 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Grounded Visual Spatial Reasoning in Multi-Modal Vision Language Models
Aug 18, 2023

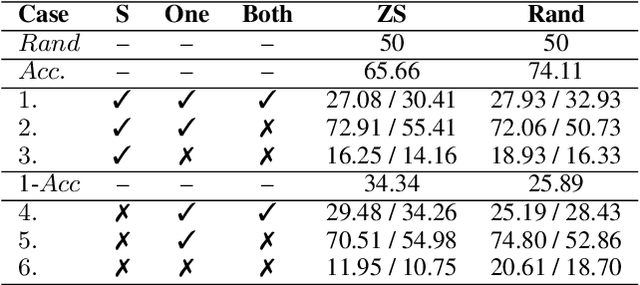

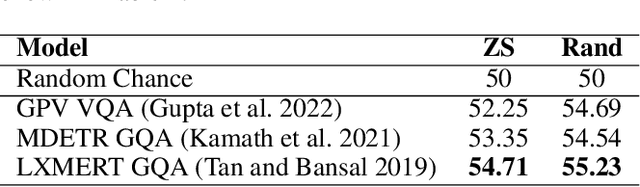
With the advances in large scale vision-and-language models (VLMs) it is of interest to assess their performance on various visual reasoning tasks such as counting, referring expressions and general visual question answering. The focus of this work is to study the ability of these models to understanding spatial relations. Previously, this has been tackled using image-text matching (Liu, Emerson, and Collier 2022) or visual question answering task, both showing poor performance and a large gap compared to human performance. To better understand the gap, we present fine-grained compositional grounding of spatial relationships and propose a bottom up approach for ranking spatial clauses and evaluating the performance of spatial relationship reasoning task. We propose to combine the evidence from grounding noun phrases corresponding to objects and their locations to compute the final rank of the spatial clause. We demonstrate the approach on representative vision-language models (Tan and Bansal 2019; Gupta et al. 2022; Kamath et al. 2021) and compare and highlight their abilities to reason about spatial relationships.
Automated mapping of virtual environments with visual predictive coding
Aug 20, 2023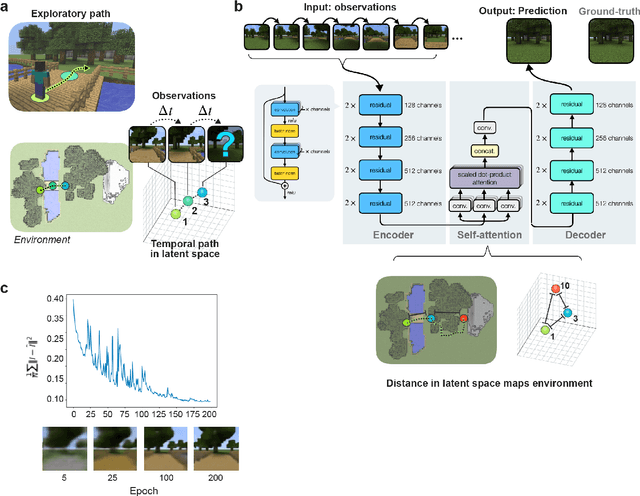
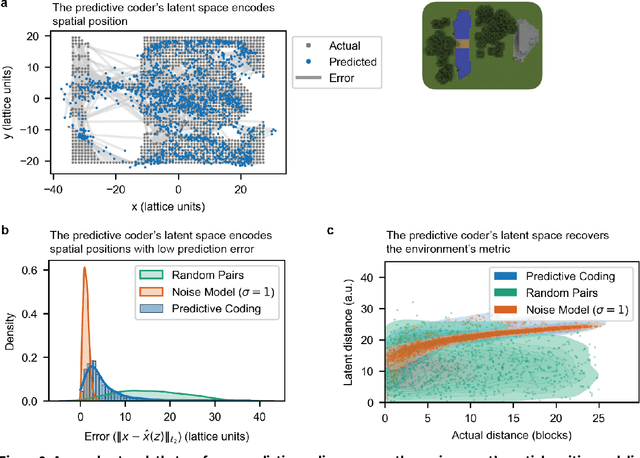
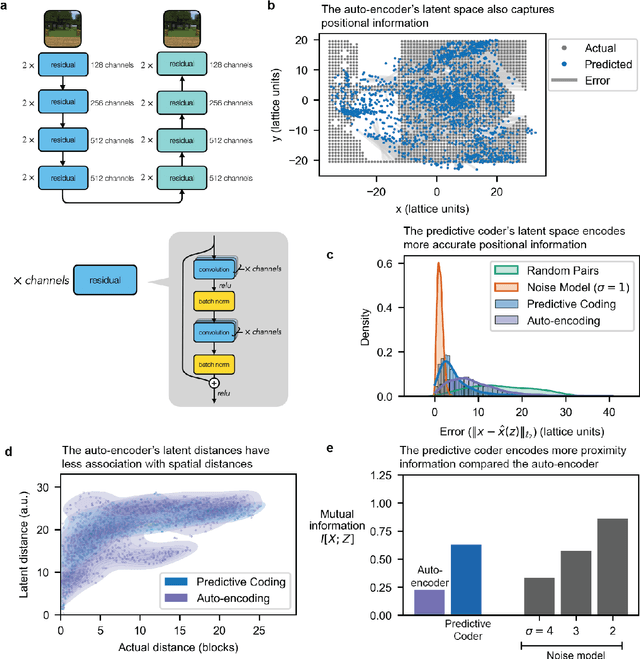
