 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rotational augmentation techniques: a new perspective on ensemble learning for image classification
Jun 12, 2023
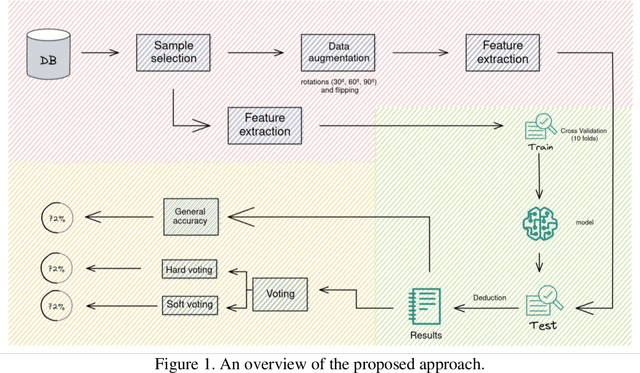



The popularity of data augmentation techniques in machine learning has increased in recent years, as they enable the creation of new samples from existing datasets. Rotational augmentation, in particular, has shown great promise by revolving images and utilising them as additional data points for training. This research study introduces a new approach to enhance the performance of classification methods where the testing sets were generated employing transformations on every image from the original dataset. Subsequently, ensemble-based systems were implemented to determine the most reliable outcome in each subset acquired from the augmentation phase to get a final prediction for every original image. The findings of this study suggest that rotational augmentation techniques can significantly improve the accuracy of standard classification models; and the selection of a voting scheme can considerably impact the model's performance. Overall, the study found that using an ensemble-based voting system produced more accurate results than simple voting.
Second Sight: Using brain-optimized encoding models to align image distributions with human brain activity
Jun 01, 2023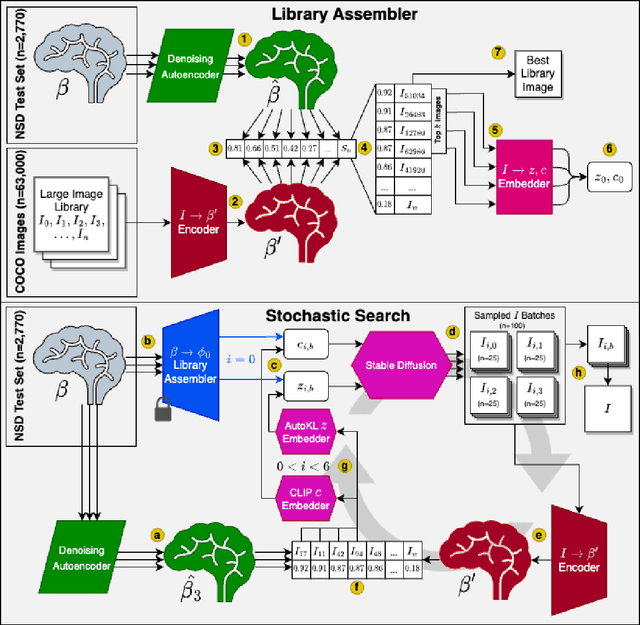
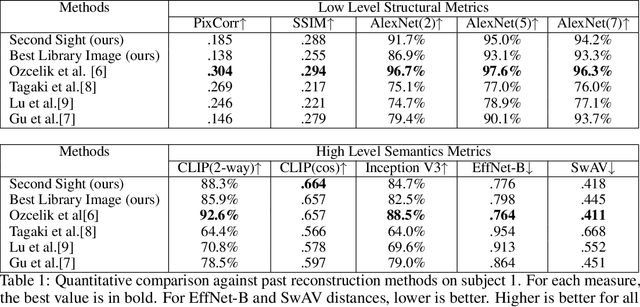

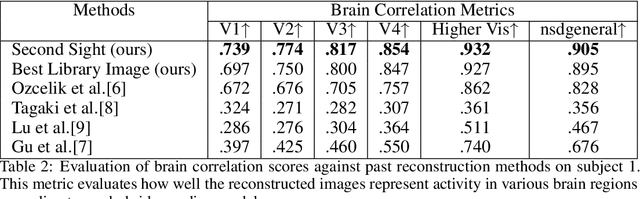
Two recent developments have accelerated progress in image reconstruction from human brain activity: large datasets that offer samples of brain activity in response to many thousands of natural scenes, and the open-sourcing of powerful stochastic image-generators that accept both low- and high-level guidance. Most work in this space has focused on obtaining point estimates of the target image, with the ultimate goal of approximating literal pixel-wise reconstructions of target images from the brain activity patterns they evoke. This emphasis belies the fact that there is always a family of images that are equally compatible with any evoked brain activity pattern, and the fact that many image-generators are inherently stochastic and do not by themselves offer a method for selecting the single best reconstruction from among the samples they generate. We introduce a novel reconstruction procedure (Second Sight) that iteratively refines an image distribution to explicitly maximize the alignment between the predictions of a voxel-wise encoding model and the brain activity patterns evoked by any target image. We