 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Neurons in Pretrained Text-Only Transformers
Aug 03, 2023
Language models demonstrate remarkable capacity to generalize representations learned in one modality to downstream tasks in other modalities. Can we trace this ability to individual neurons? We study the case where a frozen text transformer is augmented with vision using a self-supervised visual encoder and a single linear projection learned on an image-to-text task. Outputs of the projection layer are not immediately decodable into language describing image content; instead, we find that translation between modalities occurs deeper within the transformer. We introduce a procedure for identifying "multimodal neurons" that convert visual representations into corresponding text, and decoding the concepts they inject into the model's residual stream. In a series of experiments, we show that multimodal neurons operate on specific visual concepts across inputs, and have a systematic causal effect on image captioning.
Scoring Cycling Environments Perceived Safety using Pairwise Image Comparisons
Jul 31, 2023

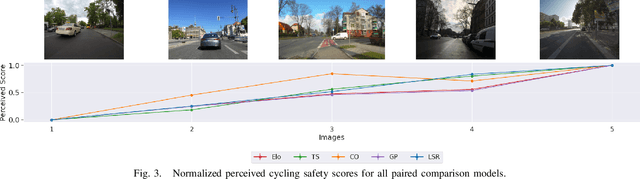
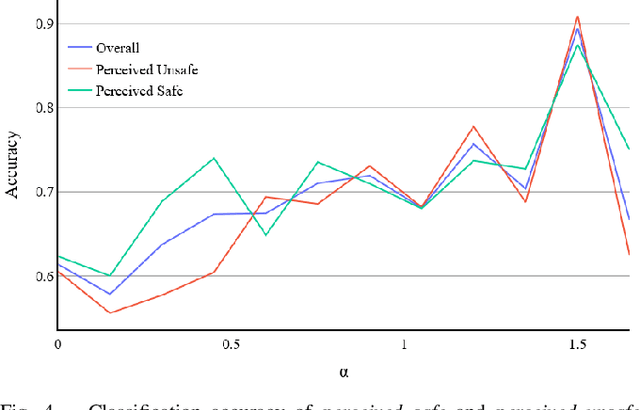
Today, many cities seek to transition to more sustainable transportation systems. Cycling is critical in this transition for shorter trips, including first-and-last-mile links to transit. Yet, if individuals perceive cycling as unsafe, they will not cycle and choose other transportation modes. This study presents a novel approach to identifying how the perception of cycling safety can be analyzed and understood and the impact of the built environment and cycling contexts on such perceptions. We base our work on other perception studies and pairwise comparisons, using real-world images to survey respondents. We repeatedly show respondents two road environments and ask them to select the one they perceive as safer for cycling. We compare several methods capable of rating cycling environments from pairwise comparisons and classify cycling environments perceived as safe or unsafe. Urban planning can use this score to improve interventions' effectiveness and improve cycling promotion campaigns. Furthermore, this approach facilitates the continuous assessment of changing cycling environments, allows for a short-term evaluation of measures, and is efficiently deployed in different locations or contexts.
