 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Introducing A Novel Method For Adaptive Thresholding In Brain Tumor Medical Image Segmentation
Jun 27, 2023
One of the most significant challenges in the field of deep learning and medical image segmentation is to determine an appropriate threshold for classifying each pixel. This threshold is a value above which the model's output is considered to belong to a specific class. Manual thresholding based on personal experience is error-prone and time-consuming, particularly for complex problems such as medical images. Traditional methods for thresholding are not effective for determining the threshold value for such problems. To tackle this challenge, automatic thresholding methods using deep learning have been proposed. However, the main issue with these methods is that they often determine the threshold value statically without considering changes in input data. Since input data can be dynamic and may change over time, threshold determination should be adaptive and consider input data and environmental conditions.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023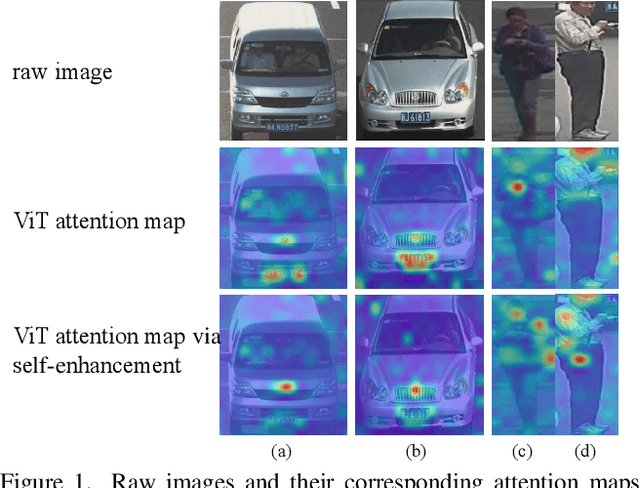
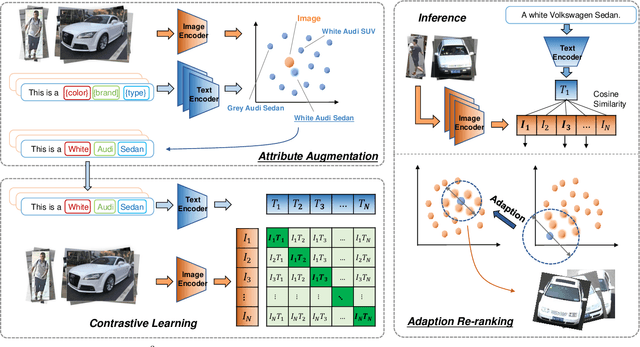

The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
Food Classification using Joint Representation of Visual and Textual Data
Aug 03, 2023Food classification is an important task in health care. In this work, we propose a multimodal classification framework that uses the modified version of EfficientNet with the Mish activation function for image classification, and the traditional BERT transformer-based network is used for text classification. The proposed network and the other state-of-the-art methods are evaluated on a large open-source dataset, UPMC Food-101. The experimental results show that the proposed network outperforms the other methods, a significant difference of 11.57% and 6.34% in accuracy is observed for image and text classification, respectively, when compared with the second-best performing method. We also compared the performance in terms of accuracy, precision, and recall for text classification using both machine learning and deep learning-based models. The comparative analysis from the prediction results of both images and text demonstrated the efficiency and robustness of the proposed approach.
