 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved mirror ball projection for more accurate merging of multiple camera outputs and process monitoring
Aug 15, 2023
Using spherical mirrors in place of wide-angle cameras allows for cost-effective monitoring of manufacturing processes in hazardous environment, where a camera would normally not operate. This includes environments of high heat, vacuum and strong electromagnetic fields. Moreover, it allows the layering of multiple camera types (e.g., color image, near-infrared, long-wavelength infrared, ultraviolet) into a single wide-angle output, whilst accounting for the different camera placements and lenses used. Normally, the different camera positions introduce a parallax shift between the images, but with a spherical projection as produced by a spherical mirror, this parallax shift is reduced, depending on mirror size and distance to the monitoring target. This paper introduces a variation of the 'mirror ball projection', that accounts for distortion produced by a perspective camera at the pole of the projection. Finally, the efficacy of process monitoring via a mirror ball is evaluated.
Trustworthy Deep Learning for Medical Image Segmentation
May 27, 2023Despite the recent success of deep learning methods at achieving new state-of-the-art accuracy for medical image segmentation, some major limitations are still restricting their deployment into clinics. One major limitation of deep learning-based segmentation methods is their lack of robustness to variability in the image acquisition protocol and in the imaged anatomy that were not represented or were underrepresented in the training dataset. This suggests adding new manually segmented images to the training dataset to better cover the image variability. However, in most cases, the manual segmentation of medical images requires highly skilled raters and is time-consuming, making this solution prohibitively expensive. Even when manually segmented images from different sources are available, they are rarely annotated for exactly the same regions of interest. This poses an additional challenge for current state-of-the-art deep learning segmentation methods that rely on supervised learning and therefore require all the regions of interest to be segmented for all the images to be used for training. This thesis introduces new mathematical and optimization methods to mitigate those limitations.
Masked Diffusion as Self-supervised Representation Learner
Aug 10, 2023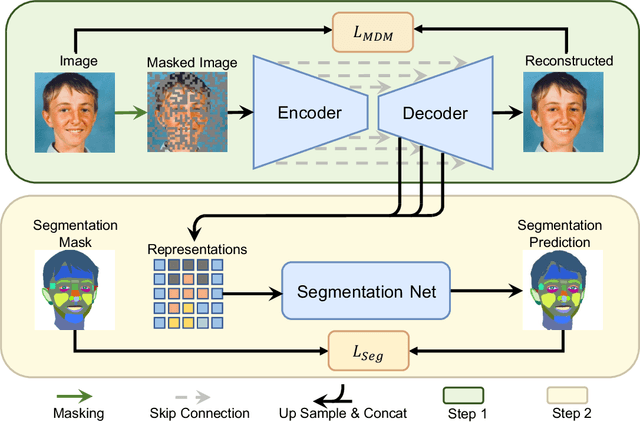
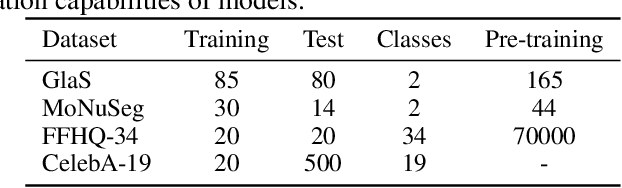
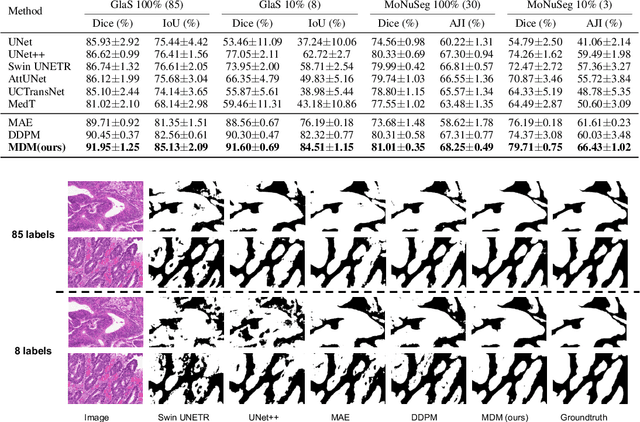

Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present masked diffusion model (MDM), a scalable self-supervised representation learner that substitutes the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly within the context of few-shot scenario.