MDViT: Multi-domain Vision Transformer for Small Medical Image Segmentation Datasets
Jul 05, 2023
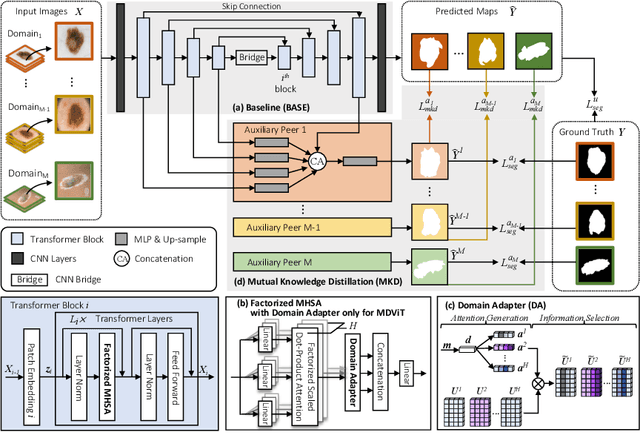
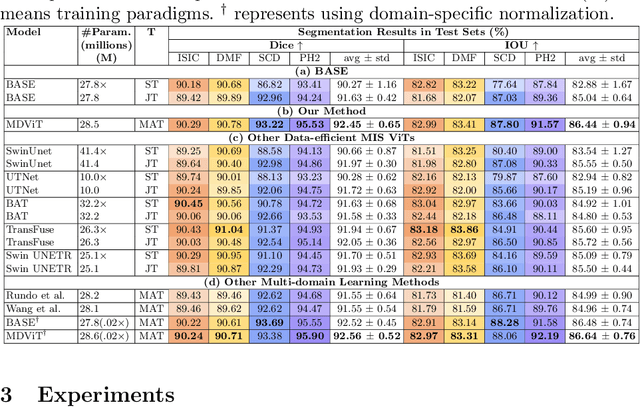
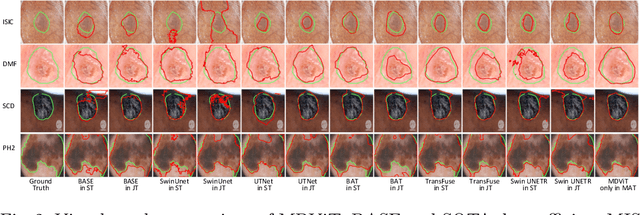
Despite its clinical utility, medical image segmentation (MIS) remains a daunting task due to images' inherent complexity and variability. Vision transformers (ViTs) have recently emerged as a promising solution to improve MIS; however, they require larger training datasets than convolutional neural networks. To overcome this obstacle, data-efficient ViTs were proposed, but they are typically trained using a single source of data, which overlooks the valuable knowledge that could be leveraged from other available datasets. Naivly combining datasets from different domains can result in negative knowledge transfer (NKT), i.e., a decrease in model performance on some domains with non-negligible inter-domain heterogeneity. In this paper, we propose MDViT, the first multi-domain ViT that includes domain adapters to mitigate data-hunger and combat NKT by adaptively exploiting knowledge in multiple small data resources (domains). Further, to enhance representation learning across domains, we integrate a mutual knowledge distillation paradigm that transfers knowledge between a universal network (spanning all the domains) and auxiliary domain-specific branches. Experiments on 4 skin lesion segmentation datasets show that