 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Segmentation via Probabilistic Graph Matching
May 13, 2023
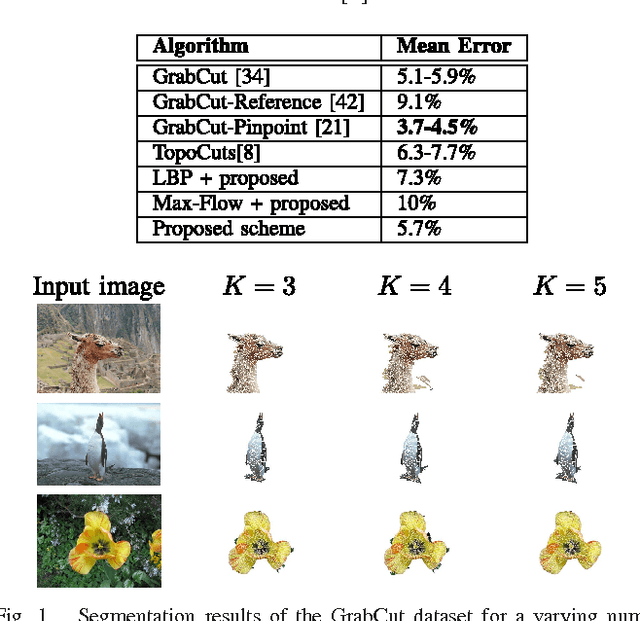
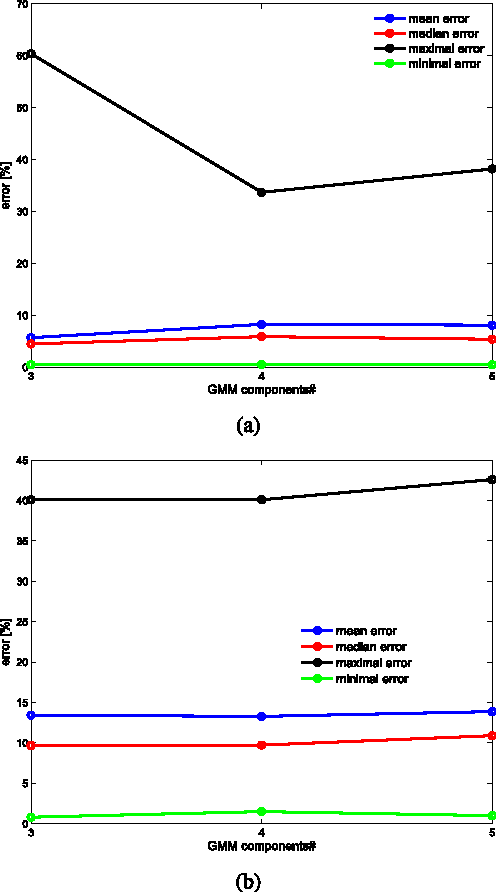
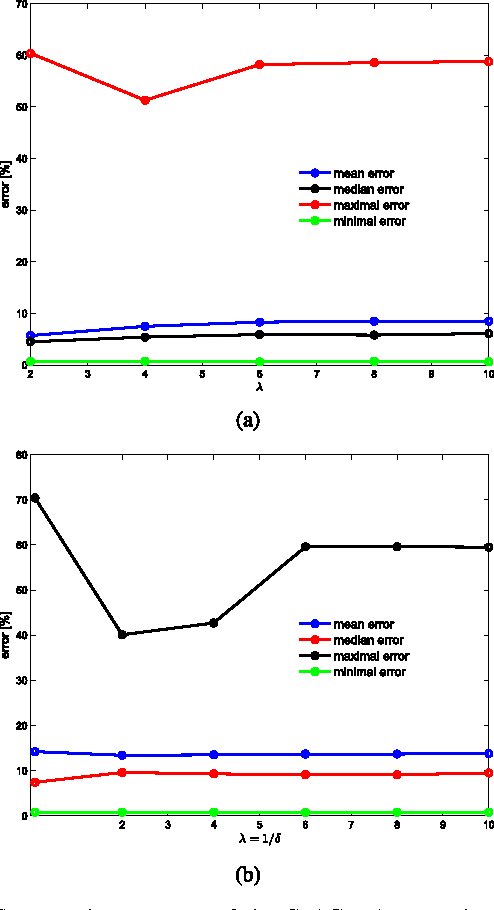

This work presents an unsupervised and semi-automatic image segmentation approach where we formulate the segmentation as a inference problem based on unary and pairwise assignment probabilities computed using low-level image cues. The inference is solved via a probabilistic graph matching scheme, which allows rigorous incorporation of low level image cues and automatic tuning of parameters. The proposed scheme is experimentally shown to compare favorably with contemporary semi-supervised and unsupervised image segmentation schemes, when applied to contemporary state-of-the-art image sets.
