 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data-iterative Optimization Score Model for Stable Ultra-Sparse-View CT Reconstruction
Aug 28, 2023
Score-based generative models (SGMs) have gained prominence in sparse-view CT reconstruction for their precise sampling of complex distributions. In SGM-based reconstruction, data consistency in the score-based diffusion model ensures close adherence of generated samples to observed data distribution, crucial for improving image quality. Shortcomings in data consistency characterization manifest in three aspects. Firstly, data from the optimization process can lead to artifacts in reconstructed images. Secondly, it often neglects that the generation model and original data constraints are independently completed, fragmenting unity. Thirdly, it predominantly focuses on constraining intermediate results in the inverse sampling process, rather than ideal real images. Thus, we propose an iterative optimization data scoring model. This paper introduces the data-iterative optimization score-based model (DOSM), integrating innovative data consistency into the Stochastic Differential Equation, a valuable constraint for ultra-sparse-view CT reconstruction. The novelty of this data consistency element lies in its sole reliance on original measurement data to confine generation outcomes, effectively balancing measurement data and generative model constraints. Additionally, we pioneer an inference strategy that traces back from current iteration results to ideal truth, enhancing reconstruction stability. We leverage conventional iteration techniques to optimize DOSM updates. Quantitative and qualitative results from 23 views of numerical and clinical cardiac datasets demonstrate DOSM's superiority over other methods. Remarkably, even with 10 views, our method achieves excellent performance.
MS-Net: A Multi-modal Self-supervised Network for Fine-Grained Classification of Aircraft in SAR Images
Aug 28, 2023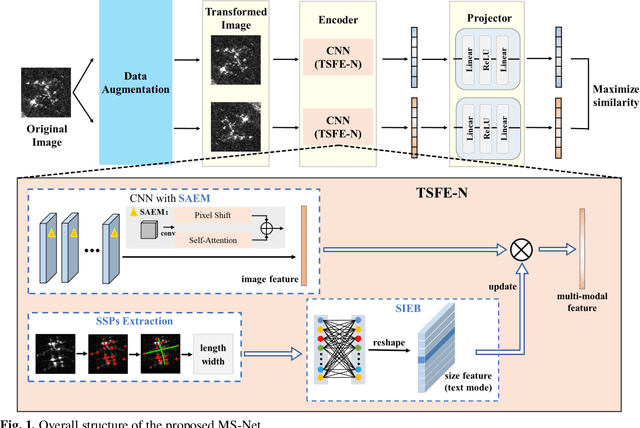
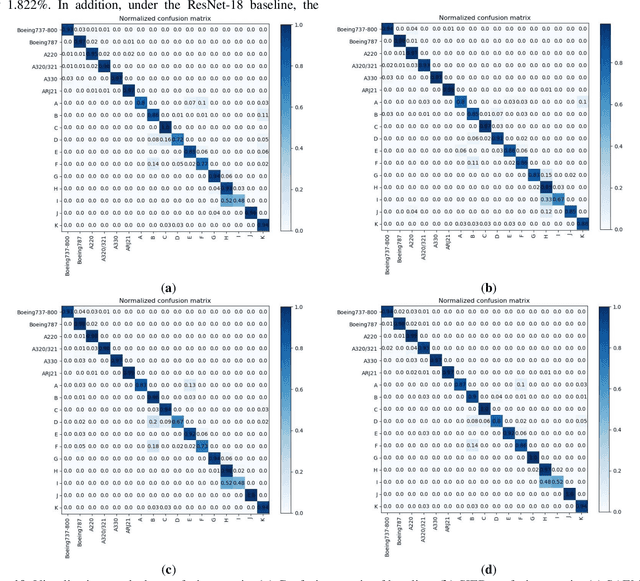
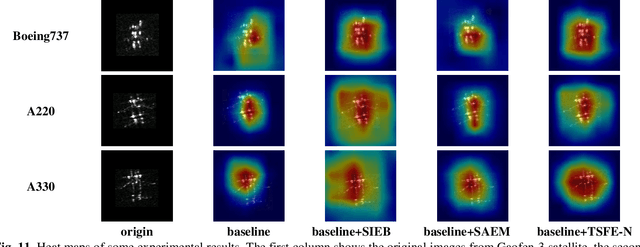
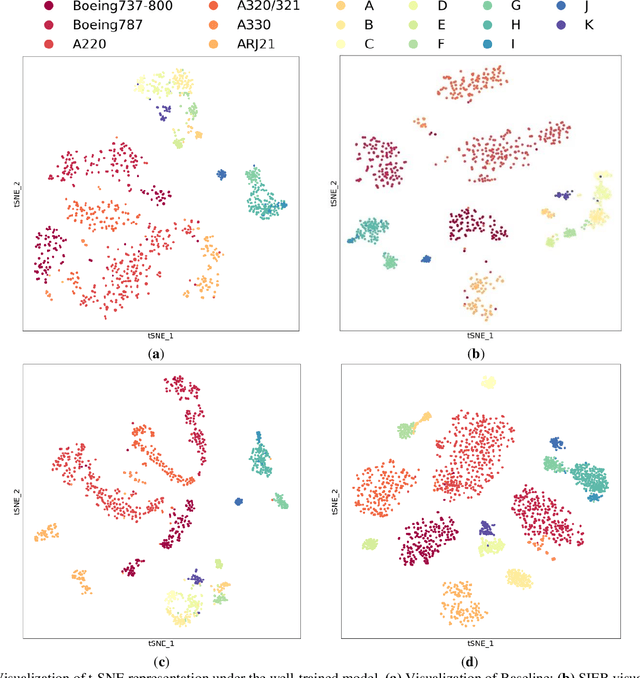
Synthetic aperture radar (SAR) imaging technology is commonly used to provide 24-hour all-weather earth observation. However, it still has some drawbacks in SAR target classification, especially in fine-grained classification of aircraft: aircrafts in SAR images have large intra-class diversity and inter-class similarity; the number of effective samples is insufficient and it's hard to annotate. To address these issues, this article proposes a novel multi-modal self-supervised network (MS-Net) for fine-grained classification of aircraft. Firstly, in order to entirely exploit the potential of multi-modal information, a two-sided path feature extraction network (TSFE-N) is constructed to