MDViT outperforms state-of-the-art algorithms, with superior segmentation performance and a fixed model size, at inference time, even as more domains are added. Our code is available at https://github.com/siyi-wind/MDViT.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023
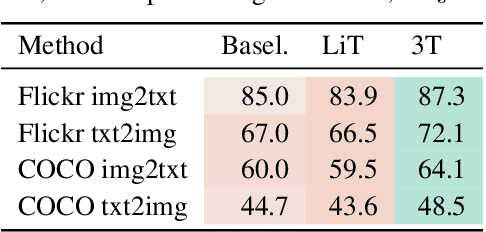
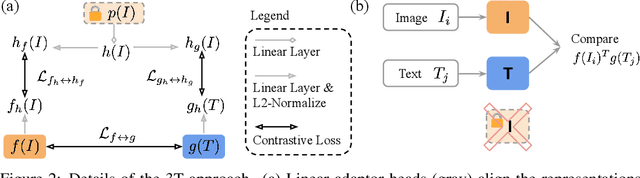
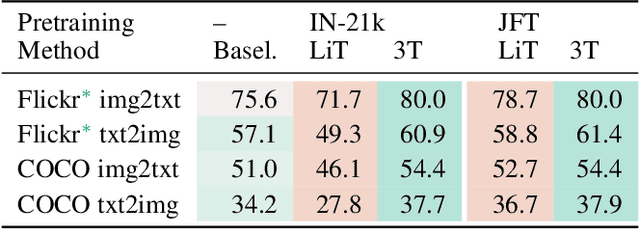
We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
AudioVMAF: Audio Quality Prediction with VMAF
Aug 07, 2023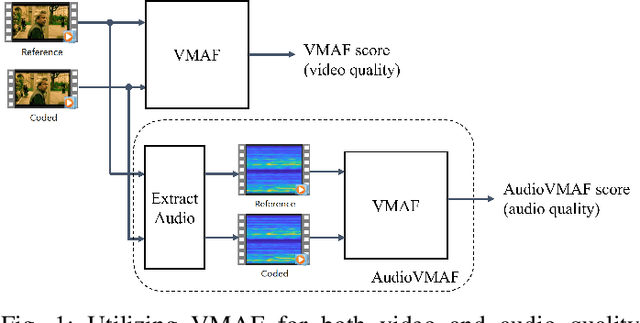
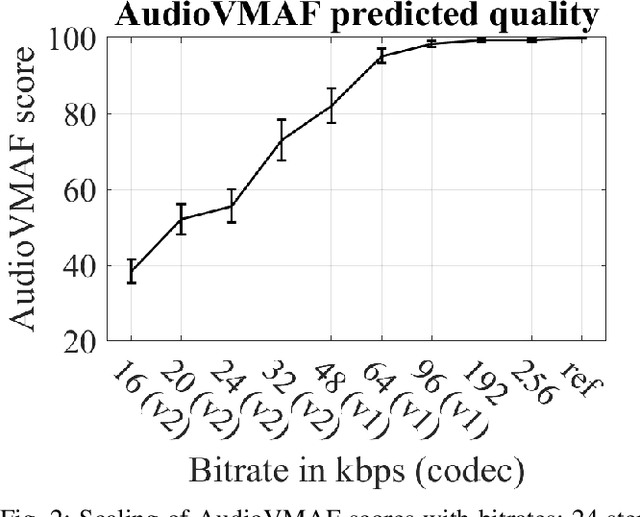
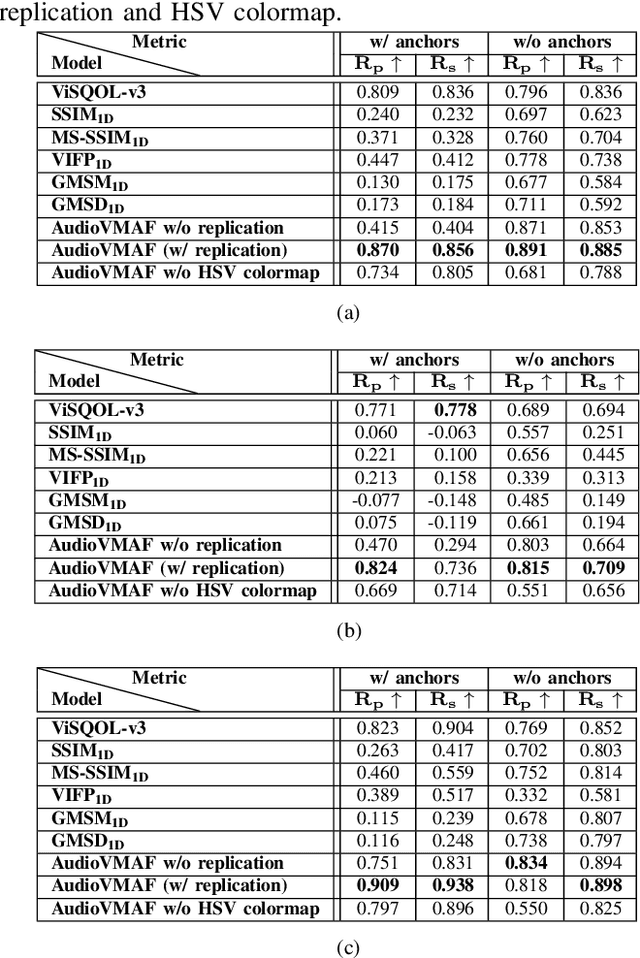
Video Multimethod Assessment Fusion (VMAF) [1], [2], [3] is a popular tool in the industry for measuring coded video quality. In this study, we propose an auditory-inspired frontend in existing VMAF for creating videos of reference and coded spectrograms, and extended VMAF for measuring coded audio quality. We name our system AudioVMAF. We demonstrate that image replication is capable of further enhancing prediction accuracy, especially when band-limited anchors are present. The proposed method significantly outperforms all existing visual quality features repurposed for audio, and even demonstrates a significant overall improvement of 7.8% and 2.0% of Pearson and Spearman rank correlation coefficient, respectively, over a dedicated audio quality metric (ViSQOL-v3 [4]) also inspired from the image domain.