ARF-Plus: Controlling Perceptual Factors in Artistic Radiance Fields for 3D Scene Stylization
Aug 23, 2023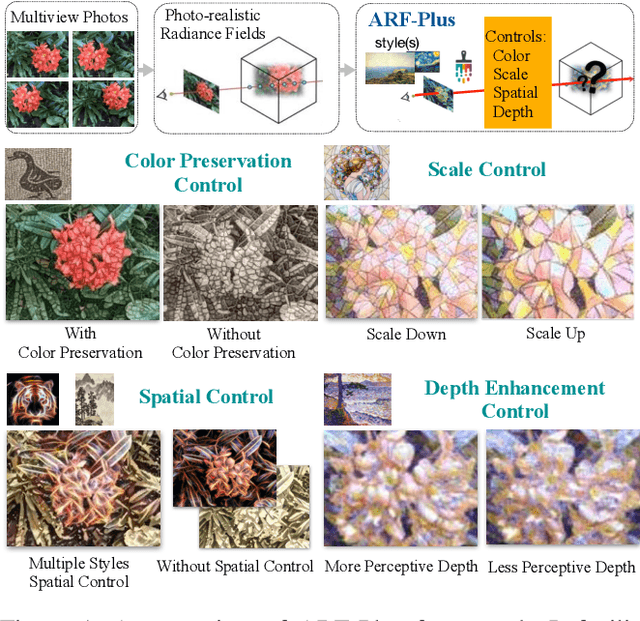
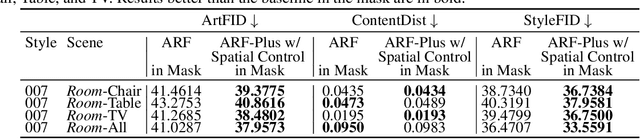

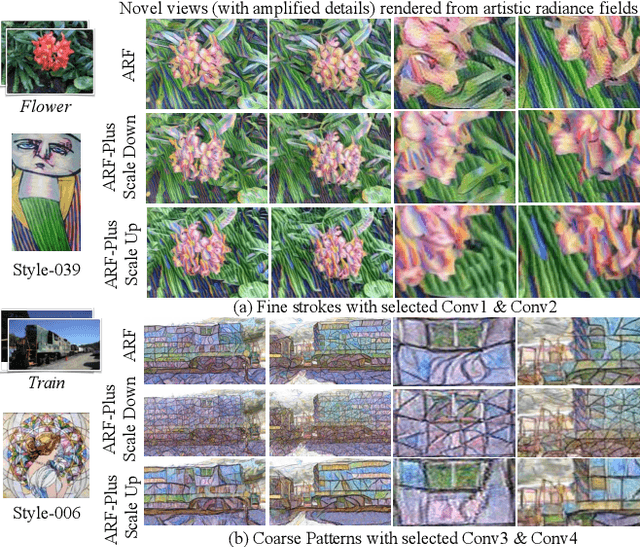
The radiance fields style transfer is an emerging field that has recently gained popularity as a means of 3D scene stylization, thanks to the outstanding performance of neural radiance fields in 3D reconstruction and view synthesis. We highlight a research gap in radiance fields style transfer, the lack of sufficient perceptual controllability, motivated by the existing concept in the 2D image style transfer. In this paper, we present ARF-Plus, a 3D neural style transfer framework offering manageable control over perceptual factors, to systematically explore the perceptual controllability in 3D scene stylization. Four distinct types of controls - color preservation control, (style pattern) scale control, spatial (selective stylization area) control, and depth enhancement control - are proposed and integrated into this framework. Results from real-world datasets, both quantitative and qualitative, show that the four types of controls in our ARF-Plus framework successfully accomplish their corresponding perceptual controls when stylizing 3D scenes. These techniques work well for individual style inputs as well as for the simultaneous application of multiple styles within a scene. This unlocks a realm of limitless possibilities, allowing customized modifications of stylization effects and flexible merging of the strengths of different styles, ultimately enabling the creation of novel and eye-catching stylistic effects on 3D scenes.
