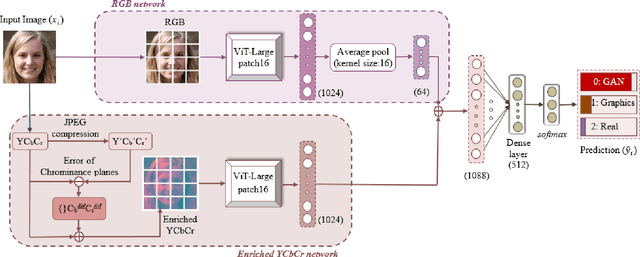
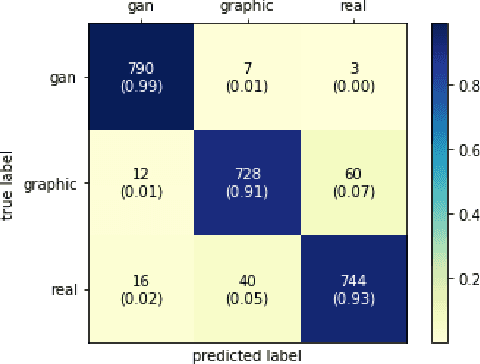
The works in literature classifying natural and computer generated images are mostly designed as binary tasks either considering natural images versus computer graphics images only or natural images versus GAN generated images only, but not natural images versus both classes of the generated images. Also, even though this forensic classification task of distinguishing natural and computer generated images gets the support of the new convolutional neural networks and transformer based architectures that can give remarkable classification accuracies, they are seen to fail over the images that have undergone some post-processing operations usually performed to deceive the forensic algorithms, such as JPEG compression, gaussian noise, etc. This work proposes a robust approach towards distinguishing natural and computer generated images including both, computer graphics and GAN generated images using a fusion of two vision transformers where each of the transformer networks operates in different color spaces, one in RGB and the other in YCbCr color space. The proposed approach achieves high performance gain when compared to a set of baselines, and also achieves higher robustness and generalizability than the baselines. The features of the proposed model when visualized are seen to obtain higher separability for the classes