 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pose-Free Neural Radiance Fields via Implicit Pose Regularization
Aug 29, 2023

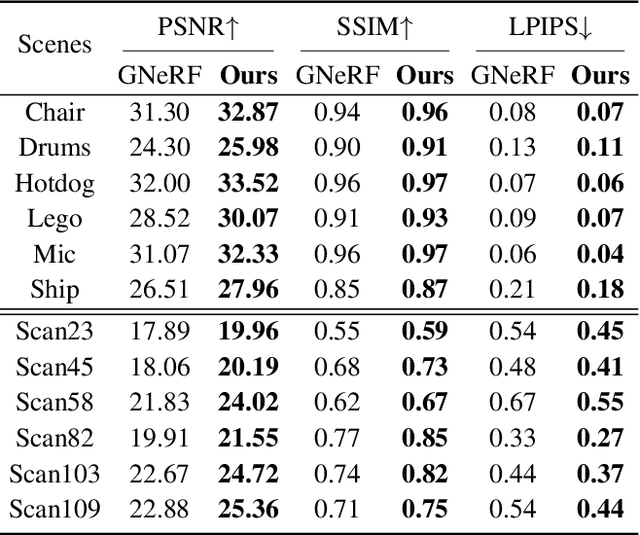
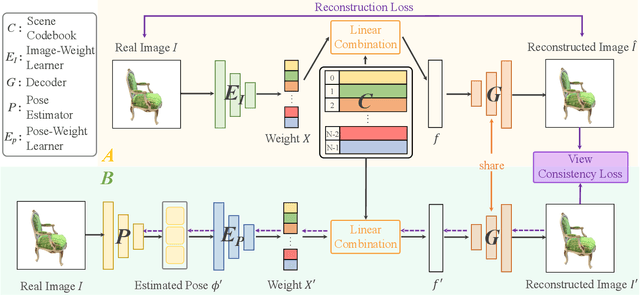
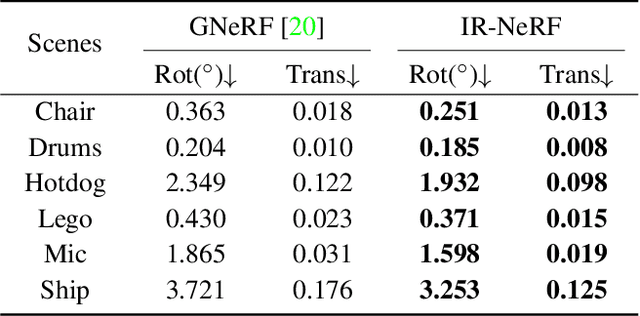
Pose-free neural radiance fields (NeRF) aim to train NeRF with unposed multi-view images and it has achieved very impressive success in recent years. Most existing works share the pipeline of training a coarse pose estimator with rendered images at first, followed by a joint optimization of estimated poses and neural radiance field. However, as the pose estimator is trained with only rendered images, the pose estimation is usually biased or inaccurate for real images due to the domain gap between real images and rendered images, leading to poor robustness for the pose estimation of real images and further local minima in joint optimization. We design IR-NeRF, an innovative pose-free NeRF that introduces implicit pose regularization to refine pose estimator with unposed real images and improve the robustness of the pose estimation for real images. With a collection of 2D images of a specific scene, IR-NeRF constructs a scene codebook that stores scene features and captures the scene-specific pose distribution implicitly as priors. Thus, the robustness of pose estimation can be promoted with the scene priors according to the rationale that a 2D real image can be well reconstructed from the scene codebook only when its estimated pose lies within the pose distribution. Extensive experiments show that IR-NeRF achieves superior novel view synthesis and outperforms the state-of-the-art consistently across multiple synthetic and real datasets.