Interaction-aware Joint Attention Estimation Using People Attributes
Aug 10, 2023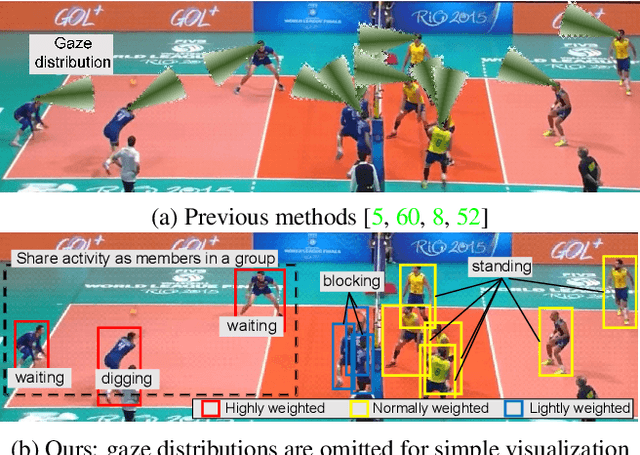

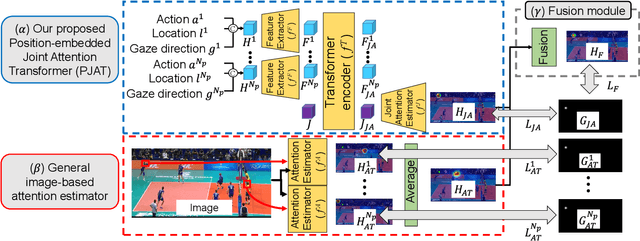
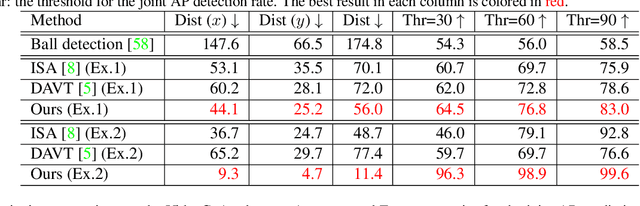
This paper proposes joint attention estimation in a single image. Different from related work in which only the gaze-related attributes of people are independently employed, (I) their locations and actions are also employed as contextual cues for weighting their attributes, and (ii) interactions among all of these attributes are explicitly modeled in our method. For the interaction modeling, we propose a novel Transformer-based attention network to encode joint attention as low-dimensional features. We introduce a specialized MLP head with positional embedding to the Transformer so that it predicts pixelwise confidence of joint attention for generating the confidence heatmap. This pixelwise prediction improves the heatmap accuracy by avoiding the ill-posed problem in which the high-dimensional heatmap is predicted from the low-dimensional features. The estimated joint attention is further improved by being integrated with general image-based attention estimation. Our method outperforms SOTA methods quantitatively in comparative experiments. Code: https://anonymous.4open.science/r/anonymized_codes-ECA4.
Transforming Breast Cancer Diagnosis: Towards Real-Time Ultrasound to Mammogram Conversion for Cost-Effective Diagnosis
Aug 10, 2023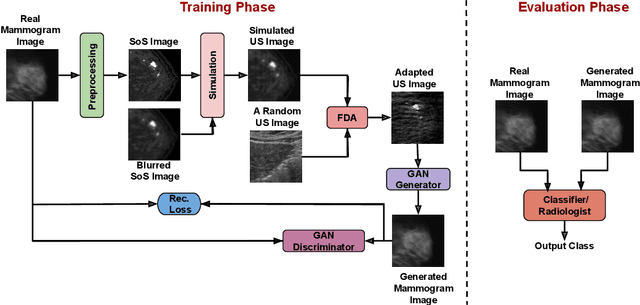
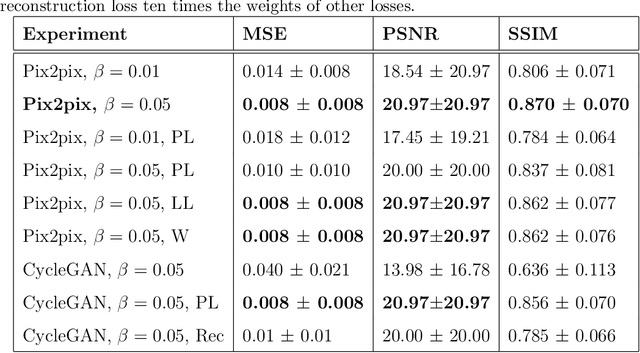

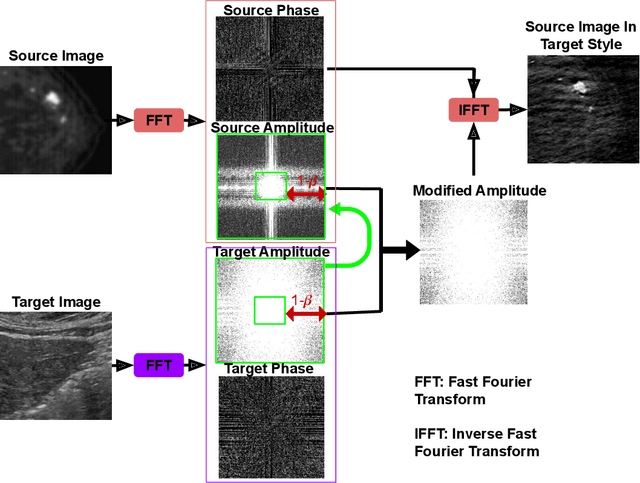
Ultrasound (US) imaging is better suited for intraoperative settings because it is real-time and more portable than other imaging techniques, such as mammography. However, US images are characterized by lower spatial resolution noise-like artifacts. This research aims to address these limitations by providing surgeons with mammogram-like image quality in real-time from noisy US images. Unlike previous approaches for improving US image quality that aim to reduce artifacts by treating them as (speckle noise), we recognize their value as informative wave interference pattern (WIP). To achieve this, we utilize the Stride software to numerically solve the forward model, generating ultrasound images from mammograms images by solving wave-equations. Additionally, we leverage the power of domain adaptation to enhance the realism of the simulated ultrasound images. Then, we utilize generative adversarial networks (GANs) to tackle the inverse problem of generating mammogram-quality images from ultrasound images. The resultant images have considerably more discernible details than the original US images.