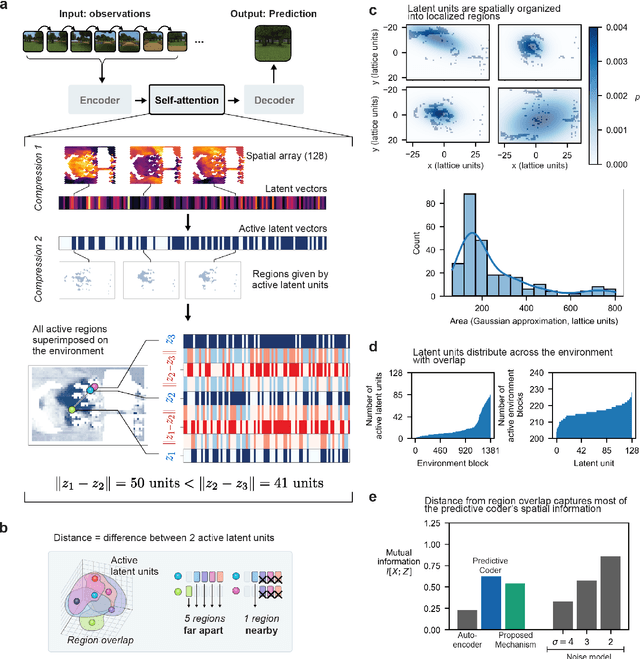
Humans construct internal cognitive maps of their environment directly from sensory inputs without access to a system of explicit coordinates or distance measurements. While machine learning algorithms like SLAM utilize specialized visual inference procedures to identify visual features and construct spatial maps from visual and odometry data, the general nature of cognitive maps in the brain suggests a unified mapping algorithmic strategy that can generalize to auditory, tactile, and linguistic inputs. Here, we demonstrate that predictive coding provides a natural and versatile neural network algorithm for constructing spatial maps using sensory data. We introduce a framework in which an agent navigates a virtual environment while engaging in visual predictive coding using a self-attention-equipped convolutional neural network. While learning a next image prediction task, the agent automatically constructs an internal representation of the environment that quantitatively reflects distances. The internal map enables the agent to pinpoint its location relative to landmarks using only visual information.The predictive coding network generates a vectorized encoding of the environment that supports vector navigation where individual latent space units delineate localized, overlapping neighborhoods in the environment. Broadly, our work introduces predictive coding as a unified algorithmic framework for constructing cognitive maps that can naturally extend to the mapping of auditory, sensorimotor, and linguistic inputs.