FG-Net: Facial Action Unit Detection with Generalizable Pyramidal Features
Aug 23, 2023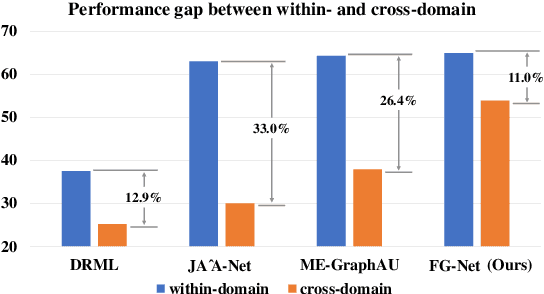
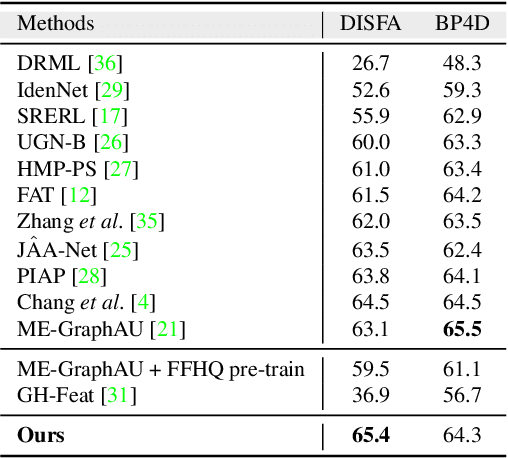
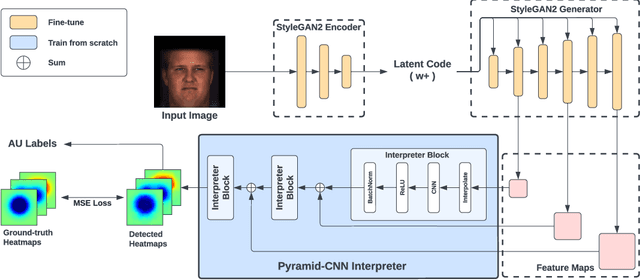
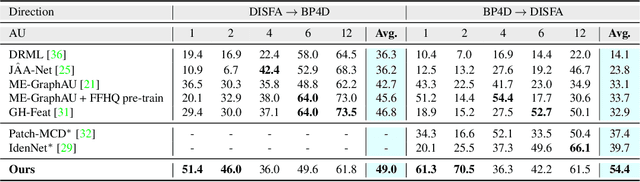
Automatic detection of facial Action Units (AUs) allows for objective facial expression analysis. Due to the high cost of AU labeling and the limited size of existing benchmarks, previous AU detection methods tend to overfit the dataset, resulting in a significant performance loss when evaluated across corpora. To address this problem, we propose FG-Net for generalizable facial action unit detection. Specifically, FG-Net extracts feature maps from a StyleGAN2 model pre-trained on a large and diverse face image dataset. Then, these features are used to detect AUs with a Pyramid CNN Interpreter, making the training efficient and capturing essential local features. The proposed FG-Net achieves a strong generalization ability for heatmap-based AU detection thanks to the generalizable and semantic-rich features extracted from the pre-trained generative model. Extensive experiments are conducted to evaluate within- and cross-corpus AU detection with the widely-used DISFA and BP4D datasets. Compared with the state-of-the-art, the proposed method achieves superior cross-domain performance while maintaining competitive within-domain performance. In addition, FG-Net is data-efficient and achieves competitive performance even when trained on 1000 samples. Our code will be released at \url{https://github.com/ihp-lab/FG-Net}
DR-Tune: Improving Fine-tuning of Pretrained Visual Models by Distribution Regularization with Semantic Calibration
Aug 23, 2023The visual models pretrained on large-scale benchmarks encode general knowledge and prove effective in building more powerful representations for downstream tasks. Most existing approaches follow the fine-tuning paradigm, either by initializing or regularizing the downstream model based on the pretrained one. The former fails to retain the knowledge in the successive fine-tuning phase, thereby prone to be