 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Rectifying Diffusion Sampling with Perturbed-Attention Guidance
Mar 26, 2024
Recent studies have demonstrated that diffusion models are capable of generating high-quality samples, but their quality heavily depends on sampling guidance techniques, such as classifier guidance (CG) and classifier-free guidance (CFG). These techniques are often not applicable in unconditional generation or in various downstream tasks such as image restoration. In this paper, we propose a novel sampling guidance, called Perturbed-Attention Guidance (PAG), which improves diffusion sample quality across both unconditional and conditional settings, achieving this without requiring additional training or the integration of external modules. PAG is designed to progressively enhance the structure of samples throughout the denoising process. It involves generating intermediate samples with degraded structure by substituting selected self-attention maps in diffusion U-Net with an identity matrix, by considering the self-attention mechanisms' ability to capture structural information, and guiding the denoising process away from these degraded samples. In both ADM and Stable Diffusion, PAG surprisingly improves sample quality in conditional and even unconditional scenarios. Moreover, PAG significantly improves the baseline performance in various downstream tasks where existing guidances such as CG or CFG cannot be fully utilized, including ControlNet with empty prompts and image restoration such as inpainting and deblurring.
EAGLE: An Edge-Aware Gradient Localization Enhanced Loss for CT Image Reconstruction
Mar 15, 2024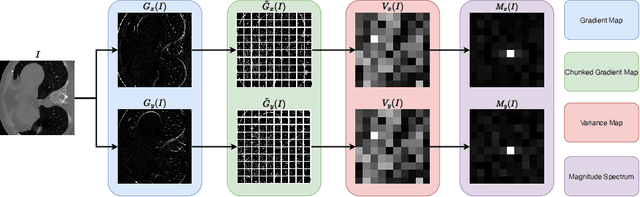
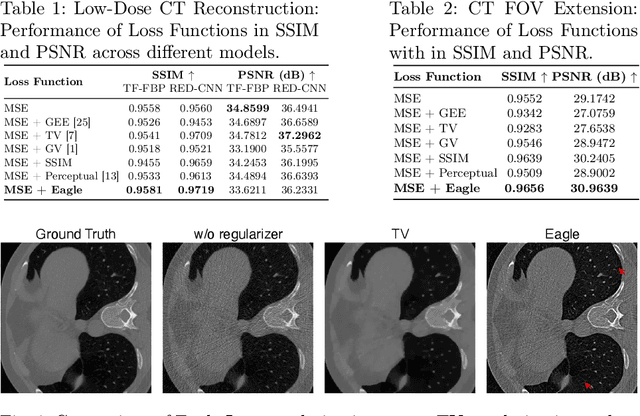

Computed Tomography (CT) image reconstruction is crucial for accurate diagnosis and deep learning approaches have demonstrated significant potential in improving reconstruction quality. However, the choice of loss function profoundly affects the reconstructed images. Traditional mean squared error loss often produces blurry images lacking fine details, while alternatives designed to improve may introduce structural artifacts or other undesirable effects. To address these limitations, we propose Eagle-Loss, a novel loss function designed to enhance the visual quality of CT image reconstructions. Eagle-Loss applies spectral analysis of localized features within gradient changes to enhance sharpness and well-defined edges. We evaluated Eagle-Loss on two public datasets across low-dose CT reconstruction and CT field-of-view extension tasks. Our results show that Eagle-Loss consistently improves the visual quality of reconstructed images, surpassing state-of-the-art methods across various network architectures. Code and data are available at \url{https://github.com/sypsyp97/Eagle_Loss}.