Generative Model for Models: Rapid DNN Customization for Diverse Tasks and Resource Constraints
Aug 29, 2023Unlike cloud-based deep learning models that are often large and uniform, edge-deployed models usually demand customization for domain-specific tasks and resource-limited environments. Such customization processes can be costly and time-consuming due to the diversity of edge scenarios and the training load for each scenario. Although various approaches have been proposed for rapid resource-oriented customization and task-oriented customization respectively, achieving both of them at the same time is challenging. Drawing inspiration from the generative AI and the modular composability of neural networks, we introduce NN-Factory, an one-for-all framework to generate customized lightweight models for diverse edge scenarios. The key idea is to use a generative model to directly produce the customized models, instead of training them. The main components of NN-Factory include a modular supernet with pretrained modules that can be conditionally activated to accomplish different tasks and a generative module assembler that manipulate the modules according to task and sparsity requirements. Given an edge scenario, NN-Factory can efficiently customize a compact model specialized in the edge task while satisfying the edge resource constraints by searching for the optimal strategy to assemble the modules. Based on experiments on image classification and object detection tasks with different edge devices, NN-Factory is able to generate high-quality task- and resource-specific models within few seconds, faster than conventional model customization approaches by orders of magnitude.
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
Aug 29, 2023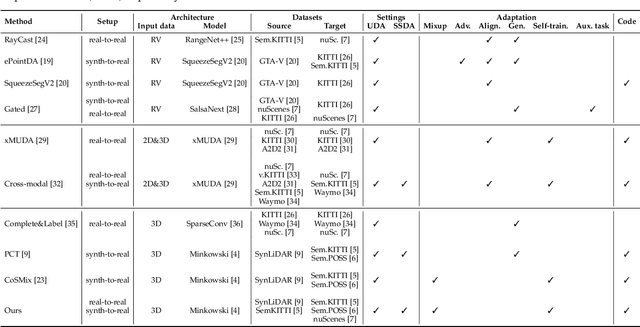
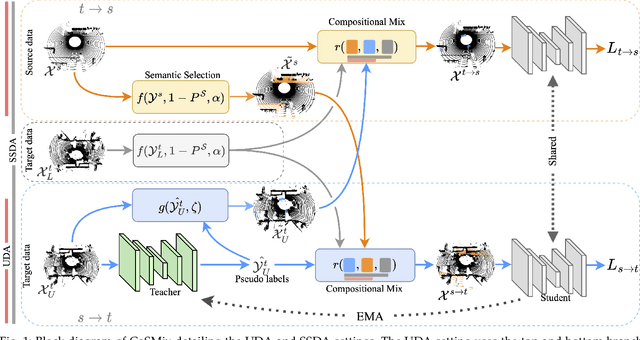
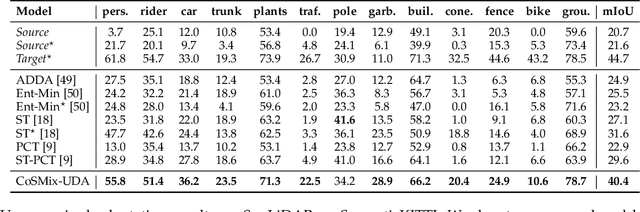
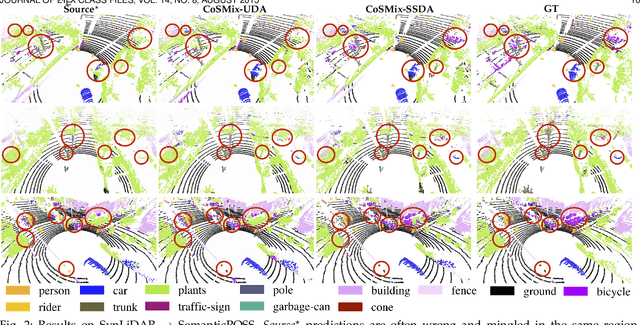
Deep-learning models for 3D point cloud semantic segmentation exhibit limited generalization capabilities when trained and tested on data captured with different sensors or in varying environments due to domain shift. Domain adaptation methods can be employed to mitigate this domain shift, for instance, by simulating sensor noise, developing domain-agnostic generators, or training point cloud completion networks. Often, these methods are tailored for range view maps or necessitate multi-modal input. In contrast, domain adaptation in the image domain can be executed through sample mixing, which emphasizes input data manipulation rather than employing distinct adaptation modules. In this study, we introduce compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. We present a two-branch symmetric network architecture capable of concurrently processing point clouds from a source domain (e.g. synthetic) and point clouds from a target domain (e.g. real-world). Each branch operates within one domain by integrating selected data fragments from the other domain and utilizing semantic information derived from source labels and target (pseudo) labels. Additionally, our method can leverage a limited number of human point-level annotations (semi-supervised) to further enhance performance. We assess our approach in both synthetic-to-real and real-to-real scenarios using LiDAR datasets and demonstrate that it significantly outperforms state-of-the-art methods in both unsupervised and semi-supervised settings.