over-fitting, and the latter imposes strong constraints to the weights or feature maps of the downstream model without considering semantic drift, often incurring insufficient optimization. To deal with these issues, we propose a novel fine-tuning framework, namely distribution regularization with semantic calibration (DR-Tune). It employs distribution regularization by enforcing the downstream task head to decrease its classification error on the pretrained feature distribution, which prevents it from over-fitting while enabling sufficient training of downstream encoders. Furthermore, to alleviate the interference by semantic drift, we develop the semantic calibration (SC) module to align the global shape and class centers of the pretrained and downstream feature distributions. Extensive experiments on widely used image classification datasets show that DR-Tune consistently improves the performance when combing with various backbones under different pretraining strategies. Code is available at: https://github.com/weeknan/DR-Tune.
Head-Tail Cooperative Learning Network for Unbiased Scene Graph Generation
Aug 23, 2023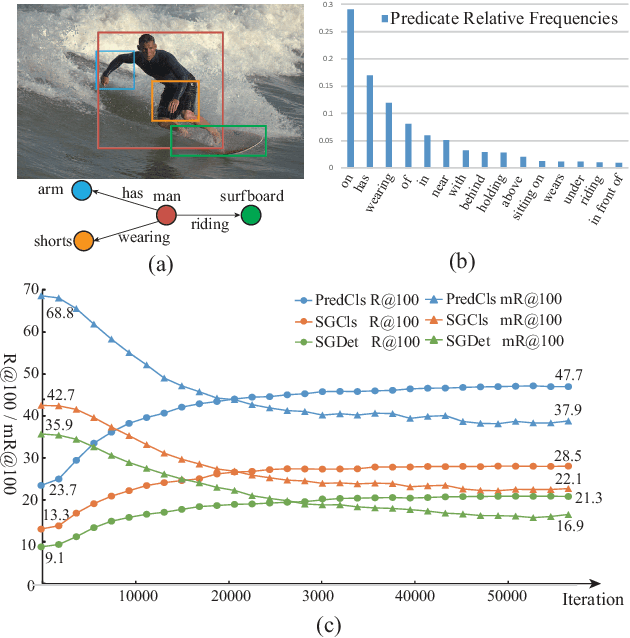
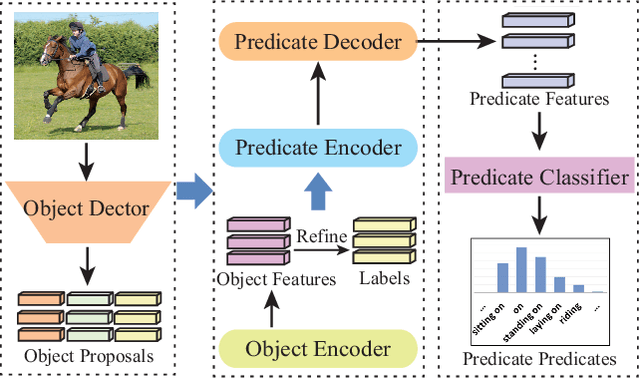
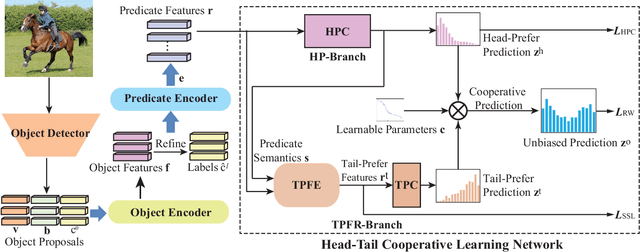
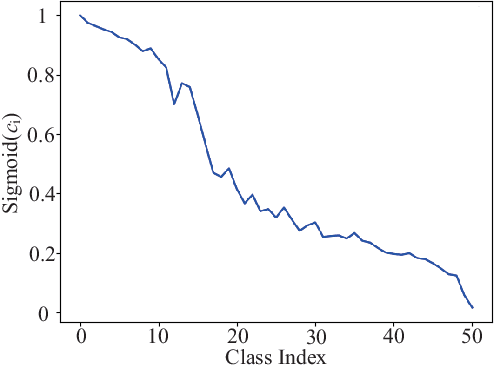
Scene Graph Generation (SGG) as a critical task in image understanding, facing the challenge of head-biased prediction caused by the long-tail distribution of predicates. However, current unbiased SGG methods can easily prioritize improving the prediction of tail predicates while ignoring the substantial sacrifice in the prediction of head predicates, leading to a shift from head bias to tail bias. To address this issue, we propose a model-agnostic Head-Tail Collaborative Learning (HTCL) network that includes head-prefer and tail-prefer feature representation branches that collaborate to achieve accurate recognition of both head and tail predicates. We also propose a self-supervised learning approach to enhance the prediction ability of the tail-prefer feature representation branch by constraining tail-prefer