Frozen Feature Augmentation for Few-Shot Image Classification
Mar 15, 2024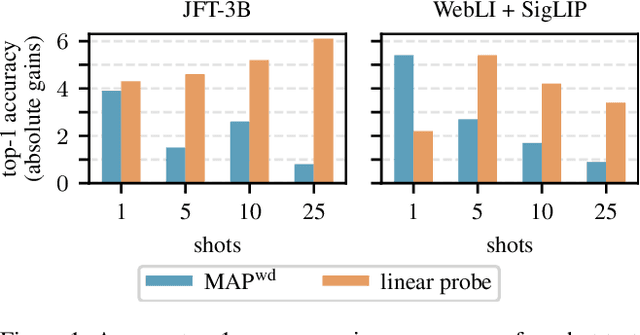
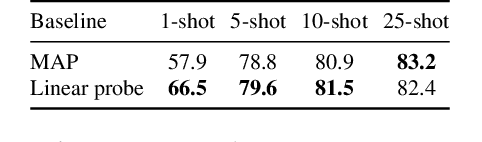
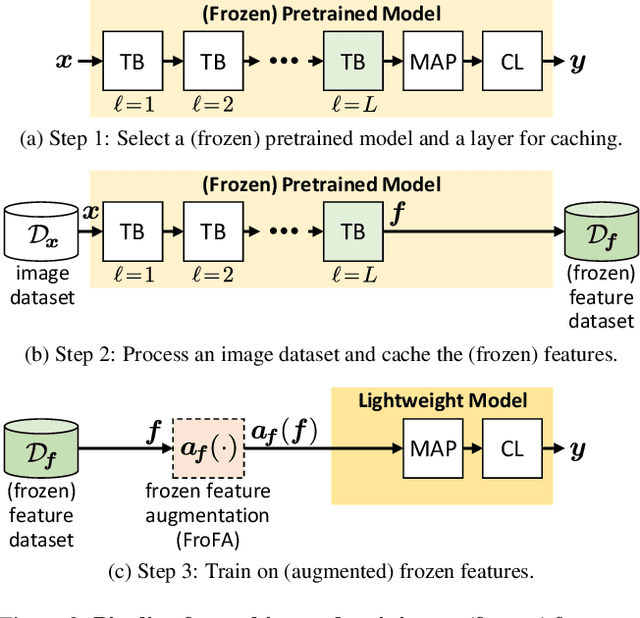
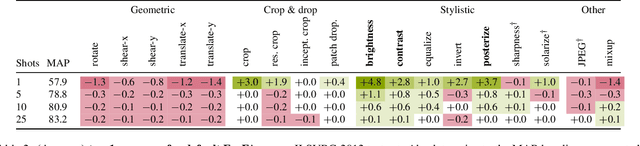
Training a linear classifier or lightweight model on top of pretrained vision model outputs, so-called 'frozen features', leads to impressive performance on a number of downstream few-shot tasks. Currently, frozen features are not modified during training. On the other hand, when networks are trained directly on images, data augmentation is a standard recipe that improves performance with no substantial overhead. In this paper, we conduct an extensive pilot study on few-shot image classification that explores applying data augmentations in the frozen feature space, dubbed 'frozen feature augmentation (FroFA)', covering twenty augmentations in total. Our study demonstrates that adopting a deceptively simple pointwise FroFA, such as brightness, can improve few-shot performance consistently across three network architectures, three large pretraining datasets, and eight transfer datasets.
HAIFIT: Human-Centered AI for Fashion Image Translation
Mar 13, 2024
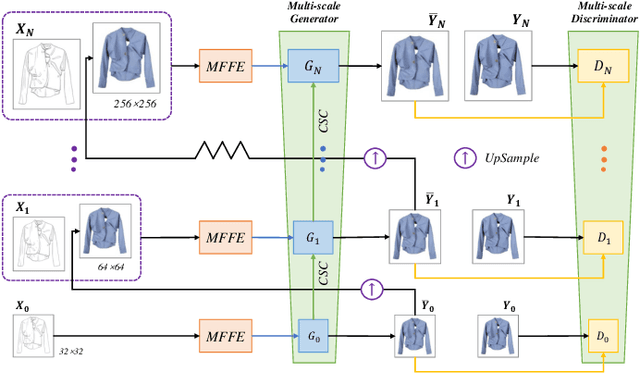
In the realm of fashion design, sketches serve as the canvas for expressing an artist's distinctive drawing style and creative vision, capturing intricate details like stroke variations and texture nuances. The advent of sketch-to-image cross-modal translation technology has notably aided designers. However, existing methods often compromise these sketch details during image generation, resulting in images that deviate from the designer's intended concept. This limitation hampers the ability to offer designers a precise preview of the final output. To overcome this challenge, we introduce HAIFIT, a novel approach that transforms sketches into high-fidelity, lifelike clothing images by integrating multi-scale features and capturing extensive feature map dependencies from diverse perspectives. Through extensive qualitative and quantitative evaluations conducted on our self-collected dataset, our method demonstrates superior performance compared to existing methods in generating photorealistic clothing images. Our method excels in preserving the distinctive style and intricate details essential for fashion design applications.