than the input image features and the baseline features. This work also studies the attention map visualizations of the networks of the fused model and observes that the proposed methodology can capture more image information relevant to the forensic task of classifying natural and generated images.
Wavelet-based Unsupervised Label-to-Image Translation
May 16, 2023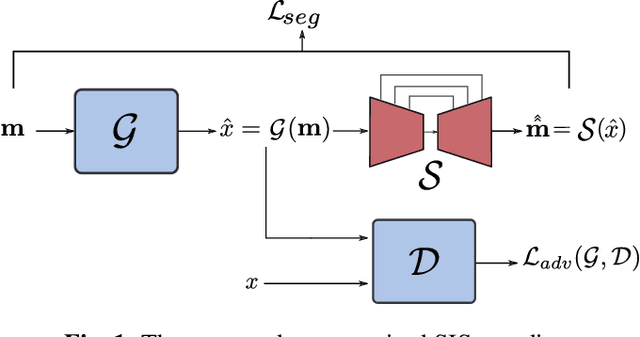
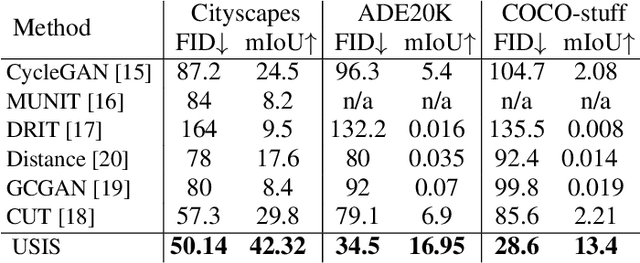

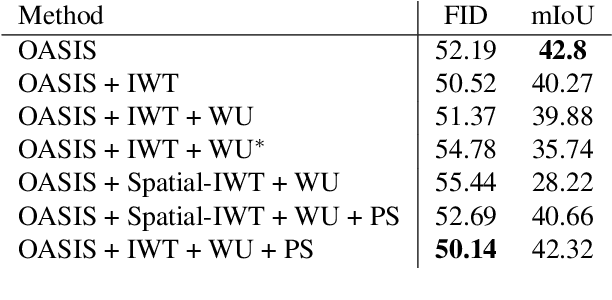
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
Large-kernel Attention for Efficient and Robust Brain Lesion Segmentation
Aug 14, 2023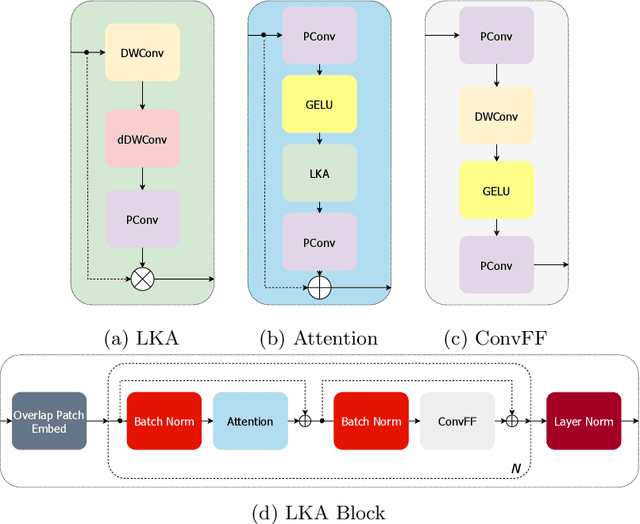

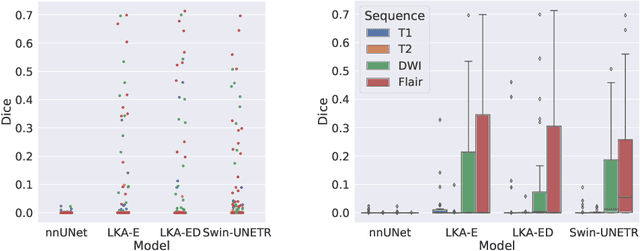
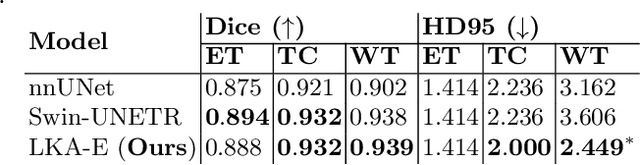
Vision transformers are effective deep learning models for vision tasks, including medical image segmentation. However, they lack efficiency and translational invariance, unlike convolutional neural networks (CNNs). To model long-range interactions in 3D brain lesion segmentation, we propose an all-convolutional transformer block variant of the U-Net architecture. We demonstrate that our model provides the greatest compromise in three factors: performance competitive with the state-of-the-art; parameter efficiency of a CNN; and the favourable inductive biases of a transformer. Our public implementation is available at https://github.com/liamchalcroft/MDUNet .