Improving Diversity in Zero-Shot GAN Adaptation with Semantic Variations
Aug 21, 2023
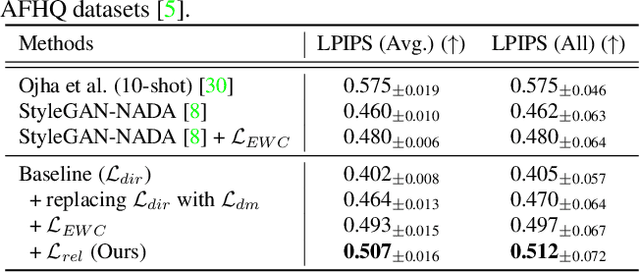
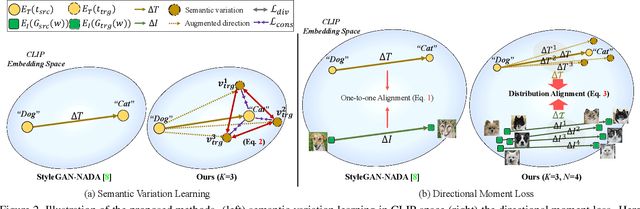

Training deep generative models usually requires a large amount of data. To alleviate the data collection cost, the task of zero-shot GAN adaptation aims to reuse well-trained generators to synthesize images of an unseen target domain without any further training samples. Due to the data absence, the textual description of the target domain and the vision-language models, e.g., CLIP, are utilized to effectively guide the generator. However, with only a single representative text feature instead of real images, the synthesized images gradually lose diversity as the model is optimized, which is also known as mode collapse. To tackle the problem, we propose a novel method to find semantic variations of the target text in the CLIP space. Specifically, we explore diverse semantic variations based on the informative text feature of the target domain while regularizing the uncontrolled deviation of the semantic information. With the obtained variations, we design a novel directional moment loss that matches the first and second moments of image and text direction distributions. Moreover, we introduce elastic weight consolidation and a relation consistency loss to effectively preserve valuable content information from the source domain, e.g., appearances. Through extensive experiments, we demonstrate the efficacy of the proposed methods in ensuring sample diversity in various scenarios of zero-shot GAN adaptation. We also conduct ablation studies to validate the effect of each proposed component. Notably, our model achieves a new state-of-the-art on zero-shot GAN adaptation in terms of both diversity and quality.
LATR: 3D Lane Detection from Monocular Images with Transformer
Aug 08, 2023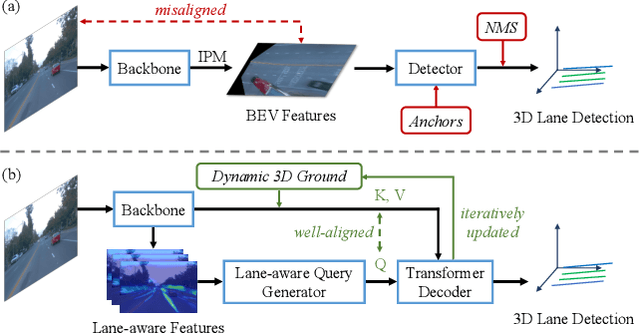
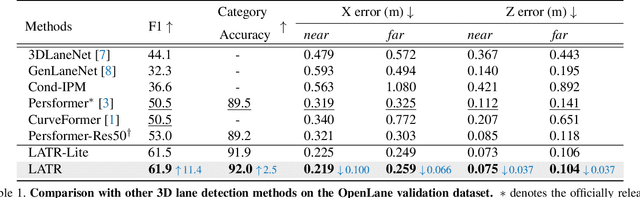
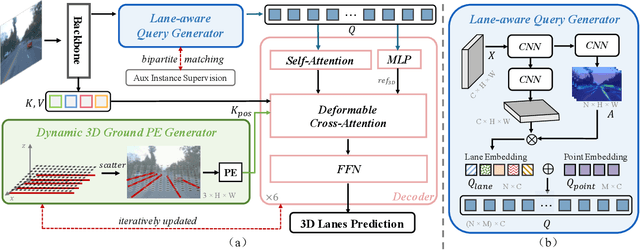
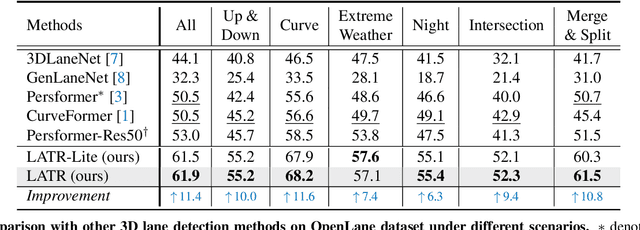