RACR-MIL: Weakly Supervised Skin Cancer Grading using Rank-Aware Contextual Reasoning on Whole Slide Images
Aug 29, 2023Cutaneous squamous cell cancer (cSCC) is the second most common skin cancer in the US. It is diagnosed by manual multi-class tumor grading using a tissue whole slide image (WSI), which is subjective and suffers from inter-pathologist variability. We propose an automated weakly-supervised grading approach for cSCC WSIs that is trained using WSI-level grade and does not require fine-grained tumor annotations. The proposed model, RACR-MIL, transforms each WSI into a bag of tiled patches and leverages attention-based multiple-instance learning to assign a WSI-level grade. We propose three key innovations to address general as well as cSCC-specific challenges in tumor grading. First, we leverage spatial and semantic proximity to define a WSI graph that encodes both local and non-local dependencies between tumor regions and leverage graph attention convolution to derive contextual patch features. Second, we introduce a novel ordinal ranking constraint on the patch attention network to ensure that higher-grade tumor regions are assigned higher attention. Third, we use tumor depth as an auxiliary task to improve grade classification in a multitask learning framework. RACR-MIL achieves 2-9% improvement in grade classification over existing weakly-supervised approaches on a dataset of 718 cSCC tissue images and localizes the tumor better. The model achieves 5-20% higher accuracy in difficult-to-classify high-risk grade classes and is robust to class imbalance.
Unsupervised Low Light Image Enhancement Using SNR-Aware Swin Transformer
Jun 03, 2023
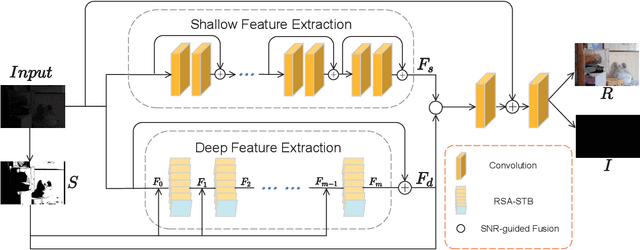
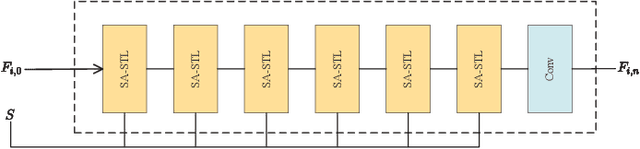
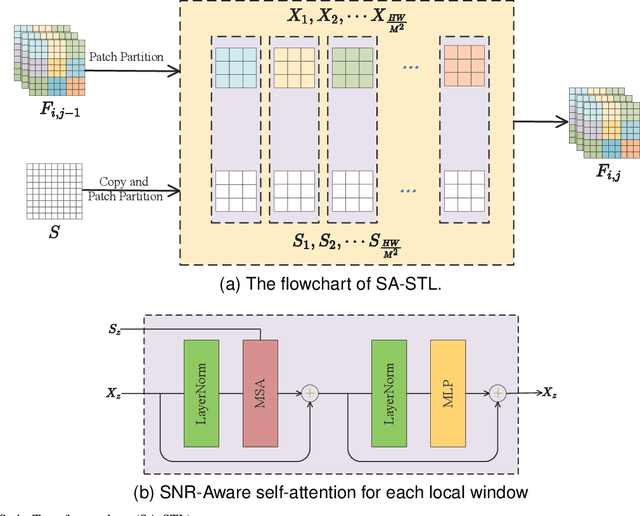
Image captured under low-light conditions presents unpleasing artifacts, which debilitate the performance of feature extraction for many upstream visual tasks. Low-light image enhancement aims at improving brightness and contrast, and further reducing noise that corrupts the visual quality. Recently, many image restoration methods based on Swin Transformer have been proposed and achieve impressive performance. However, On one hand, trivially employing Swin Transformer for low-light image enhancement would expose some artifacts, including over-exposure, brightness imbalance and noise corruption, etc. On the other hand, it is impractical to capture image pairs of low-light images and corresponding ground-truth, i.e. well-exposed image in same visual scene. In this paper, we propose a dual-branch network based on Swin Transformer, guided by a signal-to-noise ratio prior map which provides the spatial-varying information for low-light image enhancement. Moreover, we leverage unsupervised learning to construct the optimization objective based on Retinex model, to guide the training of proposed network. Experimental results demonstrate that the proposed model is competitive with the baseline models.