SaaFormer: Spectral-spatial Axial Aggregation Transformer for Hyperspectral Image Classification
Jun 29, 2023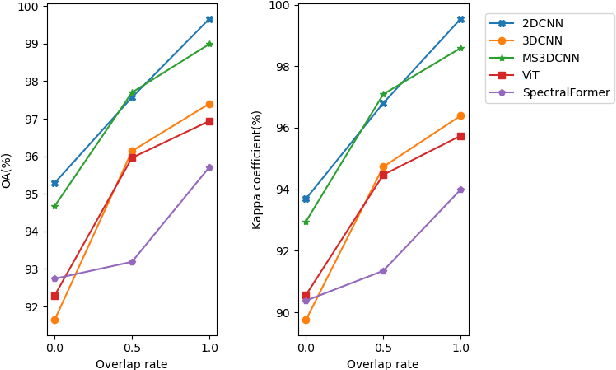
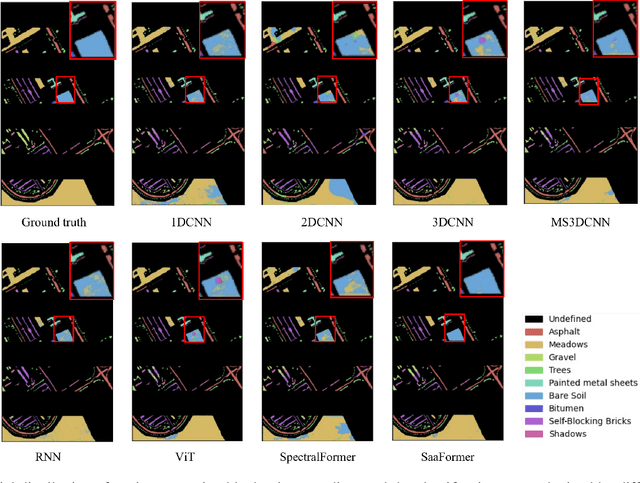
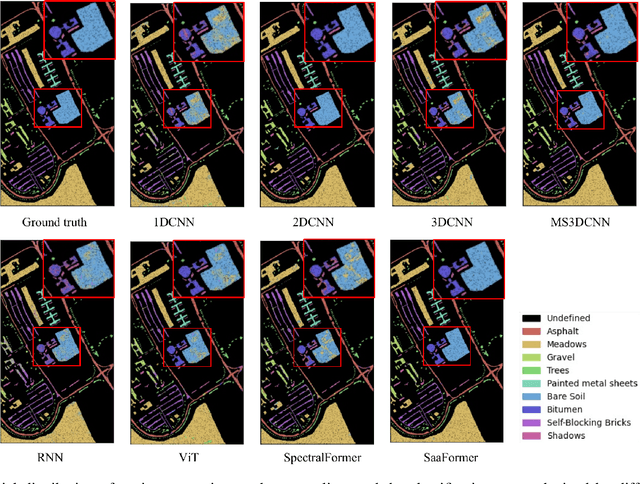
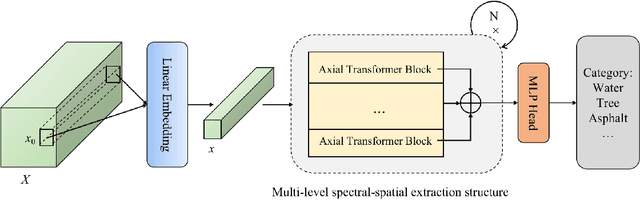
Hyperspectral images (HSI) captured from earth observing satellites and aircraft is becoming increasingly important for applications in agriculture, environmental monitoring, mining, etc. Due to the limited available hyperspectral datasets, the pixel-wise random sampling is the most commonly used training-test dataset partition approach, which has significant overlap between samples in training and test datasets. Furthermore, our experimental observations indicates that regions with larger overlap often exhibit higher classification accuracy. Consequently, the pixel-wise random sampling approach poses a risk of data leakage. Thus, we propose a block-wise sampling method to minimize the potential for data leakage. Our experimental findings also confirm the presence of data leakage in models such as 2DCNN. Further, We propose a spectral-spatial axial aggregation transformer model, namely SaaFormer, to address the challenges associated with hyperspectral image classifier that considers HSI as long sequential three-dimensional images. The model comprises two primary components: axial aggregation attention and multi-level spectral-spatial extraction. The axial aggregation attention mechanism effectively exploits the continuity and correlation among spectral bands at each pixel position in hyperspectral images, while aggregating spatial dimension features. This enables SaaFormer to maintain high precision even under block-wise sampling. The multi-level spectral-spatial extraction structure is designed to capture the sensitivity of different material components to specific spectral bands, allowing the model to focus on a broader range of spectral details. The results on six publicly available datasets demonstrate that our model exhibits comparable performance when using random sampling, while significantly outperforming other methods when employing block-wise sampling partition.