3D lane detection from monocular images is a fundamental yet challenging task in autonomous driving. Recent advances primarily rely on structural 3D surrogates (e.g., bird's eye view) that are built from front-view image features and camera parameters. However, the depth ambiguity in monocular images inevitably causes misalignment between the constructed surrogate feature map and the original image, posing a great challenge for accurate lane detection. To address the above issue, we present a novel LATR model, an end-to-end 3D lane detector that uses 3D-aware front-view features without transformed view representation. Specifically, LATR detects 3D lanes via cross-attention based on query and key-value pairs, constructed using our lane-aware query generator and dynamic 3D ground positional embedding. On the one hand, each query is generated based on 2D lane-aware features and adopts a hybrid embedding to enhance the lane information. On the other hand, 3D space information is injected as positional embedding from an iteratively-updated 3D ground plane. LATR outperforms previous state-of-the-art methods on both synthetic Apollo and realistic OpenLane by large margins (e.g., 11.4 gains in terms of F1 score on OpenLane). Code will be released at https://github.com/JMoonr/LATR.
A Differential Testing Framework to Evaluate Image Recognition Model Robustness
Jun 05, 2023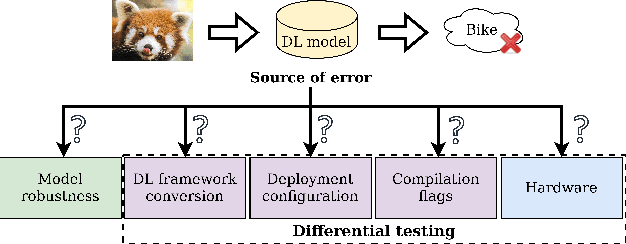
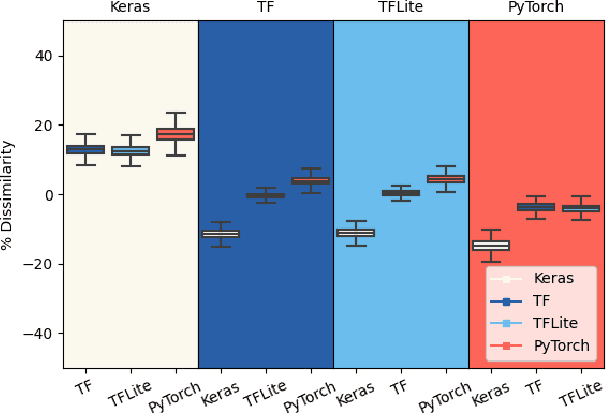
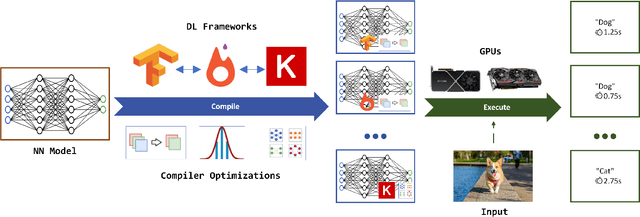
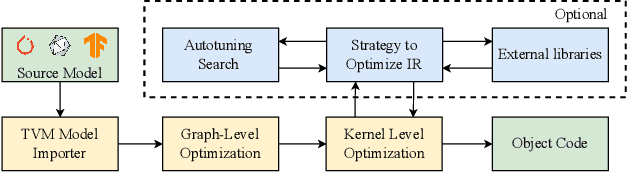
Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and TPUs for fast, timely processing. Failure in real-time image recognition tasks can occur due to sub-optimal mapping on hardware accelerators during model deployment, which may lead to timing uncertainty and erroneous behavior. Mapping on hardware accelerators is done through multiple software components like deep learning frameworks, compilers, device libraries, that we refer to as the computational environment. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment, as the impact of parameters like deep learning frameworks, compiler optimizations, and hardware devices on model performance and correctness is not well understood. In this paper we present a differential testing framework, which allows deep learning model variant generation, execution, differential analysis and testing for a number of computational environment parameters. Using our framework, we conduct an empirical