predicate features. Specifically, self-supervised learning converges head predicate features to their class centers while dispersing tail predicate features as much as possible through contrast learning and head center loss. We demonstrate the effectiveness of our HTCL by applying it to various SGG models on VG150, Open Images V6 and GQA200 datasets. The results show that our method achieves higher mean Recall with a minimal sacrifice in Recall and achieves a new state-of-the-art overall performance. Our code is available at https://github.com/wanglei0618/HTCL.
NimbRo wins ANA Avatar XPRIZE Immersive Telepresence Competition: Human-Centric Evaluation and Lessons Learned
Aug 23, 2023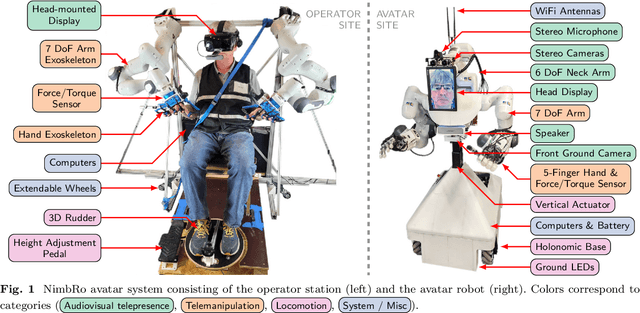


Robotic avatar systems can enable immersive telepresence with locomotion, manipulation, and communication capabilities. We present such an avatar system, based on the key components of immersive 3D visualization and transparent force-feedback telemanipulation. Our avatar robot features an anthropomorphic upper body with dexterous hands. The remote human operator drives the arms and fingers through an exoskeleton-based operator station, which provides force feedback both at the wrist and for each finger. The robot torso is mounted on a holonomic base, providing omnidirectional locomotion on flat floors, controlled using a 3D rudder device. Finally, the robot features a 6D movable head with stereo cameras, which stream images to a VR display worn by the operator. Movement latency is hidden using spherical rendering. The head also carries a telepresence screen displaying an animated image of the operator's face, enabling direct interaction with remote persons. Our system won the \$10M ANA Avatar XPRIZE competition, which challenged teams to develop intuitive and immersive avatar systems that could be operated by briefly trained judges. We analyze our successful participation in the semifinals and finals and provide insight into our operator training and lessons learned. In addition, we evaluate our system in a user study that demonstrates its intuitive and easy usability.
