 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scale-Preserving Automatic Concept Extraction (SPACE)
Aug 11, 2023
Convolutional Neural Networks (CNN) have become a common choice for industrial quality control, as well as other critical applications in the Industry 4.0. When these CNNs behave in ways unexpected to human users or developers, severe consequences can arise, such as economic losses or an increased risk to human life. Concept extraction techniques can be applied to increase the reliability and transparency of CNNs through generating global explanations for trained neural network models. The decisive features of image datasets in quality control often depend on the feature's scale; for example, the size of a hole or an edge. However, existing concept extraction methods do not correctly represent scale, which leads to problems interpreting these models as we show herein. To address this issue, we introduce the Scale-Preserving Automatic Concept Extraction (SPACE) algorithm, as a state-of-the-art alternative concept extraction technique for CNNs, focused on industrial applications. SPACE is specifically designed to overcome the aforementioned problems by avoiding scale changes throughout the concept extraction process. SPACE proposes an approach based on square slices of input images, which are selected and then tiled before being clustered into concepts. Our method provides explanations of the models' decision-making process in the form of human-understandable concepts. We evaluate SPACE on three image classification datasets in the context of industrial quality control. Through experimental results, we illustrate how SPACE outperforms other methods and provides actionable insights on the decision mechanisms of CNNs. Finally, code for the implementation of SPACE is provided.
Foundation Model is Efficient Multimodal Multitask Model Selector
Aug 11, 2023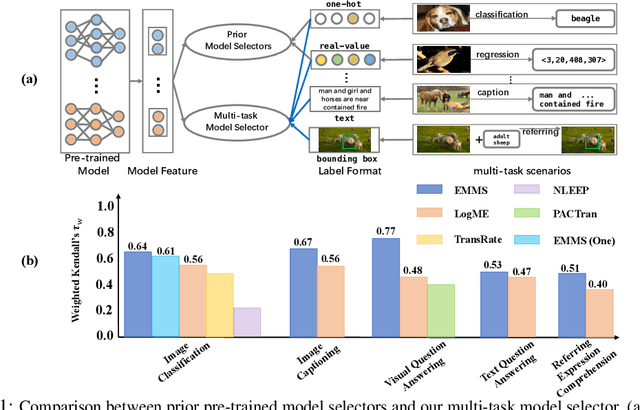
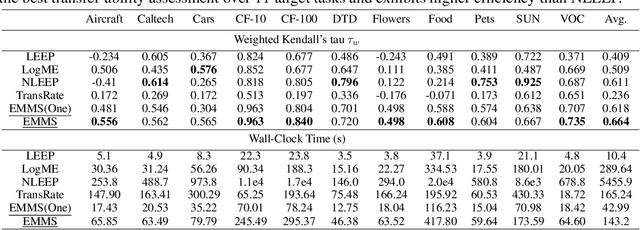
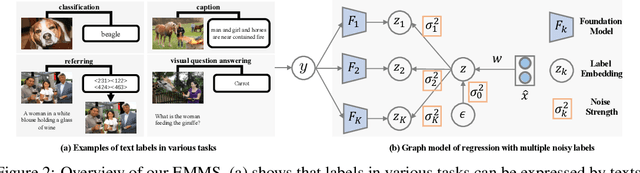
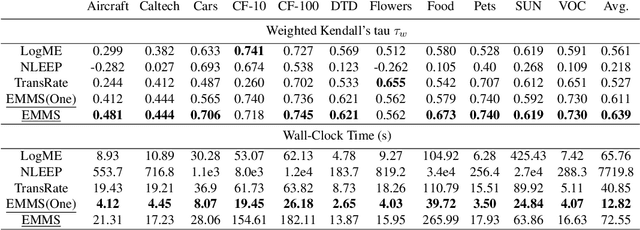
This paper investigates an under-explored but important problem: given a collection of pre-trained neural networks, predicting their performance on each multi-modal task without fine-tuning them, such as image recognition, referring, captioning, visual question answering, and text question answering. A brute-force approach is to finetune all models on all target datasets, bringing high computational costs. Although recent-advanced approaches employed lightweight metrics to measure models' transferability,they often depend heavily on the prior knowledge of a single task, making them inapplicable in a multi-modal multi-task scenario. To tackle this issue, we