InstructGIE: Towards Generalizable Image Editing
Mar 08, 2024
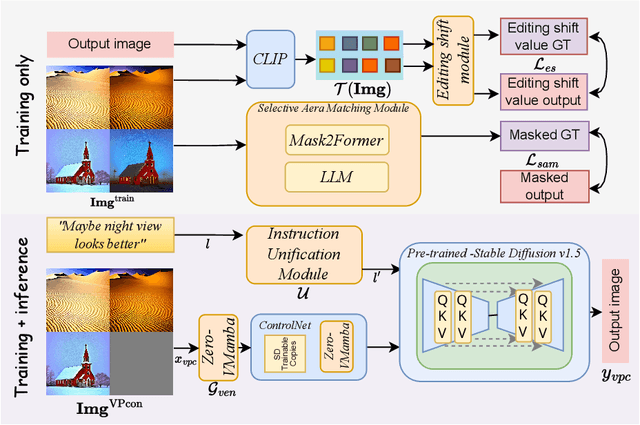


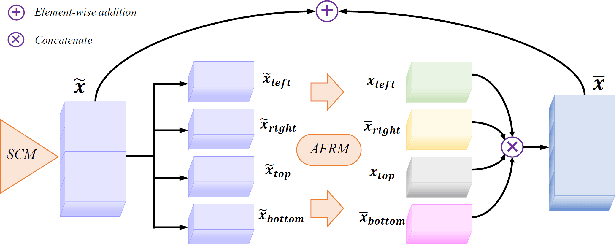
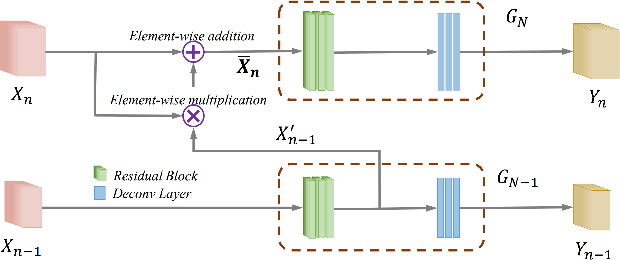
Recent advances in image editing have been driven by the development of denoising diffusion models, marking a significant leap forward in this field. Despite these advances, the generalization capabilities of recent image editing approaches remain constrained. In response to this challenge, our study introduces a novel image editing framework with enhanced generalization robustness by boosting in-context learning capability and unifying language instruction. This framework incorporates a module specifically optimized for image editing tasks, leveraging the VMamba Block and an editing-shift matching strategy to augment in-context learning. Furthermore, we unveil a selective area-matching technique specifically engineered to address and rectify corrupted details in generated images, such as human facial features, to further improve the quality. Another key innovation of our approach is the integration of a language unification technique, which aligns language embeddings with editing semantics to elevate the quality of image editing. Moreover, we compile the first dataset for image editing with visual prompts and editing instructions that could be used to enhance in-context capability. Trained on this dataset, our methodology not only achieves superior synthesis quality for trained tasks, but also demonstrates robust generalization capability across unseen vision tasks through tailored prompts.