Improving Generalization of Synthetically Trained Sonar Image Descriptors for Underwater Place Recognition
Aug 02, 2023

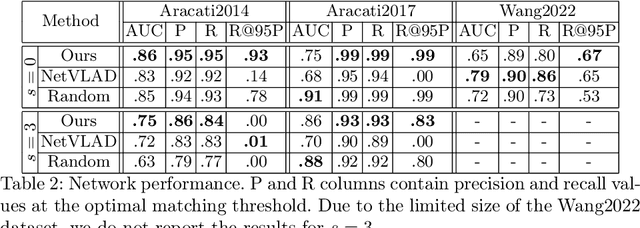
Autonomous navigation in underwater environments presents challenges due to factors such as light absorption and water turbidity, limiting the effectiveness of optical sensors. Sonar systems are commonly used for perception in underwater operations as they are unaffected by these limitations. Traditional computer vision algorithms are less effective when applied to sonar-generated acoustic images, while convolutional neural networks (CNNs) typically require large amounts of labeled training data that are often unavailable or difficult to acquire. To this end, we propose a novel compact deep sonar descriptor pipeline that can generalize to real scenarios while being trained exclusively on synthetic data. Our architecture is based on a ResNet18 back-end and a properly parameterized random Gaussian projection layer, whereas input sonar data is enhanced with standard ad-hoc normalization/prefiltering techniques. A customized synthetic data generation procedure is also presented. The proposed method has been evaluated extensively using both synthetic and publicly available real data, demonstrating its effectiveness compared to state-of-the-art methods.
SAMScore: A Semantic Structural Similarity Metric for Image Translation Evaluation
May 24, 2023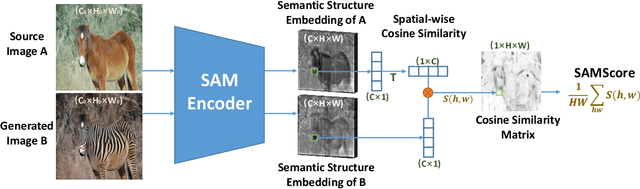
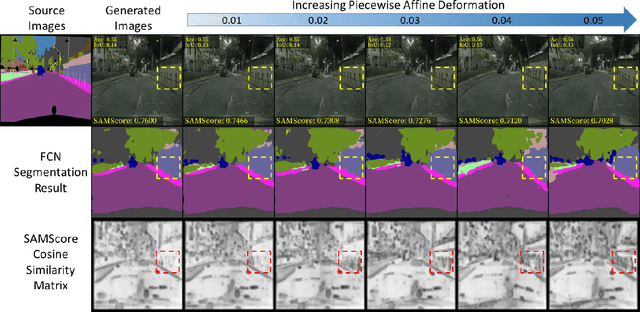

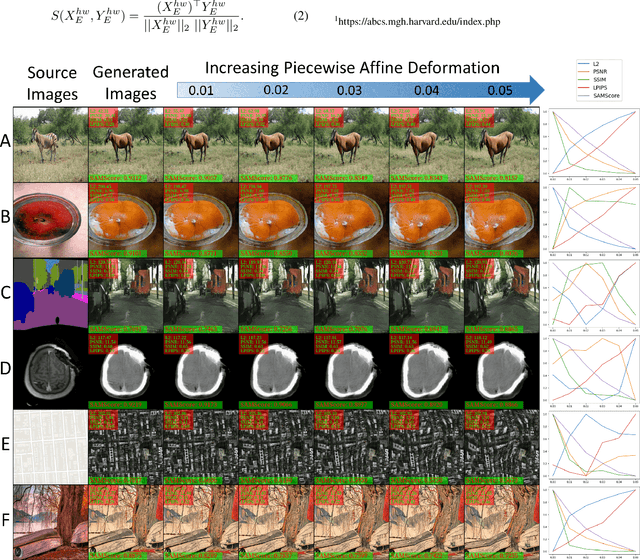
Image translation has wide applications, such as style transfer and modality conversion, usually aiming to generate images having both high degrees of realism and faithfulness. These problems remain difficult, especially when it is important to preserve semantic structures. Traditional image-level similarity metrics are of limited use, since the semantics of an image are high-level, and not strongly governed by pixel-wise faithfulness to an original image. Towards filling this gap, we introduce SAMScore, a generic semantic structural similarity metric for evaluating the faithfulness of image translation models. SAMScore is based on the recent high-performance Segment Anything Model (SAM), which can perform semantic similarity comparisons with standout accuracy. We applied SAMScore on 19 image translation tasks, and found that it is able to outperform all other competitive metrics on all of the tasks. We envision that SAMScore will prove to be a valuable tool that will help to drive the vibrant field of image translation, by allowing for more precise evaluations of new and evolving translation models. The code is available at https://github.com/Kent0n-Li/SAMScore.