Expert-Agnostic Ultrasound Image Quality Assessment using Deep Variational Clustering
Jul 06, 2023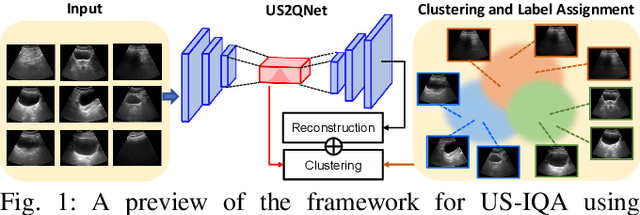
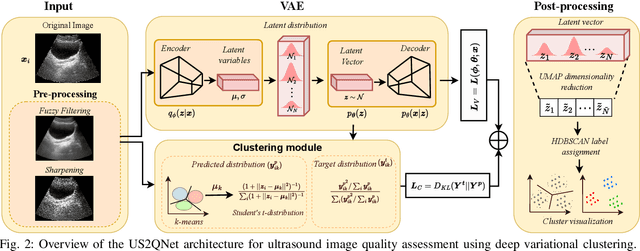
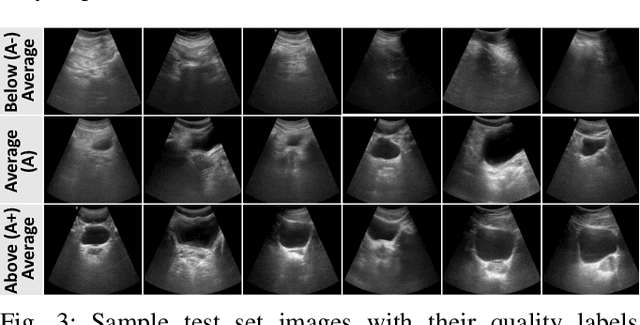
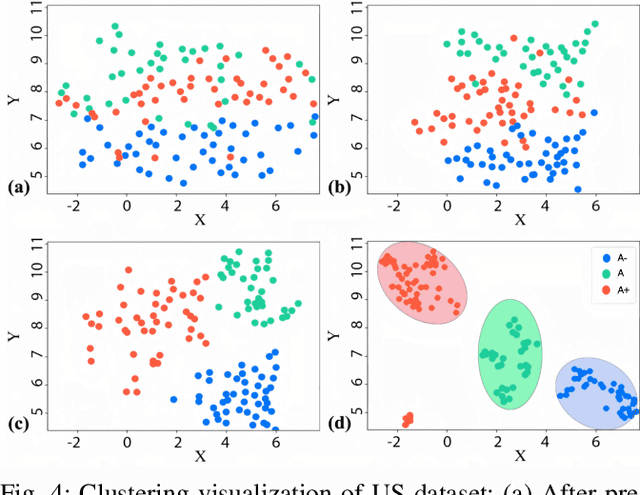
Ultrasound imaging is a commonly used modality for several diagnostic and therapeutic procedures. However, the diagnosis by ultrasound relies heavily on the quality of images assessed manually by sonographers, which diminishes the objectivity of the diagnosis and makes it operator-dependent. The supervised learning-based methods for automated quality assessment require manually annotated datasets, which are highly labour-intensive to acquire. These ultrasound images are low in quality and suffer from noisy annotations caused by inter-observer perceptual variations, which hampers learning efficiency. We propose an UnSupervised UltraSound image Quality assessment Network, US2QNet, that eliminates the burden and uncertainty of manual annotations. US2QNet uses the variational autoencoder embedded with the three modules, pre-processing, clustering and post-processing, to jointly enhance, extract, cluster and visualize the quality feature representation of ultrasound images. The pre-processing module uses filtering of images to point the network's attention towards salient quality features, rather than getting distracted by noise. Post-processing is proposed for visualizing the clusters of feature representations in 2D space. We validated the proposed framework for quality assessment of the urinary bladder ultrasound images. The proposed framework achieved 78% accuracy and superior performance to state-of-the-art clustering methods.