SAR-to-Optical Image Translation via Thermodynamics-inspired Network
May 23, 2023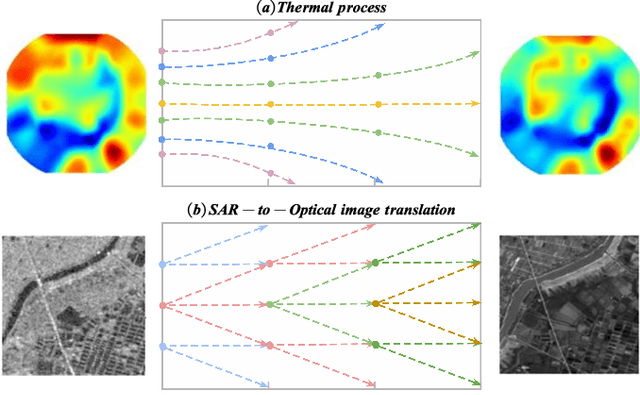
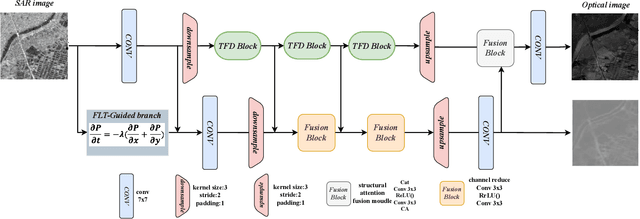
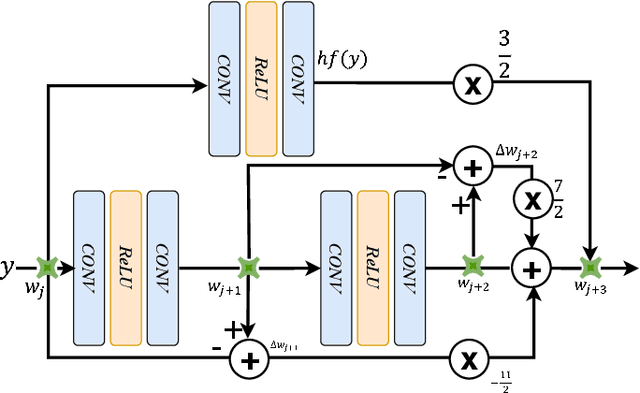
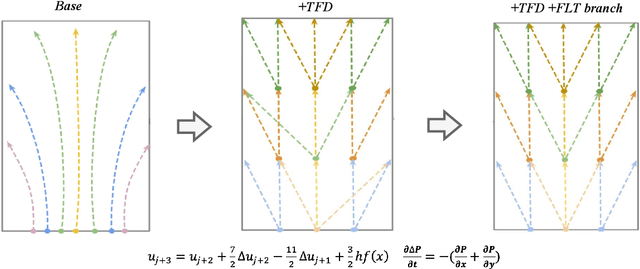
Synthetic aperture radar (SAR) is prevalent in the remote sensing field but is difficult to interpret in human visual perception. Recently, SAR-to-optical (S2O) image conversion methods have provided a prospective solution for interpretation. However, since there is a huge domain difference between optical and SAR images, they suffer from low image quality and geometric distortion in the produced optical images. Motivated by the analogy between pixels during the S2O image translation and molecules in a heat field, Thermodynamics-inspired Network for SAR-to-Optical Image Translation (S2O-TDN) is proposed in this paper. Specifically, we design a Third-order Finite Difference (TFD) residual structure in light of the TFD equation of thermodynamics, which allows us to efficiently extract inter-domain invariant features and facilitate the learning of the nonlinear translation mapping. In addition, we exploit the first law of thermodynamics (FLT) to devise an FLT-guided branch that promotes the state transition of the feature values from the unstable diffusion state to the stable one, aiming to regularize the feature diffusion and preserve image structures during S2O image translation. S2O-TDN follows an explicit design principle derived from thermodynamic theory and enjoys the advantage of explainability. Experiments on the public SEN1-2 dataset show the advantages of the proposed S2O-TDN over the current methods with more delicate textures and higher quantitative results.