On the Interplay of Convolutional Padding and Adversarial Robustness
Aug 12, 2023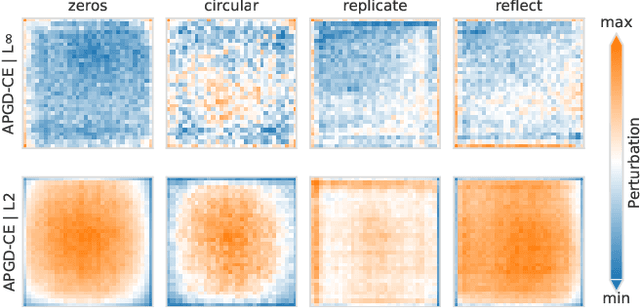
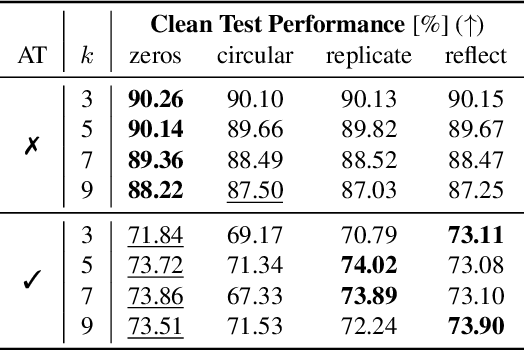

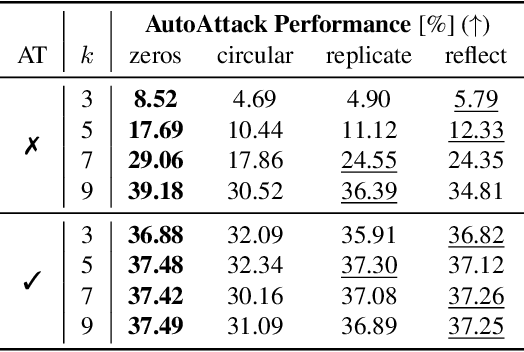
It is common practice to apply padding prior to convolution operations to preserve the resolution of feature-maps in Convolutional Neural Networks (CNN). While many alternatives exist, this is often achieved by adding a border of zeros around the inputs. In this work, we show that adversarial attacks often result in perturbation anomalies at the image boundaries, which are the areas where padding is used. Consequently, we aim to provide an analysis of the interplay between padding and adversarial attacks and seek an answer to the question of how different padding modes (or their absence) affect adversarial robustness in various scenarios.