show that our process converges on a distribution of high-quality reconstructions by refining both semantic content and low-level image details across iterations. Images sampled from these converged image distributions are competitive with state-of-the-art reconstruction algorithms. Interestingly, the time-to-convergence varies systematically across visual cortex, with earlier visual areas generally taking longer and converging on narrower image distributions, relative to higher-level brain areas. Second Sight thus offers a succinct and novel method for exploring the diversity of representations across visual brain areas.
Boosting Text-to-Image Diffusion Models with Fine-Grained Semantic Rewards
Jun 01, 2023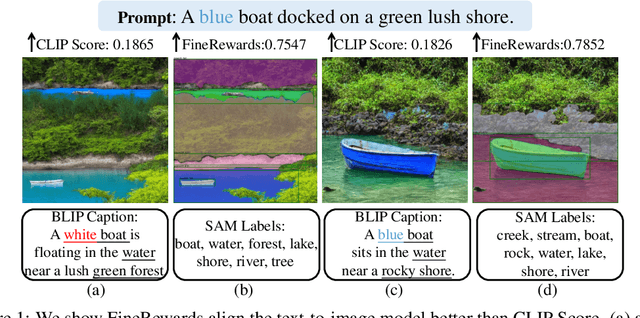
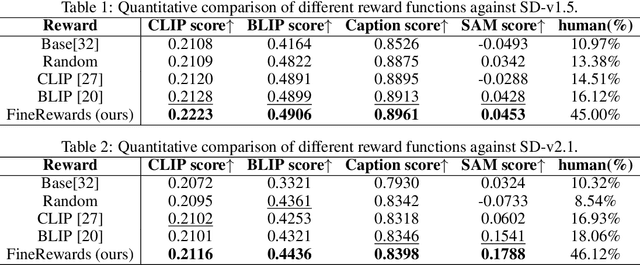
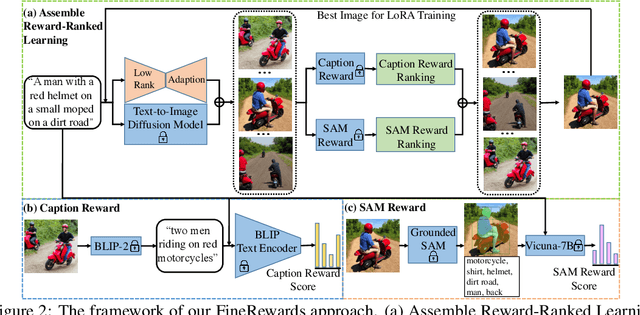

Recent advances in text-to-image diffusion models have achieved remarkable success in generating high-quality, realistic images from given text prompts. However, previous methods fail to perform accurate modality alignment between text concepts and generated images due to the lack of fine-level semantic guidance that successfully diagnoses the modality discrepancy. In this paper, we propose FineRewards to improve the alignment between text and images in text-to-image diffusion models by introducing two new fine-grained semantic rewards: the caption reward and the Semantic Segment Anything (SAM) reward. From the global semantic view, the caption reward generates a corresponding detailed caption that depicts all important contents in the synthetic image via a BLIP-2 model and then calculates the reward score by measuring the similarity between the generated caption and the given prompt. From the local semantic view, the SAM reward segments the generated images into local parts with category labels, and scores the segmented parts by measuring the likelihood of each category appearing in the prompted scene via a large language model, i.e., Vicuna-7B. Additionally, we adopt an assemble reward-ranked learning strategy to enable the integration of multiple reward functions to jointly guide the model training. Adapting results of text-to-image models on the MS-COCO benchmark show that the proposed semantic reward outperforms other baseline reward functions with a considerable margin on both visual quality and semantic similarity with the input prompt. Moreover, by adopting the assemble reward-ranked learning strategy, we further demonstrate that model performance is further improved when adapting under the unifying of the proposed semantic reward with the current image rewards.