enhance the image feature of the target and obtain the domain knowledge feature of text mode. Secondly, a contrastive self-supervised learning (CSSL) framework is employed to effectively learn useful label-independent feature from unbalanced data, a similarity per-ception loss (SPloss) is proposed to avoid network overfitting. Finally, TSFE-N is used as the encoder of CSSL to obtain the classification results. Through a large number of experiments, our MS-Net can effectively reduce the difficulty of classifying similar types of aircrafts. In the case of no label, the proposed algorithm achieves an accuracy of 88.46% for 17 types of air-craft classification task, which has pioneering significance in the field of fine-grained classification of aircraft in SAR images.
Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
Aug 10, 2023

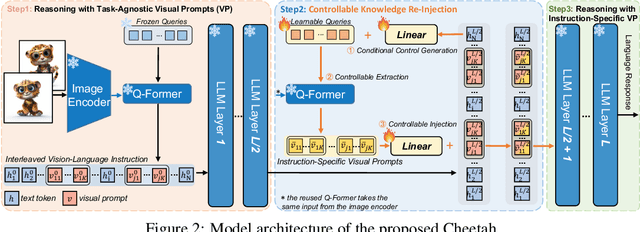
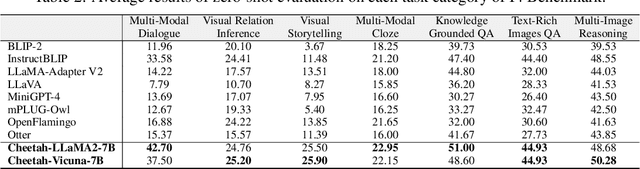
Multimodal Large Language Models (MLLMs) have recently sparked significant interest, which demonstrates emergent capabilities to serve as a general-purpose model for various vision-language tasks. However, existing methods mainly focus on limited types of instructions with a single image as visual context, which hinders the widespread availability of MLLMs. In this paper, we introduce the I4 benchmark to comprehensively evaluate the instruction following ability on complicated interleaved vision-language instructions, which involve intricate image-text sequential context, covering a diverse range of scenarios (e.g., visually-rich webpages/textbooks, lecture slides, embodied dialogue). Systematic evaluation on our I4 benchmark reveals a common defect of existing methods: the Visual Prompt Generator (VPG) trained on image-captioning alignment objective tends to attend to common foreground information for captioning but struggles to extract specific information required by particular tasks. To address this issue, we propose a generic and lightweight controllable knowledge re-injection module, which utilizes the sophisticated reasoning ability of LLMs to control the VPG to conditionally extract instruction-specific visual information and re-inject it into the LLM. Further, we introduce an annotation-free cross-attention guided counterfactual image training strategy to methodically learn the proposed module by collaborating a cascade of foundation models. Enhanced by the proposed module and training strategy, we present Cheetor, a Transformer-based MLLM that can effectively handle a wide variety of interleaved vision-language instructions and achieves state-of-the-art zero-shot performance across all tasks of I4, without high-quality multimodal instruction tuning data. Cheetor also exhibits competitive performance compared with state-of-the-art instruction tuned models on MME benchmark.