An Empirical Study of CLIP for Text-based Person Search
Aug 19, 2023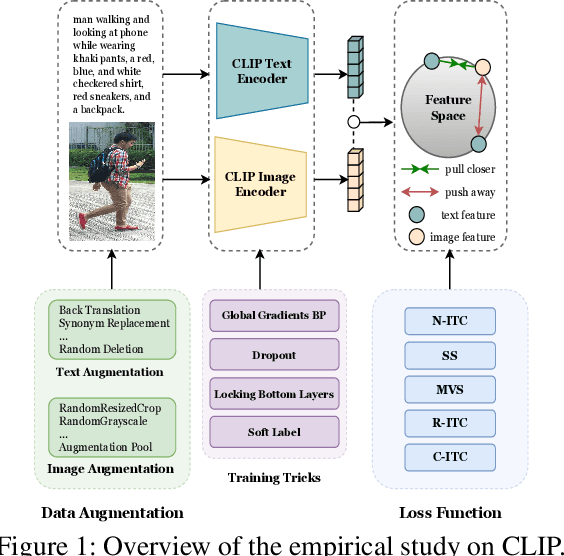
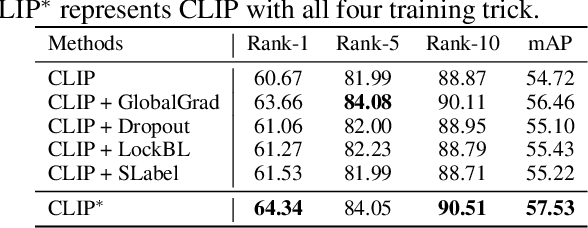
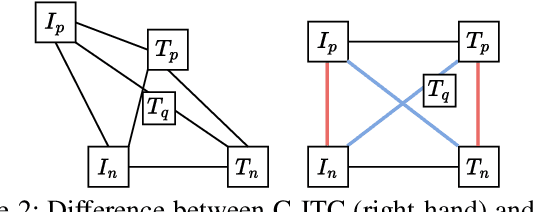
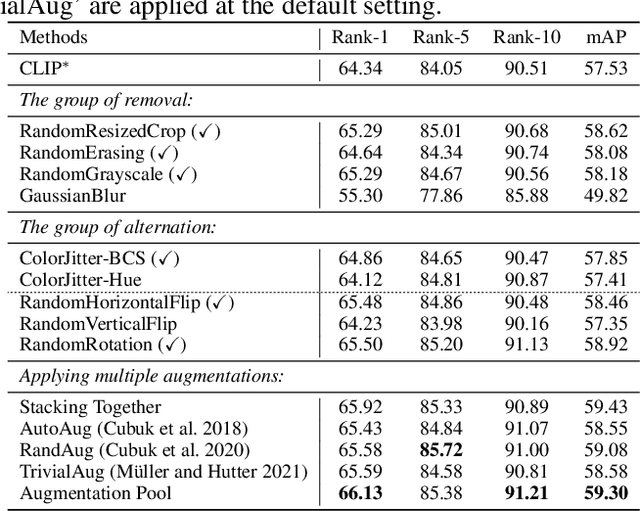
Text-based Person Search (TBPS) aims to retrieve the person images using natural language descriptions. Recently, Contrastive Language Image Pretraining (CLIP), a universal large cross-modal vision-language pre-training model, has remarkably performed over various cross-modal downstream tasks due to its powerful cross-modal semantic learning capacity. TPBS, as a fine-grained cross-modal retrieval task, is also facing the rise of research on the CLIP-based TBPS. In order to explore the potential of the visual-language pre-training model for downstream TBPS tasks, this paper makes the first attempt to conduct a comprehensive empirical study of CLIP for TBPS and thus contribute a straightforward, incremental, yet strong TBPS-CLIP baseline to the TBPS community. We revisit critical design considerations under CLIP, including data augmentation and loss function. The model, with the aforementioned designs and practical training tricks, can attain satisfactory performance without any sophisticated modules. Also, we conduct the probing experiments of TBPS-CLIP in model generalization and model compression, demonstrating the effectiveness of TBPS-CLIP from various aspects. This work is expected to provide empirical insights and highlight future CLIP-based TBPS research.