DiT: Efficient Vision Transformers with Dynamic Token Routing
Aug 07, 2023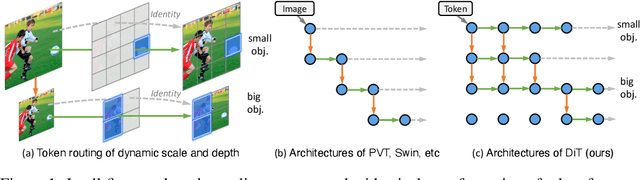
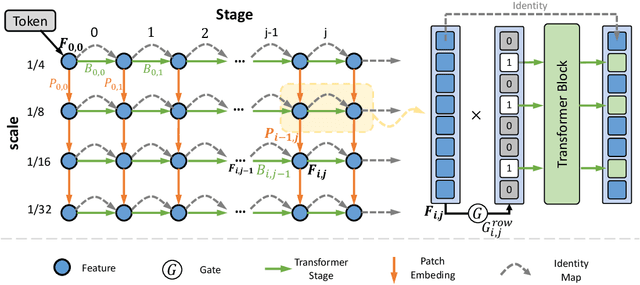
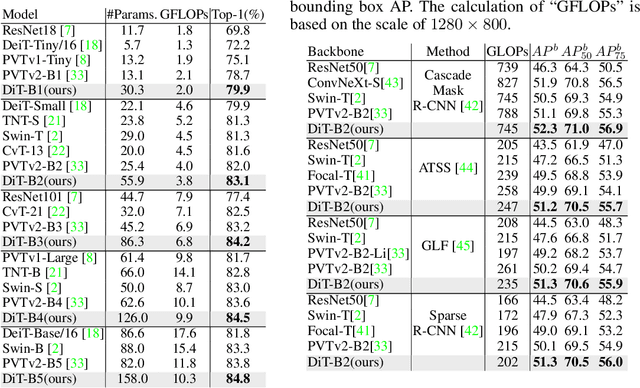
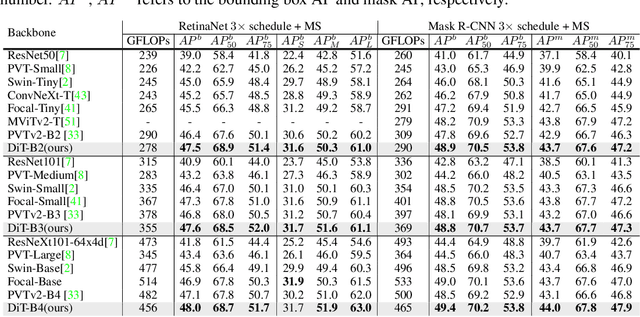
Recently, the tokens of images share the same static data flow in many dense networks. However, challenges arise from the variance among the objects in images, such as large variations in the spatial scale and difficulties of recognition for visual entities. In this paper, we propose a data-dependent token routing strategy to elaborate the routing paths of image tokens for Dynamic Vision Transformer, dubbed DiT. The proposed framework generates a data-dependent path per token, adapting to the object scales and visual discrimination of tokens. In feed-forward, the differentiable routing gates are designed to select the scaling paths and feature transformation paths for image tokens, leading to multi-path feature propagation. In this way, the impact of object scales and visual discrimination of image representation can be carefully tuned. Moreover, the computational cost can be further reduced by giving budget constraints to the routing gate and early-stopping of feature extraction. In experiments, our DiT achieves superior performance and favorable complexity/accuracy trade-offs than many SoTA methods on ImageNet classification, object detection, instance segmentation, and semantic segmentation. Particularly, the DiT-B5 obtains 84.8\% top-1 Acc on ImageNet with 10.3 GFLOPs, which is 1.0\% higher than that of the SoTA method with similar computational complexity. These extensive results demonstrate that DiT can serve as versatile backbones for various vision tasks.