All-pairs Consistency Learning for Weakly Supervised Semantic Segmentation
Aug 08, 2023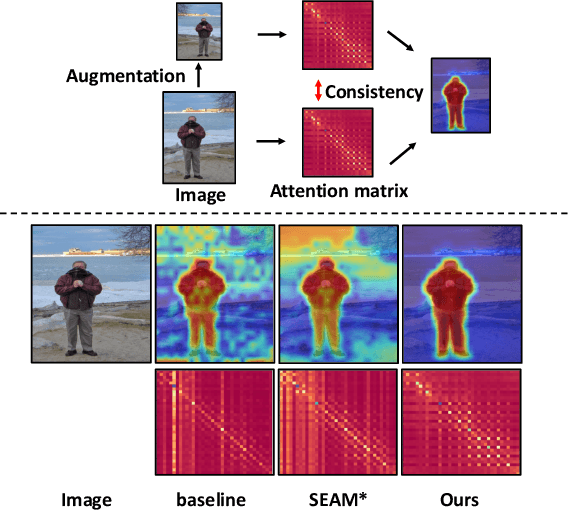
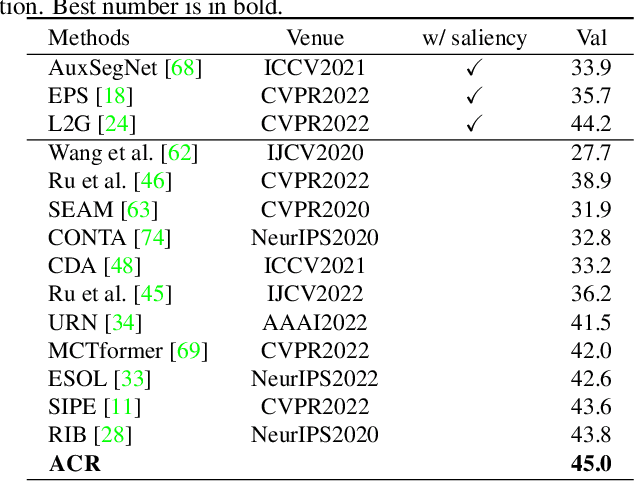
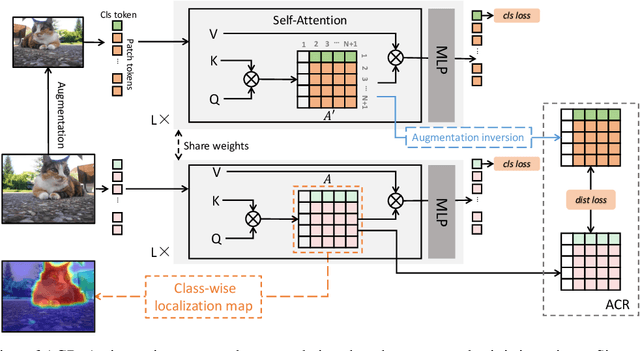

In this work, we propose a new transformer-based regularization to better localize objects for Weakly supervised semantic segmentation (WSSS). In image-level WSSS, Class Activation Map (CAM) is adopted to generate object localization as pseudo segmentation labels. To address the partial activation issue of the CAMs, consistency regularization is employed to maintain activation intensity invariance across various image augmentations. However, such methods ignore pair-wise relations among regions within each CAM, which capture context and should also be invariant across image views. To this end, we propose a new all-pairs consistency regularization (ACR). Given a pair of augmented views, our approach regularizes the activation intensities between a pair of augmented views, while also ensuring that the affinity across regions within each view remains consistent. We adopt vision transformers as the self-attention mechanism naturally embeds pair-wise affinity. This enables us to simply regularize the distance between the attention matrices of augmented image pairs. Additionally, we introduce a novel class-wise localization method that leverages the gradients of the class token. Our method can be seamlessly integrated into existing WSSS methods using transformers without modifying the architectures. We evaluate our method on PASCAL VOC and MS COCO datasets. Our method produces noticeably better class localization maps (67.3% mIoU on PASCAL VOC train), resulting in superior WSSS performances.