MMNet: Multi-Mask Network for Referring Image Segmentation
May 24, 2023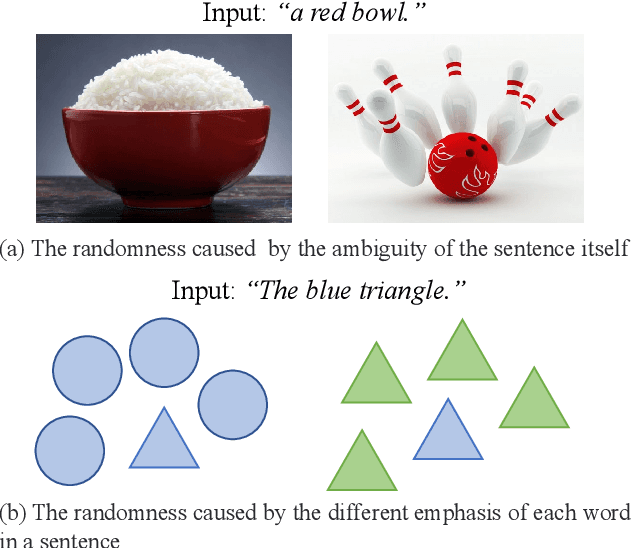
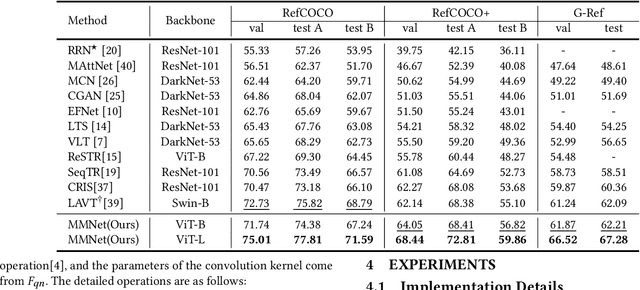
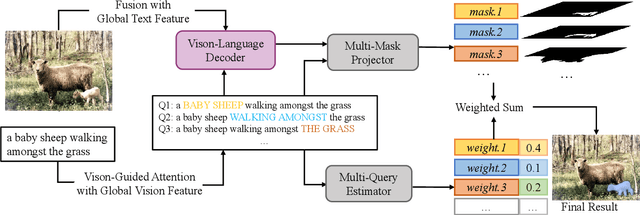
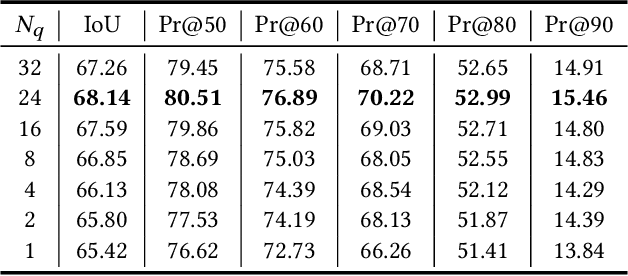
Referring image segmentation aims to segment an object referred to by natural language expression from an image. However, this task is challenging due to the distinct data properties between text and image, and the randomness introduced by diverse objects and unrestricted language expression. Most of previous work focus on improving cross-modal feature fusion while not fully addressing the inherent uncertainty caused by diverse objects and unrestricted language. To tackle these problems, we propose an end-to-end Multi-Mask Network for referring image segmentation(MMNet). we first combine picture and language and then employ an attention mechanism to generate multiple queries that represent different aspects of the language expression. We then utilize these queries to produce a series of corresponding segmentation masks, assigning a score to each mask that reflects its importance. The final result is obtained through the weighted sum of all masks, which greatly reduces the randomness of the language expression. Our proposed framework demonstrates superior performance compared to state-of-the-art approaches on the two most commonly used datasets, RefCOCO, RefCOCO+ and G-Ref, without the need for any post-processing. This further validates the efficacy of our proposed framework.