FastLLVE: Real-Time Low-Light Video Enhancement with Intensity-Aware Lookup Table
Aug 13, 2023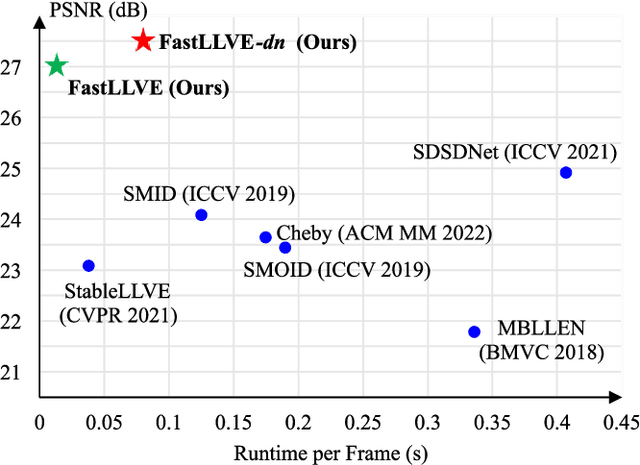
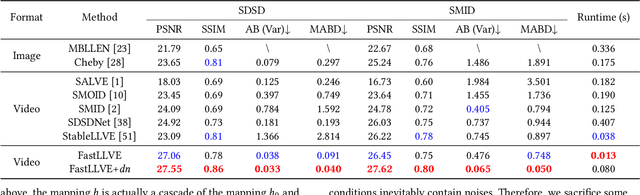
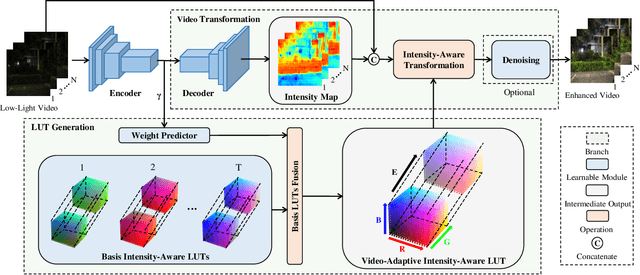

Low-Light Video Enhancement (LLVE) has received considerable attention in recent years. One of the critical requirements of LLVE is inter-frame brightness consistency, which is essential for maintaining the temporal coherence of the enhanced video. However, most existing single-image-based methods fail to address this issue, resulting in flickering effect that degrades the overall quality after enhancement. Moreover, 3D Convolution Neural Network (CNN)-based methods, which are designed for video to maintain inter-frame consistency, are computationally expensive, making them impractical for real-time applications. To address these issues, we propose an efficient pipeline named FastLLVE that leverages the Look-Up-Table (LUT) technique to maintain inter-frame brightness consistency effectively. Specifically, we design a learnable Intensity-Aware LUT (IA-LUT) module for adaptive enhancement, which addresses the low-dynamic problem in low-light scenarios. This enables FastLLVE to perform low-latency and low-complexity enhancement operations while maintaining high-quality results. Experimental results on benchmark datasets demonstrate that our method achieves the State-Of-The-Art (SOTA) performance in terms of both image quality and inter-frame brightness consistency. More importantly, our FastLLVE can process 1,080p videos at $\mathit{50+}$ Frames Per Second (FPS), which is $\mathit{2 \times}$ faster than SOTA CNN-based methods in inference time, making it a promising solution for real-time applications. The code is available at https://github.com/Wenhao-Li-777/FastLLVE.
Hyperspectral and Multispectral Image Fusion Using the Conditional Denoising Diffusion Probabilistic Model
Jul 07, 2023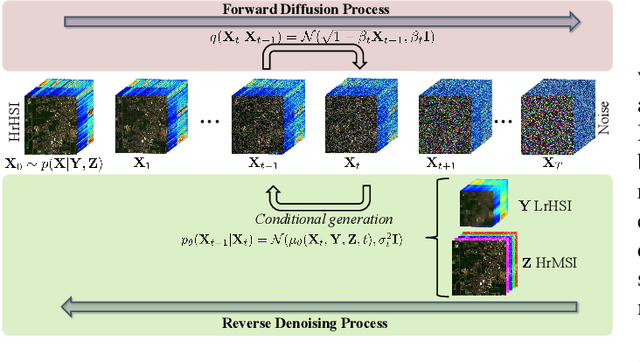
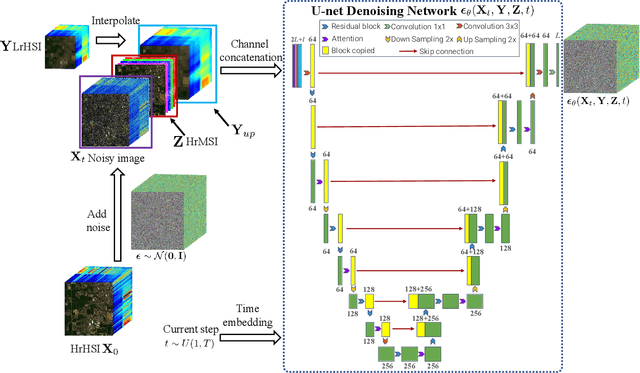

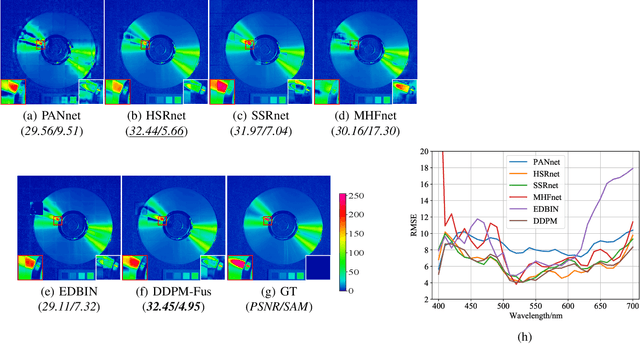