TriDo-Former: A Triple-Domain Transformer for Direct PET Reconstruction from Low-Dose Sinograms
Aug 10, 2023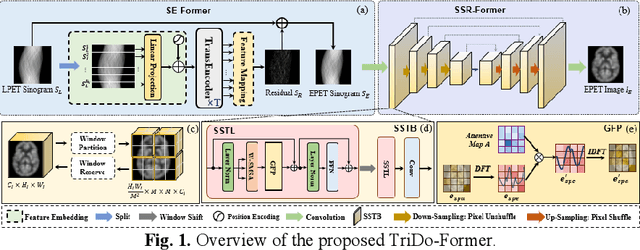
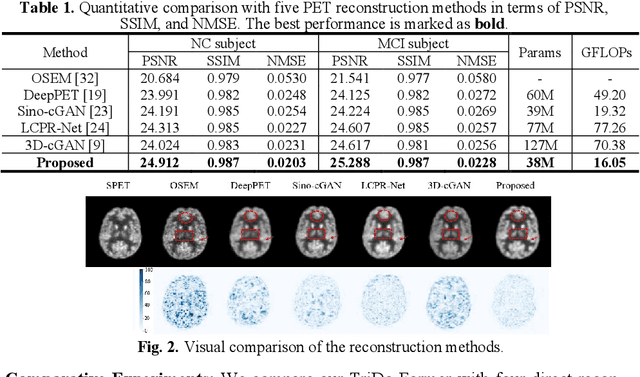
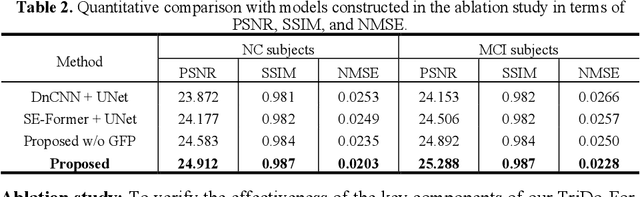
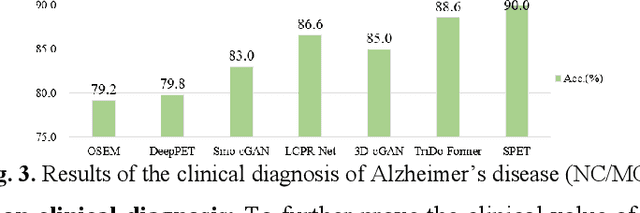
To obtain high-quality positron emission tomography (PET) images while minimizing radiation exposure, various methods have been proposed for reconstructing standard-dose PET (SPET) images from low-dose PET (LPET) sinograms directly. However, current methods often neglect boundaries during sinogram-to-image reconstruction, resulting in high-frequency distortion in the frequency domain and diminished or fuzzy edges in the reconstructed images. Furthermore, the convolutional architectures, which are commonly used, lack the ability to model long-range non-local interactions, potentially leading to inaccurate representations of global structures. To alleviate these problems, we propose a transformer-based model that unites triple domains of sinogram, image, and frequency for direct PET reconstruction, namely TriDo-Former. Specifically, the TriDo-Former consists of two cascaded networks, i.e., a sinogram enhancement transformer (SE-Former) for denoising the input LPET sinograms and a spatial-spectral reconstruction transformer (SSR-Former) for reconstructing SPET images from the denoised sinograms. Different from the vanilla transformer that splits an image into 2D patches, based specifically on the PET imaging mechanism, our SE-Former divides the sinogram into 1D projection view angles to maintain its inner-structure while denoising, preventing the noise in the sinogram from prorogating into the image domain. Moreover, to mitigate high-frequency distortion and improve reconstruction details, we integrate global frequency parsers (GFPs) into SSR-Former. The GFP serves as a learnable frequency filter that globally adjusts the frequency components in the frequency domain, enforcing the network to restore high-frequency details resembling real SPET images. Validations on a clinical dataset demonstrate that our TriDo-Former outperforms the state-of-the-art methods qualitatively and quantitatively.