Dual Branch Deep Learning Network for Detection and Stage Grading of Diabetic Retinopathy
Aug 19, 2023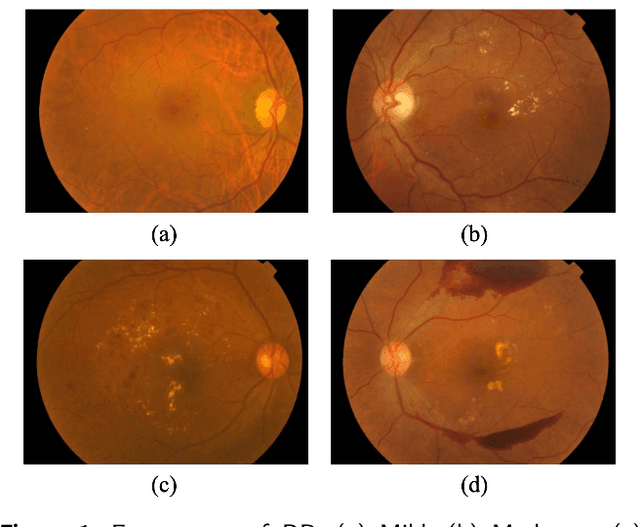
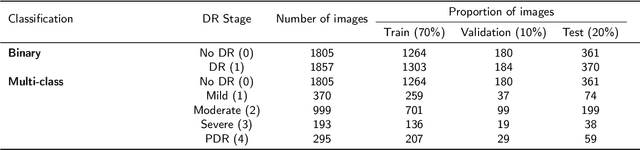
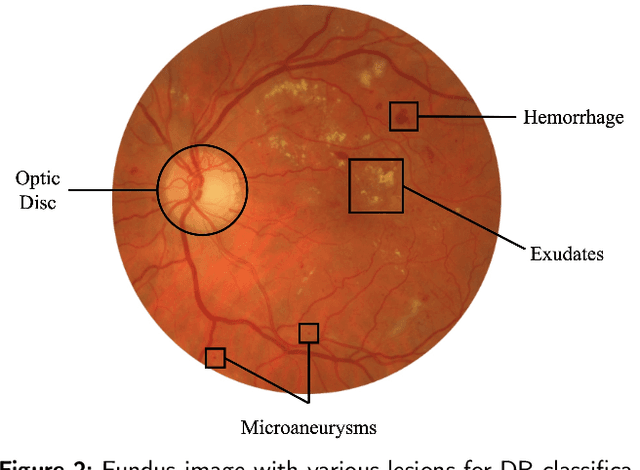
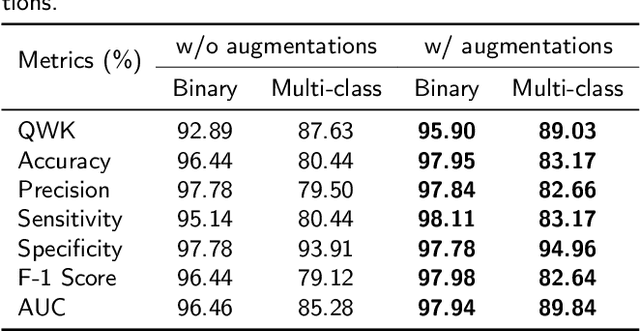
Diabetic retinopathy is a severe complication of diabetes that can lead to permanent blindness if not treated promptly. Early and accurate diagnosis of the disease is essential for successful treatment. This paper introduces a deep learning method for the detection and stage grading of diabetic retinopathy, using a single fundus retinal image. Our model utilizes transfer learning, employing two state-of-the-art pre-trained models as feature extractors and fine-tuning them on a new dataset. The proposed model is trained on a large multi-center dataset, including the APTOS 2019 dataset, obtained from publicly available sources. It achieves remarkable performance in diabetic retinopathy detection and stage classification on the APTOS 2019, outperforming the established literature. For binary classification, the proposed approach achieves an accuracy of 98.50%, a sensitivity of 99.46%, and a specificity of 97.51%. In stage grading, it achieves a quadratic weighted kappa of 93.00%, an accuracy of 89.60%, a sensitivity of 89.60%, and a specificity of 97.72%. The proposed approach serves as a reliable screening and stage grading tool for diabetic retinopathy, offering significant potential to enhance clinical decision-making and patient care.