Hyperspectral images (HSI) have a large amount of spectral information reflecting the characteristics of matter, while their spatial resolution is low due to the limitations of imaging technology. Complementary to this are multispectral images (MSI), e.g., RGB images, with high spatial resolution but insufficient spectral bands. Hyperspectral and multispectral image fusion is a technique for acquiring ideal images that have both high spatial and high spectral resolution cost-effectively. Many existing HSI and MSI fusion algorithms rely on known imaging degradation models, which are often not available in practice. In this paper, we propose a deep fusion method based on the conditional denoising diffusion probabilistic model, called DDPM-Fus. Specifically, the DDPM-Fus contains the forward diffusion process which gradually adds Gaussian noise to the high spatial resolution HSI (HrHSI) and another reverse denoising process which learns to predict the desired HrHSI from its noisy version conditioning on the corresponding high spatial resolution MSI (HrMSI) and low spatial resolution HSI (LrHSI). Once the training is completes, the proposed DDPM-Fus implements the reverse process on the test HrMSI and LrHSI to generate the fused HrHSI. Experiments conducted on one indoor and two remote sensing datasets show the superiority of the proposed model when compared with other advanced deep learningbased fusion methods. The codes of this work will be opensourced at this address: https://github.com/shuaikaishi/DDPMFus for reproducibility.
Drag-guided diffusion models for vehicle image generation
Jun 16, 2023
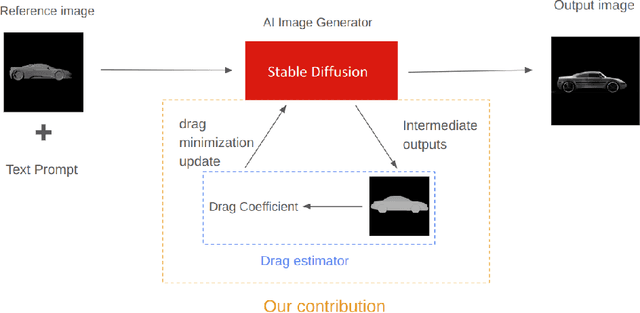

Denoising diffusion models trained at web-scale have revolutionized image generation. The application of these tools to engineering design is an intriguing possibility, but is currently limited by their inability to parse and enforce concrete engineering constraints. In this paper, we take a step towards this goal by proposing physics-based guidance, which enables optimization of a performance metric (as predicted by a surrogate model) during the generation process. As a proof-of-concept, we add drag guidance to Stable Diffusion, which allows this tool to generate images of novel vehicles while simultaneously minimizing their predicted drag coefficients.