The Radon Signed Cumulative Distribution Transform and its applications in classification of Signed Images
Jul 28, 2023
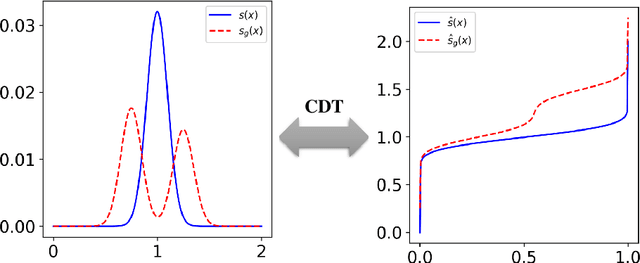

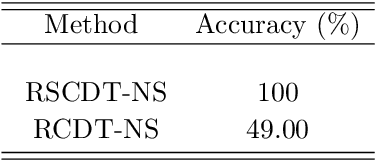
Here we describe a new image representation technique based on the mathematics of transport and optimal transport. The method relies on the combination of the well-known Radon transform for images and a recent signal representation method called the Signed Cumulative Distribution Transform. The newly proposed method generalizes previous transport-related image representation methods to arbitrary functions (images), and thus can be used in more applications. We describe the new transform, and some of its mathematical properties and demonstrate its ability to partition image classes with real and simulated data. In comparison to existing transport transform methods, as well as deep learning-based classification methods, the new transform more accurately represents the information content of signed images, and thus can be used to obtain higher classification accuracies. The implementation of the proposed method in Python language is integrated as a part of the software package PyTransKit, available on Github.
Evaluation of Multi-indicator And Multi-organ Medical Image Segmentation Models
Jun 01, 2023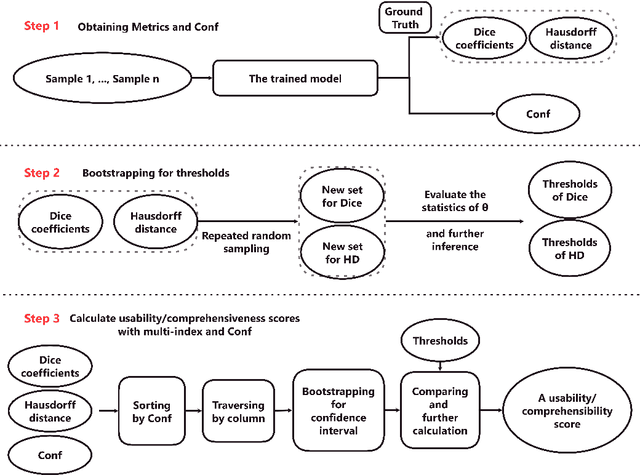
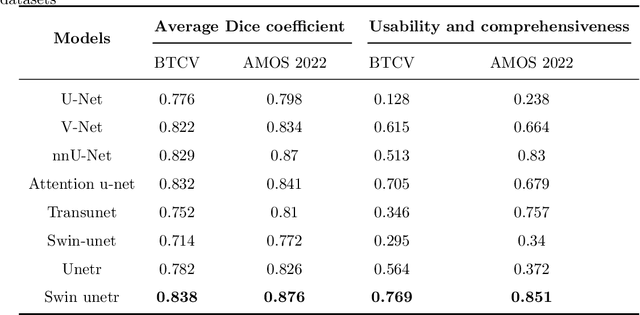

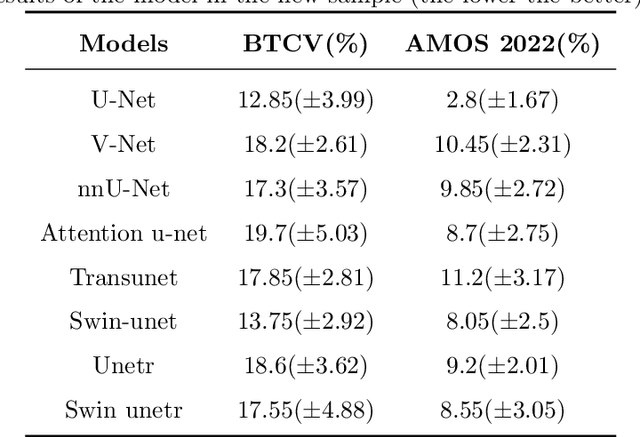
In recent years, "U-shaped" neural networks featuring encoder and decoder structures have gained popularity in the field of medical image segmentation. Various variants of this model have been developed. Nevertheless, the evaluation of these models has received less attention compared to model development. In response, we propose a comprehensive method for evaluating medical image segmentation models for multi-indicator and multi-organ (named MIMO). MIMO allows models to generate independent