2D3D-MATR: 2D-3D Matching Transformer for Detection-free Registration between Images and Point Clouds
Aug 10, 2023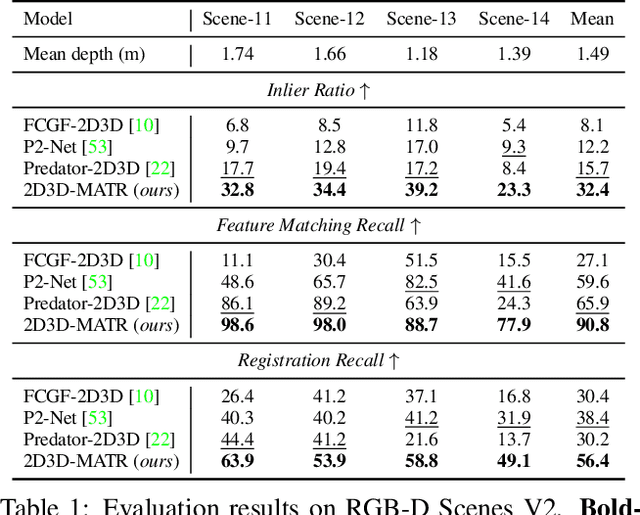
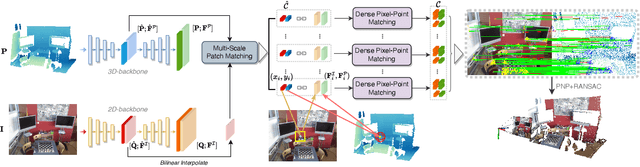
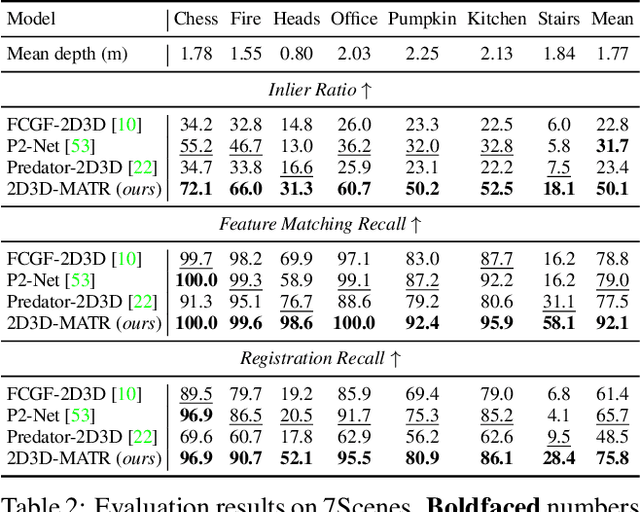
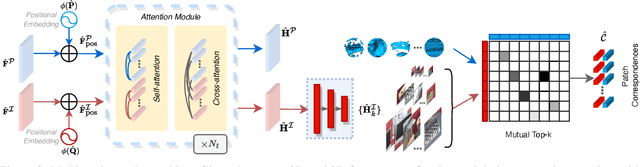
The commonly adopted detect-then-match approach to registration finds difficulties in the cross-modality cases due to the incompatible keypoint detection and inconsistent feature description. We propose, 2D3D-MATR, a detection-free method for accurate and robust registration between images and point clouds. Our method adopts a coarse-to-fine pipeline where it first computes coarse correspondences between downsampled patches of the input image and the point cloud and then extends them to form dense correspondences between pixels and points within the patch region. The coarse-level patch matching is based on transformer which jointly learns global contextual constraints with self-attention and cross-modality correlations with cross-attention. To resolve the scale ambiguity in patch matching, we construct a multi-scale pyramid for each image patch and learn to find for each point patch the best matching image patch at a proper resolution level. Extensive experiments on two public benchmarks demonstrate that 2D3D-MATR outperforms the previous state-of-the-art P2-Net by around $20$ percentage points on inlier ratio and over $10$ points on registration recall. Our code and models are available at \url{https://github.com/minhaolee/2D3DMATR}.