ControlRetriever: Harnessing the Power of Instructions for Controllable Retrieval
Aug 19, 2023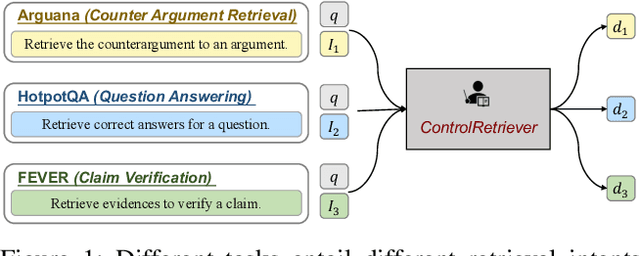
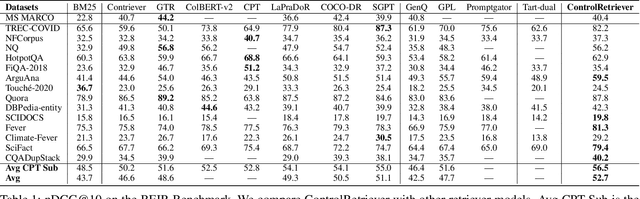
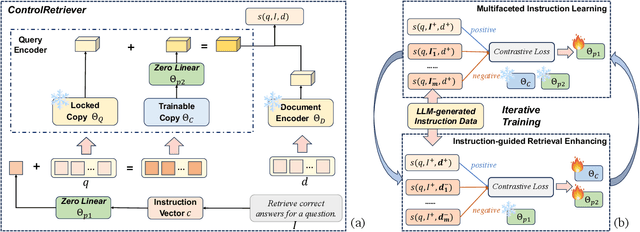
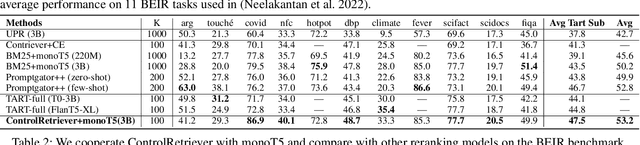
Recent studies have shown that dense retrieval models, lacking dedicated training data, struggle to perform well across diverse retrieval tasks, as different retrieval tasks often entail distinct search intents. To address this challenge, in this work we introduce ControlRetriever, a generic and efficient approach with a parameter isolated architecture, capable of controlling dense retrieval models to directly perform varied retrieval tasks, harnessing the power of instructions that explicitly describe retrieval intents in natural language. Leveraging the foundation of ControlNet, which has proven powerful in text-to-image generation, ControlRetriever imbues different retrieval models with the new capacity of controllable retrieval, all while being guided by task-specific instructions. Furthermore, we propose a novel LLM guided Instruction Synthesizing and Iterative Training strategy, which iteratively tunes ControlRetriever based on extensive automatically-generated retrieval data with diverse instructions by capitalizing the advancement of large language models. Extensive experiments show that in the BEIR benchmark, with only natural language descriptions of specific retrieval intent for each task, ControlRetriever, as a unified multi-task retrieval system without task-specific tuning, significantly outperforms baseline methods designed with task-specific retrievers and also achieves state-of-the-art zero-shot performance.