OmniZoomer: Learning to Move and Zoom in on Sphere at High-Resolution
Aug 19, 2023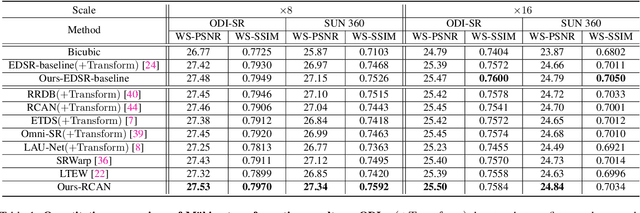
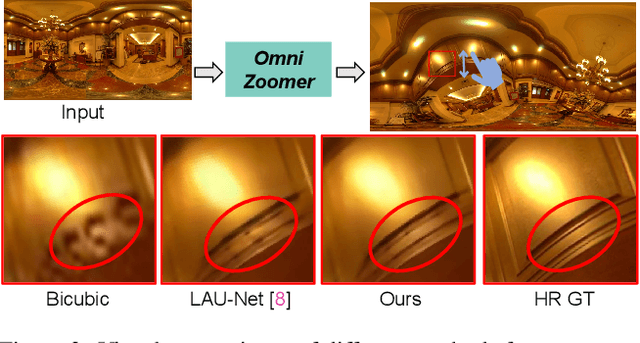
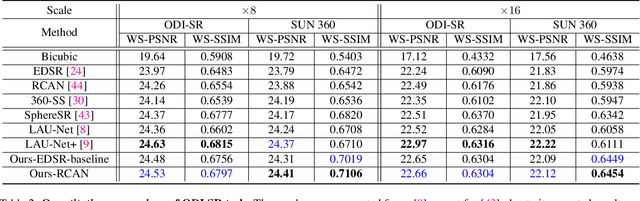
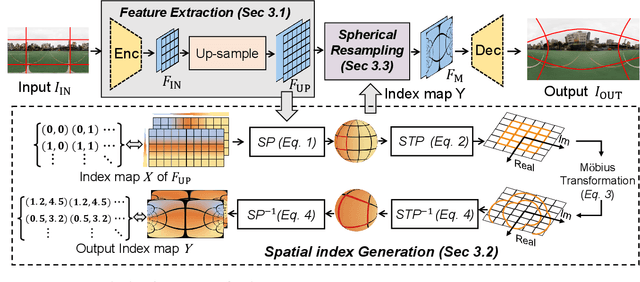
Omnidirectional images (ODIs) have become increasingly popular, as their large field-of-view (FoV) can offer viewers the chance to freely choose the view directions in immersive environments such as virtual reality. The M\"obius transformation is typically employed to further provide the opportunity for movement and zoom on ODIs, but applying it to the image level often results in blurry effect and aliasing problem. In this paper, we propose a novel deep learning-based approach, called \textbf{OmniZoomer}, to incorporate the M\"obius transformation into the network for movement and zoom on ODIs. By learning various transformed feature maps under different conditions, the network is enhanced to handle the increasing edge curvatures, which alleviates the blurry effect. Moreover, to address the aliasing problem, we propose two key components. Firstly, to compensate for the lack of pixels for describing curves, we enhance the feature maps in the high-resolution (HR) space and calculate the transformed index map with a spatial index generation module. Secondly, considering that ODIs are inherently represented in the spherical space, we propose a spherical resampling module that combines the index map and HR feature maps to transform the feature maps for better spherical correlation. The transformed feature maps are decoded to output a zoomed ODI. Experiments show that our method can produce HR and high-quality ODIs with the flexibility to move and zoom in to the object of interest. Project page is available at http://vlislab22.github.io/OmniZoomer/.