Federated Learning for Medical Image Analysis: A Survey
Jun 09, 2023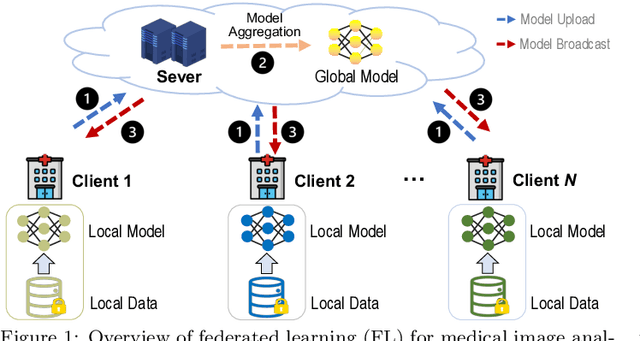
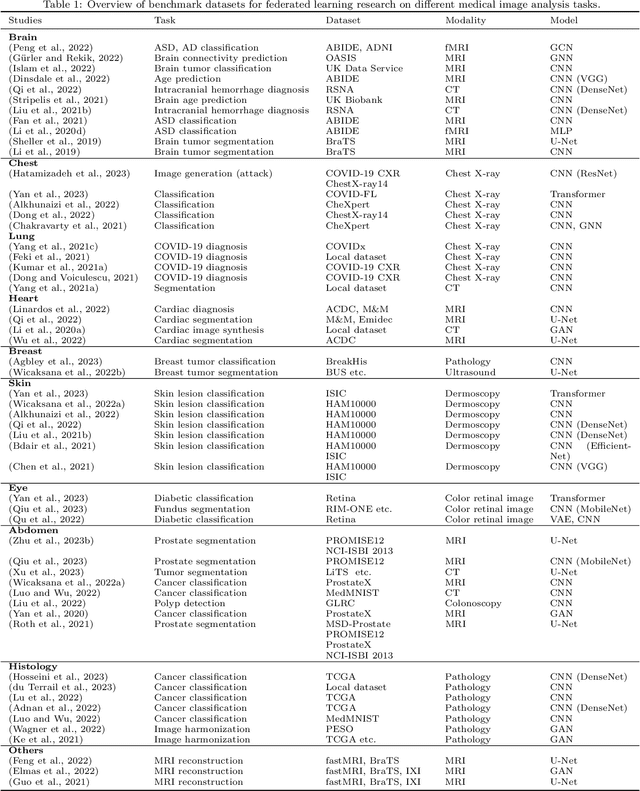
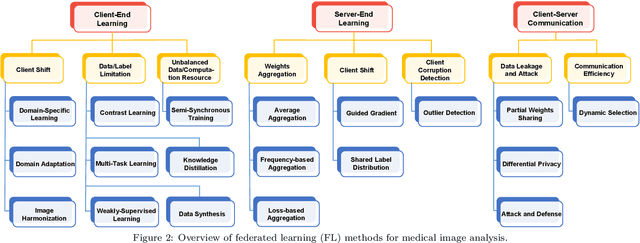
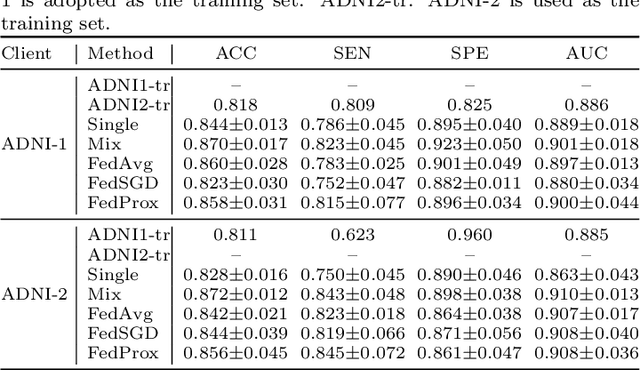
Machine learning in medical imaging often faces a fundamental dilemma, namely the small sample size problem. Many recent studies suggest using multi-domain data pooled from different acquisition sites/datasets to improve statistical power. However, medical images from different sites cannot be easily shared to build large datasets for model training due to privacy protection reasons. As a promising solution, federated learning, which enables collaborative training of machine learning models based on data from different sites without cross-site data sharing, has attracted considerable attention recently. In this paper, we conduct a comprehensive survey of the recent development of federated learning methods in medical image analysis. We first introduce the background and motivation of federated learning for dealing with privacy protection and collaborative learning issues in medical imaging. We then present a comprehensive review of recent advances in federated learning methods for medical image analysis. Specifically, existing methods are categorized based on three critical aspects of a federated learning system, including client end, server end, and communication techniques. In each category, we summarize the existing federated learning methods according to specific research problems in medical image analysis and also provide insights into the motivations of different approaches. In addition, we provide a review of existing benchmark medical imaging datasets and software platforms for current federated learning research. We also conduct an experimental study to empirically evaluate typical federated learning methods for medical image analysis. This survey can help to better understand the current research status, challenges and potential research opportunities in this promising research field.