thresholds which are then combined with multi-indicator evaluation and confidence estimation to screen and measure each organ. As a result, MIMO offers detailed information on the segmentation of each organ in each sample, thereby aiding developers in analyzing and improving the model. Additionally, MIMO can produce concise usability and comprehensiveness scores for different models. Models with higher scores are deemed to be excellent models, which is convenient for clinical evaluation. Our research tests eight different medical image segmentation models on two abdominal multi-organ datasets and evaluates them from four perspectives: correctness, confidence estimation, Usable Region and MIMO. Furthermore, robustness experiments are tested. Experimental results demonstrate that MIMO offers novel insights into multi-indicator and multi-organ medical image evaluation and provides a specific and concise measure for the usability and comprehensiveness of the model. Code: https://github.com/SCUT-ML-GUO/MIMO
OmniZoomer: Learning to Move and Zoom in on Sphere at High-Resolution
Aug 19, 2023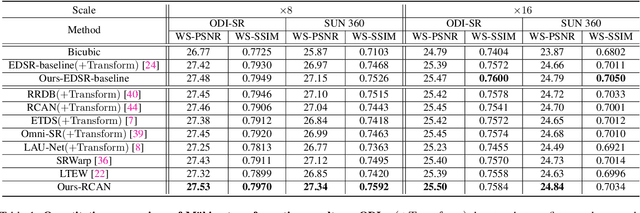
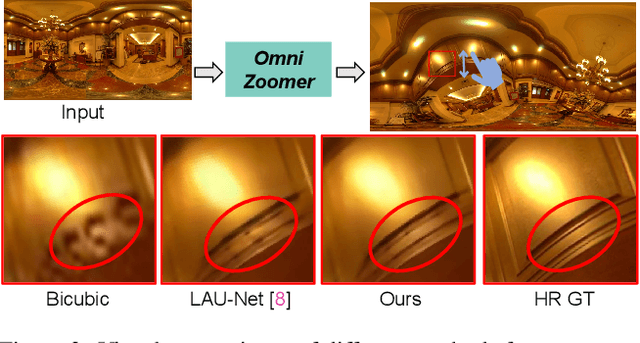
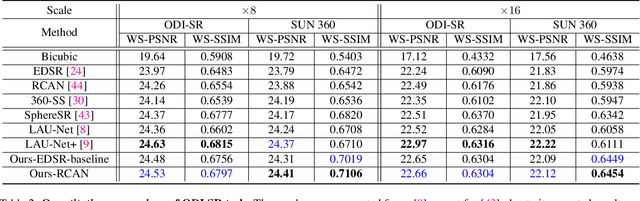
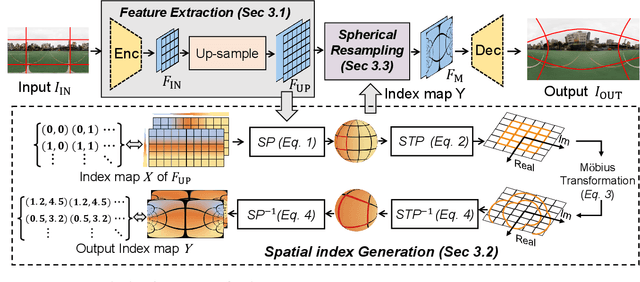
Omnidirectional images (ODIs) have become increasingly popular, as their large field-of-view (FoV) can offer viewers the chance to freely choose the view directions in immersive environments such as virtual reality. The M\"obius transformation is typically employed to further provide the opportunity for movement and zoom on ODIs, but applying it to the image level often results in blurry effect and aliasing problem. In this paper, we propose a novel deep learning-based approach, called \textbf{OmniZoomer}, to incorporate the M\"obius transformation into the network for movement and zoom on ODIs. By learning various transformed feature maps under different