Benchmarking Adversarial Robustness of Image Shadow Removal with Shadow-adaptive Attacks
Mar 15, 2024
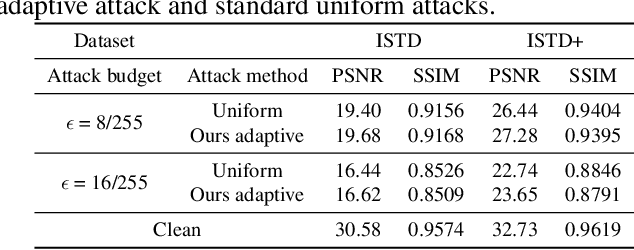
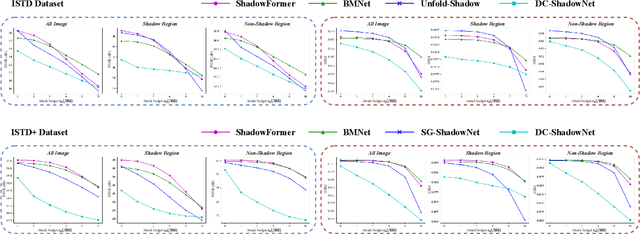

Shadow removal is a task aimed at erasing regional shadows present in images and reinstating visually pleasing natural scenes with consistent illumination. While recent deep learning techniques have demonstrated impressive performance in image shadow removal, their robustness against adversarial attacks remains largely unexplored. Furthermore, many existing attack frameworks typically allocate a uniform budget for perturbations across the entire input image, which may not be suitable for attacking shadow images. This is primarily due to the unique characteristic of spatially varying illumination within shadow images. In this paper, we propose a novel approach, called shadow-adaptive adversarial attack. Different from standard adversarial attacks, our attack budget is adjusted based on the pixel intensity in different regions of shadow images. Consequently, the optimized adversarial noise in the shadowed regions becomes visually less perceptible while permitting a greater tolerance for perturbations in non-shadow regions. The proposed shadow-adaptive attacks naturally align with the varying illumination distribution in shadow images, resulting in perturbations that are less conspicuous. Building on this, we conduct a comprehensive empirical evaluation of existing shadow removal methods, subjecting them to various levels of attack on publicly available datasets.
Multi-Scale Texture Loss for CT denoising with GANs
Mar 25, 2024Generative Adversarial Networks (GANs) have proved as a powerful framework for denoising applications in medical imaging. However, GAN-based denoising algorithms still suffer from limitations in capturing complex relationships within the images. In this regard, the loss function plays a crucial role in guiding the image generation process, encompassing how much a synthetic image differs from a real image. To grasp highly complex and non-linear textural relationships in the training process, this work presents a loss function that leverages the intrinsic multi-scale nature of the Gray-Level-Co-occurrence Matrix (GLCM). Although the recent advances in deep learning have demonstrated superior performance in classification and detection tasks, we hypothesize that its information content can be valuable when integrated into GANs' training. To this end, we propose a differentiable implementation of the GLCM suited for gradient-based optimization. Our approach also introduces a self-attention layer that dynamically aggregates the multi-scale texture information extracted from the images. We validate our approach by carrying out extensive experiments in the context of low-dose CT denoising, a challenging application that aims to enhance the quality of noisy CT scans. We utilize three publicly available datasets, including one simulated and two real datasets. The results are promising as compared to other well-established loss functions, being also consistent across three different GAN architectures. The code is available at: https://github.com/FrancescoDiFeola/DenoTextureLoss
Continuous, Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
Mar 25, 2024In recent years, advances in text-to-image (T2I) diffusion models have substantially elevated the quality of their generated images. However, achieving fine-grained control over attributes remains a challenge due to the limitations of natural language prompts (such as no continuous set of intermediate descriptions existing between ``person'' and ``old person''). Even though many methods were introduced that augment the model or generation process to enable such control, methods that do not require a fixed reference image are limited to either enabling global fine-grained attribute expression control or coarse attribute expression control localized to specific subjects, not both simultaneously. We show that there exist directions in the commonly used token-level CLIP text embeddings that enable fine-grained subject-specific control of high-level attributes in text-to-image models. Based on this observation, we introduce one efficient optimization-free and one robust optimization-based method to identify these directions for specific attributes from contrastive text prompts. We demonstrate that these directions can be used to augment the prompt text input with fine-grained control over attributes of specific subjects in a compositional manner (control over multiple attributes of a single subject) without having to adapt the diffusion model. Project page: https://compvis.github.io/attribute-control. Code is available at https://github.com/CompVis/attribute-control.
SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
Mar 25, 2024Diffusion Transformer (DiT) has emerged as the new trend of generative diffusion models on image generation. In view of extremely slow convergence in typical DiT, recent breakthroughs have been driven by mask strategy that significantly improves the training efficiency of DiT with additional intra-image contextual learning. Despite this progress, mask strategy still suffers from two inherent limitations: (a) training-inference discrepancy and (b) fuzzy relations between mask reconstruction & generative diffusion process, resulting in sub-optimal training of DiT. In this work, we address these limitations by novelly unleashing the self-supervised discrimination knowledge to boost DiT training. Technically, we frame our DiT in a teacher-student manner. The teacher-student discriminative pairs are built on the diffusion noises along the same Probability Flow Ordinary Differential Equation (PF-ODE). Instead of applying mask reconstruction loss over both DiT encoder and decoder, we decouple DiT encoder and decoder to separately tackle discriminative and generative objectives. In particular, by encoding discriminative pairs with student and teacher DiT encoders, a new discriminative loss is designed to encourage the inter-image alignment in the self-supervised embedding space. After that, student samples are fed into student DiT decoder to perform the typical generative diffusion task. Extensive experiments are conducted on ImageNet dataset, and our method achieves a competitive balance between training cost and generative capacity.
Video Editing via Factorized Diffusion Distillation
Mar 24, 2024
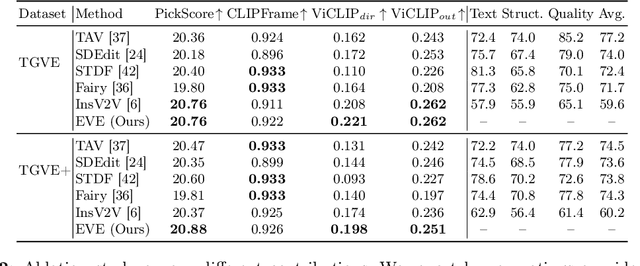
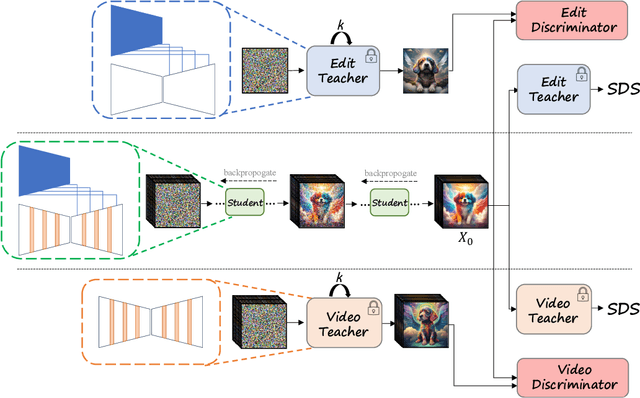
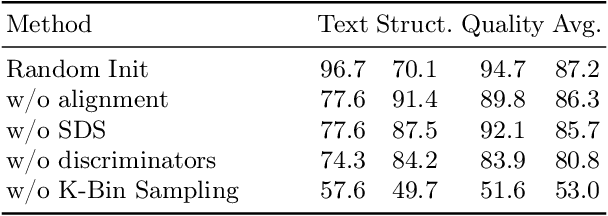
We introduce Emu Video Edit (EVE), a model that establishes a new state-of-the art in video editing without relying on any supervised video editing data. To develop EVE we separately train an image editing adapter and a video generation adapter, and attach both to the same text-to-image model. Then, to align the adapters towards video editing we introduce a new unsupervised distillation procedure, Factorized Diffusion Distillation. This procedure distills knowledge from one or more teachers simultaneously, without any supervised data. We utilize this procedure to teach EVE to edit videos by jointly distilling knowledge to (i) precisely edit each individual frame from the image editing adapter, and (ii) ensure temporal consistency among the edited frames using the video generation adapter. Finally, to demonstrate the potential of our approach in unlocking other capabilities, we align additional combinations of adapters