propose an efficient multi-task model selector (EMMS), which employs large-scale foundation models to transform diverse label formats such as categories, texts, and bounding boxes of different downstream tasks into a unified noisy label embedding. EMMS can estimate a model's transferability through a simple weighted linear regression, which can be efficiently solved by an alternating minimization algorithm with a convergence guarantee. Extensive experiments on 5 downstream tasks with 24 datasets show that EMMS is fast, effective, and generic enough to assess the transferability of pre-trained models, making it the first model selection method in the multi-task scenario. For instance, compared with the state-of-the-art method LogME enhanced by our label embeddings, EMMS achieves 9.0\%, 26.3\%, 20.1\%, 54.8\%, 12.2\% performance gain on image recognition, referring, captioning, visual question answering, and text question answering, while bringing 5.13x, 6.29x, 3.59x, 6.19x, and 5.66x speedup in wall-clock time, respectively. The code is available at https://github.com/OpenGVLab/Multitask-Model-Selector.
DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
Aug 11, 2023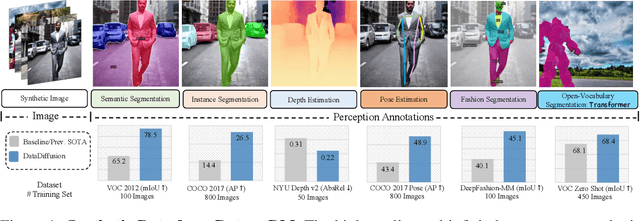

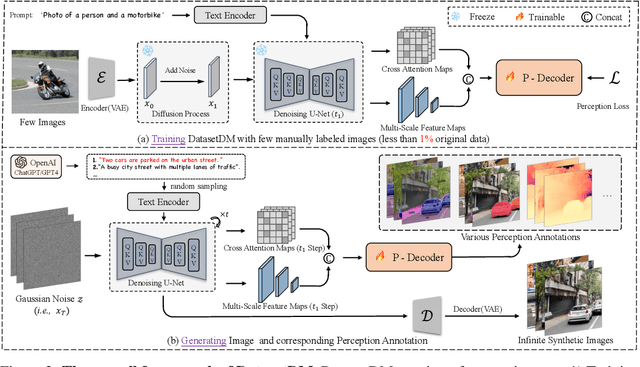
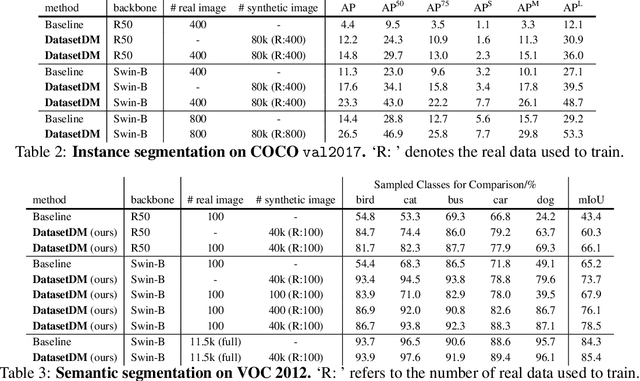
Current deep networks are very data-hungry and benefit from training on largescale datasets, which are often time-consuming to collect and annotate. By contrast, synthetic data can be generated infinitely using generative models such as DALL-E and diffusion models, with minimal effort and cost. In this paper, we present DatasetDM, a generic dataset generation model that can produce diverse synthetic images and the corresponding high-quality perception annotations (e.g., segmentation masks, and depth). Our method builds upon the pre-trained diffusion model and extends text-guided image synthesis to perception data generation. We show that the rich latent code of the diffusion model can be effectively decoded as accurate perception annotations using a decoder module. Training the decoder only needs less than 1% (around 100 images) manually labeled images, enabling the generation of an infinitely large annotated dataset. Then these synthetic data can be used for training various perception models for downstream tasks. To showcase the power of the proposed approach, we generate datasets with rich dense pixel-wise labels for a wide range of downstream tasks, including semantic segmentation, instance segmentation, and depth estimation. Notably, it achieves 1) state-of-the-art results on semantic segmentation and instance segmentation; 2) significantly more robust on domain generalization than using the real data alone; and state-of-the-art results in zero-shot segmentation setting; and 3) flexibility for efficient application and novel task composition (e.g., image editing). The project website and code can be found at https://weijiawu.github.io/DatasetDM_page/ and https://github.com/showlab/DatasetDM, respectively