conditions, the network is enhanced to handle the increasing edge curvatures, which alleviates the blurry effect. Moreover, to address the aliasing problem, we propose two key components. Firstly, to compensate for the lack of pixels for describing curves, we enhance the feature maps in the high-resolution (HR) space and calculate the transformed index map with a spatial index generation module. Secondly, considering that ODIs are inherently represented in the spherical space, we propose a spherical resampling module that combines the index map and HR feature maps to transform the feature maps for better spherical correlation. The transformed feature maps are decoded to output a zoomed ODI. Experiments show that our method can produce HR and high-quality ODIs with the flexibility to move and zoom in to the object of interest. Project page is available at http://vlislab22.github.io/OmniZoomer/.
Stylized Projected GAN: A Novel Architecture for Fast and Realistic Image Generation
Jul 30, 2023
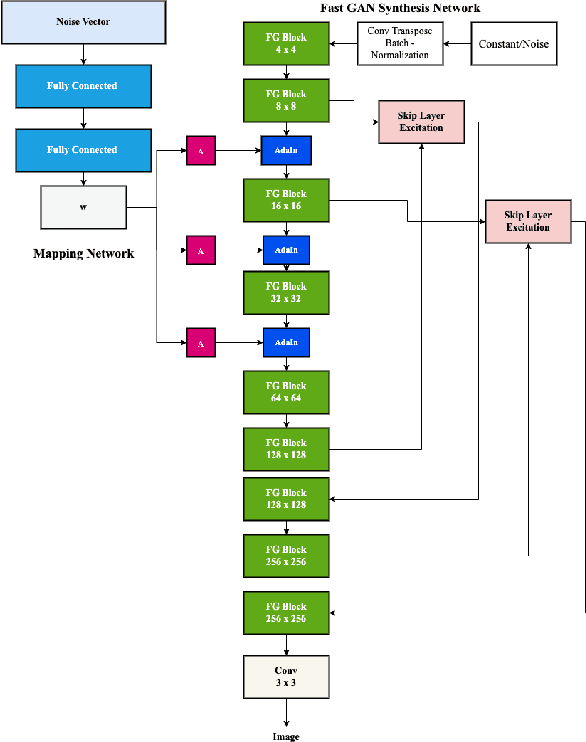
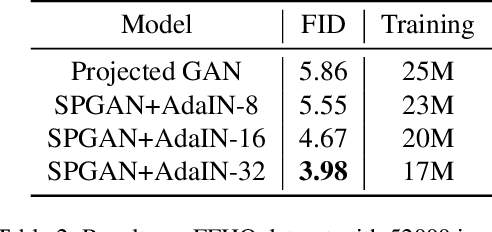
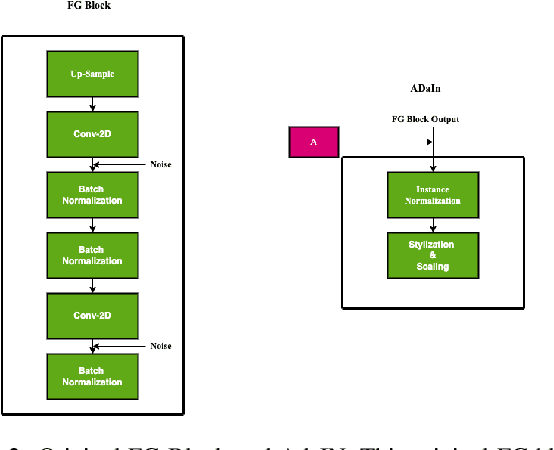
Generative Adversarial Networks are used for generating the data using a generator and a discriminator, GANs usually produce high-quality images, but training GANs in an adversarial setting is a difficult task. GANs require high computation power and hyper-parameter regularization for converging. Projected GANs tackle the training difficulty of GANs by using transfer learning to project the generated and real samples into a pre-trained feature space. Projected GANs improve the training time and convergence but produce artifacts in the generated images which reduce the quality of the generated samples, we propose an optimized architecture called Stylized Projected GANs which integrates the mapping network of the Style GANs with Skip Layer Excitation of Fast GAN. The integrated modules are incorporated within the generator architecture of the Fast GAN to mitigate the problem of artifacts in the generated images.