Federated Learning for Medical Image Analysis: A Survey
Jun 09, 2023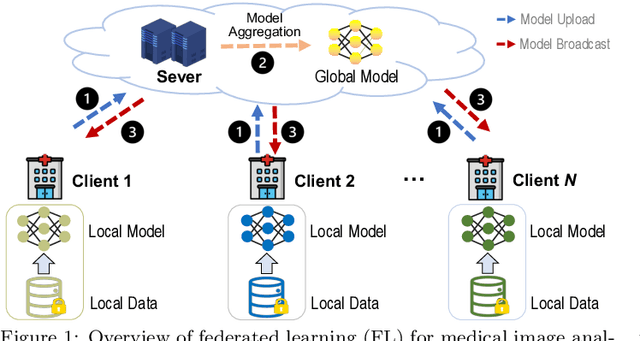
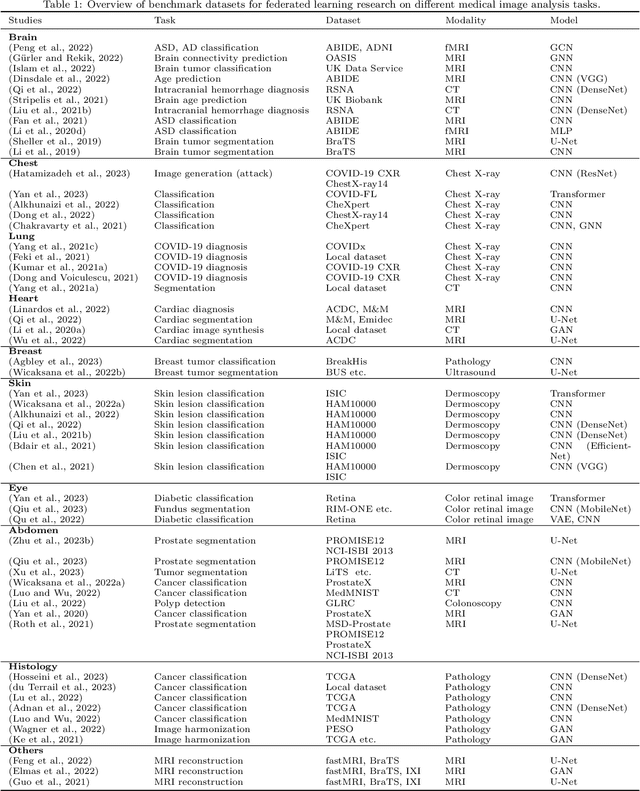
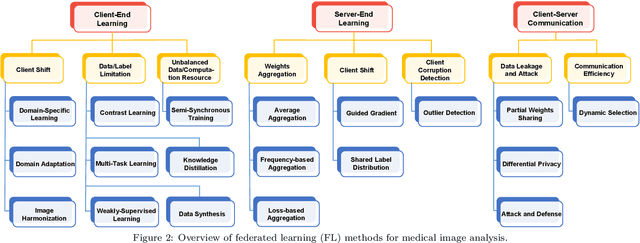
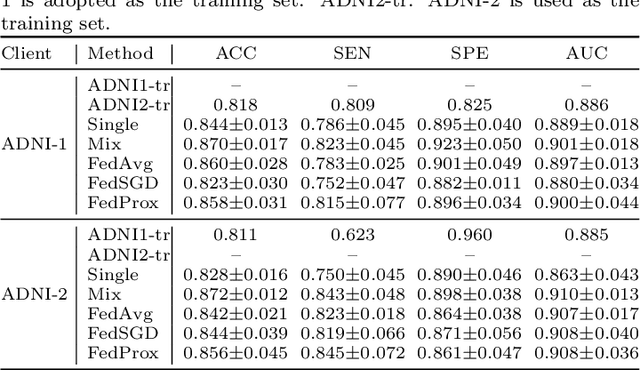
Machine learning in medical imaging often faces a fundamental dilemma, namely the small sample size problem. Many recent studies suggest using multi-domain data pooled from different acquisition sites/datasets to improve statistical power. However, medical images from different sites cannot be easily shared to build large datasets for model training due to privacy protection reasons. As a promising solution, federated learning, which enables collaborative training of machine learning models based on data from different sites without cross-site data sharing, has attracted considerable attention recently. In this paper, we conduct a comprehensive survey of the recent development of federated learning methods in medical image analysis. We first introduce the background and motivation of federated learning for dealing with privacy protection and collaborative learning issues in medical imaging. We then present a comprehensive review of recent advances in federated learning methods for medical image analysis. Specifically, existing methods are categorized based on three critical aspects of a federated learning system, including client end, server end, and communication techniques. In each category, we summarize the existing