TrOMR:Transformer-Based Polyphonic Optical Music Recognition
Aug 18, 2023Optical Music Recognition (OMR) is an important technology in music and has been researched for a long time. Previous approaches for OMR are usually based on CNN for image understanding and RNN for music symbol classification. In this paper, we propose a transformer-based approach with excellent global perceptual capability for end-to-end polyphonic OMR, called TrOMR. We also introduce a novel consistency loss function and a reasonable approach for data annotation to improve recognition accuracy for complex music scores. Extensive experiments demonstrate that TrOMR outperforms current OMR methods, especially in real-world scenarios. We also develop a TrOMR system and build a camera scene dataset for full-page music scores in real-world. The code and datasets will be made available for reproducibility.
Nested Diffusion Processes for Anytime Image Generation
May 30, 2023
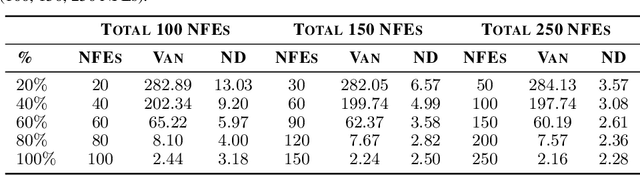
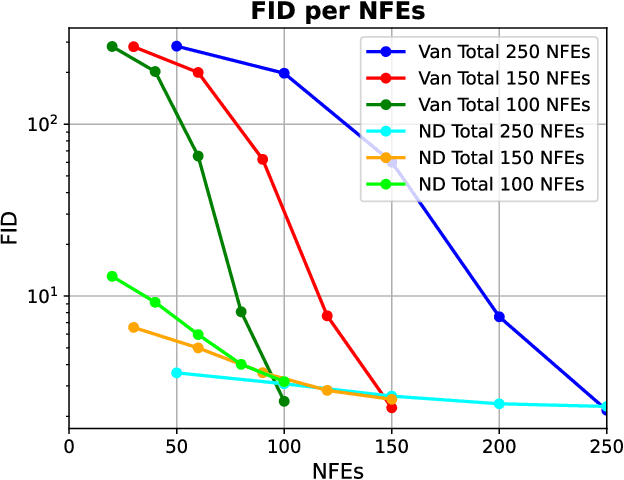

Diffusion models are the current state-of-the-art in image generation, synthesizing high-quality images by breaking down the generation process into many fine-grained denoising steps. Despite their good performance, diffusion models are computationally expensive, requiring many neural function evaluations (NFEs). In this work, we propose an anytime diffusion-based method that can generate viable images when stopped at arbitrary times before completion. Using existing pretrained diffusion models, we show that the generation scheme can be recomposed as two nested diffusion processes, enabling fast iterative refinement of a generated image. We use this Nested Diffusion approach to peek into the generation process and enable flexible scheduling based on the instantaneous preference of the user. In experiments on ImageNet and Stable Diffusion-based text-to-image generation, we show, both qualitatively and quantitatively, that our method's intermediate generation quality greatly exceeds that of the original diffusion model, while the final slow generation result remains comparable.