study of robustness analysis of three popular image recognition models using the ImageNet dataset, assessing the impact of changing deep learning frameworks, compiler optimizations, and hardware devices. We report the impact in terms of misclassifications and inference time differences across different settings. In total, we observed up to 72% output label differences across deep learning frameworks, and up to 82% unexpected performance degradation in terms of inference time, when applying compiler optimizations. Using the analysis tools in our framework, we also perform fault analysis to understand the reasons for the observed differences.
TEC-Net: Vision Transformer Embrace Convolutional Neural Networks for Medical Image Segmentation
Jun 07, 2023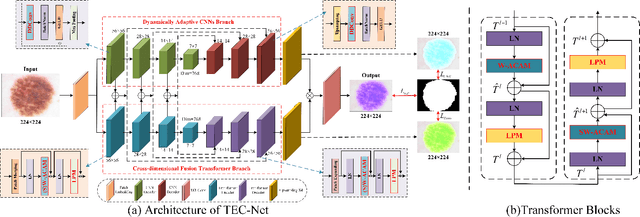
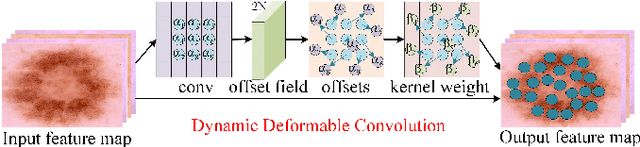
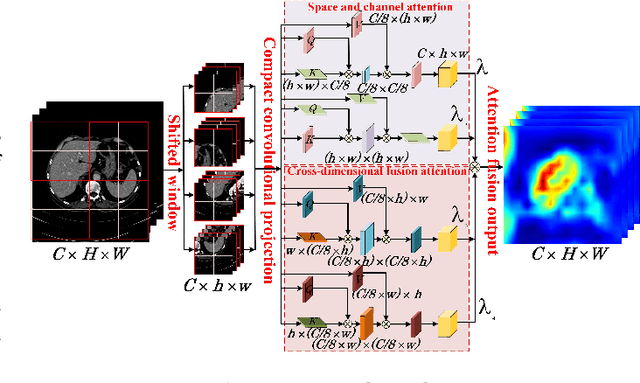
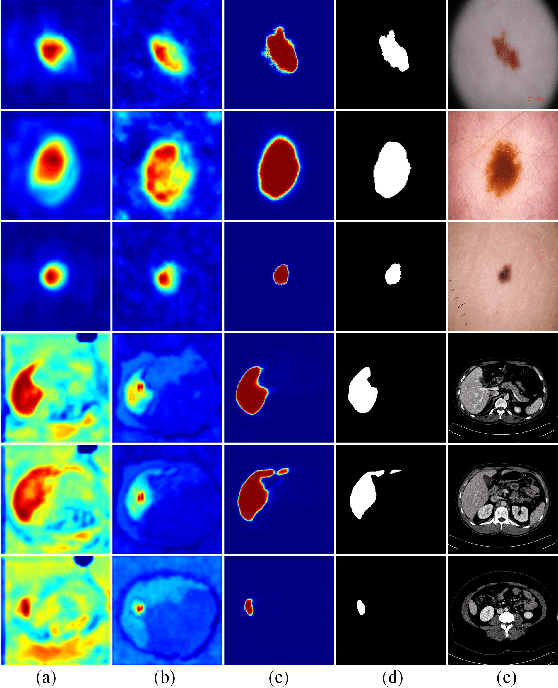
The hybrid architecture of convolution neural networks (CNN) and Transformer has been the most popular method for medical image segmentation. However, the existing networks based on the hybrid architecture suffer from two problems. First, although the CNN branch can capture image local features by using convolution operation, the vanilla convolution is unable to achieve adaptive extraction of image features. Second, although the Transformer branch can model the global information of images, the conventional self-attention only focuses on the spatial self-attention of images and ignores the channel and cross-dimensional self-attention leading to low segmentation accuracy for medical images with complex backgrounds. To solve these problems, we propose vision Transformer embrace convolutional neural networks for medical image segmentation (TEC-Net). Our network has two advantages. First, dynamic deformable convolution (DDConv) is designed in the CNN branch, which not only overcomes the difficulty of adaptive feature extraction using fixed-size convolution kernels, but also solves the defect that different inputs share the same convolution kernel parameters, effectively improving the feature expression ability of CNN branch. Second, in the Transformer branch, a (shifted)-window adaptive complementary attention module ((S)W-ACAM) and