Augmenters at SemEval-2023 Task 1: Enhancing CLIP in Handling Compositionality and Ambiguity for Zero-Shot Visual WSD through Prompt Augmentation and Text-To-Image Diffusion
Jul 09, 2023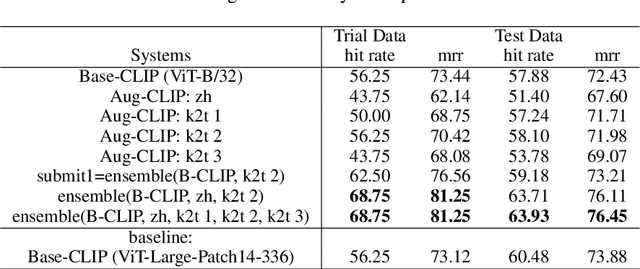


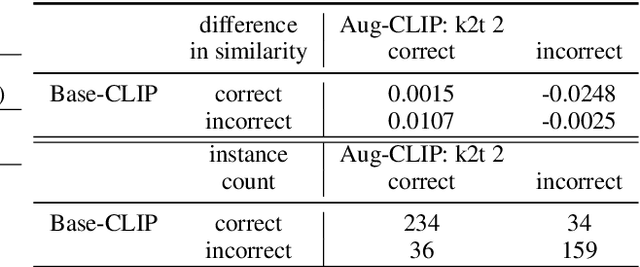
This paper describes our zero-shot approaches for the Visual Word Sense Disambiguation (VWSD) Task in English. Our preliminary study shows that the simple approach of matching candidate images with the phrase using CLIP suffers from the many-to-many nature of image-text pairs. We find that the CLIP text encoder may have limited abilities in capturing the compositionality in natural language. Conversely, the descriptive focus of the phrase varies from instance to instance. We address these issues in our two systems, Augment-CLIP and Stable Diffusion Sampling (SD Sampling). Augment-CLIP augments the text prompt by generating sentences that contain the context phrase with the help of large language models (LLMs). We further explore CLIP models in other languages, as the an ambiguous word may be translated into an unambiguous one in the other language. SD Sampling uses text-to-image Stable Diffusion to generate multiple images from the given phrase, increasing the likelihood that a subset of images match the one that paired with the text.
FoodSAM: Any Food Segmentation
Aug 11, 2023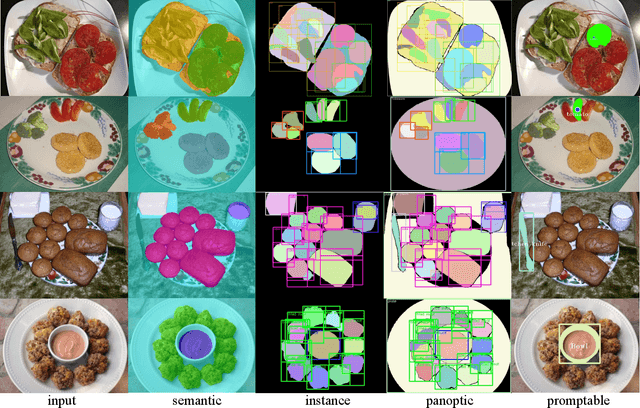
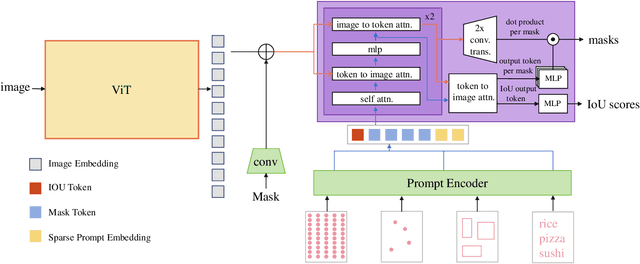
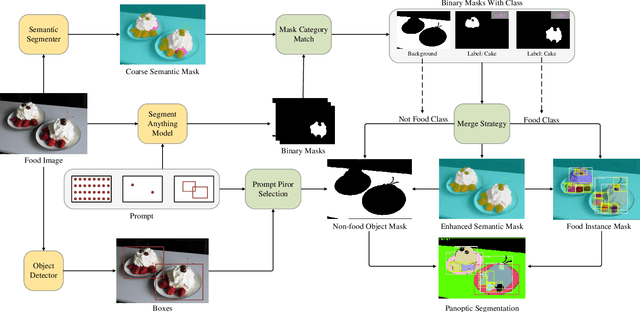