Beyond Discriminative Regions: Saliency Maps as Alternatives to CAMs for Weakly Supervised Semantic Segmentation
Aug 21, 2023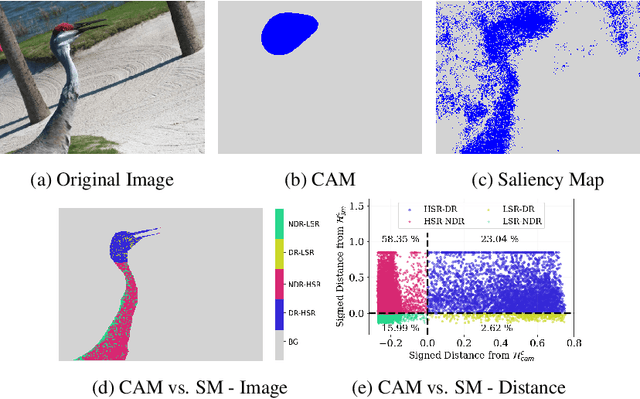
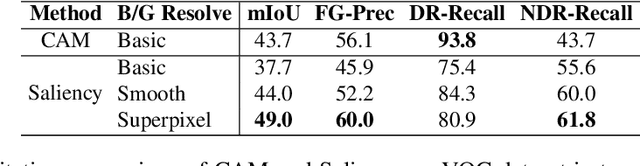
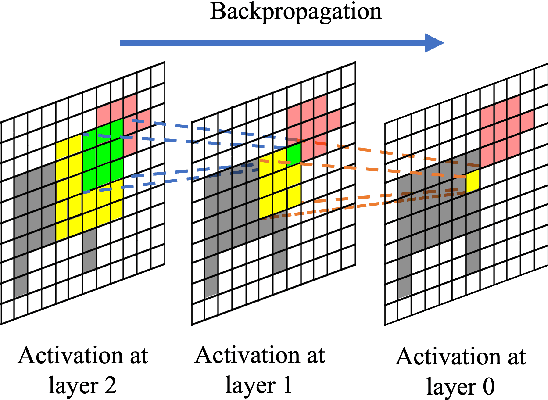
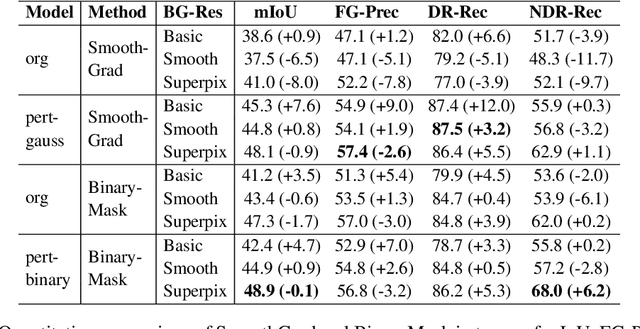
In recent years, several Weakly Supervised Semantic Segmentation (WS3) methods have been proposed that use class activation maps (CAMs) generated by a classifier to produce pseudo-ground truths for training segmentation models. While CAMs are good at highlighting discriminative regions (DR) of an image, they are known to disregard regions of the object that do not contribute to the classifier's prediction, termed non-discriminative regions (NDR). In contrast, attribution methods such as saliency maps provide an alternative approach for assigning a score to every pixel based on its contribution to the classification prediction. This paper provides a comprehensive comparison between saliencies and CAMs for WS3. Our study includes multiple perspectives on understanding their similarities and dissimilarities. Moreover, we provide new evaluation metrics that perform a comprehensive assessment of WS3 performance of alternative methods w.r.t. CAMs. We demonstrate the effectiveness of saliencies in addressing the limitation of CAMs through our empirical studies on benchmark datasets. Furthermore, we propose random cropping as a stochastic aggregation technique that improves the performance of saliency, making it a strong alternative to CAM for WS3.