compact convolutional projection are designed to enable the network to fully learn the cross-dimensional long-range dependency of medical images with few parameters and calculations. Experimental results show that the proposed TEC-Net provides better medical image segmentation results than SOTA methods including CNN and Transformer networks. In addition, our TEC-Net requires fewer parameters and computational costs and does not rely on pre-training. The code is publicly available at https://github.com/SR0920/TEC-Net.
Generative Text-Guided 3D Vision-Language Pretraining for Unified Medical Image Segmentation
Jun 07, 2023
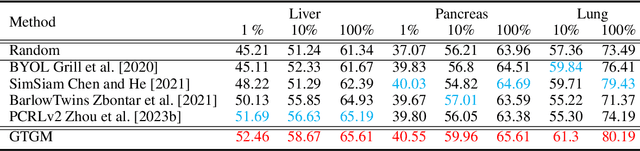
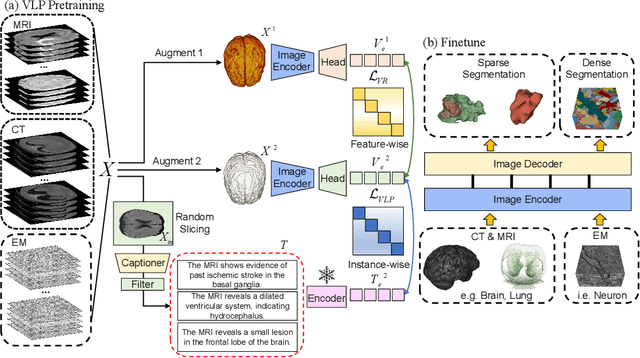
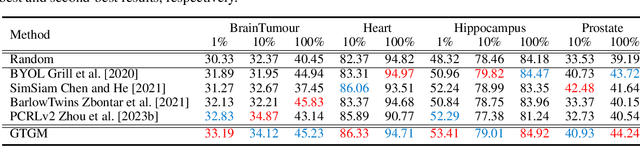
Vision-Language Pretraining (VLP) has demonstrated remarkable capabilities in learning visual representations from textual descriptions of images without annotations. Yet, effective VLP demands large-scale image-text pairs, a resource that suffers scarcity in the medical domain. Moreover, conventional VLP is limited to 2D images while medical images encompass diverse modalities, often in 3D, making the learning process more challenging. To address these challenges, we present Generative Text-Guided 3D Vision-Language Pretraining for Unified Medical Image Segmentation (GTGM), a framework that extends of VLP to 3D medical images without relying on paired textual descriptions. Specifically, GTGM utilizes large language models (LLM) to generate medical-style text from 3D medical images. This synthetic text is then used to supervise 3D visual representation learning. Furthermore, a negative-free contrastive learning objective strategy is introduced to cultivate consistent visual representations between augmented 3D medical image patches, which effectively mitigates the biases associated with strict positive-negative sample pairings. We evaluate GTGM on three imaging modalities - Computed Tomography (CT), Magnetic Resonance Imaging (MRI), and electron microscopy (EM) over 13 datasets. GTGM's superior performance across various medical image segmentation tasks underscores its effectiveness and versatility, by enabling VLP extension into 3D medical imagery while bypassing the need for paired text.