The Scientometrics and Reciprocality Underlying Co-Authorship Panels in Google Scholar Profiles
Aug 14, 2023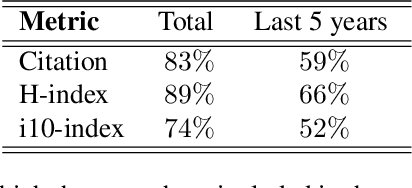
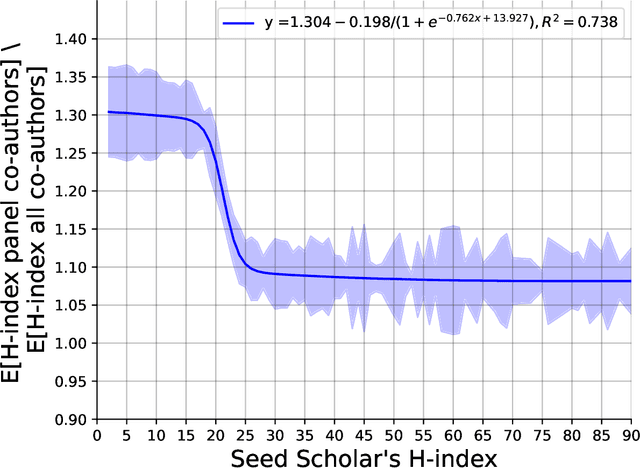

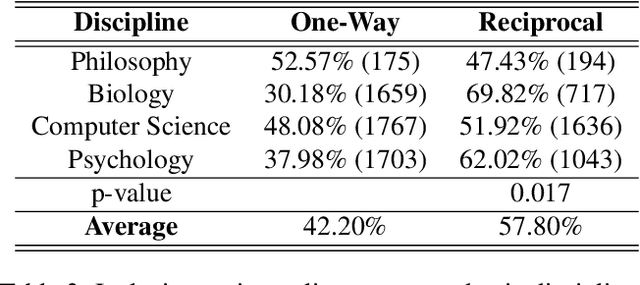
Online academic profiles are used by scholars to reflect a desired image to their online audience. In Google Scholar, scholars can select a subset of co-authors for presentation in a central location on their profile using a social feature called the Co-authroship panel. In this work, we examine whether scientometrics and reciprocality can explain the observed selections. To this end, we scrape and thoroughly analyze a novel set of 120,000 Google Scholar profiles, ranging across four disciplines and various academic institutions. Our results suggest that scholars tend to favor co-authors with higher scientometrics over others for inclusion in their co-authorship panels. Interestingly, as one's own scientometrics are higher, the tendency to include co-authors with high scientometrics is diminishing. Furthermore, we find that reciprocality is central to explaining scholars' selections.
Trustworthy Deep Learning for Medical Image Segmentation
May 27, 2023Despite the recent success of deep learning methods at achieving new state-of-the-art accuracy for medical image segmentation, some major limitations are still restricting their deployment into clinics. One major limitation of deep learning-based segmentation methods is their lack of robustness to variability in the image acquisition protocol and in the imaged anatomy that were not represented or were underrepresented in the training dataset. This suggests adding new manually segmented images to the training dataset to better cover the image variability. However, in most cases, the manual segmentation of medical images requires highly skilled raters and is time-consuming, making this solution prohibitively expensive. Even when manually segmented images from different sources are available, they are rarely annotated for exactly the same regions of interest. This poses an additional challenge for current state-of-the-art deep learning segmentation methods that rely on supervised learning and therefore require all the regions of interest to be segmented for all the images to be used for training. This thesis introduces new mathematical and optimization methods to mitigate those limitations.