federated learning methods according to specific research problems in medical image analysis and also provide insights into the motivations of different approaches. In addition, we provide a review of existing benchmark medical imaging datasets and software platforms for current federated learning research. We also conduct an experimental study to empirically evaluate typical federated learning methods for medical image analysis. This survey can help to better understand the current research status, challenges and potential research opportunities in this promising research field.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Aug 31, 2023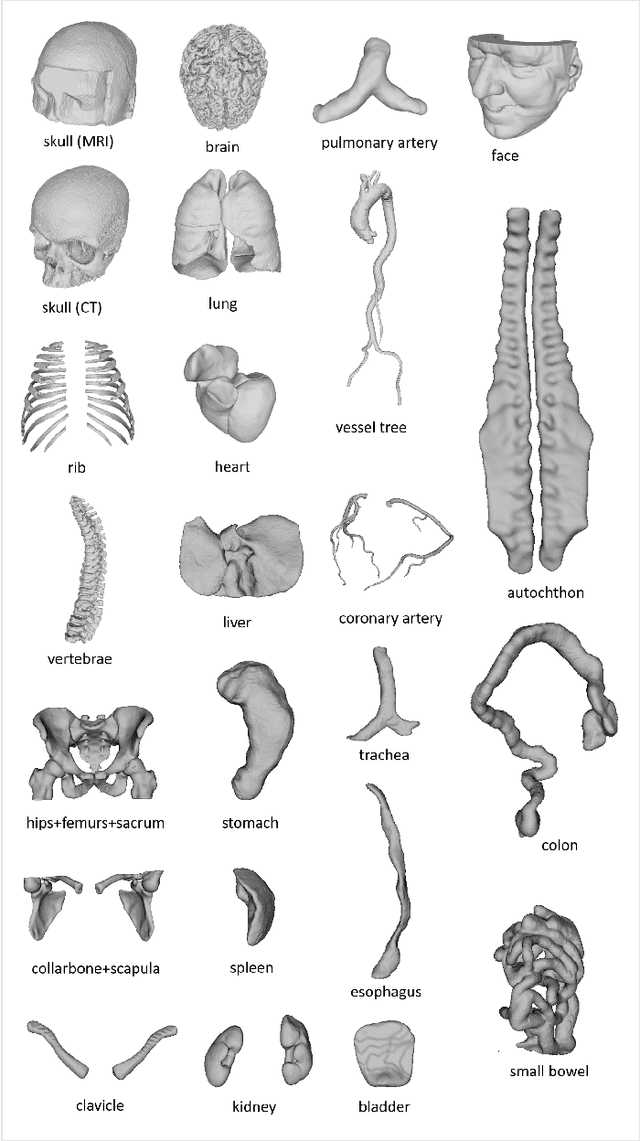

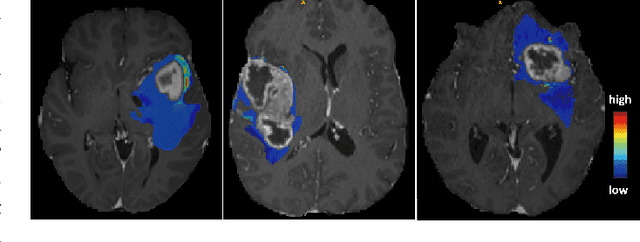
We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
AntM$^{2}$C: A Large Scale Dataset For Multi-Scenario Multi-Modal CTR Prediction
Aug 31, 2023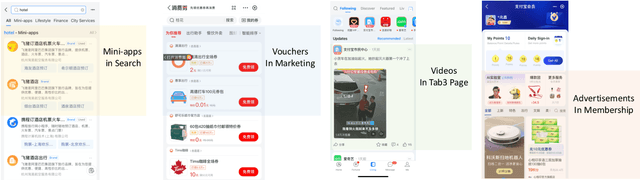
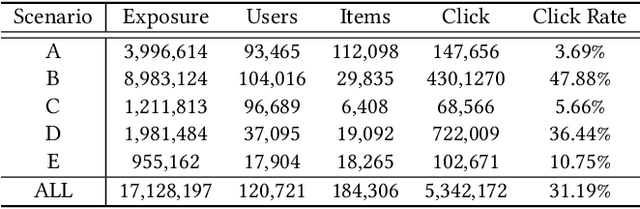
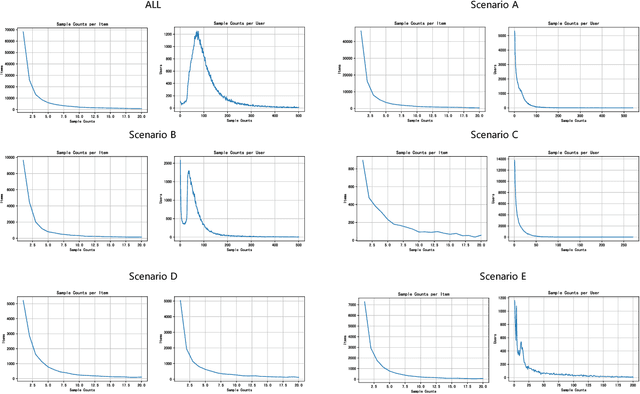
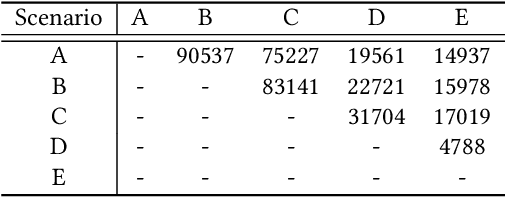
Click-through rate (CTR) prediction is a crucial issue in recommendation systems. There has been an emergence of various public CTR datasets. However, existing datasets primarily suffer from the following limitations. Firstly, users generally click different types of items from multiple scenarios, and modeling from multiple scenarios can provide a more comprehensive understanding of users. Existing datasets only include data for the same type of items from a single scenario. Secondly, multi-modal features are essential in multi-scenario prediction as they address the issue of inconsistent ID encoding between different scenarios. The existing datasets are based on ID features and lack multi-modal features. Third, a large-scale dataset can provide a more reliable evaluation of models, fully reflecting the performance differences between models. The scale of existing datasets is around 100 million, which is relatively small compared to the real-world CTR prediction. To address these limitations, we propose AntM$^{2}$C, a Multi-Scenario Multi-Modal CTR dataset based on industrial data from Alipay. Specifically, AntM$^{2}$C provides the following advantages: 1) It covers CTR data of 5 different types of items, providing insights into the preferences of users for different items, including advertisements, vouchers, mini-programs, contents, and videos. 2) Apart from ID-based features, AntM$^{2}$C also provides 2 multi-modal features, raw text and image features, which can effectively establish connections between items with different IDs. 3) AntM$^{2}$C provides 1 billion CTR data with 200 features, including 200 million users and 6 million items. It is currently the largest-scale CTR dataset available. Based on AntM$^{2}$C, we construct several typical CTR tasks and provide comparisons with baseline methods. The dataset homepage is available at https://www.atecup.cn/home.