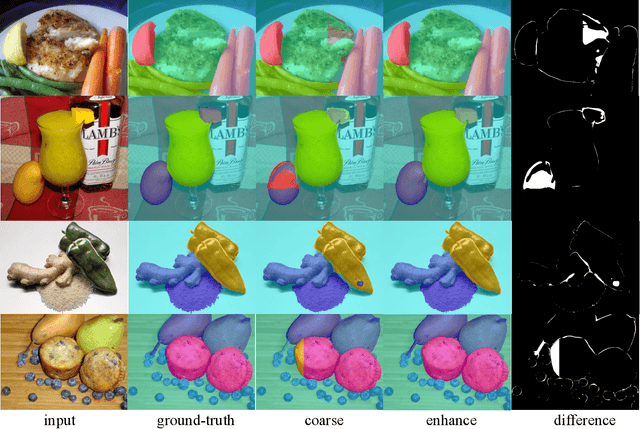
In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
Rethinking the Localization in Weakly Supervised Object Localization
Aug 11, 2023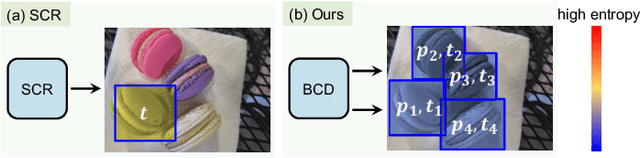
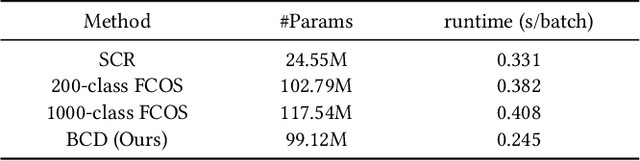
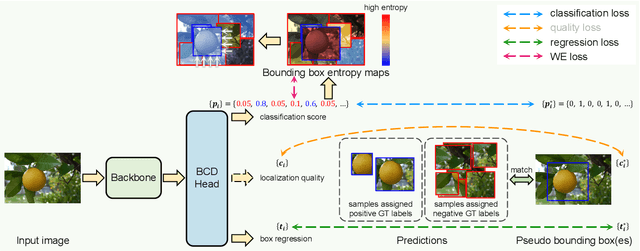
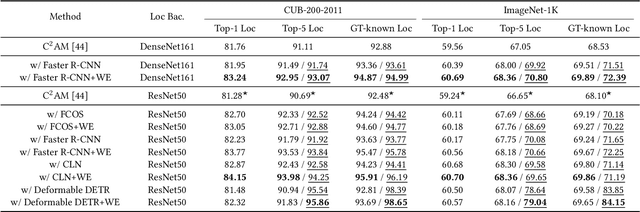
Weakly supervised object localization (WSOL) is one of the most popular and challenging tasks in computer vision. This task is to localize the objects in the images given only the image-level supervision. Recently, dividing WSOL into two parts (class-agnostic object localization and object classification) has become the state-of-the-art pipeline for this task. However, existing solutions under this pipeline usually suffer from the following drawbacks: 1) they are not flexible since they can only localize one object for each image due to the adopted single-class regression (SCR) for localization; 2) the generated pseudo bounding boxes may be noisy, but the negative impact of such noise is not well addressed. To remedy these drawbacks, we first propose to replace SCR with a binary-class detector (BCD) for localizing multiple objects, where the detector is trained by discriminating the foreground and background. Then we design a weighted entropy (WE) loss using the unlabeled data to reduce the negative impact of noisy bounding boxes. Extensive experiments on the popular CUB-200-2011 and ImageNet-1K datasets demonstrate the effectiveness of our method.