Extending Explainable Boosting Machines to Scientific Image Data
May 25, 2023

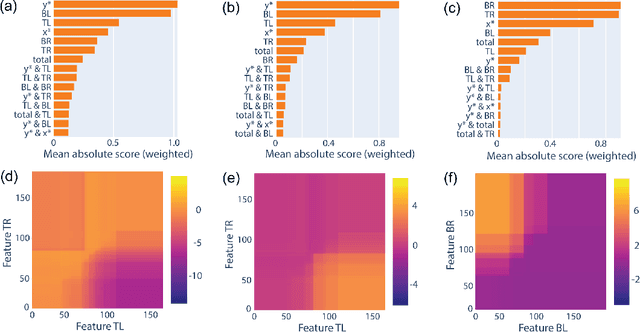
As the deployment of computer vision technology becomes increasingly common in applications of consequence such as medicine or science, the need for explanations of the system output has become a focus of great concern. Unfortunately, many state-of-the-art computer vision models are opaque, making their use challenging from an explanation standpoint, and current approaches to explaining these opaque models have stark limitations and have been the subject of serious criticism. In contrast, Explainable Boosting Machines (EBMs) are a class of models that are easy to interpret and achieve performance on par with the very best-performing models, however, to date EBMs have been limited solely to tabular data. Driven by the pressing need for interpretable models in science, we propose the use of EBMs for scientific image data. Inspired by an important application underpinning the development of quantum technologies, we apply EBMs to cold-atom soliton image data, and, in doing so, demonstrate EBMs for image data for the first time. To tabularize the image data we employ Gabor Wavelet Transform-based techniques that preserve the spatial structure of the data. We show that our approach provides better explanations than other state-of-the-art explainability methods for images.
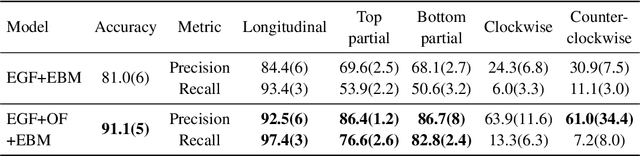
Robust Asymmetric Loss for Multi-Label Long-Tailed Learning
Aug 10, 2023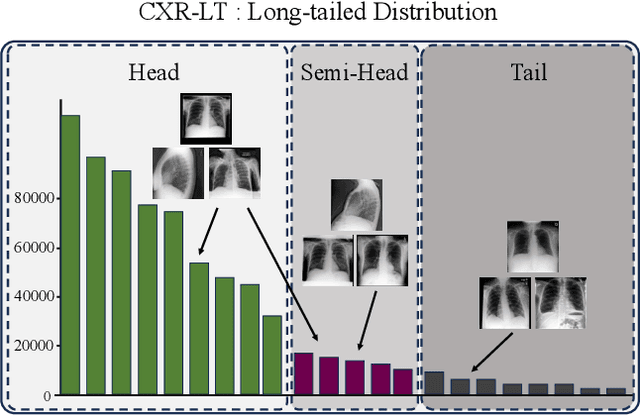
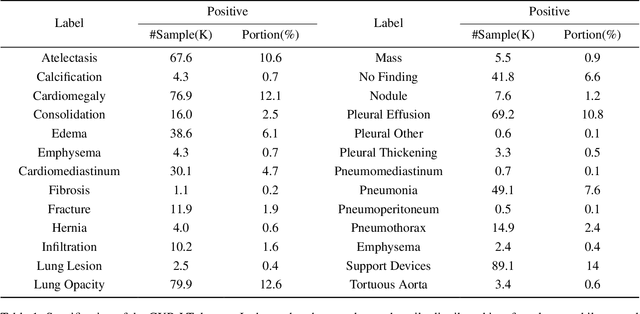
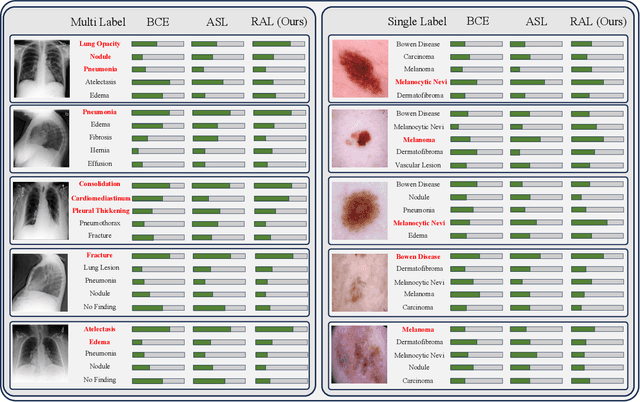
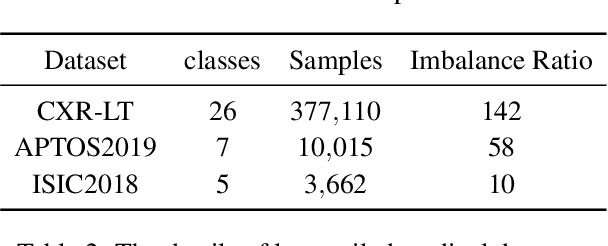
In real medical data, training samples typically show long-tailed distributions with multiple labels. Class distribution of the medical data has a long-tailed shape, in which the incidence of different diseases is quite varied, and at the same time, it is not unusual for images taken from symptomatic patients to be multi-label diseases. Therefore, in this paper, we concurrently address these two issues by putting forth a robust asymmetric loss on the polynomial function. Since our loss tackles both long-tailed and multi-label classification problems simultaneously, it leads to a complex design of the loss function with