PromptUNet: Toward Interactive Medical Image Segmentation
May 17, 2023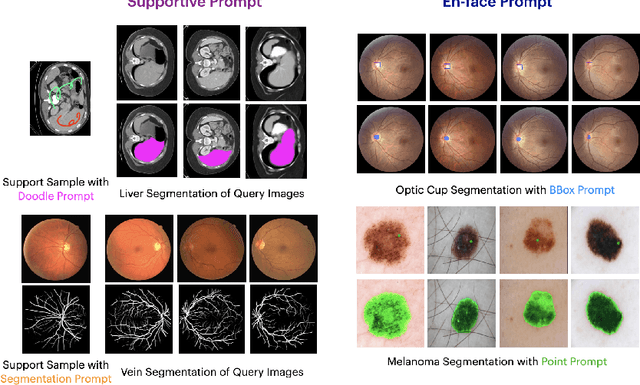
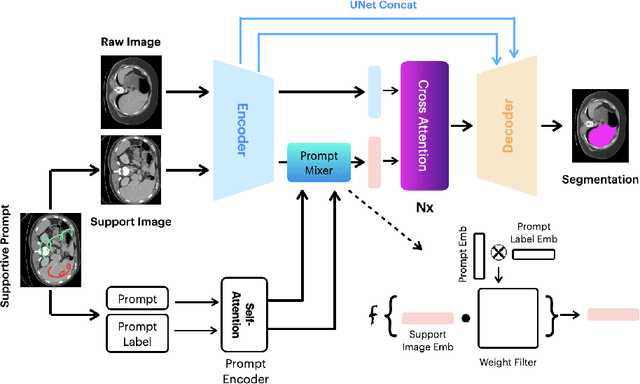
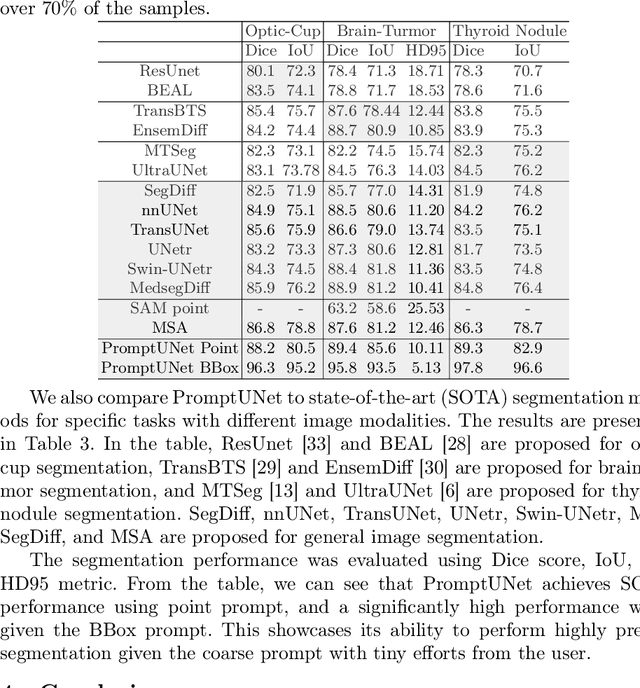
Prompt-based segmentation, also known as interactive segmentation, has recently become a popular approach in image segmentation. A well-designed prompt-based model called Segment Anything Model (SAM) has demonstrated its ability to segment a wide range of natural images, which has sparked a lot of discussion in the community. However, recent studies have shown that SAM performs poorly on medical images. This has motivated us to design a new prompt-based segmentation model specifically for medical image segmentation. In this paper, we combine the prompted-based segmentation paradigm with UNet, which is a widly-recognized successful architecture for medical image segmentation. We have named the resulting model PromptUNet. In order to adapt the real-world clinical use, we expand the existing prompt types in SAM to include novel Supportive Prompts and En-face Prompts. We have evaluated the capabilities of PromptUNet on 19 medical image segmentation tasks using a variety of image modalities, including CT, MRI, ultrasound, fundus, and dermoscopic images. Our results show that PromptUNet outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, including nnUNet, TransUNet, UNetr, MedSegDiff, and MSA. Code will be released at: https://github.com/WuJunde/PromptUNet.