1M parameters are enough? A lightweight CNN-based model for medical image segmentation
Jun 28, 2023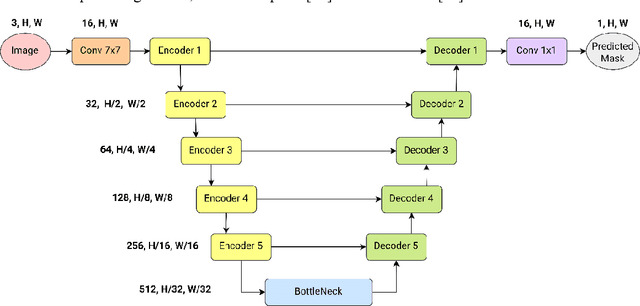
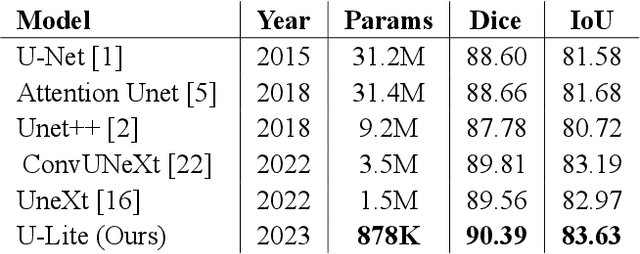
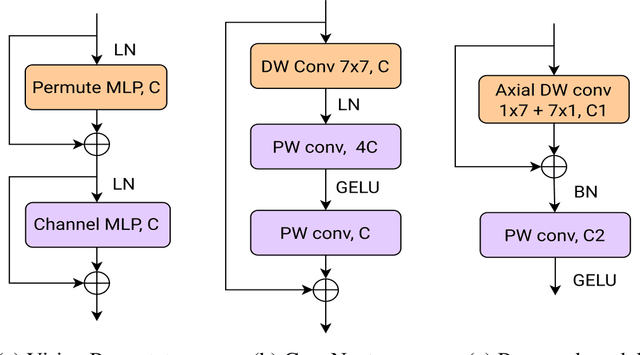
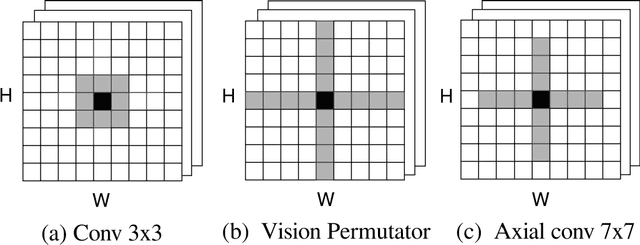
Convolutional neural networks (CNNs) and Transformer-based models are being widely applied in medical image segmentation thanks to their ability to extract high-level features and capture important aspects of the image. However, there is often a trade-off between the need for high accuracy and the desire for low computational cost. A model with higher parameters can theoretically achieve better performance but also result in more computational complexity and higher memory usage, and thus is not practical to implement. In this paper, we look for a lightweight U-Net-based model which can remain the same or even achieve better performance, namely U-Lite. We design U-Lite based on the principle of Depthwise Separable Convolution so that the model can both leverage the strength of CNNs and reduce a remarkable number of computing parameters. Specifically, we propose Axial Depthwise Convolutions with kernels 7x7 in both the encoder and decoder to enlarge the model receptive field. To further improve the performance, we use several Axial Dilated Depthwise Convolutions with filters 3x3 for the bottleneck as one of our branches. Overall, U-Lite contains only 878K parameters, 35 times less than the traditional U-Net, and much more times less than other modern Transformer-based models. The proposed model cuts down a large amount of computational complexity while attaining an impressive performance on medical segmentation tasks compared to other state-of-the-art architectures. The code will be available at: https://github.com/duong-db/U-Lite.