Data Curation for Image Captioning with Text-to-Image Generative Models
May 05, 2023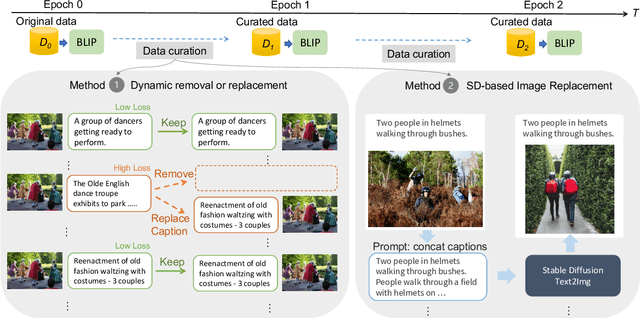
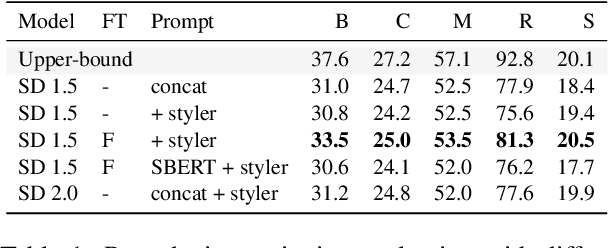
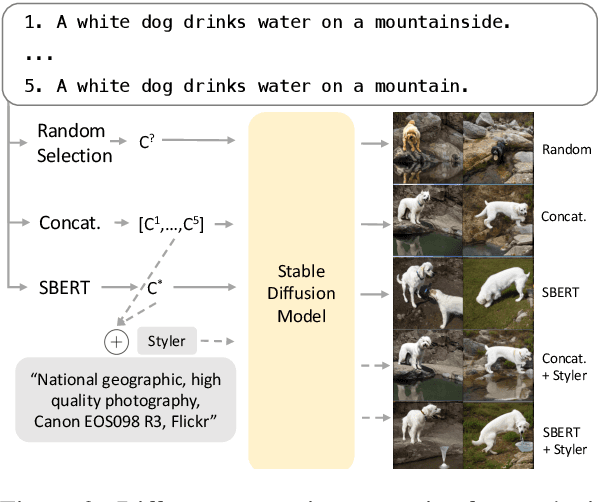
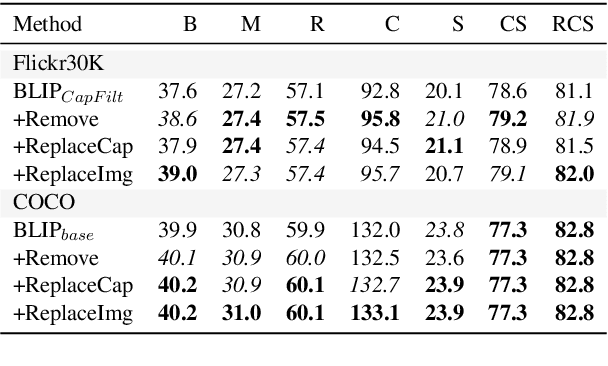
Recent advances in image captioning are mainly driven by large-scale vision-language pretraining, relying heavily on computational resources and increasingly large multimodal datasets. Instead of scaling up pretraining data, we ask whether it is possible to improve performance by improving the quality of the samples in existing datasets. We pursue this question through two approaches to data curation: one that assumes that some examples should be avoided due to mismatches between the image and caption, and one that assumes that the mismatch can be addressed by replacing the image, for which we use the state-of-the-art Stable Diffusion model. These approaches are evaluated using the BLIP model on MS COCO and Flickr30K in both finetuning and few-shot learning settings. Our simple yet effective approaches consistently outperform baselines, indicating that better image captioning models can be trained by curating existing resources. Finally, we conduct a human study to understand the errors made by the Stable Diffusion model and highlight directions for future work in text-to-image generation.