A free from local minima algorithm for training regressive MLP neural networks
Aug 22, 2023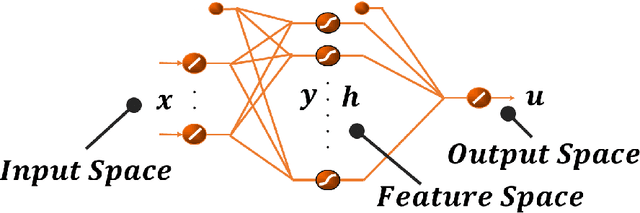
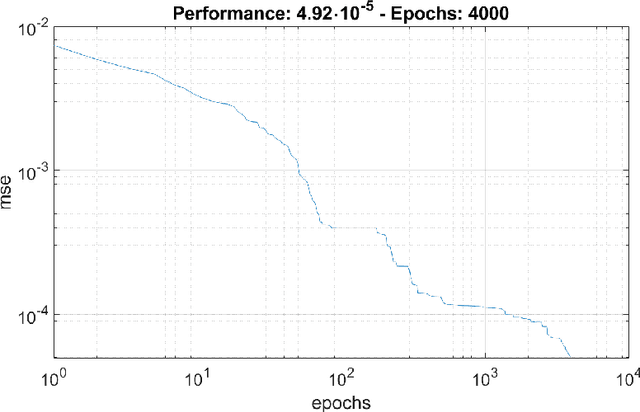
In this article an innovative method for training regressive MLP networks is presented, which is not subject to local minima. The Error-Back-Propagation algorithm, proposed by William-Hinton-Rummelhart, has had the merit of favouring the development of machine learning techniques, which has permeated every branch of research and technology since the mid-1980s. This extraordinary success is largely due to the black-box approach, but this same factor was also seen as a limitation, as soon more challenging problems were approached. One of the most critical aspects of the training algorithms was that of local minima of the loss function, typically the mean squared error of the output on the training set. In fact, as the most popular training algorithms are driven by the derivatives of the loss function, there is no possibility to evaluate if a reached minimum is local or global. The algorithm presented in this paper avoids the problem of local minima, as the training is based on the properties of the distribution of the training set, or better on its image internal to the neural network. The performance of the algorithm is shown for a well-known benchmark.
Wavelet-based Unsupervised Label-to-Image Translation
May 16, 2023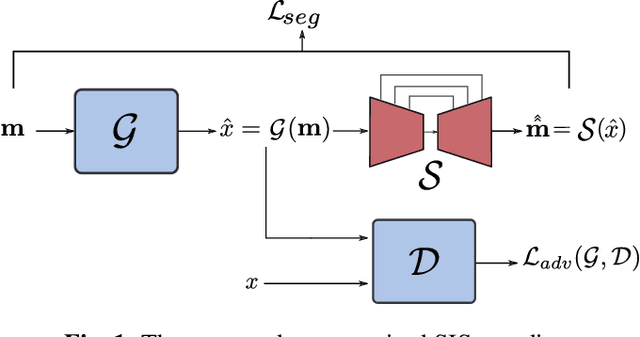
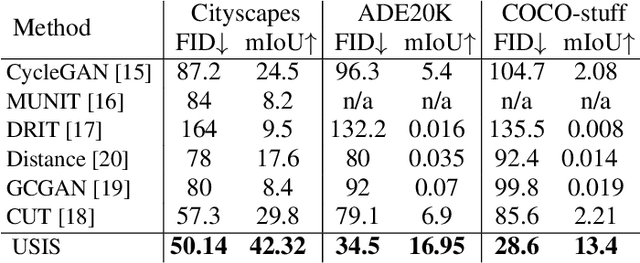

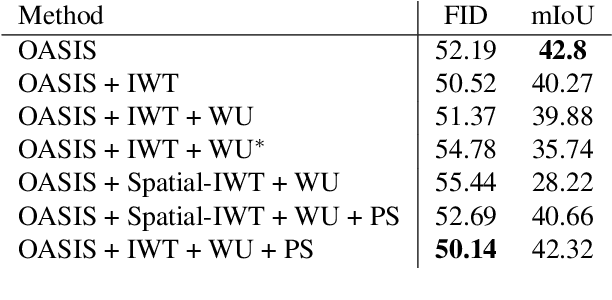
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.