Augmenting CLIP with Improved Visio-Linguistic Reasoning
Jul 27, 2023
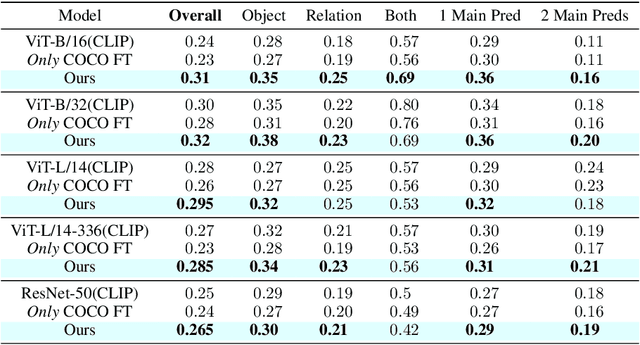
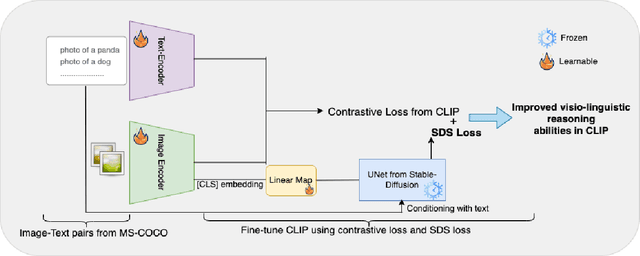
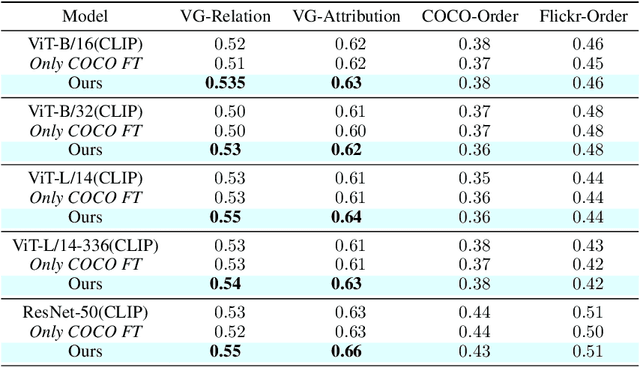
Image-text contrastive models such as CLIP are useful for a variety of downstream applications including zero-shot classification, image-text retrieval and transfer learning. However, these contrastively trained vision-language models often fail on compositional visio-linguistic tasks such as Winoground with performance equivalent to random chance. In our paper, we address this issue and propose a sample-efficient light-weight method called SDS-CLIP to improve the compositional visio-linguistic reasoning capabilities of CLIP. The core idea of our method is to use differentiable image parameterizations to fine-tune CLIP with a distillation objective from large text-to-image generative models such as Stable-Diffusion which are relatively good at visio-linguistic reasoning tasks. On the challenging Winoground compositional reasoning benchmark, our method improves the absolute visio-linguistic performance of different CLIP models by up to 7%, while on the ARO dataset, our method improves the visio-linguistic performance by upto 3%. As a byproduct of inducing visio-linguistic reasoning into CLIP, we also find that the zero-shot performance improves marginally on a variety of downstream datasets. Our method reinforces that carefully designed distillation objectives from generative models can be leveraged to extend existing contrastive image-text models with improved visio-linguistic reasoning capabilities.