a large number of hyper-parameters. Although a model can be highly fine-tuned due to a large number of hyper-parameters, it is difficult to optimize all hyper-parameters at the same time, and there might be a risk of overfitting a model. Therefore, we regularize the loss function using the Hill loss approach, which is beneficial to be less sensitive against the numerous hyper-parameters so that it reduces the risk of overfitting the model. For this reason, the proposed loss is a generic method that can be applied to most medical image classification tasks and does not make the training process more time-consuming. We demonstrate that the proposed robust asymmetric loss performs favorably against the long-tailed with multi-label medical image classification in addition to the various long-tailed single-label datasets. Notably, our method achieves Top-5 results on the CXR-LT dataset of the ICCV CVAMD 2023 competition. We opensource our implementation of the robust asymmetric loss in the public repository: https://github.com/kalelpark/RAL.
Towards Adaptable and Interactive Image Captioning with Data Augmentation and Episodic Memory
Jun 06, 2023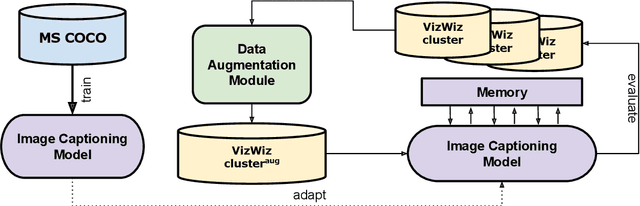
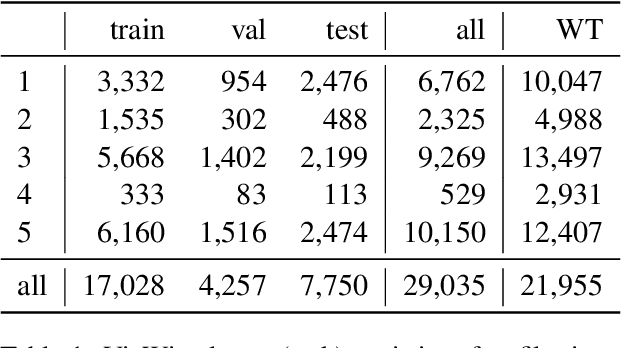

Interactive machine learning (IML) is a beneficial learning paradigm in cases of limited data availability, as human feedback is incrementally integrated into the training process. In this paper, we present an IML pipeline for image captioning which allows us to incrementally adapt a pre-trained image captioning model to a new data distribution based on user input. In order to incorporate user input into the model, we explore the use of a combination of simple data augmentation methods to obtain larger data batches for each newly annotated data instance and implement continual learning methods to prevent catastrophic forgetting from repeated updates. For our experiments, we split a domain-specific image captioning dataset, namely VizWiz, into non-overlapping parts to simulate an incremental input flow for continually adapting the model to new data. We find that, while data augmentation worsens results, even when relatively small amounts of data are available, episodic memory is an effective strategy to retain knowledge from previously seen clusters.