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder
Jun 05, 2023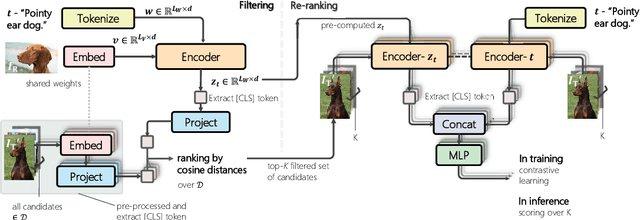
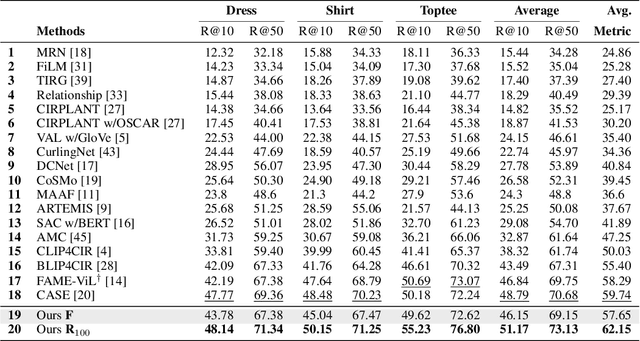
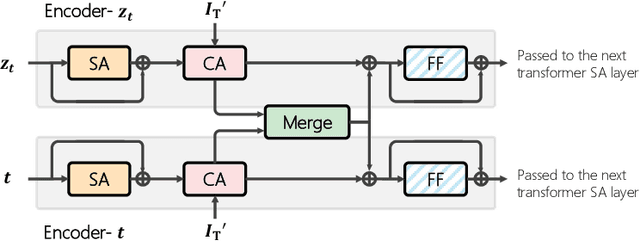
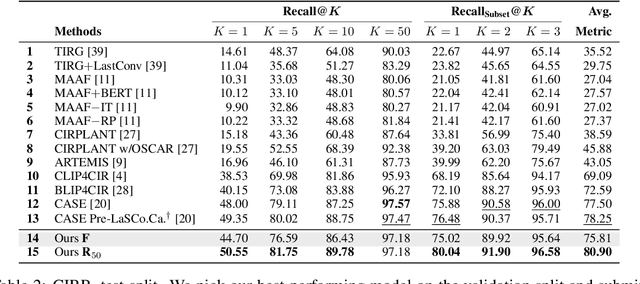
Composed image retrieval aims to find an image that best matches a given multi-modal user query consisting of a reference image and text pair. Existing methods commonly pre-compute image embeddings over the entire corpus and compare these to a reference image embedding modified by the query text at test time. Such a pipeline is very efficient at test time since fast vector distances can be used to evaluate candidates, but modifying the reference image embedding guided only by a short textual description can be difficult, especially independent of potential candidates. An alternative approach is to allow interactions between the query and every possible candidate, i.e., reference-text-candidate triplets, and pick the best from the entire set. Though this approach is more discriminative, for large-scale datasets the computational cost is prohibitive since pre-computation of candidate embeddings is no longer possible. We propose to combine the merits of both schemes using a two-stage model. Our first stage adopts the conventional vector distancing metric and performs a fast pruning among candidates. Meanwhile, our second stage employs a dual-encoder architecture, which effectively attends to the input triplet of reference-text-candidate and re-ranks the candidates. Both stages utilize a vision-and-language pre-trained network, which has proven beneficial for various downstream tasks. Our method consistently outperforms state-of-the-art approaches on standard benchmarks for the task.