Boundary-RL: Reinforcement Learning for Weakly-Supervised Prostate Segmentation in TRUS Images
Aug 22, 2023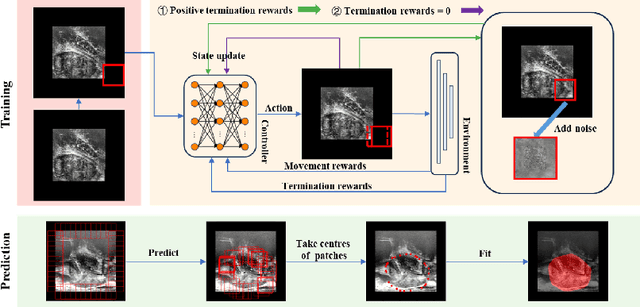
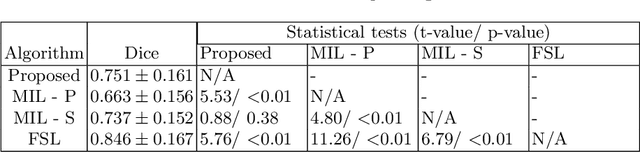
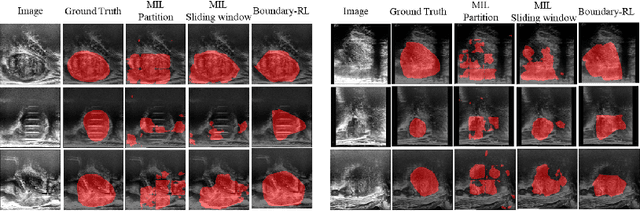
We propose Boundary-RL, a novel weakly supervised segmentation method that utilises only patch-level labels for training. We envision the segmentation as a boundary detection problem, rather than a pixel-level classification as in previous works. This outlook on segmentation may allow for boundary delineation under challenging scenarios such as where noise artefacts may be present within the region-of-interest (ROI) boundaries, where traditional pixel-level classification-based weakly supervised methods may not be able to effectively segment the ROI. Particularly of interest, ultrasound images, where intensity values represent acoustic impedance differences between boundaries, may also benefit from the boundary delineation approach. Our method uses reinforcement learning to train a controller function to localise boundaries of ROIs using a reward derived from a pre-trained boundary-presence classifier. The classifier indicates when an object boundary is encountered within a patch, as the controller modifies the patch location in a sequential Markov decision process. The classifier itself is trained using only binary patch-level labels of object presence, which are the only labels used during training of the entire boundary delineation framework, and serves as a weak signal to inform the boundary delineation. The use of a controller function ensures that a sliding window over the entire image is not necessary. It also prevents possible false-positive or -negative cases by minimising number of patches passed to the boundary-presence classifier. We evaluate our proposed approach for a clinically relevant task of prostate gland segmentation on trans-rectal ultrasound images. We show improved performance compared to other tested weakly supervised methods, using the same labels e.g., multiple instance learning.