From Global to Local: Multi-scale Out-of-distribution Detection
Aug 20, 2023Out-of-distribution (OOD) detection aims to detect "unknown" data whose labels have not been seen during the in-distribution (ID) training process. Recent progress in representation learning gives rise to distance-based OOD detection that recognizes inputs as ID/OOD according to their relative distances to the training data of ID classes. Previous approaches calculate pairwise distances relying only on global image representations, which can be sub-optimal as the inevitable background clutter and intra-class variation may drive image-level representations from the same ID class far apart in a given representation space. In this work, we overcome this challenge by proposing Multi-scale OOD DEtection (MODE), a first framework leveraging both global visual information and local region details of images to maximally benefit OOD detection. Specifically, we first find that existing models pretrained by off-the-shelf cross-entropy or contrastive losses are incompetent to capture valuable local representations for MODE, due to the scale-discrepancy between the ID training and OOD detection processes. To mitigate this issue and encourage locally discriminative representations in ID training, we propose Attention-based Local PropAgation (ALPA), a trainable objective that exploits a cross-attention mechanism to align and highlight the local regions of the target objects for pairwise examples. During test-time OOD detection, a Cross-Scale Decision (CSD) function is further devised on the most discriminative multi-scale representations to distinguish ID/OOD data more faithfully. We demonstrate the effectiveness and flexibility of MODE on several benchmarks -- on average, MODE outperforms the previous state-of-the-art by up to 19.24% in FPR, 2.77% in AUROC. Code is available at https://github.com/JimZAI/MODE-OOD.
Learnable Weight Initialization for Volumetric Medical Image Segmentation