HyperCoil-Recon: A Hypernetwork-based Adaptive Coil Configuration Task Switching Network for MRI Reconstruction
Aug 09, 2023Parallel imaging, a fast MRI technique, involves dynamic adjustments based on the configuration i.e. number, positioning, and sensitivity of the coils with respect to the anatomy under study. Conventional deep learning-based image reconstruction models have to be trained or fine-tuned for each configuration, posing a barrier to clinical translation, given the lack of computational resources and machine learning expertise for clinicians to train models at deployment. Joint training on diverse datasets learns a single weight set that might underfit to deviated configurations. We propose, HyperCoil-Recon, a hypernetwork-based coil configuration task-switching network for multi-coil MRI reconstruction that encodes varying configurations of the numbers of coils in a multi-tasking perspective, posing each configuration as a task. The hypernetworks infer and embed task-specific weights into the reconstruction network, 1) effectively utilizing the contextual knowledge of common and varying image features among the various fields-of-view of the coils, and 2) enabling generality to unseen configurations at test time. Experiments reveal that our approach 1) adapts on the fly to various unseen configurations up to 32 coils when trained on lower numbers (i.e. 7 to 11) of randomly varying coils, and to 120 deviated unseen configurations when trained on 18 configurations in a single model, 2) matches the performance of coil configuration-specific models, and 3) outperforms configuration-invariant models with improvement margins of around 1 dB / 0.03 and 0.3 dB / 0.02 in PSNR / SSIM for knee and brain data. Our code is available at https://github.com/sriprabhar/HyperCoil-Recon