InvVis: Large-Scale Data Embedding for Invertible Visualization
Aug 04, 2023
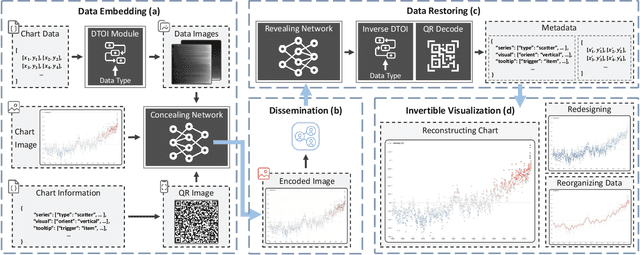
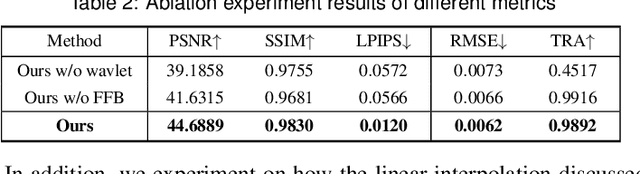
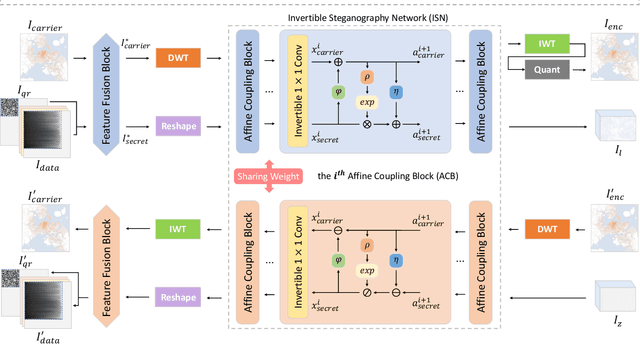
We present InvVis, a new approach for invertible visualization, which is reconstructing or further modifying a visualization from an image. InvVis allows the embedding of a significant amount of data, such as chart data, chart information, source code, etc., into visualization images. The encoded image is perceptually indistinguishable from the original one. We propose a new method to efficiently express chart data in the form of images, enabling large-capacity data embedding. We also outline a model based on the invertible neural network to achieve high-quality data concealing and revealing. We explore and implement a variety of application scenarios of InvVis. Additionally, we conduct a series of evaluation experiments to assess our method from multiple perspectives, including data embedding quality, data restoration accuracy, data encoding capacity, etc. The result of our experiments demonstrates the great potential of InvVis in invertible visualization.
KS-APR: Keyframe Selection for Robust Absolute Pose Regression
Aug 10, 2023Markerless Mobile Augmented Reality (AR) aims to anchor digital content in the physical world without using specific 2D or 3D objects. Absolute Pose Regressors (APR) are end-to-end machine learning solutions that infer the device's pose from a single monocular image. Thanks to their low computation cost, they can be directly executed on the constrained hardware of mobile AR devices. However, APR methods tend to yield significant inaccuracies for input images that are too distant from the training set. This paper introduces KS-APR, a pipeline that assesses the reliability of an estimated pose with minimal overhead by combining the inference results of the APR and the prior images in the training set. Mobile AR systems tend to rely upon visual-inertial odometry to track the relative pose of the device during the experience. As such, KS-APR favours reliability over frequency, discarding unreliable poses. This pipeline can integrate most existing APR methods to improve accuracy by filtering unreliable images with their pose estimates. We implement the pipeline on three types of APR models on indoor and outdoor datasets. The median error on position and orientation is reduced for all models, and the proportion of large errors is minimized across datasets. Our method enables state-of-the-art APRs such as DFNetdm to outperform single-image and sequential APR methods. These results demonstrate the scalability and effectiveness of KS-APR for visual localization tasks that do not require one-shot decisions.
Global in Local: A Convolutional Transformer for SAR ATR FSL
Aug 10, 2023Convolutional neural networks (CNNs) have dominated the synthetic aperture radar (SAR) automatic target recognition (ATR) for years. However, under the limited SAR images, the width and depth of the CNN-based models are limited, and the widening of the received field for global features in images is hindered, which finally leads to the low performance of recognition. To address these challenges, we propose a Convolutional Transformer (ConvT) for SAR ATR few-shot learning (FSL). The proposed method focuses on constructing a hierarchical feature representation and capturing global dependencies of local features in each layer, named global in local. A novel hybrid loss is proposed to interpret the few SAR images in the forms of recognition labels and contrastive image pairs, construct abundant anchor-positive and anchor-negative image pairs in one batch and provide sufficient loss for the optimization of the ConvT to overcome the few sample effect. An auto augmentation is proposed to enhance and enrich the diversity and amount of the few training samples to explore the hidden feature in a few SAR images and avoid the over-fitting in SAR ATR FSL. Experiments conducted on the Moving and Stationary Target Acquisition and Recognition dataset (MSTAR) have shown the effectiveness of our proposed ConvT for SAR ATR FSL. Different from existing SAR ATR FSL methods employing additional training datasets, our method achieved pioneering performance without other SAR target images in training.