Jun 28, 2023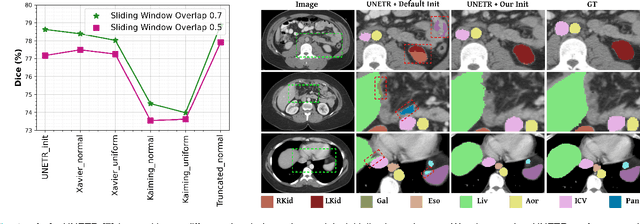
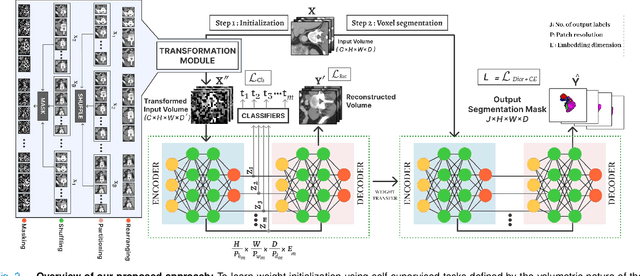
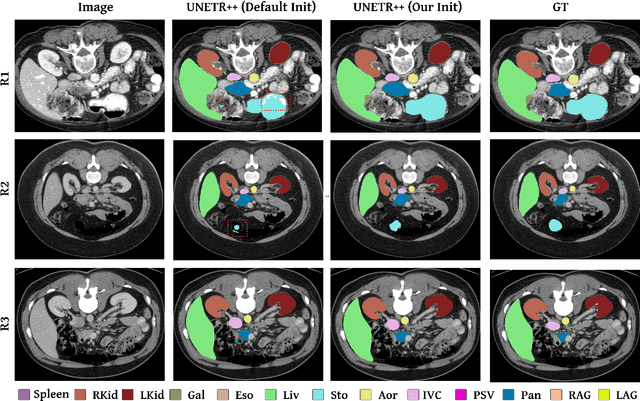
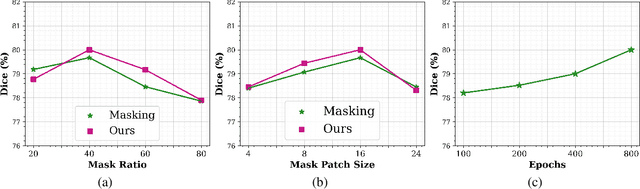
Hybrid volumetric medical image segmentation models, combining the advantages of local convolution and global attention, have recently received considerable attention. While mainly focusing on architectural modifications, most existing hybrid approaches still use conventional data-independent weight initialization schemes which restrict their performance due to ignoring the inherent volumetric nature of the medical data. To address this issue, we propose a learnable weight initialization approach that utilizes the available medical training data to effectively learn the contextual and structural cues via the proposed self-supervised objectives. Our approach is easy to integrate into any hybrid model and requires no external training data. Experiments on multi-organ and lung cancer segmentation tasks demonstrate the effectiveness of our approach, leading to state-of-the-art segmentation performance. Our proposed data-dependent initialization approach performs favorably as compared to the Swin-UNETR model pretrained using large-scale datasets on multi-organ segmentation task. Our source code and models are available at: https://github.com/ShahinaKK/LWI-VMS.
ACLS: Adaptive and Conditional Label Smoothing for Network Calibration
Aug 24, 2023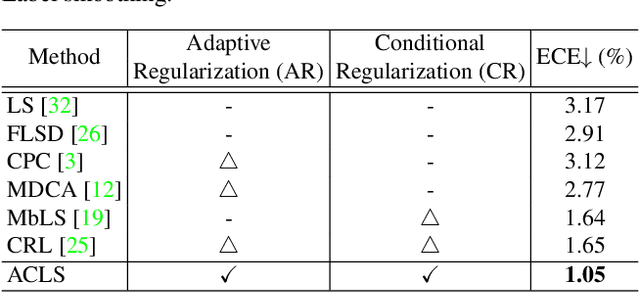
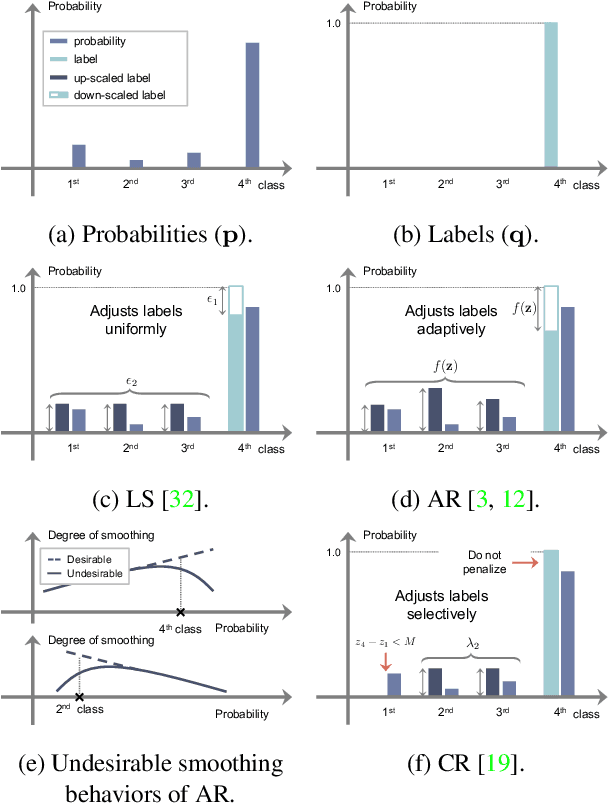
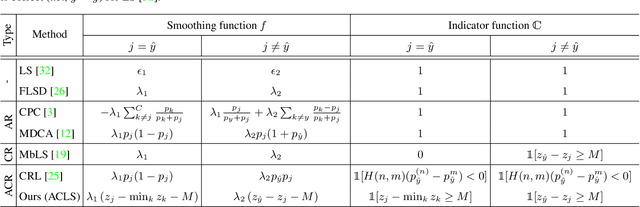
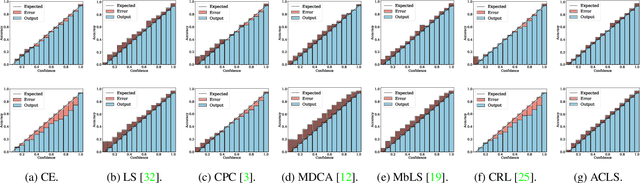
We address the problem of network calibration adjusting miscalibrated confidences of deep neural networks. Many approaches to network calibration adopt a regularization-based method that exploits a regularization term to smooth the miscalibrated confidences. Although these approaches have shown the effectiveness on calibrating the networks, there is still a lack of