HSD-PAM: High Speed Super Resolution Deep Penetration Photoacoustic Microscopy Imaging Boosted by Dual Branch Fusion Network
Aug 09, 2023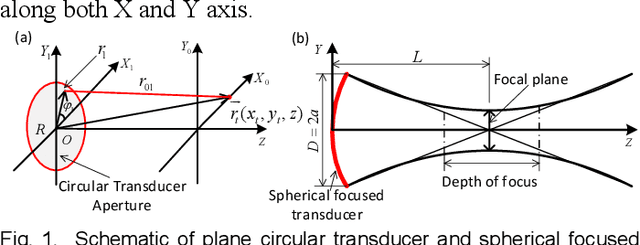
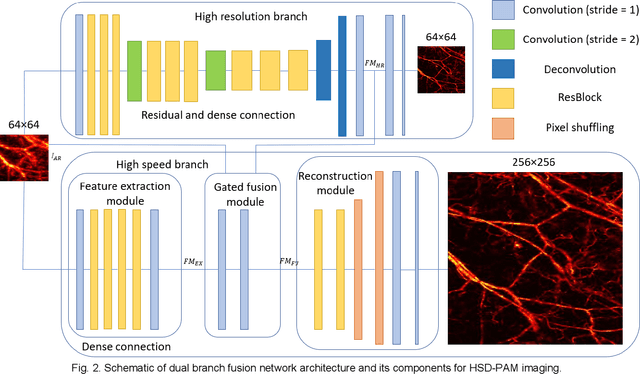
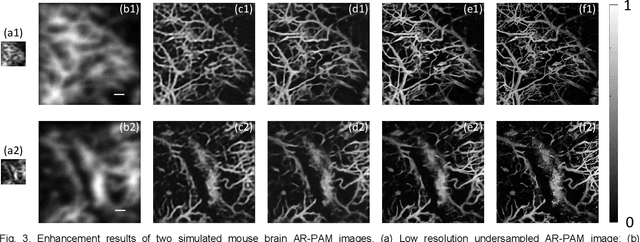
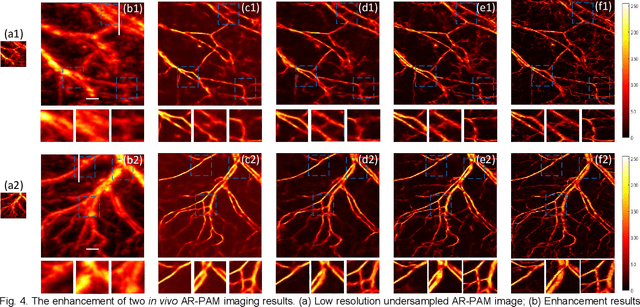
Photoacoustic microscopy (PAM) is a novel implementation of photoacoustic imaging (PAI) for visualizing the 3D bio-structure, which is realized by raster scanning of the tissue. However, as three involved critical imaging parameters, imaging speed, lateral resolution, and penetration depth have mutual effect to one the other. The improvement of one parameter results in the degradation of other two parameters, which constrains the overall performance of the PAM system. Here, we propose to break these limitations by hardware and software co-design. Starting with low lateral resolution, low sampling rate AR-PAM imaging which possesses the deep penetration capability, we aim to enhance the lateral resolution and up sampling the images, so that high speed, super resolution, and deep penetration for the PAM system (HSD-PAM) can be achieved. Data-driven based algorithm is a promising approach to solve this issue, thereby a dedicated novel dual branch fusion network is proposed, which includes a high resolution branch and a high speed branch. Since the availability of switchable AR-OR-PAM imaging system, the corresponding low resolution, undersample AR-PAM and high resolution, full sampled OR-PAM image pairs are utilized for training the network. Extensive simulation and in vivo experiments have been conducted to validate the trained model, enhancement results have proved the proposed algorithm achieved the best perceptual and quantitative image quality. As a result, the imaging speed is increased 16 times and the imaging lateral resolution is improved 5 times, while the deep penetration merit of AR-PAM modality is still reserved.