Numerical Uncertainty of Convolutional Neural Networks Inference for Structural Brain MRI Analysis
Aug 03, 2023This paper investigates the numerical uncertainty of Convolutional Neural Networks (CNNs) inference for structural brain MRI analysis. It applies Random Rounding -- a stochastic arithmetic technique -- to CNN models employed in non-linear registration (SynthMorph) and whole-brain segmentation (FastSurfer), and compares the resulting numerical uncertainty to the one measured in a reference image-processing pipeline (FreeSurfer recon-all). Results obtained on 32 representative subjects show that CNN predictions are substantially more accurate numerically than traditional image-processing results (non-linear registration: 19 vs 13 significant bits on average; whole-brain segmentation: 0.99 vs 0.92 S{\o}rensen-Dice score on average), which suggests a better reproducibility of CNN results across execution environments.
A Differential Testing Framework to Evaluate Image Recognition Model Robustness
Jun 05, 2023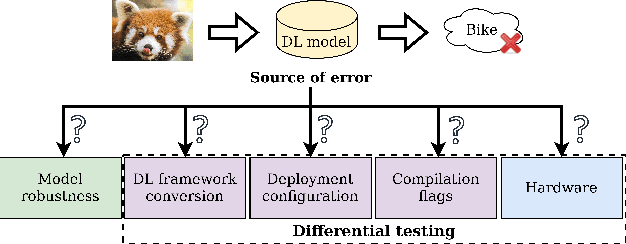
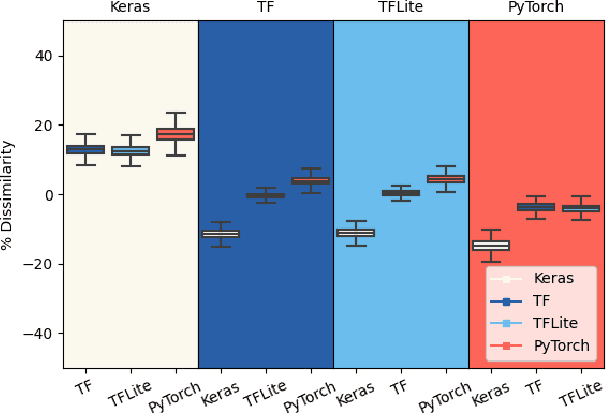
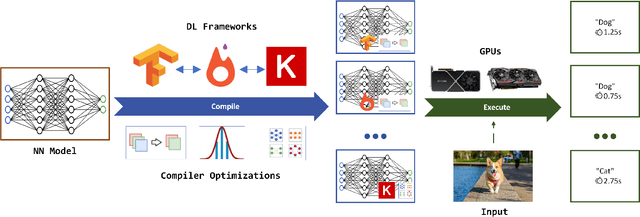
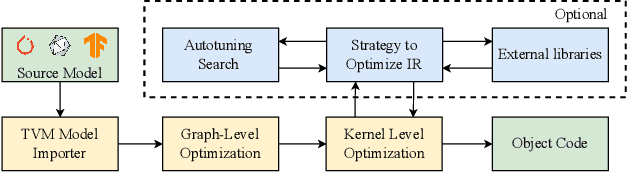
Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and TPUs for fast, timely processing. Failure in real-time image recognition tasks can occur due to sub-optimal mapping on hardware accelerators during model deployment, which may lead to timing uncertainty and erroneous behavior. Mapping on hardware accelerators is done through multiple software components like deep learning frameworks, compilers, device libraries, that we refer to as the computational environment. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment, as the impact of parameters like deep learning frameworks, compiler optimizations, and hardware devices on model performance and correctness is not well understood. In this paper we present a differential testing framework, which allows deep learning model variant generation, execution, differential analysis and testing for a number of computational environment parameters. Using our framework, we conduct an empirical study of robustness analysis of three popular image recognition models using the ImageNet dataset, assessing the impact of changing deep learning frameworks, compiler optimizations, and hardware devices. We report the impact in terms of misclassifications and inference time differences across different settings. In total, we observed up to 72% output label differences across deep learning frameworks, and up to 82% unexpected performance degradation in terms of inference time, when applying compiler optimizations. Using the analysis tools in our framework, we also perform fault analysis to understand the reasons for the observed differences.