understanding on the underlying principles of regularization in terms of network calibration. We present in this paper an in-depth analysis of existing regularization-based methods, providing a better understanding on how they affect to network calibration. Specifically, we have observed that 1) the regularization-based methods can be interpreted as variants of label smoothing, and 2) they do not always behave desirably. Based on the analysis, we introduce a novel loss function, dubbed ACLS, that unifies the merits of existing regularization methods, while avoiding the limitations. We show extensive experimental results for image classification and semantic segmentation on standard benchmarks, including CIFAR10, Tiny-ImageNet, ImageNet, and PASCAL VOC, demonstrating the effectiveness of our loss function.
PartSeg: Few-shot Part Segmentation via Part-aware Prompt Learning
Aug 24, 2023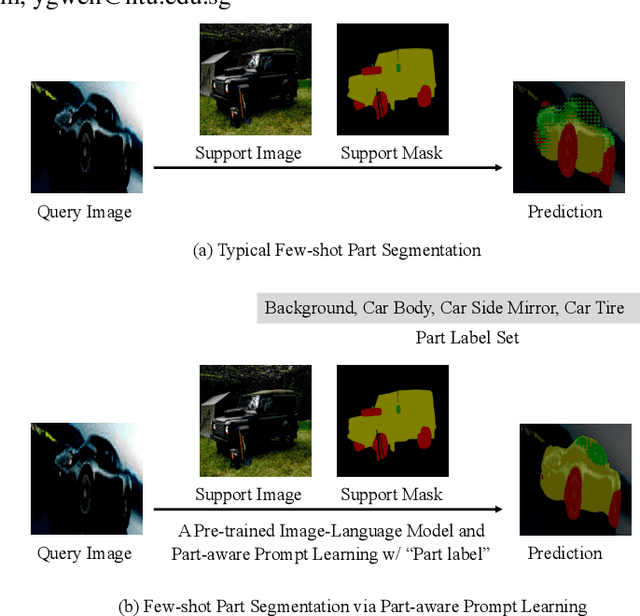

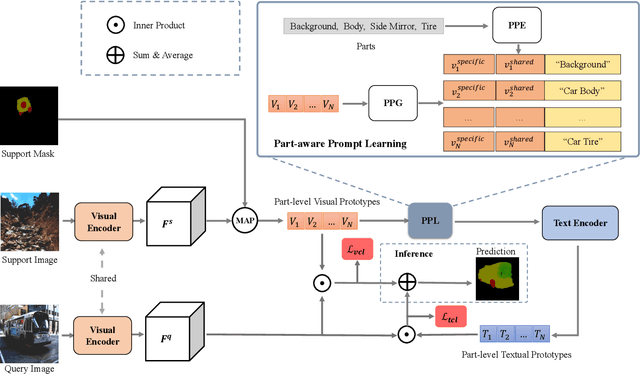

In this work, we address the task of few-shot part segmentation, which aims to segment the different parts of an unseen object using very few labeled examples. It is found that leveraging the textual space of a powerful pre-trained image-language model (such as CLIP) can be beneficial in learning visual features. Therefore, we develop a novel method termed PartSeg for few-shot part segmentation based on multimodal learning. Specifically, we design a part-aware prompt learning method to generate part-specific prompts that enable the CLIP model to better understand the concept of ``part'' and fully utilize its textual space. Furthermore, since the concept of the same part under different object categories is general, we establish relationships between these parts during the prompt learning process. We conduct extensive experiments on the PartImageNet and Pascal$\_$Part datasets, and the experimental results demonstrated that our proposed method achieves state-of-the-art performance.