Task Offloading for Smart Glasses in Healthcare: Enhancing Detection of Elevated Body Temperature
Aug 14, 2023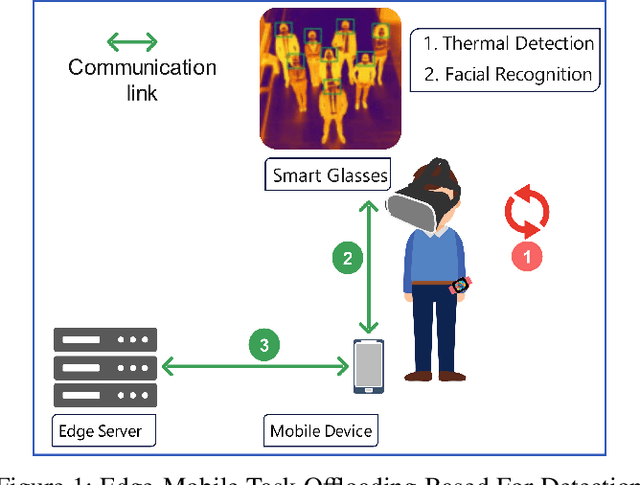
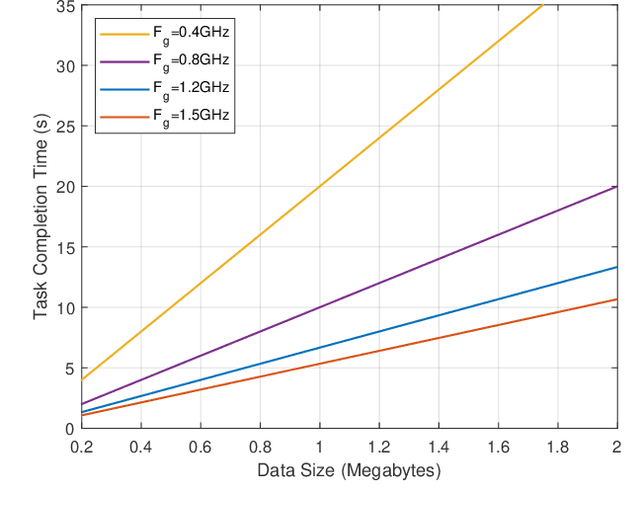
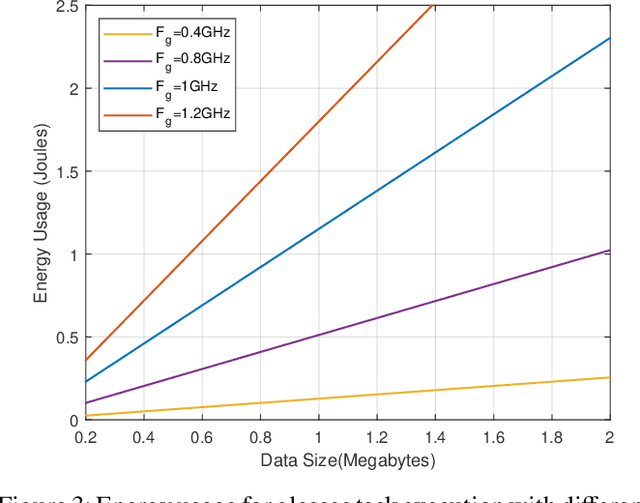
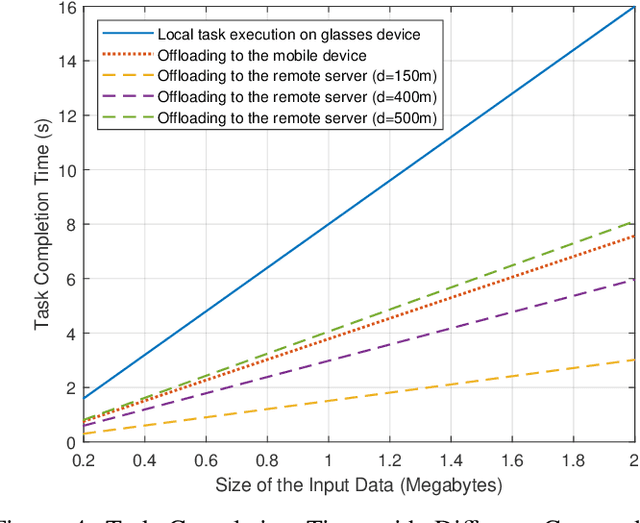
Wearable devices like smart glasses have gained popularity across various applications. However, their limited computational capabilities pose challenges for tasks that require extensive processing, such as image and video processing, leading to drained device batteries. To address this, offloading such tasks to nearby powerful remote devices, such as mobile devices or remote servers, has emerged as a promising solution. This paper focuses on analyzing task-offloading scenarios for a healthcare monitoring application performed on smart wearable glasses, aiming to identify the optimal conditions for offloading. The study evaluates performance metrics including task completion time, computing capabilities, and energy consumption under realistic conditions. A specific use case is explored within an indoor area like an airport, where security agents wearing smart glasses to detect elevated body temperature in individuals, potentially indicating COVID-19. The findings highlight the potential benefits of task offloading for wearable devices in healthcare settings, demonstrating its practicality and relevance.